













Het gebruik van IT-monitoring in de infrastructuur van een organisatie kan de betrouwbaarheid verbeteren en helpen ernstige problemen, storingen en uitvaltijden te voorkomen. Er zijn verschillende benaderingen voor het implementeren van IT-monitoring, hetzij door gebruik te maken van specifieke tools of ingebouwde functionaliteit. Met beide benaderingen kun je de monitorgegevens bekijken wanneer dat nodig is of automatische waarschuwingen en rapporten configureren om op de hoogte te worden gesteld van belangrijke gebeurtenissen. Deze blogpost legt uit hoe je de IT-monitoringstrategie kunt verbeteren door gebruik te maken van alarmen en rapporten.
Het Belang van IT-Monitoring en Rapportage voor Bedrijven
IT-monitoring is cruciaal voor organisaties omdat het helpt ervoor te zorgen dat de IT-infrastructuur goed en betrouwbaar werkt.
- Maximaliseren van uptime en betrouwbaarheid. Kritische bedrijfssystemen vereisen meestal 24/7 werking. Dergelijke systemen worden gebruikt in sectoren zoals gezondheidszorg, financiën en andere dienstverleners waar uitvaltijd ernstige gevolgen kan hebben. Gelukkig is het mogelijk om dergelijke problemen te voorkomen als je een IT-monitoringsysteem implementeert en goed configureert.
Proactieve probleemdetectie helpt beheerders potentiële problemen te ontdekken, zoals serveroverbelasting, applicatiefouten, hardwareproblemen en prestatieafname, voordat deze leiden tot grote storingen. Deze proactieve benadering stelt beheerders in staat om in te grijpen en corrigerende maatregelen te nemen voordat er een negatieve impact is op servers, virtuele machines (VM’s), bedrijfsactiviteiten en eindgebruikers. Het ontvangen van rapporten die wijzen op potentiële problemen maakt IT-monitoring en -beheer efficiënter.
- Beveiliging verbeteren. IT-monitoring wordt gebruikt om ongeoorloofde toegangs pogingen, ongebruikelijk netwerkverkeer en andere verdachte activiteiten te detecteren die een indicator kunnen zijn van een cyberaanval. Deze benadering stelt beheerders in staat om beveiligingsdreigingen tijdig te detecteren. Sommige sectoren moeten voldoen aan wettelijke vereisten die voortdurende monitoring van IT-systemen vereisen om boetes te vermijden.
- Prestatie en efficiëntie verbeteren. Beheerders kunnen het gebruik van middelen op servers, virtuele machines en netwerkinfrastructuur optimaliseren door IT-monitoring en waarschuwingen in te stellen. Het configureren van IT-monitoringtools om CPU-, geheugen- en bandbreedtegebruik te volgen voor verdere analyse van deze gegevens stelt je in staat om beter te begrijpen wat verbeterd kan worden. Hierdoor kunnen organisaties hun middelen optimaliseren en verspilling verminderen om een hoge efficiëntie in hun IT-systemen te bereiken. Dit helpt ook beheerders om knelpunten te identificeren en de prestaties te verbeteren.
- Verbeteren van bedrijfscontinuïteit en rampenherstel. Vroegtijdige detectie van storingen is een van de belangrijkste redenen waarom beheerders van organisaties IT-monitoringsystemen met meldingen moeten configureren. Deze aanpak kan tekenen van datacorruptie, applicatiecrashes en hardwarestoringen vroegtijdig detecteren om dataverlies te voorkomen. Het voorkomen van dataverlies is noodzakelijk om de bedrijfscontinuïteit te waarborgen. Door monitoringtools met geconfigureerde meldingen te gebruiken, kunnen beheerders ervoor zorgen dat back-upsystemen en rampenherstelplannen getest en correct functioneren. Het kan een garantie zijn dat een bedrijf gegevens en werkbelastingen snel kan herstellen in het geval van een ramp.
- Verbeteren van de klantervaring. Klanten verwachten dat diensten op elk moment beschikbaar zijn. Het configureren van IT-monitoringsystemen om servers, virtuele machines, netwerkinrichting en applicaties die verband houden met de werking van de website te monitoren, helpt ervoor te zorgen dat de websites en diensten altijd beschikbaar zijn voor klanten. Niet alleen de beschikbaarheid van middelen, maar ook de prestaties worden gemonitord om de beste service te bereiken.
Het ontvangen van rapporten die informatie over problemen bevatten, kan leiden tot een snelle oplossing. De rapporten bevatten de informatie die beheerders nodig hebben om problemen zo snel mogelijk op te lossen. Deze acties minimaliseren de negatieve impact op klanten en, als gevolg daarvan, hebben klanten een positieve ervaring.
