













Wat is Elasticsearch?
Elasticsearch is een zeer schaalbare en gedistribueerde zoek- en analyse-engine die gebouwd is op basis van de Apache Lucene zoekbibliotheek. Het is ontworpen om grote hoeveelheden gestructureerde, semi-gestructureerde en ongestructureerde gegevens te verwerken, waardoor het geschikt is voor een breed scala aan toepassingen, waaronder zoekmachines, loganalyse, e-commerce en beveiligingsanalyses.
Elasticsearch maakt gebruik van een gedistribueerd architectuur die het in staat stelt om grote hoeveelheden gegevens op te slaan en te verwerken over meerdere knooppunten in een cluster. Gegevens worden geïndexeerd en opgeslagen in shards, die over knooppunten worden verdeeld voor verbeterde schaalbaarheid en fouttolerantie. Elasticsearch ondersteunt ook realtime zoeken en analyses, waardoor gebruikers gegevens in bijna realtime kunnen opvragen en analyseren.
Een van de belangrijkste kenmerken van Elasticsearch zijn de krachtige zoekmogelijkheden. Het ondersteunt een breed scala aan zoekquery’s, waaronder volledig tekstzoeken, ruimtelijke zoeken, enz. Ook biedt het ondersteuning voor geavanceerde analyses, zoals aggregaties, metrieken en gegevensvisualisatie.
Elasticsearch wordt vaak in combinatie met andere tools in de Elastic Stack gebruikt, waaronder Logstash voor gegevensverzameling en -verwerking en Kibana voor gegevensvisualisatie en -analyse. Samen bieden deze tools een uitgebreid oplossing voor zoeken en analyses die voor een breed scala aan toepassingen en gebruiksvoorbeelden kan worden gebruikt.
Wat is Apache Lucene?
Apache Lucene is een open-source zoekbibliotheek die krachtige tekstzoek- en indexeringsmogelijkheden biedt. Het wordt breed gebruikt door ontwikkelaars en organisaties om zoektoepassingen te bouwen, variërend van zoekmachines tot e-commerceplatforms.
Lucene werkt door de tekstinhoud van documenten te indexeren en de index op te slaan in een gestructureerde indeling die efficiënt kan worden doorzocht. De index bestaat uit een reeks omgekeerde lijsten, die afspraken bieden tussen termen en de documenten die ze bevatten. Wanneer een zoekquery wordt ingediend, gebruikt Lucene de index om snel de documenten te vinden die overeenkomen met de query.
Naast zijn kernzoek- en indexeringsmogelijkheden biedt Lucene een reeks geavanceerde functies, waaronder ondersteuning voor fuzzy zoeken en ruimtelijk zoeken. Het biedt ook hulpmiddelen voor het markeren van zoekresultaten en het rangschikken van zoekresultaten op basis van relevantie.
Lucene wordt gebruikt door een breed scala aan organisaties en projecten, waaronder Elasticsearch. Zijn rijke reeks functies, flexibiliteit en uitbreidbaarheid maken het een populaire keuze voor het bouwen van zoektoepassingen van alle soorten.
Wat Is Een Omgekeerde Index?
Lucene’s Omgekeerde Index is een datastructuur die wordt gebruikt om tekstgegevens uit een verzameling documenten efficiënt te zoeken en te retourneren. De Omgekeerde Index is een centrale functie van Lucene en wordt gebruikt om de termen en hun geassocieerde documenten op te slaan die de index vormen.
De Omgekeerde Index biedt verschillende voordelen ten opzichte van andere zoekstrategieën. Ten eerste, het maakt snelle en efficiënte opvraging van documenten mogelijk op basis van zoektermen. Ten tweede, het kan omgaan met een grote hoeveelheid tekstgegevens, waardoor het geschikt is voor gebruiksgevallen met grote verzamelingen documenten. Tot slot ondersteunt het een breed scala aan geavanceerde zoekfuncties, zoals fuzzy matching en stemming, die de nauwkeurigheid en relevantie van zoekresultaten kunnen verbeteren.
