













Database sharding is het proces van het opdelen van gegevens in kleinere stukken, die “shards” worden genoemd. Sharding wordt meestal ingevoerd wanneer er behoefte is aan schalen van schrijfbewerkingen. Tijdens de levensduur van een succesvol toepassing zal de database server het maximum aantal schrijfbewerkingen bereiken dat het kan uitvoeren, zowel op het proces- als capaciteitsniveau. Het opdelen van de gegevens in meerdere shards – elk op zijn eigen database server – vermindert de druk op elke afzonderlijke node, waardoor de schrijfcapaciteit van de totale database effectief wordt verhoogd. Dit is wat database sharding inhoudt.
Distributed SQL is de nieuwe manier om relationele databases te schalen met een sharding-achtige strategie die volledig geautomatiseerd en transparant is voor toepassingen. Distributed SQL-databases zijn vanaf de grond af aan ontworpen om bijna lineair te schalen. In dit artikel leer je de basis van distributed SQL en hoe je ermee aan de slag kunt gaan.
Nadelen van Database Sharding
Sharding introduceert een aantal uitdagingen:
- Gegevenspartitie: Het bepalen hoe gegevens over meerdere shards te verdelen kan een uitdaging zijn, aangezien het een evenwicht vinden vereist tussen gegevensnabijheid en gelijke verdeling van gegevens om hotspots te voorkomen.
- Foutafhandeling: Als een belangrijke node uitvalt en er niet genoeg shards zijn om de belasting te dragen, hoe krijg je de gegevens dan op een nieuwe node zonder downtime?
- Query complexiteit: Toepassingscode is gekoppeld aan de data-sharding logica en query’s die gegevens van meerdere knooppunten vereisen, moeten opnieuw worden samengevoegd.
- Gegevensconsistentie: Het garanderen van gegevensconsistentie over meerdere shards kan een uitdaging zijn, aangezien het coördineren van updates over shards vereist. Dit kan vooral moeilijk zijn bij gelijktijdige updates, waarbij het mogelijk nodig is om conflicten tussen verschillende schrijfbewerkingen op te lossen.
- Elastische schaalbaarheid: Als het gegevensvolume of het aantal query’s toeneemt, kan het nodig zijn om extra shards toe te voegen aan de database. Dit kan een complex proces zijn met onvermijdelijke downtime, waarbij handmatige processen vereist zijn om gegevens gelijkmatig over alle shards te verplaatsen.
Enkele van deze nadelen kunnen worden verlicht door polyglot persistence te adopteren (het gebruik van verschillende databases voor verschillende workloads), databases met ingebouwde shardingmogelijkheden, of database proxies. Echter, terwijl ze helpen bij enkele uitdagingen in database sharding, brengen deze tools beperkingen en complexiteit met zich mee die voortdurend beheer vereisen.
Wat Is Distributeerde SQL?
Distributed SQL verwijst naar een nieuwe generatie relationele databases. In eenvoudige termen is een distributed SQL-database een relationele database met transparante sharding die voor toepassingen als een enkele logische database lijkt. Distributed SQL-databases zijn geïmplementeerd als een shared-nothing architectuur en een opslagengine die zowel lees- als schrijfbewerkingen kan laten groeien terwijl ze echte ACID compliantie en hoge beschikbaarheid behouden. Distributed SQL-databases hebben de schaalbaarheidsfuncties van NoSQL-databases—die populair werden in de jaren 2000—maar offeren geen consistentie op. Ze behouden de voordelen van relationele databases en voegen cloudcompatibiliteit toe met veerkracht in meerdere regio’s.
A different but related term is NewSQL (coined by Matthew Aslett in 2011). This term also describes scalable and performant relational databases. However, NewSQL databases don’t necessarily include horizontal scalability.
Hoe werkt Distributed SQL?
