













In Deel 1, hebben we verschillende belangrijke onderwerpen behandeld. Ik raad aan om het te lezen, aangezien dit volgende deel daarop voortbouwt.
Ter snelle herziening, in deel 1, hebben we onze gegevens vanuit een groot perspectief bekeken en onderscheid gemaakt tussen gegevens aan de binnenkant en gegevens aan de buitenkant. We hebben ook schema’s en datacontracten besproken en hoe ze de middelen bieden om onze stromen in de loop van de tijd te onderhandelen, te veranderen en te evolueren. Ten slotte hebben we de Fact (State) en Delta evenementtypes behandeld. Fact evenementen zijn het beste voor het communiceren van status en het ontkoppelen van systemen, terwijl Delta evenementen vaker worden gebruikt voor gegevens aan de binnenkant, zoals bij event sourcing en andere sterk gekoppelde gebruikssituaties.
Genormaliseerde Tabellen Maken Genormaliseerde Stromen
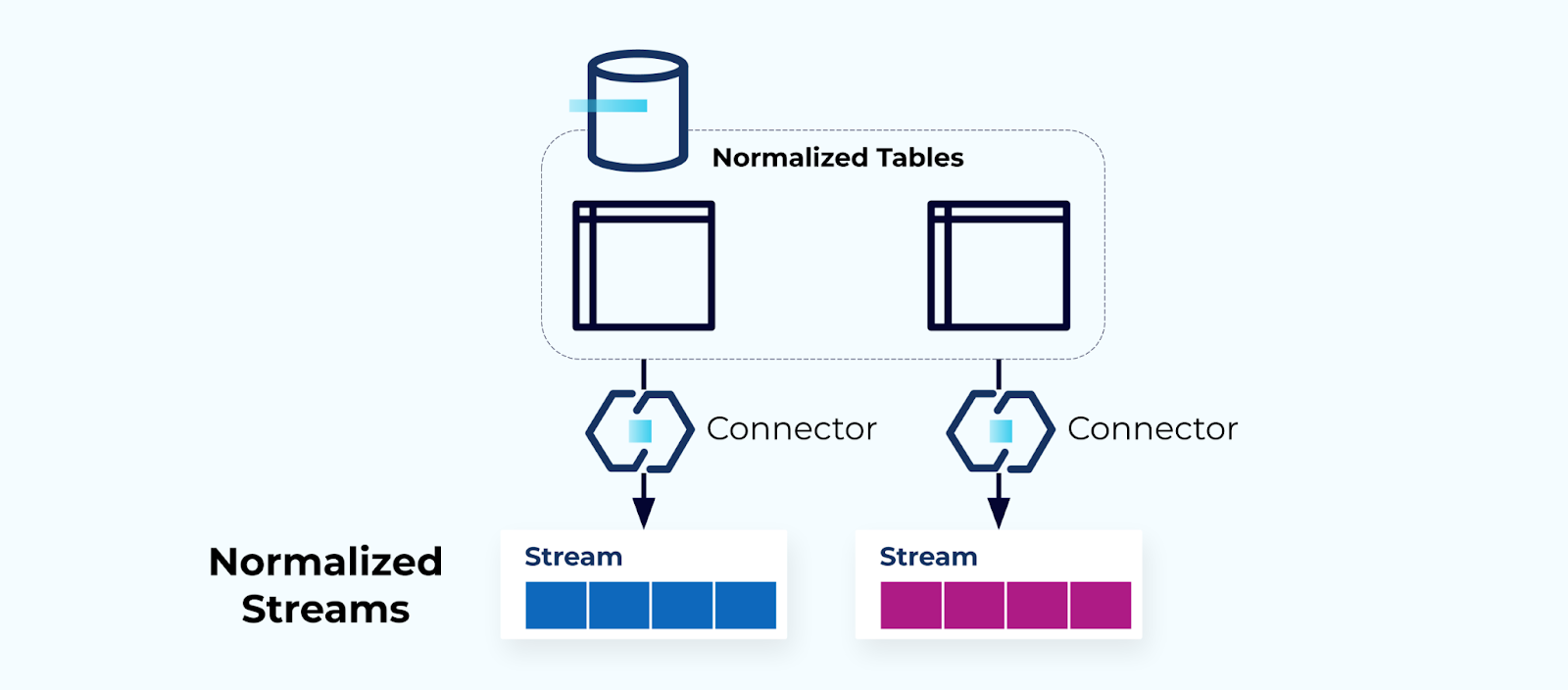
Genormaliseerde tabellen leiden tot genormaliseerde evenementstromen. Connectors (bijv. CDC) halen gegevens rechtstreeks uit de database in een gemirroreerde set van evenementstromen. Dit is niet ideaal, omdat het een sterke koppeling creëert tussen de interne database tabellen en de externe evenementstromen.
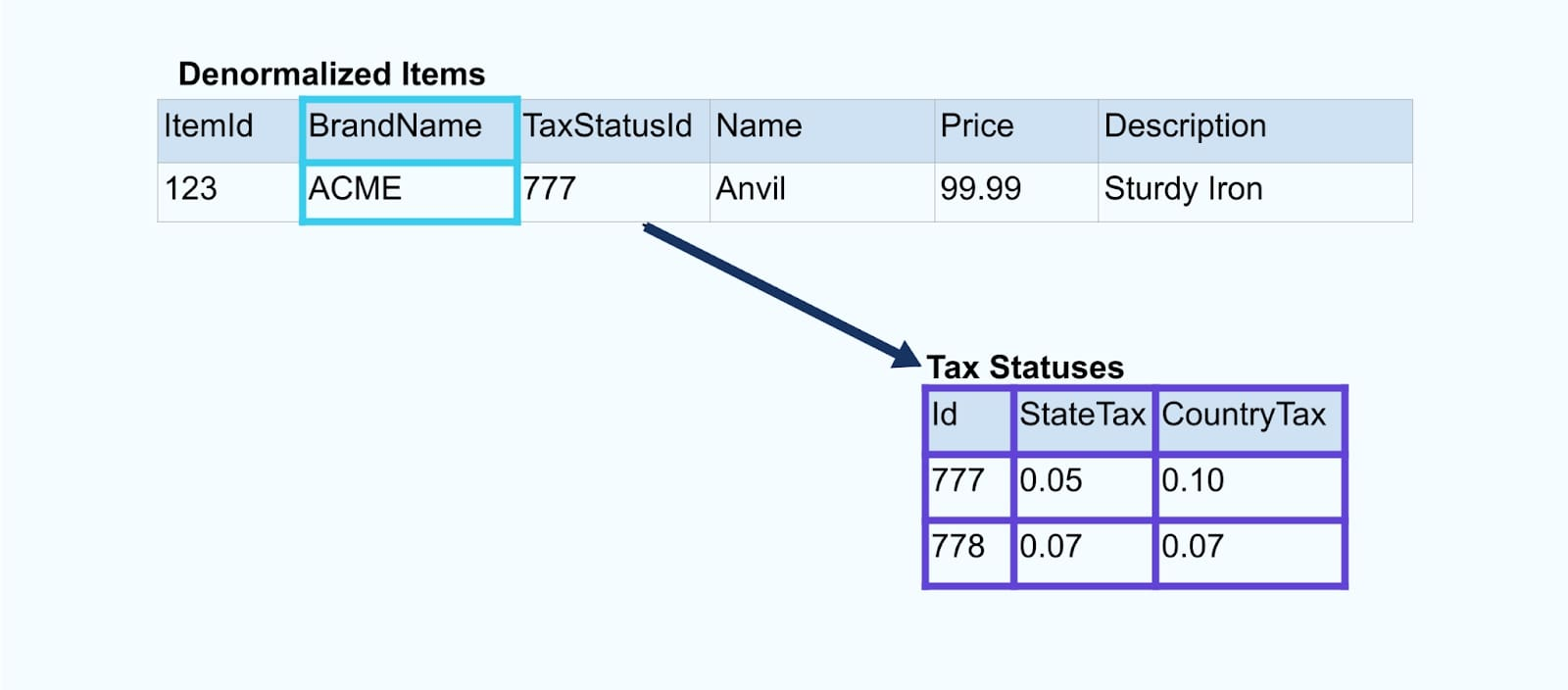
Overweeg een eenvoudig e-commerce Item en de bijbehorende Merk en Belastingstatus tabellen.
