













Het Retrieval Augmented Generation (RAG) is een transformatieve vooruitgang voor grote taalmodellen (LLMs). Het combineert de generatieve kracht van transformer-architecturen met dynamische informatieretrieval.
Deze integratie maakt het voor LLMs mogelijk om relevante externe kennis te raadplegen en toe te voegen tijdens de tekstgeneratie, resulterend in uitvoer die nauwkeuriger, contextueel en feitelijk consistent is.
De evolutie van vroege regelgebaseerde systemen tot geavanceerde neurale modellen zoals BERT en GPT-3 heeft de weg gereed voor RAG, die de beperkingen van statische parametrische geheugen aanpakt. Ook de opkomst van Multimodaal RAG breidt deze mogelijkheden uit door diverse data typen zoals afbeeldingen, geluid en video toe te voegen. Dit verhoogt de rijkswaard en relevantie van de gegenereerde inhoud.
Deze Paradigmaverschuiving verbeterd niet alleen de nauwkeurigheid en interpretabiliteit van de uitvoer van LLMs, maar biedt ook ondersteuning voor innovatieve toepassingen in diverse domeinen.
We zullen hieronder de volgende onderwerpen behandelen:
- Hoofdstuk 1. Introductie tot RAG
– 1.1 Wat is RAG? Een overzicht
– 1.2 Hoe RAG complexe problemen oplost - Hoofdstuk 2. Technische Grondslagen
– 2.1 Overgang van neurale LM’s naar RAG
– 2.2 Begrip van het geheugen van RAG: Parametrisch vs. Niet-parametrisch
– 2.3 Multi-modale RAG: Integratie van meerdere gegevenstypen - Hoofdstuk 3. Kernmechanismen
– 3.1 De kracht van het combineren van informatie ophalen en genereren in RAG
– 3.2 Integratiestrategieën voor ophalers en generatoren - Hoofdstuk 4. Toepassingen en Gebruiksscenario’s
– 4.1 RAG in de praktijk: van vraag-antwoord tot creatief schrijven
– 4.2 RAG voor talen met beperkte bronnen: Bereik en mogelijkheden uitbreiden - Hoofdstuk 5. Optimalisatietechnieken
– 5.1 Geavanceerde retrievaltechnieken voor het optimaliseren van RAG-systemen - Hoofdstuk 6. Herzien en Innovaties
– 6.1 Huidige uitdagingen en toekomstige richtingen voor RAG
– 6.2硬件加速及RAG系统的有效部署 - Hoofdstuk 7. Conclusies
– 7.1 De toekomst van RAG: Conclusies en reflecties
Vereisten voor vooropleiding
Voor het behandelen van inhoud die gericht is op grote taalmodellen (LLMs) zoals Retrieval-Augmented Generation (RAG), zijn twee essentiële vooropleidingen nodig:
- Fundamentele machine learning: Het begrijpen van basisconcepten en algoritmen van machine learning is crucial, vooral als ze betrekking hebben tot neurale netwerkarchitecturen.
- Natuurlijk Taalverwerking (NLP): Kennis over technieken van NLP, inclusief tekst voorbehandeling, tokenisatie en het gebruik van embeddings, is crucial voor werken met taalmodellen.
Hoofdstuk 1: Inleiding tot RAG
Retrieval-Augmented Generation (RAG) revolutioneert natuurlijke taalverwerking door combineren van informatieretrieval en generatieve modellen. RAG dynamisch toegang tot externe kennis te krijgen, die de nauwkeurigheid en relevantie van gegenereerde tekst verbetert.
Dit hoofdstuk ontdekt de mechanismen, voordelen en uitdagingen van RAG. We delen in op het gebied van retrievaltechnieken, integratie met generatieve modellen en de impact op verschillende toepassingen.
RAG helpt hallucinaties te verminderen, integreert actuele informatie en gaat over complexe problemen. We bespreken ook uitdagingen zoals efficiënte retrieval en morele overwegingen. Dit hoofdstuk verschaft een diepgaande verstand van de transformatieve potentiële van RAG in natuurlijke taalverwerking.
1.1 Wat is RAG? Een Overzicht
Retrieval-Augmented Generation (RAG) vertegenwoordigt eenparadigmaverschuiving in natuurlijke taalverwerking, door de sterktes van informatieretrieval en generatieve taalmodellen ononderbroken te combineren. RAG-systemen gebruiken externe kennisbronnen om de nauwkeurigheid, relevantie en coherentie van gegenereerde tekst te verbeteren, hetgeen de beperkingen van een alleenmaalsParameters geheugen in traditionele taalmodellen aanpakt. (Lewis et al., 2020)
door dynamisch relevante informatie op te halen en die tijdens het genereerproces in te voegen, maakt RAG meer contextueel gegrond en feitelijk consistente uitvoer mogelijk over een breed scala aan toepassingen, van antwoord geven op vragen en dialo格斯ystemen tot samenvatting en creatief schrijven. (Petroni et al., 2021)
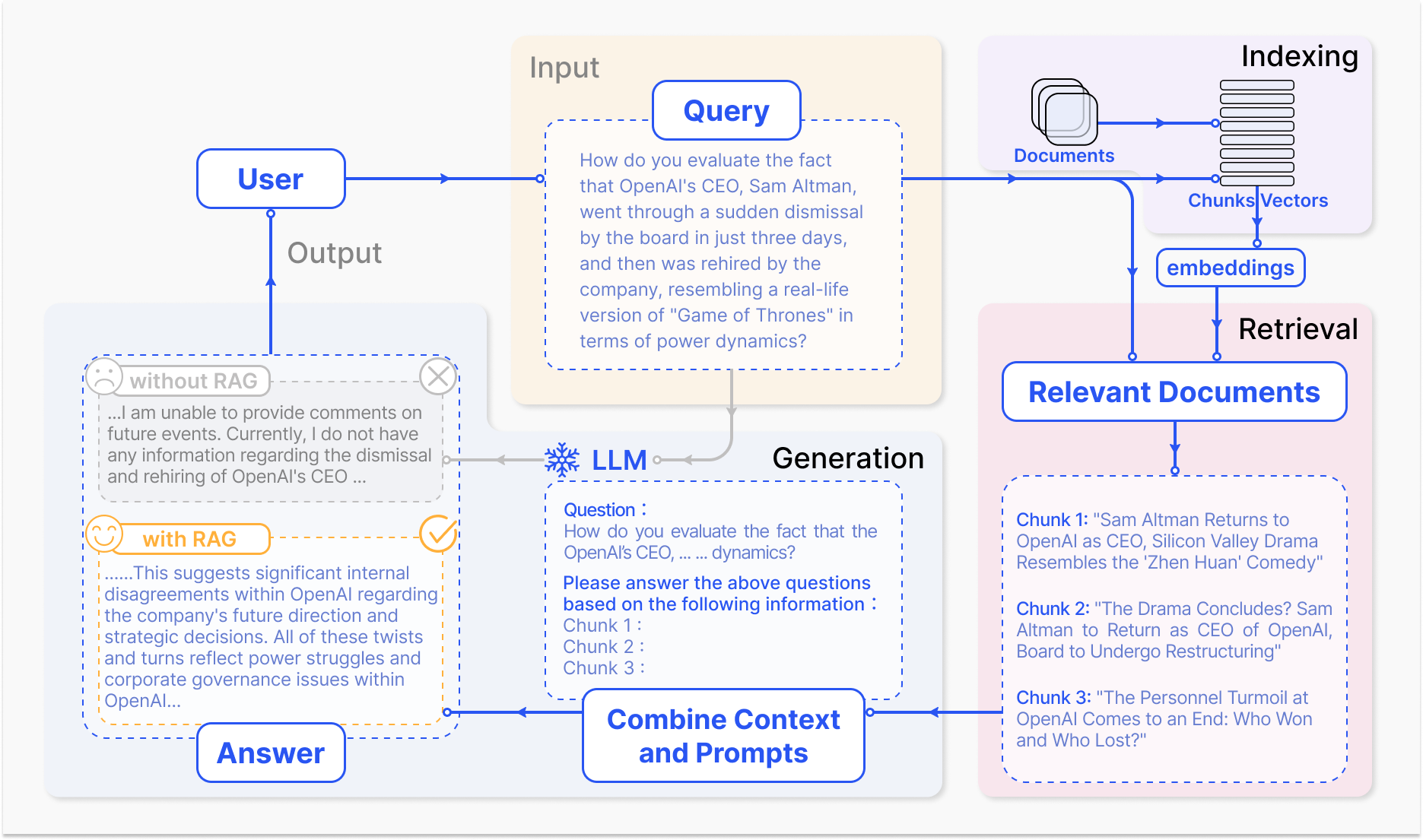
Hoe een RAG-systeem werkt – arxiv.org
Het kernmechanisme van RAG omvat twee primaire componenten: het zoeken en het genereren.
Het zoekcomponent zoekt efficiënt door grote kennisbasissen om de meest relevante informatie te identificeren op basis van de invoerquery of context. Technieken zoals spars zoeken, dat gebruik maakt van gecontroleerde indexen en termen gebaseerd op overeenkomst, en dichte zoeken, dat gebruik maakt van dichte vectorrepresentaties en semantische overeenkomst, worden toegepast om het zoekproces te optimaliseren. (Karpukhin et al., 2020)
De gevonden informatie wordt vervolgens ingevoegd in het generatieve model, meestal een grote taalmodel zoals GPT of T5, die de relevante inhoud in een coherente en vloeiende reactie samenstelt. (Izacard & Grave, 2021)
De integratie van het halen en genereren in RAG biedt verschillende voordelen ten opzichte van traditionele taalmodellen. door de gegenereerde tekst te gronden in externe kennis, reduceert RAG significant de frequentie van hallucinaties of feitelijk onjuiste uitvoeringsresultaten. (Shuster et al., 2021)
RAG laat ook toe om actuele informatie op te nemen, waardoor de gegenereerde reacties de meest recente kennis en ontwikkelingen in een bepaald domein reflecteren. (Lewis et al., 2020) Deze aanpasbaarheid is vooral crucial in velden zoals de gezondheidszorg, financiën en wetenschappelijk onderzoek, waar de nauwkeurigheid en tijdstipe van informatie van hoogste belang zijn. (Petroni et al., 2021)
Maar de ontwikkeling en implementatie van RAG-systemen bieden ook significante uitdagingen. Efficiente opname uit grote schaal kennisbases, vermindering van hallucinaties en integratie van verschillende datamodaliteiten zijn onder de technische hindernissen die moeten worden behandeld. (Izacard & Grave, 2021)
Ook ethieke overwegingen, zoals het verzekeren van onpartijdig en eerlijk informatie-ophalen en -generatie, zijn cruciale factoren voor de verantwoorde invoering van RAG-systemen. (Bender et al., 2021) Het ontwikkelen van uitgebreide evaluatiewijzen en methodieken die de interactie tussen ophaalaccuratie en generatieve kwaliteit vastleggen, is essentieel voor de assessering van de effectiviteit van RAG-systemen. (Lewis et al., 2020)
Met de evolutie van het vakgebied van RAG worden toekomstige onderzoeksrichtingen gericht op het optimaliseren van ophaalprocessen, het uitbreiden van multimodale mogelijkheden, het ontwikkelen van modulaire architecturen en het opstellen van robuste evaluatiewijzen. (Izacard & Grave, 2021) Deze voortgang zal de effectiviteit, accuraatheid en aanpasbaarheid van RAG-systemen verhogen, waardoor de weg vrij wordt gemaakt voor meer intelligenten en verschillende toepassingen in natuurlijke taalverwerking.