- Kostenbeheer. Het configureren van proactieve monitoring kan downtime voorkomen. Ongeplande downtime kan kostbaar zijn omdat een organisatie inkomsten verliest en middelen moet besteden om gegevens en de infrastructuur te herstellen. Monitoring met waarschuwingsmeldingen stelt beheerders in staat om het probleem zo snel mogelijk op te lossen en het risico op downtime te verminderen.
Begrip van Alarms in IT Monitoring
Het configureren van alarmsignalen voor IT-monitoringsystemen verbetert de reactietijd voor beheerders om op de hoogte te zijn van het probleem en het sneller op te lossen. Als alleen bronnen zoals webpagina’s met grafieken en statistieken zijn geconfigureerd, kan de systeembeheerder problemen alleen opmerken bij het controleren van de webpagina met de monitorinformatie. Beheerders hebben een breed scala aan verschillende taken en kunnen meestal niet continu een webpagina met de status van de IT-infrastructuur controleren.
Wanneer alarmsignalen zijn geconfigureerd, ontvangen beheerders zo snel mogelijk een melding over het probleem, potentieel probleem, storing of andere kritieke of verdachte gebeurtenissen. Er kan meestal een tijdsinterval worden geconfigureerd, bijvoorbeeld een bericht kan worden verzonden na 1 minuut of na 5 minuten nadat een probleem is gedetecteerd door het monitoringsysteem.
Als gevolg hiervan kan de systeembeheerder het probleem sneller opmerken en reageren om het probleem op te lossen en negatieve gevolgen te vermijden. Er kunnen verschillende meldingsmethoden worden gebruikt, zoals meldingen via e-mail, sms, Skype, enz., afhankelijk van de IT-bewakingssoftware.
Wat zijn alarmen en waarom zijn ze belangrijk?
Alarmen zijn meldingen die worden geactiveerd wanneer een specifieke gebeurtenis plaatsvindt en de juiste voorwaarden of drempels worden bereikt in het IT-systeem. Deze voorwaarden kunnen gebaseerd zijn op verschillende gebeurtenissen, waaronder:
- Prestatieproblemen: Hoge CPU-gebruik, geheugen uitputting, trage responstijden
- Resource-drempels: Weinig schijfruimte, verzadiging van netwerkbandbreedte
- Systeemstoringen: Servercrashes, toepassingsfouten, serviceonderbrekingen
- Beveiligingsincidenten: Ongeautoriseerde toegangspogingen, detectie van malware, ongebruikelijk netwerkverkeer
- Operationele gebeurtenissen: Mislukte back-ups, serviceherstarts, wijzigingen in configuratie
Wanneer een alarm wordt geactiveerd, genereert het bewakingssysteem een waarschuwing, en deze waarschuwing wordt naar de betreffende gebruiker gestuurd, voornamelijk de IT-beheerder, via verschillende kanalen. Deze waarschuwingen bevatten informatie over het probleem, inclusief de ernst ervan, het getroffen systeem of component, en aanbevolen acties.
Belangrijke metingen om te bewaken
CPU-gebruik. Het monitoren van CPU-gebruik is nodig om ervoor te zorgen dat er voldoende middelen zijn voor servers en systemen op het gebied van verwerkingskracht. Dit is belangrijk om workloads af te handelen zonder overbelast te raken. Hoog CPU-gebruik kan een signaal zijn dat het systeem overbelast is. Een laag CPU-gebruik geeft aan dat er voldoende middelen zijn of dat CPU-middelen onderbenut zijn.
Geheugen (RAM) gebruik. Applicaties en services hebben voldoende geheugen nodig voor soepele werking, en de geheugenparameter is hierbij kritiek. Beheerders moeten het RAM-gebruik monitoren om geheugenknelpunten te voorkomen, die prestatievermindering en zelfs systeemcrashes kunnen veroorzaken. Let op overmatig geheugengebruik, onvoldoende geheugenallocatie en geheugenlekken.
Schijfgebruik en I/O-prestaties. Schijfruimte en input/output (I/O) prestaties zijn kritieke metingen voor gegevensopslag. Het wordt aanbevolen om deze parameters te monitoren om opslaggerelateerde problemen, inclusief prestatieproblemen, te voorkomen. Let op hoog schijfgebruik, snelle groei van gebruikte schijfruimte, hoge latentie bij het lezen/schrijven van gegevens en frequente I/O-wachttijden. Abnormaal gedrag met betrekking tot deze parameters kan duiden op potentiële opslagproblemen.
Netwerkbandbreedte en latentie. De netwerkprestaties beïnvloeden alle operaties in een kantoor of datacenter omdat computers, servers en virtuele machines met elkaar verbonden zijn via het netwerk. Netwerkprestaties zijn cruciaal voor de diensten die aan klanten worden geleverd. Het monitoren van netwerkbandbreedte en latentie stelt je in staat om knelpunten en andere problemen te detecteren en deze op tijd op te lossen om de netwerkbronnen efficiënt te gebruiken. Let op hoge netwerknutilisatie, pakketverlies en hoge latentie, omdat deze indicatoren tekenen zijn van een trage prestaties en netwerkverbindingproblemen.