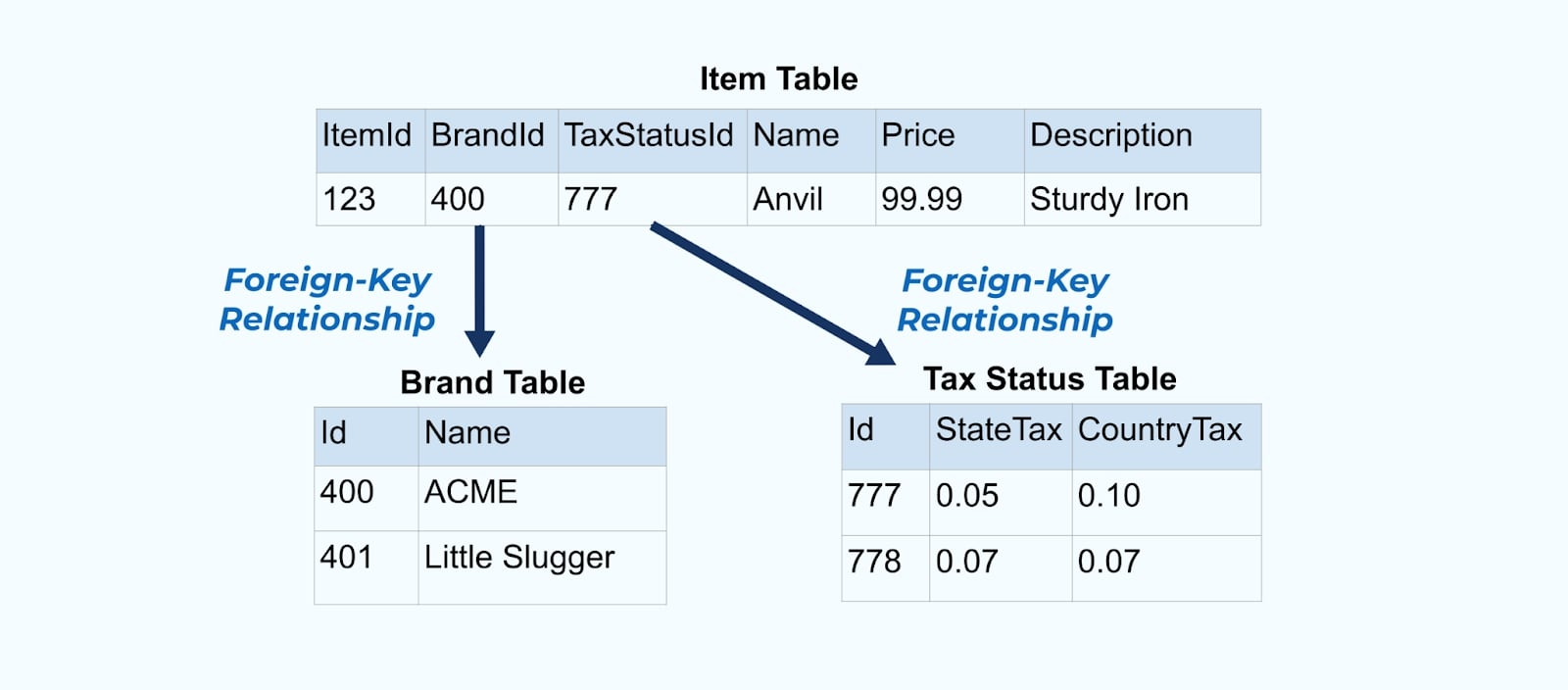
De Merk en Belastingstatus tabellen zijn gerelateerd aan de Item tabel via foreign-key relaties. Terwijl we slechts één item in de tabel tonen, heb je waarschijnlijk duizenden (of miljoenen), afhankelijk van de producten die je verkoopt.
Het is gebruikelijk om een connector voor elke tabel op te zetten, de gegevens uit de tabel te halen, deze samen te stellen tot evenementen en elke tabel naar een specifieke evenementstroom te schrijven.
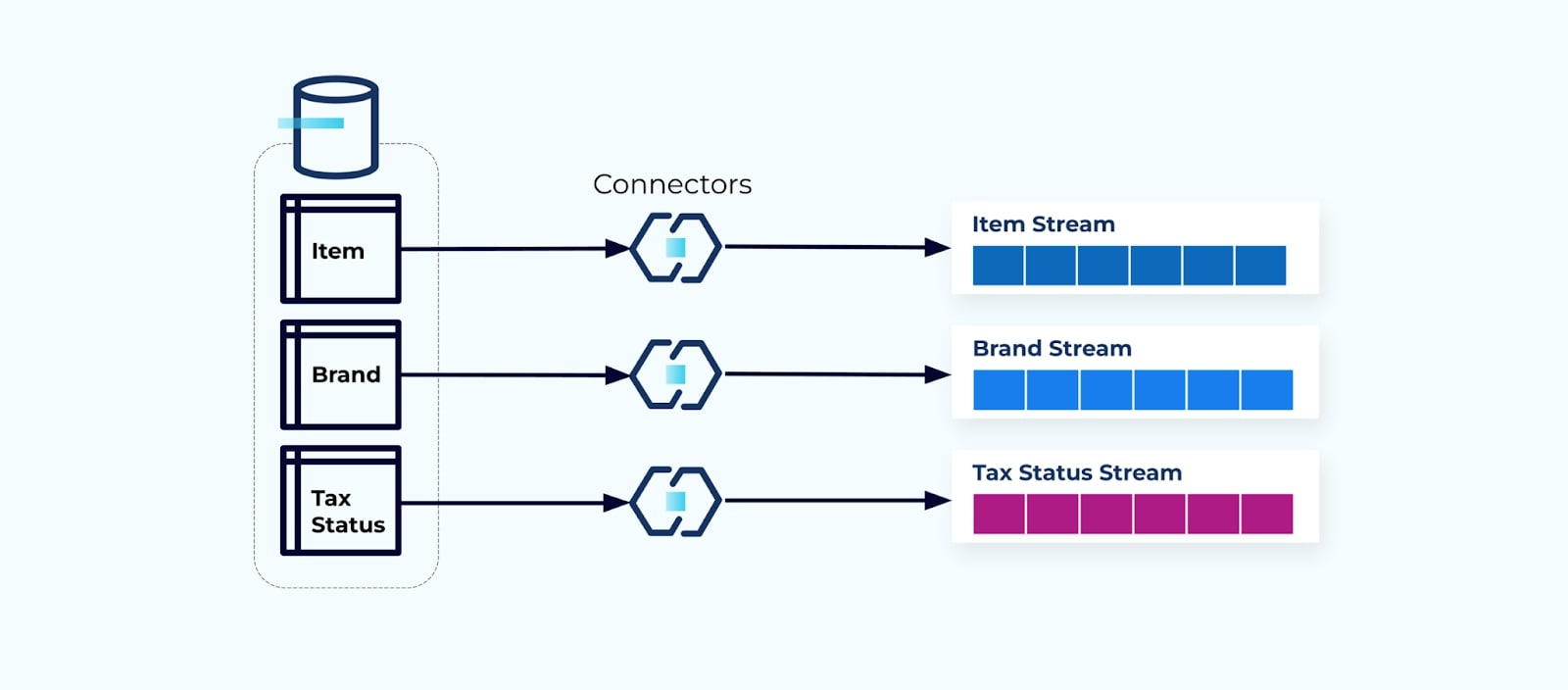
Het blootstellen van de onderliggende tabellen in de database leidt tot een bijbehorende evenementstroom per tabel. Hoewel het gemakkelijk is om op deze manier te beginnen, leidt het tot meerdere problemen, die samengevat kunnen worden als ofwel een koppeling probleem of een kosten probleem. Laten we elk probleem bekijken.
Probleem: Consumenten koppelen aan het interne model
Het blootstellen van de bron Item tabel zoals deze is, dwingt consumenten om hier direct aan te koppelen. Wijzigingen in het gegevensmodel van het bronsysteem hebben invloed op downstream consumenten.
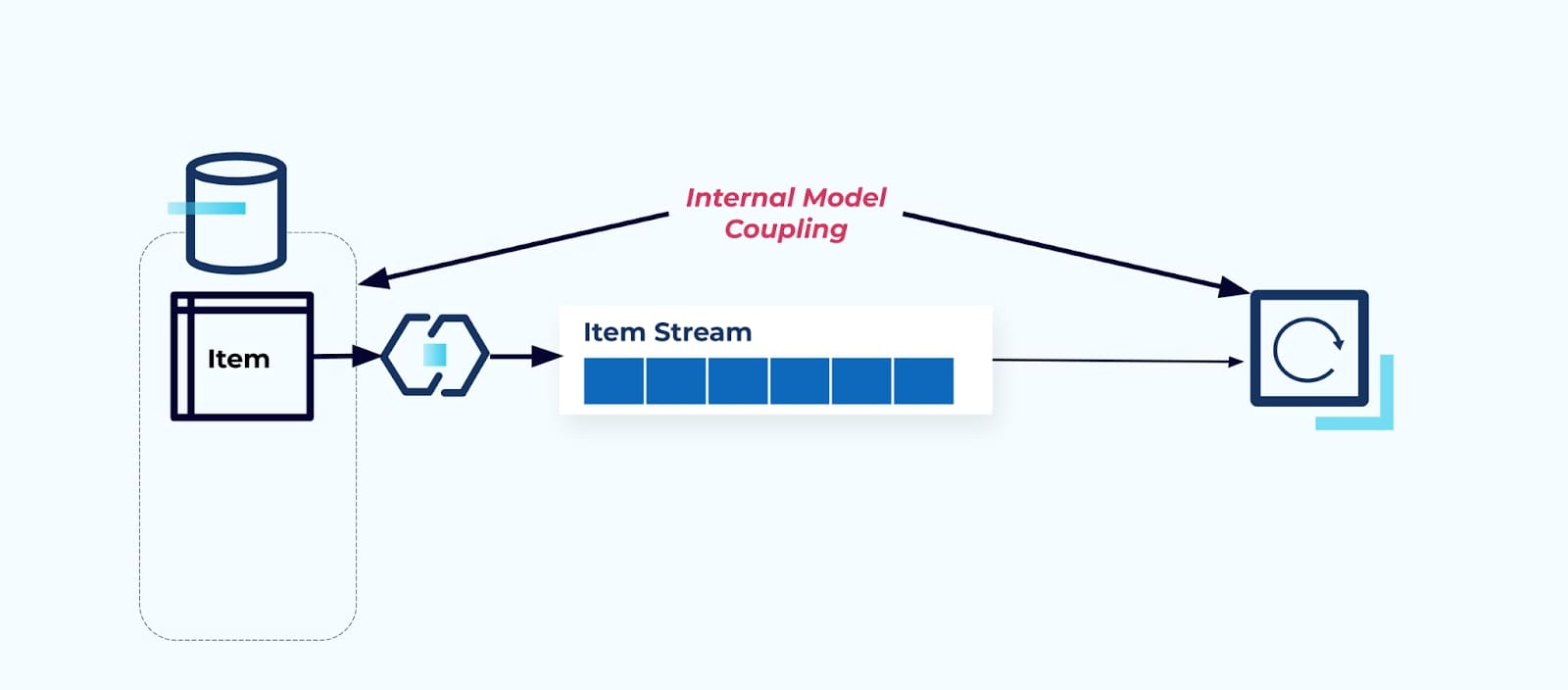
Stel dat we de Item tabel refactoren om Prijzen in zijn eigen tabel te extraheren.
