













De komst van het Apache Hadoop Distributed File System (HDFS) revolutioneerde de opslag, verwerking en analyse van gegevens voor bedrijven, waardoor de groei van big data versnelde en transformatieve veranderingen in de industrie teweegbracht.
Aanvankelijk integreerde Hadoop opslag en berekening, maar de opkomst van cloud computing leidde tot een scheiding van deze componenten. Object storage kwam op als een alternatief voor HDFS, maar had beperkingen. Om deze beperkingen aan te vullen, biedt JuiceFS, een open-source, high-performance geclusterde bestandssysteem, kostenefficiënte oplossingen voor gegevensintensieve scenario’s zoals berekening, analyse en training. De beslissing om over te stappen op opslag-berekening scheiding hangt af van factoren zoals schaalbaarheid, prestaties, kosten en compatibiliteit.
In dit artikel bespreken we de Hadoop-architectuur, de belangrijkheid en haalbaarheid van opslag-berekening ontbinding en verkennen de beschikbare marktoplossingen, met aandacht voor hun respectievelijke voordelen en nadelen. Ons doel is om inzichten en inspiratie te bieden aan bedrijven die een opslag-berekening scheiding architectuur transformatie ondergaan.
Hadoop Architectuur Design Kenmerken
Hadoop als Alles-in-Eén Framework
In 2006 werd Hadoop uitgebracht als een alles-in-één framework dat bestond uit drie componenten:
- MapReduce voor berekening
- YARN voor resource planning
- HDFS voor geclusterde bestandsopslag
 Core components of Hadoop
Core components of HadoopDiverse Berekeningscomponenten
Onder deze drie componenten is de berekeningslaag snel ontwikkeld. Aanvankelijk was er alleen MapReduce, maar de industrie zag al snel de opkomst van verschillende frameworks zoals Tez en Spark voor berekeningen, Hive voor datawarehousing en query-engines zoals Presto en Impala. In combinatie met deze componenten zijn er talrijke gegevensoverdrachtstools zoals Sqoop.

HDFS Domineerde het Opslagsysteem
Gedurende ongeveer tien jaar was HDFS, het gedistribueerde bestandssysteem, het dominante opslagsysteem. Het was de standaard keuze voor bijna alle berekeningscomponenten. Alle bovengenoemde componenten binnen het big data-ecosysteem waren ontworpen voor de HDFS API. Sommige componenten maken diepgaand gebruik van de specifieke mogelijkheden van HDFS. Bijvoorbeeld:
- HBase maakt gebruik van de lage latentie-schrijfcapaciteiten van HDFS voor hun write-ahead logs.
- MapReduce en Spark boden gegevenslokaaliteitfuncties aan.
De ontwerpkeuzes van deze big data-componenten, gebaseerd op de HDFS API, brachten mogelijke uitdagingen met zich mee voor het implementeren van dataplatformen naar de cloud.
Opslag-Compute Gekoppelde Architectuur
Het volgende diagram toont een deel van een vereenvoudigd HDFS-architectuur, die berekening met opslag combineert.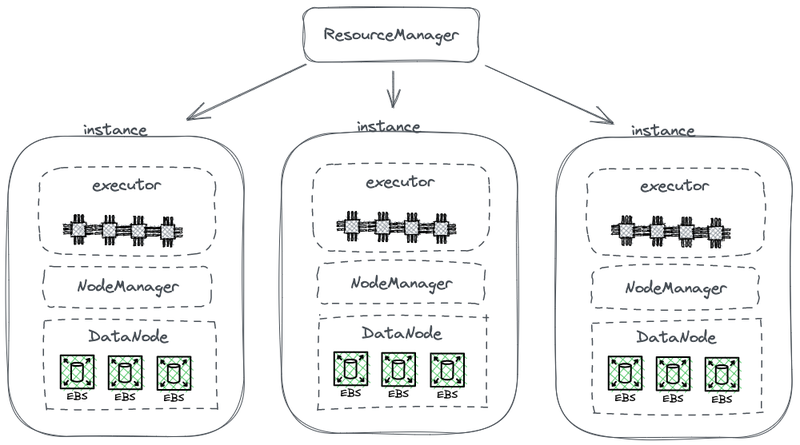
Hadoop opslag-berekening gekoppelde architectuur
In dit diagram fungeert elke knoop als een HDFS DataNode voor het opslaan van gegevens. Bovendien implementeert YARN een Node Manager-proces op elke knoop. Dit stelt YARN in staat de knoop te herkennen als onderdeel van zijn beheerde resources voor berekeningsopdrachten. Deze architectuur maakt het mogelijk dat opslag en berekening op dezelfde machine samen bestaan, en gegevens kunnen tijdens de berekening van de schijf worden gelezen.
