













Vertaling:
Leren Linux is een van de meest waardevolle vaardigheden in de tech-industrie. Het kan je helpen dingen sneller en efficiënter te laten verlopen. Veel van de krachtige servers en supercomputers wereldwijd draaien op Linux.
Terwijl het je in je huidige rol sterker maakt, kan leren Linux je ook helpen over te stappen naar andere tech-carrières zoals DevOps, Cybersecurity en Cloud Computing.
In deze handleiding leer je de basisprincipes van de Linux-opdrachtregel, en ga je over op meer geavanceerde onderwerpen zoals shellscripting en systeembeheer. Of je nu nieuw bent bij Linux of het al jaren gebruikt, dit boek heeft iets voor je.
Belangrijke Opmerking: Alle voorbeelden in dit boek worden gedemonstreerd in Ubuntu 22.04.2 LTS (Jammy Jellyfish). De meeste opdrachtregelhulpmiddelen zijn meer of minder hetzelfde in andere distributies. Echter, sommige GUI-toepassingen en opdrachten kunnen verschillen als je werkt met een andere Linux-distributie.
Inhoudsopgave
Deel 1: Introductie tot Linux
1.1. Aan de slag met Linux
Wat is Linux?
Linux is een open-source besturingssysteem gebaseerd op het Unix-besturingssysteem. Het werd in 1991 gecreëerd door Linus Torvalds.
Openbron betekent dat de broncode van het besturingssysteem openbaar toegankelijk is. Dit maakt het mogelijk voor iedereen om de originele code te wijzigen, aan te passen en het nieuwe besturingssysteem te verspreiden naar potentiele gebruikers.
Waarom zou je over Linux moeten leren?
In het huidige datacenterlandschap zijn Linux en Microsoft Windows de voornaamste spelers, waarbij Linux een groot deel van de markt heeft.
Hier zijn verschillende overtuigende redenen om Linux te leren:
-
Gezien de prevalentie van Linux-hosting is er een grote kans dat je applicatie op Linux gehost wordt. Daarom wordt het leren van Linux als ontwikkelaar steeds waardevoller.
-
Met cloud computing als norm is er een grote kans dat je cloud-exemplaren op Linux zullen rusten.
-
Linux dient als basis voor veel besturingssystemen voor het Internet of Things (IoT) en mobiele applicaties.
-
In de IT zijn er veel mogelijkheden voor mensen met vaardigheden in Linux.
Wat betekent het dat Linux een openbronbesturingssysteem is?
Eerst, wat is open source? Open source software is software waarvan de broncode vrij toegankelijk is, waardoor iedereen het kan gebruiken, aanpassen en verspreiden.
Wanneer broncode wordt gemaakt, wordt het automatisch als auteursrechtelijk beschermd beschouwd, en de distributie ervan wordt beheerst door de auteursrechthouder via softwarelicenties.
In tegenstelling tot open source beperkt propriëtaire of gesloten software de toegang tot de broncode. Alleen de makers kunnen het bekijken, aanpassen of distribueren.
Linux is voornamelijk open source, wat betekent dat de broncode vrij beschikbaar is. Iedereen kan het bekijken, aanpassen en verspreiden. Ontwikkelaars van overal ter wereld kunnen bijdragen aan de verbetering ervan. Dit legt de basis voor samenwerking, een belangrijk aspect van open source software.
Deze samenwerkingsaanpak heeft geleid tot de brede adoptie van Linux op servers, desktops, embedded systemen en mobiele apparaten.
Het meest interessante aspect van Linux als open source is dat iedereen het besturingssysteem naar hun specifieke behoeften kan aanpassen zonder beperkt te worden door propriëtaire beperkingen.
Chrome OS gebruikt door Chromebooks is gebaseerd op Linux. Android, dat veel smartphones wereldwijd aandrijft, is ook gebaseerd op Linux.
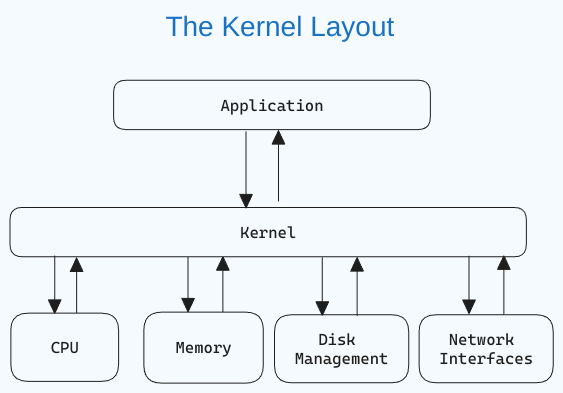
Wat is een Linux-kernel?
De kernel is het centrale onderdeel van een besturingssysteem dat de computer en zijn hardware-operaties beheert. Het handelt geheugenoperaties en CPU-tijd af.
De kernel fungeert als een brug tussen applicaties en de hardwarematige gegevensverwerking via inter-process communicatie en systeemoproepen.
Het kernel wordt eerst in de geheugen geladen bij het starten van een besturingssysteem en blijft daar totdat het systeem afsluit. Het is verantwoordelijk voor taken als schijfbeheer, takenbeheer en geheugenbeheer.
Als u geïnteresseerd bent in het uiterlijk van de Linuxkernel, hier is de GitHublink.
Wat is een Linuxdistributie?
Momenteel weet u dat u de Linuxkernelcode kunt hergebruiken, hem kunt wijzigen en een nieuwe kernel kunt creëren. U kunt verder verschillende hulpprogrammas en software combineren om een complete nieuwe besturingssysteem te maken.
Een Linuxdistributie of distro is een versie van het Linuxbesturingssysteem die de Linuxkernel, systeemhulpprogrammas en andere software bevat. Being open source, a Linux distribution is a collaborative effort involving multiple independent open-source development communities.
Wat betekent het dat een distributie afgeleid is? Als u zegt dat een distributie “afgeleid” is van een andere, is de nieuwere distro gebouwd op de basis of fundering van de originele distro. Deze afleiding kan omvatten het gebruik van hetzelfde pakketbeheersysteem (meer over dit later), kernelversie en soms dezelfde configuratietools.
Vandaag de dag zijn er duizenden Linuxdistributies om uit te kiezen, die verschillende doelstellingen en criteria voor het kiezen en ondersteunen van de software die door hun distributie wordt aangeboden bieden.
Distributies verschillen van elkaar, maar ze hebben over het algemeen verschillende gemeenschappelijke kenmerken:
-
Een distributie bestaat uit een Linuxkernel.
-
Het ondersteunt programma’s in de gebruikersruimte.
-
Een distributie kan klein en voor een specifiek doel zijn of duizenden openbronprogramma’s bevatten.
-
Er moet een manier zijn om de distributie en haar componenten te installeren en bij te werken.
Als je de Linux Distributions Tijdlijn bekijkt, zul je twee belangrijke distro’s zien: Slackware en Debian. Verscheidene distributies zijn afgeleid van deze twee. Bijvoorbeeld, Ubuntu en Kali zijn afgeleid van Debian.
Wat zijn de voordelen van afleiding? Er zijn diverse voordelen bij afleiding. Afgeleide distributies kunnen de stabiliteit, veiligheid en grote softwarerepositories van de hoofddistributie benutten.
Wanneer op een bestaande basis wordt gebouwd, kunnen ontwikkelaars al hun aandacht en inspanning richten op de gespecialiseerde functies van de nieuwe distributie. Gebruikers van afgeleide distributies kunnen profiteren van de documentatie, gemeenschapsondersteuning en middelen die al beschikbaar zijn voor de hoofddistributie.
Sommige populaire Linux-distributies zijn:
- Ubuntu: Een van de meest gebruikte en populaire Linux-distributies. Het is gebruikersvriendelijk en wordt aanbevolen voor beginners. Leer hier meer over Ubuntu.
-
Linux Mint: Gebaseerd op Ubuntu, biedt Linux Mint een gebruiksvriendelijke ervaring met een focus op multimedia-ondersteuning. Leer hier meer over Linux Mint.
-
Arch Linux: Populair bij ervaren gebruikers, Arch is een lichtgewicht en flexibele distributie gericht op gebruikers die een DIY-approach prefereren. Leer hier meer over Arch Linux.
-
Manjaro: Gecreëerd op basis van Arch Linux, biedt Manjaro een user-friendly ervaring met voorgeinstalleerde software en gemakkelijke systememanagementgereedschappen. Leer meer over Manjaro hier.
-
Kali Linux: Kali Linux biedt een uitgebreid pakket van veiligheidswerkgerei en is voornamelijk gericht op cybersecurity en hacken. Leer meer over Kali Linux hier.
Hoe Linux te installeren en te bereiken
Het beste manier om te leren is door de concepten in de praktijk te brengen. In dit gedeelte zullen we leren hoe Linux op uw machine te installeren zodat u mee kunt leven. U zult ook leren hoe u Linux op een Windows-machine kunt bereiken.
Ik adviseer u om een van de methodes die in dit gedeelte genoemd zijn te volgen om toegang tot Linux te krijgen zodat u mee kunt leven.
Linux als primair besturingssysteem installeren
Installeren van Linux als primair besturingssysteem is de meest efficiënte manier om Linux te gebruiken, want u kunt de volledige kracht van uw machine gebruiken.
In deze sectie zult u leren hoe u Ubuntu installeert, wat een van de meest populaire Linux-distributies is. Ik heb andere distributies voorlopig overgeslagen, omdat ik dingen simpel willen houden. U kunt altijd andere distributies verkennen zodra u gemakkelijkheden heeft met Ubuntu.
-
Stap 1 – Download de Ubuntu iso: Ga naar de officiële website en download het iso-bestand. Zorg ervoor dat u een stabiele uitgave kiest die gemarkeerd is als “LTS”. LTS staat voor Long Term Support, wat betekent dat u gratis beveiligings- en onderhoudsupdates kunt krijgen voor een lange periode (meestal 5 jaar).
-
Stap 2 – Maak een bootbare USB-stick: Er zijn verschillende softwareprogramma’s die een bootbare USB-stick kunnen maken. Ik aanbevelen Rufus te gebruiken, omdat het eenvoudig is te gebruiken. U kunt het hier hier downloaden.
-
Volg stap 3 – Opstarten vanaf de USB-stick:
Als uw USB-stick voor opstarten klaar is, sleep hem in en opstart vanaf de USB-stick. Het opstartmenu is afhankelijk van uw laptop. U kunt zoeken naar het opstartmenu voor uw laptopmodel.
-
Volg stap 4 – volg de aanwijzingen. Zodra de opstartproces is begonnen, selecteer
proberen of Ubuntu installeren.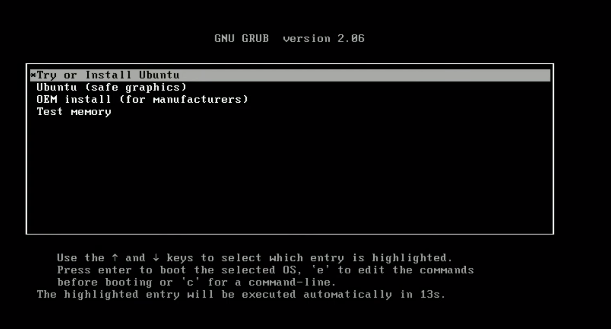
Het proces zal enige tijd in beslag nemen. Zodra de GUI verschijnt, kunt u de taal en toetsenbordindeling kiezen en doorgaan. Voer uw aanmeldingsgegevens en naam in. Onthoud de gegevens omdat u ze nodig zult om aan te melden bij uw systeem en toegang te krijgen tot volledige rechten. Wacht tot de installatie is voltooid.
-
Volg stap 5 – Opnieuw opstarten: Klik op opnieuw opstarten nu en verwijder de USB-stick.
-
Stap 6 – Login: Log in met de gegevens die u eerder heeft ingevoerd.
En daar zijn u! Nu kunt u apps installeren en uw bureaublad personaliseren.

Voor geavanceerde installaties kunt u de volgende onderwerpen verkennen:
-
Schijfpartitionering.
-
Schijfpartitionering.
Toegang tot de terminal
Een belangrijk deel van dit handboek is het leren over de terminal waarin u alle commando’s zal uitvoeren en waar de magie gebeurt. U kunt de terminal zoeken door de “windows”-toets in te drukken en “terminal” te typen. U kunt de Terminal vastmaken in de dock waar andere apps zijn geplaatst voor gemakkelijke toegang.
💡 Het sneltoets voor het openen van de terminal is
ctrl+alt+t
U kunt de terminal ook vanuit een map openen. Klik met de rechtsmuis op de plek waar u zich bevindt en kies “Open in Terminal”. Dit zal de terminal openen in dezelfde pad.
Hoe Linux te gebruiken op een Windows-machine
Soms moet u misschien Linux en Windows side by side laten draaien. Gelukkig zijn er enkele manieren om het beste van beide werelden te krijgen zonder aparte computers voor elk besturingssysteem te kopen.
In dit gedeelte zult u enkele manieren ontdekken hoe u Linux op een Windows-machine kunt gebruiken. Sommige ervan zijn browsergebaseerd of cloudgebaseerd en vereisen geen OS-installatie voordat u ze kunt gebruiken.
Optie 1: “Dual-boot” Linux + Windows Met dual boot kan je Linux naast Windows op je computer installeren, zodat je bij het opstarten kan kiezen welk besturingssysteem je wilt gebruiken.
Hiervoor moet je je harde schijf partitioneren en Linux op een aparte partitie installeren. Met deze methode kun je slechts één besturingssysteem tegelijk gebruiken.
Optie 2: Gebruik Windows Subsystem for Linux (WSL) Windows Subsystem for Linux biedt een compatibiliteitslaag waarmee je Linux binaire uitvoerbare bestanden rechtstreeks op Windows kunt uitvoeren.
WSL gebruiken heeft enkele voordelen. De installatie van WSL is eenvoudig en niet tijdverrijdend. Het is lichter dan virtuele machines waarbij je resources van de gastheer machine moet toewijzen. Je hoeft geen ISO of virtuele schijfimage voor Linux machines te installeren, die vaak grote bestanden zijn. Je kunt Windows en Linux naast elkaar gebruiken.
Hoe WSL2 te installeren
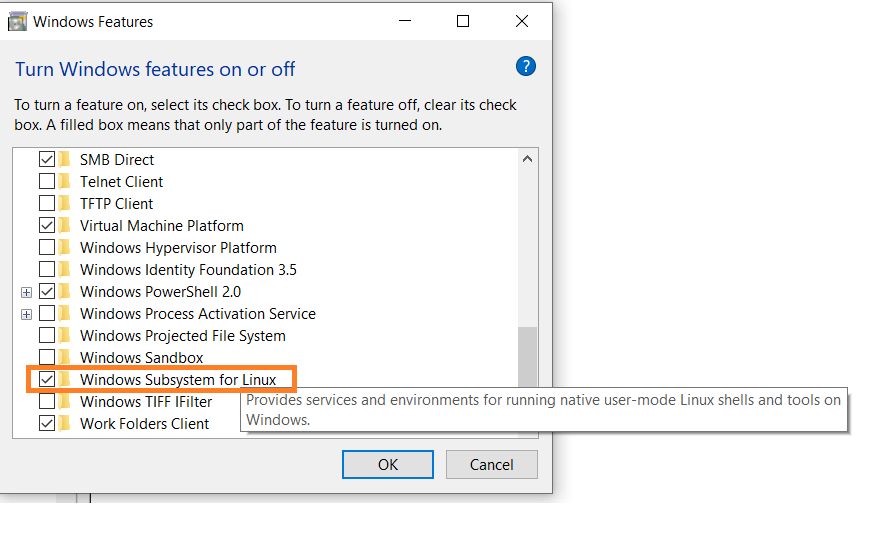
Als eerste, schakel de optie Windows Subsystem for Linux in de instellingen in.
-
Ga naar Start. Zoek naar “Windowsfuncties aan- of uitzetten.”
-
Controleer de optie “Windows Subsystem for Linux” als deze nog niet geselecteerd is.
-
Vervolgens, open je het opdrachtvenster en voer je de installatieopdrachten in.
-
Open Command Prompt als beheerder:

-
Voer de onderstaande opdracht uit:
wsl --install
Dit is het resultaat:
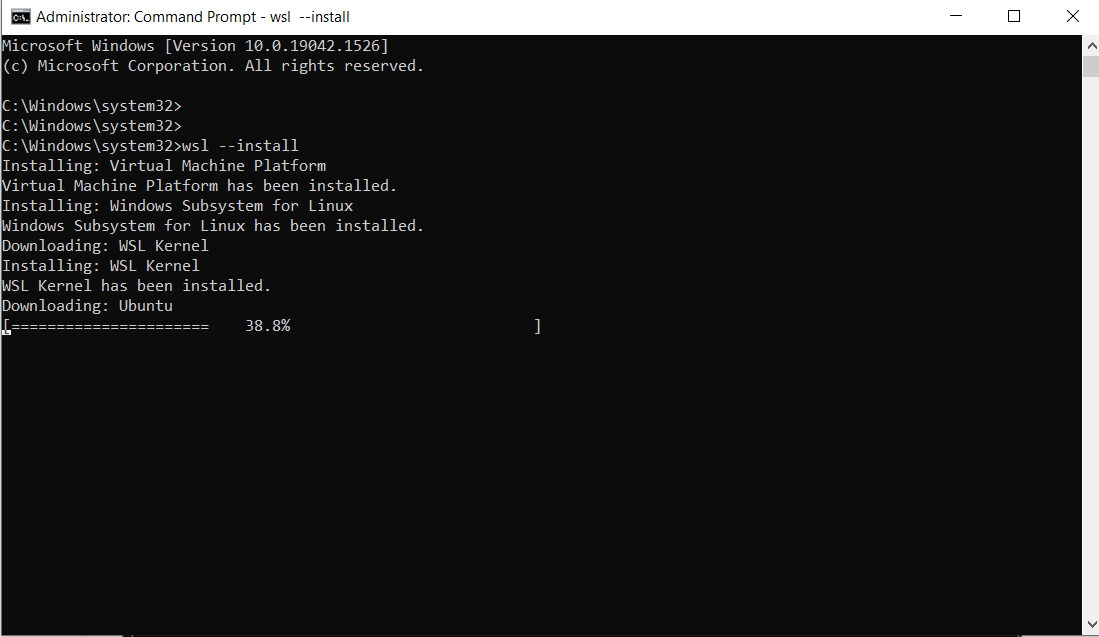
Opmerking: Standaard wordt Ubuntu geïnstalleerd.
- Nadat de installatie voltooid is, moet u uw Windows-machine herstarten. Start dus uw Windows-machine opnieuw.
Na de herstart zou u misschien een venster zoals dit kunnen zien:
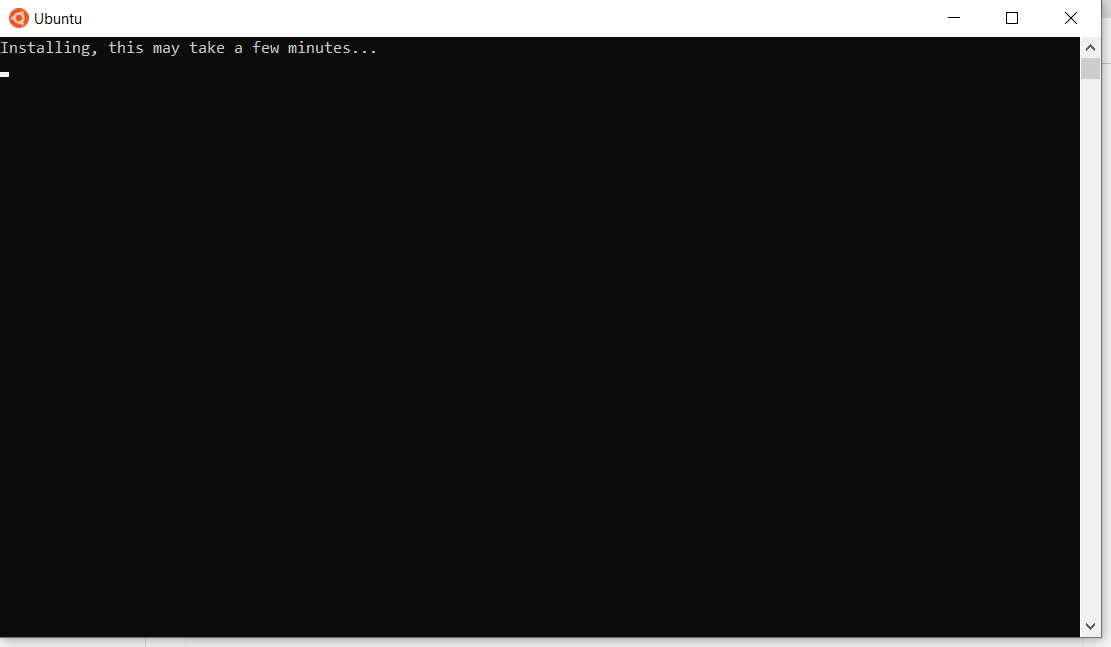
Nadat de installatie van Ubuntu voltooid is, wordt u gevraagd uw gebruikersnaam en wachtwoord in te geven.

En dat is het! U bent klaar om Ubuntu te gebruiken.
Start Ubuntu door het zoekmenu te gebruiken.
En hier hebben we uw Ubuntu-instantie gelanceerd.

Optie 3: Gebruik een virtuele machine (VM)
Een virtuele machine (VM) is een software-emulatie van een fysieke computerinstallatie. Het laat u toe om meerdere besturingssystemen en toepassingen tegelijkertijd op één fysieke machine te draaien.
U kunt virtualisatiesoftware zoals Oracle VirtualBox of VMware gebruiken om een virtuele machine te maken die Linux draait binnen uw Windows-omgeving. Dit maakt het mogelijk om Linux als gastbesturingssysteem parallel aan Windows te draaien.
VM-software biedt opties om hardwarebronnen toe te kennen en te beheren voor elke VM, inclusief CPU-kernen, geheugen, schijfruimte en netwerkbandbreedte. U kunt deze toewijzingen aanpassen op basis van de vereisten van de gastbesturingssystemen en toepassingen.
Hier zijn enkele veelvoorkomende opties beschikbaar voor virtualisatie:
Optie 4: Gebruik een op browser gebaseerde oplossing
Op browser gebaseerde oplossingen zijn vooral handig voor snel testen, leren of toegang tot Linux-omgevingen van apparaten die geen Linux hebben geïnstalleerd.
U kunt gebruik maken van online code-editors of webgebaseerde terminals voor toegang tot Linux. Let op dat u meestal geen volledige beheerdersrechten hebt in deze gevallen.
Online code editors
Online code editors bieden editors met ingebouwde Linux terminals. Hoewel hun hoofddoel code maken is, kunt u de Linux-terminal ook gebruiken om commando’s uit te voeren en taken uit te voeren.
Replit is een voorbeeld van een online code editor, waar je tegelijkertijd je code kunt schrijven en toegang hebt tot de Linux-shell.