Om te begrijpen hoe Distributed SQL werkt, laten we het geval van MariaDB Xpand bekijken—een gegevensbestand voor gedistribueerde SQL dat compatibel is met de open-source MariaDB database. Xpand werkt door de gegevens en indices over knooppunten te verdelen en taken automatisch uit te voeren zoals gegevensrebalanceren en gedistribueerde queryuitvoering. Queries worden parallel uitgevoerd om vertraging te minimaliseren. Gegevens worden automatisch gerepliceerd om ervoor te zorgen dat er geen enkele punt van falen is. Wanneer een knooppunt uitvalt, rebalanceert Xpand de gegevens onder de overlevende knooppunten. Hetzelfde gebeurt wanneer een nieuw knooppunt wordt toegevoegd. Een component genaamd rebalancer zorgt ervoor dat er geen hotspots zijn—een uitdaging bij handmatige database sharding—wat optreedt wanneer één knooppunt ongelijkmatig te veel transacties moet afhandelen in vergelijking met andere knooppunten die soms onbenut blijven.
Laten we een voorbeeld bestuderen. Stel dat we een database-exemplaar hebben met some_table en een aantal rijen:
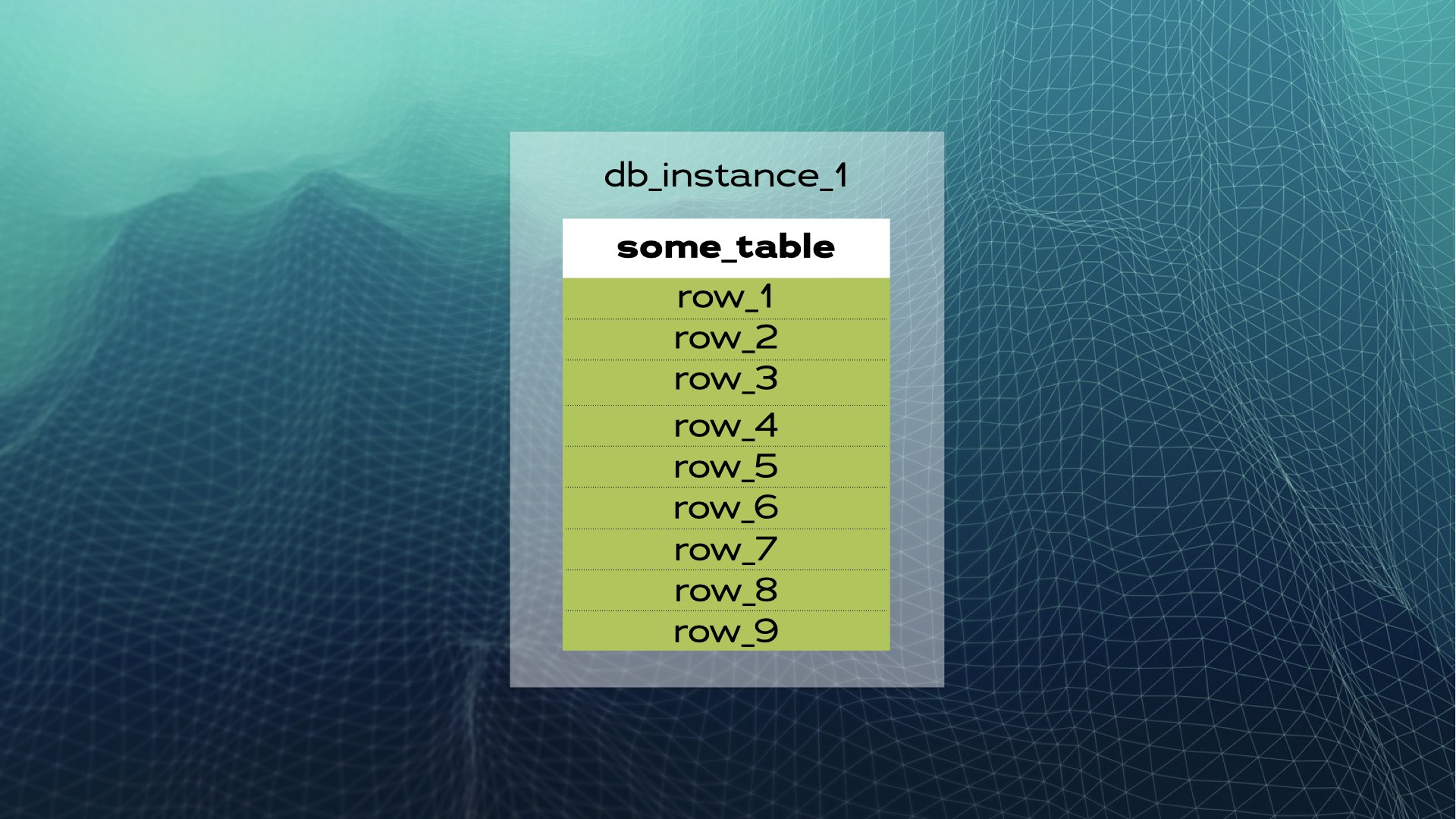
We kunnen de gegevens in drie stukken (shards) verdelen:

En vervolgens elk gegevensstuk naar een afzonderlijk database-exemplaar verplaatsen:
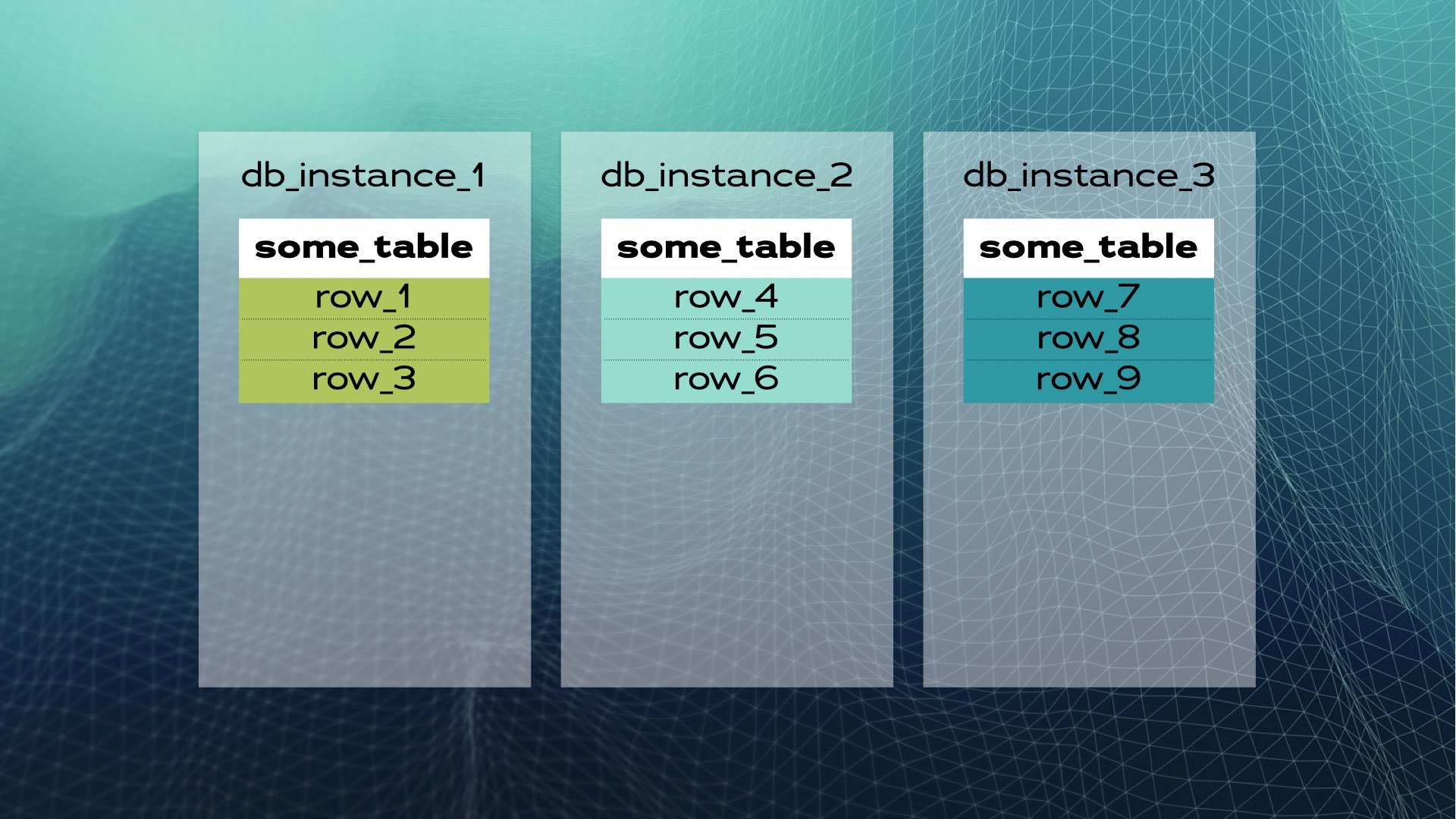
Dit is hoe handmatig gegevensbestand delen eruit ziet. Gedistribueerde SQL doet dit automatisch voor u. In het geval van Xpand wordt elke