Waarom Hadoop Gekoppelde Opslag en Berekening
Hadoop gekoppelde opslag en berekening vanwege de beperkingen van netwerkcommunicatie en hardware tijdens het ontwerpproces.
In 2006 bevond cloud computing zich nog in zijn beginstadium, en Amazon had net zijn eerste service uitgebracht. In datacenters waren de heersende netwerkkaarten voornamelijk aan het werken op 100 Mbps. Datadisks die werden gebruikt voor big data workloads haalden een doorvoer van ongeveer 50 MB/s, gelijk aan 400 Mbps in termen van netwerkbandbreedte.
Overwegend een knooppunt met acht schijven dat op maximale capaciteit draait, werden verschillende gigabits per seconde netwerkbandbreedte vereist voor efficiënte gegevensoverdracht. Helaas was de maximale capaciteit van de netwerkkaarten beperkt tot 1 Gbps. Als gevolg hiervan was de netwerkbandbreedte per knooppunt ontoereikend om de mogelijkheden van alle schijven binnen het knooppunt volledig te benutten. Daarom, als rekenkundige taken aan één kant van het netwerk waren en de gegevens zich op dataknooppunten aan de andere kant bevonden, was de netwerkbandbreedte een belangrijk knelpunt.
Waarom Opslag-Compute Ontbinding Nodig Is
Van 2006 tot ongeveer 2016, stonden bedrijven voor de volgende problemen:
- De vraag naar rekenkracht en opslag in toepassingen was ongelijk, en hun groeisnelheden verschilden. Terwijl het bedrijfsgegevens snel groeiden, groeide de behoefte aan rekenkracht niet zo snel. Deze taken, ontwikkeld door mensen, vermenigvuldigden zich niet exponentieel in een korte periode. De gegevens die van deze taken voortvloeiden, groeiden echter snel, mogelijk exponentieel. Bovendien kan sommige gegevens niet onmiddellijk nuttig zijn voor het bedrijf, maar zal het in de toekomst waardevol zijn. Daarom bewaarden bedrijven de gegevens grondig om het potentieel waarde ervan te verkennen.
- Tijdens het schalen moesten bedrijven zowel rekenkracht als opslag tegelijkertijd uitbreiden, wat vaak leidde tot ongebruikte computerenergie. De hardwaretopologie van de opslag-rekenaar gekoppelde architectuur beïnvloedde de capaciteitsuitbreiding. Wanneer de opslagcapaciteit tekort schoot, moesten we niet alleen machines toevoegen, maar ook CPU’s en geheugen upgraden aangezien de data-knooppunten in de gekoppelde architectuur verantwoordelijk waren voor berekeningen. Daarom waren machines meestal uitgerust met een goed uitgebalanceerde rekenkracht en opslagconfiguratie, waardoor voldoende opslagcapaciteit werd geboden samen met vergelijkbare rekenkracht. Echter, de werkelijke vraag naar rekenkracht nam niet zo sterk toe als verwacht. Als gevolg hiervan veroorzaakte de uitgebreide rekenkracht een grote verspilling voor bedrijven.
