













Amazon Simple Storage Service (S3) is een zeer schaalbare, duurzame en beveiligde objectopslagdienst aangeboden door Amazon Web Services (AWS). S3 stelt bedrijven in staat om elke hoeveelheid gegevens vanaf elke plek op het web op te slaan en op te vragen door gebruik te maken van zijn enterprise-niveau diensten. S3 is ontworpen om zeer interoperabel te zijn en integreert soepel met andere Amazon Web Services (AWS) en externe tools en technologieën om gegevens die in Amazon S3 worden opgeslagen te verwerken. Een daarvan is Amazon EMR (Elastic MapReduce), waarmee je grote hoeveelheden gegevens kunt verwerken met behulp van open-source tools zoals Spark.
Apache Spark is een open-source gedistribueerd rekeningsysteem dat wordt gebruikt voor het verwerken van grote hoeveelheden gegevens. Spark is ontworpen om snelheid te garanderen en ondersteunt verschillende gegevensbronnen, waaronder Amazon S3. Spark biedt een efficiënte manier om grote hoeveelheden gegevens te verwerken en ingewikkelde berekeningen uit te voeren in minimale tijd.
Memphis.dev is een volgende-generatie alternatief voor traditionele berichtenbrokers. Een eenvoudige, robuuste en duurzame cloud-native berichtenbroker, omgeven door een volledig ecosysteem dat de kosteneffectieve, snelle en betrouwbare ontwikkeling van moderne wachtrij-gebaseerde gebruiksgevallen mogelijk maakt.
Het gangbare patroon van berichtenbrokers is het verwijderen van berichten na het doorlopen van het gedefinieerde retentiebeleid, zoals tijd/grootte/aantal berichten. Memphis biedt een tweede opslaglaag voor langere, mogelijk oneindige retentie voor opgeslagen berichten. Elk bericht dat uit de stationaire toestand wordt verwijderd, migreert automatisch naar de tweede opslaglaag, in dit geval AWS S3.
In deze tutorial word je begeleid door het proces van het instellen van een Memphis station met een 2e opslagklasse die is verbonden met AWS S3. Een omgeving op AWS. Gevolgd door het maken van een S3 bucket, het instellen van een EMR cluster, het installeren en configureren van Apache Spark op het cluster, het voorbereiden van gegevens in S3 voor verwerking, het verwerken van gegevens met Apache Spark, beste praktijken en prestatietuning.
Het instellen van de omgeving
Memphis
- Om te beginnen, installeer eerst Memphis.
- Schakel AWS S3-integratie in via het Memphis integratiecentrum.