shard een slice genoemd. Rijen worden gesliced met behulp van een hash van een subset van de kolommen van de tabel. Niet alleen wordt gegevens gesliced, maar ook indexen worden gesliced en verdeeld over de knooppunten (database-exemplaren). Bovendien, om hoge beschikbaarheid te garanderen, worden slices gerepliceerd op andere knooppunten (het aantal replicas per knooppunt is configureerbaar). Dit gebeurt ook automatisch:
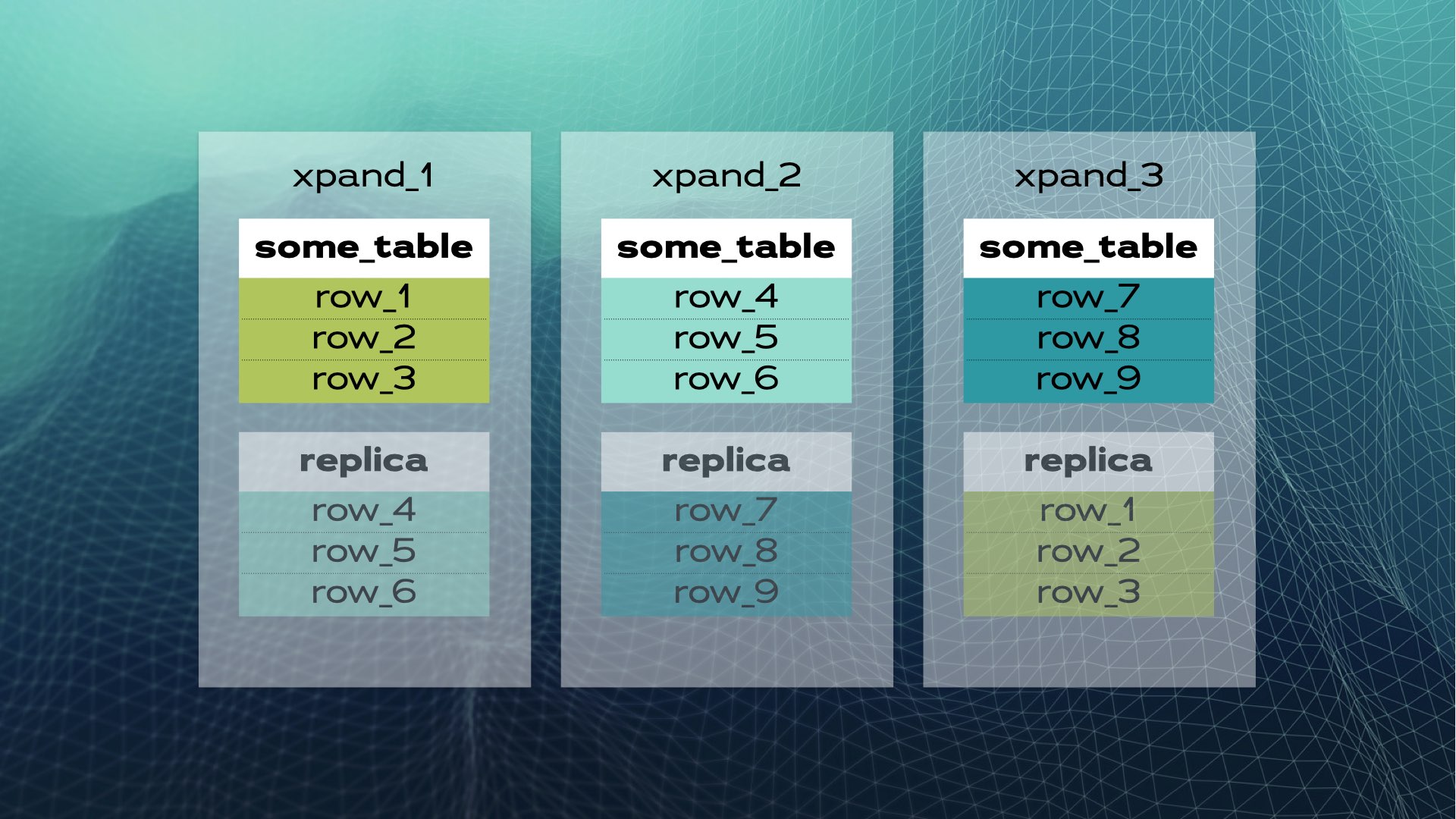
Wanneer een nieuw knooppunt wordt toegevoegd aan de cluster of wanneer een knooppunt faalt, rebalanceert Xpand de gegevens automatisch zonder dat er handmatige interventie nodig is. Hier is wat er gebeurt wanneer een knooppunt wordt toegevoegd aan de vorige cluster:

Sommige rijen worden verplaatst naar het nieuwe knooppunt om de totale systeemcapaciteit te vergroten. Houd er rekening mee dat, hoewel dit niet in het diagram wordt weergegeven, indexen en ook replicas ook worden verplaatst en dienovereenkomstig worden bijgewerkt. Een iets vollediger beeld (met een iets andere verplaatsing van gegevens) van de vorige cluster wordt in dit diagram weergegeven:
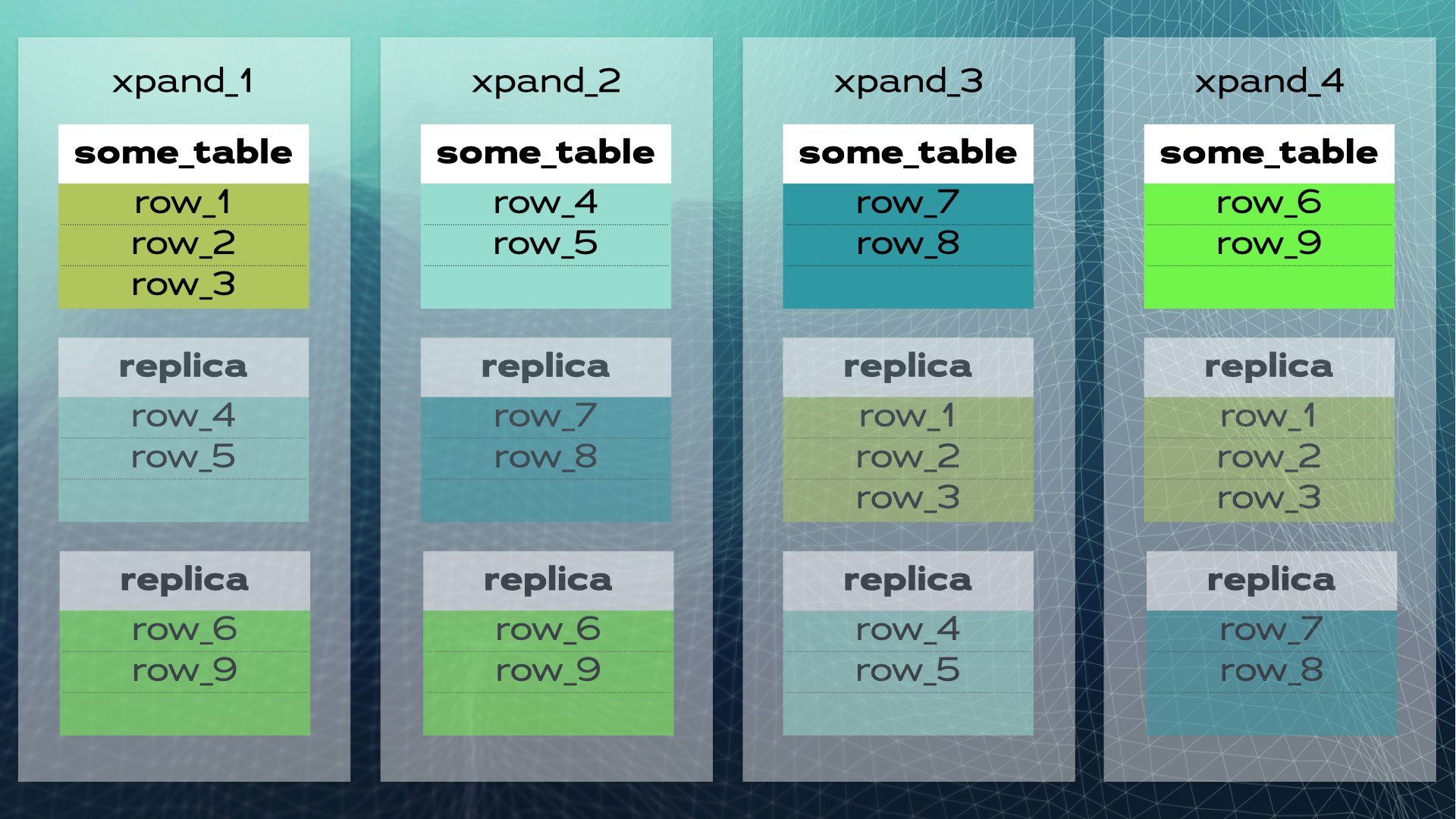
Deze architectuur staat bijna lineaire schaalbaarheid toe. Er is geen behoefte aan handmatige interventie op toepassingsniveau. Voor de toepassing ziet de cluster eruit als een enkele logische database. De toepassing verbindt zich gewoon met de database via een load balancer (MariaDB MaxScale):
