













Wat is Elasticsearch?
Elasticsearch is een gedistribueerde, open-source zoek- en analysemotor gebouwd bovenop de Apache Lucene bibliotheek. Elasticsearch biedt ook vectorzoekopdrachten en retrieval augmented generation (RAG), waardoor moderne AI-toepassingen naadloos worden ondersteund. Toepassingen kunnen gestructureerde en ongestructureerde gegevens opslaan in Elasticsearch, met of zonder een gedefinieerd schema, door JSON-payloads naar een Elasticsearch-cluster te sturen.
Elasticsearch-architectuur
Vanaf de basis bestaan de belangrijkste componenten van een Elasticsearch-cluster uit:
Document
Een document is het kleinste informatierecord dat door Elasticsearch wordt opgeslagen en wordt weergegeven als JSON. Een document bestaat uit meerdere velden (sleutel-waardeparen) van verschillende typen en kan een vooraf gedefinieerd schema hebben of schema-loos zijn, waarbij de gegevenstypen van eventuele nieuwe geïndexeerde velden worden afgeleid.
Index
Een index is een logische verzameling documenten met hetzelfde schema, geïdentificeerd door een indexnaam.
Shard
Elasticsearch-indexen zijn opgedeeld in beheersbare eenheden die shards worden genoemd, wat een verzameling documenten is. Shards zijn de basiszoekeenheid en worden gerepliceerd over meerdere knooppunten voor redundantie en fouttolerantie.
Knooppunt
Een node is een onafhankelijke instantie van Elasticsearch en beheert een verzameling shards die behoren tot een of meer indices. Nodes kunnen verschillende rollen hebben, zoals datanode, masternode en invoegnode.
Cluster
Een Elasticsearch-cluster is een verzameling onderling verbonden nodes. Alle nodes in een cluster kunnen verzoeken van clients afhandelen en met elkaar communiceren. Elke node in een cluster bezit een subset van de shards die behoren tot een index.
Query-architectuur
De volgende architectuurdiagram schetst de doorstroming van een zoekverzoek:

- De gebruiker of toepassing maakt een zoekopdracht. De query kan worden afgehandeld door een willekeurige node in het cluster. De node die het verzoek afhandelt, is de “coördinerende” node.
- De coördinerende node zendt de query uit naar alle betrokken shards en hun replica’s.
- Elke shard voert de query lokaal uit en retourneert een lichte set resultaten naar de coördinerende node.
- De coördinerende node merge de ontvangen resultaten. Dit is het einde van de “query”-fase. De queryfase identificeert de basisdocumenten die de zoekresultaten vormen, maar het volledige document moet nog worden opgehaald.
- De coördinerende node verzendt ophaalverzoeken naar de eigenaars van de shards, die de documenten in de resultaatset verrijken.
- De verrijkte documenten worden teruggestuurd naar de coördinerende node.
- De volledige set zoekresultaten, gerangschikt en verrijkt, wordt teruggegeven aan de aanvrager.