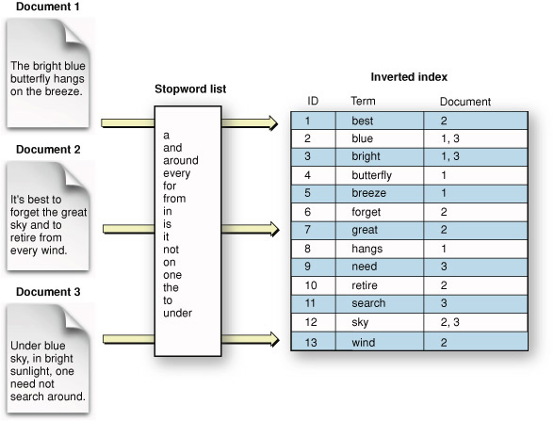
Waarom Elasticsearch?
Er zijn verschillende redenen waarom Elasticsearch een populaire keuze is voor het bouwen van zoek- en analyseapplicaties:
Gemakkelijk te schalen (Gedistribueerd): Elasticsearch is vanaf de basis ontworpen om horizontaal te schalen. Wanneer u capaciteit nodig heeft, voeg gewoon meer knooppunten toe en laat de cluster zichzelf herorganiseren om gebruik te maken van de extra hardware.
Eén server kan één of meer delen van één of meer indexen bevatten, en wanneer er nieuwe knooppunten aan het cluster worden toegevoegd, worden ze gewoon aan de feestelijkheden toegevoegd. Elk dergelijk indexdeel, of deel ervan, wordt een shard genoemd, en Elasticsearch shards kunnen zeer gemakkelijk door het cluster worden verplaatst.
Alles is één JSON-oproep verwijderd (RESTful API): Elasticsearch is API-gestuurd. Bijna elke actie kan worden uitgevoerd met behulp van een eenvoudige RESTful API met JSON over HTTP. Reacties zijn altijd in JSON-indeling.
Ontsluierde kracht van Lucene onder de motorkap: Elasticsearch maakt intern gebruik van Lucene om zijn toonaangevende gedistribueerde zoek- en analysemogelijkheden te bouwen. Aangezien Lucene een stabiele, bewezen technologie is en voortdurend wordt uitgebreid met meer functies en best practices, is Lucene als de onderliggende motor die Elasticsearch aandrijft.
Uitstekende Query DSL: De REST API biedt een zeer complexe en veelzijdige query-DSL die zeer eenvoudig te gebruiken is. Elke query is slechts een JSON-object dat in principe elk type query kan bevatten of zelfs meerdere van hen gecombineerd. Het gebruik van gefilterde query’s, met enkele query’s uitgedrukt als Lucene-filters, helpt het gebruik van caching te optimaliseren en zo veel voorkomende of complexe query’s te versnellen met delen die opnieuw kunnen worden gebruikt.
Multi-Tenancy: Meerdere indices kunnen worden opgeslagen op één Elasticsearch-installatie – knooppunt of cluster. Het mooie is dat je met één eenvoudige query meerdere indices kunt doorzoeken.
Ondersteuning voor geavanceerde zoekfuncties (Volledige Tekst): Elasticsearch gebruikt Lucene om de krachtigste volledige tekstzoekmogelijkheden die beschikbaar zijn in een open-source product te bieden. De zoekfunctie biedt ondersteuning voor meertalige ondersteuning, een krachtig querytaal, ondersteuning voor geolocatie, contextgevoelige suggesties “meant-you-mean”, autocomplete en zoekfragmenten. Scriptondersteuning in filters en scorers.
Configureerbaar en Uitbreidbaar: Veel configuraties van Elasticsearch kunnen worden gewijzigd terwijl Elasticsearch draait, maar sommige zullen een herstart (en in sommige gevallen herindexering) vereisen. De meeste configuraties kunnen ook worden gewijzigd via de REST API.
Document Oriented: Complexe echte wereldentiteiten opslaan in Elasticsearch als gestructureerde JSON-documenten. Alle velden worden standaard geïndexeerd en alle indices kunnen in één query worden gebruikt om resultaten te retourneren met adembenemende snelheid.