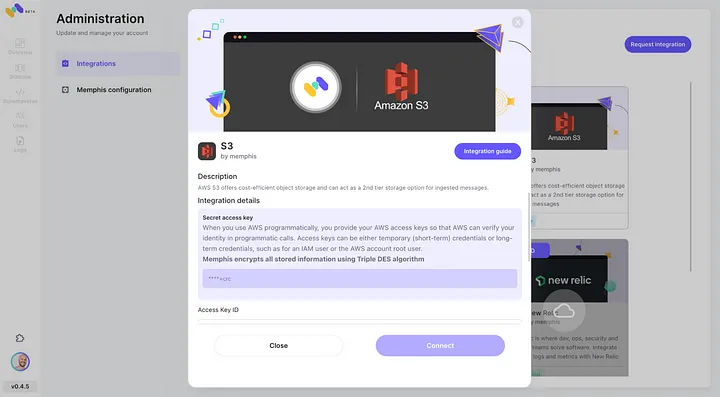
3. Maak een station (topic) en kies een retentiebeleid.
4. Elk bericht dat het geconfigureerde retentiebeleid passeert, wordt afgevoerd naar een S3 bucket.
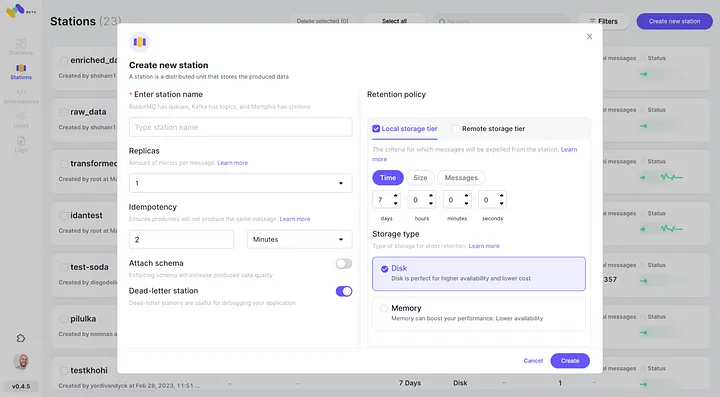
5. Controleer de zojuist geconfigureerde AWS S3-integratie als 2e opslagklasse door op “Verbinden” te klikken.
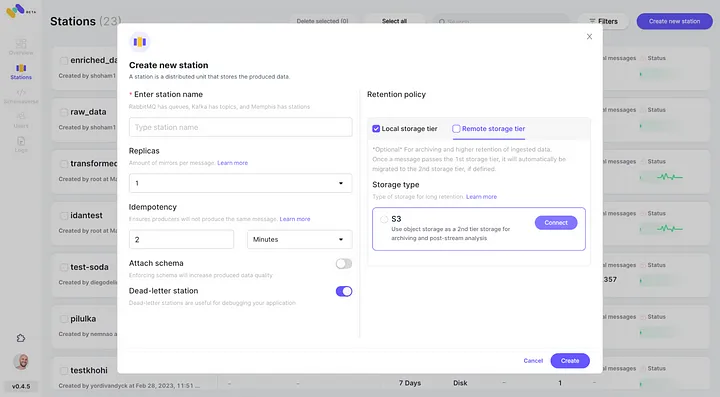
6. Begin met het produceren van gebeurtenissen voor je zojuist gemaakte Memphis station.
Maak een AWS S3 Bucket
Als je dat nog niet gedaan hebt, moet je eerst een AWS account aanmaken. Vervolgens, maak je een S3 bucket aan waar je je gegevens kunt opslaan. Je kunt de AWS Management Console, de AWS CLI, of een SDK gebruiken om een bucket te maken. Voor deze tutorial ga je de AWS management console gebruiken.
Klik op “Bucket aanmaken.”
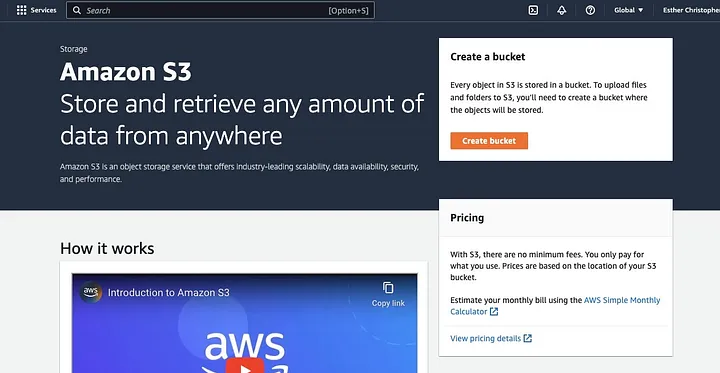
Vervolgens ga je een bucketnaam aanmaken die voldoet aan de naamgevingsconventie en kies je de regio waar je de bucket wilt plaatsen. Configureer de “Object eigendom” en “Alle publieke toegang blokkeren” naar je gebruiksvoorbeeld.