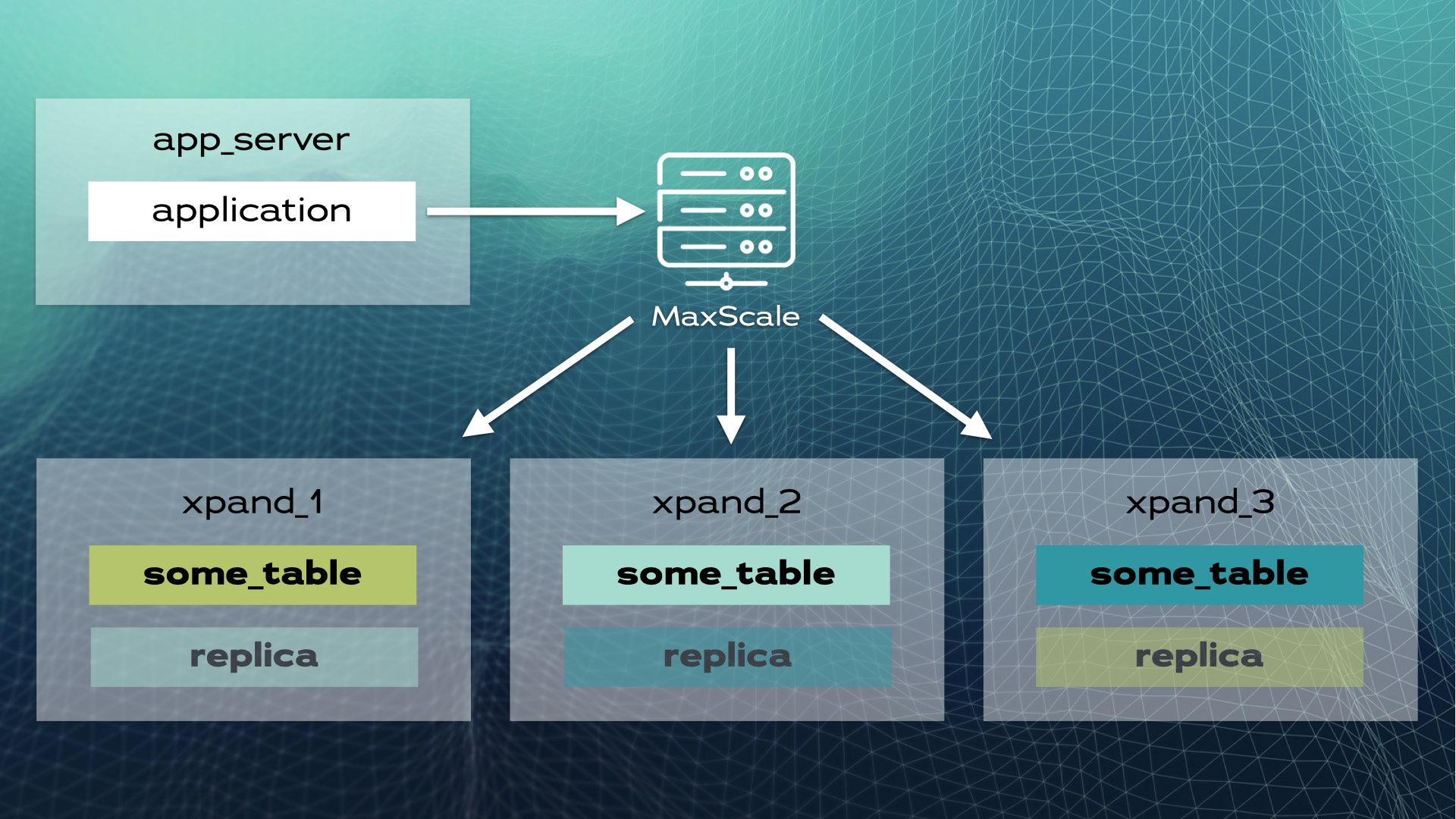
Wanneer de toepassing een schrijfoperatie stuurt (bijvoorbeeld INSERT of UPDATE), wordt de hash berekend en naar de juiste slice gestuurd. Meerdere schrijfsels worden parallel naar meerdere knooppunten gestuurd.
Wanneer niet te gebruiken Distributed SQL
Het schards van een database verbetert de prestaties, maar introduceert ook extra overhead op communicatieniveau tussen knooppunten. Dit kan leiden tot tragere prestaties als de database niet correct is geconfigureerd of als de query router niet is geoptimaliseerd. Distributed SQL is mogelijk niet de beste optie in toepassingen met minder dan 10.000 queries per seconde of 5.000 transacties per seconde. Ook als uw database voornamelijk bestaat uit veel kleine tabellen, kan een monolithische database betere prestaties leveren.
Aan de slag met Distributed SQL
Aangezien een gedistribueerde SQL-database zich voor een toepassing gedraagt alsof het één logische database is, is het beginnen eenvoudig. Het enige wat u nodig heeft, is het volgende:
- Een SQL-client zoals DBeaver, DbGate, DataGrip of elke SQL-client-extensie voor uw IDE
- A distributed SQL database
Docker maakt het tweede deel gemakkelijk. Bijvoorbeeld, MariaDB publiceert de mariadb/xpand-single Docker-afbeelding die u in staat stelt om een enkelnodige Xpand-database voor evaluatie, testen en ontwikkeling op te zetten.