Dienst- en procesbeschikbaarheid. Belangrijke processen draaien in besturingssystemen op servers of virtuele machines, en ze moeten beschikbaar zijn om aan de zakelijke behoeften te voldoen. Het monitoren van diensten en hun beschikbaarheid zorgt ervoor dat kritieke diensten operationeel zijn. Om de beschikbaarheid van diensten te waarborgen, moeten beheerders de uptime, frequenties van herstarten van diensten en procesfouten monitoren.
Databaseprestaties. Databases maken vaak deel uit van complexere oplossingen, waaronder webapplicaties. Bovendien vereisen de meeste softwareoplossingen voor intern gebruik in organisaties databases. Om deze redenen is het belangrijk om de prestaties en beschikbaarheid van databases te monitoren. Het monitoren van databases zorgt ervoor dat gegevens toegankelijk zijn en gerelateerde operaties soepel verlopen. Bij het monitoren van een database moet je je richten op query-responstijden, traag lopende queries, databasevergrendelingen en het gebruik van verbindingspools, aangezien deze statistieken van vitaal belang zijn voor de gezondheid van de database.
Rapportage voor IT-monitoring
Rapportage wordt gebruikt om gestructureerde, actiegerichte inzichten te bieden uit de grote hoeveelheid gegevens die zijn verzameld door monitoringtools. Rapportage transformeert ruwe gegevens in informatie die leesbaar en begrijpelijk kan zijn voor mensen die in een organisatie werken, en vooral voor IT-beheerders. Na het controleren van de rapporten kunnen beheerders en management weloverwogen beslissingen nemen. Dit stelt de IT-teams in staat om de prestaties te optimaliseren, problemen te voorkomen en de bedrijfscontinuïteit te verbeteren.
Rapporten kunnen anomalieën benadrukken die niet opvallen bij het onderzoeken van de alarmen. Gegevens in rapporten worden samengevoegd voor meer gemak om de noodzaak te vermijden om handmatig naar belangrijke statistieken te zoeken en de verzamelde gegevens te organiseren. Als gevolg hiervan hebben beheerders een overzicht op hoog niveau van de gehele infrastructuur en de belangrijkste componenten. Informatie over de omstandigheden die leiden tot een incident kan door beheerders worden gebruikt voor een snelle incidentrespons en het uitvoeren van preventieve maatregelen.
Monitoring met NAKIVO Backup & Replication
NAKIVO Backup & Replication kan u helpen de elementen van uw IT-infrastructuur te monitoren. Ga naar de Monitoring sectie in de webinterface, voeg de te monitoren items toe en controleer de grafieken die de ondersteunde statistieken van de VMware vSphere infrastructuur weergeven.
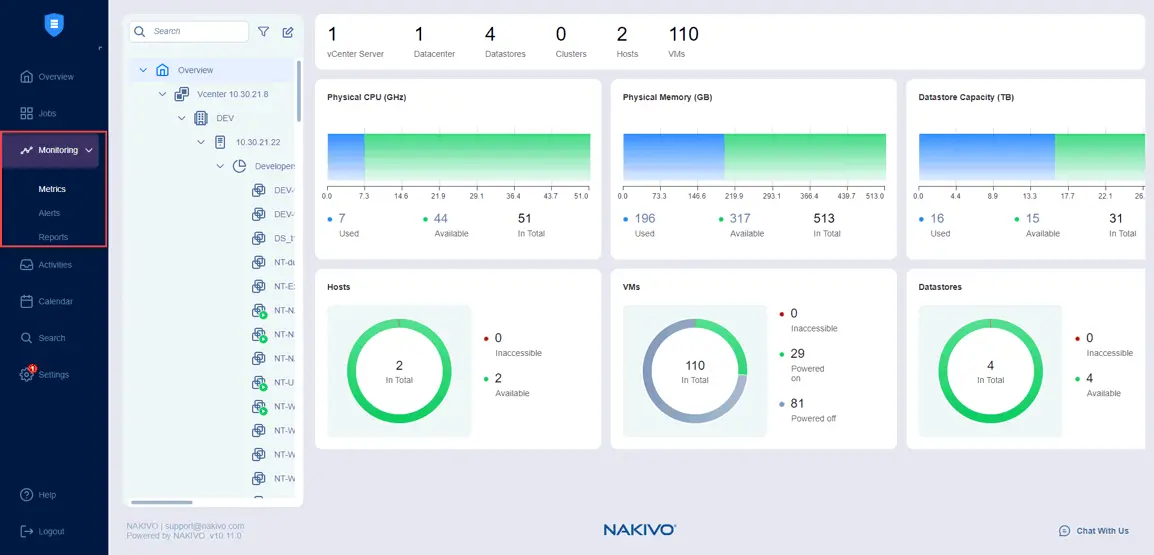
U kunt items selecteren om te monitoren, zoals ESXi-hosts of clustering, VMware VM’s en datastores in Monitoring > Statistieken.
