













Klassiek Geval 1
Veel softwareprofessionals missen diepgaande kennis van TCP/IP-logisch redeneren, wat er vaak toe leidt dat problemen worden geïdentificeerd als mysterieuze problemen. Sommigen worden ontmoedigd door de complexiteit van TCP/IP-netwerkliteratuur, terwijl anderen worden misleid door verwarrende details in Wireshark. Zo kan een DBA die te maken heeft met prestatieproblemen, pakketvangstgegevens in Wireshark verkeerd interpreteren en ten onrechte concluderen dat TCP-herzendingen de oorzaak zijn.

Aangezien herzending wordt vermoed, is het essentieel om de aard ervan te begrijpen. Herzending houdt fundamenteel verband met time-out-herzending. Om te bevestigen of herzending inderdaad de oorzaak is, is tijdsgerelateerde informatie nodig, die niet wordt verstrekt in de bovenstaande schermafbeelding. Na het aanvragen van een nieuwe schermafbeelding van de DBA, werd de tijdstempelinformatie toegevoegd.

Bij het analyseren van netwerkpakketten is tijdstempelinformatie cruciaal voor nauwkeurige logische redenering. Een tijdsverschil in het microsecondenbereik tussen twee identieke pakketten suggereert ofwel een time-out-herzending of een duplicaat van pakketvangst. In een typische LAN-omgeving met een Round-trip Time (RTT) van ongeveer 100 microseconden, waar TCP-herzendingen minstens één RTT vereisen, duidt een herzending die slechts 1/100e van de RTT duurt waarschijnlijk op een duplicaat van pakketvangst in plaats van een werkelijke time-out-herzending.
Klassiek Geval 2
Nog een klassiek geval illustreert het belang van logisch redeneren bij de analyse van netwerkproblemen.
Op een dag kwam er een zakelijke ontwikkelaar haastig binnen, zeggend dat een gepland script dat gebruikmaakte van de MySQL-database middleware was mislukt in de vroege ochtenduren zonder respons. Na het horen van het probleem, controleerde ik de foutenlogs van de MySQL-database middleware maar vond geen waardevolle aanwijzingen. Dus vroeg ik de ontwikkelaars of ze het probleem konden reproduceren, wetende dat eenmaal reproduceerbaar, een probleem makkelijker op te lossen is.
De ontwikkelaars probeerden meerdere keren het probleem te reproduceren maar slaagden er niet in. Echter, ze maakten een nieuwe ontdekking: ze ontdekten dat het uitvoeren van dezelfde SQL-query’s gedurende de dag resulteerde in verschillende responstijden vergeleken met de vroege ochtend. Ze vermoedden dat wanneer de SQL-respons traag was, de MySQL-database middleware de sessie blokkeerde en geen resultaten terugstuurde naar de client.
Op basis van deze inzichten werd aan het database-operatieteam gevraagd om de SQL van het script aan te passen om een trage SQL-respons te simuleren. Als gevolg daarvan gaf de MySQL-database middleware de resultaten terug zonder het vasthangprobleem dat gezien werd in de vroege ochtenduren.
Enige tijd lang kon de werkelijke oorzaak niet geïdentificeerd worden, en ontwikkelaars ontdekten een functioneel probleem met de MySQL-database middleware. Daarom raakten ontwikkelaars en DBA-operaties er steeds meer van overtuigd dat de MySQL-database middleware de reactietijden vertraagde. In werkelijkheid hadden deze problemen echter geen verband met de responstijden van de MySQL-database middleware.
Uit de gebeurtenissen van de eerste dag bleek inderdaad dat het probleem zich voordeed. Iedereen die erbij betrokken was, probeerde de oorzaak te achterhalen, maakte verschillende gissingen, maar de werkelijke reden bleef ongrijpbaar.
De volgende dag meldden ontwikkelaars dat het scriptprobleem weer optrad in de vroege ochtend, maar dat ze het overdag niet konden reproduceren. Ontwikkelaars, onder druk gezet omdat het script binnenkort online zou worden gebruikt, klaagden over de situatie. Mijn enige suggestie was om het script overdag te gebruiken om problemen in de vroege ochtend te voorkomen. Met alle verdenkingen gericht op de MySQL-database-middleware, was het uitdagend om het probleem vanuit andere perspectieven te analyseren.
Als ontwikkelaar die verantwoordelijk is voor de MySQL-database-middleware, kunnen dergelijke mysterieuze problemen niet gemakkelijk over het hoofd worden gezien. Het negeren ervan kan invloed hebben op het latere gebruik van de MySQL-database-middleware, en er is ook druk vanuit het leiderschap om het probleem snel op te lossen. Uiteindelijk werd besloten om een low-cost pakketopvanganalyseoplossing te implementeren: tijdens de uitvoering van het script in de vroege ochtend zouden pakketopvangsten worden uitgevoerd op de server om te analyseren wat er op dat moment gebeurde. Het doel was om te bepalen of de MySQL-database-middleware ofwel helemaal geen reactie verzond of dat het wel een reactie verzond die het client-script niet ontving. Zodra kon worden bevestigd dat de MySQL-database-middleware een reactie had verzonden, zou het probleem niet worden toegeschreven aan de ontwikkelaars van de MySQL-database-middleware.