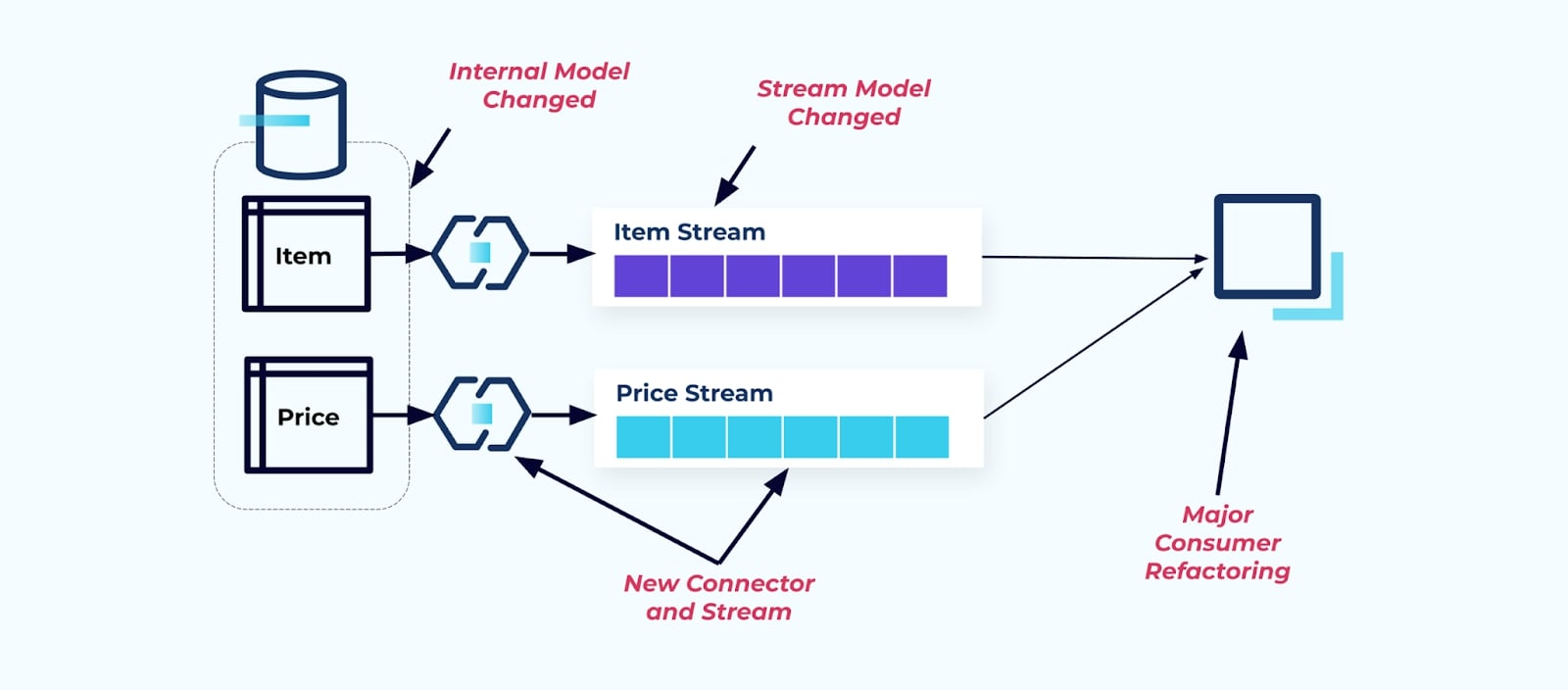
Het refactoren van de brontabellen resulteert in een verbroken gegevenscontract voor de itemstroom. De consument krijgt niet langer dezelfde itemgegevens die ze oorspronkelijk verwachtten. We moeten ook een nieuwe connector maken – een nieuwe Prijs-stroom – en tot slot onze consumentenlogica refactoren om het opnieuw te laten werken. Het hernoemen van kolommen, het wijzigen van standaardwaarden en het veranderen van kolomtypes zijn andere vormen van wijzigingen die worden geïntroduceerd door de strikte koppeling aan het interne gegevensmodel.
Probleem: Streaming Joins Zijn (Gewoonlijk) Duur
Relationele databases zijn speciaal ontworpen om snel en goedkoop joins op te lossen. Streaming joins zijn helaas dat niet.
Bekijk twee services die toegang willen tot een Item, de Belasting en de Merk-informatie. Als de gegevens al naar de bijbehorende stroom zijn geschreven, moeten elke consument (aan de rechterkant in de onderstaande afbeelding) dezelfde joins berekenen om Item, Merk, en Belasting te denormaliseren.
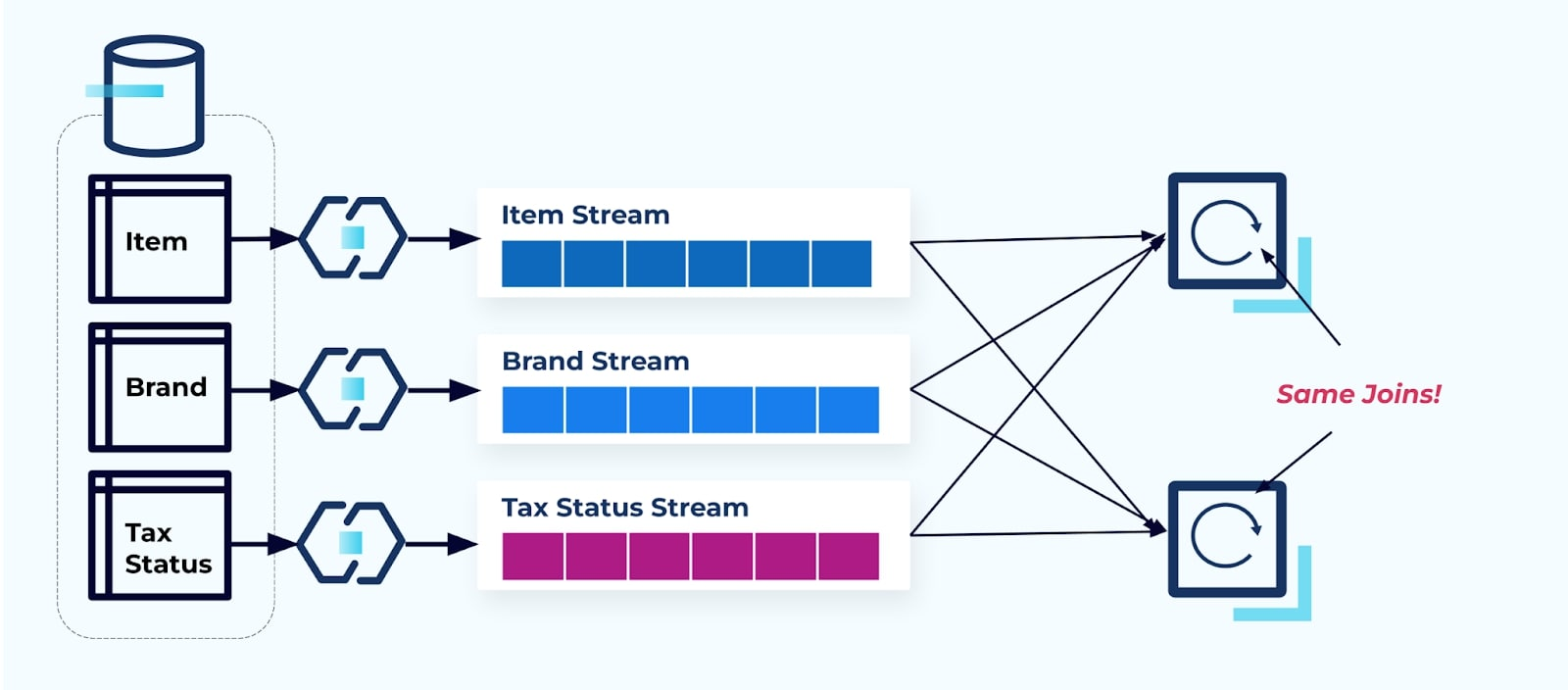
Deze strategie kan hoge kosten met zich meebrengen, zowel in ontwikkelingsuren voor het schrijven van de applicaties als in serverkosten voor het berekenen van de joins. Het oplossen van streaming joins op grote schaal kan leiden tot veel datashuffling, wat verwerkingskracht, netwerkkosten en opslagkosten met zich meebrengt. Bovendien ondersteunen niet alle streamverwerkingsframeworks joins, vooral niet op externe sleutels. Van degenen die dat wel doen, zoals Flink, Spark, KSQL of Kafka Streams (bijvoorbeeld), zul je merken dat je beperkt bent tot een subset van programmeertalen (Java, Scala, Python).