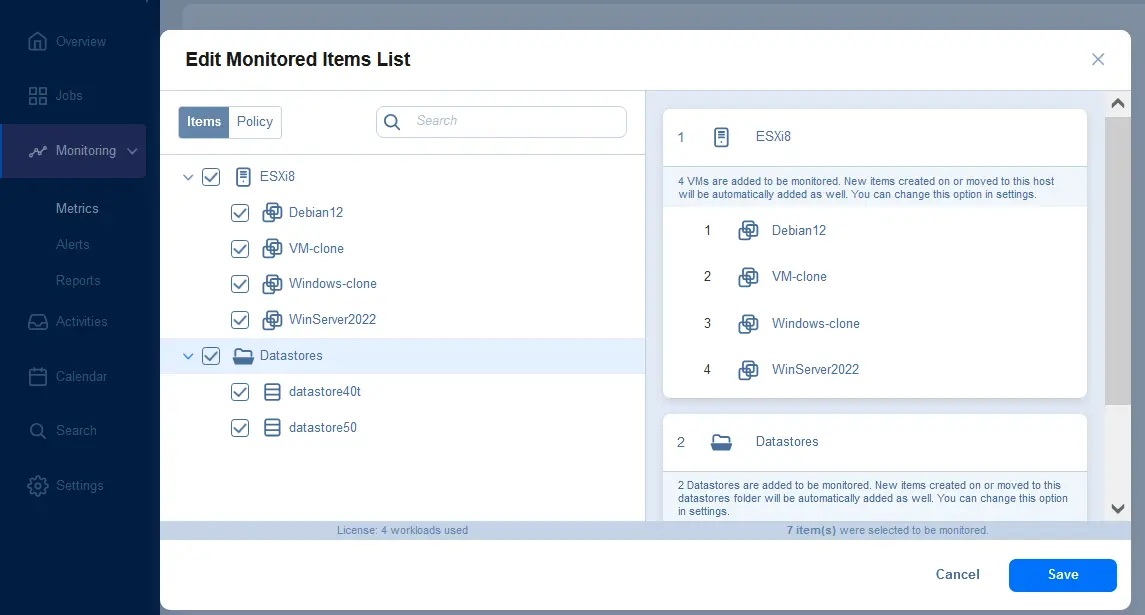
Het configureren van alarmen in de NAKIVO-oplossing
U kunt meldingen configureren in de NAKIVO-oplossing om zo snel mogelijk op de hoogte te worden gebracht van mogelijke problemen, zodat u ze snel kunt aanpakken voordat ze leiden tot ernstige gevolgen.
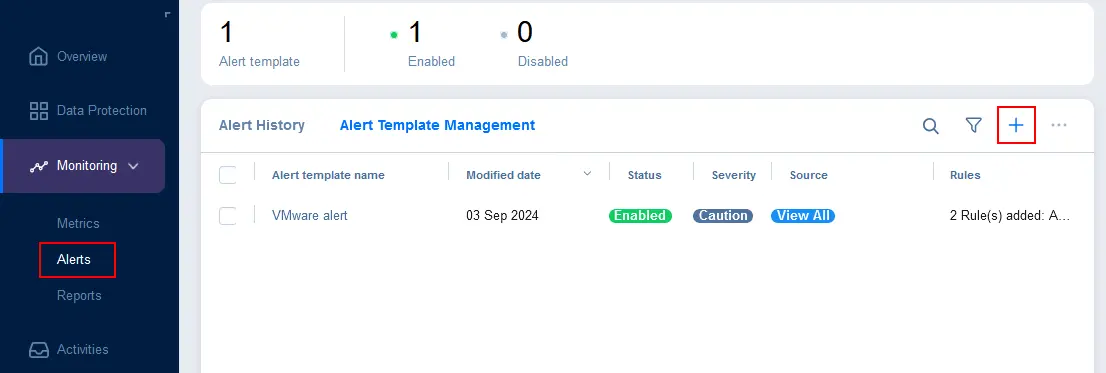
- Ga naar Monitoring > Alerts, selecteer het tabblad Alert Template Management, en klik op + om meldingen toe te voegen voor specifieke items.