Hier volgt een eenvoudig Python-codevoorbeeld dat een Retrieval Augmented Generation (RAG) opstelling laat zien gebruik makende van de populaire bibliotheken LangChain en FAISS:
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.document_loaders import TextLoader
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
# 1. Bestanden laden en integreren
loader = TextLoader('your_documents.txt') # Vervang door uw bron voor documenten
documents = loader.load()
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(documents, embeddings)
# 2. Relevante documenten ophalen
def retrieve_docs(query):
return vectorstore.similarity_search(query)
# 3. RAG-keten opstellen
llm = OpenAI(temperature=0.1) # Temperatuur aanpassen voor creatieve responsen
chain = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=vectorstore.as_retriever())
# 4. RAG-model gebruiken
def get_answer(query):
return chain.run(query)
# Voorbeeld van gebruik
query = "What are the key features of Company X's latest product?"
answer = get_answer(query)
print(answer)
#Voorbeeld van bedrijfshistorie
query = "When was Company X founded and who were the founders?"
answer = get_answer(query)
print(answer)
#Voorbeeld van financiële prestaties
query = "What were Company X's revenue and profit figures for the last quarter?"
answer = get_answer(query)
print(answer)
#Voorbeeld van toekomstige展望
query = "What are Company X's plans for expansion or new product development?"
answer = get_answer(query)
print(answer)
door de kracht van opname en generatie te combineren, biedt RAG immense beloftes voor het veranderen van hoe we interacteren met en genereren van informatie, revolutionerend verschillende domeinen en de toekomst van de mens-machineinteractie vormgevend.
1.2 Hoe RAG complexe problemen oplost
Opname-geïntegreerde Generatie (RAG) biedt een krachtige oplossing voor complexe problemen die traditionele grote taalmodellen (LLMs) lastig vinden, vooral in scenario’s die grote hoeveelheden ongestructureerd data omvatten.
Een dergelijk probleem is de mogelijkheid om lezers vanzelfsprekend over specifieke documenten of multimedia-inhoud, zoals YouTube-video’s, een betekenisvolle conversatie te voeren zonder eerst aan deze bronnen op maat te trainen of duidelijke training op de doelstellingen.
Traditionele LLM’s, ondanks hun indrukwekkende generatieve kenmerken, zijn beperkt door hun parametrische geheugen, dat vastligt bij het moment van trainen. (Lewis et al., 2020) Dit betekent dat ze niet direct nieuwe informatie kunnen raadplegen of integreren buiten hun trainingsgegevens, waardoor het moeilijk wordt om geïnformeerde discussies te voeren over ongeziene documenten of video’s.
Hiermee kan een LLM antwoorden genereren die onconsistent, irrelevant of feitelijk onjuist zijn als ze opvraagt over specifieke inhoud. (Petroni et al., 2021)
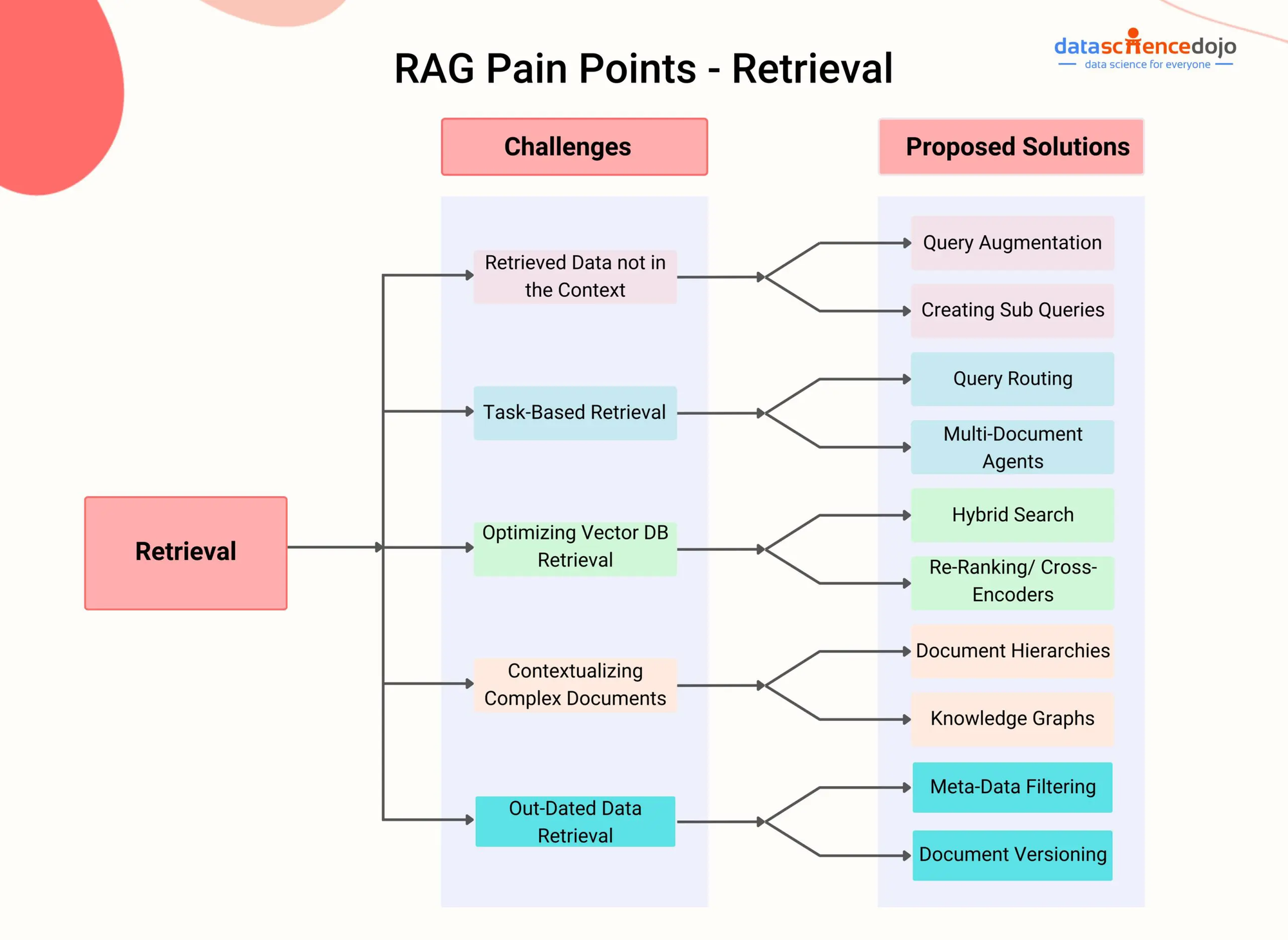
RAG Pijnpunten – DataScienceDojo
RAG bestedt aandacht aan deze beperking door een opnamecomponent te integreren die het model in staat stelt dynamisch relevante informatie van externe kennisbronnen te raadplegen en toe te voegen tijdens het generatiesproces.
door middel van geavanceerde opname technieken, zoals dichte passage opname (Karpukhin et al., 2020) of gemengde zoekopdracht (Izacard & Grave, 2021), kunnen RAG-systemen effectief de meest relevante passages of segmenten identificeren uit een gegeven document of video op basis van de conversatiecontext.
Bijvoorbeeld, denk aan een scenario waarin een gebruiker een conversatie wil aangaan over een specifiek YouTube-video op een wetenschappelijk thema. Een RAG-systeem kan eerst de audiocontent van het video afspelen en de resulterende tekst dan opslaan met dichte vectorrepresentaties.
Dan, als de gebruiker een vraag stelt die verband houdt met het video, kan de opslagcomponent van het RAG-systeem snel de meest relevante passages uit de transcriptie identificeren op basis van de semantische gelijkenis tussen de vraag en de geindexeerde inhoud.
De teruggevonden passages worden vervolgens ingevoerd in de generatieve model, die een helder en informatief antwoord syntheseert dat rechtstreeks antwoord op de vraag van de gebruiker geeft en de antwoord plaatst in het context van de video. (Shuster et al., 2021)
Deze aanpak maakt het mogelijk voor RAG-systemen om kennisbare conversaties te voeren over een breed scala aan documenten en multimediainhoud zonder expliciet fine-tuning nodig te hebben. Door dynamisch te zoeken en de relevante informatie op te nemen, kan RAG antwoorden genereren die nauwkeuriger, contextueel relevant en feitelijk consistent zijn vergeleken met traditionele LLMs. (Lewis et al., 2020)
Ook de mogelijkheid van RAG om ongestructureerde data uit verschillende modaliteiten, zoals tekst, afbeeldingen en audio, te behandelen, maakt het een veelzijdig oplossingsmodel voor complexe problemen die heterogene informatiebronnen in het spel hebben. (Izacard & Grave, 2021) Met de voortdurende evolutie van RAG-systemen wordt hun potentie om complexe problemen in diverse domeinen op te lossen groter.
Door de moderne retrievaltechnieken en multimodale integratie te benutten, kunnen RAG meer intelligent en contextgerichte conversatieagentschappen, persoonlijke aanbevelingssystemen en kennisintensive toepassingen mogelijk maken.
Met de voortgang van onderzoek in gebieden als efficiënt indexeren, crossmodaal aligneren en integratie van retrieval en generatie, zal RAG zonder twijfel een cruciale rol spelen in het doorbreken van de grenzen van wat mogelijk is met taalkundige modellen en kunstmatige intelligentie.
Hoofdstuk 2: Technische Grondslagen
In dit hoofdstuk gaat het in op de vermeldenswaardige wereld van de Multimodale Retrieval-Augmented Generatie (RAG), een nieuwe en vooruitstrevende benadering die de beperkingen van traditionele taalkundige modellen overstijgt.
Door de ongehinderde integratie van diverse datamodaliteiten zoals afbeeldingen, audio en video met Grote Taalkundige Modellen (LLMs), wordt de Multimodale RAG de AI-systemen machtig om over een rijker informatiegebied te redeneren.
We zullen de mechanismen achter deze integratie, zoals contrasterend leren en crossmodaal aandacht, onderzoeken en zien hoe LLMs in staat zijn meer gedetailleerde en contextueel relevante reacties te genereren.
Terwijl Multimodale RAG promissievolle voordelen biedt zoals verbeterde nauwkeurigheid en de mogelijkheid om nieuwe toepassingen zoals visuele vragenbeantwoording te ondersteunen, presenteert ze ook unieke uitdagingen. Dit omvat de behoefte aan grote schaal multimodale datasets, verhoogde computatorische complexiteit en de mogelijke voorkeur in geretourneerde informatie.
Als we op dit avontuur aanbreken, zal niet alleen het transformatieve potentiële van Multimodale RAG blootstellen, maar ook de obstakels die voor ons liggen kritisch onderzoeken, waardoor we een diepere verstand krijgen van dit snel evoluerende veld.
2.1 Neurale LM’s naar RAG
De evolutie van taalklassetjes is gemarkeerd door een geleidelijke voortgang van vroege regelgebaseerde systemen tot steeds meer geavanceerde statistische en neurale netwerkgebaseerde modellen.
In de vroege dagen vertrouwden taalklassetjes op handgemaakte regels en taalkundige kennis om tekst te genereren, wat resulteerde in een rigide en beperkte output. Het ontstaan van statistische modellen, zoals n-grammodellen, introduceerde een datadriven aanpak die patronen leerde uit grote corpora, wat meer natuurlijke en coherente taalgeneratie mogelijk maakte. (Redis)
Hoe RAG werkt – promptingguide.ai
Het was echter de opkomst van neurale netwerkmodellen, vooral transformer architecturen zoals BERT en GPT-3, die de veld van natuurlijke taalverwerking (NLP) revolutionair maakte.