Oplossing: Het serveren van denormaliseerde gegevens is het beste
Als principe, maak gebeurenstreams gemakkelijk te gebruiken voor je consumenten. Denormaliseer de gegevens voordat je ze beschikbaar stelt aan consumenten met behulp van een abstractielaag en creëer een expliciet extern model gegevenscontract (gegevens aan de buitenkant) waar consumenten zich op kunnen aansluiten.
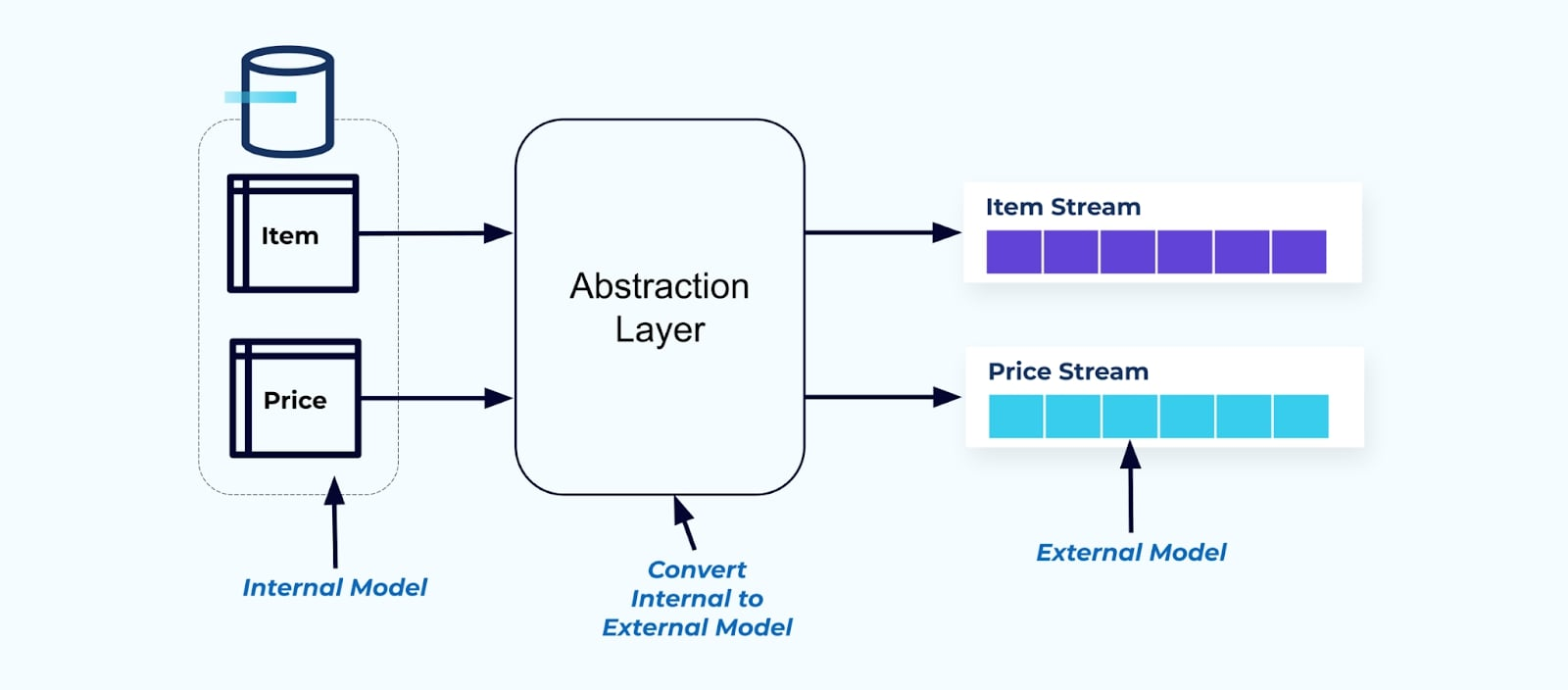
Wijzigingen in het interne model blijven geïsoleerd in de bronsystemen. Consumenten krijgen een goed gedefinieerd gegevenscontract om zich op aan te sluiten. Wijzigingen die worden aangebracht in het bronsysteem kunnen ongehinderd doorgaan, zolang het bronsysteem het gegevenscontract voor de consumenten handhaaft.
Maar waar denormaliseren we? Twee opties:
- Herconstrueren buiten het bronsysteem via een speciaal gebouwde join-service.
- Tijdens het maken van gebeurtenissen in het bronsysteem met behulp van het Transactie Uitbox patroon.
Laten we elk oplossing eens bekijken.
Optie 1: Denormaliseren met behulp van een speciaal gebouwde join-service
In dit voorbeeld spiegelen de streams aan de linkerkant de tabellen waar ze vandaan komen in de database.
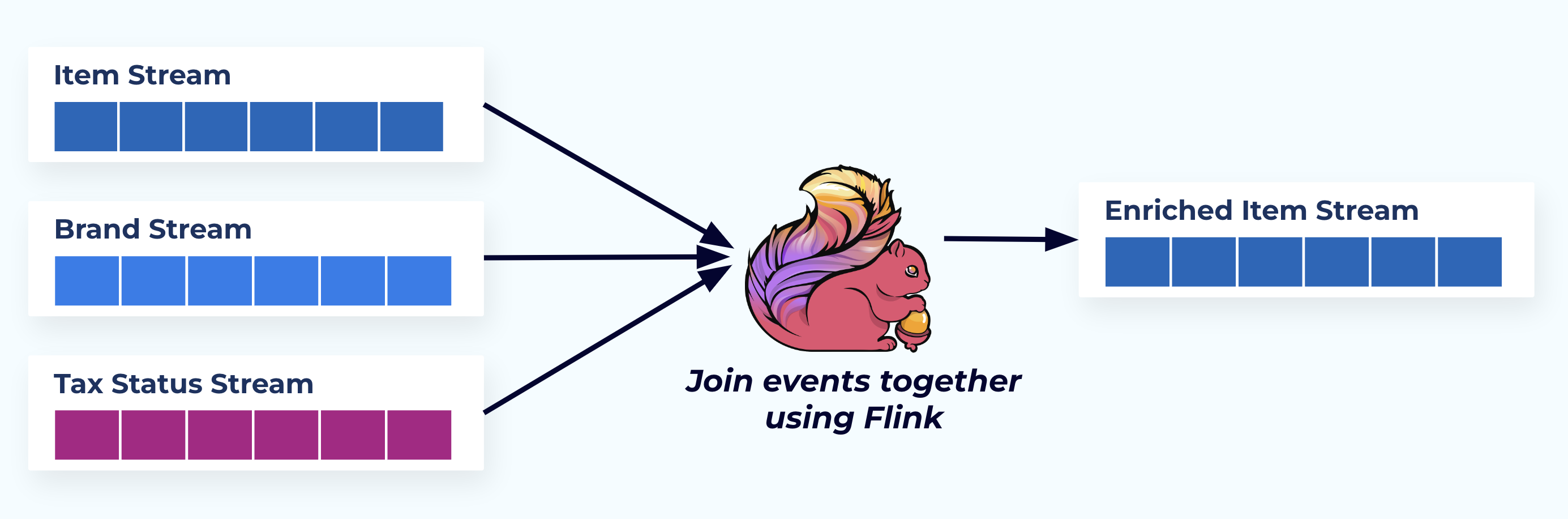
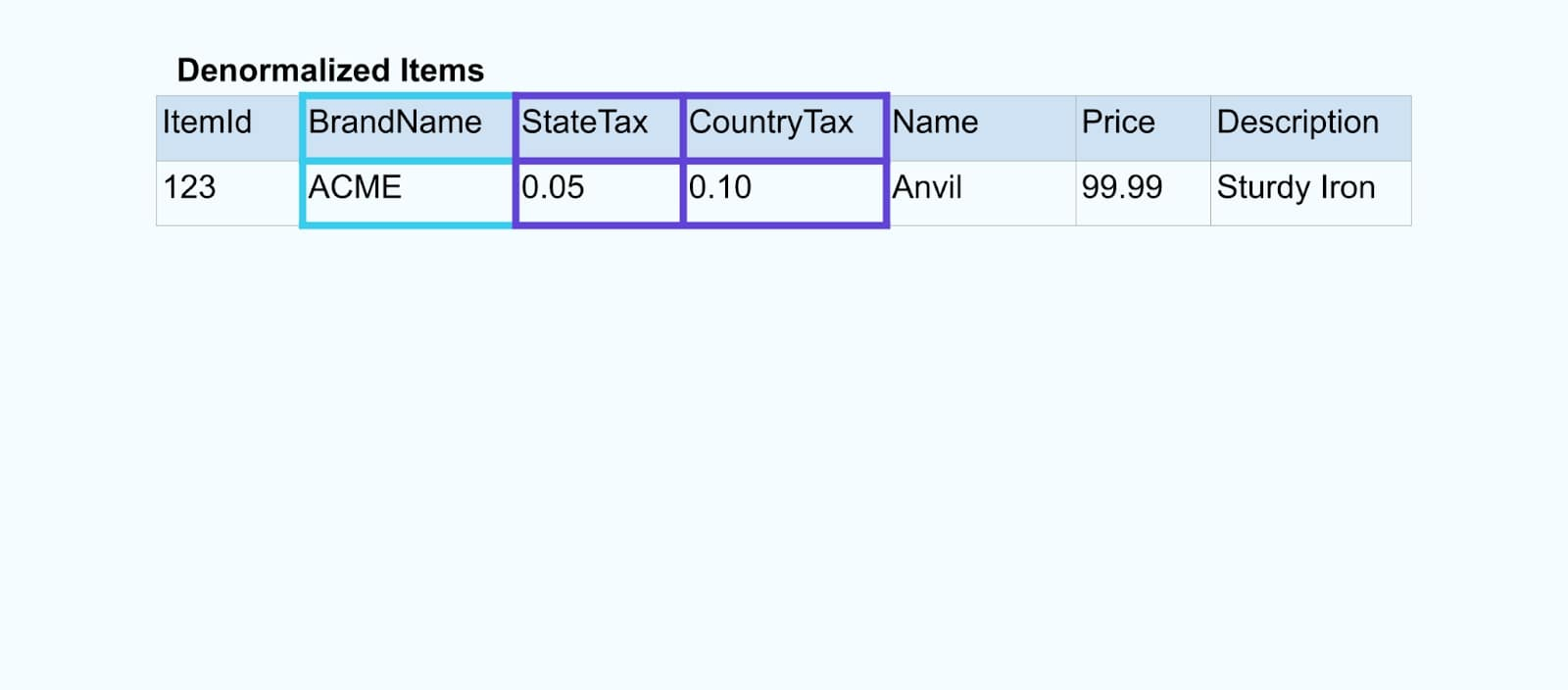
We voegen de gebeurtenissen samen met behulp van een speciaal gebouwde applicatie (of streaming SQL-query) op basis van de foreign-key relaties en produceren een enkele verrijkte itemstroom.