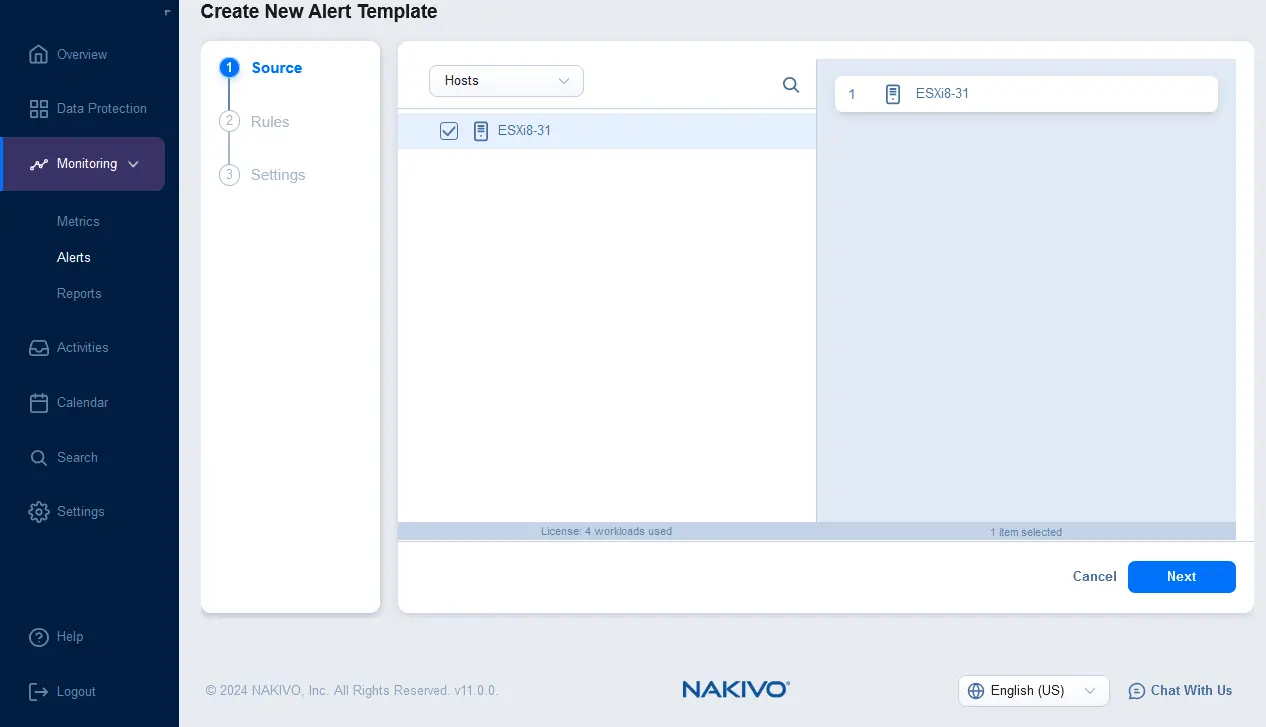
- Selecteer de gemonitorde items waarvoor het alarm moet worden geactiveerd. U kunt ESXi-hosts, virtuele machines (VM’s) of datastores selecteren. Klik op Volgende om door te gaan.
- Configureer regels voor een nieuw alert-sjabloon. Klik op + en selecteer de regelvoorwaarde. U kunt bijvoorbeeld een alert-sjabloon instellen dat moet worden geactiveerd als het gemiddelde geheugengebruik van de host meer dan 90% is gedurende 1 uur. U kunt meerdere regels toevoegen voor één alert-sjabloon.