- Het in evenwicht brengen van berekeningen en opslag en het kiezen van geschikte machines werd een uitdaging. De hele cluster-resourcebenutting qua opslag en I/O kon sterk ongelijk zijn, en deze onbalans werd erger naarmate het cluster groter werd. Bovendien was het aankopen van geschikte machines moeilijk, aangezien de machines een balans moesten vinden tussen berekenings- en opslagvereisten.
- Omdat gegevens ongelijkmatig konden worden verdeeld, was het moeilijk om berekeningsopdrachten effectief te plannen op de instanties waar de gegevens zich bevonden. Het gegevenslokaliteit scheduleerstrategie kan niet effectief real-world scenario’s aanpakken vanwege de mogelijkheid van ongelijkmatige gegevensverdeling. Bijvoorbeeld, bepaalde knooppunten kunnen lokale hotspots worden, die meer rekenkracht vereisen. Als gevolg hiervan, zelfs als taken op de big data-platform werden geprogrammeerd op deze hotspot-knooppunten, kan I/O-prestaties nog steeds een beperkende factor worden.
Waarom Opslag en Berekening Ontkoppeling Haalbaar Is
De haalbaarheid van het scheiden van opslag en berekening werd mogelijk gemaakt door vooruitgangen in hardware en software tussen 2006 en 2016. Deze vooruitgangen omvatten:
Netwerkkaarten
De overname van 10 Gb netwerkkaarten is breed verspreid geworden, met toenemende beschikbaarheid van hogere capaciteiten zoals 20 Gb, 40 Gb en zelfs 50 Gb in datacenters en cloudomgevingen. In AI-scenario’s worden ook netwerkkaarten met een capaciteit van 100 GB gebruikt. Dit vertegenwoordigt een significante toename van netwerkbandbreedte met meer dan 100 keer.
Schijven
Veel bedrijven vertrouwen nog steeds op schijfoplossingen voor opslag in grote datagebieden. De doorvoer van schijven is verdubbeld, toegenomen van 50 MB/s naar 100 MB/s. Een instantie uitgerust met een 10 GB netwerkkaart kan een piekdoorvoer ondersteunen van ongeveer 12 schijven. Dit is voldoende voor de meeste bedrijven, en dus is de netwerkoverdracht niet langer een knelpunt.
Software
Het gebruik van efficiënte compressiealgoritmen zoals Snappy, LZ4 en Zstandard en kolomopslagformaten zoals Avro, Parquet en Orc heeft de I/O-druk verder verminderd. Het knelpunt in big data-verwerking is verschoven van I/O naar CPU-prestaties.
Hoe Opslag-Berekening Ontkoppeling Uit te Voeren
Eerste Poging: Onafhankelijke Implementatie van HDFS naar de Cloud
Onafhankelijke Implementatie van HDFS
Sinds 2013 zijn er pogingen binnen de industrie geweest om opslag en berekening te scheiden. De eerste aanpak is vrij eenvoudig, met de onafhankelijke implementatie van HDFS zonder integratie met de rekenwerkers. Deze oplossing introduceerde geen nieuwe componenten in het Hadoop-ecosysteem.
Zoals weergegeven in de onderstaande afbeelding, werd de NodeManager niet langer geïmplementeerd op DataNodes. Dit betekende dat berekeningstaken niet langer naar DataNodes werden verzonden. Opslag werd een apart cluster, en de door berekeningen vereiste gegevens werden over het netwerk overgebracht, ondersteund door end-to-end 10 Gb netwerkkaarten. (Merk op dat de netwerkoverdrachtslines niet zijn aangegeven in de afbeelding.)

Hoewel deze oplossing de datalokaliteit, het meest ingewikkelde ontwerp van HDFS, verliet, bevorderde de verhoogde snelheid van netwerkcommunicatie aanzienlijk de configuratie van het cluster. Dit werd aangetoond door experimenten die werden uitgevoerd door Davies, mede-oprichter van Juicedata, en zijn teamgenoten tijdens hun tijd bij Facebook in 2013. De resultaten bevestigden de haalbaarheid van onafhankelijke implementatie en beheer van rekennodes.