Op de derde dag meldden ontwikkelaars dat het vroege ochtendprobleem zich niet opnieuw voordeed, en de analyse van pakketten bevestigde dat het probleem niet optrad. Na zorgvuldige overweging leek het onwaarschijnlijk dat het probleem alleen bij de MySQL-database middleware lag: frequente gebeurtenissen in de vroege ochtend en zeldzame gebeurtenissen gedurende de dag waren verwarrend. De enige actie die ondernomen kon worden, was wachten tot het probleem zich opnieuw voordeed en het analyseren op basis van de pakketcaptures.
Op de vierde dag deed het probleem zich niet opnieuw voor.
Op de vijfde dag deed het probleem echter eindelijk weer voor, wat hoop op een oplossing bracht.
De pakketcapturebestanden zijn talrijk. Vraag eerst aan de ontwikkelaars om de tijdstempel te verstrekken wanneer het probleem optrad, doorzoek vervolgens de uitgebreide gegevens van de pakketcapture om de SQL-query te identificeren die het probleem veroorzaakte. Het uiteindelijke resultaat is als volgt:
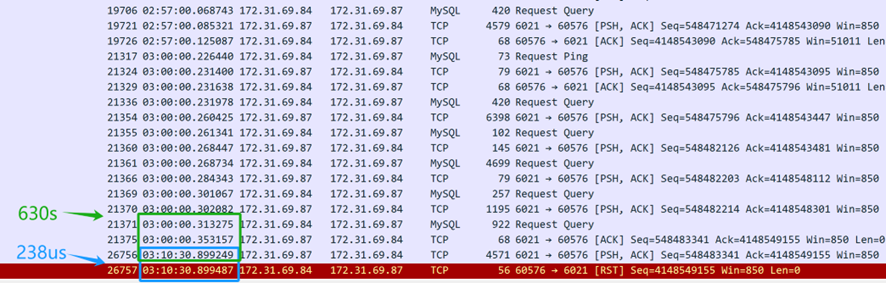
Uit de bovenstaande pakketcapture-inhoud (vastgelegd vanaf de server) blijkt dat de SQL-query om 3 uur ’s ochtends is verzonden. De MySQL-database middleware deed er 630 seconden over (03:10:30.899249-03:00:00.353157) om de SQL-reactie naar de client terug te sturen, wat aangeeft dat de MySQL-database middleware inderdaad reageerde op de SQL-query. Slechts 238 microseconden later (03:10:30.899487-03:10:30.899249) ontving de TCP-laag van de server echter een resetpakket, wat verdacht snel was. Het is belangrijk op te merken dat dit resetpakket niet onmiddellijk als afkomstig van de client kan worden aangenomen.
Ten eerste is het noodzakelijk te bevestigen wie het resetpakket heeft verzonden — of het door de client is verzonden of door een tussenliggend apparaat onderweg. Aangezien de pakketcaptatie alleen aan de serverzijde is uitgevoerd, is informatie over de pakketstatus van de client niet beschikbaar. Door de pakketcaptatiebestanden van de serverzijde te analyseren en logische redeneringen toe te passen, is het doel om de oorzaak van het probleem te achterhalen.
Als de aanname wordt gedaan dat de client een reset heeft verzonden, zou dat impliceren dat de TCP-laag van de client de TCP-status van deze verbinding niet langer herkent — overgaand van een gevestigde staat naar een niet-bestaande. Deze wijziging in de TCP-status zou de clienttoepassing op de hoogte stellen van een verbindingsprobleem, waardoor het clientscript onmiddellijk een fout zou geven. Echter, in werkelijkheid wacht het clientscript nog steeds op de reactie. Daarom houdt de aanname dat de client een reset heeft verzonden niet stand — de client heeft geen reset verzonden. De verbinding van de client is nog steeds actief, maar aan de serverzijde is de bijbehorende verbinding beëindigd door de reset.
Wie heeft de reset dan verzonden? De belangrijkste verdachte is de cloudomgeving van Amazon. Op basis van deze analyse van de pakketcaptatie heeft de DBA-operaties Amazon klantenservice geraadpleegd en de volgende informatie ontvangen:
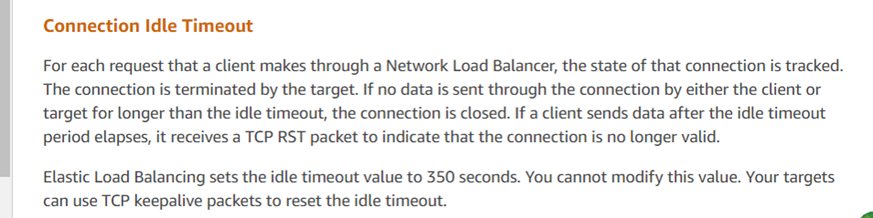
De reactie van de klantenservice komt overeen met de analyse resultaten, wat aangeeft dat Amazon’s ELB (Elastic Load Balancer, vergelijkbaar met LVS) de TCP-sessie geforceerd heeft beëindigd. Volgens hun feedback, als een reactie de drempel van 350 seconden overschrijdt (zoals waargenomen in de pakketcaptatie als 630 seconden), stuurt het ELB-apparaat van Amazon een reset naar de reagerende partij (in dit geval de server). De cliëntscripts die door de ontwikkelaars zijn ingezet, ontvingen de reset niet en gingen ten onrechte ervan uit dat de serververbinding nog actief was. Officiële aanbevelingen voor dergelijke problemen zijn onder meer het gebruik van TCP keepalive-mechanismen om deze problemen te verminderen.
Met de officiële reactie die is verkregen, werd het probleem als volledig opgelost beschouwd.
Deze specifieke casus illustreert hoe online problemen zeer complex kunnen zijn, waarbij het vastleggen van cruciale informatie — in dit geval, pakketcaptatiegegevens — nodig is om de situatie te begrijpen zoals deze zich voordeed. Door logisch redeneren en de toepassing van reductio ad absurdum, werd de onderliggende oorzaak geïdentificeerd.
Source:
https://dzone.com/articles/logical-reasoning-in-network-problems