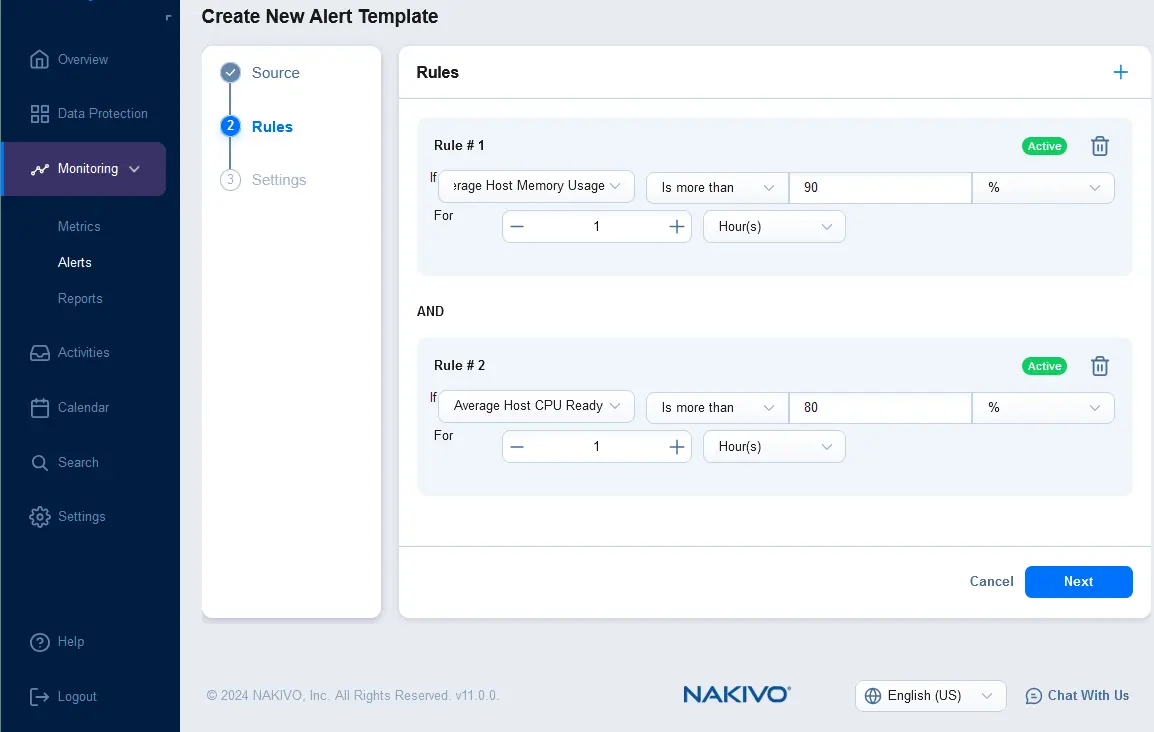
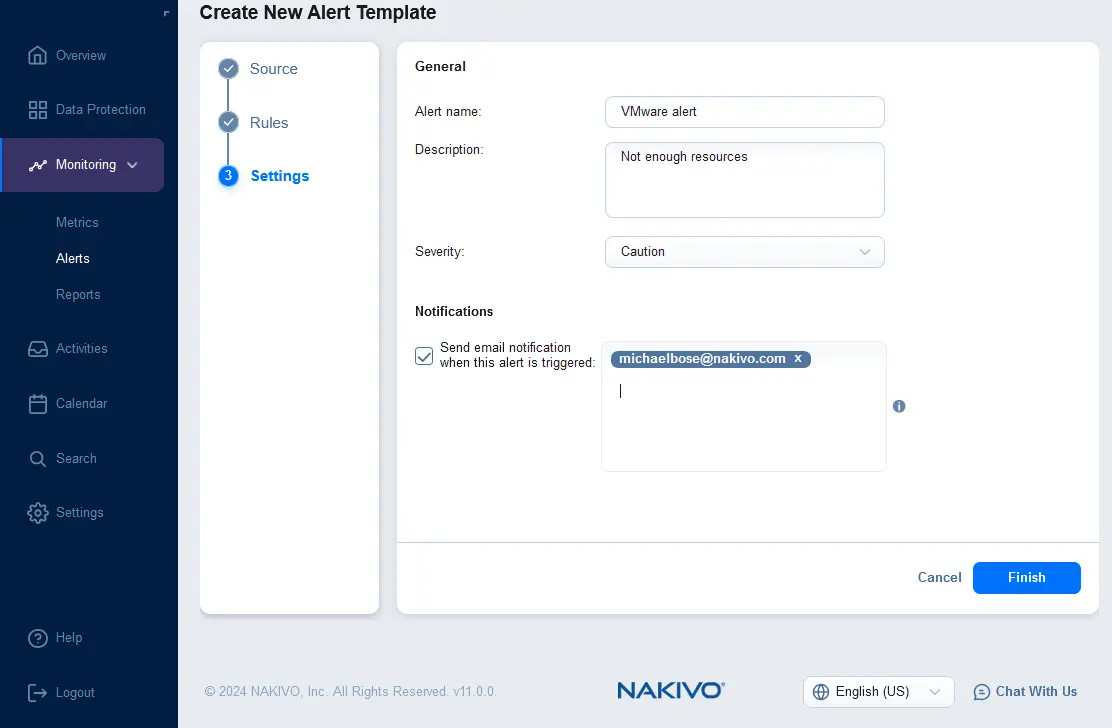
- Configureer de instellingen voor de alarmtemplate. Voer de naam en beschrijving van het alarm in en selecteer de ernst. U kunt het selectievakje aanvinken om een e-mailnotificatie te verzenden wanneer dit alarm wordt geactiveerd en meerdere e-mailadressen invoeren van de ontvangers die de alarmnotificaties moeten ontvangen. Klik op Voltooien.
Rapporten configureren in de NAKIVO-oplossing
- Om rapporten te configureren, gaat u naar Monitoring > Rapporten, klik op + en druk op Rapport.