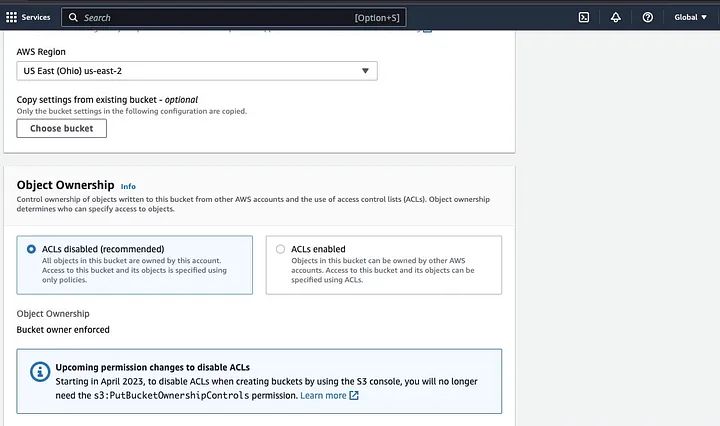
Zorg ervoor dat je andere bucketmachtigingen configureert om je Spark-toepassing toegang te geven tot de gegevens. Tot slot, klik op de “Bucket aanmaken” knop om de bucket te creëren.
Instellen van een EMR Cluster met Spark Geïnstalleerd
Amazon Elastic MapReduce (EMR) is een webservice gebaseerd op Apache Hadoop die gebruikers in staat stelt om kosteneffectief grote hoeveelheden gegevens te verwerken met behulp van big data-technologieën, inclusief Apache Spark. Om een EMR cluster te maken met Spark geïnstalleerd, open je de EMR console en selecteer “Clusters” onder “EMR on EC2” aan de linkerkant van de pagina.
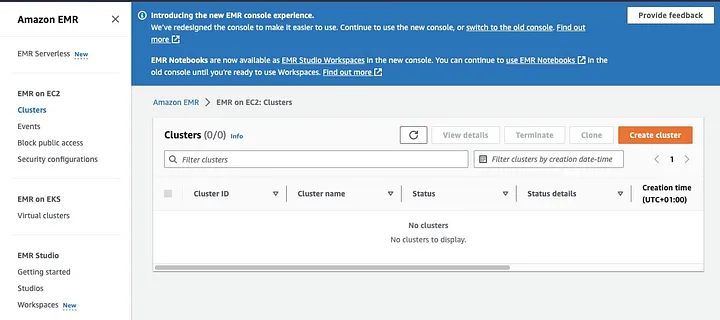
Klik op “Cluster aanmaken” en geef het cluster een beschrijvende naam. Onder “Application bundle,” selecteer Spark om het op je cluster te installeren.
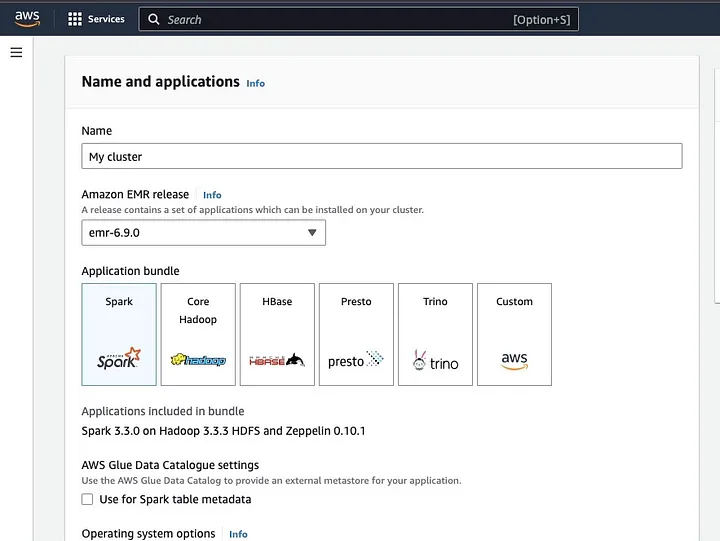
Scrol omlaag naar de sectie “Cluster logs” en selecteer het selectievakje van Publish cluster-specifieke logs naar Amazon S3.