Deze modellen, bekend als grote taalmodellen (LLMs), gebruiken de kracht van diep leren om complexe taalpatronen vast te leggen en mens-achtige tekst met ongeziene vloeiendheid en coherente uit te voeren. (Yarnit) De toenemende complexiteit en schaal van LLMs, met modellen zoals GPT-3 die meer dan 175 miljard parameternen claimt, heeft geleid tot opmerkelijke capaciteiten in taken als taalvertaling, vraagbehandeling en inhoud creëren.
On DESPITE hun indrukwekkende prestaties lijden traditionele LLMs aan beperkingen door hun afhankelijkheid van een alleenmaatschappijelijke geheugen. (StackOverflow) Het kennisgedeelte van deze modellen is statisch, beperkt door de trainingstopdatum van hun gegevens.
Als gevolg hiervan kan LLMs uitdrukkingen genereren die factueel onjuist zijn of niet consistent zijn met de meest recente informatie. Ook wordt hun mogelijkheid om accurate en contextueel relevante antwoorden op kennisintensive vragen te geven belemmerd door het ontbreken van een expliciete toegang tot externe kennisbronnen.
Het Retrieval Augmented Generation (RAG) model verschijnt als een doorbraak in de oplossing voor deze beperkingen. door de integratie van de informatieretrievalcapaciteiten van LLMs met de generatieve kracht, biedt RAG modellen de mogelijkheid om dynamisch relevant kennis van externe bronnen toe te voegen en te incorporeren tijdens het genereren proces.
Deze fusie tussen parametrische en niet-parametrische geheugenresourceën maakt het voor RAG-geequipeerde LLM’s mogelijk om niet alleen vloeiend en coherente uitvoer te produceren, maar ook feitelijk correcte en contextueel geïnformeerde resultaten.
RAG representeert een belangrijke vooruitgang in taalsynthese, door de sterke punten van LLM’s te combineren met de uitgebreide kennis die beschikbaar is in externe bronnen. Door de beste van beide werelden te benutten, geeft RAG modellen de macht om tekst te genereren die betrouwbaarder, informatief en overeenkomt met wereldwijde kennis.
Deze paradigm shift opent nieuwe mogelijkheden voor NLP-toepassingen, van vragenbeantwoorden en inhoud creëren tot kennisintensive taken in domeinen zoals gezondheidszorg, financiën en wetenschappelijk onderzoek.
2.2 Parametrische versus niet-parametrische geheugen
Parametrische geheugen verwijst naar de kennis die opgeslagen is binnen de parameters van voorge trainde taalmodellen, zoals BERT en GPT-4. Deze modellen leren taalpatronen en relaties te capturën uit grote hoeveelheden tekstgegevens tijdens het trainingsproces, en encode deze kennis in hun miljoenen of miljarden parameters.
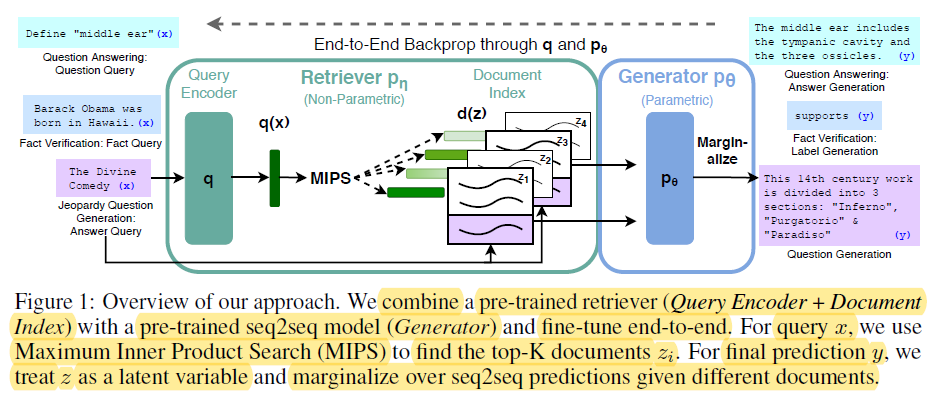
End-t-End Backprop through q and p0 – miro.medium.com
De sterke punten van parametrische geheugen zijn:
- Vloeiendheid: Voorge trainde taalmodellen genereren menselijk-achtige tekst met opvallende vloeiendheid en coherente structuur, waarbij de subtiele details en stijl van natuurlijke taal worden gevangen. (Redis en Lewis et al.)
- Generalisatie: Het kennisgedeelte in de modellenParameters staat het toe om te generaliseren tot nieuwe taken en domeinen, wat overdracht van kennis en capabilities voor drievoudige shot learning mogelijk maakt. (Redis en Lewis et al.)
Hoegenaamd heeft parametrische geheugen ook significante beperkingen:
- Feitelijke fouten: Taalmodellen kunnen uitvoer genereren die niet consistent zijn met feiten uit de echte wereld, aangezien hun kennis beperkt is tot de gegevens waarop ze zijn getraind.
- Verouderde kennis: Het kennisgedeelte in de modellenparameters wordt verouderd over tijd, aangezien het vastligt op het moment van training en niet de updates of veranderingen in de echte wereld weerspiegelt.
- Hoge computatieleverancier: Het trainen van grote taalmodellen vereist uiterst grote hoeveelheden aan computatieleveranciers en energie, waardoor het kostbaar en tijdrovend is om hun kennis bij te werken.
- Algemeen kennis: De kennis die wordt vastgelegd door taalmodellen is breed en algemeen, en mist de diepte en specifiekheid die vereist zijn voor veel domeinspecifieke toepassingen.
In contrast daarmee, noemt men non-parametrische geheugen het gebruik van uitdrukkelijke kennisbronnen, zoals databases, documenten en kennisgrafieken, om taalmodellen actuele en nauwkeurige informatie te verschaffen. Deze externe bronnen dienen als een aanvullend type geheugen, wat modellen toestaat toegang te krijgen en relevante informatie te ontgrendelen tijdens het generatieproces.
De voordelen van non-parametrische geheugen omvatten:
- Actuele informatie: Externe kennisbronnen kunnen gemakkelijk worden bijgewerkt en onderhouden, ervoor zorgend dat de model toegang heeft tot de nieuwste en meest nauwkeurige informatie.
- Gereduceerde hallucinaties: “Door relevante informatie van externe bronnen terug te halen, reduceert RAG significant de incidentie van hallucinaties of feitelijk incorrecte generatieve uitvoer.” (Lewis et al. en Guu et al.)
- Specifieke domeinkennis: Niet-parametrische geheugen biedt modellen de mogelijkheid om specifieke kennis uit domeinspecifieke bronnen te benutten, wat betekent dat ze voor specifieke toepassingen meer nauwkeurige en contextueel relevante uitvoer kunnen leveren. (Lewis en anderen. en Guu en anderen.)
De beperkingen van parametrische geheugen duiden op de noodzaak van een Paradigmaverschuiving in het genereren van taal.
RAG vertegenwoordigt een significante vooruitgang in de natuurlijke taalverwerking door de prestaties van generatieve modellen te verbeteren door integratie van informatieretrievaltechnieken. (Redis)
Hieronder volgt de Python-code om de verschillen tussen parametrische en niet-parametrische geheugen uit te leggen in het kader van RAG, met een duidelijke uitvoer die deze onderscheidingen benadrukt:
from sentence_transformers import SentenceTransformer
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import FAISS
from langchain.chains import RetrievalQAWithSourcesChain
from langchain.llms import OpenAI
# Voorbeeld Document Collectie (ga voor meer omvangrijke documenten in een echte situatie)
documents = [
"The Large Hadron Collider (LHC) is the world's largest and most powerful particle accelerator.",
"The LHC is located at CERN, near Geneva, Switzerland.",
"The LHC is used to study the fundamental particles of matter.",
"In 2012, the LHC discovered the Higgs boson, a particle that gives mass to other particles.",
]
# 1. Niet-Parametrische Geheugen (Retrieval met Embeddings)
model_name = "sentence-transformers/all-mpnet-base-v2"
embeddings = HuggingFaceEmbeddings(model_name=model_name)
vectorstore = FAISS.from_documents(documents, embeddings)
# 2. Parametrische Geheugen (Taalmodel met Retrieval)
llm = OpenAI(temperature=0.1) # Pas de temperatuur aan voor creativiteit van het antwoord
chain = RetrievalQAWithSourcesChain.from_chain_type(llm=llm, chain_type="stuff", retriever=vectorstore.as_retriever())
# --- Queries and Responses ---
query = "What was discovered at the LHC in 2012?"
answer = chain.run(query)
print("Parametric (w/ Retrieval): ", answer["answer"])
query = "Where is the LHC located?"
docs = vectorstore.similarity_search(query)
print("Non-Parametric: ", docs[0].page_content)
Uitvoer:
Parametric (w/ Retrieval): The Higgs boson, a particle that gives mass to other particles, was discovered at the LHC in 2012.
Non-Parametric: The LHC is located at CERN, near Geneva, Switzerland.
En dit is wat er gebeurt in deze code:
Parametrische Geheugen:
- Gebruikt de brede kennis van de LLM om een alomvattende antwoord te genereren, inclusief de cruciale feit dat de Higgs boson massa geeft aan andere deeltjes. De LLM is “parameteriseerd” door zijn uitgebreide trainingsdata.
Niet-Parametrische Geheugen:
- Voert een verwantschapszoekexecutie uit in het vectorruimte, vindt het meest relevante document dat direct antwoord geeft op de vraag over de locatie van het LHC. Het produceert geen nieuwe informatie, het haalt alleen de relevante feiten op.
Belangrijkste Verschillen:
| Feature | Parametric Memory | Non-Parametric Memory |
|---|---|---|
| Kennisopslag | Gecodeerd in de parameters (gewichten) van het model als geleerde weergaven. | Gestoord direct als ruw tekst of andere formaten (bijv. embeddings). |
| Ophalen | Gebruikt de generatieve kapabilitaten van het model om tekst te produceren die relevant is voor de query, gebaseerd op zijn geleerde kennis. | Involveert het zoeken van documenten die de query dicht bij staan (bijv. door verwantschap of trefwoorden matching). |
| Verschoppelijkheid | Hoog verschoppelijk en kan nieuwe reacties genereren, maar kan ook hallucineren (foutieve informatie produceren). | Minder verschoppelijk, maar minder gevoelig voor hallucinaties omdat het bestaande data vertrouwt. |
| Antwoordstijl | Kan meer uitgebreide en geavanceerde reacties produceren, maar met meer irrelevante informatie. | Biedt directe en concisse antwoorden, maar kan context of uitleg ontbreken. |
| Rekenkosten | Het genereren van antwoorden kan computationeel intensief zijn, vooral voor grote modellen. | Het ophalen kan sneller zijn, vooral met efficiente indexering en zoekalgoritmen. |
door de sterktes van parametrisch en niet-parametrisch geheugen te combineren, adresseert RAG de beperkingen van traditionele taalmodellen en maakt het mogelijk om meer nauwkeurige, actuele en contextueel relevante uitvoer te genereren. (Redis, Lewis et al., en Guu et al.)