Echter, deze poging ontwikkelde zich niet verder. De belangrijkste reden is de uitdagingen bij het implementeren van HDFS naar de cloud.
Uitdagingen bij het Implementeren van HDFS naar de Cloud
Het implementeren van HDFS naar de cloud kent de volgende problemen:
- Het HDFS multi-replica mechanisme kan de kosten van bedrijven in de cloud verhogen: Vroeger bouwden bedrijven een HDFS-systeem in hun datacenters met behulp van bare disks. Om het risico van schijfbeschadiging te beperken, heeft HDFS een multi-replica mechanisme geïmplementeerd om de databezorg en beschikbaarheid te waarborgen. Echter, bij het migreren van gegevens naar de cloud, bieden cloudproviders clouddisks die al zijn beschermd door het multi-replica mechanisme. Hierdoor moeten bedrijven de gegevens binnen de cloud drie keer repliceren, wat resulteert in een aanzienlijke kostenstijging.
- Beperkte mogelijkheden voor implementatie op bare disks: Hoewel cloudproviders enkele machine types met bare disks aanbieden, zijn de beschikbare opties beperkt. Bijvoorbeeld, van de 100 beschikbare virtuele machine types in de cloud, ondersteunen slechts 5-10 machine types bare disks. Deze beperkte selectie kan mogelijk niet voldoen aan de specifieke vereisten van bedrijfskluste.
- Onmogelijkheid om de unieke voordelen van de cloud te benutten: Het implementeren van HDFS in de cloud vereist handmatige machineaanmaak, implementatie, onderhoud, monitoring en bediening zonder de gemakken van elastische schaal en de pay-as-you-go model. Dit zijn de belangrijkste voordelen van cloud computing. Daarom is het niet eenvoudig om HDFS in de cloud te implementeren terwijl tegelijkertijd opslag-compute scheiding wordt bereikt.
Beperkingen van HDFS
HDFS zelf heeft deze beperkingen:
- NameNodes hebben beperkte schaalbaarheid: De NameNodes in HDFS kunnen alleen verticaal schalen en kunnen niet gedistribueerd schalen. Deze beperking legt een beperking op aan het aantal bestanden dat binnen een enkele HDFS-cluster kan worden beheerd.
- Storing meer dan 500 miljoen bestanden brengt hoge operationele kosten met zich mee: Volgens onze ervaring is het over het algemeen gemakkelijk om HDFS te bedienen en te onderhouden met minder dan 300 miljoen bestanden. Wanneer het aantal bestanden de 500 miljoen overschrijdt, moet het HDFS Federation mechanisme worden ingevoerd. Dit leidt echter tot hoge operationele en beheerkosten.
- Hoge resourcegebruik en zware belasting van de NameNode beïnvloeden de beschikbaarheid van het HDFS-cluster: Wanneer een NameNode te veel resources in beslag neemt met een hoge belasting, kan volledige garbage collection (GC) worden geactiveerd. Dit beïnvloedt de beschikbaarheid van het hele HDFS-cluster. Het systeemopslag kan uitvaltijd ondervinden, waardoor het onmogelijk wordt om gegevens te lezen, en er is geen manier om de GC-procedure te beïnvloeden. De duur van de systeembeperking is niet te bepalen. Dit is een blijvend probleem in HDFS-clusters met een hoge belasting.
Publieke Cloud + Object Storage
Met de vooruitgang van cloud computing hebben bedrijven nu de mogelijkheid om object storage te gebruiken als een alternatief voor HDFS. Object storage is specifiek ontworpen voor het opslaan van grote hoeveelheden ongestructureerde gegevens, en biedt een architectuur voor eenvoudige gegevensupload en -download. Het biedt een zeer schaalbaar opslagvermogen, waardoor het kosteneffectief is.
