













Iedereen die vandaag de dag in DevOps werkt, zou waarschijnlijk instemmen dat het coderen van resources het gemakkelijker maakt om te observeren, te reguleren en te automatiseren. Echter, de meeste ingenieurs zouden ook erkennen dat deze transformatie gepaard gaat met een nieuwe reeks uitdagingen.
Misschien is de grootste uitdaging van IaC-operaties de afwijkingen – een scenario waarbij run-time omgevingen afwijken van hun IaC-gedefinieerde status, wat een smeulend probleem creëert met ernstige langetermijngevolgen. Deze inconsistenties ondermijnen de consistentie van cloudomgevingen, wat kan leiden tot potentiële problemen met de betrouwbaarheid en onderhoudbaarheid van de infrastructuur, en zelfs aanzienlijke beveiligings- en nalevingsrisico’s.
In een poging om deze risico’s te minimaliseren, classificeren degenen die verantwoordelijk zijn voor het beheer van deze omgevingen afwijkingen als een taak van hoge prioriteit (en een belangrijke tijdsverspilling) voor infrastructuurteams.
Dit heeft geleid tot een groeiende adoptie van tools voor driftdetectie die afwijkingen markeren tussen de gewenste configuratie en de werkelijke status van de infrastructuur. Hoewel effectief in het detecteren van afwijkingen, zijn deze oplossingen beperkt tot het geven van waarschuwingen en het benadrukken van codeverschillen, zonder diepgaande inzichten in de oorzaak.
Waarom Driftdetectie tekortschiet
De huidige staat van driftdetectie is het gevolg van het feit dat drifts optreden buiten de gevestigde CI/CD-pijplijn en vaak worden teruggevoerd op handmatige aanpassingen, door API geactiveerde updates of noodoplossingen. Als gevolg hiervan laten deze wijzigingen meestal geen auditspoor achter in de IaC-laag, wat een blinde vlek creëert die de tools beperkt tot alleen het signaleren van codeverschillen. Dit laat platformengineeringteams speculeren over de oorsprong van drift en hoe deze het beste kan worden aangepakt.
Deze gebrek aan duidelijkheid maakt het oplossen van drift een riskante taak. Immers, het automatisch terugdraaien van wijzigingen zonder de bedoeling ervan te begrijpen — een veelvoorkomende standaardaanpak — kan een can of worms openen en een cascade van problemen veroorzaken.
Een risico is dat dit legitieme aanpassingen of optimalisaties ongedaan kan maken, waardoor problemen opnieuw kunnen opduiken die al waren opgelost of de werking van een waardevol hulpmiddel van derden kunnen verstoren.
Neem bijvoorbeeld een handmatige oplossing die buiten het gebruikelijke IaC-proces is toegepast om een plotseling probleem in de productie aan te pakken. Voordat dergelijke wijzigingen worden teruggedraaid, is het essentieel om ze te codificeren om hun bedoeling en impact te behouden of het risico te lopen een oplossing voor te stellen die erger kan zijn dan de ziekte.
Detectie Ontmoet Context
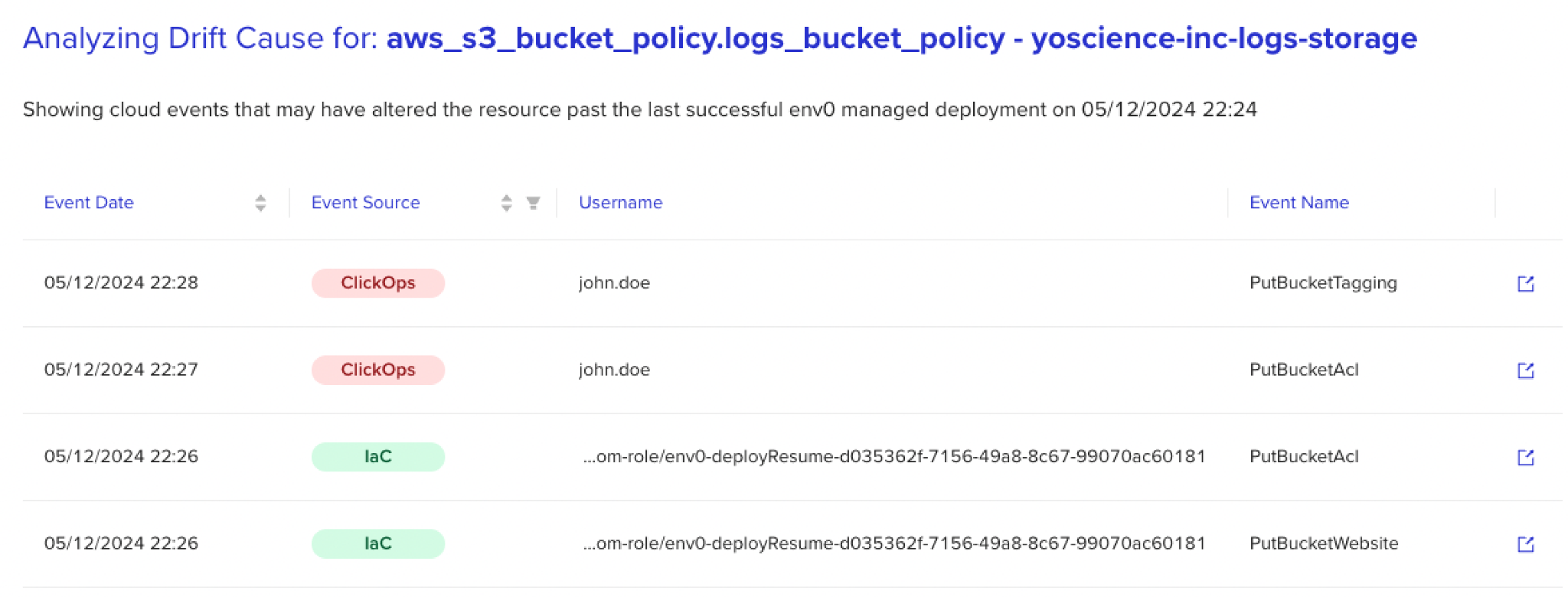
Het zien van organisaties die worstelen met deze dilemma’s heeft het concept van ‘ Drift Oorzaak ‘ geïnspireerd. Dit concept gebruikt AI-ondersteunde logica om grote evenementenlogs te doorzoeken en extra context te bieden voor elke drift, waarbij veranderingen terug naar hun oorsprong worden getraceerd – en niet alleen onthult ‘wat’, maar ook ‘wie’, ‘wanneer’ en ‘waarom.’