2.3 Multimodale RAG: integratie van tekst
Multimodale RAG uitbreidt het traditionele op basis van tekst RAG-paradigma door meerdere datamodaliteiten, zoals afbeeldingen, audio en video, toe te voegen om de opslag- en geneercapabilities van grote taalmodellen (LLMs) te verbeteren.
door de techniek van contrasteleer te benutten, leren multimodale RAG-systemen om heterogene datatypen in een gemeenschappelijk vectorruimte in te delen, wat een gemakkelijke cross-modaal opslag mogelijk maakt. Dit maakt het LLMs mogelijk om over een rijker context te redeneren, tekstuele informatie samen met visuele en audiografische aanwijzingen te combineren om meer gedetailleerde en contextueel relevante uitvoer te genereren. (Shen et al.)
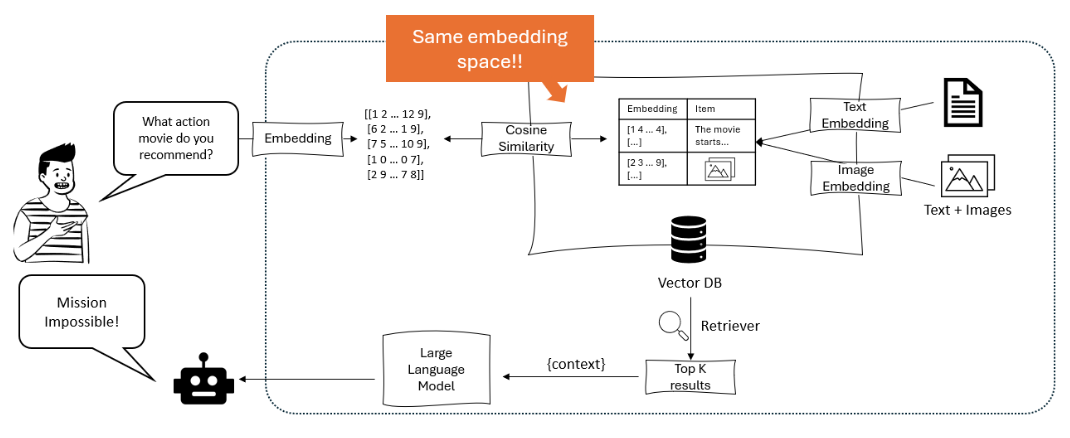
Het diagram toont een aanbevelingssysteem waarin een grote taalmodel een gebruikersvraag omzet in vectorrepresentaties, die vervolgens via cosinesimilariteit binnen een vectordatabase worden gematched die zowel tekst als beeldsvectorrepresentaties bevat, om relevante items op te halen en aan te bevelen. – opendatascience.com
Een belangrijke aanpak binnen multimodale RAG is de gebruik van transformer-gebaseerde modellen zoals ViLBERT en LXMERT die cross-modaal aandachtsmechanismen gebruiken. Deze modellen kunnen relevante gebieden in afbeeldingen of specifieke segmenten in audio/video bijhouden bij het genereren van tekst, waarmee fijne-graaf interacties tussen modaliteiten worden gevangen. Dit maakt meer visueel en contextueel gegrondte antwoorden mogelijk. (Protecto.ai)
De integratie van tekst met andere modaliteiten in RAG-pipelines brengt uitdagingen zoals het aligneren van semantische representaties over verschillende datatypen en het behandelen van de unieke eigenschappen van elke modaliteit tijdens het embeddingsproces. Technieken zoals modaliteitsspecifieke encodering en cross-aandacht worden gebruikt om deze uitdagingen aan te pakken. (Zhu et al.)
Maar de potentiële voordelen van multimodale RAG zijn significant, inclusief verbeteringen in nauwkeurigheid, bestuurbaarheid en interpretabiliteit van gegenereerde inhoud, evenals de mogelijkheid om nieuwe toepassingen zoals visuele vragenbehandeling en multimodale inhoudcreation te ondersteunen.
Bijvoorbeeld, Li en andere (2020) hebben een multimodale RAG-framework voor visuele vraagbehandeling voorgesteld dat relevante beelden en tekstuele informatie ophaalt om accurate antwoorden te genereren, en dat deze betere resultaten behaalt dan eerdere state-of-the-art-methodes op benchmarks als VQA v2.0 en CLEVR. (MyScale)
On DESPITE de vertrouwelijk resultaten, introduceert multimodale RAG ook nieuwe uitdagingen, zoals een verhoogde computatiele complexiteit, de behoefte aan grote multimodale datasets, en de mogelijkheid voor vooroordelen en ruis in de opgehaalde informatie.
Onderzoekers ontdekken actief technieken om deze problemen aan te pakken, zoals efficiente indexstructuren, data augmentatie strategieën en adversaire training methodes. (Sohoni et al.)
Hoofdstuk 3: Kernmechanismen van RAG
Dit hoofdstuk ontdekt de subtiele interactie tussen retrievers en generatieve modellen in Retrieval-Augmented Generation (RAG) systemen, die hun belangrijke rollen in indexering, opname en sintheses van informatie uitmaken om accurate en contextueel relevante reacties te produceren.
We delen in de subtiele verschillen tussen sparse en dichte retrievaltechnieken, en vergelijken hun sterktes en zwaktes in verschillende scenario’s. Bovendien onderzoeken we diverse strategieën voor het integreren van opgehaalde informatie in generatieve modellen, zoals concatenatie en cross-attention, en bespreken we hun impact op de algehele effectiviteit van RAG-systemen.
door het begrip van deze integratie strategieën, krijgt u waardevolle inzichten in hoe u RAG systemen kan optimaliseren voor specifieke taken en domeinen, waardoor de weg vrij wordt gemaakt voor een meer geïnformeerde en effectieve gebruik van dit krachtige paradigma.
3.1 De kracht van het combineren van Informatie Retrieval en Generatie in RAG
Retrieval-Augmented Generation (RAG) vertegenwoordigt een krachtig paradigma dat ongebroken informatieretrieval met generatieve taalmodellen integreert. RAG bestaat uit twee hoofdcomponenten, net als u kunt afleiden van zijn naam: Retrieval en Generatie.
De component voor retrival is verantwoordelijk voor het indexeren en doorzoeken van een uitgebreide kennisopslagplaats, terwijl de component voor generatie de gevonden informatie gebruikt om contextueel relevante en feitelijk correcte antwoorden te produceren. (Redis en Lewis et al.)
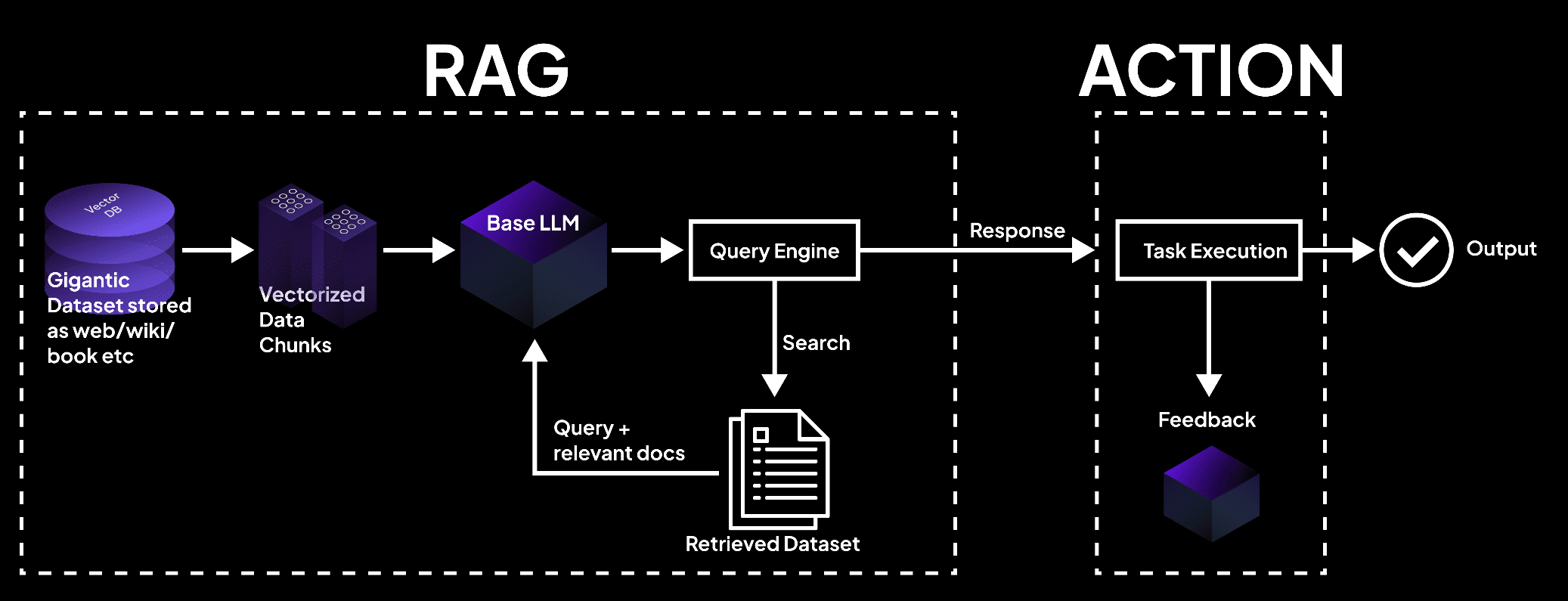
De afbeelding toont een RAG-systeem waarin een vector database gegevens verwerkt in kavels, door een taalmodel gequeryd om documenten op te halen voor takenuitvoering en nauwkeurige uitvoer. – superagi.com
Het opvragenproces begint met het indexeren van externe kennisbronnen, zoals databases, documenten en webpagina’s. (Redis en Lewis et al.) Opvragers en indexeurs spelen een cruciale rol in dit proces door de informatie efficiënt te organiseren en op te slaan in een format dat de snelle zoek- en opvraging faciliteert.
Wanneer een query wordt gesteld bij het RAG-systeem, zoekt de opvrager door de geindexeerde kennisbasis om de meest relevante stukken informatie te identificeren op basis van semantische gelijkheid en andere relevantiecijfers.
Zodra de relevante informatie is opgevraagd, neemt de component voor genereren de overhand. De opgehaalde inhoud wordt gebruikt om de generatieve taalmodel aan te sturen en te begeleiden, waarmee het de nodige context en feitelijke basis krijgt om accurate en informatieve antwoorden te genereren.
Het taalmodel gebruikt geavanceerde inferentietechnieken, zoals aandachtsmechanismen en transformer-architecturen, om de opgehaalde informatie met zijn bestaande kennis te samenstellen en coherent en vloeiend tekst te genereren.
De informatieflux binnen een RAG-systeem kan als volgt worden weergegeven:
graph LR
A[Query] --> B[Retriever]
B --> C[Indexed Knowledge Base]
C --> D[Relevant Information]
D --> E[Generator]
E --> F[Response]
De voordelen van RAG zijn vele malen:
Deze fusie van gegevens opname en generatiecapabilities maakt het mogelijk om antwoorden te creëren die niet alleen contextueel toepasbaar zijn, maar ook geïnformeerd zijn door de meest actuele en nauwkeurige informatie beschikbaar. (Guu et al.)
door deelname van externe kennisbronnen, RAG de frequentie van hallucinaties of feitelijk onjuiste uitvoer significant te verminderen, die de enige generatieve modellen vaak worden genoteerd.