Voordelen van Object Storage als vervanging van HDFS
Object storage is in opkomst, beginnend bij AWS en vervolgens overgenomen door andere cloudproviders als vervanging voor HDFS. De volgende voordelen springen eruit:
- Dienstgericht en klaar-om-gebruik: Object storage vereist geen implementatie, bewaking of onderhoudstaken, en biedt een handig en gebruiksvriendelijk ervaring.
- Elastic scaleren en betalen naar gebruik: Ondernemingen betalen voor objectopslag op basis van hun werkelijke gebruik, waardoor capaciteitsplanning overbodig wordt. Ze kunnen een objectopslagbucket maken en zoveel gegevens opslaan als nodig is zonder zorgen over beperkingen van opslagcapaciteit.
Nadelen van Object Storage
Echter, bij het gebruik van objectopslag om complexe gegevenssystemen zoals Hadoop te ondersteunen, ontstaan de volgende uitdagingen:
Nadeel #1: Slechte Prestaties van Bestandslijst
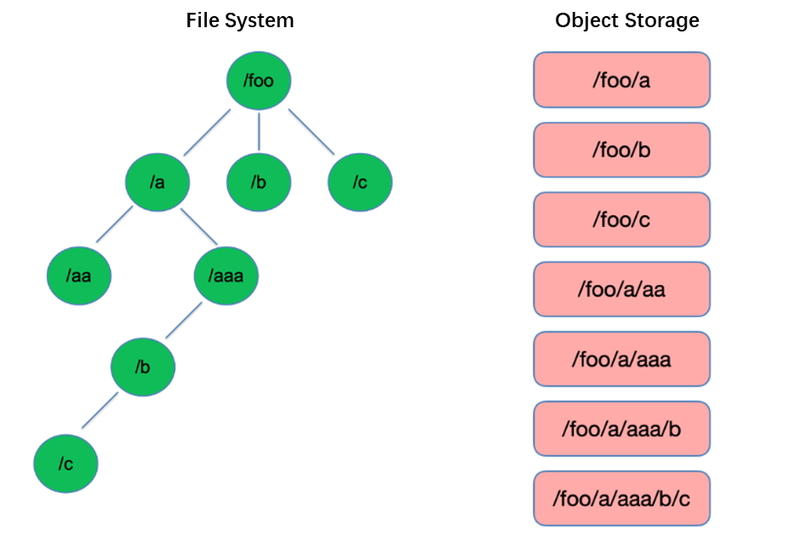
Lijsten zijn een van de meest basale operaties in het besturingssysteem. Ze zijn lichtgewicht en snel in boomachtige structuren zoals HDFS.
In tegenstelling daarop heeft objectopslag een platte structuur en vereist indexering met sleutels (unieke identificatoren) voor het opslaan en opvragen van duizenden of zelfs miljarden objecten. Hierdoor kan objectopslag bij een List-operatie alleen zoeken binnen deze index, wat resulteert in aanzienlijk mindere prestaties vergeleken met boomachtige structuren.
Nadeel #2: Ontbreken van Atomic Rename-mogelijkheid, die de taakprestaties en stabiliteit beïnvloedt
In extract, transform, load (ETL) rekenmodellen schrijft elke subtaak zijn resultaten naar een tijdelijke map. Wanneer de hele taak is voltooid, kan de tijdelijke map worden hernoemd naar de uiteindelijke mapnaam.
Deze Rename-operaties zijn atoomachtig en snel in bestandssystemen zoals HDFS en garanderen transacties. Echter, omdat objectopslag geen native directorystructuur heeft, is het uitvoeren van een Rename-operatie een gesimuleerd proces dat een aanzienlijke hoeveelheid intern gegevenskopiëren inhoudt. Dit proces kan tijdrovend zijn en geen transactiegaranties bieden.