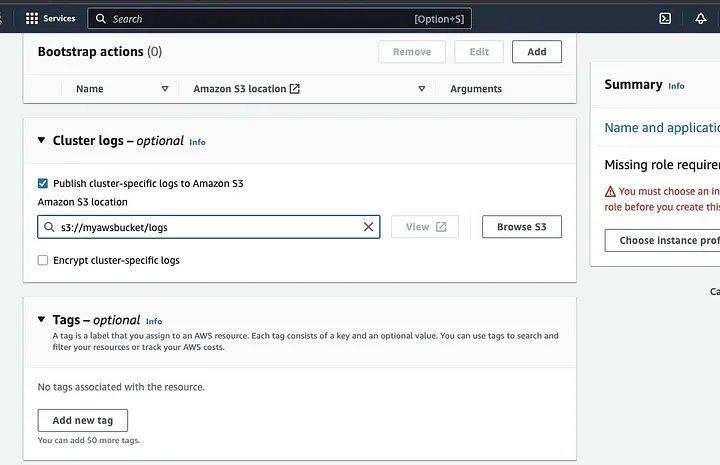
Dit zal een prompt creëren om de Amazon S3 locatie in te voeren met behulp van de S3 bucket naam die je in de vorige stap hebt gemaakt, gevolgd door /logs, bijvoorbeeld s3://myawsbucket/logs. /logs zijn vereist door Amazon om een nieuwe map in je bucket te maken waar Amazon EMR de logbestanden van je cluster kan kopiëren.
Ga naar de “Security configuration and permissions sectie” en voer je EC2 sleutelpaar in of ga akkoord met de optie om er een te maken.
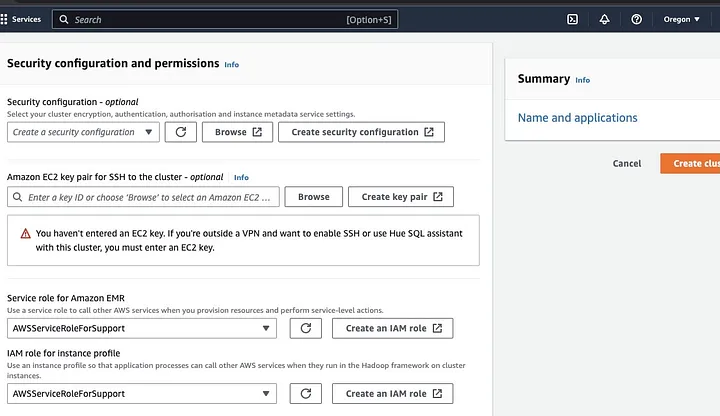
Klik vervolgens op de vervolgkeuzemogelijkheden voor “Service role for Amazon EMR” en kies AWSServiceRoleForSupport. Kies dezelfde vervolgkeuzemogelijkheid voor “IAM role for instance profile.” Vernieuw het pictogram indien nodig om deze vervolgkeuzemogelijkheden te krijgen.
Tot slot klik je op de knop “Create cluster” om het cluster te starten en controleer de clusterstatus om te bevestigen dat het is gemaakt.
Installatie en configuratie van Apache Spark op EMR Cluster
Nadat je een EMR cluster hebt gemaakt, is de volgende stap om Apache Spark op het EMR Cluster te configureren. De EMR clusters bieden een beheerde omgeving voor het uitvoeren van Spark-toepassingen op AWS-infrastructuur, waardoor het gemakkelijk is om Spark-clusters in de cloud te starten en te beheren. Het configureert Spark om te werken met je gegevens en verwerkingsbehoeften en vervolgens Spark-taken naar het cluster te verzenden om je gegevens te verwerken.
U kunt Apache Spark configureren voor het cluster met het Secure Shell (SSH) protocol. Maar eerst moet u de SSH-beveiligingsverbindingen met uw cluster autoriseren, die standaard zijn ingesteld toen u het EMR-cluster hebt gemaakt. Een handleiding over het autoriseren van SSH-verbindingen kan worden gevonden hier.
Om een SSH-verbinding te maken, moet u het EC2-sleutelpaar aangeven dat u hebt geselecteerd bij het maken van het cluster. Verbind vervolgens met het EMR-cluster met behulp van de Spark shell door eerst verbinding te maken met het primaire knooppunt. U moet eerst de master-public DNS van het primaire knooppunt ophalen door naar links in de AWS-console te navigeren, onder EMR op EC2, Clusters te kiezen en vervolgens het cluster te selecteren waarvan u de public DNS-naam wilt krijgen.