Om een Xpand-container te starten, voer de volgende opdracht uit:
docker run --name xpand \
-d \
-p 3306:3306 \
--ulimit memlock=-1 \
mariadb/xpand-single \
--user "user" \
--passwd "password"Bekijk de Docker-afbeelding documentatie voor meer informatie.
Opmerking: Op het moment van het schrijven van dit artikel is de mariadb/xpand-single Docker-afbeelding niet beschikbaar op ARM-architectuur. Op deze architectuur (bijvoorbeeld Apple-machines met M1-processors), gebruik UTM om een virtuele machine (VM) te maken en installeer bijvoorbeeld Debian. Wijs een hostnaam toe en gebruik SSH om verbinding te maken met de VM om Docker te installeren en de MariaDB Xpand-container te maken.
Verbinding maken met de Database
Het verbinden met een Xpand-database is hetzelfde als verbinding maken met een MariaDB Community of Enterprise server. Als u het mariadb CLI-hulpmiddel geïnstalleerd heeft, voert u simpelweg het volgende uit:
mariadb -h 127.0.0.1 -u user -pJe kunt verbinding maken met de database met behulp van een GUI voor SQL-databases zoals DBeaver, DataGrip, of een SQL-extensie voor je IDE (zoals deze voor VS Code). We gaan een gratis en open source SQL-client gebruiken genaamd DbGate. Je kunt DbGate downloaden en uitvoeren als een desktoptoepassing of aangezien je Docker gebruikt, kun je het implementeren als een webtoepassing die je vanaf elke locatie kunt openen via een webbrowser (vergelijkbaar met de populaire phpMyAdmin). Voer gewoon de volgende opdracht uit:
docker run -d --name dbgate -p 3000:3000 dbgate/dbgateZodra de container start, verwijs je browser naar http://localhost:3000/. Vul de verbindingsgegevens in:
Klik op Test en bevestig dat de verbinding succesvol is:

Klik op Opslaan en maak een nieuwe database aan door met de rechtermuisknop op de verbinding in het linkerpaneel te klikken en Database aanmaken te selecteren. Probeer tabellen aan te maken of een SQL-script te importeren. Als je gewoon iets wilt uitproberen, zijn de Nation of Sakila goede voorbeelddatabases.
Verbinding maken vanuit Java, JavaScript, Python en C++
Om verbinding te maken met Xpand vanuit applicaties kunt u de MariaDB Connectors gebruiken. Er zijn veel mogelijke combinaties van programmeertalen en bewaarframeworkcombinaties. Het behandelen hiervan valt buiten het bereik van dit artikel, maar als u gewoon wilt beginnen en iets in actie wilt zien, bekijk dan deze quick start pagina met codevoorbeelden voor Java, JavaScript, Python en C++.
De ware kracht van Distributed SQL
In dit artikel hebben we geleerd hoe we een enkelnoodige Xpand kunnen opstarten voor ontwikkeling en testdoeleinden, in tegenstelling tot productiewerklasten. De ware kracht van een gedistribueerde SQL-database ligt echter in de mogelijkheid om niet alleen leesbewerkingen (zoals in klassieke database-sharding) te schalen, maar ook schrijfbewerkingen door gewoon meer knooppunten toe te voegen en de rebalancer de gegevens optimaal te laten verplaatsen. Hoewel het mogelijk is om Xpand in een multi-node-topologie te implementeren, is de gemakkelijkste manier om het in productie te gebruiken via SkySQL.
Als u meer wilt weten over gedistribueerde SQL en MariaDB Xpand, hier is een lijst met nuttige bronnen:
Source:
https://dzone.com/articles/distributed-sql-an-alternative-to-sharding