Meerover laat RAG toe om de meest actuele informatie te integreren, ervoor zorgend dat de gegenereerde reacties de laatste kennis en ontwikkelingen in een gegeven domein weergeven. Dat is bijzonder belangrijk in gebieden zoals gezondheidszorg, financiën en wetenschappelijk onderzoek, waar de nauwkeurigheid en de tijdstip van de informatie van groot belang zijn. (Guu et al. en NVIDIA)
RAG toont ook ongeëvenaard aanpassingsvermogen, die de taalmodellen in staat stellen een breed scala aan taken uit te voeren met verbetering van de prestaties. Door dynamisch betreffende informatie op te halen op basis van de specifieke vraag of context, geeft RAG de modellen de macht om reacties te genereren die speciaal aangepast zijn aan de unieke eisen van elke taak, of het nu gaat om antwoord geven op vragen, inhoud genereren of domeinspecifieke toepassingen.
Vele studies hebben de effectiviteit van RAG getoond in het verbeteren van de feitelijke nauwkeurigheid, relevantie en aanpassingsvermogen van generatieve taalmodellen.
Bijvoorbeeld, Lewis en zijn collega’s (2020) toonden aan dat RAG de overheid behaalde op een reeks vraagbeantwortings taken, met de beste resultaten op benchmarks zoals Natural Questions en TriviaQA. (Lewis en zijn collega’s)
Ook Izacard en Grave (2021) demonstreerden de superioriteit van RAG ten opzichte van traditionele taalmodellen voor het genereren van coherent en feitelijk consistent langzame tekst.
Retrieval-Augmented Generation representeert een transformatieve aanpak voor taalgenerering, door de kracht van informatieretrieval te gebruiken om de nauwkeurigheid, relevantie en aanpasbaarheid van generatieve modellen te verbeteren.
Door externe kennis gemakkelijk te integreren met bestaande taalkundige vaardigheden, opent RAG nieuwe mogelijkheden voor natuurlijke taalverwerking en legt de weg voor intelligentere en betrouwbaardere taalgenereeringssystemen.
3.2 Strategieën voor Integratie van检索er-Generator
Retrieval-Augmented Generation (RAG) systemen zijn gebaseerd op twee kerncomponenten:检索ers en generatieve modellen.检索ers zijn verantwoordelijk voor de efficiënte zoek- en ophalingsacties van relevante informatie uit grote hoeveelheden kennisbases.
“Het omvat twee hoofdfases, indexering en zoeken. Indexering organiseert documenten om efficiente ophalingsacties te ondersteunen, gebruik makende van ofwel inverteerde indexen voor ruimtelijke ophalen of dichte vectorcodering voor dichte ophalen.” (Redis)
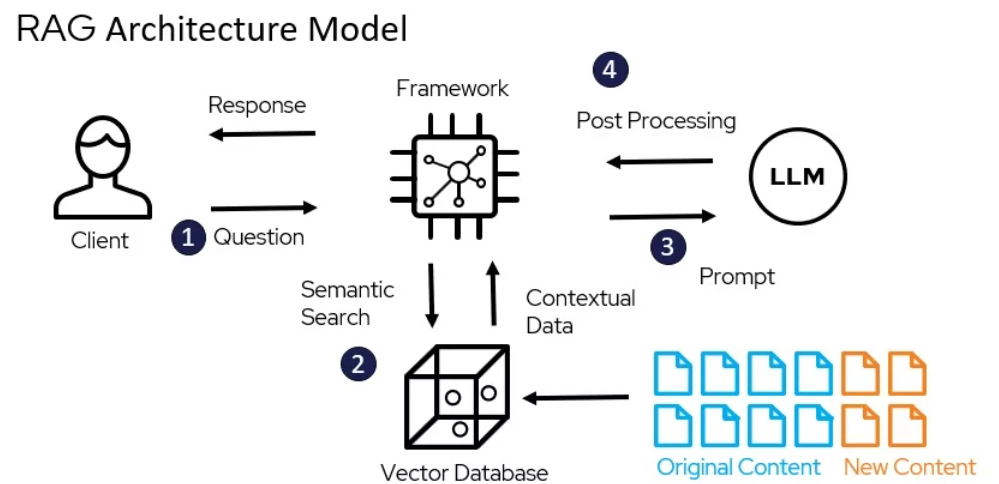
The Architecture Model of RAG – miro.medium.com
Sparse retrievaltechnieken, zoals TF-IDF en BM25, representeren documenten als hoogdimensionale ruwe vectoren, waar elke dimensie correspondeert met een unieke term in het vocabulaire. De relevantie van een document ten opzichte van een query wordt bepaald door de overlap van termen, gewogen door hun belang.
Bijvoorbeeld, met behulp van de populaire Elasticsearch-bibliotheek, kan een TF-IDF-gebaseerde terughaler worden geïmplementeerd als volgt:
from elasticsearch import Elasticsearch
es = Elasticsearch()
es.index(index="documents", doc_type="_doc", body={"text": "This is a sample document."})
query = "sample"
results = es.search(index="documents", body={"query": {"match": {"text": query}}})
Dense retrievaltechnieken, zoals dichte passageretrieval (DPR) en BERT-gebaseerde modellen, representeren documenten en queries als dichte vectoren in een continue embeddingruimte. De relevantie wordt bepaald door de cosinusovereenkomst tussen de query- en documentvectoren.
DPR kan worden geïmplementeerd met behulp van de Hugging Face Transformers-bibliotheek:
from transformers import DPRContextEncoder, DPRQuestionEncoder
context_encoder = DPRContextEncoder.from_pretrained("facebook/dpr-ctx_encoder-single-nq-base")
question_encoder = DPRQuestionEncoder.from_pretrained("facebook/dpr-question_encoder-single-nq-base")
context_embeddings = context_encoder(documents)
query_embedding = question_encoder(query)
scores = torch.matmul(query_embedding, context_embeddings.transpose(0, 1))
Generatieve modellen, zoals GPT en T5, worden in RAG gebruikt om coherente en contextueel relevante antwoorden te genereren op basis van de geretourneerde informatie. Door deze modellen op domeinspecifieke data te fine-tunen en prompt engineering technieken te gebruiken, kan hun prestatie in RAG-systemen significant worden verbeterd. (DEV Community)
Integratiestrategieën bepalen hoe de geretourneerde inhoud wordt ingebed in de generatieve modellen.
Het generatiecomponent gebruikt de opgehaalde content om coherent en contextueel relevante reacties te formuleren met de aanmoedigings- en inferentiefases. (Redis)
Twee algemene aanpakken zijn concatenatie en cross-attention.
Concatenatie omvat het aan elkaar plakken van de opgehaalde passages aan de invoerquery, waardoor de generatieve model de relevante informatie kan aanraken tijdens het decoderen.
Hoewel deze aanpak eenvoudig uit te voeren is, kan hij moeite doen met lange sequences en irrelevante informatie. (DEV Community) Cross-attentionmechanismen, zoals RAG-Token en RAG-Sequence, laten de generatieve model selectief de aandacht besteden aan de opgehaalde passages bij elke decode-stap.
Dit maakt een meer gekleurde controle mogelijk over de integratieproces, maar komt met een hogere computationele complexiteit.
Bijvoorbeeld, RAG-Token kan worden geïmplementeerd met behulp van de Hugging Face Transformers-bibliotheek:
from transformers import RagTokenizer, RagRetriever, RagSequenceForGeneration
tokenizer = RagTokenizer.from_pretrained("facebook/rag-token-nq")
retriever = RagRetriever.from_pretrained("facebook/rag-token-nq", index_name="exact", use_dummy_dataset=True)
model = RagSequenceForGeneration.from_pretrained("facebook/rag-token-nq")
input_ids = tokenizer(query, return_tensors="pt").input_ids
retrieved_docs = retriever(input_ids)
generated_output = model.generate(input_ids, retrieved_docs=retrieved_docs)
De keuze van de retriever, de generatieve model en de integratiestrategie hangt af van de specifieke vereisten van het RAG-systeem, zoals de grootte en de natuur van de kennisbase, het gewenste evenwicht tussen efficiency en effectiviteit en het doelgebied van toepassing.
Hoofdstuk 4: Toepassingen en gevallen.
Dit hoofdstuk verkent het transformatieve potentieel van Retrieval-Augmented Generation (RAG) bij het revolutioneren van toepassingen in talen met weinig bronnen en multilinguale toepassingen. We duiken diep in strategieën zoals het vertalen van brondocumenten naar talen met rijke bronnen, het gebruiken van multilinguale embeddings en het toepassen van federated learning om gegevensbeperkingen en linguïstische verschillen te overwinnen.
Daarnaast nemen we het kritieke probleem op van het verminderen van hallucinaties in multilinguale RAG-systemen om accurate en betrouwbare inhoudsgeneratie te verzekeren. Door deze innovatieve benaderingen te verkennen, biedt dit hoofdstuk een alomvattende gids voor het inzetten van de kracht van RAG voor inclusiviteit en diversiteit in taalverwerking.
4.1 RAG-toepassingen: van QA naar creatief schrijven
Retrieval-Augmented Generation (RAG) heeft talloze praktische toepassingen gevonden in verschillende domeinen, die laten zien hoe het potentieel heeft om onze interactie met en generatie van informatie te revolutioneren. Door gebruik te maken van de kracht van opzoeken en genereren, hebben RAG-systemen aanzienlijke verbeteringen laten zien in accuraatheid, relevantie en gebruikersbetrokkenheid.
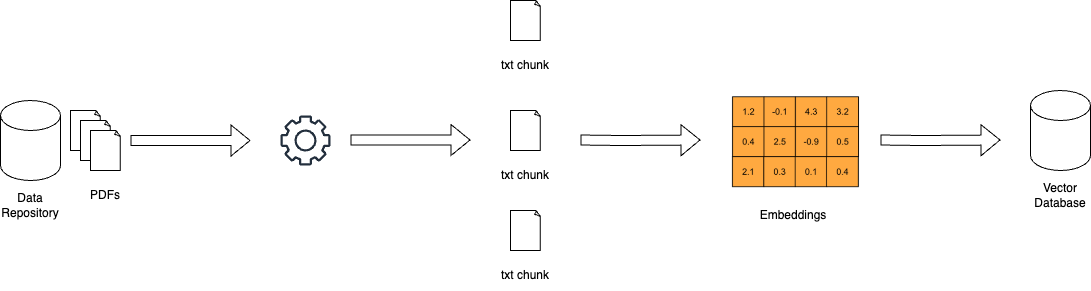
Hoe RAG werkt – miro.medium.com
Vragenbeantwoorden
RAG heeft aangetoond een game-changer te zijn op het gebied van vragenbeantwoording. Door relevante informatie uit externe kennisbronnen op te halen en deze te integreren in het genereerproces, kunnen RAG-systemen meer nauwkeurige en contextueel relevante reacties aan gebruikersvragen leveren. (LangChain en Django Stars)
Bijvoorbeeld, Izacard en Grave (2021) hebben een RAG-gebaseerde model voorgesteld genaamd Fusion-in-Decoder (FiD), die de beste prestaties behaalde op verschillende vragenbeantwoordingsoorten, inclusief Natural Questions en TriviaQA. (Izacard and Grave)
FiD maakt gebruik van een dichte retriever om relevante passages op te halen en een generatief model om de gevonden informatie in een doorlopend antwoord samen te voeren, waarmee het significant betere resultaten behaalt dan zuivere generatieve modellen. (Izacard and Grave)
Dialo格斯ysteem
RAG heeft ook toepassingen gevonden in het creëren van beter betrokken en informatieverrijken conversatieagenten. Door externe kennis op te halen via retrieval, kunnen op RAG gebaseerde dialogiesystemen responsen genereren die niet alleen contextueel toepasselijk zijn, maar ook feitelijk onderbouwd. (LlamaIndex en MyScale)
Shuster et al. (2021) introduceerden een op RAG gebaseerd dialogiesysteem genaamd BlenderBot 2.0, dat verbeterde conversatievaardigheden toonde vergeleken met zijn voorganger. (Shuster et al.)