Deze mogelijkheid om niet-uniforme logs in bulk te verwerken en driftgerelateerde gegevens te verzamelen, verandert het script van het reconciliatieproces. Om dit te illustreren, laat me je terugbrengen naar het scenario dat ik eerder noemde en een beeld schetsen van het ontvangen van een driftmelding van je detectieoplossing – dit keer met extra context.
Nu, met de informatie die door Drift Oorzaak wordt verstrekt, kun je niet alleen op de hoogte zijn van de drift, maar ook inzoomen om te ontdekken dat de wijziging door John om 2 uur ’s nachts is aangebracht, net op het moment dat de applicatie een verkeerspiek aan het verwerken was.
Zonder deze informatie zou je kunnen aannemen dat de drift problematisch is en de wijziging terugdraaien, wat mogelijk cruciale operaties verstoort en downstream-fouten veroorzaakt.
Met de extra context krijg je echter de kans om de puzzelstukjes aan elkaar te verbinden, contact op te nemen met John, te bevestigen dat de oplossing een onmiddellijk probleem aanpakte en te besluiten dat het niet blindelings moet worden gereconcilieerd. Bovendien kun je met deze context ook vooruitdenken en aanpassingen aan de configuratie introduceren om schaalbaarheid toe te voegen en te voorkomen dat het probleem zich opnieuw voordoet.
Dit is een eenvoudig voorbeeld, natuurlijk, maar ik hoop dat het goed doet om het voordeel te laten zien van het hebben van extra context over de onderliggende oorzaak – een element dat lang heeft ontbroken in driftdetectie, hoewel het standaard is in andere gebieden van debugging en probleemoplossing. Het doel is natuurlijk om teams te helpen begrijpen niet alleen wat er is veranderd, maar ook waarom het is veranderd, zodat ze in staat zijn om met vertrouwen de beste koers van actie te bepalen.
Voorbij IaC-beheer
Maar het hebben van extra context voor drift, hoe belangrijk het ook mag zijn, is slechts één stuk van een veel grotere puzzel. Het beheren van grote cloudvloten met gecodificeerde middelen introduceert meer dan alleen driftuitdagingen, vooral op grote schaal. Huidige generatie IaC-beheer tools zijn effectief in het aanpakken van resourcebeheer, maar de vraag naar meer zichtbaarheid en controle in omgevingen op ondernemingsschaal introduceert nieuwe vereisten en drijft hun onvermijdelijke evolutie.
Een richting waarin ik deze evolutie zie bewegen is Cloud Asset Management (CAM), dat alle middelen in een cloudomgeving bijhoudt en beheert – of ze nu zijn provisioned via IaC, API’s of handmatige operaties – en een unified view van activa biedt en organisaties helpt configuraties, afhankelijkheden en risico’s te begrijpen, die allemaal essentieel zijn voor compliance, kostenoptimalisatie en operationele efficiëntie.
Terwijl het beheer van IaC zich richt op de operationele aspecten, legt Cloud Asset Management de nadruk op zichtbaarheid en begrip van de cloudpositie. Als een aanvullende observatielaag overbrugt het de kloof tussen gecodificeerde workflows en ad-hoc wijzigingen, en biedt het een uitgebreid overzicht van de infrastructuur.
1+1 Zal Drie Gelijk Zijn
De combinatie van IaC-beheer en CAM stelt teams in staat om complexiteit met helderheid en controle te beheren. Nu het einde van het jaar nadert, is het ‘voorspellingsseizoen’ — dus hier is de mijne. Na de meeste delen van het afgelopen decennium te hebben besteed aan het bouwen en verfijnen van een van de meer populaire (als ik dat zelf mag zeggen) IaC-beheerplatforms, zie ik dit als de natuurlijke voortgang van onze industrie: het combineren van IaC-beheer, automatisering en governance met verbeterde zichtbaarheid in niet-gecodificeerde activa.
Deze synergie, geloof ik, zal de basis vormen voor een beter soort cloud governance-framework — één die preciezer, aanpasbaar en toekomstbestendig is. Tegenwoordig is het bijna een gegeven dat IaC de basis vormt van het beheer van cloudinfrastructuren. Toch moeten we ook erkennen dat niet alle activa ooit gecodificeerd zullen zijn. In dergelijke gevallen kan een end-to-end infrastructuurbeheersoplossing niet beperkt blijven tot alleen de IaC-laag.
De volgende grens is dan ook het helpen van teams om de zichtbaarheid in niet-gecodificeerde activa uit te breiden, zodat de infrastructuur, naarmate deze evolueert, naadloos blijft presteren — één verzoende afwijking tegelijk en verder.
Source:
https://dzone.com/articles/the-problem-of-drift-detection-and-drift-cause-analysis