Wanneer gebruikers objectopslag gebruiken, gebruiken ze vaak het padformaat van traditionele bestandssystemen als sleutel voor objecten, zoals “/order/2-22/8/10/detail.” Tijdens een Rename-operatie wordt het nodig om alle objecten te zoeken waarvan de sleutels de directorynaam bevatten en alle objecten te kopiëren met de nieuwe directorynaam als sleutel. Dit proces betreft gegevenskopiëren, wat resulteert in aanzienlijk lagere prestaties in vergelijking met bestandssystemen, mogelijk traag met een of twee ordes van grootte.
Daarnaast, door het ontbreken van transactiegaranties, is er een risico op falen tijdens het proces, wat resulteert in incorrecte gegevens. Deze kleine verschillen hebben gevolgen voor de prestaties en stabiliteit van de hele taakpijplijn.
Nadeel #3: De Eventual Consistency Mechanism Beïnvloedt GegevensCorrectheid en TaakStabiliteit
Bijvoorbeeld, wanneer meerdere clients gelijktijdig bestanden onder een pad aanmaken, kan de door de List API verkregen bestandslijst niet onmiddellijk alle aangemaakte bestanden bevatten. Het kost tijd voordat de interne systemen van de objectopslag gegevensconsistentie bereiken. Deze toegangspatroon wordt vaak gebruikt in ETL-gegevensverwerking, en eventual consistency kan gegevenscorrectheid en taakstabiliteit beïnvloeden.
Om het probleem van de onvermogen van objectopslag om sterk gegevensconsistentie te handhaven aan te pakken, heeft AWS een product uitgebracht genaamd EMRFS. De aanpak is om een extra DynamoDB-database in te zetten. Bijvoorbeeld, wanneer Spark een bestand schrijft, schrijft het ook tegelijkertijd een kopie van de bestandslijst naar DynamoDB. Er wordt vervolgens een mechanisme ingesteld om de List API van de objectopslag continu aan te roepen en de verkregen resultaten te vergelijken met de opgeslagen resultaten in de database totdat ze hetzelfde zijn, waarna de resultaten worden geretourneerd. Echter, de stabiliteit van dit mechanisme is niet goed genoeg omdat het kan worden beïnvloed door de belasting in de regio waar de objectopslag zich bevindt, wat resulteert in wisselende prestaties. Daarom is het geen ideale oplossing.
Nadeel #4: Beperkte Compatibiliteit Met Hadoop-componenten
HDFS was de primaire opslagkeuze in de vroege stadia van de Hadoop-ecosysteem, en diverse componenten werden ontwikkeld op basis van de HDFS API. De introductie van objectopslag heeft geleid tot veranderingen in de gegevensopslagstructuur en API’s.
Cloudproviders moeten connectors tussen componenten en cloudobjectopslag aanpassen, evenals patches aanbrengen in bovenliggende componenten om compatibiliteit te garanderen. Deze taak legt een aanzienlijke werkdruk op de openbare cloudproviders.
Als gevolg hiervan is het aantal ondersteunde rekencomponenten in big data-platformen die worden aangeboden door openbare cloudproviders beperkt, meestal bestaande uit slechts enkele versies van Spark, Hive en Presto. Deze beperking stelt uitdagingen voor het migreren van big data-platformen naar de cloud of voor gebruikers met specifieke eisen voor hun eigen distributie en componenten.
Om te profiteren van de krachtige prestaties van objectopslag terwijl de betrouwbaarheid van bestandssystemen behouden blijft, kunnen bedrijven objectopslag gebruiken in combinatie met JuiceFS.
Object Storage + JuiceFS
Wanneer gebruikers complexe gegevensberekening, analyse en training willen uitvoeren op objectopslag, kan objectopslag op zichzelf mogelijk niet voldoende aan de eisen van bedrijven voldoen. Dit is een belangrijke drijfveer achter de ontwikkeling van JuiceFS door Juicedata, met als doel de beperkingen van objectopslag aan te vullen.
JuiceFS is een open source, high-performance gedistribueerd bestandssysteem ontworpen voor de cloud. Samen met objectopslag biedt JuiceFS kosteneffectieve oplossingen voor gegevensintensieve scenario’s zoals berekening, analyse en training.