BlenderBot 2.0 haalt relevante informatie op uit een diversiteit aan kennisbronnen, inclusief Wikipedia, nieuwsartikelen, en social media, waardoor het kan deelnemen aan meer geïnformeerde en samenhangende conversaties over een breed scala aan onderwerpen. (Shuster et al.)
Samenvatting
RAG heeft het potentieel getoond om de kwaliteit van gegenereerde samenvattingen te verbeteren door relevante informatie uit meerdere bronnen op te nemen. (Hyperight) Pasunuru et al. (2021) stelden een op RAG gebaseerd samenvattingsmodel voor genaamd PEGASUS-X, dat relevante passages ophaalt en integreert uit externe documenten om meer informatieve en samenhangende samenvattingen te genereren.
PEGASUS-X heeft pure generatieve modellen overtopt op verschillende samenvatting benchmarks, door de effectiviteit van het opslaan van informatie te demonstreren bij het verbeteren van de feitelijke nauwkeurigheid en relevantie van gegenereerde samenvattingen.
Creatief schrijven
Het potentiëlegebied van RAG strekt zich uit buiten feitelijke domeinen en naar het domein van creatief schrijven. Door relevante passages op te slaan uit een diverse corpora van literaire werken, kunnen RAG-systemen nieuwe en Engelsschattende verhalen of artikelen genereren.
Rashkin en zijn collega’s (2020) introduceerden een RAG-gebaseerd creatief schrijfmodel genaamd CTRL-RAG, dat relevante passages opslaat uit een grote schaal fictie-dataset en deze integreert in het generatiesproces. CTRL-RAG toonde de mogelijkheid om coherente en stijlvolle consistente verhalen te genereren, die het potentiële van RAG in creatieve toepassingen tonen.
Case studies
Verschillende wetenschappelijke artikelen en projecten hebben de effectiviteit van RAG in verschillende domeinen aangetoond.
Bijvoorbeeld, Lewis en zijn collega’s (2020) introduceerden het RAG-framewerk en toepassen ze het op het domein van open-domain vragenbeantwoorden, behaalden ze de meest recente prestaties op de Natural Questions benchmark. (Lewis et al.) Zij benadrukten de uitdagingen van efficiente opslag van informatie en de belangrijkheid van het fijnafstemmen van de generatieve model op opgeslagen passages.
In een andere case study hebben Petroni en collega’s (2021) RAG toegepast op de taak van feitencontrole, en laten zij zien dat RAG in staat is relevante bewijzen op te halen en nauwkeurige vonissen te genereren. Zij hebben de mogelijkheden van RAG getoond om misinformatie tegen te gaan en de betrouwbaarheid van informatiesystemen te verbeteren.
Het effect van RAG op de gebruikerservaring en de bedrijfmetrieken is significant. door meer nauwkeurige en informatieve reacties te leveren, hebben RAG-gebaseerde systemen de gebruikersvriendelijkheid en de betrokkenheid verbeterd. (LlamaIndex en MyScale)
Bij gesprekkige agenten heeft RAG meer natuurlijke en coherente interacties mogelijk gemaakt, wat heeft geleid tot verhoging van de gebruikersbinding en loyaliteit. (LlamaIndex en MyScale) In het domein van creatief schrijven heeft RAG de mogelijkheid om de contentcreatieprocessen uit te rationaliseren en nieuwe ideeën te genereren, waardoor bedrijven tijd en resources besparen kunnen.
Zoals u kunt zien, zijn de praktische toepassingen van RAG uitgebreid over een breed scala aan domeinen, van vragenbeantwoorden en gesprekkige systemen tot samenvatting en creatief schrijven. door de kracht van opslag en generatie te benutten, heeft RAG significante verbeteringen in nauwkeurigheid, relevantie en gebruikersbetrokkenheid aangetoond.
Als het veld doorgaat met evolueren, kunnen we verwachten dat er meer innovatieve toepassingen van RAG zullen zijn, die het ons veranderen hoe we informatie interageren met en genereren in verschillende contexten.
4.2 RAG voor laagresourcengebruikende talen en tweetalige omgevingen
Het benutten van de kracht van Retrieval-Augmented Generation (RAG) voor laagresourcengebruikende talen en tweetalige omgevingen is niet alleen een kans, het is een noodzakelijkheid. Met meer dan 7000 talen die wereldwijd worden gesproken, veel van die talen die een substraat aan digitaal materiaal ontberen, is het uitdaging duidelijk: hoe zorgen we ervoor dat deze talen niet achter worden gelaten in de digital age?
Vertaling als brug
Eén effectieve strategie is het vertalen van brondocumenten naar een taal met meer resources alvorens indexering. Deze aanpak maakt gebruik van de uitgebreide corpora beschikbaar in talen als Engels, wat de nauwkeurigheid en relevantie van het opslaan significant verbeterd.
door het vertalen van documenten naar Engels, kunt u toegang krijgen tot de omvangrijke hulpbronnen en geavanceerde opslagtechnieken die al zijn ontwikkeld voor hoge-resourcetalen, waardoor de prestaties van RAG-systemen in laag-resourcen contexten verbeterd worden.
Tweetalige inscripties
Recente vooruitgang in tweetalige woordinscripties biedt een andere hoopvolle oplossing. Door shared embedding ruimtes voor meerdere talen te maken, kunt u de cross-linguale prestaties zelfs voor zeer laagresourcengebruikende talen verbeteren.
Onderzoek heeft ge显示 dat het toevoegen van tussenlandtalen met hoge-kwaliteit inscripties de kloof kan overbruggen tussen afgelegen taalparen, het overall kwaliteit van tweetalige inscripties verbeterd.
Deze methode verbeterd niet alleen de exactheid van het opslaan maar zorgt ook ervoor dat het gegenereerde content contextueel relevant en lingüïstisch coherent is.
Federated Learning
Federated learning biedt een nieuwe benadering om beperkingen op het gebied van gegevensdeling en taalkundige verschillen te overschrijden. Door modelleren op gedecentraliseerde gegevensbronnen, kunt u de privacy van gebruikers behouden terwijl u de prestaties van het model op meerdere talen verbetert.
Deze methode heeft een accuracy van 6,9% hoger en een trainingsparameterreductie van 99% gerealiseerd ten opzichte van traditionele methodes, waardoor het een hoog effectieve oplossing is voor multilinguale RAG-systemen.
Mitigering van Hallucinaties
Een van de kritieke uitdagingen bij het implementeren van RAG-systemen in multilinguale omgevingen is het verminderen van hallucinaties – gevallen waarin het model factueel onjuist of irrelevante informatie genereert.
Geavanceerde RAG-technieken, zoals Modular RAG, introduceren nieuwe modules en fijne-tune strategieën om dit probleem aan te pakken. Door de kennisbase continu bij te werken en zorgvuldig evaluatiesmetrics te gebruiken, kunt u de incidentie van hallucinaties aanzienlijk verminderen en zorg ervoor dat het gegenereerde content zowel accurate als betrouwbaar is.
Praktische Implementatie
Om deze strategieën effectief uit te voeren, moet u de volgende praktische stappen overwegen:
- Gebruik Vertaling: Vertaal documenten in talen met een laag gegevensniveau eerst naar een talen met een hoog gegevensniveau, zoals Engels, alvorens ze te indexeren.
- Gebruik meertalige inschattingen: Integreer tussenlandelijke talen met hoge-kwaliteit inschattingen om de跨语言的性能 te verbeteren.
- Gebruik gedeelde learning: Schaal modellen op gedeelde gegevensbronnen voor betere prestaties terwijl privacy wordt behouden.
- Verminderen verzonnen: Toepassing geavanceerde RAG technieken en continue kennisbank updates om feitelijke nauwkeurigheid te verzekeren.
door deze strategieën over te nemen, kunt u de prestaties van RAG systemen in gebrekkige hulpbronnen en meertalige omgevingen aanzienlijk verbeteren, waarborgend dat geen taal achterstaat in de digitaal revolutie.
Hoofdstuk 5: Optimalisatietechnieken
Dit hoofdstuk gaat dieper in op de geavanceerde terughalings technieken die de effectiviteit van Retrieval-Augmented Generation (RAG) systemen ondersteunen. We ontdekken hoe kolommen optimalisatie, metadata integratie, graaf gebaseerde indexering, align technieken, gemengde zoekopdrachten en heranking de nauwkeurigheid, relevantie en comprehensie van informatie terughalen verbetert.
door deze cutting-edge methodes te begrijpen, krijgt u inzichten in hoe RAG systemen evolueren van gewone zoekmachines tot intelligentie informatie providers in staat zijn complexe query’s te begrijpen en nauwkeurige, contextueel relevante reacties af te leveren.
5.1 Geavanceerde terughalings technieken voor het optimaliseren van RAG systemen
Retrieval Augmented Generation (RAG) systemen zijn de manier waarop we toegang krijgen en gebruik maken van informatie revolutionair. Het hart van deze systemen ligt in hun vermogen effectieve terughalings van relevante informatie uit te voeren.
Laten we diepergaande inzage krijgen in de geavanceerde doorzoekingstechnieken die RAG-systemen de macht geven accurate, contextueel relevante en uitgebreide antwoorden te leveren.
Chunk Optimering: Maximeren van Relevantie door Moleculaire Doorzoeking
In de wereld van RAG-systemen kunnen grote documenten overweldigend zijn. Chunk optimering bestedt hiertegen door uitgebreide teksten op te delen in kleinere, gemakkelijker handelbare eenheden genaamd chunks. Deze granulariteit stelt doorzoekingssystemen in staat specifieke tekstsecties te identificeren die overeenkomen met querytermen, waardoor de nauwkeurigheid en effectiviteit worden verbeterd.
Het kunst van chunk optimering bestaat erin te bepalen welke ideale chunkgrootte en overlap is. Een te kleine chunk kan een gebrek aan context hebben, terwijl een te grote chunk relevantie verwaarloost. Dynamische chunking, een techniek die de chunkgrootte aanpast op basis van de structuur en semantiek van de inhoud, zorgt ervoor dat elke chunk coherent en contextueel betekenisvol is.
Metadata-integratie: De kracht van Informatie-Tags benutten
Metadata, de vaak overgeslagen informatie die bij documenten hoort, kan een goudmijn zijn voor doorzoekingssystemen. Door metadata zoals documenttype, auteur, publicatiedatum en thematig label te integreren, kunnen RAG-systemen meer doelgerichte zoekopdrachten uitvoeren.
Self-query retrieval, een techniek die mogelijk wordt gemaakt door metadata-integratie, laat het systeem toe dat aan de hand van de eerste resultaten extra queries te genereren. Dit iteratieve proces verfijnde de zoekopdracht, waardoor de teruggevonden documenten niet alleen overeenkomen met de query maar ook aan de specifieke vereisten en contextuele behoeften van de gebruiker voldoen.
Geavanceerde Indexstructuren: Grafiekgebaseerde Netwerken voor Complexe Query’s.
Traditionele indexeringmethoden, zoals inverted indexen en dichte vectorcoderingen, hebben beperkingen bij het behandelen van complexe queries die meerdere objecten en hun relaties invoorkomen. Graph-gebaseerde indexen bieden een oplossing door documenten en hun connecties in een grafische structuur te organiseren.