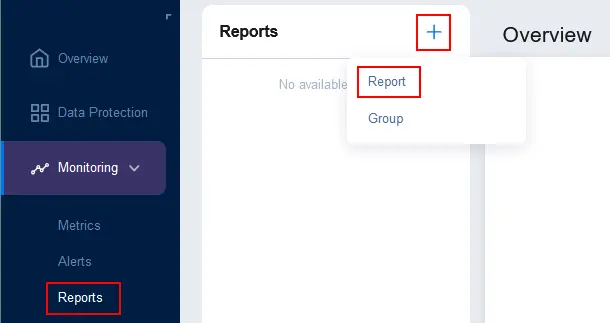
- U kunt een van de ondersteunde brontypes selecteren:
- Infrastructuur Overzicht – informatie over vCenter-servers, door vCenter beheerde ESXi-hosts en zelfstandige ESXi-hosts
- VM Prestaties
- Datastore Capaciteit
- Host Prestaties
- Beschermingsrapport
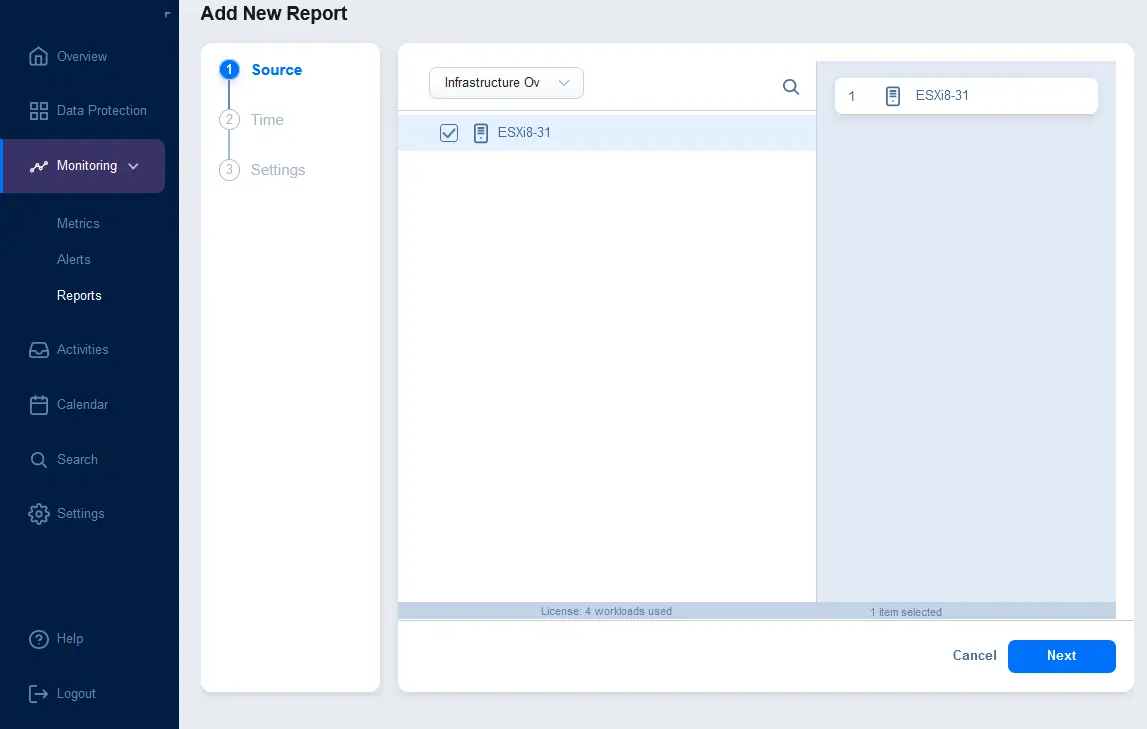
Wanneer het brontype is geselecteerd, selecteer dan de items die in het rapport moeten worden opgenomen. In de onderstaande schermafbeelding kunt u zien dat Infrastructuur Overzicht is geselecteerd in de vervolgkeuzelijst en een ESXi-host is geselecteerd om in het rapport op te nemen. Klik op Volgende om door te gaan.
- Configureer de tijd- en datumbereiken voor het rapport. U kunt bijvoorbeeld een rapport voor de afgelopen 30 dagen maken.