Typ op uw OS-terminal het volgende commando.
ssh hadoop@ec2-###-##-##-###.compute-1.amazonaws.com -i ~/mykeypair.pemVervang ec2-###-##-##-###.compute-1.amazonaws.com door de naam van uw master-public DNS en ~/mykeypair.pem door de bestands- en padnaam van uw .pem-bestand (Volg deze handleiding om het .pem bestand te krijgen). Er verschijnt een promptbericht waarop u ja moet antwoorden – typ exit om de SSH-opdracht te sluiten.
Voorbereiden van gegevens voor verwerking met Spark en uploaden naar S3-bucket
Dataprocessing vereist voorbereiding voordat het wordt geüpload om de gegevens in een formaat te presenteren dat Spark gemakkelijk kan verwerken. Het gebruikte formaat wordt beïnvloed door het type gegevens dat u heeft en de analyse die u van plan bent uit te voeren. Sommige gebruikte formaten zijn CSV, JSON en Parquet.
Maak een nieuwe Spark-sessie en laad uw gegevens in Spark met behulp van de relevante API. Gebruik bijvoorbeeld de spark.read.csv() methode om CSV-bestanden in een Spark DataFrame te lezen.
Amazon EMR, een beheerd dienst voor Hadoop-ecosystem clusters, kan worden gebruikt om gegevens te verwerken. Het vermindert de behoefte om clusters in te stellen, af te stemmen en te onderhouden. Het biedt ook andere integraties met Amazon SageMaker, bijvoorbeeld om een SageMaker model training taak vanuit een Spark-pijplijn in Amazon EMR te starten.
Zodra uw gegevens klaar zijn, kunt u met de DataFrame.write.format("s3") methode een CSV-bestand uit de Amazon S3-bucket in een Spark DataFrame lezen. U moet uw AWS-referenties hebben geconfigureerd en schrijftoegang hebben om de S3-bucket te openen.
Geef de S3-bucket en het pad op waar u de gegevens wilt opslaan. U kunt bijvoorbeeld de df.write.format("s3").save("s3://my-bucket/path/to/data") methode gebruiken om de gegevens naar de opgegeven S3-bucket te bewaren.
Zodra de gegevens zijn opgeslagen in de S3-bucket, kunt u deze vanuit andere Spark-toepassingen of tools openen, of u kunt deze downloaden voor verdere analyse of verwerking. Om de bucket te uploaden, maak een map en kies de bucket die u oorspronkelijk hebt gemaakt. Kies de knop Acties en klik op “Map maken” in de vervolgkeuzelijsten. U kunt nu de nieuwe map een naam geven.
Om de gegevensbestanden naar de bucket te uploaden, selecteer de naam van de gegevensmap.
Klik in het Upload-scherm op “Bestandsassistent” en kies “Bestanden toevoegen”.
Volg de richtlijnen in de Amazon S3-console om de bestanden te uploaden en selecteer “Uploaden starten”.
Het is belangrijk om te overwegen en de beste praktijken voor het beveiligen van uw gegevens te garanderen voordat u uw gegevens naar de S3-bucket uploadt.
Begrijpen van Gegevensindelingen en Schemas
Gegevensindelingen en schemas zijn twee gerelateerde maar volledig verschillende en belangrijke concepten in gegevensbeheer. De gegevensindeling verwijst naar de organisatie en structuur van gegevens binnen de database. Er zijn verschillende indelingen om gegevens op te slaan, zoals CSV, JSON, XML, YAML, enz. Deze indelingen bepalen hoe gegevens moeten worden georganiseerd naast de verschillende soorten gegevens en toepassingen die erop van toepassing zijn. Tegelijkertijd zijn gegevensschemas de structuur van de database zelf. Het bepaalt de lay-out van de database en zorgt ervoor dat gegevens op de juiste manier worden opgeslagen. Een database-schema specificeert de weergaven, tabellen, indexen, typen en andere elementen. Deze concepten zijn belangrijk in analyses en de visualisatie van de database.