Deze graf-achtige organisatie maakt het efficient mogelijk om door gerelateerde documenten te bladeren en te retrieve, zelfs in ingewikkeldere scenario’s. Hiërarchische indexering enapproximatieve dichtstbijzijnde-neighbor zoeken versterken de schaalbaarheid en snelheid van grafiekgebaseerde retraal systemen.
Align Technieken: Ensuring Accuracy and Reducing Hallucinations
De geloofwaardigheid van RAG-systemen hangt af van hun mogelijkheid om accurate informatie te leveren. Align technieken, zoals counterfactual training, adresseren deze zorg. Door het model te laten vertonen aan hypothetische scenario’s, leert counterfactual training het model de verschillen tussen echte wereld feiten en gegenereerde informatie te onderscheiden, waardoor hallucinaties worden verminderd.
In multimodale RAG-systemen, die informatie integreren uit verschillende bronnen zoals tekst en afbeeldingen, speelt contrastieve leren een cruciale rol. Deze techniek aligneert de semantische representaties van verschillende data modaliteiten, waardoor de geretourneerde informatie coherent en contextueel geïntegreerd is.
Hybride Zoeken: Het Verlangen van Sleutelwoorden Precisie met Semantische Verstandhouding
Hybride zoeken combineert de beste van beide werelden: de snelheid en precisie van sleutelwoorden-gebaseerde zoeken met de semantische verstandhouding van vector zoeken. Initieel reduceert een sleutelwoorden-gebaseerde zoekactie de potentiële documenten snel tot een kleiner aantal.
Subsequently wordt de zoekresultaten verfijnder op basis van semantische verwantschap door middel van een vector-gebaseerd zoeken. Deze aanpak is bijzonder effectief als exacte trefwoordenovereenkomsten noodzakelijk zijn, maar ook een diepere kennis van de bedoeling van de zoekopdracht is nodig voor accurate opname.
Re-ranking: Refining Relevance for the Optimal Response
In de laatste fase van het opnameproces neemt re-ranking deel om de resultaten verder te verfijnen. Machine learning modellen, zoals cross-encoders, herbeoordelen de relevantiecijfers van de opgehaalde documenten. door de query en documenten te verwerken, krijgen deze modellen een diepere kennis van hun relatie.
Deze gekleurde vergelijking zorgt ervoor dat de hoogst geklasseerde documenten echt overeenkomen met de gebruikersquery en context, waardoor er een beter en informatieverleend zoekervaring wordt geboden.
De kracht van RAG-systemen ligt in hun mogelijkheid om informatie op een vloeiende manier te behalen en weer te geven. door deze geavanceerde opname technieken -chunk optimalisatie, metadata integratie, grafiek gebaseerde indexering, align technieken, hybride zoeken en re-ranking- te gebruiken, evolueren RAG-systemen tot meer dan alleen zoek engines. Ze ontwikkelen zich tot intelligent informatie verschaffers, in staat complexe query’s te begrijpen, kleine nuances te onderscheiden en nauwkeurige, relevante en vertrouwelijke antwoorden af te leveren.
Hoofdstuk 6: uitdagingen en innovaties
Dit hoofdstuk gaat diep in op de kritieke uitdagingen en toekomstige richtingen in de ontwikkeling en implementatie van Retrieval-Augmented Generation (RAG) systemen.
We ontdekken de complexiteiten van het evalueren van RAG-systemen, inclusief de behoefte aan omvangrijke metrics en aanpasbare frameworks om hun prestatie accuraat te beoordelen. We besteden aandacht ook aan ethische overwegingen zoals het verminderen van bias en rechtvaardigheid in informatieretrieval en -generatie.
We besteden aandacht ook aan de import van hardwareversnelling en efficiente implementatie strategieën, door de gebruik van geavanceerde hardware en optimalisatie tools zoals Optimum aan te duiden om prestaties en schaalbaarheid te verbeteren.
Door deze uitdagingen te begrijpen en potentiële oplossingen te verkennen, biedt dit hoofdstuk een compleet overzicht van de weg voor de voortdurende vooruitgang en verantwoordelijke implementatie van RAG-technologie.
6.1 Uitdagingen en Toekomstige Richtingen
Retrieval-Augmented Generation (RAG) systemen hebben uitstekende potentiële voordelen ge展示d bij het verbeteren van de nauwkeurigheid, relevantie en coherente tekstgeneratie. Maar de ontwikkeling en implementatie van RAG-systemen stellen ook significante uitdagingen voor die moeten worden behandeld om hun potentiële volledig te benutten.
“Het evalueren van RAG-systemen betekent dus dat men veel specifieke componenten moet in acht nemen en de complexiteit van de algehele systeembeoordeling.” (Salemi et al.)
Uitdagingen bij het Evalueren van RAG-Systemen
Een van de primaire technische uitdagingen in RAG is het efficient verkrijgen van relevante informatie uit grote schaal kennisbasis. (Salemi et al. en Yu et al.)
Met de groeiende omvang en diversiteit van kennisbronnen wordt de ontwikkeling van schaalbare en robuuste terughalingsmechanismen steeds belangrijker. Technieken zoals hiërarchisch indexeren, ruimtelijke dichtsbijzijnde vragen zoeken en aanpassbare terughalingsstrategieën moeten worden onderzocht om het terughalingsproces te optimaliseren.
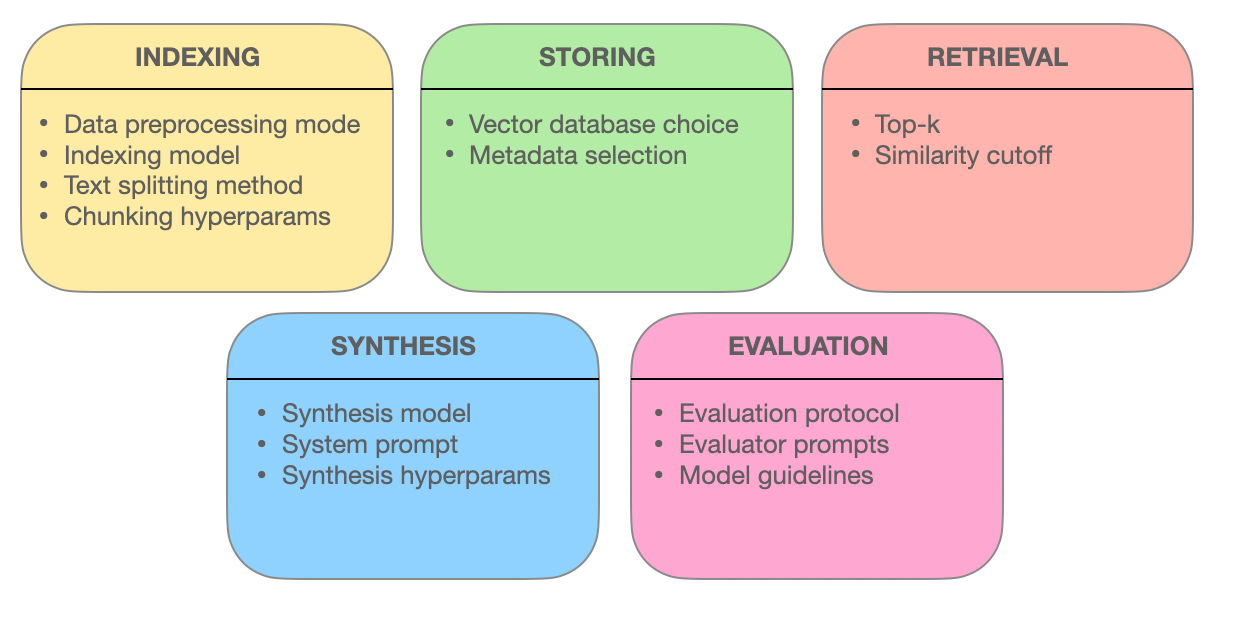
Enkele elementen van een RAG-systeem – miro.medium.com
Een andere significante uitdaging is het verminderen van de hallucinatieproblematiek, waarbij de generatieve model feitelijk onjuiste of onconsistente informatie produceert.
Bijvoorbeeld kan een RAG-systeem een historische gebeurtenis die nooit is voorgevallen of een wetenschappelijke ontdekking verkeerd toewijzen genereren. Terwijl terughalen helpt om de gegenereerde tekst op feitelijke kennis te gronden, blijft het vaststellen van de trouw en de coherente gegenereerde uitvoer een complex probleem.
Bijvoorbeeld, een RAG-systeem kan accurate informatie over een wetenschappelijke ontdekking uit een betrouwbare bron zoals Wikipedia terughalen, maar de generatieve model zou nog steeds hallucineren door deze informatie foutief te combineren of niet-bestaande details toe te voegen.
Effectieve mechanismen ontwikkelen om hallucinaties te detecteren en te voorkomen is een actief onderzoeksgebied. Technieken zoals feitverificatie met behulp van externe databases en consistentiecontrole door middel van cross-referencing van meerdere bronnen worden onderzocht. Deze methodes streefden ernaar toe dat het gegenereerde content nog accurate en betrouwbaar blijft, ondanks de inherente uitdagingen bij het aligneren van het opvragen en genereren van processen.
Het integreren van diverse kennisbronnen, zoals gestructureerde databases, ongestructureerd text en multimodale data, brengt extra uitdagingen met zich mee in RAG-systemen. (Yu et al. en Zilliz) Het aligneren van de representaties en semantiek over verschillende data-modaliteiten en kennisformaten vereist geavanceerde technieken, zoals cross-modaliteit aandacht en kennisgrafiek embedden. Het waarborgen van de compatible en interoperabiliteit van diverse kennisbronnen is cruciaal voor de effectieve functioneren van RAG-systemen. (Zilliz)
Buiten de technische uitdagingen zijn RAG-systemen ook van belang voor de ethiek. Het garanderen van onpartijdig en fair informatieretrieval en -generatie is een kritische zorg. RAG-systemen kunnen onbewust biases die in de trainingsgegevens of kennisbronnen aanwezig zijn versterken, wat leidt tot discriminatoire of misleide uitvoeringen. (Salemi et al. en Banafa)
Het ontwikkelen van technieken om biases te detecteren en te verminderen, zoals adversaire training en rechtvaardigheidstekenende retrieval, is een belangrijke onderzoeksrichting. (Banafa)
Toekomstige Onderzoeksrichtingen
Om de uitdagingen bij de evaluatie van RAG-systemen aan te spreken, kunnen verschillende potentiële oplossingen en onderzoeksrichtingen worden onderzocht.
Het ontwikkelen van complete evaluatiescores die de interactie tussen retrievalaccuratie en generatieve kwaliteit vastleggen, is crucial. (Salemi et al.)
Gemetrieken die de relevantie, coherente en feitelijke correctheid van gegenereerd text beoordelen, terwijl wordt gekeken naar de effectiviteit van de opslagcomponent, moeten worden vastgesteld. (Salemi et al.) Dit vereist een holistische aanpak die buiten de traditionele metrieken als BLEU en ROUGE gaat en de menselijke evaluatie en takenspecifieke maatstaven integreert.
Het onderzoeken van aanpasbare en realtime evaluatiesystemen is een andere promissorieke richting.
RAG-systemen werken in dynamische omgevingen waarin de kennisbronnen en gebruikersvereisten mogelijk over tijd evolueren. (Yu et al.) Het ontwikkelen van evaluatiesystemen die aan deze veranderingen kunnen aanpassen en realtime feedback kunnen geven over de prestatie van het systeem, is essentieel voor de continue verbetering en monitoren.