Hoe JuiceFS + Object Storage Werkt
Het onderstaande diagram toont de implementatie van JuiceFS binnen een Hadoop-cluster.
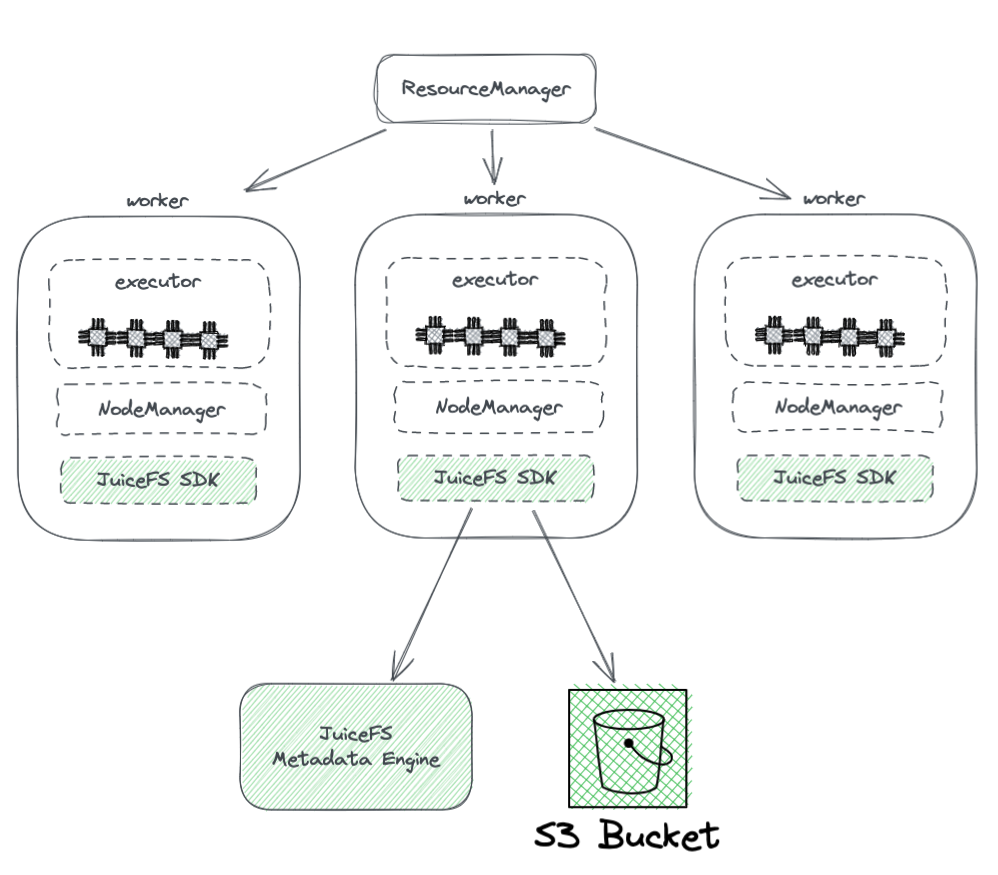
Uit het diagram kunnen we het volgende afleiden:
- Alle werknoden die worden beheerd door YARN dragen een JuiceFS Hadoop SDK, wat de volledige compatibiliteit met HDFS garandeert.
- De SDK heeft toegang tot twee componenten:
-
JuiceFS Metadata Engine: Het metadata-engine fungeert als tegenhanger van HDFS’ NameNode. Het slaat de metadata-informatie van het hele bestandssysteem op, inclusief directoryaantallen, bestandsnamen, machtigingen en tijdstempels, en lost de schaalbaarheids- en GC-uitdagingen op die HDFS’ NameNode ondervindt.
-
S3 Bucket: De gegevens worden opgeslagen in de S3 bucket, die als analoog kan worden gezien aan HDFS’ DataNode. Het kan worden gebruikt als een groot aantal schijven, die de taak van gegevensopslag en replicatie beheren.