Opruimen en Voorverwerken van Gegevens in S3
Het is essentieel om dubbel te controleren op fouten in uw gegevens voordat u ze verwerkt. Om hiermee te beginnen, open de gegevensmap die u hebt opgeslagen in uw S3-bucket en download deze naar uw lokale machine. Vervolgens laad u de gegevens in het gegevensverwerkingshulpmiddel, dat wordt gebruikt om de gegevens te reinigen en voor te verwerken. Voor deze tutorial wordt het voorverwerkingshulpmiddel Amazon Athena gebruikt, wat helpt om ongestructureerde en gestructureerde gegevens die zijn opgeslagen in Amazon S3 te analyseren.
Ga naar Amazon Athena in de AWS Console.
Klik op “Create” om een nieuwe tabel te maken en vervolgens op “CREATE TABLE”.
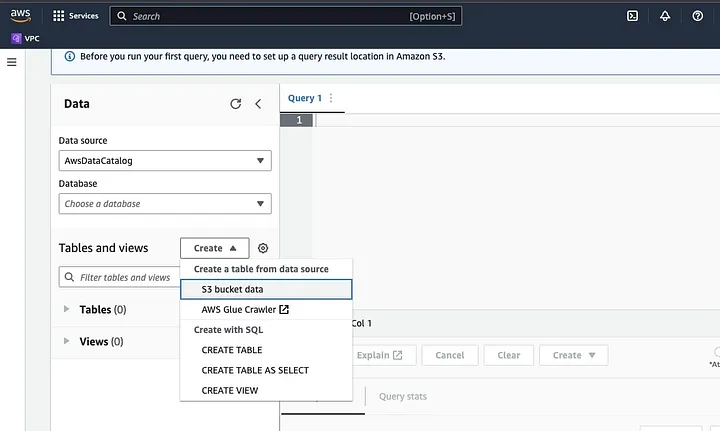
Typ het pad van uw gegevensbestand in het deel dat is gemarkeerd als LOCATION.
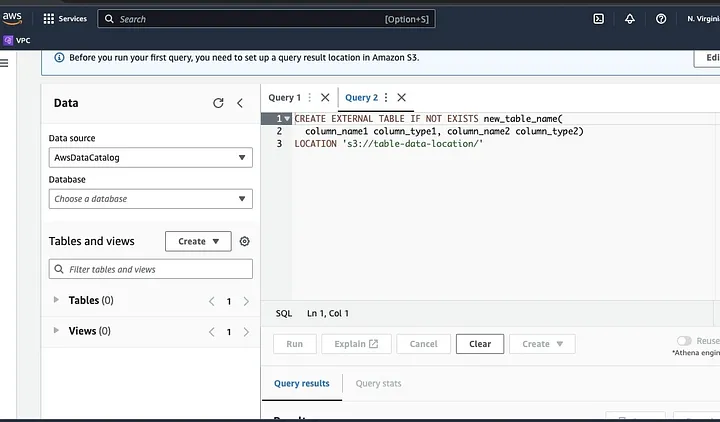
Volg de aanwijzingen om het schema voor de gegevens te definiëren en sla de tabel op. Nu kunt u een query uitvoeren om te valideren dat de gegevens correct zijn geladen en vervolgens de gegevens schoonmaken en voorbewerken
Een voorbeeld:
Deze query identificeert de duplicaten in de gegevens.
SELECT row1, row2, COUNT(*)
FROM table
GROUP row, row2
HAVING COUNT(*) > 1;Dit voorbeeld maakt een nieuwe tabel zonder duplicaten:
CREATE TABLE new_table AS
SELECT DISTINCT *
FROM table;Ten slotte exporteer de gereinigde gegevens terug naar S3 door naar de S3-bucket en de map te navigeren om het bestand te uploaden.
Begrijpen van het Spark Framework
Het Spark-framework is een open-source, eenvoudig en expressief clustercomputingsysteem dat is ontworpen voor snelle ontwikkeling. Het is gebaseerd op de Java-programmeertaal en dient als alternatief voor andere Java-frameworks. Het belangrijkste kenmerk van Spark is zijn mogelijkheden voor geheugenresidente gegevensverwerking die de verwerking van grote datasets versnellen.