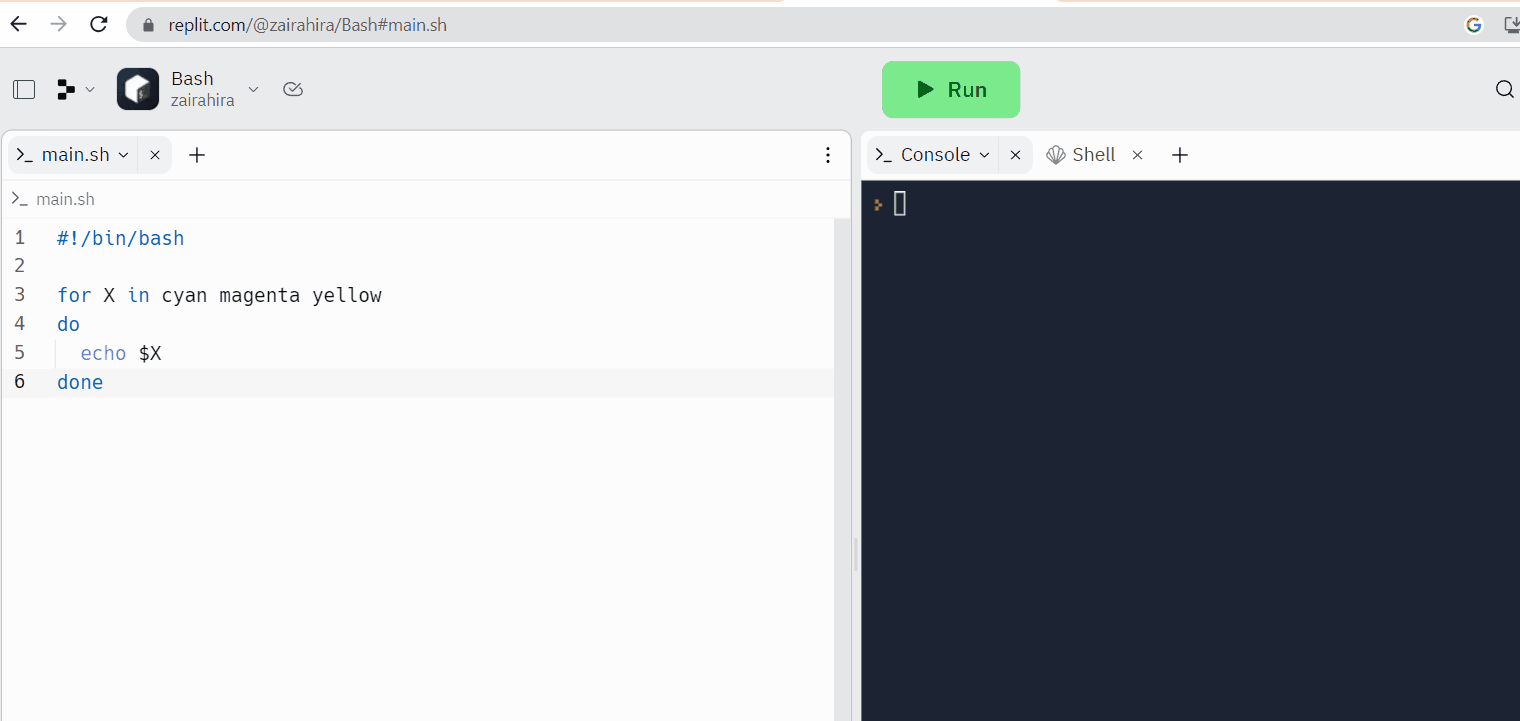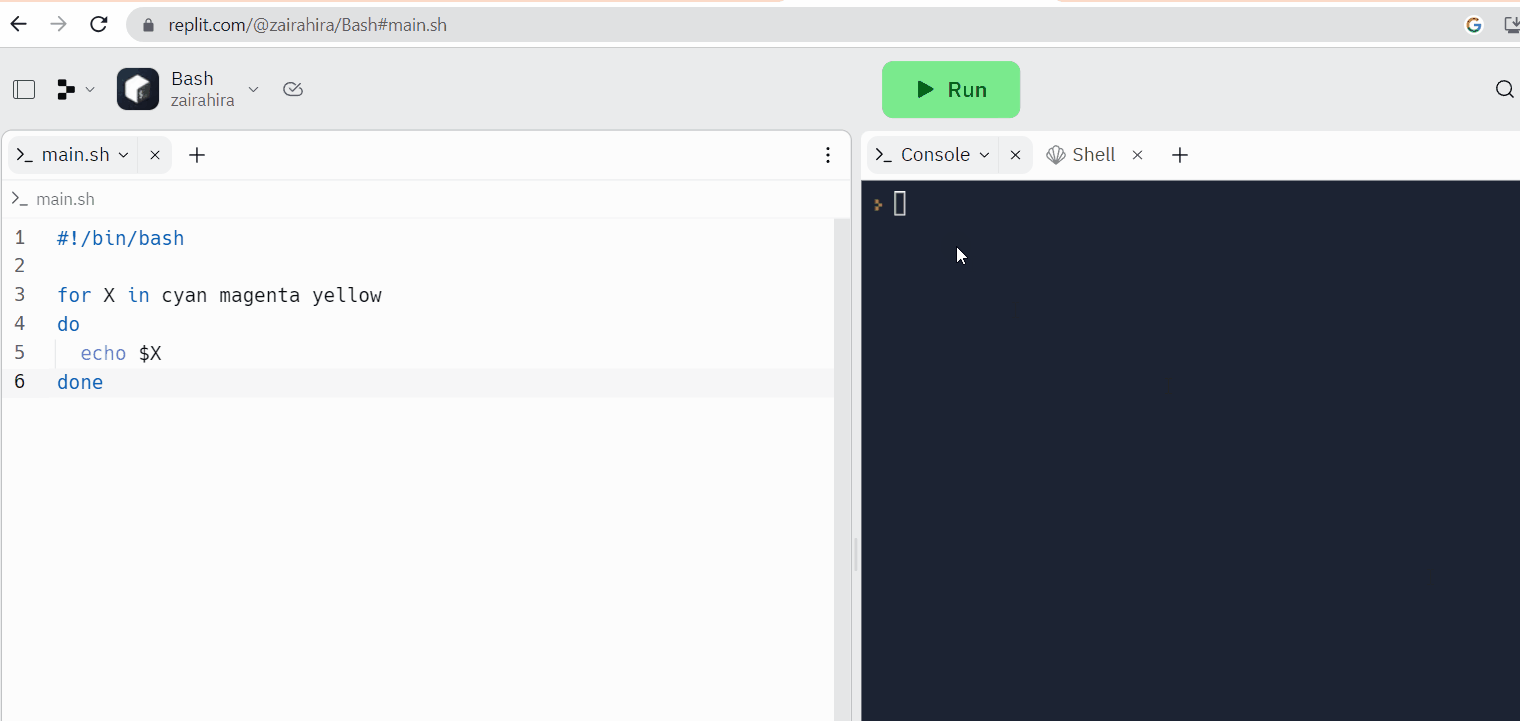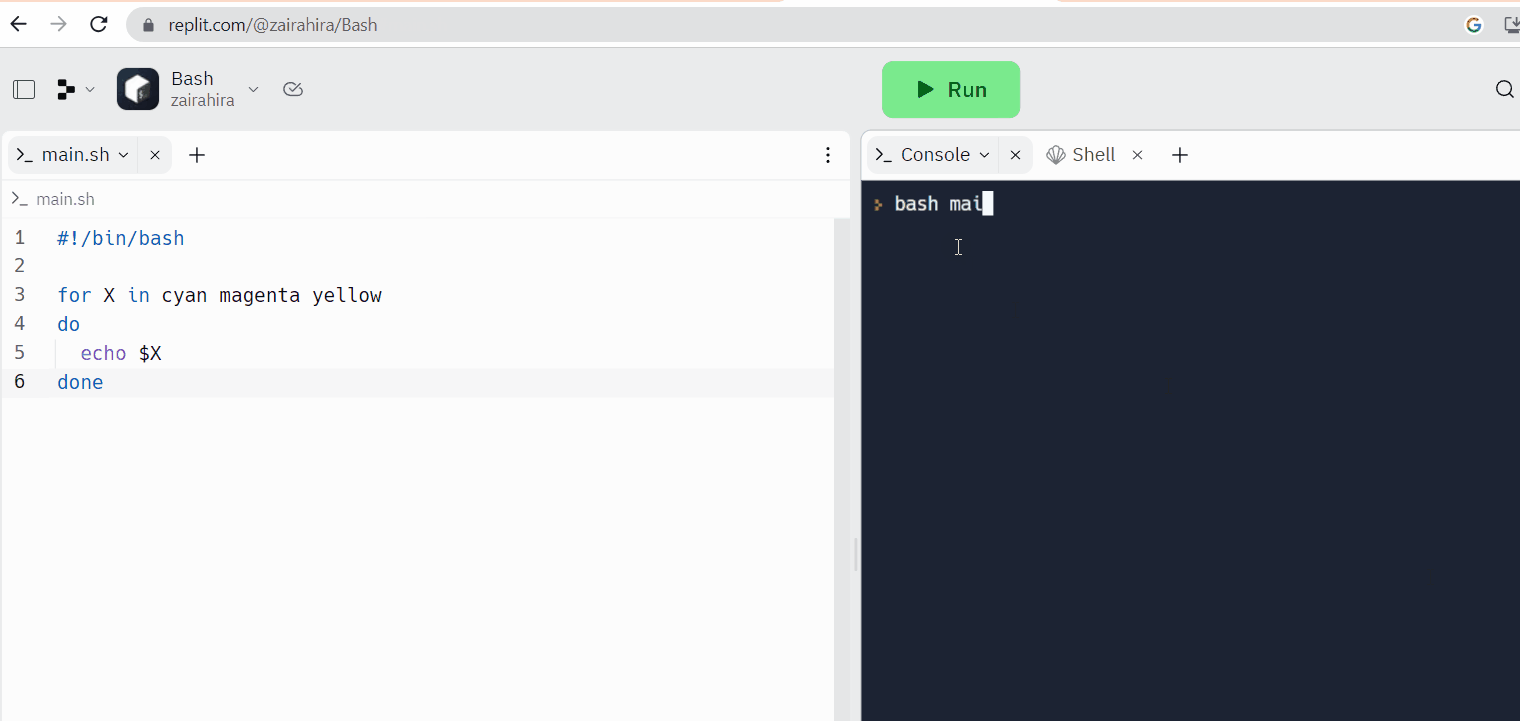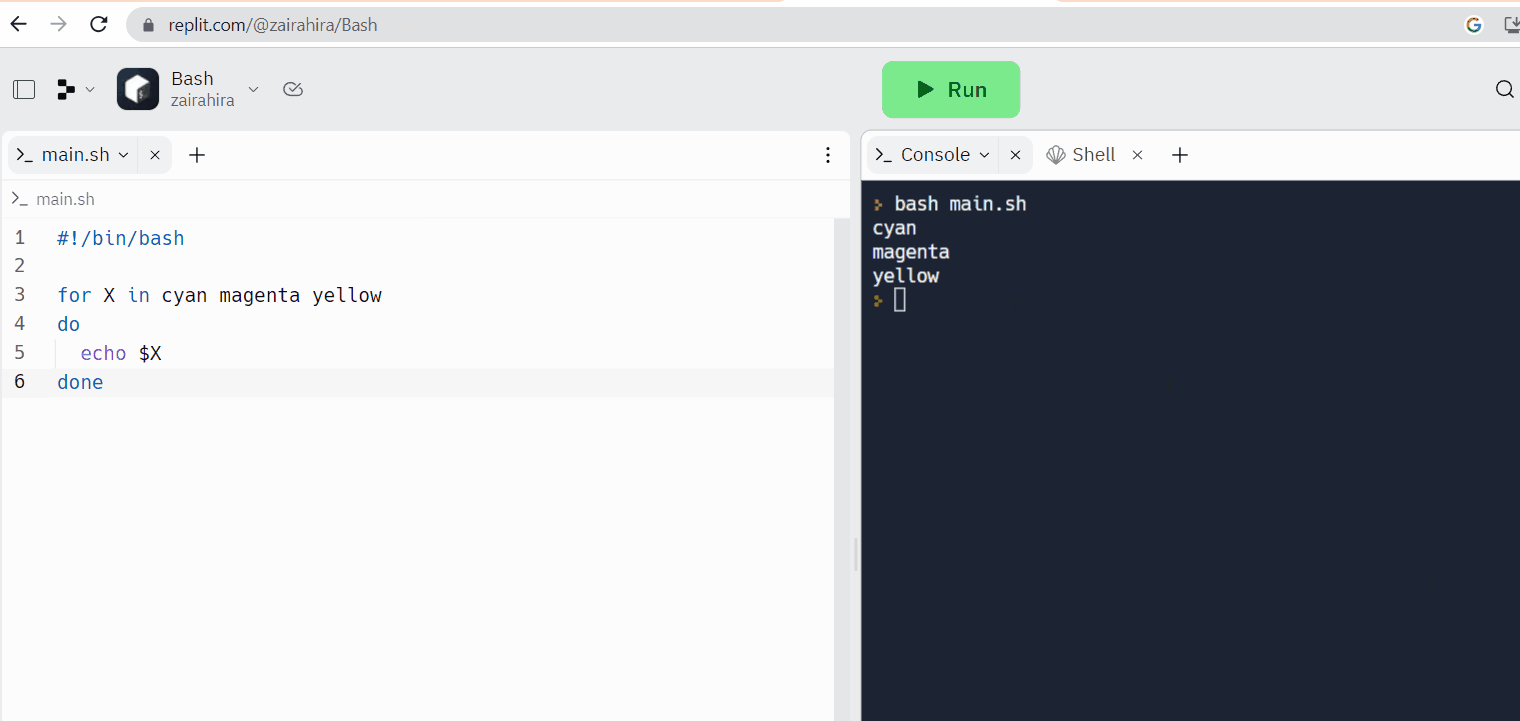
Web-gebaseerde Linux terminals:
Online Linux-terminals bieden direct toegang tot een Linux-opdrachtregelinterface vanuit uw browser. Deze terminals bieden een webgebaseerde interface naar een Linux-shell, zodat u commando’s kunt uitvoeren en werken met Linux-hulpprogramma’s.
Een dergelijk voorbeeld is JSLinux. Onderstaand schermbeeld toont een direct te gebruiken Linux-omgeving:
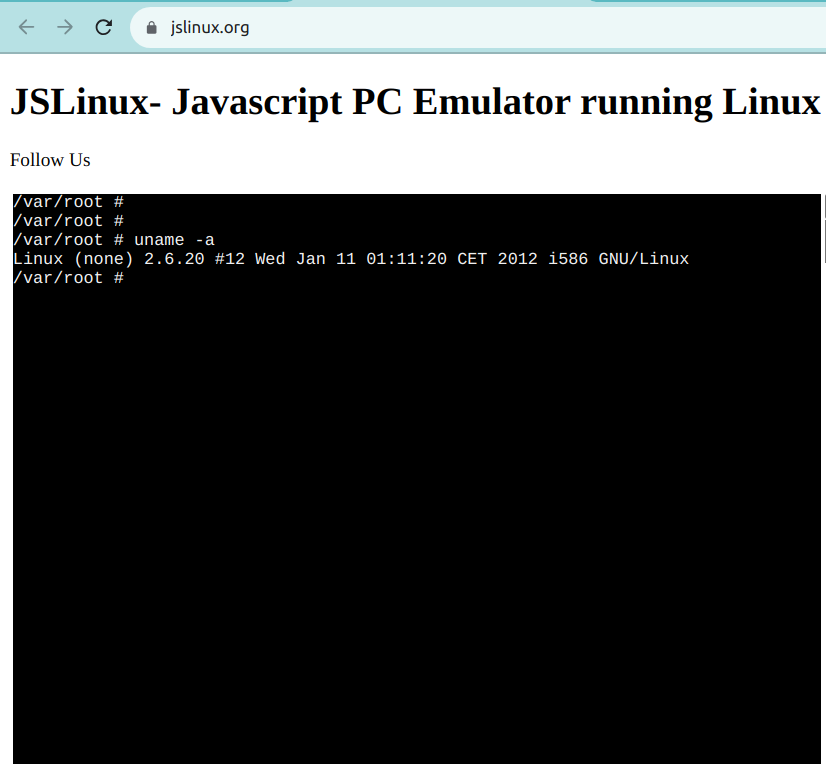
Optie 5: Gebruik een cloudgebaseerde oplossing
In plaats van Linux direct op uw Windows-machine te draaien, kunt u overwegen om cloudgebaseerde Linux-omgevingen of virtuele private servers (VPS) te gebruiken om vanaf afstand toegang te krijgen en te werken met Linux.
Diensten zoals Amazon EC2, Microsoft Azure of DigitalOcean bieden Linux-instanties waarmee u vanaf uw Windows-computer kunt verbinden. Let op dat sommige van deze diensten gratis niveau’s bieden, maar zij zijn meestal niet langdurig gratis.
Deel 2: Introductie tot de Bash Shell en systeemcommando’s
2.1. Aan de slag met de Bash shell
Introductie tot de Bash shell
De Linux-opdrachtregel wordt geleverd door een programma genaamd de shell. Door de jaren heen is het shell-programma geëvolueerd om aan verschillende opties te voldoen.
Verschillende gebruikers kunnen worden geconfigureerd om verschillende shells te gebruiken. Maar de meeste gebruikers houden er liever vast aan de huidige standaardshell te gebruiken. De standaardshell voor veel Linux-distributies is de GNU Bourne-Again Shell (bash). Bash is de opvolger van de Bourne shell (sh).
Om uit te vinden welke shell u momenteel gebruikt, open uw terminal en voer het volgende commando in:
echo $SHELL
Commandobreakdown:
-
Het commando
echowordt gebruikt om op de terminal af te drukken. -
De
$SHELLis een speciale variabele die de naam van de huidige shell bevat.
In mijn setup is de uitvoer /bin/bash. Dit betekent dat ik de bash-shell gebruik.
# uitvoer
echo $SHELL
/bin/bash
Bash is zeer krachtig omdat het bepaalde bewerkingen kan vereenvoudigen die moeilijk efficient uit te voeren zijn met een GUI (of Grafische Gebruikersinterface). Onthoud dat de meeste servers geen GUI hebben en het beste is om te leren gebruik te maken van de mogelijkheden van een opdrachtregelinterface (CLI).
Terminal vs Shell
De termen “terminal” en “shell” worden vaak door elkaar gebruikt, maar ze verwijzen naar verschillende delen van de opdrachtregelinterface.
Het terminal is de interface die u gebruikt om met de shell te interageren. De shell is de commando-interpreter die uw commando’s verwerkt en uitvoert. U zult meer over shells leren in deel 6 van de handleiding.
Wat is een prompt?
Wanneer een shell interactief wordt gebruikt, toont het een $ wanneer het een commando van de gebruiker wacht. Dit wordt de shell-prompt genoemd.
[username@host ~]$
Als de shell wordt uitgevoerd als root (u zult later meer leren over de root-gebruiker), wordt de prompt veranderd in #.
[root@host ~]#
2.2. Commandostructuur
Een commando is een programma dat een specifieke bewerking uitvoert. Zodra u toegang heeft tot de shell, kunt u elk commando invoer na de $ tekens zien en de uitvoer op het terminal.
Genereel gezien volgen Linux-commandos deze syntaxis:
command [options] [arguments]
Hier is het onderdeel van de bovengenoemde syntaxis:
-
command: Dit is de naam van het commando dat u wilt uitvoeren.ls(lijst),cp(kopieer) enrm(verwijder) zijn algemene Linux-commandos. -
[opties]
: Opties, of vlaggen, worden vaak voorafgegaan door een streep (-) of een dubbele streep (–) en veranderen het gedrag van de opdracht. Ze kunnen hoe de opdracht werkt veranderen. Bijvoorbeeld,
ls -a
gebruikt de optie
-a
om verborgen bestanden in het huidige directory weer te geven.
-
[argumenten]: Argumenten zijn de invoer voor de opdrachten die dit nodig hebben. Dit kunnen bestandsnamen, gebruikersnamen of andere gegevens zijn die de opdracht zal aanpassen. Bijvoorbeeld, in de opdrachtcat access.log, iscatde opdracht enaccess.logde invoer. Als resultaat, decatopdracht toont de inhoud van het bestandaccess.log.
Opties en argumenten zijn niet verplicht voor alle opdrachten. Sommige opdrachten kunnen worden uitgevoerd zonder enige opties of argumenten, terwijl anderen misschien een of beide nodig hebben om correct te functioneren. U kunt altijd naar de handleiding van de opdracht blijven om de ondersteunde opties en argumenten te controleren.
💡Tip: U kunt de handleiding van een commando bekijken door de `man`-opdracht te gebruiken.
U kunt de handleiding van de `ls`-opdracht opvragen met `man ls`, en ziet het er ongeveer zo uit:

Handleidingpagina’s zijn een uitstekende en snelle manier om de documentatie te raadplegen. Ik adviseer u erg om de man-pagina’s van de meest gebruikte commando’s door te nemen.
2.3. Bash-commando’s en toetsenbordtoetsen
Als u zich in de terminal bevindt, kunt u uw taken versnellen door middel van toetsenbordtoetsen.
Hier zijn enkele van de meest voorkomende terminaltoetsen:
| Bewerking | Toetsenbordtoets |
| Zoek naar het vorige commando | Pijl omhoog |
| Ga naar het begin van het vorige woord | Ctrl+Pijl links |
| Wis karakters van de cursor tot en met de einde van de commandolijn | Ctrl+K |
| Complete commando’s, bestandsnamen en opties | Druk op Tab |
| Ga naar het begin van de commandolijn | Ctrl+A |
| Laat de lijst van eerdere commando’s zien | history |
2.4. Uitschakelen van uw identiteit: De `whoami`-opdracht
U kunt de gebruikersnaam bekijken die u met behulp van de `whoami`-opdracht bent ingelogd. Deze opdracht is handig als u tussen verschillende gebruikers gaat wisselen en de huidige gebruiker wilt controleren.
Typ net na de `$`-teken `whoami` en druk op Enter.
whoami
Dit is de uitvoer die ik kreeg.
zaira@zaira-ThinkPad:~$ whoami
zaira
Deel 3: Uw Linux-systeem begrijpen
3.1. Uw besturingssysteem en specificaties ontdekken
Systeeminformatie afdrukken met het uname-commando
U kunt gedetailleerde systeeminformatie krijgen van het uname-commando.
Wanneer u de optie -a opgeeft, worden alle systeeminformatie afgedrukt.
uname -a
# uitvoer
Linux zaira 6.5.0-21-generic #21~22.04.1-Ubuntu SMP PREEMPT_DYNAMIC vr 9 feb 13:32:52 UTC 2 x86_64 x86_64 x86_64 GNU/Linux
In de bovenstaande uitvoer,
-
Linux: Geeft het besturingssysteem aan. -
zaira: Vertegenwoordigt de hostname van de machine. -
6.5.0-21-generic #21~22.04.1-Ubuntu SMP PREEMPT_DYNAMIC vr 9 feb 13:32:52 UTC 2: Biedt informatie over de kernelversie, bouwdatum en enkele aanvullende details. -
x86_64 x86_64 x86_64: Geeft de architectuur van het systeem aan. -
GNU/Linux: Vertegenwoordigt het type besturingssysteem.
Vind details van de CPU-architectuur met behulp van de lscpu-commando
Het lscpu-commando in Linux wordt gebruikt om informatie te tonen over de CPU-architectuur. Wanneer je lscpu in de terminal uitvoert, levert het details op zoals:
-
De architectuur van de CPU (bijvoorbeeld, x86_64)
-
CPU-modi (bijvoorbeeld, 32-bit, 64-bit)
-
Byte-orders (bijvoorbeeld, Little Endian)
-
CPU’s (aantal CPU’s), enzovoort
Laten we het eens uitproberen:
lscpu
# uitvoer
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 48 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 12
On-line CPU(s) list: 0-11
Vendor ID: AuthenticAMD
Model name: AMD Ryzen 5 5500U with Radeon Graphics
Thread(s) per core: 2
Core(s) per socket: 6
Socket(s): 1
Stepping: 1
CPU max MHz: 4056.0000
CPU min MHz: 400.0000
Dat was een heleboel informatie, maar ook nuttig! Onthoud dat je altijd de relevante informatie kunt doorbladeren met behulp van specifieke vlaggen. Bekijk het commando-handleiding met man lscpu.
Deel 4: Bestanden Beheren Vanaf de Opdrachtregel
4.1. Het Linux Bestandsysteemhierarchie
alle bestanden in Linux worden opgeslagen in een bestandsysteem. Het volgt een omgekeerd bomenstructuur omdat de root bovenaan ligt.
Het / is de rootmap en het beginpunt van het bestandsysteem. De rootmap bevat alle andere mappen en bestanden op het systeem. Het /-teken dient ook als directory-scheidingsteken tussen padnamen. Bijvoorbeeld, /home/alice vormt een volledig pad.
Hieronder wordt de complete bestandsysteemhiërarchie getoond. Elk directory dienst een specifieke doelstelling.
Merk op dat dit geen uitgebreide lijst is en dat verschillende distributies mogelijk andere configuraties hebben.
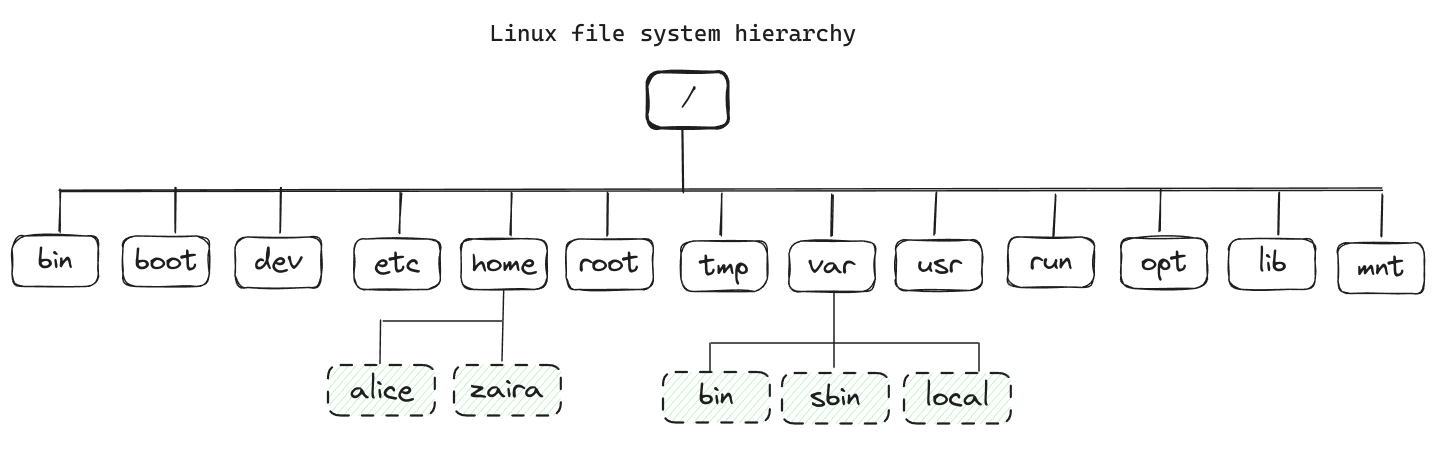
Hieronder volgt een tabel die de doelstelling van elk directory weergeeft:
| Locatie | Doelstelling |
| /bin | Essentiële commandobinaries |
| /boot | Statische bestanden van de bootloader, nodig om het opstartproces te starten. |
| /etc | Specifieke hostconfiguraties |
| /home | Gebruikersthuismap |
| /root | Thuismap voor de beheerdersaccount |
| /lib | Essentiële gedeelde bibliotheken en kernelmodules |
| /mnt | Mountpunten voor tijdelijke mounts |
| /opt | Add-on toepassingssoftwarepakketten |
| /usr | Geïnstalleerde software en gedeelde bibliotheken |
| /var | Variabel data dat ook tussen opstarten bestaat |
| /tmp | Tijdelijke bestanden beschikbaar voor alle gebruikers |
💡 Tip: U kunt meer leren over het bestandsysteem met behulp van de man hier opdracht.
U kunt uw bestandsysteem controleren met de tree -d -L 1 opdracht. U kunt de -L vlag wijzigen om de diepte van het bomen te veranderen.
tree -d -L 1
# uitvoer
.
├── bin -> usr/bin
├── boot
├── cdrom
├── data
├── dev
├── etc
├── home
├── lib -> usr/lib
├── lib32 -> usr/lib32
├── lib64 -> usr/lib64
├── libx32 -> usr/libx32
├── lost+found
├── media
├── mnt
├── opt
├── proc
├── root
├── run
├── sbin -> usr/sbin
├── snap
├── srv
├── sys
├── tmp
├── usr
└── var
25 directories
Deze lijst is niet uitputtend en verschillende distributies en systemen kunnen verschillend geconfigureerd zijn.
4.2. Navigeren door het Linux-bestandsysteem
Absoluut pad vs relatief pad
Het absolute pad is het volledige pad vanaf de root-map naar het bestand of de map. Het begint altijd met een /. Bijvoorbeeld, /home/john/documents.
Het relatieve pad daarentegen is het pad vanaf de huidige map naar de bestemmingsmap of bestand. Het begint niet met een /. Bijvoorbeeld, documents/work/project.
Uw huidige map vinden met het pwd-commando
Het is gemakkelijk om in het Linux-bestandsysteem verdwaald te raken, vooral als u nieuw bent bij de opdrachtprompt. U kunt uw huidige map vinden met het pwd-commando.
Hier is een voorbeeld:
pwd
# uitvoer
/home/zaira/scripts/python/free-mem.py
Maps wijzigen met het cd-commando
De opdracht om te wijzigen van map is cd en staat voor “change directory”. U kunt het cd-commando gebruiken om naar een andere map te navigeren.
U kunt een relatief pad of een absoluut pad gebruiken.
Bijvoorbeeld, als u de onderstaande bestandsstructuur wilt navigeren (volgens de rode lijnen):
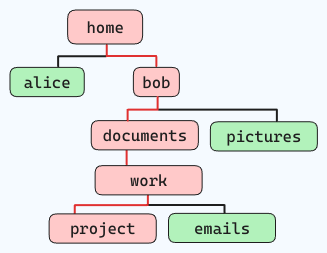
en u staat in “home”, zou de opdracht als volgt zijn:
cd home/bob/documents/work/project
Enkele andere vaak gebruikte cd-snelkoppelingen zijn:
| Opdracht | Omschrijving |
cd .. |
Ga één map terug |
cd ../.. |
Ga twee mappen terug |
cd of cd ~ |
Ga naar de thuismap |
cd - |
Ga naar de vorige pad |
4.3. Beheren van bestanden en mappen
Bij het werken met bestanden en mappen wil je mogelijk bestanden en mappen kopiëren, verplaatsen, verwijderen en nieuwe aanmaken. Hier zijn enkele opdrachten die je hierbij kunnen helpen.
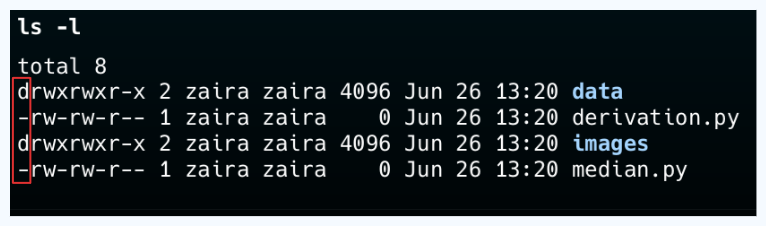
💡Tip: Je kunt onderscheid maken tussen een bestand en een map door te kijken naar de eerste letter in de uitvoer van ls -l. Een '-' representeert een bestand en een 'd' representeert een map.
Aanmaken van nieuwe mappen met de mkdir opdracht
Je kunt een lege map aanmaken met de mkdir opdracht.
# maakt een lege map genaamd "foo" in de huidige map
mkdir foo
Je kunt ook mappen recursief aanmaken met de -p optie.
mkdir -p tools/index/helper-scripts
# uitvoer van tree
.
└── tools
└── index
└── helper-scripts
3 directories, 0 files
Aanmaken van nieuwe bestanden met de touch opdracht
De touch opdracht maakt een leeg bestand. Je kunt het gebruiken als volgt:
# maakt een leeg bestand "file.txt" in de huidige map
touch file.txt
Bestandsnamen kunnen achter elkaar worden gezet als je meerdere bestanden in één opdracht wilt aanmaken.
# maakt lege bestanden "file1.txt", "file2.txt" en "file3.txt" aan in de huidige map
touch file1.txt file2.txt file3.txt
Bestanden en mappen verwijderen met de命令en rm en rmdir
U kunt de命令 rm gebruiken om zowel bestanden als niet-lege mappen te verwijderen.
| 命令 | Omschrijving |
rm file.txt |
Verwijdert het bestand file.txt |
rm -r directory |
Verwijdert de map directory en zijn inhoud |
rm -f file.txt |
Verwijdert het bestand file.txt zonder een bevestiging te vragen |
rmdir directory |
Verwijdert een lege map |
🛑 Merk op dat u de vlag -f moet gebruiken met voorzichtigheid aangezien u geen verzoek tot bevestiging krijgt voordat een bestand wordt verwijderd. Ook moet u voorzichtig zijn met het uitvoeren van rm-commando’s in de root-map, want dit kan resulteren in het verwijderen van belangrijke systeembestanden.
Bestanden kopiëren met de命令 cp
Om bestanden te kopiëren in Linux, gebruikt u de命令 cp.
- Syntaxis om bestanden te kopiëren:
cp source_file bestemming_van_bestand
Deze命令 kopieert het bestand file1.txt naar een nieuwe locatie /home/adam/logs.
cp file1.txt /home/adam/logs
De命令 cp maakt ook een kopie van één bestand met de gegeven naam.
This command copies a file genaamd file1.txt naar een andere file genaamd file2.txt in dezelfde map.
cp file1.txt file2.txt
Verplaatsen en hernoemen van bestanden en mappen met behulp van het mv commando
Het mv commando wordt gebruikt om bestanden en mappen van de ene map naar de andere te verplaatsen.