Indexeringsarchitectuur
Het volgende architectuurschema schetst de flow van een indexeerverzoek:
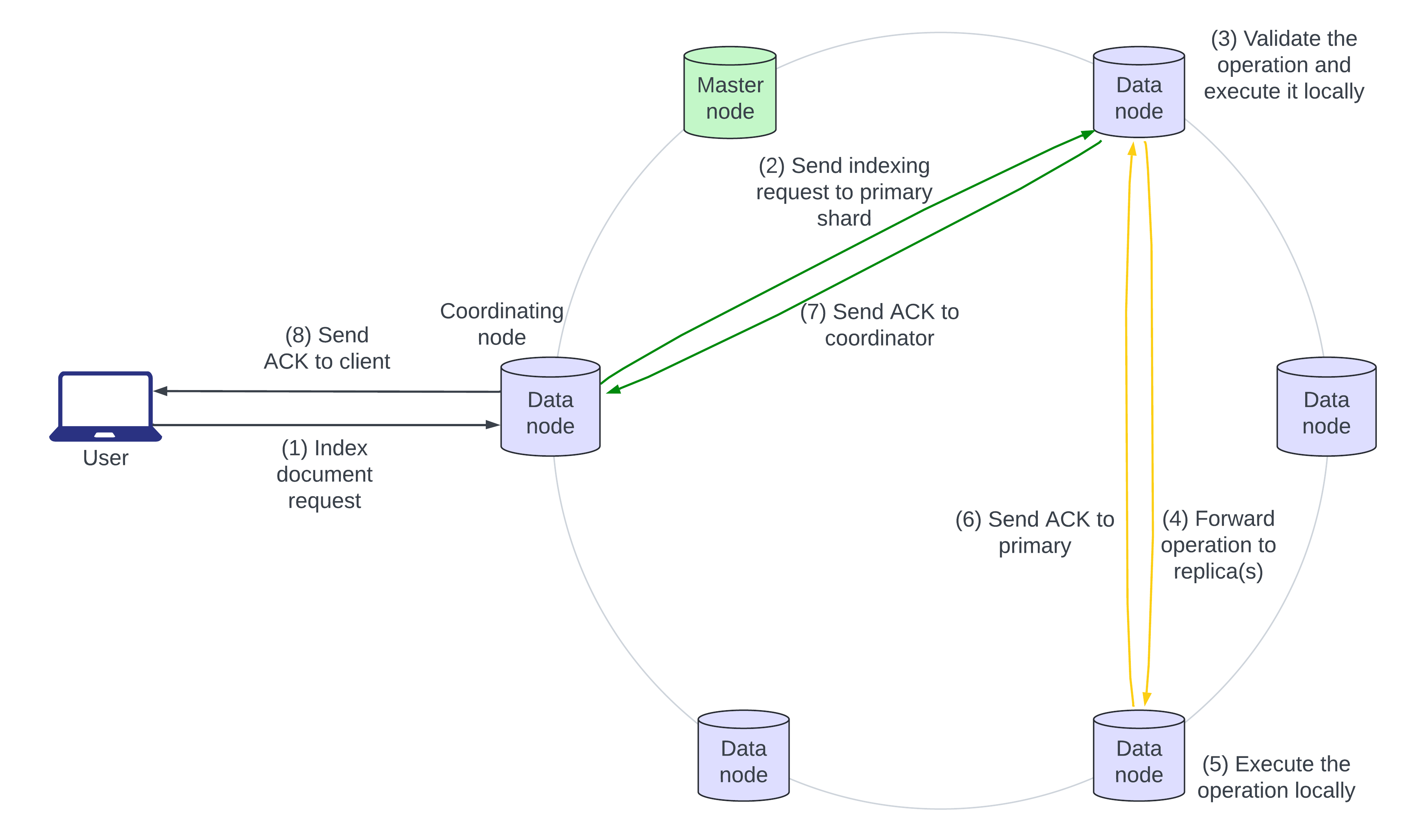
- De gebruiker stuurt een JSON-document voor Elasticsearch om te indexeren. Als het document al bestaat, worden er nieuwe velden toegevoegd en worden bestaande velden overschreven. De node die het verzoek als eerste ontvangt, is de “coördinerende” node.
- De coördinerende node identificeert de primaire shard van het inkomende document, meestal op basis van de document-ID, en stuurt het verzoek door naar de datanode die de primaire shard bezit.
- De primaire shard valideert de operatie en voert deze lokaal uit.
- De primaire shard stuurt vervolgens de operatie door naar al zijn replica’s parallel.
- De replicashards passen de operatie lokaal toe op hun nodes.
- Stappen 6, 7 en 8 tonen de bevestiging van de schrijfactie die opborrelt vanuit de replicashard naar de primaire shard, naar de coördinerende node en naar de aanvrager.
Conclusie
Dit artikel beschrijft de verschillende componenten van een Elasticsearch-cluster: documenten, indexen, shards en nodes. Het schetst ook de levensduur van een zoekverzoek en een indexeerverzoek. Dankzij de flexibele architectuur is het eenvoudig om nodes toe te voegen en te verwijderen naarmate het cluster groeit. In combinatie met functies zoals schema-loze indexering en ondersteuning voor AI-zoekfuncties maakt dit Elasticsearch tot de facto standaard voor organisaties die efficiënt grote hoeveelheden data in realtime willen opslaan, doorzoeken en analyseren.
Source:
https://dzone.com/articles/elasticsearch-query-and-indexing-architecture