Configureren van Spark om te werken met S3
Om Spark te configureren om te werken met S3, begin door de Hadoop AWS-afhankelijkheid toe te voegen aan uw Spark-toepassing. Doe dit door de volgende regel toe te voegen aan uw build-bestand (bijvoorbeeld build.sbt voor Scala of pom.xml voor Java):
libraryDependencies += "org.apache.hadoop" % "hadoop-aws" % "3.3.1"Voer de AWS toegangssleutel-ID en geheime toegangssleutel in uw Spark-toepassing in door de volgende configuratie-eigenschappen in te stellen:
spark.hadoop.fs.s3a.access.key <ACCESS_KEY_ID>
spark.hadoop.fs.s3a.secret.key <SECRET_ACCESS_KEY>Stel de volgende eigenschappen in met behulp van het SparkConf object in uw code:
val conf = new SparkConf()
.set("spark.hadoop.fs.s3a.access.key", "<ACCESS_KEY_ID>")
.set("spark.hadoop.fs.s3a.secret.key", "<SECRET_ACCESS_KEY>")Stel de S3-eindpunt-URL in uw Spark-toepassing in door de volgende configuratie-eigenschap in te stellen:
spark.hadoop.fs.s3a.endpoint s3.<REGION>.amazonaws.comVervang <REGION> door de AWS-regio waar uw S3-bucket zich bevindt (bijv. us-east-1).
Een DNS-compatibele bucketnaam is vereist om de S3-client in Hadoop toegang te geven voor de S3-verzoeken. Als uw bucketnaam punten of underscores bevat, moet u mogelijk path style access inschakelen voor de S3-client in Hadoop, die een virtueel host style gebruikt. Stel de volgende configuratie-eigenschap in om padtoegang te activeren:
spark.hadoop.fs.s3a.path.style.access trueTen slotte, maak een Spark-sessie met de S3-configuratie door het spark.hadoop prefix in de Spark-configuratie in te stellen:
val spark = SparkSession.builder()
.appName("MyApp")
.config("spark.hadoop.fs.s3a.access.key", "<ACCESS_KEY_ID>")
.config("spark.hadoop.fs.s3a.secret.key", "<SECRET_ACCESS_KEY>")
.config("spark.hadoop.fs.s3a.endpoint", "s3.<REGION>.amazonaws.com")
.getOrCreate()Vervang de velden van <ACCESS_KEY_ID>, <SECRET_ACCESS_KEY>, en <REGION> met uw AWS-referenties en S3-regio.
Om gegevens uit S3 in Spark te lezen, wordt de spark.read methode gebruikt, en geef vervolgens het S3-pad naar uw gegevens op als invoersource.
Een voorbeeldcode die laat zien hoe u een CSV-bestand uit S3 in een DataFrame in Spark kunt lezen:
val spark = SparkSession.builder()
.appName("ReadDataFromS3")
.getOrCreate()
val df = spark.read
.option("header", "true") // Specify whether the first line is the header or not
.option("inferSchema", "true") // Infer the schema automatically
.csv("s3a://<BUCKET_NAME>/<FILE_PATH>")In dit voorbeeld vervangt u <BUCKET_NAME> door de naam van uw S3-bucket en <FILE_PATH> door het pad naar uw CSV-bestand binnen de bucket.
Transformeren van gegevens met Spark
Data transformatie met Spark verwijst meestal naar bewerkingen op gegevens om ze te reinigen, filteren, aggregeren en samen te voegen. Spark biedt een uitgebreid scala aan API’s voor gegevenstransformatie. Ze omvatten DataFrame, Dataset en RDD API’s. Sommige van de meest voorkomende gegevenstransformatiebewerkingen in Spark zijn filteren, kolommen selecteren, gegevens aggregeren, gegevens samenvoegen en gegevens sorteren.
Hier is een voorbeeld van gegevenstransformatiebewerkingen:
Gegevens sorteren: Deze bewerking houdt in dat gegevens worden gesorteerd op basis van één of meerdere kolommen. De orderBy of sort methode op een DataFrame of Dataset wordt gebruikt om gegevens te sorteren op basis van één of meerdere kolommen. Bijvoorbeeld:
val sortedData = df.orderBy(col("age").desc)U moet mogelijk het resultaat terugschrijven naar S3 om de resultaten op te slaan.