Schema Free: Elasticsearch stelt je gemakkelijk aan de slag. Stuur een JSON-document, en het zal proberen de gegevensstructuur te detecteren, de gegevens te indexeren en ze zoekbaar te maken.
Conflict Management: Optimistische versiebeheer kan ingezet worden waar nodig om ervoor te zorgen dat gegevens nooit verloren gaan door conflicterende wijzigingen van meerdere processen.
Actieve Community: De community, naast het maken van mooie tools en plugins, is zeer behulpzaam en ondersteunend. De algemene sfeer is geweldig en dit is een belangrijke indicator voor elk OSS-project. Er worden ook enkele boeken geschreven door communityleden en veel blogberichten op het net waarin ervaringen en kennis worden gedeeld.
Elasticsearch Architectuur
De belangrijkste componenten van de Elasticsearch-architectuur zijn:
Node: Een node is een instantie van Elasticsearch die gegevens opslaat en zoek- en indexeringsmogelijkheden biedt. Nodes kunnen worden geconfigureerd als master node of data node, of beide. Master nodes zijn verantwoordelijk voor het beheer van de hele cluster, terwijl data nodes de gegevens opslaan en zoekoperaties uitvoeren.
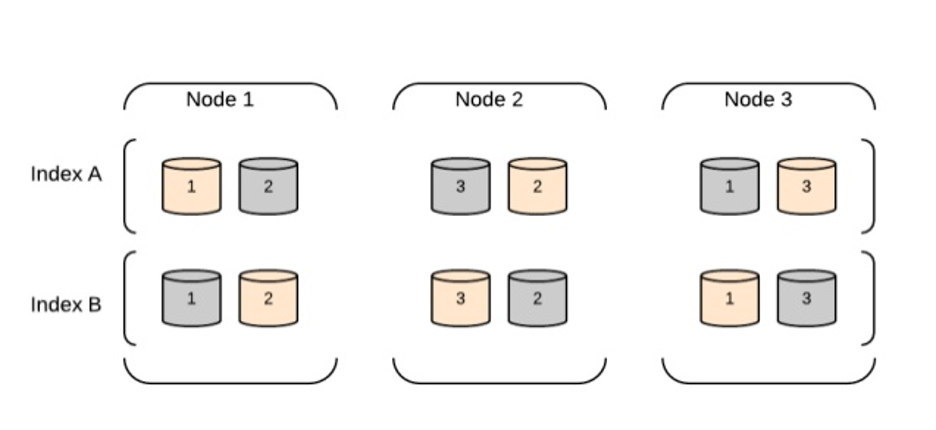
Cluster: Een cluster is een groep van één of meer nodes die samenwerken om gegevens op te slaan en te verwerken. Een cluster kan meerdere indices (verzamelingen van documenten) en shards (een manier om gegevens over meerdere nodes te verdelen) bevatten.
Index: Een index is een verzameling documenten die een vergelijkbare structuur delen. Elk document wordt weergegeven als een JSON-object en bevat één of meer velden. Elasticsearch indexeert standaard alle velden, waardoor het gemakkelijk is om gegevens te zoeken en te analyseren.
Shards: Een index kan worden gesplitst in meerdere shards, die in wezen kleinere subsets van de index zijn. Sharding maakt parallel verwerking van gegevens mogelijk en wordt gegevens opgeslagen over meerdere knooppunten.
Replicas: Elasticsearch kan replicas van elke shard maken om fouttolerantie en hoge beschikbaarheid te bieden. Replicas zijn kopieën van de originele shard en kunnen zich op verschillende knooppunten bevinden.