Syntax om bestanden te verplaatsen:mv bronbestand doelmap
Voorbeeld: Verplaats een bestand genaamd file1.txt naar een map genaamd backup:
mv file1.txt backup/
Om een map en zijn inhoud te verplaatsen:
mv dir1/ backup/
Hernoemen van bestanden en mappen in Linux gebeurt ook met het mv commando.
Syntax om bestanden te hernoemen:mv oudenaam nieuwnaam
Voorbeeld: Hernoem een bestand van file1.txt naar file2.txt:
mv file1.txt file2.txt
Hernoem een map van dir1 naar dir2:
mv dir1 dir2
4.4. Zoeken naar Bestanden en Mappen Met het find Commando
Het find commando laat u efficiënt zoeken naar bestanden, mappen, en tekens en blokapparaten.
Hieronder staat de basis syntax van het find commando:
find /path/ -type f -name file-to-search
Waarbij,
-
/padhet pad is waar het bestand verwacht wordt te worden gevonden. Dit is het startpunt voor het zoeken naar bestanden. Het pad kan ook/of.zijn, die respectievelijk de root en de huidige map vertegenwoordigen. -typevertegenwoordigt de bestandsdescriptors. Ze kunnen elk van onderstaande zijn:
f– Normaal bestand zoals tekstbestanden, afbeeldingen en verborgen bestanden.
d– Map. Deze zijn de mappen die worden overwegen.
l– Symboolische knoop. Symboolische knoopken worden naar bestanden verwijst en zijn vergelijkbaar met korte wegen.
c– Tekstuele apparaten. Bestanden die worden gebruikt om tekstuele apparaten te bereiken worden tekstuele apparaatbestanden genoemd. Stuurprogramma’s communiceren met tekstuele apparaten door tekens (bytes, octets) te versturen en te ontvangen. Voorbeelden zijn keyboards, geluidskaarten en de muis.
b– Blokapparaten. Bestanden die worden gebruikt om toegang te krijgen tot blokapparaten worden blokapparaatbestanden genoemd. Stuurprogramma’s communiceren met blokapparaten door gehele blokken gegevens te versturen en te ontvangen. Voorbeelden zijn USB en CD-ROM.-
-nameis de naam van het bestandstype dat u wilt zoeken.
Hoe bestanden op naam of extensie te zoeken
Suppose we need to find files that contain “style” in their name. We’ll use this command:
find . -type f -name "style*"
#output
./style.css
./styles.css
Now let’s say we want to find files with a particular extension like .html. We’ll modify the command like this:
find . -type f -name "*.html"
# output
./services.html
./blob.html
./index.html
Hoe verborgen bestanden te zoeken
Een punt aan het begin van de bestandsnaam geeft aan dat het een verborgen bestand is. Normaal zijn ze verborgen, maar ze kunnen worden getoond met ls -a in het huidige directory.
We kunnen de find-opdracht aanpassen zoals getoond onderstaand om naar verborgen bestanden te zoeken:
find . -type f -name ".*"
Lijst en vind verborgen bestanden
ls -la
# mapinhoud
total 5
drwxrwxr-x 2 zaira zaira 4096 Mar 26 14:17 .
drwxr-x--- 61 zaira zaira 4096 Mar 26 14:12 ..
-rw-rw-r-- 1 zaira zaira 0 Mar 26 14:17 .bash_history
-rw-rw-r-- 1 zaira zaira 0 Mar 26 14:17 .bash_logout
-rw-rw-r-- 1 zaira zaira 0 Mar 26 14:17 .bashrc
find . -type f -name ".*"
# find-uitvoer
./.bash_logout
./.bashrc
./.bash_history
Hier kunt u een lijst zien van verborgen bestanden in mijn home directory.
Hoe logbestanden en configuratiebestanden te zoeken
Logbestanden hebben meestal de extensie .log en kunnen zo gevonden worden:
find . -type f -name "*.log"
Ook kunnen we configuratiebestanden zoeken:
find . -type f -name "*.conf"
Hoe andere bestanden van type te zoeken
We kunnen karakterblokbestanden zoeken door c aan -type te geven:
find / -type c
Ook kunnen we apparaatblokbestanden vinden door b te gebruiken:
find / -type b
Hoe mappen te zoeken
In het voorbeeld hieronder zoeken we mappen met de vlag -type d.
ls -l
# lijst mapinhoud
drwxrwxr-x 2 zaira zaira 4096 Mar 26 14:22 hosts
-rw-rw-r-- 1 zaira zaira 0 Mar 26 14:23 hosts.txt
drwxrwxr-x 2 zaira zaira 4096 Mar 26 14:22 images
drwxrwxr-x 2 zaira zaira 4096 Mar 26 14:23 style
drwxrwxr-x 2 zaira zaira 4096 Mar 26 14:22 webp
find . -type d
# find directory uitvoer
.
./webp
./images
./style
./hosts
Hoe bestanden van grootte te zoeken
Een uitstekend nuttig gebruik van de find-opdracht is het opslaan van bestanden op basis van een bepaalde grootte.
find / -size +250M
Hier zijn we bestanden die groter zijn dan 250MB opgeslagen.
Andere eenheden zijn:
-
G: GigaBytes. -
M: MegaBytes. -
K: KiloBytes -
c: bytes.
Vervangen met de relevante eenheid.
find <directory> -type f -size +N<Unit Type>
Hoe bestanden opgewijzigdatum te zoeken
Met behulp van de vlag -mtime kun je bestanden en mappen filteren op basis van de wijzigingsdatum.
find /path -name "*.txt" -mtime -10
Bijvoorbeeld,
-
-mtime +10 betekent dat je een bestand zoekt dat 10 dagen geleden is aangepast.
-
-mtime -10 betekent minder dan 10 dagen.
-
-mtime 10 Als je + of – overleeft betekend het exact 10 dagen.
4.5. Basiscommando’s voor het bekijken van bestanden
Concateneer en toon bestanden met de cat-commando
Het cat-commando in Linux wordt gebruikt om de inhoud van een bestand weer te geven. Het kan ook gebruikt worden om bestanden samen te voegen en nieuwe bestanden te maken.
Hier is de basisgrammatica van het cat-commando:
cat [options] [file]
De eenvoudigste manier om cat te gebruiken is zonder opties of argumenten. Dit zal de inhoud van het bestand in de terminal weergeven.
Bijvoorbeeld, als u de inhoud van een bestand wilt bekijken met de naam file.txt, kunt u het volgende commando gebruiken:
cat file.txt
Dit zal de hele inhoud van het bestand direct in de terminal weergeven.
Het bekijken van tekstbestanden interactief met less en more
Terwijl cat de hele bestanden direct weergeeft, bieden less en more de mogelijkheid om de inhoud van een bestand interactief te bekijken. Dit is handig als u door een grote bestand wilt bladeren of specifieke inhoud zoeken.
Het syntaxis van de less-commando is:
less [options] [file]
Het more-commando is vergelijkbaar met less maar heeft minder functies. Het wordt gebruikt om de inhoud van een bestand een scherm per keer weer te geven.
De syntaxis van het more-commando is:
more [options] [file]
Voor beide commando’s kunt u de spatiebalk gebruiken om een pagina naar beneden te scrollen, de Enter-toets om een lijn naar beneden te scrollen, en de q-toets om het viewer af te sluiten.
Om terug te gaan, kunt u de b-toets gebruiken, en om vooruit te gaan kunt u de f-toets gebruiken.
Het weergeven van de laatste delen van bestanden met behulp van tail
Soms moet u misschien alleen de laatste enkele regels van een bestand bekijken in plaats van de gehele bestanden. Het tail-commando in Linux wordt gebruikt om de laatste delen van een bestand weer te geven.
Bijvoorbeeld, tail file.txt zal de laatste 10 regels van het bestand file.txt standaard weergeven.
Als u een andere aantal regels wilt weergeven, kunt u de optie -n gebruiken, gevolgd door het aantal regels dat u wilt weergeven.
# Laatste 50 regels van bestand file.txt weergeven
tail -n 50 file.txt
💡Tip: Een andere toepassing van de tail-optie is de volgen (-f) optie. Deze optie maakt het mogelijk om de inhoud van een bestand te bekijken terwijl het wordt aangemaakt. Dit is een nuttige utility voor het live bekijken en monitoren van logbestanden.
Weergave van de beginnen van bestanden met head
Net zoals tail de laatste delen van een bestand weergeeft, kunt u de head-commando in Linux gebruiken om de beginnen van een bestand weer te geven.
Bijvoorbeeld, head file.txt zal de eerste 10 regels van het bestand file.txt standaard weergeven.
Om het aantal weer te geven te wijzigen, kunt u de optie -n gebruiken, gevolgd door het aantal regels die u wilt weergeven.
Telen van woorden, regels en tekens met wc
U kunt woorden, regels en tekens in een bestand tellen met behulp van de wc-commando.
Bijvoorbeeld, het uitvoeren van wc syslog.log gaf me de volgende uitvoer:
1669 9623 64367 syslog.log
In de bovenstaande uitvoer,
-
1669代表syslog.log文件中的行数。 -
9623代表syslog.log文件中的单词数。 -
64367representeert het aantal tekens in het bestandsyslog.log.
Dus, de opdracht wc syslog.log telde 1669 regels, 9623 woorden, en 64367 tekens in het bestand syslog.log.
Bestanden regelbijregel vergelijken met diff
Vergelijken en verschillen vinden tussen twee bestanden is een algemene taak in Linux. Je kunt twee bestanden rechtstreeks in de opdrachtregel vergelijken met de diff-opdracht.
De basis-syntax van de diff-opdracht is:
diff [options] file1 file2
Hier zijn twee bestanden, hello.py en also-hello.py, die we zullen vergelijken met de diff-opdracht:
# inhoud van hello.py
def greet(name):
return f"Hello, {name}!"
user = input("Enter your name: ")
print(greet(user))
# inhoud van also-hello.py
more also-hello.py
def greet(name):
return fHello, {name}!
user = input(Enter your name: )
print(greet(user))
print("Nice to meet you")
- Controleer of de bestanden hetzelfde zijn of niet
diff -q hello.py also-hello.py
# Output
Files hello.py and also-hello.py differ
- Zie hoe de bestanden verschillen. Voor dat doel kun je het
-u-flag gebruiken om een geünificeerde uitvoer te zien:
diff -u hello.py also-hello.py
--- hello.py 2024-05-24 18:31:29.891690478 +0500
+++ also-hello.py 2024-05-24 18:32:17.207921795 +0500
@@ -3,4 +3,5 @@
user = input(Enter your name: )
print(greet(user))
+print("Nice to meet you")
— hello.py 2024-05-24 18:31:29.891690478 +0500
- In de bovenstaande uitvoer:
--- hello.py 2024-05-24 18:31:29.891690478 +0500duidt op het geleverde bestand en zijn tijdsaanduiding.+++ also-hello.py 2024-05-24 18:32:17.207921795 +0500duidt op het andere bestand dat wordt vergeleken en zijn tijdsaanduiding.@@ -3,4 +3,5 @@toont de regelnummers waar de wijzigingen plaatsvinden. In dit geval duidt het op regel 3 tot 4 in het originele bestand die zijn veranderd in regel 3 tot 5 in het aangepaste bestand.user = input(Enter your name: )is een regel uit het originele bestand.print(greet(user))is een andere regel uit het originele bestand.
+print("Nice to meet you")is de extra regel in het aangepaste bestand.
diff -y hello.py also-hello.py
Om de diff in een side-by-side indeling te zien, kun je de -y vlag gebruiken:
def greet(name): def greet(name):
return fHello, {name}! return fHello, {name}!
user = input(Enter your name: ) user = input(Enter your name: )
print(greet(user)) print(greet(user))
> print("Nice to meet you")
# Uitvoer
- In de uitvoer:
- De lijnen die hetzelfde zijn in beide bestanden worden naast elkaar getoond.
Lijnen die verschillen worden getoond met een >-teken, dat aangeeft dat de lijn alleen in een van de bestanden aanwezig is.
Deel 5: De basis van textbewerking in Linux
Het beheersen van de commandoregel om tekst bij te werken is één van de meest nuttige vaardigheden in Linux. In deze sectie leer je hoe je twee populaire tekstbewerkingsprogramma’s in Linux kunt gebruiken: Vim en Nano.
Ik adviseer je om een van de keuzelijke tekstbewerkers die je vindt te beheersen en eraan vast te blijven. Dat zal je tijd besparen en productie verhogen. Vim en Nano zijn veilige keuzes omdat ze op de meeste Linuxdistributies aanwezig zijn.
5.1. Meestermaken in Vim: De volledige gids
Inleiding tot Vim
- Vim is een populaire tekstbewerkingsgereedschap voor de commandoregel. Vim heeft zijn voordelen: het is krachtig, aanpasbaar en snel. Hier zijn enkele redenen waarom je Vim zou moeten leren:
- De meeste servers worden via een CLI bezocht, dus in systeembeheer heb je niet noodzakelijk de beschikking over een GUI. Maar Vim heeft je voor gezien – het zal altijd aanwezig zijn.
- Vim gebruikt een toetsenbordgerichte benadering, omdat het is ontworpen om zonder muis te worden gebruikt, wat de bewerkingstaken aanzienlijk kan versnellen zodra je de sneltoetsen hebt geleerd. Dit maakt het ook sneller dan GUI-tools.
- Sommige Linux-hulpprogramma’s, zoals het bewerken van cron-taken, werken in hetzelfde bewerkingsformaat als Vim.
Vim is geschikt voor iedereen – beginners en gevorderden. Vim ondersteunt complexe tekenreeksen zoeken, zoeken met markering en nog veel meer. Via plugins biedt Vim uitgebreide mogelijkheden aan ontwikkelaars en systeembeheerders, waaronder code-aanvulling, syntaxisaccentuering, bestandsbeheer, versiebeheer en meer.
Vim heeft twee varianten: Vim (vim) en Vim tiny (vi). Vim tiny is een kleinere versie van Vim die enkele functies van Vim mist.
Hoe te beginnen met vim
vim your-file.txt
Begin met het gebruik van Vim met dit commando:
your-file.txt kan een nieuw bestand zijn of een bestaand bestand dat je wilt bewerken.
Navigeren in Vim: Meester worden van beweging en commando-modi
In de begintijd van de CLI hadden toetsenborden geen pijltjestoetsen. Daarom werd navigatie gedaan met behulp van de beschikbare toetsen, hjkl daarbij één van.
Als toetsenbordgebaseerd programma, kan het gebruik van hjkl-toetsen de tekstbewerkingstaken aanzienlijk versnellen.
Opmerking: Hoewel pijltjestoetsen prima zouden werken, kun je nog steeds experimenteren met hjkl-toetsen om te navigeren. Sommige mensen vinden deze manier van navigeren efficient.

💡Tip: Om de hjkl-volgorde te onthouden, gebruik dit: hang achteruit, jump naar beneden, kick omhoog, leap naar voren.
De drie Vim-modi
- Je moet de 3 werkmodi van Vim kennen en weten hoe je tussen ze kan schakelen. Toetsaanslagen gedragen zich anders in elke commando-modus. De drie modi zijn als volgt:
- Commando-modus.
- Bewerkingsmodus.
Visuele modus.
Commando-modus. Als je Vim start, bevind je je standaard in de commando-modus. Deze modus stelt je in staat om naar andere modi te gaan.
⚠ Om naar andere modi te schakelen, moet je eerst in de commando-modus zijn
Bewerkingsmodus
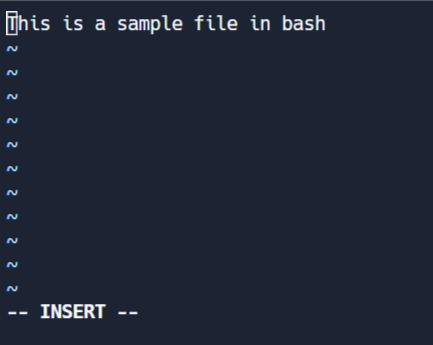
Deze modus laat je wijzigingen aan het bestand maken. Om de bewerkingsmodus te betreden, druk op I terwijl je in de commando-modus bent. Let op de '-- INSERT' schakelaar onderaan het scherm.
Visueel modus
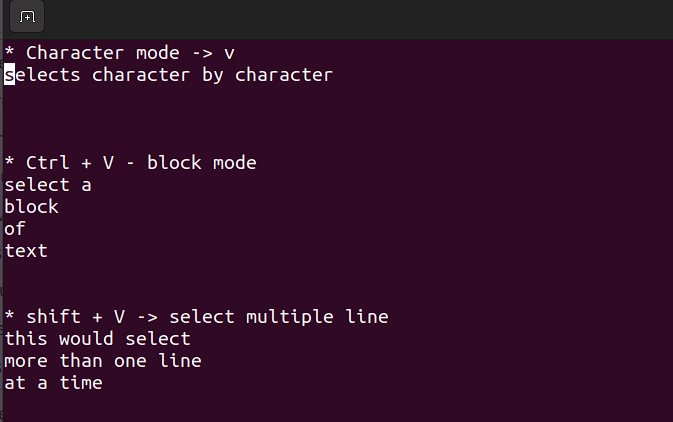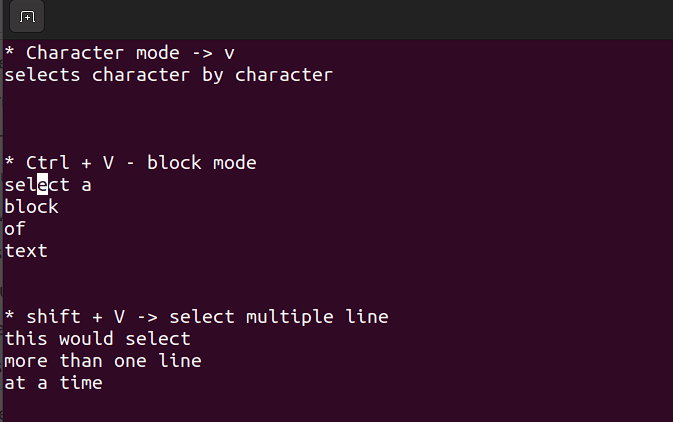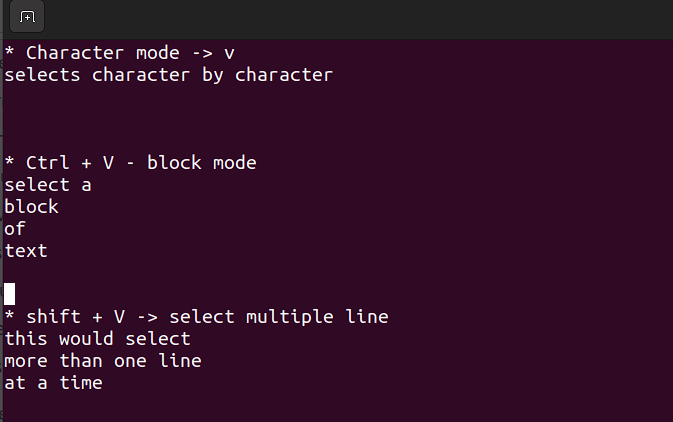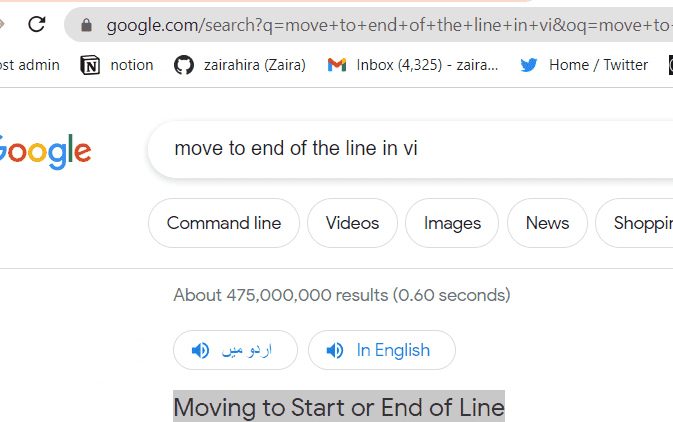
- In deze modus kun je op een enkel teken, een blok tekst of regels tekst werken. Laat ons deze stap voor stap uitleggen. Onthoud, gebruik de volgende combinaties als je in de commandomodus bent.
Shift + V→ Selecteer meerdere regels.Ctrl + V→ Blokmodus
V → Tekenmodus
De visuele modus is handig als je kopiëren en plakken of regels in bulk bewerken moet.
Uitgebreide commandomodus.
De uitgebreide commandomodus laat je uitvoeren van geavanceerde bewerkingen zoals zoeken, instellen van regelnummers en markeren van tekst. We zullen de uitgebreide modus in de volgende sectie behandellen.
Hoe blijf je op de hoogte? Als je je huidige modus vergeet, druk simpelweg ESC twee keer af en je zult terugkeren naar de Commandomodus.
Efficientie bij bewerken in Vim: Kopiëren, plakken en zoeken
1. Hoe te kopiëren en plakken in Vim
- Kopiëren en plakken wordt ‘yanken’ en ‘putten’ genoemd in de termen van Linux. Om te kopiëren/yanken, volg de volgende stappen:
- Selecteer tekst in de visuele modus.
- Druk
'y'op om te kopiëren/yanken.
Huidige positie van de cursor verplaatsen en 'p' drukken.
2. Hoe te zoeken naar tekst in Vim
Elke reeks van strings kan worden doorzocht met Vim door gebruik te maken van de / in commandomode. Om te zoeken, gebruik /string-to-match.
In commandomode, typ :set hls en druk op enter. Zoek gebruik makend van /string-to-match. Dit zal de zoekopdrachten accentueren.
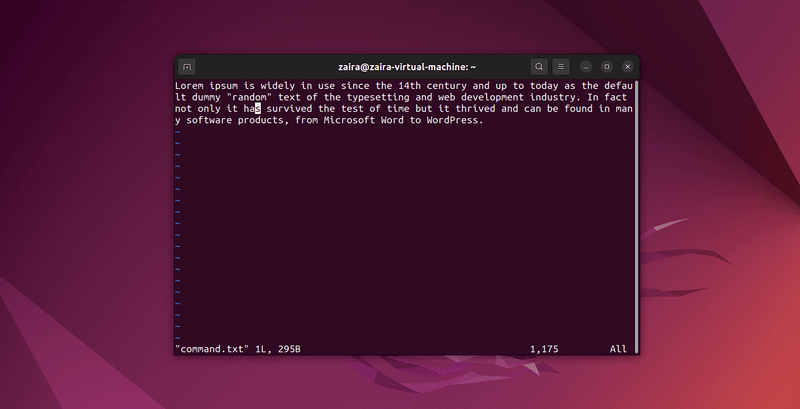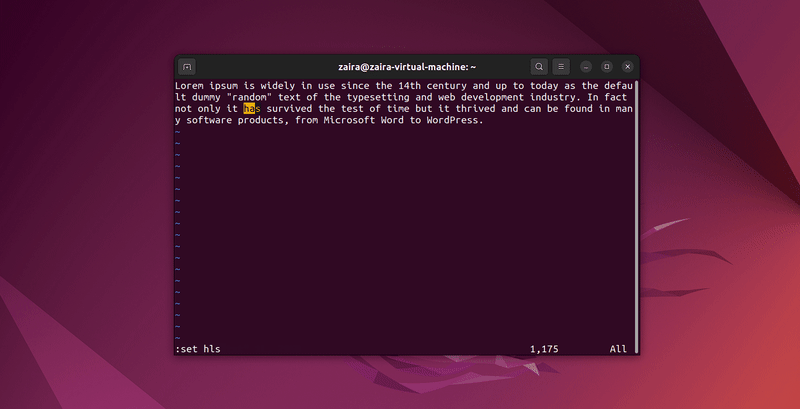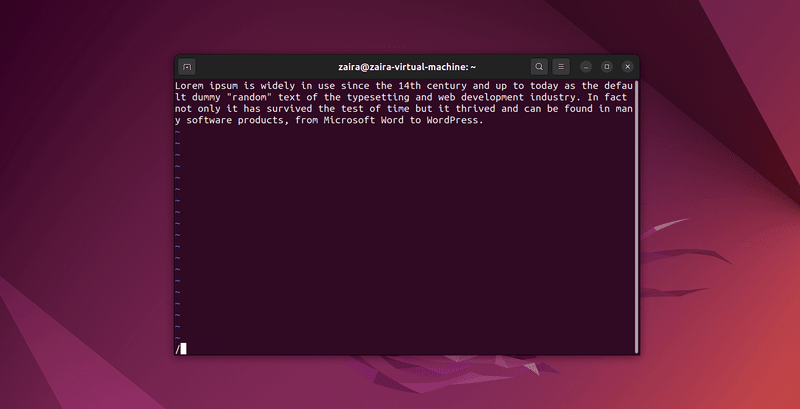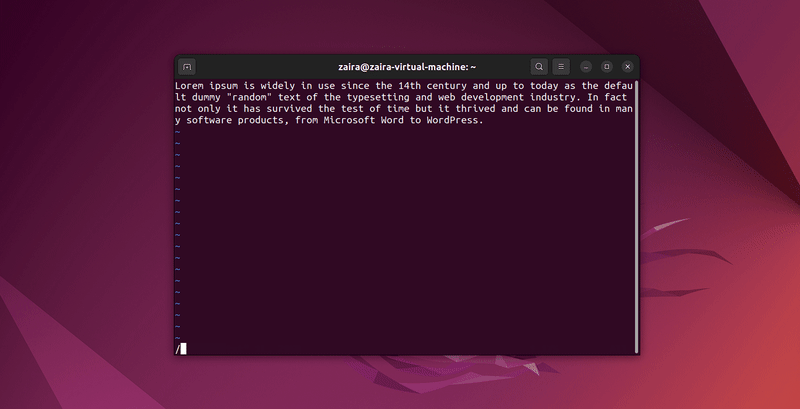
Laten we een paar strings doorzoeken:
3. Hoe Vim te verlaten
- Verander eerst naar commandomode (door twee keer op Escape te drukken) en gebruik dan deze vlaggen:
- Verlaat zonder opslaan →
:q!
Verlaat en sla op → :wq!
Sneltoetsen in Vim: Maak bewerkingen sneller
- Opmerking: Al deze sneltoetsen werken alleen in commandomode.
Ctrl+u: Half pagina naar bovenP: Plakken boven de cursor:%s/old/new/g: Vervang alle optredens vanolddoornewin het bestand:q!: Sluiten zonder opslaan
Ctrl+w gevolgd door h/j/k/l: Navigeren tussen gesplitte vensters
5.2. Meestermaken in Nano
Aan de slag met Nano: de gebruiker-vriendelijke tekstbewerker
Nano is eengebruiker-vriendelijke tekstbewerker die gemakkelijk te gebruiken is en perfect geschikt is voor beginnende gebruikers. Het is vooraf geïnstalleerd op de meeste Linuxdistributies.
nano
Om een nieuw bestand te maken met Nano, gebruikt u het volgende commando:
nano filename
Om te beginnen met bewerken van een bestaand bestand met Nano, gebruikt u het volgende commando:
Lijst van toetsenbindings in Nano
Laten we de belangrijkste toetsenbindings in Nano bestuderen. U zult de toetsenbindings gebruiken om verschillende handelingen uit te voeren zoals opslaan, afsluiten, kopiëren, plakken en meer.
Schrijven naar een bestand en opslaan
Zodra je Nano opent met het nano-commando, kun je beginnen met het schrijven van tekst. Om het bestand op te slaan, druk je op Ctrl+O. Je wordt gevraagd om de bestandsnaam in te voeren. Druk op Enter om het bestand op te slaan.
Afsluiten van nano
Je kunt Nano afsluiten door Ctrl+X in te drukken. Als je niet-opgeslagen wijzigingen hebt, vraagt Nano je om de wijzigingen op te slaan voordat je afsluit.
Kopiëren en plakken
Om een regio te selecteren, gebruik je ALT+A. Er verschijnt een markering. Gebruik de pijltjes om de tekst te selecteren. Zodra geselecteerd, verlaat je de markering met ALT+^.
Om de geselecteerde tekst te kopiëren, druk je op Ctrl+K. Om de gekopieerde tekst te plakken, druk je op Ctrl+U.
Knippen en plakken
Selecteer de regio met ALT+A. Zodra geselecteerd, knip je de tekst met Ctrl+K. Om de geknipte tekst te plakken, druk je op Ctrl+U.
Navigatie
Gebruik Alt \ om naar het begin van het bestand te gaan.
Gebruik Alt / om naar het einde van het bestand te gaan.
Regelnummers bekijken
Wanneer je een bestand opent met nano -l bestandsnaam, kun je regelnummers aan de linkerkant van het bestand bekijken.