Spark biedt verschillende API’s om gegevens naar S3 te schrijven, zoals DataFrameWriter, DatasetWriter en RDD.saveAsTextFile.
Hieronder vindt u een codevoorbeeld dat laat zien hoe u een DataFrame naar S3 in Parquet-indeling kunt schrijven:
val outputS3Path = "s3a://<BUCKET_NAME>/<OUTPUT_DIRECTORY>"
df.write
.mode(SaveMode.Overwrite)
.option("compression", "snappy")
.parquet(outputS3Path)Vervang het invoerveld van de <BUCKET_NAME> door de naam van uw S3-bucket en <OUTPUT_DIRECTORY> door het pad naar de uitvoermap in de bucket.
De mode methode specificeert het schrijfgedrag, dat kan Overwrite, Append, Ignore of ErrorIfExists zijn. De option methode kan worden gebruikt om verschillende opties voor de uitvoerindeling te specificeren, zoals compressiecodec.
U kunt gegevens ook in andere indelingen naar S3 schrijven, zoals CSV, JSON en Avro, door de uitvoerindeling te wijzigen en de juiste opties op te geven.
Begrijpen van Data Partitioning in Spark
In eenvoudige termen verwijst data partitioning in Spark naar het splitsen van de dataset in kleinere, meer hanteerbare delen over het cluster. Het doel hiervan is om de prestaties te optimaliseren, de schaalbaarheid te verminderen en uiteindelijk de databasebeheerbaarheid te verbeteren. In Spark wordt de gegevens verwerkt in parallel op meerdere clusters. Dit is mogelijk gemaakt door Resilient Distributed Datasets (RDD), die een verzameling zijn van enorme, complexe gegevens. Standaard wordt de RDD over verschillende knooppunten verdeeld vanwege hun omvang.
Om optimaal te presteren, zijn er manieren om Spark te configureren om ervoor te zorgen dat taken snel worden uitgevoerd en de middelen effectief worden beheerd. Enkele van deze omvatten caching, geheugenbeheer, gegevensserialisatie en het gebruik van mapPartitions() boven map().
Spark UI is een web-based grafische gebruikersinterface die uitgebreid informatie biedt over de prestaties en middelenverbruik van een Spark-toepassing. Het omvat verschillende pagina’s, zoals Overzicht, Executors, Stadia en Taken, die informatie bieden over verschillende aspecten van een Spark-taak. Spark UI is een essentieel hulpmiddel voor het controleren en debuggen van Spark-toepassingen, aangezien het helpt bij het identificeren van prestatieknelpunten en middelenbeperkingen en het oplossen van fouten. Door de metrische gegevens te onderzoeken, zoals het aantal voltooide taken, de duur van de taak, CPU- en geheugenverbruik, en het schrijven en lezen van shuffle-gegevens, kunnen gebruikers hun Spark-taken optimaliseren en ervoor zorgen dat ze efficiënt worden uitgevoerd.
Conclusie
Samenvatting, het verwerken van uw gegevens op AWS S3 met behulp van Apache Spark is een effectieve en schaalbare manier om enorme datasets te analyseren. Door gebruik te maken van de cloudgebaseerde opslag- en computing-resources van AWS S3 en Apache Spark, kunnen gebruikers hun gegevens snel en effectief verwerken zonder zich zorgen te hoeven maken over architectuurbeheer.
In deze tutorial hebben we het opzetten van een S3-bucket en een Apache Spark-cluster op AWS EMR behandeld, het configureren van Spark om te werken met AWS S3, en het schrijven en uitvoeren van Spark-toepassingen om gegevens te verwerken. We hebben ook gegevenspartitie in Spark, Spark UI en het optimaliseren van de prestaties in Spark behandeld.
Referentie
Voor meer diepgang in het configureren van spark voor optimale prestaties, kijk hier.
https://docs.aws.amazon.com/emr/latest/ManagementGuide/emr-connect-master-node-ssh.html
Source:
https://dzone.com/articles/stateful-stream-processing-with-memphis-and-apache-spark