Logischerwijs lossen we de relaties op en verkleinen we de gegevens tot een enkele gedemormaliseerde rij.
Speciaal gebouwde joiners vertrouwen op streamverwerkingsframeworks zoals Apache Kafka Streams en Apache Flink om zowel primaire als foreign key joins op te lossen. Ze materialiseren de streamgegevens in duurzame interne tabelindelingen, waardoor de joinerapplicatie gebeurtenissen over willekeurige periodes kan samenvoegen – niet alleen die beperkt zijn door een tijdsgebonden venster.
Joiners die Flink of Kafka Streams gebruiken zijn ook opmerkelijk schaalbaar — ze kunnen meeschalen met de belasting en enorme hoeveelheden verkeer verwerken.
Een tip: Plaats geen bedrijfslogica in de joiner. Om succesvol te zijn in dit patroon, moet de samengevoegde data nauwkeurig het bronmateriaal vertegenwoordigen, eenvoudig als een gedemormaliseerd resultaat. Laat de downstreamgebruikers hun eigen bedrijfslogica toepassen, gebruikmakend van de gedemormaliseerde data als enige bron van waarheid.
Als je geen downstream joiner wilt gebruiken, zijn er andere opties. Laten we vervolgens eens kijken naar het transactionele outbox-patroon.
Optie 2: Transactioneel Outbox-patroon
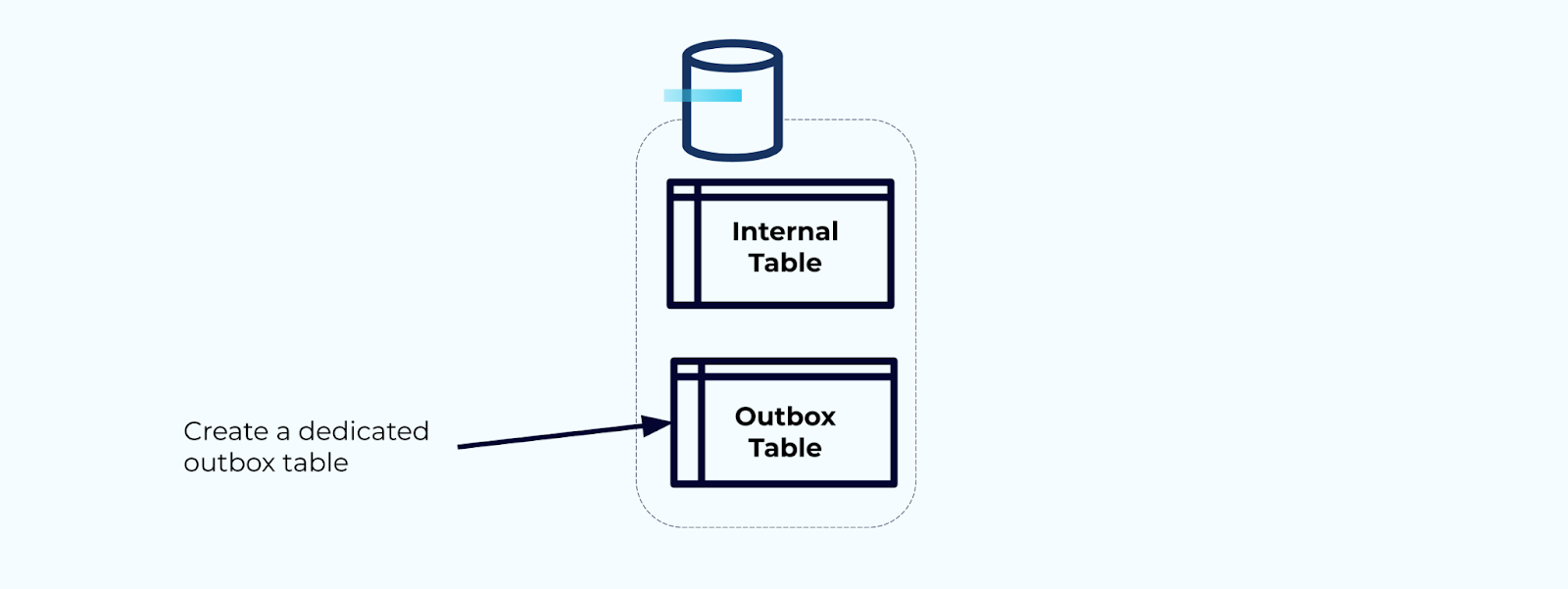
Maak eerst een speciale outbox-tabel aan voor het schrijven van gebeurtenissen naar de stroom.
Ten tweede, omwikkel alle noodzakelijke interne tabelupdates in een transactie. Transacties garanderen dat alle updates die aan de interne tabel worden gedaan, ook worden geschreven naar de outbox-tabel.
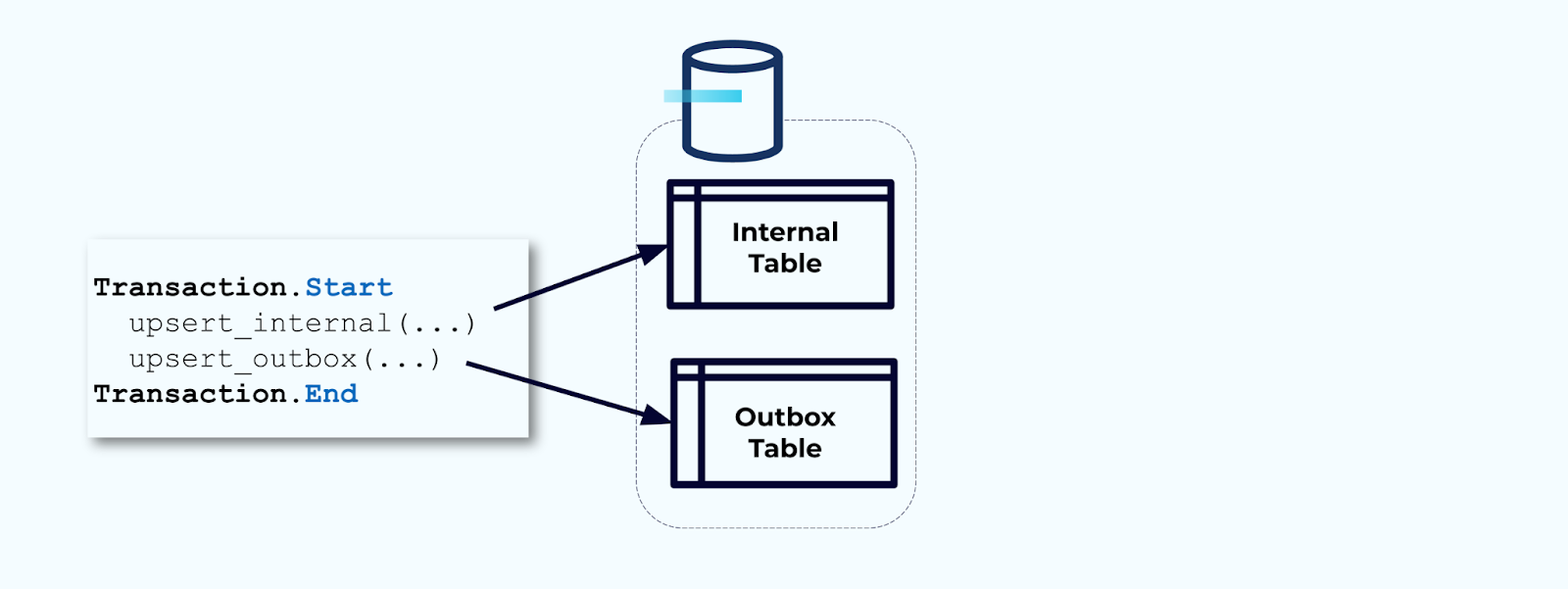
De outbox stelt je in staat om het interne gegevensmodel te isoleren, omdat je de gegevens kunt samenvoegen en transformeren voordat je ze naar je outbox schrijft. De outbox fungeert als de abstractielaag tussen je gegevens aan de binnenkant en gegevens aan de buitenkant, als een gegevenscontract voor je consumenten.