Zoeken
Je kunt naar een specifiek regelnummer zoeken met Alt + G. Voer het regelnummer in bij de prompt en druk op Enter.
U kunt ook een zoekopdracht voor een tekenreeks starten met CTRL + W en druk op Enter. Als u naar achteren wilt zoeken, kunt u na het starten van de zoekopdracht met Ctrl+W op Alt+W drukken.
- Samenvatting van toetsenbordtoetsen in Nano
Ctrl+G: Toont de hulptekstCtrl+J: Uitlijnen van het huidige alineaCtrl+V: Scroll omlaag een paginaCtrl+\: Zoeken en vervangen
Alt+E: Laatste ongedane actie herhalen
Deel 6: Bash-scripting
6.1. Definitie van Bash-scripting
Een Bash-script is een bestand dat een reeks commando’s bevat die door de Bash-programma’s uitgevoerd worden, op lijn voor lijn. Het maakt het mogelijk een reeks acties uit te voeren, zoals navigeren naar een specifiek directory, een map aanmaken en een proces met de commandoregel te starten.
Door opdrachten in een script op te slaan, kun je dezelfde reeks stappen meerdere keren herhalen en uitvoeren door het script te draaien.
6.2. Voordelen van Bash Scripting
Bash scripting is een krachtig en veelzijdig hulpmiddel voor het automatiseren van systeembeheer taken, het beheren van systeembronnen, en het uitvoeren van andere routinetaken in Unix/Linux systemen.
- Enkele voordelen van shell scripting zijn:
- Automatisering: Shell scripts stellen je in staat om repetitieve taken en processen te automatiseren, waardoor tijd wordt bespaard en het risico op fouten die kunnen optreden bij handmatige uitvoering wordt verminderd.
- Overdraagbaarheid: Shell scripts kunnen op verschillende platforms en besturingssystemen worden uitgevoerd, waaronder Unix, Linux, macOS en zelfs Windows door het gebruik van emulators of virtuele machines.
- Gevoeligheid: Shellscripts zijn zeer aanpasbaar en kunnen gemakkelijk worden aangepast om specifieke vereisten tegemoet te komen. Ze kunnen ook worden gecombineerd met andere programmeertalen of hulpprogramma’s om meer krachtige scripts te maken.
- Toegankelijkheid: Shellscripts zijn gemakkelijk te schrijven en vereisen geen speciaal gereedschap of software. Ze kunnen worden bijgewerkt met elke tekstbewerker, en de meeste besturingssystemen hebben een ingebouwde shell-interpreter.
- Integratie: Shellscripts kunnen worden geïntegreerd met andere toolsenapplicaties, zoals databases, web servers en cloud services, waardoor meer complexe automatiseringen en systeembeheer taken mogelijk worden.
Debugging: Shellscripts zijn gemakkelijk aan te boren, en de meeste shells hebben ingebouwde debugging- en foutrapportagegereedschappen die kunnen helpen om problemen snel te identificeren en op te lossen.
6.3. Overzicht van Bash Shell en Command Line Interface
De termen “shell” en “bash” worden vaak door elkaar gebruikt. Maar er is een subtiele verschillende tussen de twee.
De term “shell” verwijst naar een programma dat een commandoregelinterface biedt voor interactie met een besturingssysteem. Bash (Bourne-Again SHell) is een van de meest gebruikte Unix/Linux shells en is de standaard shell in veel Linuxdistributies.
Tot nu toe werden de commando’s die u heeft ingevoerd eigenlijk altijd ingevoerd in een “shell”.
Alhoewel Bash een type shell is, zijn er ook andere shells beschikbaar, zoals de Korn shell (ksh), de C shell (csh) en de Z shell (zsh). Elke shell heeft zijn eigen syntaxis en set van functies, maar ze delen allemaal het doel om een commandoregelinterface te bieden voor interactie met het besturingssysteem.
ps
# output:
PID TTY TIME CMD
20506 pts/0 00:00:00 bash <--- the shell type
20931 pts/0 00:00:00 ps
U kunt uw shelltype bepalen met behulp van het ps commando:
In samenvatting, terwijl “shell” een breed begrip is dat verwijst naar elk programma dat een commandoregelinterface biedt, is “Bash” een specifiek type shell dat breed in Unix/Linux systemen wordt gebruikt.
Opmerking: In deze sectie zullen we de “bash” shell gebruiken.
6.4. Hoe u Bash scripts kunt maken en uitvoeren
Scriptbenaming conventies
Volgens de benaming conventie eindigen bash scripts op .sh. Het is echter perfect mogelijk om bash scripts uit te voeren zonder de sh uitbreiding.
Het toevoegen van de Shebang
Bash-scripts beginnen met een shebang. Shebang is een combinatie van bash # en bang ! gevolgd door de pad naar de bash-shell. Dit is de eerste regel van het script. Shebang vertelt de shell om het via de bash-shell uit te voeren. Shebang is eenvoudigweg een absolute pad naar de bash-interpreter.
#!/bin/bash
Hieronder is een voorbeeld van de shebang-aanduiding.
which bash
U kunt het pad van uw bash-shell (dat verschillen kan van bovengenoemd) vinden met de opdracht:
Uw eerste bash-script maken
Ons eerste script vraagt de gebruiker om een pad in te geven. In ruil daarvoor wordt de inhoud getoond.
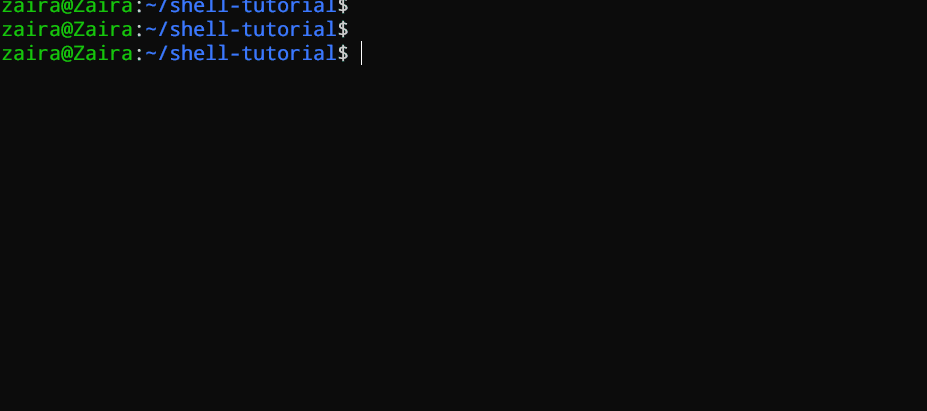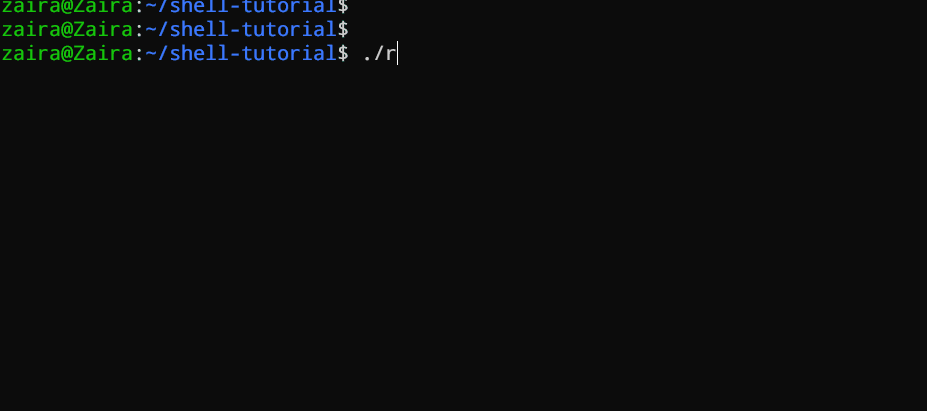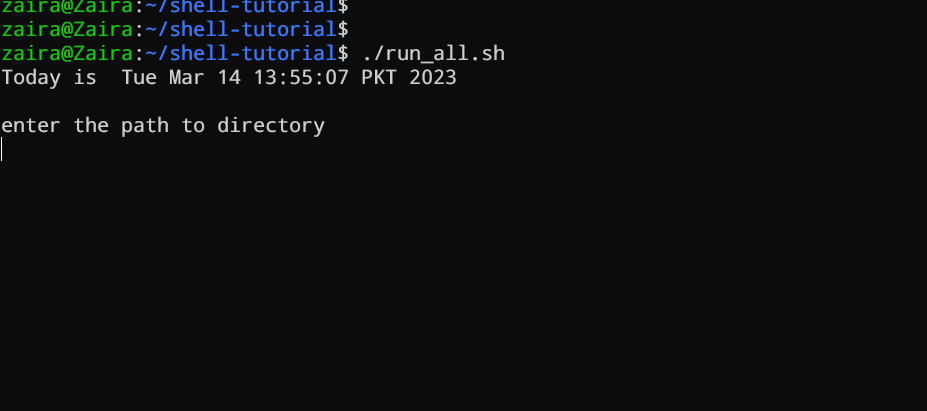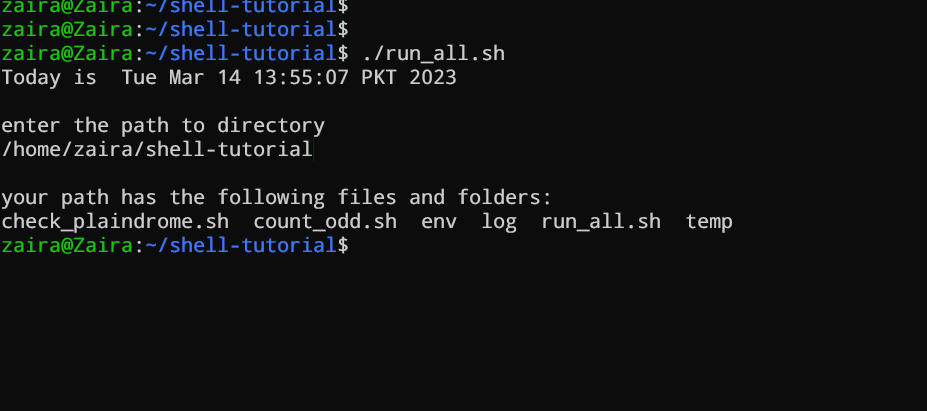
vim run_all.sh
Maak een bestand aan met de naam run_all.sh met behulp van elke editor van uw keuze.
#!/bin/bash
echo "Today is " `date`
echo -e "\nenter the path to directory"
read the_path
echo -e "\n you path has the following files and folders: "
ls $the_path
Voeg de volgende commando’s toe aan uw bestand en sla het op:
1 Laten we een diepere kijk op het script lijn per lijn. Ik toont hetzelfde script opnieuw, maar deze keer met lijnnummers.
2 echo "Today is " `date`
3
4 echo -e "\nenter the path to directory"
5 read the_path
6
7 echo -e "\n you path has the following files and folders: "
8 ls $the_path
- #!/bin/bash
- Lijn #1: De shebang (
#!/bin/bash) wijst naar het pad van de bash-shell. - Lijn #2: Het
echo-commando toont de huidige datum en tijd op de terminal. Noteer datdatein achtersteekjes staat. - Lijn #4: We willen dat de gebruiker een geldig pad invoert.
- Regel #5: Het
readcommando leest de invoer in en slaat deze op in de variabelethe_path.
regel #8: Het ls commando neemt de variabele met de opgeslagen pad en toont de huidige bestanden en mappen.
Uitvoeren van het bash-script
chmod u+x run_all.sh
Om het script uitvoerbaar te maken, ken je uitvoeringsrechten toe aan je gebruiker met deze opdracht:
- Hierbij,
chmodwijzigt de eigenaarsrechten van een bestand voor de huidige gebruiker:u.+xvoegt uitvoeringsrechten toe aan de huidige gebruiker. Dit betekent dat de gebruiker die eigenaar is nu het script kan uitvoeren.
run_all.sh is het bestand dat we willen uitvoeren.
- Je kunt het script uitvoeren met een van de genoemde methoden:
sh run_all.sh
./run_all.sh
Laten we het in actie zien 🚀
6.5. Basisprincipes van Bash Scripting
Opmerkingen in bash scripting
Opmerkingen beginnen met een # in bash scripting. Dit betekent dat elke regel die begint met een # een opmerking is en door de interpreter wordt genegeerd.
Opmerkingen zijn zeer nuttig bij het documenteren van de code, en het is een goede gewoonte om ze toe te voegen om anderen te helpen de code te begrijpen.
Dit zijn voorbeelden van opmerkingen:
# Dit is een voorbeeld van een opmerking
# Beide van deze regels worden door de interpreter genegeerd
Variabelen en datatypes in Bash
Variabelen laten je data opslaan. Je kunt variabelen gebruiken om data te lezen, te openen en te manipuleren in je script.
Er zijn geen datatypes in Bash. In Bash kan een variabele numerieke waarden, individuele karakters of tekenreeksen opslaan.
- In Bash kun je variabelen en waarden op de volgende manieren gebruiken en instellen:
country=Netherlands
De waarde direct toewijzen:
same_country=$country
2. De waarde toewijzen op basis van de uitvoer verkregen van een programma of commando, met behulp van commando-substitutie. Merk op dat $ nodig is om toegang te krijgen tot de waarde van een bestaande variabele.
Dit wijst de waarde van country toe aan de nieuwe variabele same_country.
country=Netherlands
echo $country
Om toegang te krijgen tot de variabele waarde, voeg je $ toe aan de variabele naam.
Netherlands
new_country=$country
echo $new_country
# uitvoer
Netherlands
# uitvoer
Boven kunt u zien een voorbeeld van toewijzen en afdrukken van variabele waarden.
Conventies voor variabelenaming
- In Bash-scripting gelden de volgende conventies voor variabelenaming:
- Varaiblenamen moeten beginnen met een letter of een underscore (
_). - Varaiblenamen kunnen letters, cijfers, en underscores (
_) bevatten. - Varaiblenamen zijn hoofdlettergevoelig.
- Varaiblenamen moeten geen spaties of speciale tekens bevatten.
- Gebruik beschrijvende namen die het doel van de variabele weerspiegelen.
Vermeid gebruik van gereserveerde sleutelwoorden, zoals if, then, else, fi, enzovoort als variabelenamen.
name
count
_var
myVar
MY_VAR
Hier zijn enkele voorbeelden van geldige variabelenamen in Bash:
En hier zijn enkele voorbeelden van ongeldige variabelenamen:
2ndvar (variable name starts with a number)
my var (variable name contains a space)
my-var (variable name contains a hyphen)
# onjuiste variabelenamen
Volgens deze naamgevingsconventies worden Bash-scripts gemakkelijker leesbaar en gemakkelijker bij te houden.
Invoer en uitvoer in Bash-scripts
Invoer opnemen
- In dit gedeelte zullen we over enkele methodes praten om invoer aan onze scripts te verschaffen.
Lezen van de gebruikersinvoer en opslaan in een variabele
#!/bin/bash
echo "What's your name?"
read entered_name
echo -e "\nWelcome to bash tutorial" $entered_name
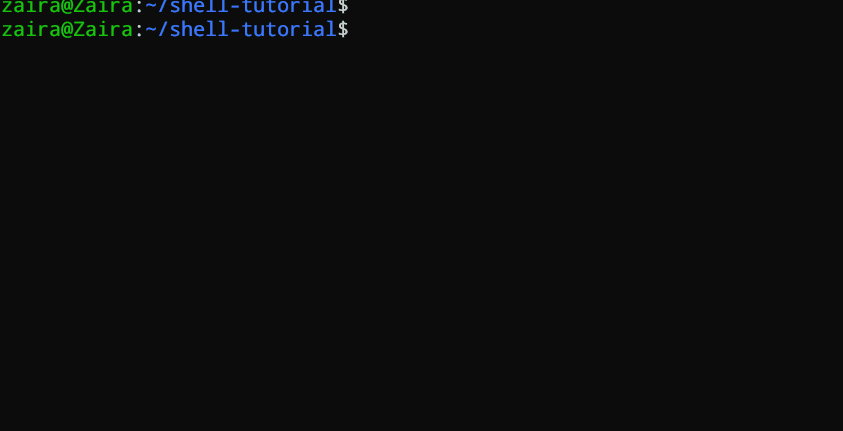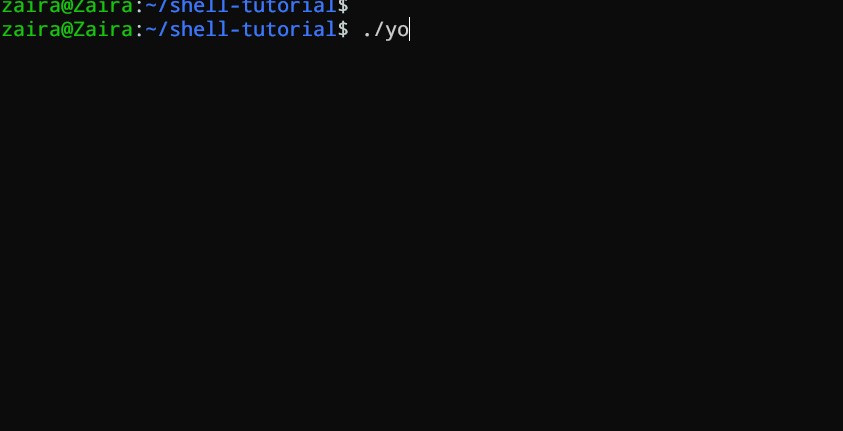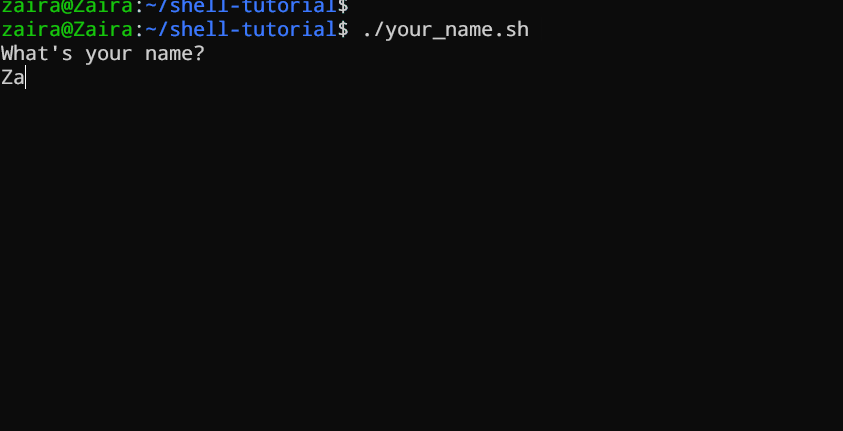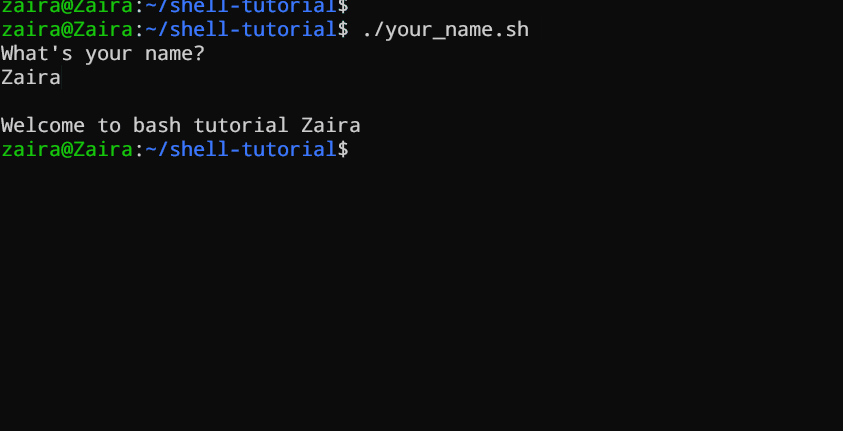
We kunnen gebruikersinvoer lezen met behulp van de `read`-opdracht.
2. Lezen uit een bestand
while read line
do
echo $line
done < input.txt
Dit code leest elke regel uit een bestand genaamd `input.txt` en print het op het terminal. We zullen later in dit gedeelte de while-lussen bestuderen.
3. Commandoregelargumenten
In een Bash-script of functie staan `$1` de eerste argumenten die worden meegegeven, `$2` de tweede argument enzovoort.
#!/bin/bash
echo "Hello, $1!"
Dit script neemt een naam aan als commandoregelargument en print een persoonlijke groet.
We hebben `Zaira` aangegeven als ons argument voor het script.
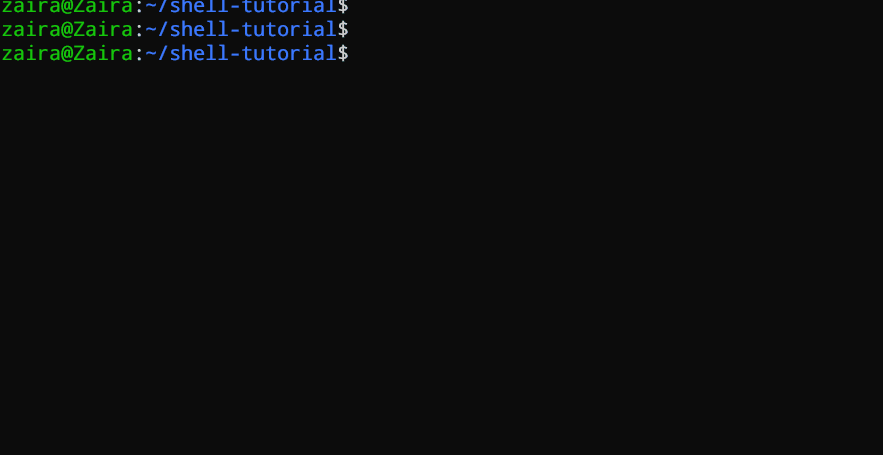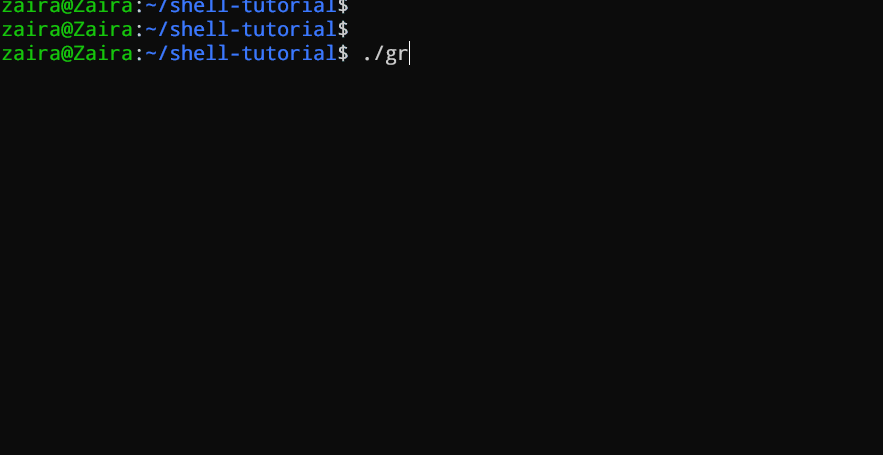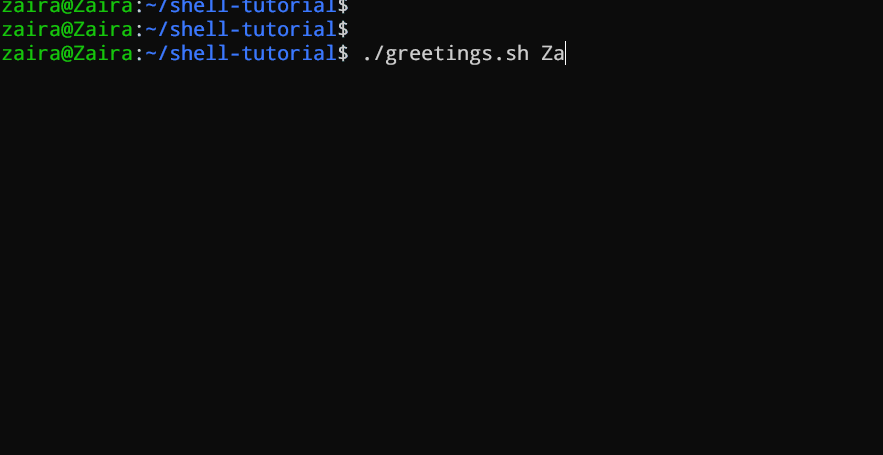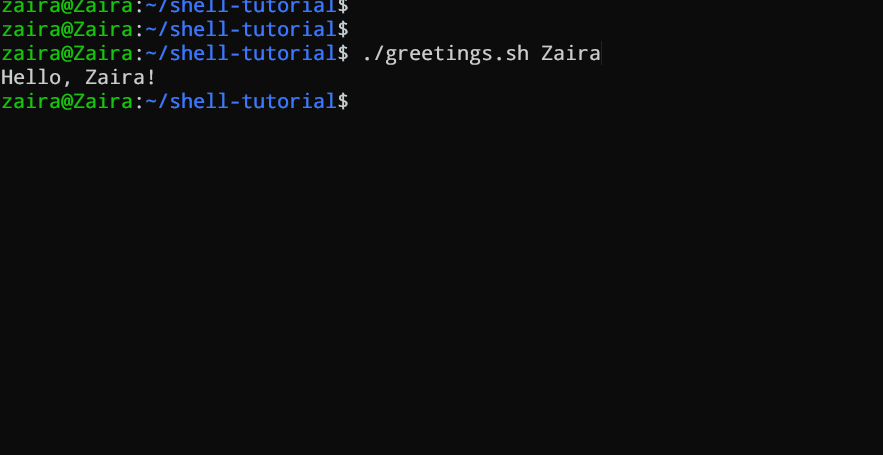
Uitvoer:
Uitvoer tonen
- In dit gedeelte zullen we over enkele methodes praten om uitvoer te krijgen van de scripts.
echo "Hello, World!"
Afdrukken op het terminal:
Dit print de tekst “Hello, World!” op het terminal.
echo "This is some text." > output.txt
2. Schrijven naar een bestand:
Dit schrijft de tekst “Dit is enige tekst.” naar een bestand genaamd `output.txt`. Noteer dat de `>&` operator een bestand overschrijft als het al enige inhoud bevat.
echo "More text." >> output.txt
3. Toevoegen aan een bestand:
Dit voegt de tekst “Meer tekst.” toe aan het einde van het bestand output.txt.
ls > files.txt
4. Output omleiden:
Dit vermeldt de bestanden in de huidige map en schrijft de uitvoer naar een bestand genaamd files.txt. U kunt de uitvoer van elke opdracht op deze manier naar een bestand omleiden.
U leert over output-omleiding in detail in sectie 8.5.
Conditionele instructies (if/else)
Expressies die een booleaanse uitkomst produceren, ofwel true of false, worden voorwaarden genoemd. Er zijn verschillende manieren om voorwaarden te evalueren, inclusief if, if-else, if-elif-else, en geneste voorwaarden.
if [[ condition ]];
then
statement
elif [[ condition ]]; then
statement
else
do this by default
fi
Syntax:
Syntax van bash-conditie-instructies
if [ $a -gt 60 -a $b -lt 100 ]
We kunnen logische operatoren zoals AND -a en OR -o gebruiken om vergelijkingen die meer betekenis hebben te maken.
Deze instructie controleert of beide voorwaarden true zijn: a is groter dan 60 AND b is kleiner dan 100.
#!/bin/bash
Laten we eens een voorbeeld zien van een Bash-script dat if, if-else, en if-elif-else-instructies gebruikt om te bepalen of een door de gebruiker ingevoerde nummer positief, negatief, of nul is:
echo "Please enter a number: "
read num
if [ $num -gt 0 ]; then
echo "$num is positive"
elif [ $num -lt 0 ]; then
echo "$num is negative"
else
echo "$num is zero"
fi
# Script om te bepalen of een nummer positief, negatief, of nul is
Het script vraagt de gebruiker eerst om een nummer in te voeren. Vervolgens gebruikt het een if statement om te controleren of het nummer groter is dan 0. Als dat het geval is, geeft het script aan dat het nummer positief is. Als het nummer niet groter is dan 0, gaat het script door naar de volgende statement, wat een if-elif statement is.
Hier controleert het script of het nummer kleiner is dan 0. Als dat zo is, geeft het script aan dat het nummer negatief is.
Ten slotte, als het nummer niet groter is dan 0 noch kleiner dan 0, gebruikt het script een else statement om aan te geven dat het nummer nul is.