Dit kan technieken omvatten als online leren, actief leren en kunstmatig intelligent leren om de evaluatemetrieken en modellen bij te werken op basis van gebruikersfeedback en systeemgedrag. (Yu et al.)
Samenwerkingsverbanden tussen onderzoekers, industriële praktijkbeoefenaren en domeinexperts zijn nodig om de vakgebieden van RAG-evaluatie vooruit te brengen. Het vaststellen van standaardiseerde benchmarks, datasets en evaluatieprotocollen kan de vergelijking en reproduceerbaarheid van RAG-systemen over verschillende domeinen en toepassingen vergemakkelijken. (Salemi et al. en Banafa)
Involveren van belanghebbenden, inclusief eindgebruikers en beleidsmakers, is essentieel om er voor te zorgen dat de ontwikkeling en implementatie van RAG-systemen overeenkomen met maatschappelijke waarden en ethische beginselen. (Banafa)
Hoewel RAG-systemen groot potentieel hebben getoond, is het belangrijk om de uitdagingen in hun evaluatie aan te spreken voor hun algemeen gebruik en vertrouwen. door het ontwikkelen van complete evaluatiescores, het onderzoeken van aanpasbare en realtime evaluatiekaders en het behouden van samenwerkingsverbanden, kunnen we de weg vrijmaken voor meer betrouwbare, onpartijdige en effectieve RAG-systemen.
Als het vakgebied doorgaat met het evolueren, is het noodzakelijk om onderzoeksinspiratie prioriteit te geven die niet alleen de technische mogelijkheden van RAG verbetert maar ook er voor zorgt dat hun verantwoordelijke en ethische implementatie in echte wereld toepassingen wordt behouden.
6.2 Hardwareversnelling en efficiente implementatie van RAG-systemen
Het benutten van hardwareversnelling is crucial voor de efficiente implementatie van Retrieval-Augmented Generation (RAG) systemen. Door computationele intensieve taken over te laten aan speciale hardware, kunt u de prestaties en schaalbaarheid van uw RAG modellen significant verbeteren.
Lever op Speciale Hardware
Optimum’s hardware-specifieke optimalisatie tools bieden significante voordelen. Bijvoorbeeld, het gebruik van RAG systemen op Habana Gaudi processoren kan leiden tot een opvallende vermindering in inference latency, terwijl Intel Neural Compressor optimalisaties de latency metrics nog verbetering kunnen brengen. AWS Inferentia hardware, geoptimaliseerd via Optimum Neuron, kan de doorvoerscapaciteit verhogen, waardoor uw RAG systeem beter en efficiënter reageert.
Optimaliseer Resource Gebruik
Efficient resource gebruik is cruciaal. Optimum ONNX Runtime optimalisaties kunnen resulteren in meer efficiënte geheugengebruik, terwijl de BetterTransformer API CPU en GPU gebruik kunnen verbeteren. Deze optimalisaties zorgen ervoor dat uw RAG systeem op zijn hoogtepunt functioneert, operationele kosten reduceert en prestaties verbeterd.
Schaalbaarheid en Flexibiliteit
Optimum biedt een vloeiende overstap tussen verschillende hardwareversnellers, waardoor dynamische schaalbaarheid mogelijk is. Deze multi-hardware ondersteuning laat u toe om zonder significante herconfiguratie aan te passen aan verschillende computatievermogens. Ook kunnen de model quantisatie en verkleiningsfuncties in Optimum een efficiëntere modelgrootte faciliteren, waardoor implementatie gemakkelijker en kostenverterbaarder wordt.
Case Studies en Real-World Applicaties
Overweeg de toepassing van Optimum in de gezondheidszorg informatieretrieval. Door hardware-specifieke optimalisaties te benutten, kunnen RAG-systemen efficiënteel grote datasets verwerken, biedende accurate en tijdige informatieretrieval. Dit verbeterd niet alleen de kwaliteit van de gezondheidszorg maar verbetert ook het algemene gebruikerservaring.
Praktische stappen voor implementatie
- Kies aanbevolen hardware: Kies hardwareacceleratoren zoals Habana Gaudi of AWS Inferentia gebaseerd op uw specifieke prestatievereisten.
- Gebruik optimalisatiegereedschap: Implementeer Optimum’s optimalisatietools om de latentie, doorvoersnelheid en resourceschatting te verhogen.
- Verzeker scalabiliteit:gebruik multi-hardwareondersteuning om uw RAG-systeem dynamisch op maat te schalen als nodig.
- Optimaliseer modelgrootte: Gebruik modelquantificering en snoeiing om de computationele overhead te verminderen en de implementatie gemakkelijker te faciliteren.
door deze strategieën te integreren, kunt u de prestatie, schaalbaarheid en efficientie van uw RAG-systemen significant verhogen, zodat ze goed uitgerust zijn om complexe, echte-wereldtoepassingen aan te kunnen.
Conclusie: Het transformatieve potentiële van RAG
Retrieval-Augmented Generation (RAG) vertegenwoordigt een transformatieve Paradigma in natuurlijke taalverwerking, door de kracht van informatieretrieval eenvoudig te integreren met de generatieve mogelijkheden van grote taalmodellen.
Door de besturing van externe kennisbronnen te gebruiken, hebben RAG-systemen uitstekende verbeteringen in de nauwkeurigheid, relevantie en coherentie van gegenereerde tekst getoond over een breed scala aan toepassingen, van vragenbeantwoordende systemen en dialo格斯ystemen tot samenvatting en creatief schrijven.
De evolutie van taalklassetjes, van vroege regelgebaseerde systemen tot de moderne neurale architecturen zoals BERT en GPT-3, heeft de weg vrijgemaakt voor de opkomst van RAG. De beperkingen van zuiver parametrische geheugen in traditionele taalklassetjes, zoals kenniscut-offdatums en feitelijke onjuistheden, zijn effectief door de integratie van niet-parametrische geheugen via opname mechanismen aan de slag gegaan.
De kernonderdelen van RAG-systemen, namelijk retriever en generatieve modellen, werken samen om contextueel relevante en feitelijk gegrondde uitvoer te produceren.
Retrievers, die technieken als spars en dichte retriever gebruiken, zoeken efficiënt door brede kennisbasissen om de meest relevante informatie te identificeren. Generatieve modellen, die architecturen als GPT en T5 gebruiken, synthetiseren de gevonden inhoud in een helder en vloeiend tempo.
Integratiestrategieën, zoals concatenatie en cross-attention, bepalen hoe de gevonden informatie wordt opgenomen in het generatieproces.
De praktische toepassingen van RAG strekken zich uit over diverse domeinen, die het potentiële van RAG tonen om verschillende industrieën te revolutioneren.
In vragenbeantwoordende systemen heeft RAG de nauwkeurigheid en relevantie van antwoorden significant verbeterd, waardoor informatief en betrouwbaardere informatieopslag mogelijk is geworden. Dialo格斯ystemen hebben onder RAG gegroeid, waardoor de conversaties meer aantrekkelijk en coherent zijn geworden. Samenvattingstaken hebben de kwaliteit en coherente verbeterd door de integratie van relevante informatie uit meerdere bronnen. Zelfs creatief schrijven is onderzocht, met RAG-systemen vernieuwende en stijlvolle consistente verhalen genererend.
Maar de ontwikkeling en evaluatie van RAG-systemen bieden ook significante uitdagingen. Efficiente opslag uit grote kennisbasissen, vermindering van hallucinaties en integratie van verschillende datamodaliteiten zijn technische uitdagingen die moeten worden behandeld. Ethische overwegingen, zoals het waarborgen van onpartijdig en eerlijke informatieopslag en -genereren, zijn crucial voor de verantwoordelijke implementatie van RAG-systemen.
Om het potentieel van RAG volledig te benutten, moeten toekomstige onderzoeksrichtingen zich concentreren op het ontwikkelen van complete evaluatiescores die de interactie tussen opslagnauwkeurigheid en genererende kwaliteit vastleggen.
Adaptieve en realtime evaluatieframeworks die de dynamische natuur van RAG-systemen kunnen aanvaarden, zijn essentieel voor de doorlopende verbetering en monitering. Collectieve inspanningen tussen onderzoekers, industriële praktijke en domeinexperts zijn nodig om standaardiseerde benchmarks, datasets en evaluatiesprotocollen in te stellen.
Als het veld van RAG doorgaat met evolueren, biedt het veelbelovende toekomstigheden voor het transformeren van hoe we informatie interageren en genereren. door de kracht van het ophalen en genereren in handen te nemen, hebben RAG-systemen de mogelijkheid om verschillende domeinen te revolutioneren, van informatie ophalen en gesprekkenagenten tot inhoud creëren en kennis ontdekken.
Het Retrieval-Augmented Generation (RAG) is een belangrijk mijlpaal in de reis naar meer intelligent, nauwkeurig en contextueel relevant taalgeneratie.
Door de kloof tussen parametrisch en niet-parametrisch geheugen over te bruggen, hebben RAG-systemen nieuwe mogelijkheden geopend voor natuurlijke taalverwerking en zijn toepassingen.
Als de onderzoek voortgaat en de uitdagingen worden aangepakt, kunnen we RAG verwachten om een steeds belangrijker rol te spelen in het vormen van de toekomst van de mens-machineinteractie en kennisgeneratie.
Over de auteur
Vahe Aslanyan, hier, aan het knooppunt van computerwetenschap, datawetenschap en AI. Bezoek vaheaslanyan.com om een portfolio te zien dat getuigt van nauwkeurigheid en vooruitgang. Mijn ervaring brugt het kloof tussen volledig schakelbaar ontwikkelen en AI-product optimalisatie, gestimuleerd door het oplossen van problemen in nieuwe manieren.
Met een trackrecord die een toonaangevende data science cursus lanceerde en samenwerkte met topspecialisten uit de industrie, blijft mijn focus op het verhogen van de techonderwijsstandaarden tot universele normen.
Hoe kun je dieper duiken?
Na het bestuderen van deze handleiding, als u nog dieper wilt duiken en een gestructureerd leerstijl heeft, overweeg dan om bij ons aan te sluiten bij LunarTech, we bieden individuele cursussen en een Bootcamp aan in Data Science, Machine Learning en AI.
We bieden een uitgebreid programma dat een diepgaande begrip van de theorie, praktische handmatige implementatie, uitgebreid praktische materiaal en gepersonaliseerde voorbereiding voor interviews biedt om u voor te bereiden op succes op uw eigen pad.
U kunt onze Ultimate Data Science Bootcamp bekijken en deelname aan een gratis proefles om de inhoud direct uit te proberen. Dit heeft de erkenning gekregen om een van de Beste Data Science Bootcamps van 2023 te zijn en is gepubliceerd in respectable publicaties zoals Forbes, Yahoo, Entrepreneur en meer. Dit is uw kans om deel uit te maken van een community die op innovatie en kennis leeft. Hier is het welkomstbericht!
Connecteer me met.

LunarTech Nieuwsbrief
- Volg me op LinkedIn voor veel gratis resources in CS, ML en AI
- Bezoek mijn persoonlijke website
- Schrijf je in voor mijn The Data Science and AI Newsletter
Als je meer wilt leren over een carrière in Data Science, Machine Learning en AI, en hoe je een Data Science baan kunt verkrijgen, kun je dit gratis Data Science and AI Career Handbook downloaden.
Source:
https://www.freecodecamp.org/news/retrieval-augmented-generation-rag-handbook/