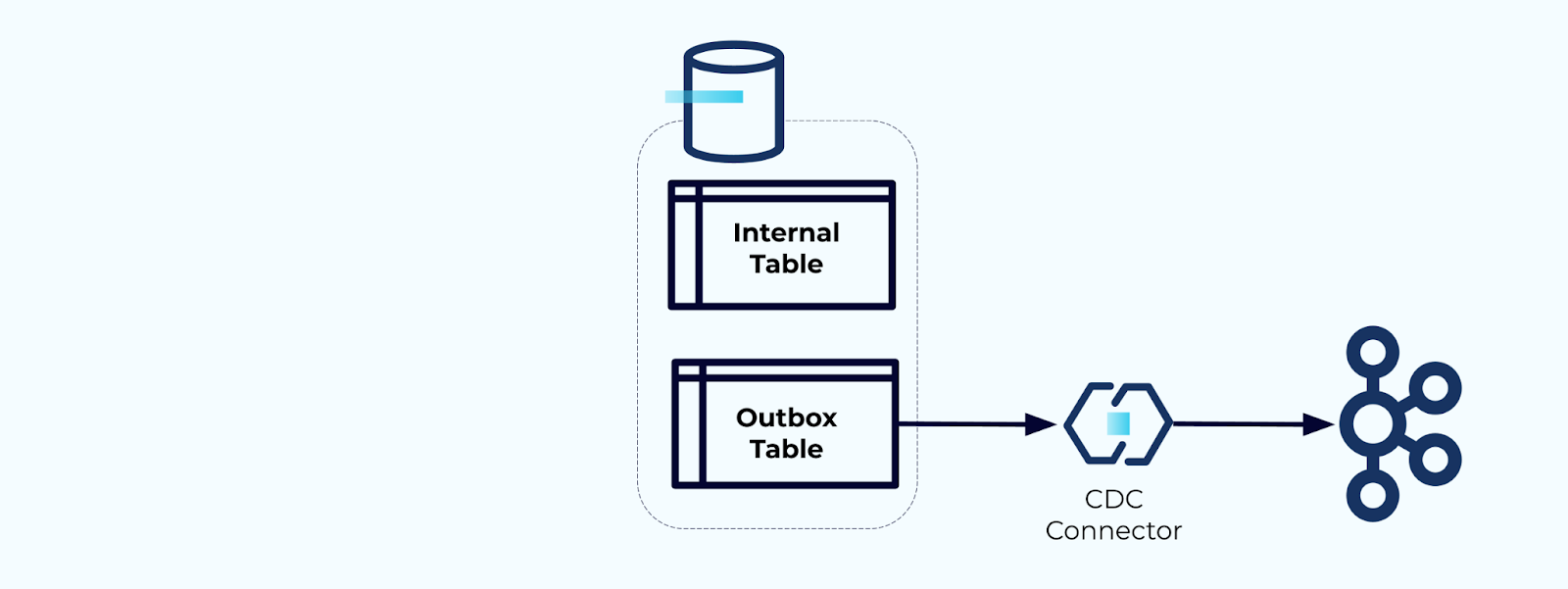
Tenslotte kun je een connector gebruiken om de gegevens uit de outbox te halen en naar Kafka te brengen.
Je moet ervoor zorgen dat de outbox niet oneindig blijft groeien – verwijder de gegevens na vastlegging door de CDC of periodiek met een geplande taak.
Voorbeeld: Denormaliseren van Gebruikersgedrag Tracking Gebeurtenissen
Het bijhouden van gebruikersgedrag op je webpagina’s en applicaties is een veelvoorkomende bron van genormaliseerde gebeurtenissen – denk aan Google Analytics of interne opties van de eerste partij. Maar we nemen niet alle informatie in de gebeurtenis op; in plaats daarvan beperken we het tot identificatoren (sneller, kleiner, goedkoper), denormaliseren nadat de feiten zijn gecreëerd.
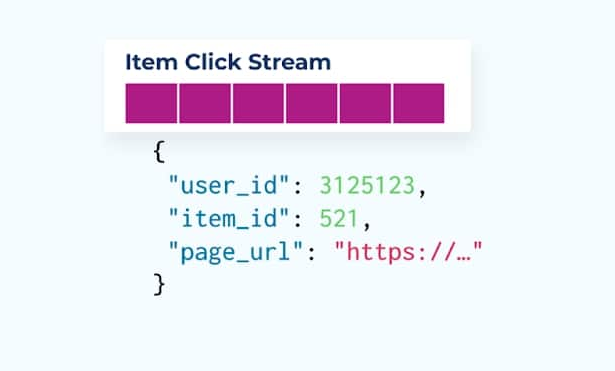
Bekijk een stroom van itemklikgebeurtenissen die aangeven wanneer een gebruiker op een item heeft geklikt tijdens het browsen door e-commerce-items. Let op dat deze itemklikgebeurtenis geen rijkere iteminformatie bevat, zoals naam, prijs en beschrijving, alleen basis ids.
Het eerste wat veel click-stream consumenten doen is deze combineren met de item fact stream. En aangezien je te maken hebt met veel click gebeurtenissen, ontdek je dat dit uiteindelijk een grote hoeveelheid rekenkracht vergt. Een speciaal gebouwde Flink applicatie kan de item clicks combineren met de gedetailleerde item data en deze uitsturen naar een verrijkte item click stream.
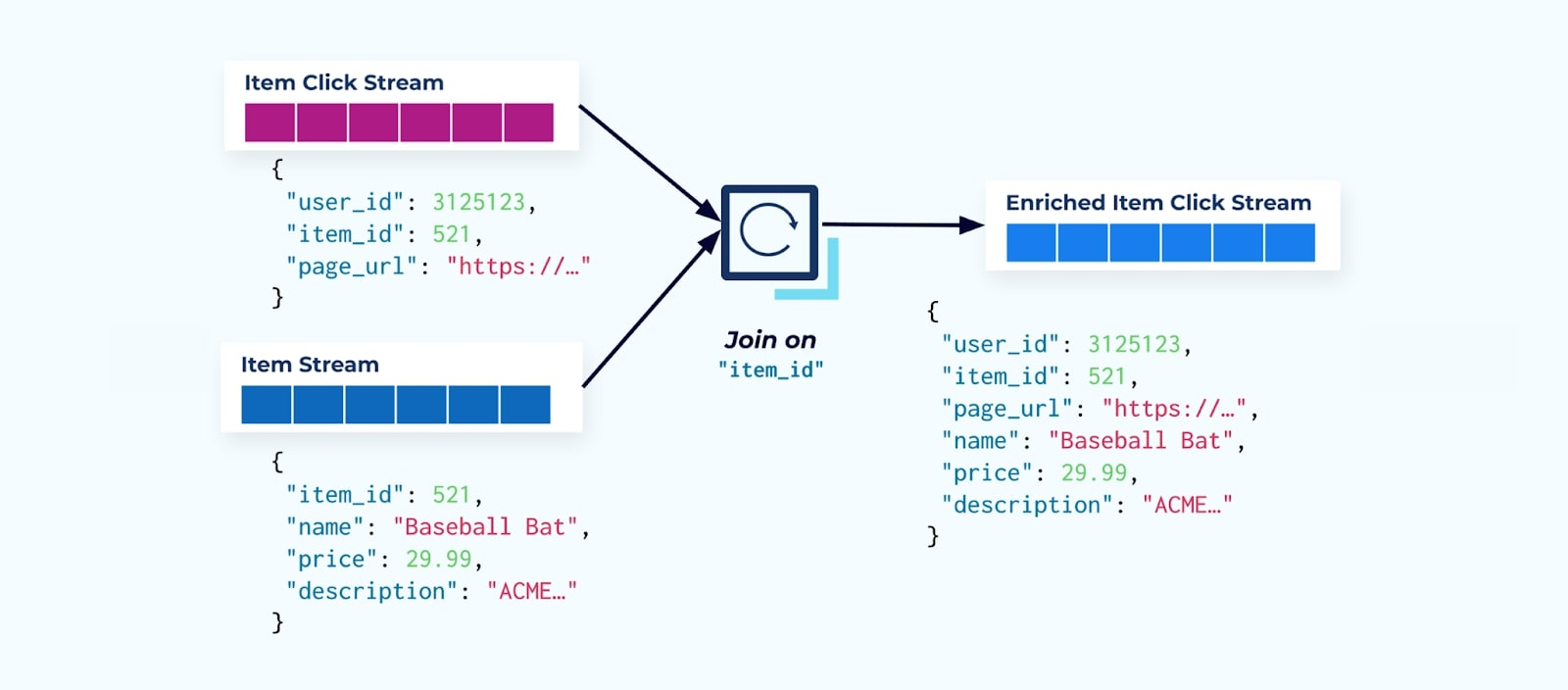
Grotere bedrijven met meerdere afdelingen (en systemen) zullen waarschijnlijk zien dat hun gegevens uit verschillende bronnen komen, en het combineren achteraf met behulp van een stream joiner is het meest waarschijnlijke resultaat.