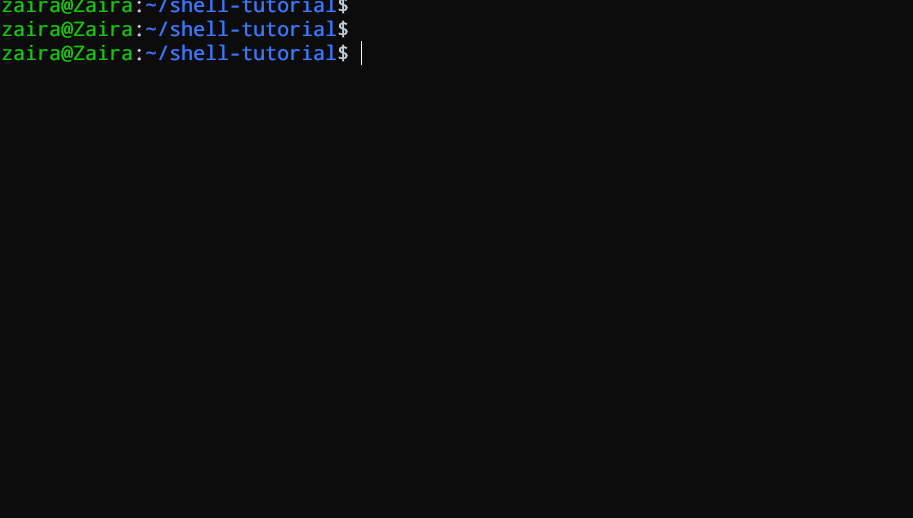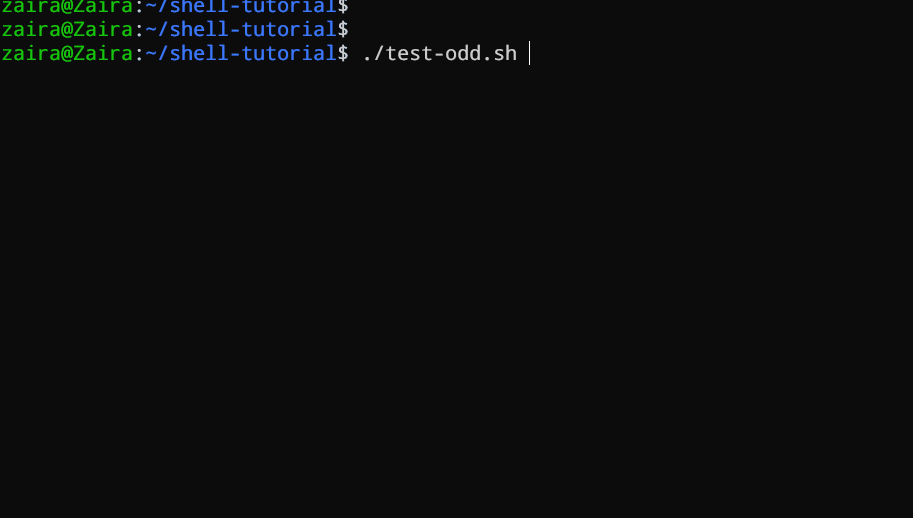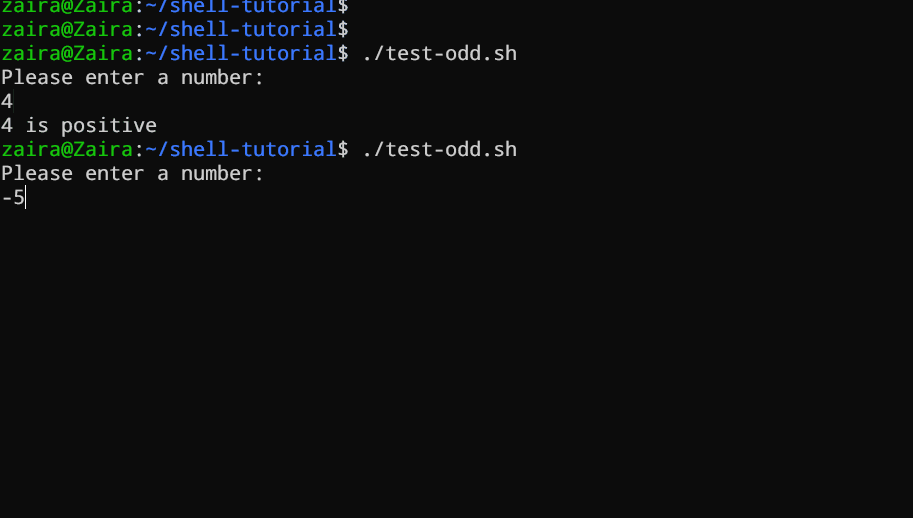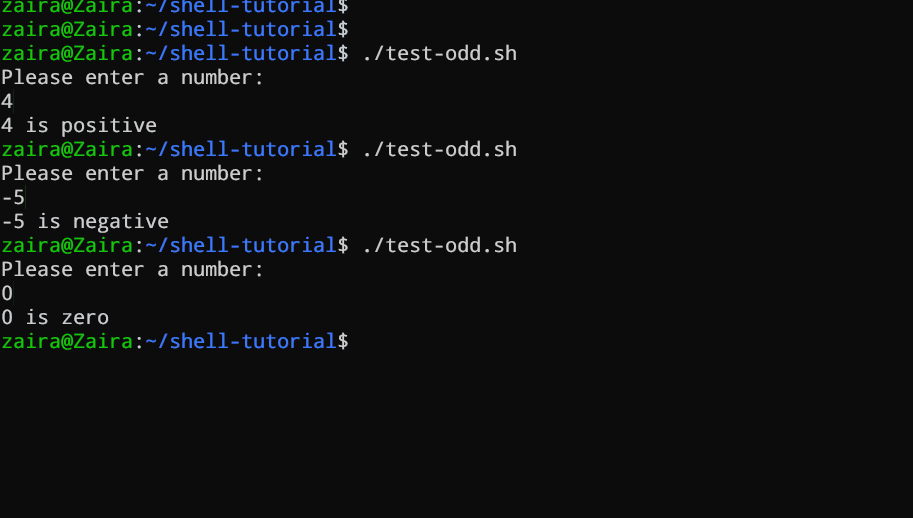
Het zien in actie 🚀
Lussen en takken in Bash
While-lus
While-lussen controleren of een conditie waar is en lussen door totdat de conditie blijft true. We moeten een tellerstatement geven dat de teller verhoogt om de uitvoering van de lus te controleren.
#!/bin/bash
i=1
while [[ $i -le 10 ]] ; do
echo "$i"
(( i += 1 ))
done
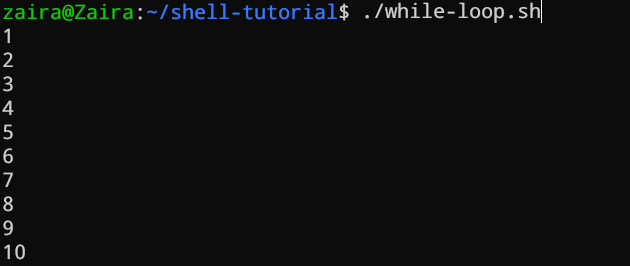
In het onderstaande voorbeeld is (( i += 1 )) het tellerstatement dat de waarde van i verhoogt. De lus zal exact 10 keer worden uitgevoerd.
For-lus
De for-lus, net als de while-lus, laat je statements een bepaald aantal keer uitvoeren. Elke lus verschilt in syntax en gebruik.
#!/bin/bash
for i in {1..5}
do
echo $i
done

In het onderstaande voorbeeld wordt de lus 5 keer doorlopen.
Case-statements
case expression in
pattern1)
In Bash worden case-instructies gebruikt om een gegeven waarde met een lijst van patronen te vergelijken en een blok code uit te voeren op basis van het eerste overeenkomende patroon. De syntax voor een case-instructie in Bash is als volgt:
;;
pattern2)
# code uit te voeren als de expressie overeenkomt met patroon1
;;
pattern3)
# code uit te voeren als de expressie overeenkomt met patroon2
;;
*)
# code uit te voeren als de expressie overeenkomt met patroon3
;;
esac
# code uit te voeren als geen van de bovenstaande patronen overeenkomt met de expressie
Hierbij is “expression” de waarde die we willen vergelijken, en “patroon1”, “patroon2”, “patroon3”, enzovoort zijn de patronen waarmee we deze willen vergelijken.
De dubbele punt “;;” scheidt elk blok code dat uitgevoerd moet worden voor elk patroon. De asterisk “*” representeert de standaardcase, die uitgevoerd wordt als geen van de gespecificeerde patronen overeenkomt met de expressie.
fruit="apple"
case $fruit in
"apple")
echo "This is a red fruit."
;;
"banana")
echo "This is a yellow fruit."
;;
"orange")
echo "This is an orange fruit."
;;
*)
echo "Unknown fruit."
;;
esac
Bekijk bijvoorbeeld:
In dit voorbeeld, omdat de waarde van fruit apple is, komt het eerste patroon overeen en wordt het blok code uitgevoerd dat Dit is een rode vrucht. echo’t. Als de waarde van fruit in plaats daarvan banana was, zou het tweede patroon overeenkomen en zou het blok code dat Dit is een gele vrucht. echo’t, worden uitgevoerd, enzovoort.
Als de waarde van fruit niet overeenkomt met een van de gespecificeerde patronen, wordt de standaardcase uitgevoerd, die Onbekende vrucht. echo’t.
Deel 7: Beheren van softwarepakketten in Linux
Linux komt met verschillende ingebouwde programma’s. Maar je moet misschien nieuwe programma’s installeren op basis van je behoeften. Je moet mogelijk ook bestaande toepassingen upgraden.
7.1. Paketten en Pakketbeheer
Wat is een pakket?
Een pakket is een verzameling bestanden die samen gebundeld zijn. Deze bestanden zijn essentieel voor het uitvoeren van een bepaald programma. Deze bestanden bevatten de uitvoerbare bestanden van het programma, bibliotheken en andere bronnen.
Naast de bestanden die nodig zijn voor het uitvoeren van het programma, bevatten paketten ook installatie-scripts, die de bestanden kopiëren naar waar ze nodig zijn. Een programma kan veel bestanden en afhankelijkheden bevatten. Met paketten is het gemakkelijker om alle bestanden en afhankelijkheden tegelijkertijd te beheren.
Wat is het verschil tussen broncode en binaire code?
Programmeurs schrijven broncode in een programmeertaal. Deze broncode wordt vervolgens gecompileerd in machinecode die de computer kan begrijpen. De gecompileerde code wordt binaire code genoemd.
Wanneer je een pakket download, krijg je ofwel de broncode of de binaire code. De broncode is de door mensen leesbare code die kan worden gecompileerd in binaire code. De binaire code is de gecompileerde code die de computer kan begrijpen.
Bronepakketten kunnen worden gebruikt met elke soort machine als de broncode correct is gecompileerd. Binaire code daarentegen is gecompileerde code die specifiek is voor een bepaalde soort machine of architectuur.
uname -m
Je kunt de architectuur van je machine vinden met behulp van het commando uname -m.
x86_64
# uitvoer
Pakketafhankelijkheden
Programma’s delen vaak bestanden. In plaats van deze bestanden in elk pakket op te nemen, kan een apart pakket ze voor alle programma’s leveren.
Om een programma te installeren dat deze bestanden nodig heeft, moet je ook het pakket installeren dat ze bevat. Dit wordt een pakketafhankelijkheid genoemd. Het specificeren van afhankelijkheden maakt pakketten kleiner en eenvoudiger door duplicaten te verminderen.
Wanneer je een programma installeert, moeten de afhankelijkheden ook worden geïnstalleerd. De meeste vereiste afhankelijkheden zijn meestal al geïnstalleerd, maar er kunnen enkele extra nodig zijn. Dus wees niet verrast als meerdere andere pakketten worden geïnstalleerd samen met je gekozen pakket. Dit zijn de noodzakelijke afhankelijkheden.
Pakketbeheerders
Linux biedt een uitgebreid pakketbeheersysteem voor het installeren, upgraden, configureren en verwijderen van software.
Met pakketbeheer krijg je toegang tot een georganiseerde basis van duizenden softwarepakketten, samen met de mogelijkheid om afhankelijkheden op te lossen en te controleren op software-updates.
Pakketten kunnen worden beheerd met behulp van command-line utilities die eenvoudig kunnen worden geautomatiseerd door systeembeheerders, of via een grafische interface.
Softwarekanalen/repositories
⚠️ Pakketbeheer is verschillend voor verschillende distro’s. Hier gebruiken we Ubuntu.
Het installeren van software is in Linux een beetje anders in vergelijking met Windows en Mac.
Linux gebruikt repositories om softwarepakketten op te slaan. Een repository is een verzameling softwarepakketten die beschikbaar zijn voor installatie via een pakketbeheerder.
Een pakketbeheerder slaat ook een index van alle beschikbare pakketten op uit een opslagplaats. Soms wordt de index herbouwd om er zeker van te zijn dat ze up-to-date is en om te weten welke pakketten zijn bijgewerkt of toegevoegd aan het kanaal sinds de laatste controle.
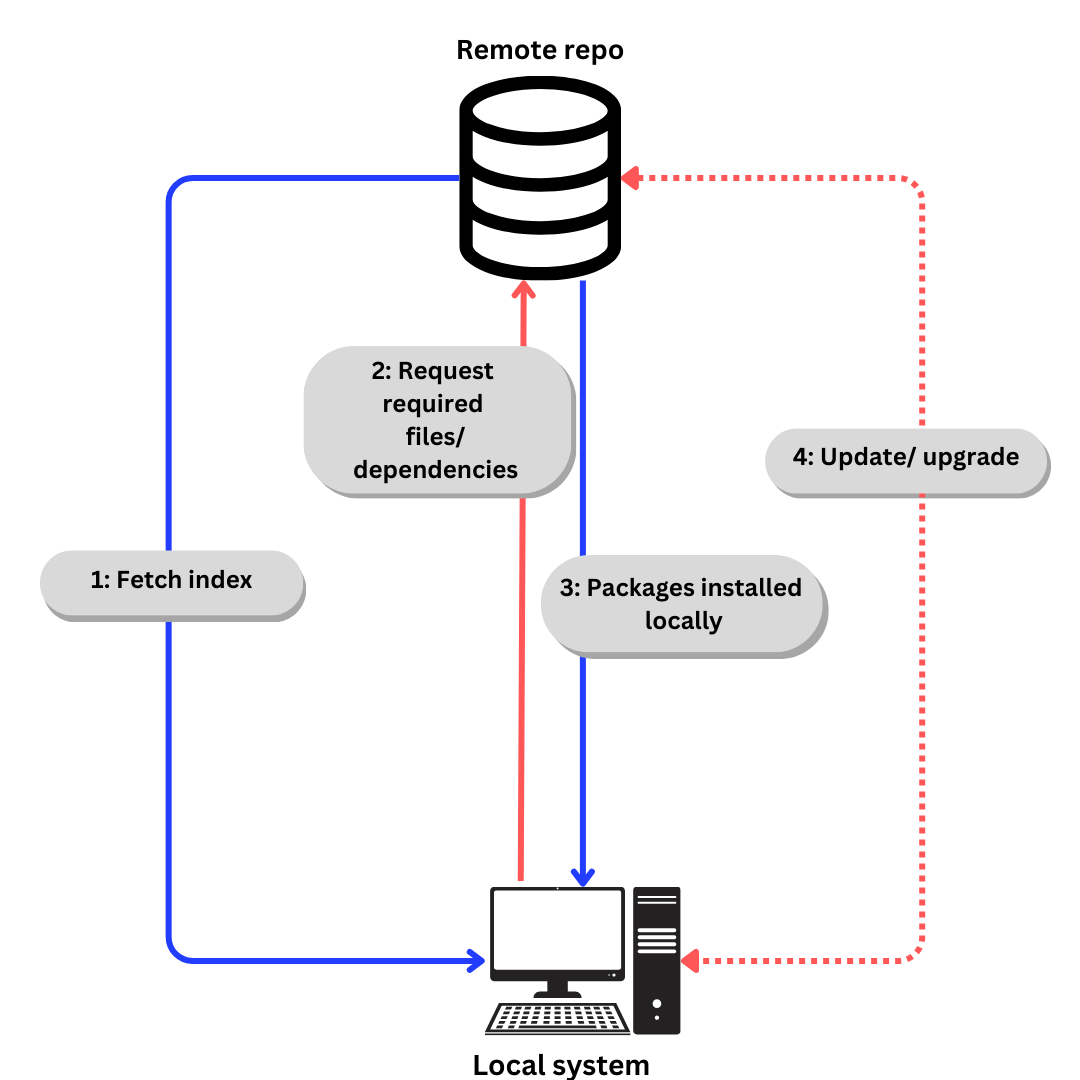
Het algemene proces van downloaden van software uit een opslagplaats ziet er iets als dit uit:
- Als we specifiek over Ubuntu praten,
- Wordt de index gehaald met behulp van
apt update.(aptwordt in de volgende sectie uitgelegd). - Vereist bestanden/ afhankelijkheden gevraagd volgens de index met
apt install - Pakketten en afhankelijkheden worden lokaal geïnstalleerd.
Update afhankelijkheden en pakketten wanneer nodig met apt update en apt upgrade
Op Debian-gebaseerde distributies kun je de lijst met opslagplaatsen (repositorien) opslaan in /etc/apt/sources.list.
7.2. Een pakket installeren via de commandoregel
De apt-opdracht is een krachtige commandoregelgereedschap, dat werkt met Ubuntu’s “Advanced Packaging Tool (APT)”.
Met apt en de bijbehorende commando’s biedt men de mogelijkheid om nieuwe softwarepakketten te installeren, bestaande softwarepakketten te upgraden, de pakketlijstindex bij te werken, en zelfs het hele Ubuntu-systeem te upgraden.
Om de logs van de installatie met apt te bekijken, kunt u het bestand /var/log/dpkg.log inzien.
Hieronder volgen de gebruiksmogelijkheden van het commando apt:
Installatie van pakketten
sudo apt install htop
Bijvoorbeeld, om het pakket htop te installeren, kunt u het volgende commando gebruiken:
Bijwerken van de pakketlijstindex
sudo apt update
De pakketlijstindex is een lijst van alle pakketten beschikbaar in de repositories. Om de lokale pakketlijstindex bij te werken, kunt u het volgende commando gebruiken:
Upgraden van pakketten
Geïnstalleerde pakketten op uw systeem kunnen updates ontvangen die foutreparaties, beveiligingspatches, en nieuwe functies bevatten.
sudo apt upgrade
Om pakketten te upgraden, kunt u het volgende commando gebruiken:
Verwijderen van pakketten
sudo apt remove htop
Om een pakket, zoals htop, te verwijderen, kunt u het volgende commando gebruiken:
7.3. Installeren van een pakket via een geavanceerde grafische methode – Synaptic
Als u niet comfortabel bent met de opdrachtprompt, kunt u een GUI-toepassing gebruiken om pakketten te installeren. U kunt dezelfde resultaten bereiken als met de opdrachtprompt, maar dan met een grafische interface.
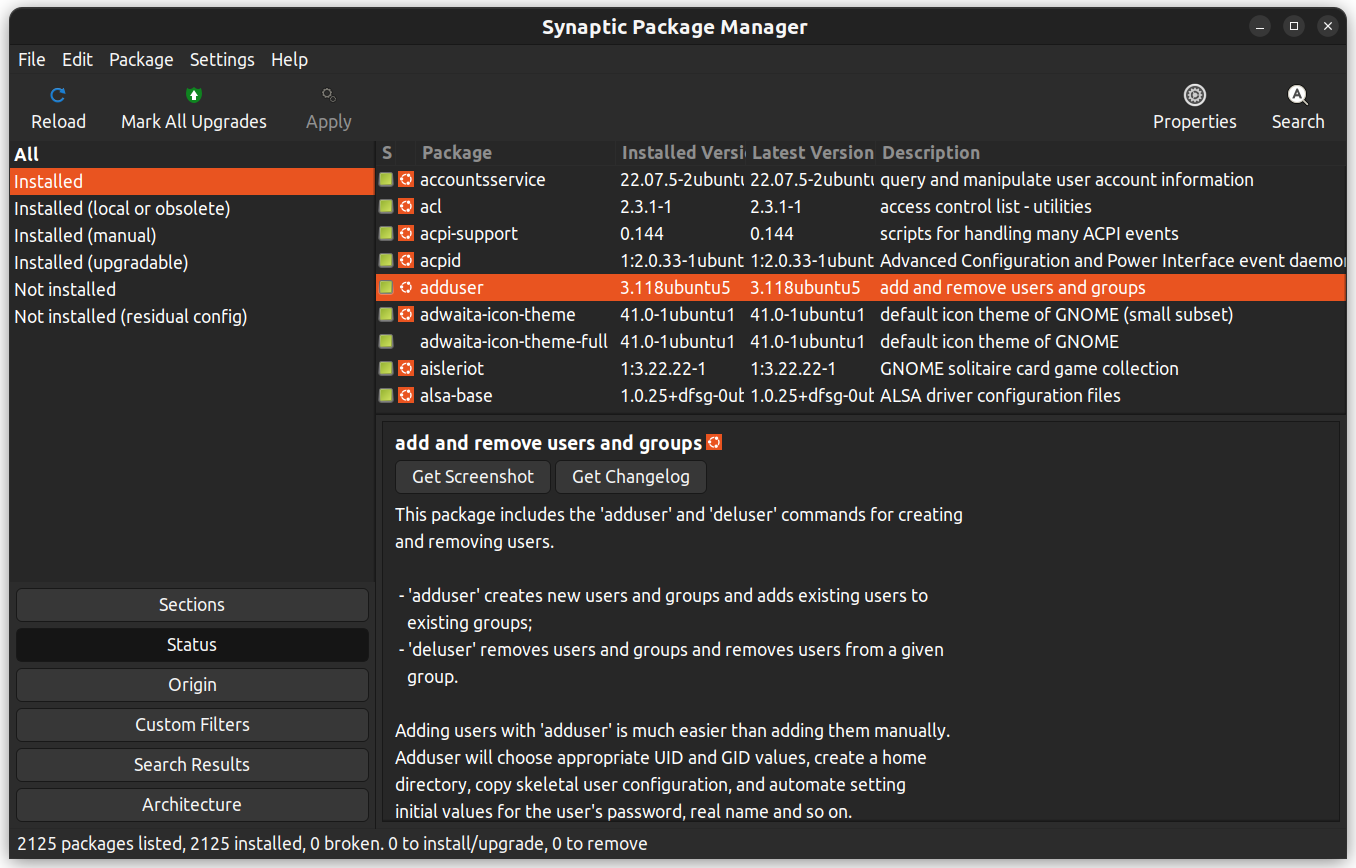
Synaptic is een GUI-pakketbeheertoepassing die helpt bij het weergeven van de geïnstalleerde pakketten, hun status, uitstaande updates, enzovoort. Het biedt aangepaste filters om u te helpen bij het versnijden van de zoekresultaten.
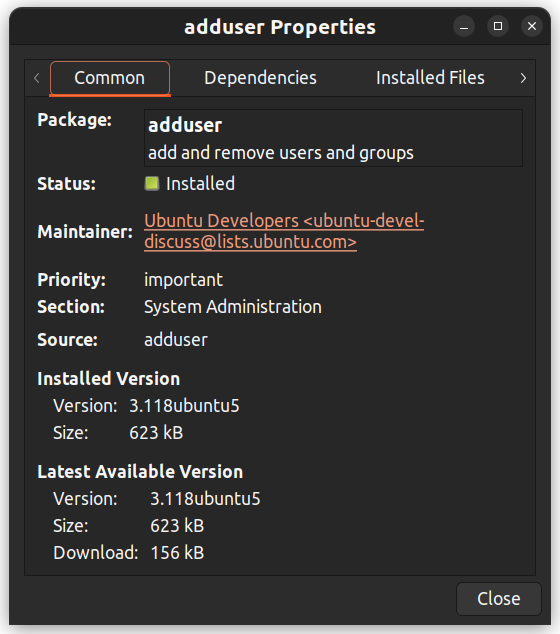
U kunt ook met de rechtsmuisknop op een pakket klikken en verdere details bekijken zoals afhankelijkheden, onderhouder, grootte en de geinstalleerde bestanden.
7.4. Installatie van gedownloadde pakketten van een website
U zou misschien een pakket willen installeren dat u heeft gedownload van een website, in plaats van uit een software-pakketbron. Deze pakketten worden .deb bestanden genoemd.
cd directory
sudo dpkg -i package_name.deb
Gebruikdpkgom pakketten te installeren:dpkg is een commandoregelgereedschap dat gebruikt wordt om pakketten te installeren. Om een pakket met dpkg te installeren, open het Terminal en typ de volgende:
Let op: Vervang “directory” door de directory waar het pakket is opgeslagen en “package_name” door de bestandsnaam van het pakket.
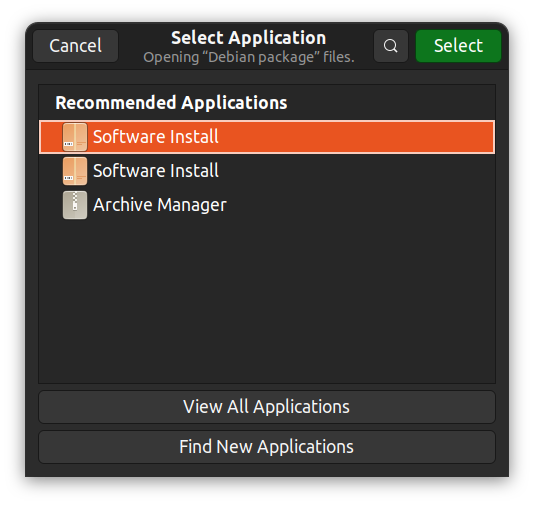
Als alternatief kunt u met de rechtsmuisknop klikken, kies “Open Met Andere Applicatie” en selecteer een GUI-app van uw keuze.
💡 Tip: In Ubuntu kunt u een lijst zien van geïnstalleerde pakketten met dpkg --list.
Hoofdstuk 8: Geavanceerde Linuxonderwerpen
8.1. Gebruikersbeheer
Er kunnen meerdere gebruikers zijn met verschillende niveaus toegang tot een systeem. In Linux heeft de root-gebruiker de hoogste toegangsniveau en kan elke operatie op het systeem uitvoeren. Bijgewerkte gebruikers hebben beperkte toegang en kunnen alleen operaties uitvoeren die ze toegang tot hebben toegestaan.
Wat is een gebruiker?
Een gebruikersaccount biedt scheiding tussen verschillende mensen en programma’s die commando’s kunnen uitvoeren.
Mensen identificeren gebruikers door een naam, want namen zijn gemakkelijk om mee te werken. Maar het systeem identificeert gebruikers door een uniek nummer genaamd de gebruikers-ID (UID).
Wanneer gebruikers zich aanmelden met het aangeboden gebruikersnaam, moeten ze een wachtwoord invoeren om zichzelf te autoriseren.
Gebruikersaccounts vormen de basis van de systeemveiligheid. Bestandseigendomsrechten zijn ook verbonden met gebruikersaccounts en ze implementeren toegangsbeheer voor bestanden. Elk proces heeft een geassocieerd gebruikersaccount dat een laag beheer biedt voor de beheerders.
- Er zijn drie hoofdtypes van gebruikersaccounts:
- Superuser: De superuser heeft volledige toegang tot het systeem. De naam van de superuser is
root. Het heeft eenUIDvan 0. - Systeemgebruiker: De systeemgebruiker heeft gebruikersaccounts die worden gebruikt om systeemdiensten uit te voeren. Deze accounts worden gebruikt om systeemdiensten uit te voeren en zijn niet bedoeld voor menselijke interactie.
Gebruiker: Reguliere gebruikers zijn menselijke gebruikers die toegang tot het systeem hebben.
id
uid=1000(john) gid=1000(john) groups=1000(john),4(adm),24(cdrom),27(sudo),30(dip)... output truncated
De id opdracht toont de gebruikers-ID en groeps-ID van de huidige gebruiker.
id username
Om de basisinformatie van een andere gebruiker te bekijken, moet u de gebruikersnaam als argument doorgeven aan de id opdracht.
ps -u
Om gebruikersgerelateerde informatie voor processen te bekijken, gebruikt u de opdracht `ps` met de optie `-u`.
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.1 16968 3920 ? Ss 18:45 0:00 /sbin/init splash
root 2 0.0 0.0 0 0 ? S 18:45 0:00 [kthreadd]
# Uitvoer
Standaard gebruikt het systeem de bestand `/etc/passwd` om gebruikersgegevens op te slaan.
root:x:0:0:root:/root:/bin/bash
Hier is een regel uit het bestand `/etc/passwd`:
- Het bestand `/etc/passwd` bevat de volgende informatie over elke gebruiker:
- Gebruikersnaam:
root– De gebruikersnaam van het account. - Wachtwoord:
x– Het versleutelde wachtwoord voor het account, opgeslagen in de bestand `/etc/shadow` voor veiligheidsredenen. - Gebruikers ID (UID):
0– Het unieke numerieke identificatienummer voor het account. - Groeps ID (GID):
0– Het primaire groepsidentificatienummer voor het account. - Gebruikersinfo:
root– De echte naam van het account. - Home directory:
/root– De home directory voor het gebruikersaccount.