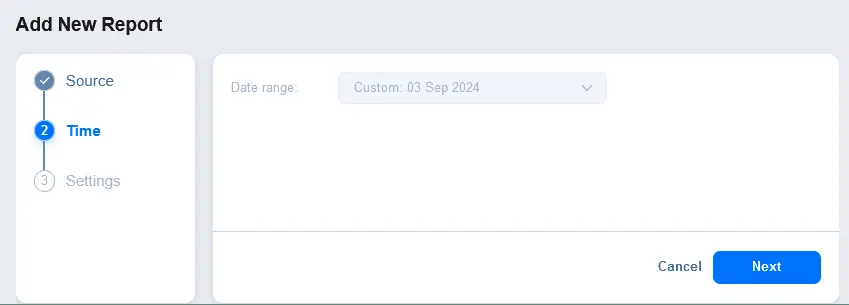
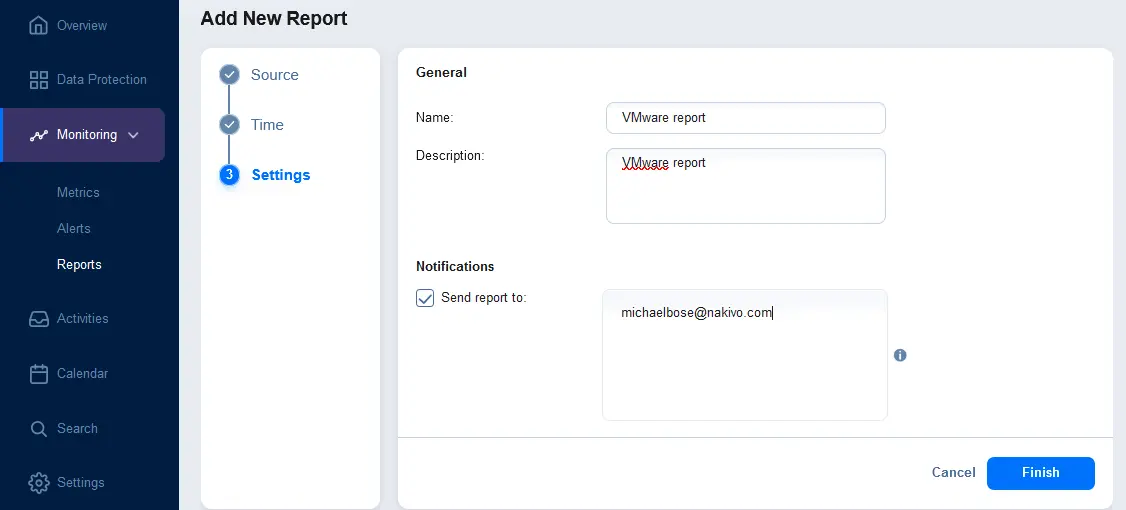
- Stel rapportinstellingen in. Voer een weergegeven rapportnaam en beschrijving in. Optioneel, in de Meldingen sectie, selecteer het selectievakje om een rapport naar de opgegeven e-mailadressen te sturen. Voer een e-mailadres in en druk op Enter om dit e-mailadres toe te passen. U kunt meerdere e-mailadressen invoeren. Klik op Voltooien om de instellingen voor het maken van het rapport op te slaan.
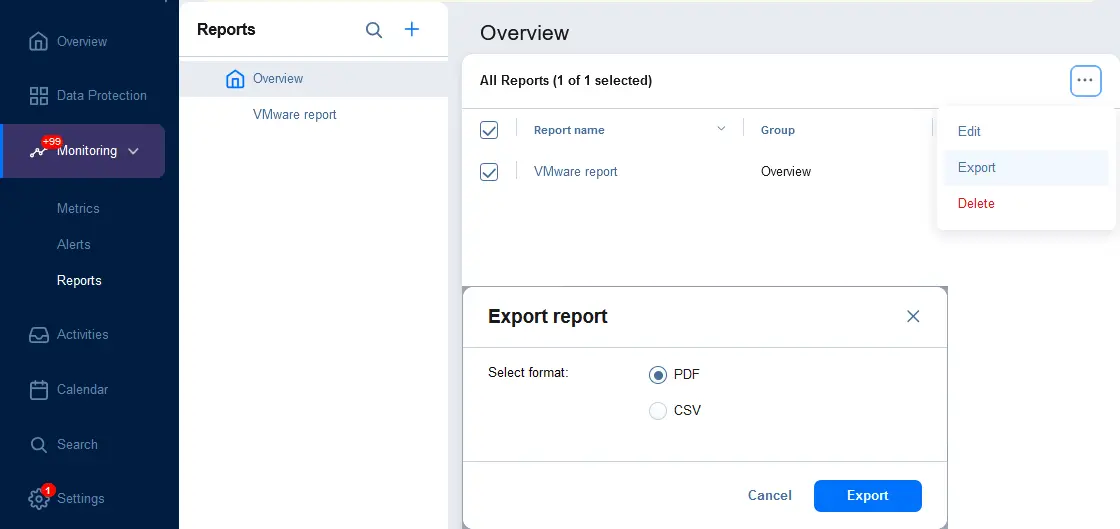
- U kunt rapporten exporteren naar een bestand. Ga naar Monitoring > Rapporten en selecteer de rapporten die u wilt exporteren (vink de selectievakjes aan). Klik op de … (meer opties) knop, klik op Exporteren, en selecteer in het dialoogvenster het bestandsformaat (PDF of CSV). Klik op Exporteren.
Conclusie
Het monitoren van IT-infrastructuur kan de efficiëntie van administratie verbeteren, bedrijfscontinuïteit waarborgen en kosten besparen. Het wordt aanbevolen om IT-monitoringtools te configureren om waarschuwingen en rapporten te versturen voor een vroegtijdige reactie op incidenten om potentiële problemen te voorkomen en bestaande problemen zo snel mogelijk op te lossen. Gebruik NAKIVO Backup & Replication om uw gegevens te beschermen, inclusief VMware virtuele machines, en om uw vSphere-infrastructuur en gegevensbeschermingstaken te monitoren.
Source:
https://www.nakivo.com/blog/how-to-use-alarms-and-reporting-for-it-monitoring/