Overwegingen met betrekking tot Langzaam-Wijzigende Dimensies
We hebben al gesproken over de prestatieoverwegingen bij het schrijven van gebeurtenissen die grote datasets bevatten (bijv. grote tekstblobs) en domeinen die vaak veranderen (bijv. itemvoorraad). Nu zullen we kijken naar langzaam-wijzigende dimensies (SCDs), vaak aangegeven via een foreign-key-relatie, aangezien deze een andere bron van aanzienlijke gegevensvolumes kunnen zijn.
Laten we weer teruggaan naar ons itemvoorbeeld. Stel dat je een bewerking hebt die de Itemtabel bijwerkt. We gaan het item hernoemen van Anvil naar Iron Anvil.
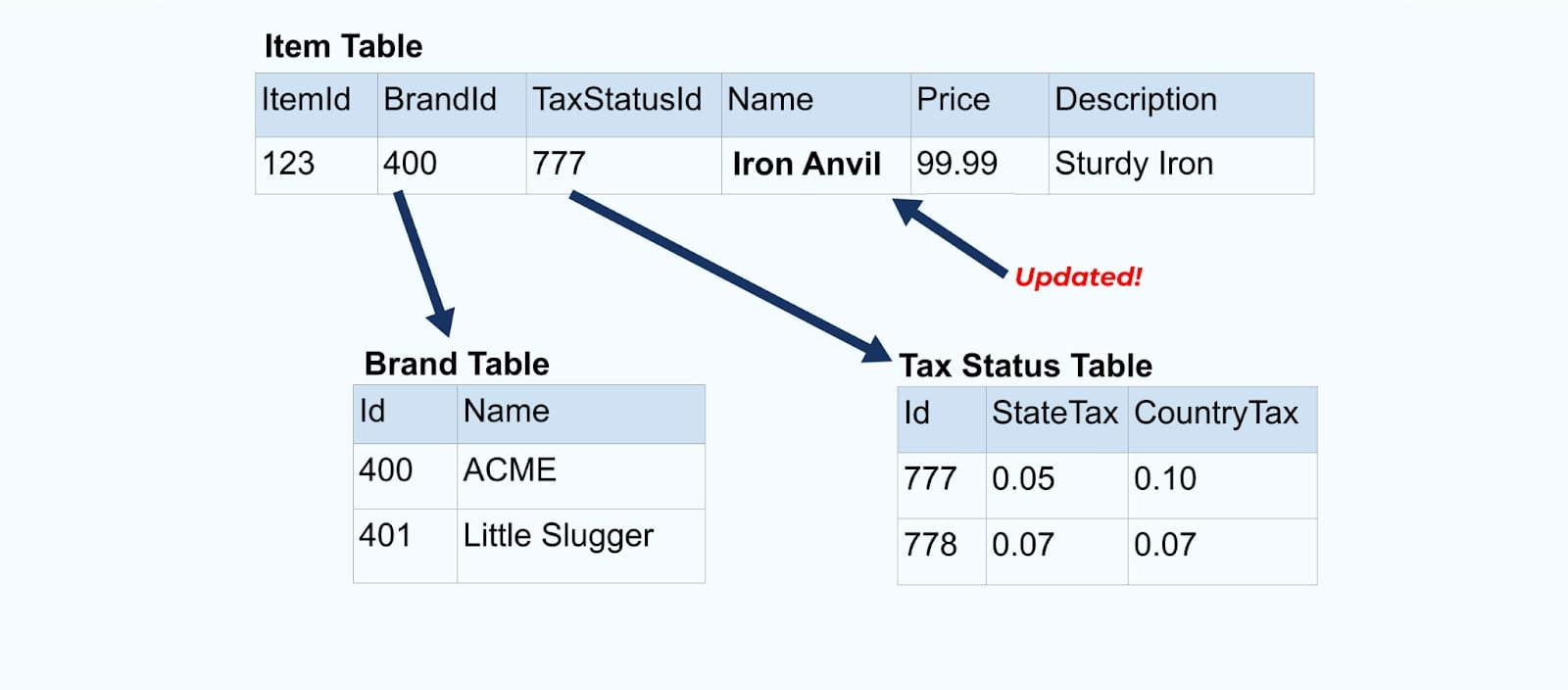
Bij het bijwerken van de gegevens in de database sturen we ook het bijgewerkte item uit (bijvoorbeeld via het outbox-patroon), compleet met de gedemoraliseerde belastingstatus en merktabel.
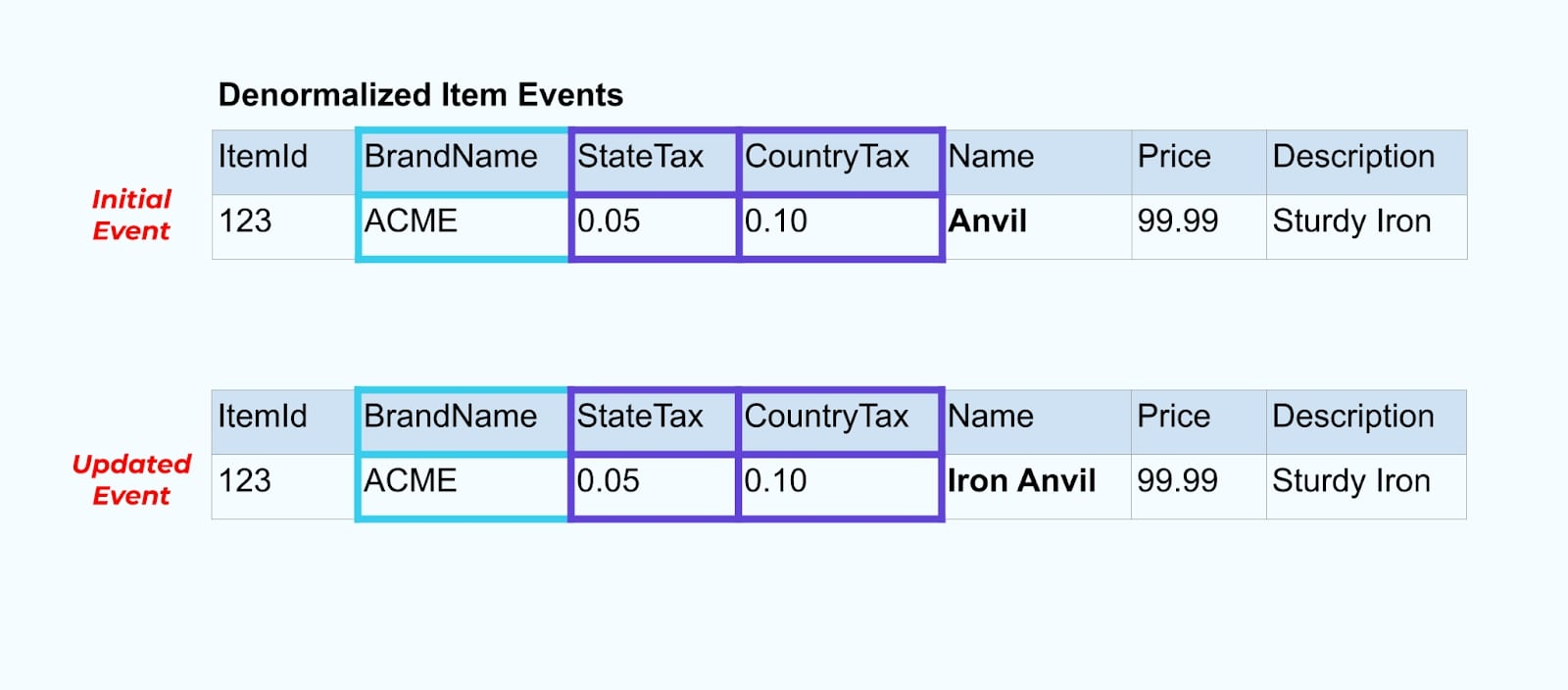
Echter, we moeten ook overwegen wat er gebeurt wanneer we waarden in de merk- of belastingtabellen wijzigen. Het bijwerken van een van deze langzaam-wijzigende dimensies kan resulteren in een aanzienlijk groot aantal updates voor alle betrokken items.