Shell: /bin/bash – De standaard shell voor het gebruikersaccount. Een systeemgebruiker zou misschien /sbin/nologin gebruiken als interactieve login niet is toegestaan voor dat account.
Wat is een groep?
Een groep is een verzameling van gebruikersaccounts die gezamenlijke toegang en resources delen. Groepen hebben een groepsnaam om ze te identificeren. Het systeem identificeert groepen met behulp van een unieke nummer, het groeps-ID (GID).
Standaard wordt de informatie over groepen in de /etc/group bestand opgeslagen.
adm:x:4:syslog,john
Hier is een invoer uit het /etc/group bestand:
- Hier is de opdeling van de velden in de gegeven invoer:
- Groepsnaam:
adm– De naam van de groep. - Wachtwoord:
x– Het wachtwoord voor de groep is voor veiligheidsoverwegingen opgeslagen in het/etc/gshadowbestand. Het wachtwoord is optioneel en leeg indien niet ingesteld. - Groep-ID (GID):
4– De unieke numerieke identifier voor de groep.
Groepsleden: syslog,john – De lijst met gebruikersnamen die lid zijn van de groep. In dit geval heeft de groep adm twee leden: syslog en john.
In deze specifieke invoer is de groepsnaam adm, het groep-ID is 4, en de groep heeft twee leden: syslog en john. Het wachtwoordveld is meestal ingesteld op x om aan te geven dat het groepswachtwoord opgeslagen is in het bestand /etc/gshadow.
- De groepen zijn verder opgedeeld in ‘primaire’ en ‘aanvullende’ groepen.
- Primaire Groep: Elke gebruiker krijgt standaard één primaire groep toegewezen. Deze groep heeft meestal dezelfde naam als de gebruiker en wordt gemaakt bij het aanmaken van het gebruikersaccount. Bestanden en mappen die door de gebruiker zijn aangemaakt behoren meestal toe aan deze primaire groep.
Bijkomende Groepen: Dit zijn extra groepen waartoe een gebruiker kan behoren naast zijn of haar primaire groep. Gebruikers kunnen lid zijn van meerdere bijkomende groepen. Deze groepen bieden aan een gebruiker toegang tot bestemmingen die gedeeld worden binnen deze groepen. Ze helpen toegang tot gedeelde resources te bieden zonder de bestandrechten van het systeem te beïnvloeden en de beveiliging intact te houden. Terwijl een gebruiker eenmaal moet behoren tot een primaire groep, is het lidmaatschap van bijkomende groepen optioneel.
Toegangsbeheer: het opsporen en begrijpen van bestandrechten
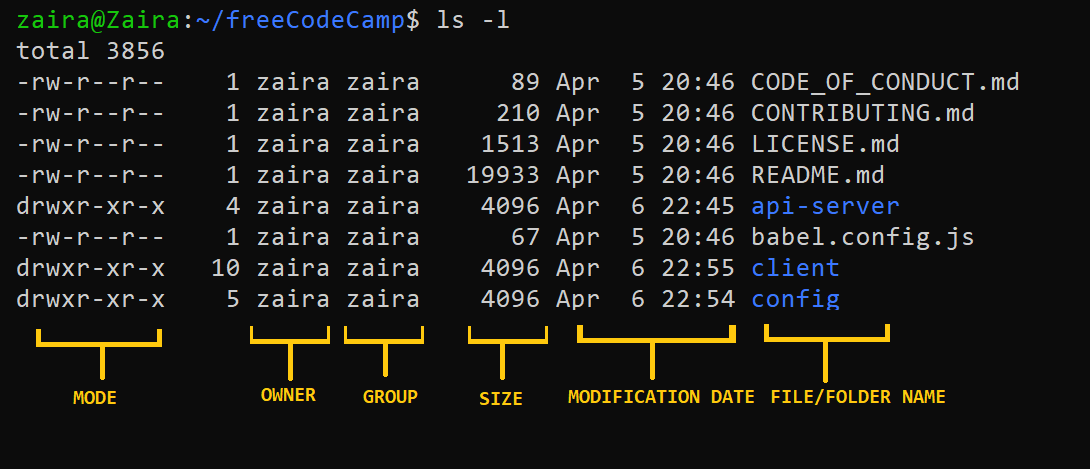
Bestandseigendom kan worden bekijkt met de opdracht ls -l. De eerste kolom in de uitvoer van de opdracht ls -l toont de rechten van het bestand. Andere kolommen tonen de eigenaar van het bestand en de groep die het bestand toebehorende.

Laten we een kijkje nemen in de modus kolom:
- Modus bepaalt twee dingen:
- Bestandstype: Bestandstype definieert het type van het bestand. Voor reguliere bestanden die eenvoudige data bevatten is het leeg
-. Voor andere speciale bestandstypes is het symbool anders. Voor een map, die een speciaal bestand is, is hetd. Speciale bestanden worden anders behandeld door het OS.
Rechtenklassen: De volgende set tekens definiëren de rechten voor gebruiker, groep, en anderen respectievelijk.
– Gebruiker: Dit is de eigenaar van een bestand en de eigenaar van het bestand behoort tot deze klasse.
– Groep: De leden van de bestandsgroep behoren tot deze klasse
– Andere: Alle gebruikers die niet deel uitmaken van de gebruiker- of groepsklassen behoren tot deze klasse.
💡Tip: Mapeigendom kan bekeken worden met het commando ls -ld.
Hoe je symbolische rechten of de rwx-rechten leest
- De
rwx-weergave wordt ook wel de symbolische weergave van rechten genoemd. In de set met rechten, rstaat voor lezen. Het wordt aangegeven in het eerste karakter van de drietal.wstaat voor schrijven. Het wordt aangegeven in het tweede karakter van de drietal.
x staat voor uitvoeren. Het wordt aangegeven in het derde karakter van de drietal.
Lezen:
Voor normale bestanden geeft leesrechten de mogelijkheid het bestand alleen maar te openen en te lezen. Gebruikers kunnen het bestand niet wijzigen.
Voor mappen heeft lezen hetzelfde effect: het toestaat het bekijken van de inhoud van de map zonder wijzigingen aan de map zelf.
Schrijven:
Wanneer bestanden schrijfrechten hebben, kan de gebruiker het bestand wijzigen (bewerken, verwijderen) en opslaan.
Voor mappen betekent dit dat een gebruiker de inhoud ervan kan wijzigen (bestanden maken, verwijderen en hernoemen binnenin de map), alsook de inhoud van bestanden waarvoor de gebruiker schrijfrechten heeft.
Voorbeelden van rechten in Linux
- Nu we weten hoe we rechten moeten lezen, laten we enkele voorbeelden zien.
-
-rw-rw-r--: Een bestand dat door zijn eigenaar en groep gewijzigd kan worden, maar niet door anderen.
drwxrwx---: Een map die door zijn eigenaar en groep gewijzigd kan worden.
Uitvoeren:
Voor bestanden geven execute-rechten toe aan de gebruiker om een uitvoerbare script te kunnen draaien. Voor mappen kunnen de gebruiker deze openen en details over de bestanden in de map bekijken.
Hoe bestandsrechten en eigendomsrechten in Linux te wijzigen met behulp van `chmod` en `chown`
Nu we de basis van eigendoms- en toegangsrechten kennen, zien we hoe we de toegangsrechten kunnen wijzigen met behulp van de `chmod` opdracht.
chmod permissions filename
Syntaxis vanchmod:
- Waar,
rechtenkunnen zijn: lezen, schrijven, uitvoeren of een combinatie daarvan.
bestandsnaam is de naam van het bestand waarvoor de toegangsrechten moeten worden gewijzigd. Dit parameter kan ook een lijst zijn van bestanden om in bulk toegangsrechten aan te passen.
- We kunnen toegangsrechten wijzigen met behulp van twee modi:
- Symbolische modus: deze methode gebruikt symbolen zoals
u,g,oom gebruikers, groepen en anderen te vertegenwoordigen. Toestemmingen worden weergegeven alsr, w, xvoor respectievelijk lezen, schrijven en uitvoeren. Je kunt toestemmingen wijzigen met +, – en =.
Absolute modus: deze methode vertegenwoordigt toestemmingen als 3-cijferige octale getallen die variëren van 0-7.
Laten we ze nu in detail bekijken.
Hoe Toestemmingen te Wijzigen met Symbolische Modus
| De tabel hieronder vat de gebruikersrepresentatie samen: | GEBRUIKERSREPRESENTATIE |
| u | BESCHRIJVING |
| g | gebruiker/eigenaar |
| o | groep |
andere
| We kunnen wiskundige operatoren gebruiken om toestemmingen toe te voegen, te verwijderen en toe te wijzen. De tabel hieronder toont de samenvatting: | OPERATOR |
| BESCHRIJVING | + |
| Voegt een toestemming toe aan een bestand of map | – |
| Verwijdert de toestemming | \= |
Stelt de machtigingen in als ze niet aanwezig zijn. Override ook de machtigingen als ze eerder zijn ingesteld.
Voorbeeld:
Supposeer ik een script en ik will dat ik het uitvoerbaar maak voor de eigenaar van het bestand zaira.

Huidige bestandsmachtigingen zijn als volgt:
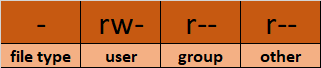
Laat ons de machtigingen zo verdelen:
chmod u+x mymotd.sh
Om uitvoeringsrechten (x) toe te voegen aan de eigenaar (u) met symbolische modus, kunnen we de onderstaande commando gebruiken:
Uitvoer:
Nu kunnen we zien dat de uitvoeringsmachtigingen zijn toegevoegd voor eigenaar zaira.
- Aanvullende voorbeelden voor het veranderen van machtigingen via symbolische methode:
- Verwijderen van
lezenenschrijvenrechten voorgroepenandere:chmod go-rw. - Verwijderen van
lezenrechten voorandere:chmod o-r.
Toewijzen van schrijven rechten aan groep en overschrijven van bestaande rechten: chmod g=w.
Hoe machtigingen te wijzigen met behulp van absolute modus
Absolute modus gebruikt getallen om rechten te representeren en wiskundige operatoren om ze te wijzigen.
| Het volgende tabel laat zien hoe we relevante rechten kunnen toewijzen: | RECHT |
| TOEWIJZING RECHT | lezen |
| toevoegen 4 | schrijven |
| toevoegen 2 | uitvoeren |
toevoegen 1
| Rechten kunnen worden ingetrokken met behulp van aftrekking. Het volgende tabel laat zien hoe u relevante rechten kunt verwijderen. | RECHT |
| INGETROKKEN RECHT | lezen |
| aftrekken 4 | schrijven |
| aftrekken 2 | uitvoeren |
aftrekken 1
- Voorbeeld:
Stel lezen (toevoegen 4) in voor gebruiker, lezen (toevoegen 4) en uitvoeren (toevoegen 1) in voor groep en alleen uitvoeren (toevoegen 1) voor anderen.
chmod 451 bestandnaam
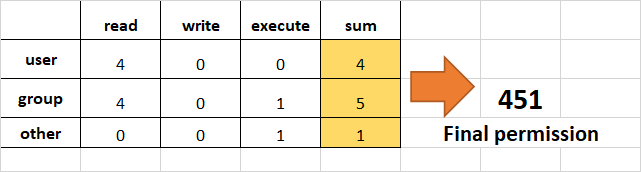
Dit is hoe we de berekening hebben uitgevoerd:
- Zie dat dit hetzelfde is als
r--r-x--x.
Verwijder uitvoeren rechten van anders en groep.
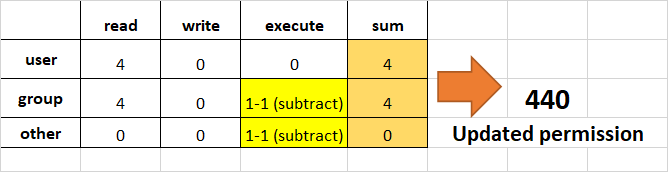
- Om uitvoeren rechten van
andersengroepte verwijderen, aftrekken we 1 van de uitvoeren onderdeel van de laatste 2 bytes.
Toewijzen lezen, schrijven en uitvoeren aan gebruiker, lezen en uitvoeren aan groep en alleen lezen aan anderen.

Dit zou hetzelfde zijn als rwxr-xr--.
Hoe om eigenaar te wijzigen met de chown commando
Volgend, zal ik leren hoe u de eigenaar van een bestand kunt wijzigen. U kunt de eigenaar van een bestand of map wijzigen met behulp van het chown commando. In sommige gevallen vereist het wijzigen van de eigenaar sudo-rechten.
chown user filename
Syntaxis van chown:
Hoe eigenaar van gebruiker te wijzigen met chown
Laat ons de eigenaar overschrijven van de gebruiker zaira naar de gebruiker news.

chown news mymotd.sh
Commando om de eigenaar te wijzigen: sudo chown news mymotd.sh.

Uitvoer:
Hoe eigenaar en groepsbeheerder tegelijkertijd te wijzigen
chown user:group filename
We kunnen ook chown gebruiken om eigenaar en groepsbeheerder tegelijkertijd te wijzigen.
Hoe mapeigenaar te wijzigen
chown -R admin /opt/script
U kunt eigenaar recursief wijzigen voor inhoud in een map. Het voorbeeld hieronder wijzigt de eigenaar van de map /opt/script zodat de gebruiker admin toegang krijgt.
Hoe groepsbeheerder te wijzigen
chown :admins /opt/script
In gevalen dat we alleen de groepsbeheerder willen wijzigen, kunnen we chown gebruiken door de groepsnaam vooraf te zetten met een kolon :
Hoe tussen gebruikers te schakelen
[user01@host ~]$ su user02
Password:
[user02@host ~]$
U kunt van gebruiker wisselen met de `su`-opdracht.
Hoe u superuser-toegang krijgt
De superuser of de root-gebruiker heeft de hoogste toegangsniveau op een Linux-systeem. De root-gebruiker kan elke bewerking op het systeem uitvoeren. De root-gebruiker kan alle bestanden en mappen bereiken, software installeren of verwijderen, en systeemconfiguraties wijzigen of overschrijven.
Met grote macht komt grote verantwoordelijkheid. Als de root-gebruiker wordt aangevallen, kan iemand volledige controle over het systeem krijgen. Het wordt aangeraden de root-gebruikersaccount alleen bij nodig te gebruiken.
[user01@host ~]$ su
Password:
[root@host ~]Als u de gebruikersnaam overslaat, de `su`-opdracht stapt automatisch over op het root-gebruikersaccount.
#
Een andere variant van de `su`-opdracht is `su -`. De `su`-opdracht stapt over op het root-gebruikersaccount maar verandert geen omgevingsvariabelen. De `su -`-opdracht stapt over op het root-gebruikersaccount en verandert de omgevingsvariabelen naar die van de doelgebruiker.
Opdrachten met sudo uitvoeren
Om opdrachten uit te voeren als de `root`-gebruiker zonder over te stappen op het `root`-gebruikersaccount, kunt u de `sudo`-opdracht gebruiken. De `sudo`-opdracht laat u opdrachten uitvoeren met verhoogde privileges.
Uitvoeren van opdrachten met `sudo` is een veiligere optie dan het uitvoeren van opdrachten als de `root`-gebruiker. Dit omdat alleen een specifiek geval van gebruikers de toestemming krijgt om opdrachten uit te voeren met `sudo`. Dit is gedefinieerd in het bestand `/etc/sudoers`.
Also, sudo legt alle commando’s die ermee uitgevoerd worden vast, wat een controlespoor biedt van wie welke commando’s heeft uitgevoerd en wanneer.
cat /var/log/auth.log | grep sudo
In Ubuntu kun je de audit logs hier vinden:
user01 is not in the sudoers file. This incident will be reported.
Voor een gebruiker die geen toegang heeft tot sudo, wordt dit gemarkeerd in logs en wordt er een bericht zoals dit gegeven:
Locale gebruikersaccounts beheren
Gebruikers vanaf de commandoregel aanmaken
sudo useradd username
Het commando om een nieuwe gebruiker toe te voegen is:
Dit commando stelt een thuismap van de gebruiker in en creëert een privégroep genoemd naar de gebruikersnaam. Op dit moment heeft het account geen geldig wachtwoord, waardoor de gebruiker niet kan inloggen totdat er een wachtwoord is aangemaakt.
Bestaande gebruikers wijzigen
Het usermod commando wordt gebruikt om bestaande gebruikers te wijzigen. Hier zijn enkele veelgebruikte opties die met het usermod commando worden gebruikt:
- Hier zijn enkele voorbeelden van het
usermodcommando in Linux: - Wijzig de gebruikersnaam waarmee iemand kan inloggen:
- Wijzig een gebruikers thuismap:
- Voeg een gebruiker toe aan een bijzondere groep:
- Wijzig de shell van een gebruiker:
- Vergrendel een gebruikers account:
- Ontgrendel een gebruikersaccount:
- Stel een vervaldatum in voor een gebruikersaccount:
- Wijzig de gebruikers-ID (UID) van een gebruiker:
- Wijzig de hoofdgroep van een gebruiker:
Een gebruiker uit een bijgroep verwijderen:
Gebruikers verwijderen
- Het
userdelcommando wordt gebruikt om een gebruikersaccount en gerelateerde bestanden van het systeem te verwijderen. sudo userdel username: verwijdert de gegevens van de gebruiker uit/etc/passwdmaar behoudt de thuismap van de gebruiker.
Het sudo userdel -r username commando verwijdert de gegevens van de gebruiker uit /etc/passwd en verwijdert ook de thuismap van de gebruiker.
Wijzigen van gebruikerswachtwoorden
- Het
passwdcommando wordt gebruikt om een gebruikerswachtwoord te wijzigen.
sudo passwd username: stelt het initiale wachtwoord in of wijzigd het bestaande wachtwoord van username. Het wordt ook gebruikt om het wachtwoord van de huidig ingelogde gebruiker te wijzigen.
8.2 Verbinden met externe servers via SSH
Vertaling:
Toegang tot externe servers is een van de essentiële taken voor systeembeheerders. U kunt verbinding maken met verschillende servers of toegang krijgen tot databases via uw lokale machine en opdrachten uitvoeren, allemaal met behulp van SSH.
Wat is het SSH-protocol?
SSH staat voor Secure Shell. Het is een cryptografisch netwerkprotocol dat veilige communicatie tussen twee systemen mogelijk maakt.
De standaardpoort voor SSH is 22.
- De twee deelnemers bij communicatie via SSH zijn:
- De server: de machine waartoe u toegang wilt.
De client: het systeem van waaruit u toegang tot de server zoekt.
- Verbinding met een server gaat als volgt:
- Verbindingsinitiatie: De client stuurt een verbindingsverzoek naar de server.
- Wissel van Sleutels: De server stuurt zijn publieke sleutel naar de client. Beiden komen overeen over de te gebruiken encryptiemethoden.
- Sessiesleutelgeneratie: De client en server gebruiken het Diffie-Hellman-sleuteluitwisselingsprotocol om een gedeelde sessiesleutel aan te maken.
- Client Authenticatie: De cliënt logt in op de server met een wachtwoord, een private sleutel of een andere methode.
Beveiligde Communicatie: Na authenticatie communiceren de cliënt en de server veilig met encryptie.
Hoe om verbinding te maken met een externe server met behulp van SSH?
Het commando ssh is een ingebouwd hulpmiddel in Linux en is ook standaard. Het maakt het aanroepen van servers erg gemakkelijk en veilig.
Hier spreken we over hoe de cliënt een verbinding maakt met de server.
- Voordat u verbinding maakt met een server, moet u de volgende informatie hebben:
- De IP-adres of het domeinnaam van de server.
- Het gebruikersnaam en wachtwoord van de server.
Het poortnummer waar u toegang toe heeft op de server.
ssh username@server_ip
De basisexpressie van het commando ssh is:
ssh [email protected]
Bijvoorbeeld, als uw gebruikersnaam is john en het server IP is 192.168.1.10, zal het commando zijn:
[email protected]'s password:
Welcome to Ubuntu 20.04.2 LTS (GNU/Linux 5.4.0-70-generic x86_64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/advantage
System information as of Fri Jun 5 10:17:32 UTC 2024
System load: 0.08 Processes: 122
Usage of /: 12.3% of 19.56GB Users logged in: 1
Memory usage: 53% IP address for eth0: 192.168.1.10
Swap usage: 0%
Last login: Fri Jun 5 09:34:56 2024 from 192.168.1.2
john@hostname:~$ Na dat zal u gevraagd worden om het geheime wachtwoord in te voeren. Uw scherm zal er ongeveer zo uitzien:
# start invoer commando’s
U kunt nu de relevante commando’s op de server 192.168.1.10 uitvoeren.
ssh -p port_number username@server_ip
⚠️ Het standaard poort voor ssh is 22 maar hij is ook kwetsbaar, want黑客 zal waarschijnlijk hier eerst proberen. Uw server kan een ander poort exposeren en de toegang delen met u. Om verbinding te maken met een andere poort, gebruikt u de optie -p.
8.3. Geavanceerde Log doorlading en Analyse
Logbestanden, als geconfigureerd, worden door uw systeem voor verschillende nuttige redenen gegenereerd. Ze kunnen gebruikt worden om systeemgebeurtenissen te volgen, systeemprestaties te monitoren en problemen op te lossen. Ze zijn speciaal nuttig voor systeembeheerders waarmee ze toepassingsfouten, netwerkgebeurtenissen en gebruikersactiviteit kunnen volgen.
Hier is een voorbeeld van een logbestand:
2024-04-25 09:00:00 INFO Startup: Application starting
2024-04-25 09:01:00 INFO Config: Configuration loaded successfully
2024-04-25 09:02:00 DEBUG Database: Database connection established
2024-04-25 09:03:00 INFO User: New user registered (UserID: 1001)
2024-04-25 09:04:00 WARN Security: Attempted login with incorrect credentials (UserID: 1001)
2024-04-25 09:05:00 ERROR Network: Network timeout on request (ReqID: 456)
2024-04-25 09:06:00 INFO Email: Notification email sent (UserID: 1001)
2024-04-25 09:07:00 DEBUG API: API call with response time over threshold (Duration: 350ms)
2024-04-25 09:08:00 INFO Session: User session ended (UserID: 1001)
2024-04-25 09:09:00 INFO Shutdown: Application shutdown initiated
# voorbeeld logbestand
- Een logbestand bevat gewoonlijk de volgende kolommen:
- Timestamp: De datum en tijd waarop het gebeurtenis plaatsvond.
- Log Level: De ernst van het gebeurtenis (INFO, DEBUG, WARN, ERROR).
- Component: Het systeemonderdeel dat het gebeurtenis genereerde (Startup, Config, Database, User, Security, Network, Email, API, Session, Shutdown).
- Bericht: Een beschrijving van het gebeurde evenement.
Aanvullende informatie: Aanvullende informatie die gerelateerd is aan het evenement.
In real-time systemen zijn logbestanden vaak kilometers lang en worden ze elke seconde aangemaakt. Het hangt af van de configuratie hoe lang en uitgebreid ze zijn. Elke kolom in een logbestand is een stuk informatie dat kan worden gebruikt om problemen te traceren. Dit maakt logbestanden moeilijk te lezen en te verstaan met de hand.
Daar komt log parsing voor. Log parsing is het proces van nuttige informatie uit logbestanden te halen. Het bestaat uit het verdelen van logbestanden in kleinere, gemakkelijker te beheren delen, en het uitvoeren van relevante informatie.
De gefilterde informatie kan ook nuttig zijn voor het maken van waarschuwingen, rapporten en dashboards.
In deze sectie zult u een aantal technieken voor het parsen van logbestanden in Linux verkennen.
Tekst extractie met behulp van `grep`
`grep` is een ingebouwde bash-hulpmiddel. Het staat voor “global regular expression print”. `grep` wordt gebruikt om strings in bestanden te matchen.
- Hier zijn enkele algemene toepassingen van `grep`:
- Deze opdracht zoekt naar “zoek_tekst” in het bestand genaamd
bestandsnaam. - Deze opdracht zoekt naar “
zoek_tekst” in alle bestanden binnen de opgegeven map en haar submappen. - Deze opdracht voert een hoofdletterongevoelig zoekactie uit voor “zoek_tekst” in het bestand genaamd
bestandsnaam. - Deze opdracht toont de regelnummers samen met de overeenkomende regels in het bestand genaamd
bestandsnaam. - Deze opdracht telt het aantal regels dat “zoekstring” bevat in het bestand genaamd
bestandsnaam. - Deze opdracht toont alle lijnen die “zoek_string” in het bestand met de naam
filenameniet bevatten. - Deze opdracht zoekt naar het hele woord “woord” in het bestand met de naam
filename.
Deze opdracht staat het gebruik van uitgebreide reguliere expressies toe voor complexere patroonvergelijking in het bestand met de naam filename.
💡 Tip: Als er meerdere bestanden in een map zijn, kunt u de onderstaande opdracht gebruiken om de lijst met bestanden te vinden die de gewenste teksten bevatten.
grep -l "String to Match" /path/to/directory
# vind de lijst van bestanden die de gewenste teksten bevatten
Datatextractie met sed
sed staat voor “stream editor”. Het verwerkt data stroomopwaarts, wat betekent dat het een lijn tegelijk leest. sed laat u toe om patronen te zoeken en acties uit te voeren op de lijnen die overeenkomen met die patronen.
Basis syntaxis vansed:
sed [options] 'command' file_name
De basis syntaxis van sed is als volgt:
Hierin is commando gebruikt om acties zoals vervanging, verwijdering, insering enzovoort uit te voeren op de tekstgegevens. Het bestandsnaam is de naam van het bestand dat u wilt verwerken.
sedgebruik:
1. Vervanging:
sed 's/old-text/new-text/' filename
Het s vlag wordt gebruikt om tekst te vervangen. Het oude-teken wordt vervangen door nieuw-teken:
sed 's/error/warning/' system.log
Bijvoorbeeld, om alle voorvallen van “fout” te veranderen in “waarschuwing” in het logbestand system.log:
2. Printen van regels die een specifiek patronen bevatten:
sed -n '/pattern/p' filename
Gebruik sed om regels te filteren en weer te geven die overeenkomen met een specifiek patronen:
sed -n '/ERROR/p' system.log
Bijvoorbeeld, om alle regels die “FOUT” bevatten te vinden:
3. Verwijderen van regels die een specifiek patronen bevatten:
sed '/pattern/d' filename
U kunt regels uit het resultaat verwijderen die overeenkomen met een specifiek patronen:
sed '/DEBUG/d' system.log
Bijvoorbeeld, om alle regels die “DEBUG” bevatten te verwijderen:
4. Uitlezen van specifieke velden uit een loglijn:
sed -n 's/^\([0-9]\{4\}-[0-9]\{2\}-[0-9]\{2\}\).*/\1/p' system.log
U kunt gebruik maken van reguliere expressies om delen van regels te extraheren. Veronderstel dat elke logregel begint met een datum in het formaat “JJJJ-MM-DD”. U zou de datum kunnen extraheren uit elke regel:
Tekst分析的 met awk
awk heeft de mogelijkheid om gemakkelijk elke regel op te splitsen in velden. Het is goed geschikt voor het verwerken van gestructureerde tekst zoals logbestanden.
Basis syntaxis vanawk
awk 'pattern { action }' file_name
De basis syntaxis van awk is:
Hierbij is patroon een voorwaarde die moet worden voldaan vooraleer de actie wordt uitgevoerd. Als het patroon wordt weggelaten, wordt de actie uitgevoerd op elke regel.
2024-04-25 09:00:00 INFO Startup: Application starting
2024-04-25 09:01:00 INFO Config: Configuration loaded successfully
2024-04-25 09:02:00 INFO Database: Database connection established
2024-04-25 09:03:00 INFO User: New user registered (UserID: 1001)
2024-04-25 09:04:00 INFO Security: Attempted login with incorrect credentials (UserID: 1001)
2024-04-25 09:05:00 INFO Network: Network timeout on request (ReqID: 456)
2024-04-25 09:06:00 INFO Email: Notification email sent (UserID: 1001)
2024-04-25 09:07:00 INFO API: API call with response time over threshold (Duration: 350ms)
2024-04-25 09:08:00 INFO Session: User session ended (UserID: 1001)
2024-04-25 09:09:00 INFO Shutdown: Application shutdown initiated
INFO
- In de komende voorbeelden, zal u gebruik maken van dit logbestand als voorbeeld:
Toegang tot kolommen metawk
zaira@zaira-ThinkPad:~$ awk '{ print $1 }' sample.log
De velden in awk (standaard gescheiden door spaties) kunnen worden benaderd met behulp van $1, $2, $3, enzovoort.