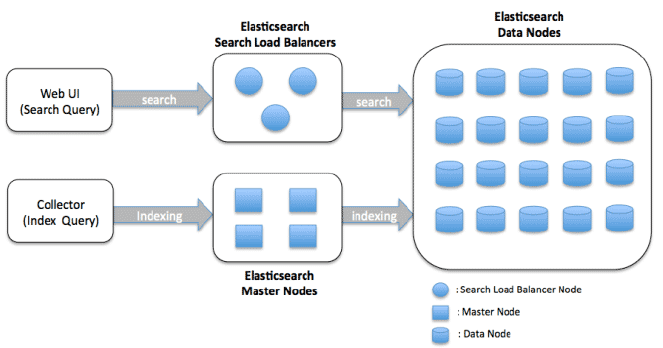
Data Node Cluster Architecture
Data nodes zijn verantwoordelijk voor het opslaan en indexeren van gegevens, evenals het uitvoeren van zoek- en aggregatieoperaties. Het architectuur is ontworpen om schaalbaar en gedistribueerd te zijn, waardoor horizontale schaalvergroting mogelijk is door meer knooppunten toe te voegen aan het cluster.
Hier zijn de belangrijkste componenten van een Elasticsearch data node cluster architectuur:
Data Node: Een node is een instantie van Elasticsearch die gegevens opslaat en zoek- en indexeringsmogelijkheden biedt. In een data node cluster is elke node verantwoordelijk voor het opslaan van een deel van de indexgegevens en het afhandelen van zoekquery’s tegen die gegevens.
Cluster State: Het cluster state is een datastructuur die informatie bevat over het cluster, inclusief de lijst met knooppunten, indices, shards en hun locaties. Het master node is verantwoordelijk voor het onderhouden van het cluster state en het distribueren naar alle andere knooppunten in het cluster.
Ontdekking en transport: Knooppunten in een Elasticsearch-cluster communiceren met elkaar via twee protocollen: ontdekking en transport. Het ontdekkingsprotocol is verantwoordelijk voor het detecteren van nieuwe knooppunten die zich bij het cluster aansluiten of knooppunten die het cluster hebben verlaten. Het transportprotocol is verantwoordelijk voor het verzenden en ontvangen van gegevens tussen knooppunten.
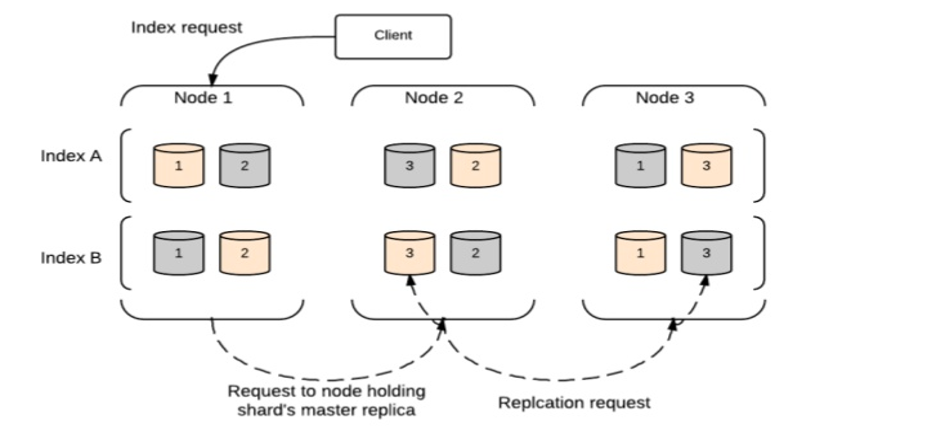
Indexaanvraag
Een indexaanvraag wordt in Elasticsearch uitgevoerd volgens onderstaand blokschema.
Wie gebruikt Elasticsearch?
Enkele bedrijven en organisaties die Elasticsearch gebruiken:
Netflix: Netflix gebruikt Elasticsearch om zijn zoek- en aanbevelingsengine te ondersteunen, waardoor gebruikers snel content kunnen vinden om te kijken.
GitHub: GitHub gebruikt Elasticsearch om snelle en efficiënte zoekmogelijkheden te bieden voor hun code-repositories, issues en pull requests.
Uber: Uber gebruikt Elasticsearch om hun realtime analytics-platform te ondersteunen, waardoor ze gegevens over hun ritdienst in realtime kunnen volgen en analyseren.
Wikipedia: Wikipedia gebruikt Elasticsearch om zijn zoekmachine te ondersteunen en snelle en nauwkeurige zoekresultaten te bieden aan gebruikers.
Source:
https://dzone.com/articles/introduction-to-elasticsearch-1