-
-
JuiceFS bestaat uit drie componenten:
- JuiceFS Hadoop SDK
- Metadata Engine
- S3 Bucket
Voordelen van JuiceFS ten opzichte van directe gebruik van object storage
JuiceFS biedt verschillende voordelen in vergelijking met het directe gebruik van object storage:
- Volledige compatibiliteit met HDFS: Dit wordt bereikt door de oorspronkelijke ontwerpen van JuiceFS om volledig POSIX te ondersteunen. De POSIX API heeft een grotere dekking en complexiteit dan HDFS.
- Gebruik met bestaande HDFS en object storage mogelijk: Dankzij het ontwerp van het Hadoop-systeem kan JuiceFS naast bestaande HDFS- en object storage-systemen worden gebruikt zonder de noodzaak tot volledige vervanging. In een Hadoop-cluster kunnen meerdere bestandssystemen worden geconfigureerd, waardoor JuiceFS en HDFS naast elkaar kunnen bestaan en samenwerken. Deze architectuur maakt een volledige vervanging van bestaande HDFS-clusters overbodig, wat veel moeite en risico’s zou betekenen. Gebruikers kunnen JuiceFS geleidelijk integreren op basis van hun applicatievereisten en clusteromstandigheden.
- Krachtige metadata-prestaties: JuiceFS scheidt de metadata engine van S3 en is niet langer afhankelijk van de metadata-prestaties van S3. Dit zorgt voor optimale metadata-prestaties. Bij het gebruik van JuiceFS worden interacties met de onderliggende object storage vereenvoudigd tot basisoperaties zoals Get, Put en Delete. Deze architectuur overwint de prestatiebeperkingen van object storage metadata en elimineert problemen met betrekking tot eventuele consistentie.
- Ondersteuning voor atoom Rename: JuiceFS ondersteunt atoom Rename-bewerkingen vanwege zijn onafhankelijke metadata-engine. Cache verbetert de toegangsprestaties van heet data en biedt de gegevenslokaliteitfunctie: Met cache hoeft heet data niet elke keer opnieuw via het netwerk uit objectopslag opgehaald te worden. Bovendien implementeert JuiceFS de HDFS-specifieke gegevenslokaliteit API, zodat alle bovenliggende componenten die gegevenslokaliteit ondersteunen, weer op de hoogte zijn van gegevensaffiniteit. Dit stelt YARN in staat om taken voorrang te geven op knooppunten waar caching is ingesteld, waardoor de algehele prestaties vergelijkbaar zijn met de op opslag-reken gekoppelde HDFS.
- JuiceFS is compatibel met POSIX, waardoor het gemakkelijk te integreren is met machine learning- en AI-gerelateerde toepassingen.
Conclusie
Met de ontwikkeling van de bedrijfsvereisten en de vooruitgang in technologieën is de architectuur van opslag en rekenkracht veranderd, van koppelen naar scheiden.
Er zijn diverse benaderingen om opslag en rekenkracht te scheiden, elk met zijn eigen voordelen en nadelen. Dit varieert van het implementeren van HDFS naar de cloud tot het gebruik van publieke cloudoplossingen die compatibel zijn met Hadoop en zelfs het aannemen van oplossingen zoals objectopslag + JuiceFS, die geschikt zijn voor complexe big data-berekeningen en opslag in de cloud.
Voor bedrijven is er geen wondermiddel en het belangrijkste is om de architectuur te selecteren op basis van hun specifieke behoeften. Echter, ongeacht de keuze, is eenvoud altijd een veilige gok.
Over de auteur
Rui Su, een partner bij Juicedata, is sinds 2017 betrokken geweest bij het complete ontwikkelingsproces van het JuiceFS-product, de markt en de open source gemeenschap. Met 16 jaar ervaring in de branche heeft hij functies bekleed zoals R&D, productmanager en oprichter in software, internet en niet-gouvernementele organisaties.
Source:
https://dzone.com/articles/from-hadoop-to-cloud-why-and-how-to-decouple-stora