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
zaira@zaira-ThinkPad:~$ awk '{ print $2 }' sample.log
# uitvoer
09:00:00
09:01:00
09:02:00
09:03:00
09:04:00
09:05:00
09:06:00
09:07:00
09:08:00
09:09:00
- # uitvoer
awk '/ERROR/ { print $0 }' logfile.log
Print regels die een bepaald patroon bevatten (bijvoorbeeld, ERROR)
2024-04-25 09:05:00 ERROR Network: Network timeout on request (ReqID: 456)
# uitvoer
- Dit print alle regels die “ERROR” bevatten.
awk '{ print $1, $2 }' logfile.log
Extraher de eerste veld (Datum en Tijd)
2024-04-25 09:00:00
2024-04-25 09:01:00
2024-04-25 09:02:00
2024-04-25 09:03:00
2024-04-25 09:04:00
2024-04-25 09:05:00
2024-04-25 09:06:00
2024-04-25 09:07:00
2024-04-25 09:08:007
2024-04-25 09:09:00
# uitvoer
- Dit zal de eerste twee velden uit elke regel extraheren, die in dit geval de datum en tijd zijn.
awk '{ count[$3]++ } END { for (level in count) print level, count[level] }' logfile.log
Samenvatten van voorkomens van elk logniveau
1
WARN 1
ERROR 1
DEBUG 2
INFO 6
# uitvoer
- De uitvoer zal een samenvatting zijn van het aantal voorkomens van elk logniveau.
awk '{ $3="INFO"; print }' sample.log
Filter specifieke velden uit (bijvoorbeeld, waar het 3e veld INFO is)
2024-04-25 09:00:00 INFO Startup: Application starting
2024-04-25 09:01:00 INFO Config: Configuration loaded successfully
2024-04-25 09:02:00 INFO Database: Database connection established
2024-04-25 09:03:00 INFO User: New user registered (UserID: 1001)
2024-04-25 09:04:00 INFO Security: Attempted login with incorrect credentials (UserID: 1001)
2024-04-25 09:05:00 INFO Network: Network timeout on request (ReqID: 456)
2024-04-25 09:06:00 INFO Email: Notification email sent (UserID: 1001)
2024-04-25 09:07:00 INFO API: API call with response time over threshold (Duration: 350ms)
2024-04-25 09:08:00 INFO Session: User session ended (UserID: 1001)
2024-04-25 09:09:00 INFO Shutdown: Application shutdown initiated
INFO
# uitvoer
Deze opdracht zal alle regels extraheren waar het 3e veld “INFO” is.
💡 Tip: De standaardscheidingsteken in awk is een spatie. Als uw logbestand een ander scheidingsteken gebruikt, kunt u dit specificeren met de -F optie. Bijvoorbeeld, als uw logbestand een dubbele punt gebruikt als scheidingsteken, kunt u awk -F: '{ print $1 }' logfile.log gebruiken om het eerste veld te extraheren.
Logbestanden parsen met cut
De cut opdracht is een eenvoudige maar krachtige opdracht die wordt gebruikt om secties van tekst uit elke regel van invoer te extraheren. Omdat logbestanden gestructureerd zijn en elk veld wordt gescheiden door een specifiek teken, zoals een spatie, tab of een aangepast scheidingsteken, doet cut uitstekend werk bij het extraheren van die specifieke velden.
cut [options] [file]
De basis syntaxis van de cut opdracht is:
- Enkele veelgebruikte opties voor de cut opdracht:
-d: Specificeert een scheidingsteken dat wordt gebruikt als veldscheider.-f: Selecteert de weer te geven velden.
-c : Geeft karaktersposities aan.
cut -d ' ' -f 1 logfile.log
Bijvoorbeeld, het onderstaande commando zou het eerste veld (gescheiden door een spatie) uit elke regel van het logbestand extraheren:
Voorbeelden van gebruikcutvoor log parsing
2024-04-25 08:23:01 INFO 192.168.1.10 User logged in successfully.
2024-04-25 08:24:15 WARNING 192.168.1.10 Disk usage exceeds 90%.
2024-04-25 08:25:02 ERROR 10.0.0.5 Connection timed out.
...
Stel dat je een logbestand hebt met de volgende structuur, waarbij de velden worden gescheiden door spaties:
cutkan op de volgende manieren worden gebruikt:
cut -d ' ' -f 2 system.log
De tijd uit elke logingang extraheren:
08:23:01
08:24:15
08:25:02
...
# Output
- Dit commando gebruikt een spatie als scheidingsteken en selecteert het tweede veld, dat het tijdcomponent van elke logingang is.
cut -d ' ' -f 4 system.log
IP-adressen uit de logs extraheren:
192.168.1.10
192.168.1.10
10.0.0.5
# Output
- Dit commando extrahert het vierde veld, dat het IP-adres van elke logingang is.
cut -d ' ' -f 3 system.log
Log niveaus extraheren (INFO, WARNING, ERROR):
INFO
WARNING
ERROR
# Output
- Dit extrahert het derde veld dat het log niveau bevat.
Combinerencutmet andere commando’s:
grep "ERROR" system.log | cut -d ' ' -f 1,2
De uitvoer van andere commando's kan worden doorgesluisd naar het commando cut. Laten we zeggen dat je logs wilt filteren voordat je ze snijdt. Je kunt grep gebruiken om regels die "ERROR" bevatten te extraheren en vervolgens cut gebruiken om specifieke informatie uit die regels te krijgen:
2024-04-25 08:25:02
# Output
- Deze opdracht filtert eerst regels die “ERROR” bevatten, en pakt vervolgens de datum en tijd uit deze regels.
Meerdere velden uitlezen:
cut -d ' ' -f 1,2,3 system.log`
Het is mogelijk om meerdere velden tegelijkertijd uit te lezen door een bereik of een door komma's gescheiden lijst van velden op te geven:
2024-04-25 08:23:01 INFO
2024-04-25 08:24:15 WARNING
2024-04-25 08:25:02 ERROR
...
# Uitvoer
De bovenstaande opdracht pakt de eerste drie velden van elke logboekregel die de datum, tijd en logniveau zijn.
Logbestanden parsen met sort en uniq
Sorteren en duplicaten verwijderen zijn common operaties bij het werken met logbestanden. De opdrachten sort en uniq zijn krachtige commando’s die gebruikt worden om de invoer te sorteren en duplicaten te verwijderen respectievelijk.
Basis syntaxis van sort
sort [options] [file]
Het commando sort orgineert regels van tekst alfabetisch of numeriek.
- Enkele belangrijke opties voor het sort commando:
-n: Sorteert het bestand op basis van het aannemen dat de inhoud numeriek is.-r: Spiegelt de volgorde van de sorteer.-k: Geeft een sleutel of kolomnummer op om op te sorteren.
-u: Sorteert en verwijdert dubbele regels.
De opdracht uniq wordt gebruikt om door te filteren of tellen en rapporteren van herhaalde regels in een bestand.
uniq [options] [input_file] [output_file]
De syntaxis van uniq is:
- Enkele belangrijke opties voor de opdracht
uniqzijn: -c: Voorvoegt getallen toe aan regels die het aantal optredens aangeven.-d: Print alleen dubbele regels.
-u: Print alleen unieke regels.
Voorbeelden van het gebruik van sort en uniq samen voor logboekverwerking
2024-04-25 INFO User logged in successfully.
2024-04-25 WARNING Disk usage exceeds 90%.
2024-04-26 ERROR Connection timed out.
2024-04-25 INFO User logged in successfully.
2024-04-26 INFO Scheduled maintenance.
2024-04-26 ERROR Connection timed out.
- Veronderstel dat we de volgende voorbeelden logboekinvoeringen hebben voor deze demonstraties:
sort system.log
Sorteren logboekinvoeringen op datum:
2024-04-25 INFO User logged in successfully.
2024-04-25 INFO User logged in successfully.
2024-04-25 WARNING Disk usage exceeds 90%.
2024-04-26 ERROR Connection timed out.
2024-04-26 ERROR Connection timed out.
2024-04-26 INFO Scheduled maintenance.
# Uitvoer
- Dit sorteert de logboekinvoeringen alfabetisch, wat effectief het sorteren op datum wordt als de datum het eerste veld is.
sort system.log | uniq
Sorteren en duplicaten verwijderen:
2024-04-25 INFO User logged in successfully.
2024-04-25 WARNING Disk usage exceeds 90%.
2024-04-26 ERROR Connection timed out.
2024-04-26 INFO Scheduled maintenance.
# Uitvoer
- Deze opdracht sorteert het logbestand en pijpt het naar
uniq, waardoor duplicaten worden verwijderd.
sort system.log | uniq -c
Tellen van optredens van elke regel:
2 2024-04-25 INFO User logged in successfully.
1 2024-04-25 WARNING Disk usage exceeds 90%.
2 2024-04-26 ERROR Connection timed out.
1 2024-04-26 INFO Scheduled maintenance.
# Uitvoer
- Sorteert de logboekinvoeringen en telt daarna elke unieke regel. Volgens de uitvoer is de regel
'2024-04-25 INFO Gebruiker is succesvol ingelogd.'2 keer aanwezig in het bestand.
sort system.log | uniq -u
Unieke logboekposten identificeren:
2024-04-25 WARNING Disk usage exceeds 90%.
2024-04-26 INFO Scheduled maintenance.
# Uitvoer
- Deze opdracht toont lijnen die uniek zijn.
sort -k2 system.log
Sorteren op logboekniveau:
2024-04-26 ERROR Connection timed out.
2024-04-26 ERROR Connection timed out.
2024-04-25 INFO User logged in successfully.
2024-04-25 INFO User logged in successfully.
2024-04-26 INFO Scheduled maintenance.
2024-04-25 WARNING Disk usage exceeds 90%.
# Uitvoer
Sorteert de posten op basis van het tweede veld, dat het logboekniveau is.
8.4. Beheren van Linux-processen via de commandoregel
- Een proces is een lopend exemplaar van een programma. Een proces bestaat uit:
- Een adresruimte van toegewezen geheugen.
- Processtatussen.
Eigenschappen zoals eigenaarshouding, beveiligingsattributen en resourcegebruik.
- Een proces heeft ook een omgeving die bestaat uit:
- Lokale en globale variabelen
- Het huidige planningcontext
Toegekende systeembronnen, zoals netwerkpoorten of bestandendescriptoren.
Als u de opdracht ls -l uitvoert, creëert het besturingssysteem een nieuw proces om de opdracht uit te voeren. Het proces heeft een ID, een status en loopt tot de opdracht voltooid is.
Inzicht in procesaanmaken en levenscyclus
In Ubuntu worden alle processen afkomstig van het initiale systeemproces dat systemd heet, dat het eerste proces is dat de kernel tijdens het opstarten start.
Het systemd-proces heeft een proces-ID (PID) van 1 en is verantwoordelijk voor het initialiseren van het systeem, het starten en beheren van andere processen en het afhandelen van systeemdiensten. Alle andere processen op het systeem zijn afgeleid van systemd.
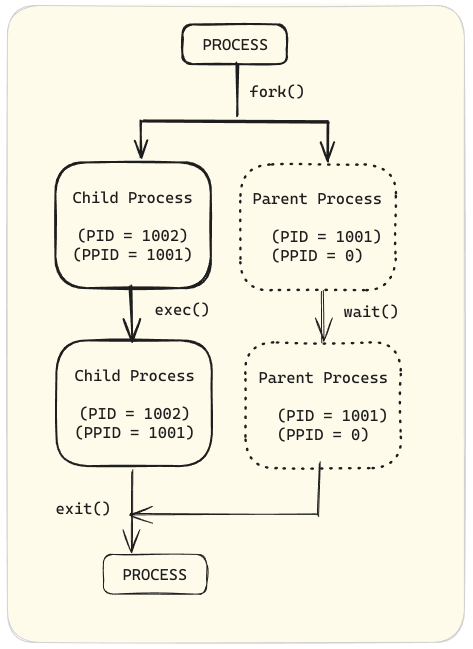
Een ouder proces kopieert zijn eigen adresruimte (fork) om een nieuw (kind) processtructuur te creëren. Elk nieuw proces wordt een unieke proces-ID (PID) toegewezen voor het volgen en voor de veiligheid. De PID en de PID van het ouderproces (PPID) behoren tot het nieuwe procesmilieu. Elk proces kan een kindproces aanmaken.
Met behulp van de fork-routine erft een kindproces de veiligheidsidentiteiten, vorige en huidige bestanden描述符, poort- en resourcerechten, omgevingsvariabelen en programmacode van zijn ouderproces. Een kindproces kan dan zijn eigen programmacode uitvoeren.
Gebruikelijk is dat een ouderproces slaapt terwijl het kindproces draait, en dat het een verzoek (wait) stelt om te worden geïnformeerd wanneer het kindklaar is.
Bij het verlaten van het kindproces heeft het al zijn middelen en omgeving geclosseerd of verwerkt. Het enige overblijvende middel, dat een zombie wordt genoemd, is een invoer in de proceslijst. Het ouderproces wordt als wakker gemarkeerd wanneer het kind afgaat, en het schoonmaakt de proceslijst van het kind, vrijmakend hiermee het laatste middel van het kindproces. Het ouderproces draait vervolgens zijn eigen programmacode uit.
Het begrijpen van de processestaten.

Processen in Linux komen in verschillende staten voor tijdens hun levenscyclus. De status van een proces geeft aan wat het proces momenteel doet en hoe het interactie heeft met het systeem. Processen schakelen tussen staten op basis van hun uitvoeringsstatus en het scheduleralgoritme van het systeem.
| Processen in een Linuxsysteem kunnen in één van de volgende staten zijn: | Status |
| Beschrijving | (nieuw) |
| Initiële status als een proces is aangemaakt via een fork-systeemoproep. | Klaar om te draaien (gereed) (R) |
| Proces is klaar om te draaien en wacht op schemaalgoritme op een CPU. | Draaiend (gebruiker) (R) |
| Proces executeert in gebruikersmodus, draaiende gebruikerstoepassingen. | Draaiend (kernel) (R) |
| Proces executeert in kernelmodus, afhandelen systeemoproeven of hardwareinterrupts. | slapend (S) |
| Proces wacht op een gebeurtenis (bijvoorbeeld, I/O-bewerking) af te ronden en kan gemakkelijk worden ontwaakten. | slapend (ononderbroken) (D) |
| Proces is in een ononderbroken slaapstatus, wachtend op een specifieke conditie (meestal I/O) af te ronden, en kan niet worden onderbroken door signaal. | slapend (schijf slapend) (K) |
| Proces wacht op schijfI/O-bewerkingen af te ronden. | slapend (idle) (I) |
| Proces is idle, doet geen werk en wacht op een gebeurtenis te gebeuren. | Gestopt (T) |
| De processusuitvoering is gestopt, meestal door een signaal, en kan later hervat worden. | Zombie (Z) |
De processus is uitgevoerd maar heeft nog een entry in de processustabel, wachtend op het lezen van de afsluitstatus door zijn ouder.
| De processen gaan van de ene naar de andere toestand op de volgende manieren: | Overgang |
| Beschrijving | Fork |
| Maakt een nieuw proces vanuit een ouderproces, gaat van (nieuw) naar Runnable (klaar) (R). | Plan |
| De scheduler selecteert een uitvoerbaar proces, gaat het naar de staat Running (gebruiker) of Running (kernel). | Uitvoeren |
| Proces gaat van Runnable (klaar) (R) naar Running (kernel) (R) wanneer het wordt gepland voor uitvoering. | Preempt of Herplan |
| Proces kan worden gepreempt of hergepland, verplaatsend het terug naar Runnable (klaar) (R). | Syscall |
| Proces maakt een systeemoproep, gaat van Running (gebruiker) (R) naar Running (kernel) (R). | Terugkeren |
| Proces heeft een systeemoproep afgerond en keert terug naar Running (gebruiker) (R). | Wachten |
| Proces wacht op een gebeurtenis, gaat van Running (kernel) (R) naar een van de slaaptoestanden (S, D, K, of I). | Gebeurtenis of Signaal |
| Proces wordt door een gebeurtenis of signaal ontwaakt, waardoor het terugkeert van een slaaptoestand naar klaar (R). | Suspend |
| Proces wordt geschorst, waardoor het overgaat van uitvoering (kernel) of klaar naar gestopt (T). | Resume |
| Proces wordt hervat, waardoor het overgaat van gestopt (T) terug naar klaar (R). | Exit |
| Proces beëindigt zijn activiteit, waardoor het overgaat van uitvoering (gebruiker) of uitvoering (kernel) naar zombie (Z). | Reap |
Hoofdproces leest het afsluitingsresultaat van de zombie-proces en verwijdert het uit de proces-tabel.
Hoe processen te bekijken
zaira@zaira:~$ ps aux
U kunt de opdracht ps gebruiken in combinatie met een keuze van opties om processen op een Linux-systeem te bekijken. De ps-opdracht wordt gebruikt om informatie weer te geven over een selectie actieve processen. Bijvoorbeeld, ps aux toont alle processen die op het systeem zijn actief.
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.0 168140 11352 ? Ss May21 0:18 /sbin/init splash
root 2 0.0 0.0 0 0 ? S May21 0:00 [kthreadd]
root 3 0.0 0.0 0 0 ? I< May21 0:00 [rcu_gp]
root 4 0.0 0.0 0 0 ? I< May21 0:00 [rcu_par_gp]
root 5 0.0 0.0 0 0 ? I< May21 0:00 [slub_flushwq]
root 6 0.0 0.0 0 0 ? I< May21 0:00 [netns]
root 11 0.0 0.0 0 0 ? I< May21 0:00 [mm_percpu_wq]
root 12 0.0 0.0 0 0 ? I May21 0:00 [rcu_tasks_kthread]
root 13 0.0 0.0 0 0 ? I May21 0:00 [rcu_tasks_rude_kthread]
*... output truncated ....*
# Uitvoer
- De bovenstaande uitvoer toont een momentopname van de huidige processen op het systeem. Elke rij vertegenwoordigt een proces met de volgende kolommen:
USER: De gebruiker die eigenaar is van het proces.PID: Het proces-ID.%CPU: De CPU-gebruik van het proces.%MEM: Het geheugengebruik van het proces.VSZ: De virtuele geheugengrootte van het proces.RSS: De resident set size, dat is het niet-geswapte fysieke geheugen dat een taak heeft gebruikt.TTY: De controlerende terminal van het proces. Een?geeft aan dat er geen controlerende terminal is.Ss: Sessieleider. Dit is een proces dat een sessie heeft gestart en leider is van een groep processen en kan terminalsignalen beheren. De eersteSgeeft het slaapstatus aan, en de tweedesgeeft aan dat het een sessieleider is.START: De starttijd of -datum van het proces.TIME: De cumulatieve CPU-tijd.
COMMANDO: Het commando dat de processtart aanstuurde.
Achtergrond- en voorgrondprocessen
In dit gedeelte zult u leren hoe u taken kunt besturen door ze in de achtergrond of voorgrond uit te voeren.
Een taak is een proces dat wordt gestart door een shell. Als u een opdracht in de terminal uitvoert, wordt hij beschouwd als een taak. Een taak kan in de voorgrond of achtergrond worden uitgevoerd.
- Om de controle te demonstreren, zal u eerst drie processen aanmaken en daarna in de achtergrond ervan uitvoeren. Daarna zal u de processen vermelden en ze tussen de voorgrond en achtergrond afwisselen. U zult zien hoe u ze kan laten slapen of volledig afsluiten.
Twee Processen Aanmaken
Open een terminal en start drie langdurige processen. Gebruik het sleep-commando, dat het proces 300, 400 en 500 seconden lang draait.
sleep 300 &
sleep 400 &
sleep 500 &
# sleep commando voor 300, 400 en 500 seconden
- Het
&aan het eind van elk commando zorgt ervoor dat het proces naar de achtergrond wordt verplaatst.
Toon Achtergrondtaakken
jobs
Gebruik het jobs-commando om de lijst van achtergrondtaakken weer te geven.
jobs
[1] Running sleep 300 &
[2]- Running sleep 400 &
[3]+ Running sleep 500 &
- Het resultaat zou er ongeveer uitzien:
Breng een Achtergrondtaak naar de Voorgrond
fg %1
Om een achtergrondtaak naar de voorgrond te brengen, gebruik het fg-commando gevolgd door de taaknummer. Bijvoorbeeld, om de eerste taak (sleep 300) naar de voorgrond te brengen:
- Dit zal de taak
1naar de voorgrond brengen.
Verplaats de Voorgrondtaak Terug naar de Achtergrond
Terwijl de taak actief is in de voorgrond, kun je hem onderbreken en hem terug naar de achtergrond verplaatsen door Ctrl+Z te drukken om de taak te onderbreken.
zaira@zaira:~$ fg %1
sleep 300
^Z
[1]+ Stopped sleep 300
zaira@zaira:~$ jobs
Een onderbroken taak zal er ongeveer zo uitzien:
[1]+ Stopped sleep 300
[2] Running sleep 400 &
[3]- Running sleep 500 &
# onderbroken taak
Gebruik nu de opdracht bg om de taak met ID 1 voort te zetten in de achtergrond.
# Druk Ctrl+Z op om de voorgrondtaak te onderbreken
bg %1
- # En start hem vervolgens weer in de achtergrond
jobs
[1] Running sleep 300 &
[2]- Running sleep 400 &
[3]+ Running sleep 500 &
Toon de taken opnieuw
- In deze oefening heb je:
- Drie achtergrondprocessen gestart met behulp van slaapopdrachten.
- Gebruikt jobs om de lijst van achtergrondtaken weer te geven.
- Breng een taak naar de voorgrond met
fg %job_number. - Onderbrek de taak met
Ctrl+Zen zet hem terug naar de achtergrond metbg %job_number.
Gebruikte jobs opnieuw om de status van de achtergrondtaken te verifiëren.
Nu kun je goed hoe je taken kunt beheren.
Processen vermoorden
Het is mogelijk om een niet-reagerend of ongewenst proces te beëindigen met het kill-commando. Het kill-commando stuurt een signaal naar een proces-ID om het te beëindigen.
Er zijn verschillende opties beschikbaar met het kill-commando.
kill -l
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP
6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1
11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM
16) SIGSTKFLT 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP
21) SIGTTIN 22) SIGTTOU 23) SIGURG 24)
...terminated
# Opties beschikbaar met kill
- Hier zijn enkele voorbeelden van het
kill-commando in Linux: - Dit commando stuurt het standaard
SIGTERM-signaal naar het proces met PID 1234, met het verzoek om te beëindigen. - Dit commando stuurt het standaard
SIGTERM-signaal naar alle processen met de opgegeven naam. - Deze opdracht zendt het signaal
SIGKILLnaar het proces met PID 1234, het forceert het afsluiten. - Deze opdracht zendt het signaal
SIGSTOPnaar het proces met PID 1234, het stopt het.
Deze opdracht zendt het standaard signaal SIGTERM naar alle processen van de gespecificeerde gebruiker.
Deze voorbeelden demonstreren verschillende manieren om het kill commando te gebruiken om processen te beheren in een Linux omgeving.
Hier volgt de informatie over de kill commando opties en signalen in tabelvorm: Deze tabel geeft een overzicht van de meest gebruikte kill commando-opties en signalen die in Linux worden gebruikt voor het beheren van processen. |
Commando / Optie | Signaal |
| Beschrijving | kill <pid> |
SIGTERM |
| Vraagt het proces om netjes te beëindigen (standaardsignaal). | kill -9 <pid> |
SIGKILL |
| Verplicht het proces onmiddellijk te beëindigen zonder op te ruimen. | kill -SIGKILL <pid> |
SIGKILL |
| Houdt het proces onmiddellijk tegen zonder opruiming. | kill -15 <pid> |
SIGTERM |
Stuurt expliciet het signaal SIGTERM om een sierlijke beëindiging aan te vragen. |
kill -SIGTERM <pid> |
SIGTERM |
Stuurt expliciet het SIGTERM-signaal om een gedelegeerde beëindiging aan te vragen. |
kill -1 <pid> |
SIGHUP |
| Traditioneel betekent dit “ophangen”; kan worden gebruikt om configuratiebestanden opnieuw te laden. | kill -SIGHUP <pid> |
SIGHUP |
| Traditioneel betekent “hangen op”; kan worden gebruikt om configuratiebestanden opnieuw te laden. | kill -2 <pid> |
SIGINT |
Vraagt het proces om te beëindigen (hetzelfde als het indrukken van Ctrl+C in de terminal). |
kill -SIGINT <pid> |
SIGINT |
Vraagt het proces om te beëindigen (hetzelfde als het indrukken van Ctrl+C in de terminal). |
kill -3 <pid> |
SIGQUIT |
| Laat het proces beëindigen en produceert een core dump voor debugging. | kill -SIGQUIT <pid> |
SIGQUIT |
| Laat het proces beëindigen en produceert een core dump voor debugging. | kill -19 <pid> |
SIGSTOP |
| Pauzeert het proces. | kill -SIGSTOP <pid> |
SIGSTOP |
| Pauzeert het proces. | kill -18 <pid> |
SIGCONT |
| Hervat een gepauzeerd proces. | kill -SIGCONT <pid> |
SIGCONT |
| Hervat een gepauzeerd proces. | killall <name> |
Varieert |
| Verstuurt een signaal naar alle processen met de opgegeven naam. | killall -9 <name> |
SIGKILL |
| Forceert het beëindigen van alle processen met de gegeven naam. | pkill <patroon> |
Varieert |
| Stuurt een signaal naar processen op basis van een patroonmatch. | pkill -9 <patroon> |
SIGKILL |
| Forceert het beëindigen van alle processen die overeenkomen met het patroon. | xkill |
SIGKILL |
Grafisch hulpprogramma dat het mogelijk maakt om op een venster te klikken om het bijbehorende proces te beëindigen.
8.5. Standaard Input en Output Streams in Linux
- Het lezen van een input en schrijven van een output is een essentieel onderdeel van het begrijpen van de commandoregel en shell scripting. In Linux heeft elk proces drie standaard streams:
- De bestandsdescriptor voor
stdinis0. - Standaarduitvoer (
stdout): Dit is de standaard uitvoerstroom waar een proces zijn output schrijft. Standaard is de standaarduitvoer de terminal. De uitvoer kan ook worden omgeleid naar een bestand of een ander programma. De bestanddescriptor voorstdoutis1.
Standaardfout (stderr): Dit is de standaard foutstroom waar een proces zijn foutmeldingen schrijft. Standaard is de standaardfout de terminal, waardoor foutmeldingen zichtbaar zijn, zelfs als stdout wordt omgeleid. De bestanddescriptor voor stderr is 2.
Omleiding en Pijplijnen
Omleiding: U kunt de fout- en uitvoerstromen omleiden naar bestanden of andere commando's. Bijvoorbeeld:
ls > output.txt
# Standaarduitvoer omleiden naar een bestand
ls non_existent_directory 2> error.txt
# Standaardfout omleiden naar een bestand
ls non_existent_directory > all_output.txt 2>&1
# Zowel standaarduitvoer als standaardfout omleiden naar een bestand
- In het laatste commando,
ls non_existent_directory: lijst de inhoud van een map genaamd non_existent_directory. Aangezien deze map bestaat niet, zallseen foutmelding genereren.> all_output.txt: Het>-operator redirectt de standaarduitvoer (stdout) van dels-commando naar het bestandall_output.txt. Als het bestand bestaat niet, zal het worden aangemaakt. Als het bestand bestaat, zal zijn inhoud worden overschreven.
2>&1:: Hier, 2 vertegenwoordigt het bestandskaartje voor standaardfout (stderr). &1 vertegenwoordigt het bestandskaartje voor standaarduitvoer (stdout). Het &-teken wordt gebruikt om aan te geven dat 1 geen bestandsnaam maar een bestandskaartje is.
Zo, 2>&1 betekent “redirect stderr (2) naar waar stdout (1) momenteel heen gaat,” wat in dit geval naar het bestand all_output.txt gaat. Daarom zullen zowel de uitvoer (als die er zou zijn) en het foutbericht van ls naar all_output.txt geschreven worden.
Pijplijnen:
ls | grep image
Je kunt pijpen (|) gebruiken om de uitvoer van één commando als invoer voor een ander door te geven:
image-10.png
image-11.png
image-12.png
image-13.png
... Output truncated ...