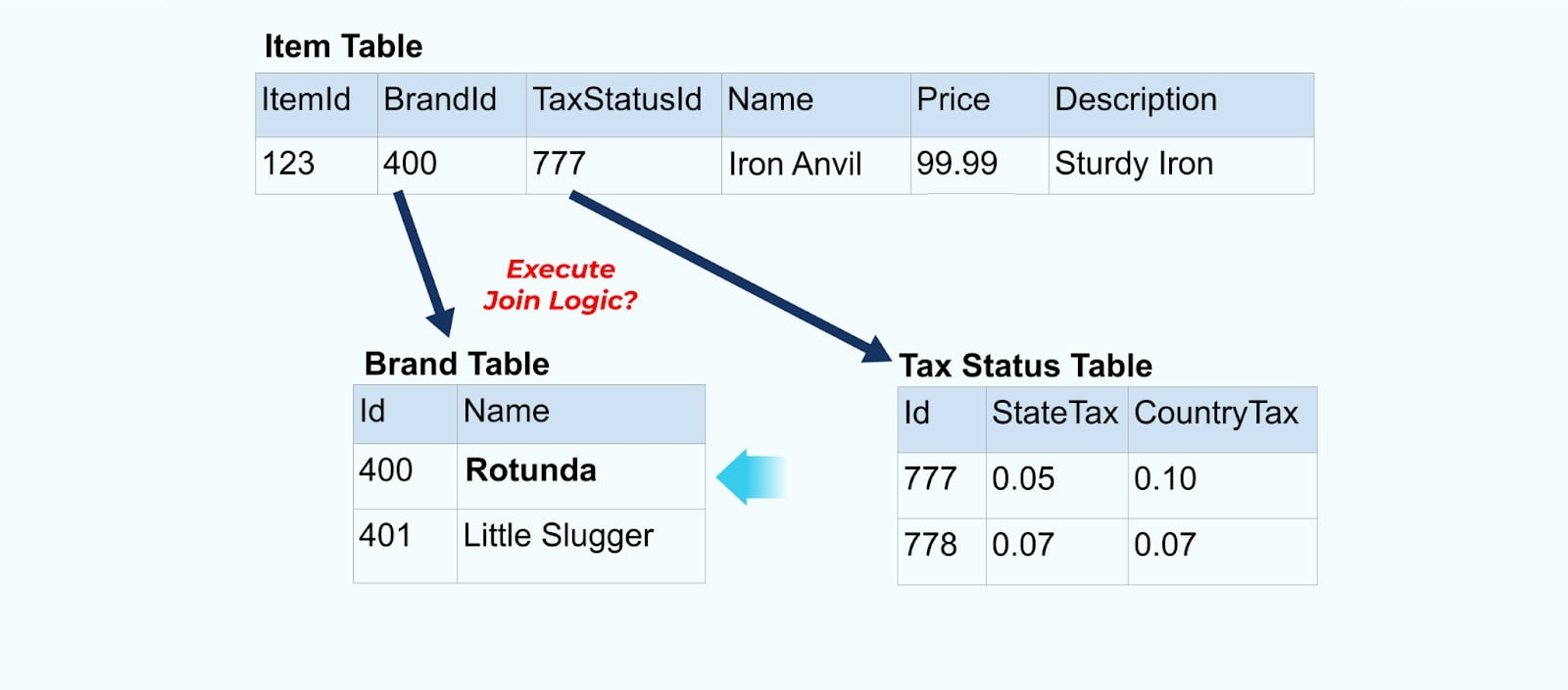
Bijvoorbeeld ondergaat het bedrijf ACME een rebranding en komt met een nieuwe merknaam, waarbij ze veranderen van ACME naar Rotunda. We organiseren nog een evenement voor ItemId=123.
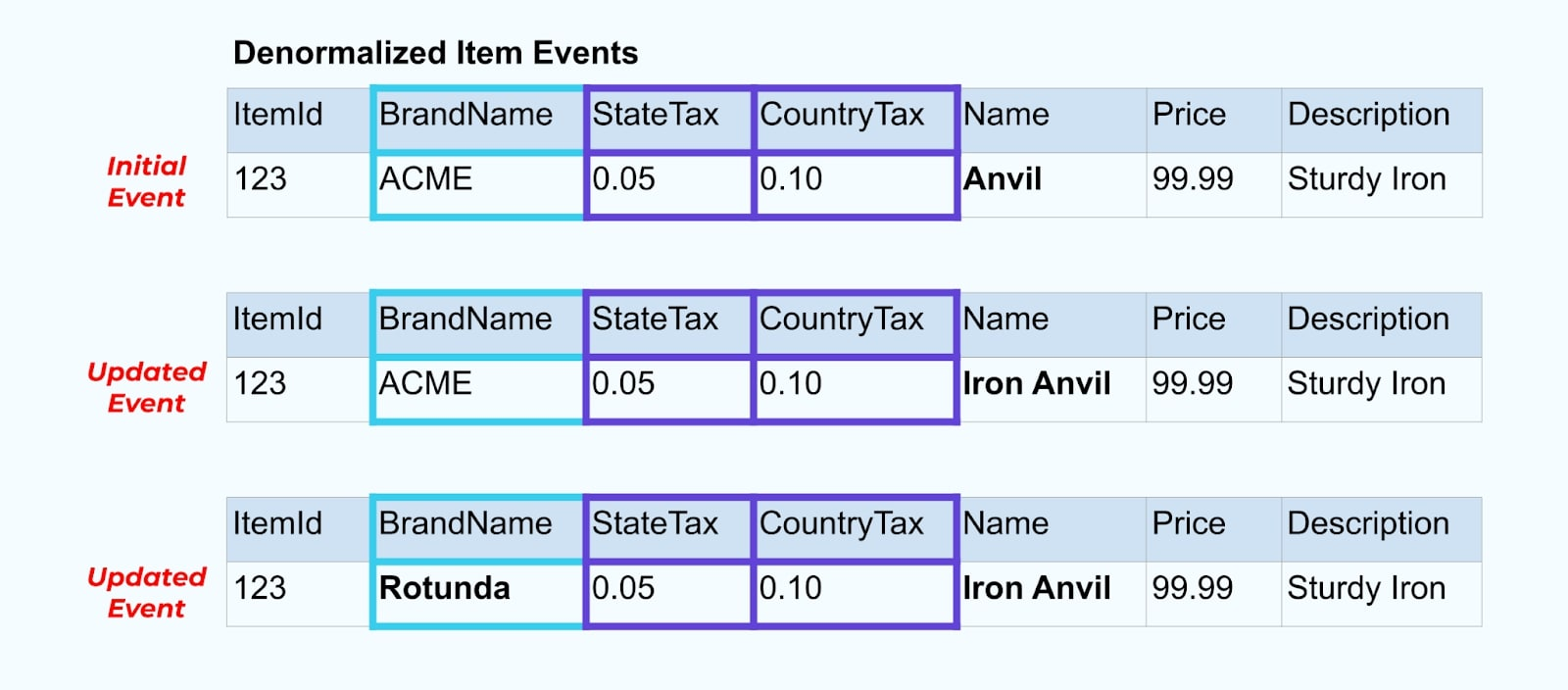
Echter heeft Rotunda (voorheen ACME) waarschijnlijk vele honderden (of duizenden) items die ook bijgewerkt worden door deze verandering, resulterend in een overeenkomstig aantal bijgewerkte verrijkte itemgebeurtenissen.
Als je SCD’s en foreign-key relaties denormaliseert, houd dan rekening met de impact die een verandering in de SCD kan hebben op de gebeurtenissenstroom als geheel. Je kunt besluiten om denormalisatie over te slaan en dit over te laten aan de consument in het geval dat een verandering in de SCD resulteert in miljoenen of miljarden bijgewerkte gebeurtenissen.
Samenvatting
Denormalisatie maakt het voor consumenten gemakkelijker om gegevens te gebruiken, maar gaat ten koste van meer upstream-verwerking en een zorgvuldige selectie van gegevens om op te nemen. Consumenten kunnen gemakkelijker toepassingen bouwen en kunnen kiezen uit een breder scala aan technologieën, ook die welke geen streaming joins native ondersteunen.
Normalisatie van gegevens upstream werkt goed wanneer de gegevens klein zijn en zelden worden bijgewerkt. Grotere gebeurtenisgroottes, frequente updates en SCD’s zijn allemaal factoren om op te letten bij het bepalen wat je upstream moet denormaliseren en wat je aan je consumenten moet overlaten om zelf te doen.
Uiteindelijk is het kiezen van welke gegevens moeten worden opgenomen in een gebeurtenis en welke moeten worden weggelaten een evenwichtsoefening tussen de behoeften van de consument, de mogelijkheden van de producent en de unieke gegevensmodelrelaties. Maar de beste plek om te beginnen is door de behoeften van je consumenten en de isolatie van het interne gegevensmodel van je bronsysteem te begrijpen.
Source:
https://dzone.com/articles/how-to-design-event-streams-part-2