# Uitvoer
8.6 Automatisering in Linux – Taken automatiseren met Cron Jobs
Cron is een krachtig hulpmiddel voor takenplanning dat beschikbaar is in Unix-achtige besturingssystemen. Door cron te configureren, kun je geautomatiseerde taken instellen die op dagelijkse, wekelijke, maandelijkse of andere specifieke tijden worden uitgevoerd. De automatiseringsmogelijkheden die cron biedt spelen een cruciale rol in Linux systeembeheer.
De crond daemon (een type computerprogramma dat op de achtergrond draait) maakt cron functionaliteit mogelijk. Cron leest de crontab (cron-tabellen) voor het uitvoeren van voorgedefinieerde scripts.
Met behulp van een specifieke syntaxis kun je een cron job configureren om scripts of andere commando’s automatisch uit te voeren.
Wat zijn cron jobs in Linux?
Elk taken dat je plande via crons wordt een cron job genoemd.
Laat nu eens zien hoe cron jobs werken.
Hoe toegang tot crons te beheren
Om cron jobs te gebruiken, moet een beheerder cron jobs toestaan om toegevoegd te worden voor gebruikers in het bestand /etc/cron.allow.
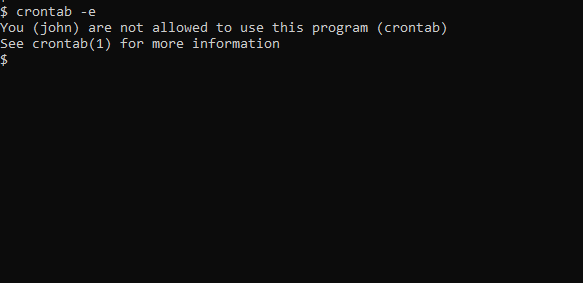
Als je zo’n prompt krijgt, betekent dit dat je geen toestemming hebt om cron te gebruiken.
![]()
Om John toe te staan crons te gebruiken, moet je zijn naam opnemen in /etc/cron.allow. Maak het bestand aan als het niet bestaat. Hierdoor kan John cron jobs aanmaken en bewerken.
Gebruikers kan ook de toegang tot cron jobs worden ontzegd door hun gebruikersnaam op te geven in het bestand /etc/cron.d/cron.deny.
Hoe voeg ik cron jobs toe in Linux
Als eerste, om cron jobs te gebruiken, moet je de status van de cron service controleren. Als cron niet is geïnstalleerd, kun je het eenvoudig downloaden via de pakketbeheerder. Controleer het als volgt:
sudo systemctl status cron.service
# Controleer cron-service op Linux-systeem
Syntaxis van cron-taken
- Crontabs gebruiken de volgende vlaggen voor het toevoegen en weergeven van cron-taken:
crontab -e: bewerkt crontab-items om cron jobs toe te voegen, te verwijderen of te bewerken.crontab -l: lijst met alle cron jobs voor de huidige gebruiker.crontab -u gebruikersnaam -l: lijst met crons van andere gebruikers.
crontab -u gebruikersnaam -e: de crons van een andere gebruiker bewerken.
Wanneer je crons opsomt en ze bestaan, zie je iets als dit:
* * * * * sh /path/to/script.sh
# Cron job voorbeeld
- In het bovenstaande voorbeeld,
* vertegenwoordigt respectievelijk minuut(en), uur(en), dag(en), maand(en) en weekdag(en). Details over deze waarden zijn hieronder beschreven: |
WAAI | |
| BESCHRIJVING | Minuten | 0-59 |
| De opdracht zal worden uitgevoerd op de specifieke minuut. | Uren | 0-23 |
| De opdracht zal worden uitgevoerd op de specifieke uur. | Dagen | 1-31 |
| Opdrachten zullen worden uitgevoerd op deze dagen van de maand. | Maanden | 1-12 |
| De maand waarin taken moeten worden uitgevoerd. | Weekdagen | 0-6 |
- Dagen van de week waarop taken worden uitgevoerd. Hierbij is 0 zondag.
shduidt op dat het script een bash-script is en moet worden uitgevoerd vanuit/bin/bash.
/path/to/script.sh specificeert de weg naar het script.
* * * * * sh /path/to/script/script.sh
| | | | | |
| | | | | Command or Script to Execute
| | | | |
| | | | |
| | | | |
| | | | Day of the Week(0-6)
| | | |
| | | Month of the Year(1-12)
| | |
| | Day of the Month(1-31)
| |
| Hour(0-23)
|
Min(0-59)
Hieronder is een overzicht van de syntaxis van het cron-taak:
Voorbeelden van cron-taken
| Er zijn hieronder enkele voorbeelden van het plannen van cron-taakken. | PLANDatum |
| Geplande waarde | 5 0 * 8 * |
| Om 00:05 in augustus. | 5 4 * * 6 |
| Om 04:05 op zaterdag. | 0 22 * * 1-5 |
Om 22:00 op elke weekdag van maandag tot en met vrijdag.
Het is oké als je dit niet allemaal in één keer kunt begrijpen. Je kunt oefenen en cron-schema’s genereren met de crontab guru website.
Hoe stel je een cron-taak in
- In dit gedeelte bekijken we een voorbeeld van hoe je een eenvoudig script kunt plannen met een cron-taak.
#!/bin/bash
echo `date` >> date-out.txt
Maak een script genaamd date-script.sh dat de systeemdatum en -tijd afdrukt en toevoegt aan een bestand. Het script wordt hieronder weergegeven:
chmod 775 date-script.sh
2. Maak het script uitvoerbaar door het uitvoeringsrechten te geven.
3. Voeg het script toe in de crontab met behulp van crontab -e.
*/1 * * * * /bin/sh /root/date-script.sh
Hier hebben we het zo gepland dat het elke minuut wordt uitgevoerd.
cat date-out.txt
4. Controleer de output van het bestand date-out.txt. Volgens het script zou de systeemdatum elke minuut naar dit bestand moeten worden afgedrukt.
Wed 26 Jun 16:59:33 PKT 2024
Wed 26 Jun 17:00:01 PKT 2024
Wed 26 Jun 17:01:01 PKT 2024
Wed 26 Jun 17:02:01 PKT 2024
Wed 26 Jun 17:03:01 PKT 2024
Wed 26 Jun 17:04:01 PKT 2024
Wed 26 Jun 17:05:01 PKT 2024
Wed 26 Jun 17:06:01 PKT 2024
Wed 26 Jun 17:07:01 PKT 2024
# output
Hoe crons te troubleshooten
Crons zijn erg nuttig, maar ze werken mogelijk niet altijd zoals bedoeld. Gelukkig zijn er enkele effectieve methoden die je kunt gebruiken om ze te troubleshooten.
1. Controleer het schema.
Ten eerste kun je proberen het schema te verifiëren dat is ingesteld voor de cron. Je kunt dat doen met de syntaxis die je in de bovenstaande secties hebt gezien.
2. Controleer de cron logs.
Eerst moet u controleren of de cron op de gewenste tijd is uitgevoerd. In Ubuntu kunt u dit controleren door de cron logs te raadplegen die zijn gelegen in /var/log/syslog.
Als er een entry is in deze logs op de correcte tijd, betekent dat de cron volgens het door u ingestelde schema is uitgevoerd.
1 Jun 26 17:02:01 zaira-ThinkPad CRON[27834]: (zaira) CMD (/bin/sh /home/zaira/date-script.sh)
2 Jun 26 17:02:02 zaira-ThinkPad systemd[2094]: Started Tracker metadata extractor.
3 Jun 26 17:03:01 zaira-ThinkPad CRON[28255]: (zaira) CMD (/bin/sh /home/zaira/date-script.sh)
4 Jun 26 17:03:02 zaira-ThinkPad systemd[2094]: Started Tracker metadata extractor.
5 Jun 26 17:04:01 zaira-ThinkPad CRON[28538]: (zaira) CMD (/bin/sh /home/zaira/date-script.sh)
Hieronder zijn de logs van ons cron-taak voorbeeld. Noteer de eerste kolom die de timestamps weergeeft. Het pad van het script wordt ook aan het eind van de regel vermeld. Regels #1, 3 en 5 tonen dat het script volgens het bedoelde plan is uitgevoerd.
3. Stuur de uitvoer van cron naar een bestand.
U kunt de uitvoer van een cron doorsturen naar een bestand en kijk het bestand na voor mogelijke fouten.
* * * * * sh /path/to/script.sh &> log_file.log
# Stuur de uitvoer van cron naar een bestand
8.7. basis Linux Netwerkbeheer
Linux biedt een aantal commando’s om informatie te bekijken die gerelateerd is aan het netwerk. In dit gedeelte zal dit kort besproken worden.
Bekijk netwerkinterfaces met ifconfig
ifconfig
Het commando ifconfig geeft informatie over netwerkinterfaces. Hier is een voorbeelduitvoer:
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.1.100 netmask 255.255.255.0 broadcast 192.168.1.255
inet6 fe80::a00:27ff:fe4e:66a1 prefixlen 64 scopeid 0x20<link>
ether 08:00:27:4e:66:a1 txqueuelen 1000 (Ethernet)
RX packets 1024 bytes 654321 (654.3 KB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 512 bytes 123456 (123.4 KB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 256 bytes 20480 (20.4 KB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 256 bytes 20480 (20.4 KB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
# Uitvoer
De uitvoer van het ifconfig commando toont de op het systeem ingestelde netwerkinterfaces, samen met details zoals IP-adressen, MAC-adressen, pakketstatistieken en meer.
Deze interfaces kunnen fysieke of virtuele apparaten zijn.
Om IPv4- en IPv6-adressen uit te trekken, kunt u ip -4 addr en ip -6 addr gebruiken, respectievelijk.
Bekijk netwerkactiviteit metnetstat
Het netstat commando toont netwerkactiviteit en statistieken met de volgende informatie:
- Hier volgen enkele voorbeelden van het gebruik van het
netstatcommando in de commandoregel: - Alle luisterende en niet-luisterende sockets weergeven:
- Alleen luisterpoorten weergeven:
- Netwerkstatistieken weergeven:
- Routingtabel weergeven:
- Toon TCP-verbindingen:
- Toon UDP-verbindingen:
- Toon netwerkinterface:
- Toon PID en programmanamen voor verbindingen:
- Toon statistieken voor een specifiek protocol (bijvoorbeeld TCP):
Toon uitgebreide informatie:
Controleer netwerkconnectiviteit tussen twee apparaten met ping
ping google.com
ping wordt gebruikt om netwerkconnectiviteit tussen twee apparaten te testen. Het stuurt ICMP-pakketten naar het doelapparaat en wacht op een antwoord.
ping google.com
PING google.com (142.250.181.46) 56(84) bytes of data.
64 bytes from fjr04s06-in-f14.1e100.net (142.250.181.46): icmp_seq=1 ttl=60 time=78.3 ms
64 bytes from fjr04s06-in-f14.1e100.net (142.250.181.46): icmp_seq=2 ttl=60 time=141 ms
64 bytes from fjr04s06-in-f14.1e100.net (142.250.181.46): icmp_seq=3 ttl=60 time=205 ms
64 bytes from fjr04s06-in-f14.1e100.net (142.250.181.46): icmp_seq=4 ttl=60 time=100 ms
^C
--- google.com ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3001ms
rtt min/avg/max/mdev = 78.308/131.053/204.783/48.152 ms
ping test of je een antwoord terugkrijgt zonder een timeout.
— google.com ping statistieken —
Je kunt de respons stoppen met Ctrl + C.
Endpoints testen met het curl commando
- Het
curlcommando staat voor “client URL”. Het wordt gebruikt om gegevens naar of van een server over te dragen. Het kan ook worden gebruikt om API-eindpunten te testen, wat helpt bij het oplossen van systeem- en toepassingsfouten.
curl http://www.official-joke-api.appspot.com/random_joke
{"type":"general",
"setup":"What did the fish say when it hit the wall?","punchline":"Dam.","id":1}
- Als voorbeeld kun je
http://www.official-joke-api.appspot.com/gebruiken om te experimenteren met hetcurlcommando.
curl -o random_joke.json http://www.official-joke-api.appspot.com/random_joke
Het curl commando zonder opties gebruikt standaard de GET-methode.
curl -oslaat de uitvoer op in het genoemde bestand.
curl -I http://www.official-joke-api.appspot.com/random_joke
HTTP/1.1 200 OK
Content-Type: application/json; charset=utf-8
Vary: Accept-Encoding
X-Powered-By: Express
Access-Control-Allow-Origin: *
ETag: W/"71-NaOSpKuq8ChoxdHD24M0lrA+JXA"
X-Cloud-Trace-Context: 2653a86b36b8b131df37716f8b2dd44f
Content-Length: 113
Date: Thu, 06 Jun 2024 10:11:50 GMT
Server: Google Frontend
# slaat de uitvoer op in random_joke.json
curl -I haalt alleen de headers op.
8.8. Linux Probleemoplossing: Tools en Technieken
System activiteitenrapport met sar
De opdracht sar in Linux is een krachtig hulpmiddel voor het verzamelen, rapporteren en opslaan van informatie over systeemactiviteit. Het maakt deel uit van het pakket sysstat en wordt breed gebruikt voor het monitoren van systeemprestaties over tijd.
Om sar te gebruiken moet je eerst sysstat installeren met sudo apt install sysstat.
Als het geïnstalleerd is, start je de service met sudo systemctl start sysstat.
Controleer de status met sudo systemctl status sysstat.
sar [options] [interval] [count]
Als de status actief is, zal het systeem beginnen met het verzamelen van verschillende statistieken die je kunt gebruiken om historische gegevens te bekijken en te analyseren. We zullen daar spoedig gedetailleerd naar kijken.
sar -u 1 3
De syntaxis van de opdracht sar is als volgt:
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
19:09:26 CPU %user %nice %system %iowait %steal %idle
19:09:27 all 3.78 0.00 2.18 0.08 0.00 93.96
19:09:28 all 4.02 0.00 2.01 0.08 0.00 93.89
19:09:29 all 6.89 0.00 2.10 0.00 0.00 91.01
Average: all 4.89 0.00 2.10 0.06 0.00 92.95
Bijvoorbeeld, sar -u 1 3 zal statistieken over CPU-gebruik elke seconde voor drie keer weergeven.
# Output
Hier zijn enkele veel voorkomende gebruiksscenario’s en voorbeelden van hoe je de opdracht sar kunt gebruiken.
sar kan gebruikt worden voor diverse doeleinden:
sar -r 1 3
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
19:10:46 kbmemfree kbavail kbmemused %memused kbbuffers kbcached kbcommit %commit kbactive kbinact kbdirty
19:10:47 4600104 8934352 5502124 36.32 375844 4158352 15532012 65.99 6830564 2481260 264
19:10:48 4644668 8978940 5450252 35.98 375852 4165648 15549184 66.06 6776388 2481284 36
19:10:49 4646548 8980860 5448328 35.97 375860 4165648 15549224 66.06 6774368 2481292 116
Average: 4630440 8964717 5466901 36.09 375852 4163216 15543473 66.04 6793773 2481279 139
1. Geheugengebruik
Om geheugengebruik (vrij en gebruikt) te controleren, gebruik:
Deze opdracht geeft geheugensstatistieken elke seconde drie keer weer.
sar -S 1 3
sar -S 1 3
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
19:11:20 kbswpfree kbswpused %swpused kbswpcad %swpcad
19:11:21 8388604 0 0.00 0 0.00
19:11:22 8388604 0 0.00 0 0.00
19:11:23 8388604 0 0.00 0 0.00
Average: 8388604 0 0.00 0 0.00
2. Swapruimtegebruik
Om statistieken over swapruimtegebruik te bekijken, gebruik:
Deze opdracht helpt bij het monitoren van swap-gebruik, wat crucial is voor systemen die aan fysieke geheugen zijn gesloten.
sar -d 1 3
3. I/O-apparatenlast
Om activiteit te rapporteren voor blokapparaten en partities van blokapparaten:
Deze opdracht biedt gedetailleerde statistieken over gegevensverplaatsingen naar en vanaf blokapparaten, en is handig voor het diagnoseren van I/O-kanalen.
sar -n DEV 1 3
5. Netwerkstatistieken
sar -n DEV 1 3
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
19:12:47 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
19:12:48 lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
19:12:48 enp2s0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
19:12:48 wlp3s0 10.00 3.00 1.83 0.37 0.00 0.00 0.00 0.00
19:12:48 br-5129d04f972f 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
.
.
.
Average: IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
Average: lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: enp2s0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
...output truncated...
Om netwerkstatistieken te bekijken, zoals het aantal ontvangen (verzonden) pakketten per netwerkinterface:
# -n DEV vertelt sar om netwerkapparaatinterface te rapporteren
Dit toont netwerkstatistieken elke seconde voor drie seconden, wat helpt bij het monitoren van netwerkverkeer.
- 6. Historische gegevens
- # zijn “true” en “false”. Gelieve geen andere waarden in te voeren, deze
- Configureer het gegevensverzamelingsinterval: Bewerk de cron job-configuratie om het gegevensverzamelingsinterval in te stellen.
sar -u -f /var/log/sysstat/sa04
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
15:20:49 LINUX RESTART (12 CPU)
16:13:30 LINUX RESTART (12 CPU)
18:16:00 CPU %user %nice %system %iowait %steal %idle
18:16:01 all 0.25 0.00 0.67 0.08 0.00 99.00
Average: all 0.25 0.00 0.67 0.08 0.00 99.00
Vervang <DD> door de dag van de maand waarvan je de gegevens wilt zien.
In de onderstaande opdracht geeft /var/log/sysstat/sa04 statistieken voor de 4e dag van de huidige maand.
sar -I SUM 1 3
7. Realtime CPU-afbrekingen
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
19:14:22 INTR intr/s
19:14:23 sum 5784.00
19:14:24 sum 5694.00
19:14:25 sum 5795.00
Average: sum 5757.67
Om real-time onderbrekingen per seconde die door de CPU worden afgehandeld te observeren, gebruik deze opdracht:
# Uitvoer
Deze opdracht helpt bij het monitoren van hoe vaak de CPU onderbrekingen afhandelt, wat cruciaal kan zijn voor real-time prestatieafstelling.
Deze voorbeelden illustreren hoe u sar kunt gebruiken om verschillende aspecten van systeemprestaties te monitoren. Regelmatig gebruik van sar kan helpen bij het identificeren van systeembottlenecks en ervoor zorgen dat toepassingen efficient blijven werken.
8.9. Algemene probleemoplossingsstrategie voor servers
Waarom moeten we monitoring begrijpen?
Systeemonderzoek is een belangrijk aspect van systeembeheer. Kritieke toepassingen vereisen een hoog niveau van proactief gedrag om storingen te voorkomen en het uitval-effect te verminderen.
Linux biedt zeer krachtige hulpmiddelen om de systeemgezondheid te meten. In dit gedeelte leert u over de verschillende methoden die beschikbaar zijn om de gezondheid van uw systeem te controleren en bottlenecks te identificeren.
[user@host ~]$ uptime 19:15:00 up 1:04, 0 users, load average: 2.92, 4.48, 5.20
Laadgemiddelde en systeemuptime vinden
Systeemherstarts kunnen voorkomen die soms sommige configuraties verstoren. Om te controleren hoe lang de machine al actief is, gebruikt u de opdracht: uptime. Naast de uptime toont de opdracht ook het laadgemiddelde.
Laadgemiddelde is de systeembelasting over de afgelopen 1, 5, en 15 minuten. Een snel oogopslag geeft aan of de systeembelasting lijkt te stijgen of te dalen met de tijd.
Opmerking: Ideaal CPU-wachtrij is 0. Dit is alleen mogelijk wanneer er geen wachtrijen voor de CPU zijn.
lscpu
Per-CPU-belasting kan worden berekend door het laadgemiddelde te delen door het totale aantal beschikbare CPU's.
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 48 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 12
On-line CPU(s) list: 0-11
.
.
.
output omitted
Om het aantal CPU’s te vinden, gebruik de opdracht lscpu.
# uitvoer
Als de gemiddelde belasting lijkt te stijgen en niet terug te komen, zijn de CPU’s overbelast. Er is een proces dat vastzit of er is een geheugenlek.
free -mh
Berekenen van vrij geheugen
total used free shared buff/cache available
Mem: 14Gi 3.5Gi 7.7Gi 109Mi 3.2Gi 10Gi
Swap: 8.0Gi 0B 8.0Gi
Soms kan een hoge geheugengebruik problemen veroorzaken. Gebruik het commando free om het beschikbare geheugen en het gebruikte geheugen te controleren.
# uitvoer
Berekenen schijfruimte
df -h
Filesystem Size Used Avail Use% Mounted on
tmpfs 1.5G 2.4M 1.5G 1% /run
/dev/nvme0n1p2 103G 34G 65G 35% /
tmpfs 7.3G 42M 7.2G 1% /dev/shm
tmpfs 5.0M 4.0K 5.0M 1% /run/lock
efivarfs 246K 93K 149K 39% /sys/firmware/efi/efivars
/dev/nvme0n1p3 130G 47G 77G 39% /home
/dev/nvme0n1p1 511M 6.1M 505M 2% /boot/efi
tmpfs 1.5G 140K 1.5G 1% /run/user/1000
Om ervoor te zorgen dat het systeem gezond is, mag je het schijfruimte niet vergeten. Gebruik het onderstaande commando om alle beschikbare aankoppelpunten en hun respectieve gebruikscijfers te lijsten. Ideaal is dat gebruikte schijfruimtes niet meer dan 80% zijn.
Het commando df biedt gedetailleerde informatie over schijfruimtes.
Bepalen van processtaten
[user@host ~]$ ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
runner 1 0.1 0.0 1535464 15576 ? S 19:18 0:00 /inject/init
runner 14 0.0 0.0 21484 3836 pts/0 S 19:21 0:00 bash --norc
runner 22 0.0 0.0 37380 3176 pts/0 R+ 19:23 0:00 ps aux
Processtaten kunnen worden gevolgd om te zien of er een vastgelopen proces is met hoog geheugen- of CPU-gebruik.
Als we eerder zagen, geeft het commando ps nuttige informatie over een proces. Kijk naar de kolommen CPU en MEM.
Realtime-systeemmonitoring
Realtime monitoring biedt inzicht in de realtijd-systeemstatus.
Een hulpmiddel dat je hiervoor kunt gebruiken is het commando top.
Het commando top toont een dynamische weergave van de systeemprocessen, met een samenvattende kop gevolgd door een lijst van processen of threads. In tegenstelling tot zijn statische equivalent ps, vernieuwt top continu de systeemstatistieken.
Met top kun je goed georganiseerde details in een compact venster zien. Er zijn een aantal vlaggen, sneltoetsen en highlightmethodes die samen met top komen.
U kunt ook processen stoppen met behulp van top. Om dit te doen, druk op k en voer vervolgens de process-id in.
Logboeken interpreteren
Systeem- en toepassingslogboeken bevatten tonnen informatie over wat het systeem door gaat. Ze bevatten nuttige informatie en foutcodes die naar fouten wijzen. Als u foutcodes zoekt in logboeken, kan de identificatie en reparatie tijd ervan aanzienlijk worden verkort.
Netwerkpoortenanalyse
Het netwerkdeel moet niet genegeerd worden, want netwerkproblemen zijn normaal en kunnen het systeem en de verkeersstromen beïnvloeden. Veelvoorkomende netwerkproblemen omvatten poortuitputting, poortverstoppeling, niet-vrijgegeven bronnen, enzovoort.
| Om dergelijke problemen te identificeren, moeten we de poortstatussen begrijpen. | Enkele van de poortstatussen worden hier kort uitgelegd: |
| Status | Omschrijving |
| LISTEN | vertegenwoordigt poorten die wachten op een verbindingsverzoek van elke externe TCP-poort. |
| ESTABLISHED | vertegenwoordigt openbare verbindingen waarop gegevens ontvangen kunnen worden die naar het doel kunnen worden verzonden. |
| TIME WAIT | vertegenwoordigt de wachtijd om erop te wachten dat de bevestiging van het verzoek tot beëindigen van de verbinding wordt ontvangen. |
FIN WAIT2
vertegenwoordigt het wachten op een verzoek tot beëindigen van de verbinding van de externe TCP.
[user@host ~]$ /sbin/sysctl net.ipv4.ip_local_port_range
net.ipv4.ip_local_port_range = 15000 65000
Laten we onderzoeken hoe we port-gerelateerde informatie in Linux kunnen analyseren.
Poortbereiken: Poortbereiken zijn gedefinieerd in het systeem en kunnen dienovereenkomstig worden verhoogd/verlaagd. In de onderstaande snippet is het bereik van 15000 tot 65000, wat in totaal 50000 (65000 – 15000) beschikbare poorten maakt. Als gebruikte poorten deze limiet bereiken of overschrijden, is er een probleem.
De fout die in dergelijke gevallen in logs wordt gemeld, kan Failed to bind to port of Too many connections zijn.
Verlies van pakketten identificeren
Bij systeemmonitoring moeten we ervoor zorgen dat de uitgaande en inkomende communicatie intact is.
[user@host ~]$ ping 10.13.6.113
PING 10.13.6.141 (10.13.6.141) 56(84) bytes of data.
64 bytes from 10.13.6.113: icmp_seq=1 ttl=128 time=0.652 ms
64 bytes from 10.13.6.113: icmp_seq=2 ttl=128 time=0.593 ms
64 bytes from 10.13.6.113: icmp_seq=3 ttl=128 time=0.478 ms
64 bytes from 10.13.6.113: icmp_seq=4 ttl=128 time=0.384 ms
64 bytes from 10.13.6.113: icmp_seq=5 ttl=128 time=0.432 ms
64 bytes from 10.13.6.113: icmp_seq=6 ttl=128 time=0.747 ms
64 bytes from 10.13.6.113: icmp_seq=7 ttl=128 time=0.379 ms
^C
--- 10.13.6.113 ping statistics ---
7 packets transmitted, 7 received,0% packet loss, time 6001ms
rtt min/avg/max/mdev = 0.379/0.523/0.747/0.134 ms
Een nuttige opdracht is ping. ping raakt het doelsysteem en brengt de reactie terug. Let op de laatste paar regels van statistieken die het percentage pakketverlies en de tijd laten zien.
# ping bestemming IP
Pakketten kunnen ook tijdens runtime worden vastgelegd met tcpdump. We zullen hier later op ingaan.
Verzamelen van statistieken voor probleemonderzoek achteraf
- Het is altijd een goede gewoonte om bepaalde statistieken te verzamelen die nuttig zouden zijn om later de hoofdoorzaak te identificeren. Gewoonlijk verliezen we na een systeemherstart of herstart van diensten de eerdere systeemmomentopname en logs.
Hieronder staan enkele methoden om een systeemmomentopname vast te leggen.
- Logback-up
Voordat u wijzigingen aanbrengt, kopieert u logbestanden naar een andere locatie. Dit is cruciaal om te begrijpen in welke toestand het systeem was tijdens het optreden van het probleem. Soms zijn logbestanden de enige manier om inzicht te krijgen in vroegere systeemtoestanden omdat andere runtime-statistieken verloren gaan.
sudo tcpdump -i any -w
TCP Dump
Tcpdump is een opdrachtregelhulpmiddel dat u in staat stelt netwerkverkeer te vangen en te analyseren dat binnenkomt en vertrekt. Het wordt voornamelijk gebruikt om netwerkproblemen te helpen oplossen. Als u denkt dat systeemverkeer wordt beïnvloed, neemt u tcpdump als volgt:
# Waarbij,
# -i any het verkeer van alle interfaces vangt
# -w geeft het uitvoerbestandsnaam op
# Stop het commando na een paar minuten omdat de bestandsgrootte kan toenemen
# gebruik de bestandsextensie .pcap
Als tcpdump is vastgelegd, kunt u hulpmiddelen zoals Wireshark gebruiken om het verkeer visueel te analyseren.
Conclusie
Bedankt voor het lezen van het boek tot het einde. Als u het nuttig vond, overweeg dan om het met anderen te delen.
Het boek eindigt hier niet. Ik zal het blijven verbeteren en nieuwe materialen toevoegen in de toekomst. Als u problemen heeft gevonden of suggesties voor verbetering hebt, geef dan gerust een PR/ Issue aan.
- Blijf verbonden en ga door met uw leerreis!
-
LinkedIn: Ik delen daar artikelen en berichten over tech. Geef een aanbeveling op LinkedIn en stem voor mij op relevante vaardigheden.
Krijg toegang tot exclusieve content: Voor een persoonlijke hulp en exclusief content gaat u hier.
Krijg toegang tot exclusieve content: Voor een persoonlijke hulp en exclusief content gaat u hier.
Source:
https://www.freecodecamp.org/news/learn-linux-for-beginners-book-basic-to-advanced/