













In Deel 1 van deze reeks, keken we naar MongoDB, een van de meest betrouwbare en robuuste documentgerichte NoSQL-databases. Hier in Deel 2, zullen we een andere niet te vermijden NoSQL-database onderzoeken: Elasticsearch.
Meer dan alleen een populaire en krachtige open-source gedistribueerde NoSQL-database, Elasticsearch is in de eerste plaats een zoek- en analysemotor. Het is gebaseerd op Apache Lucene, de meest bekende zoekmachine Java-bibliotheek, en kan real-time zoek- en analysemethoden uitvoeren op gestructureerde en ongestructureerde data. Het is ontworpen om efficiënt grote hoeveelheden data te behandelen.
Nogmaals, we moeten vermelden dat dit korte bericht absoluut geen Elasticsearch-tutorial is. Overeenkomstig wordt de lezer sterk aangeraden om uitgebreid gebruik te maken van de officiële documentatie, evenals het uitstekende boek, “Elasticsearch in Action” van Madhusudhan Konda (Manning, 2023) om meer te leren over de architectuur en operaties van het product. Hier, zijn we gewoon hetzelfde gebruiksscenario opnieuw implementeren zoals eerder, maar deze keer met Elasticsearch in plaats van MongoDB.
dus, hier gaan we!
Het Domeinmodel
De onderstaande afbeelding toont ons *customer-order-product* domeinmodel:
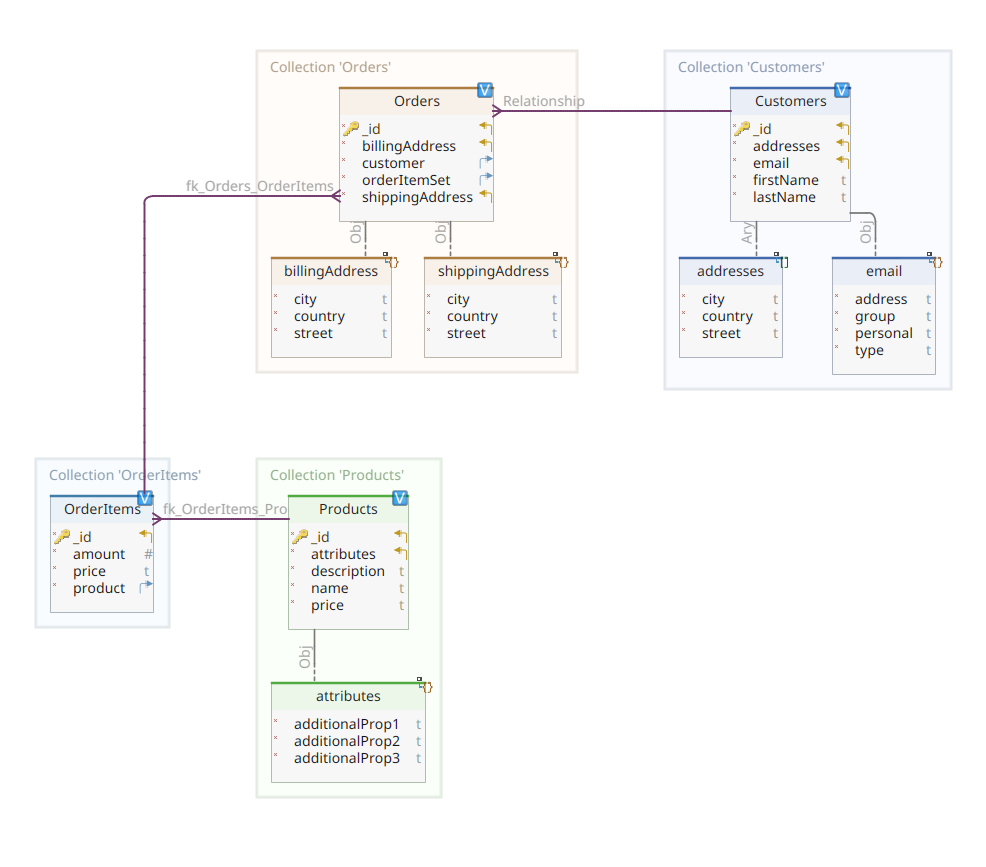
Dit diagram is hetzelfde als datgene dat is gepresenteerd in Deel 1. Net als MongoDB is Elasticsearch ook een documentgegevensopslag en verwacht het dan ook dat documenten worden gepresenteerd in JSON-notatie. Het enige verschil is dat Elasticsearch de gegevens moet indexeren om ze te kunnen beheren.
Er zijn verschillende manieren waarop gegevens in een Elasticsearch-gegevensopslag kunnen worden geïndexeerd; bijvoorbeeld door ze door te voeren vanuit een relationele database, ze uit een bestandssysteem te extraheren, ze van een real-time bron te streamen, enz. Maarichever de methode van ingave ook is, het bestaat uiteindelijk uit het aanroepen van de Elasticsearch RESTful API via een dedicated client. Er zijn twee categorieën van dergelijke dedicated clients:
- REST-gebaseerde clients zoals
curl,Postman, HTTP-modules voor Java, JavaScript, Node.js, enz. - Programmeertaal SDK’s (Software Development Kit): Elasticsearch biedt SDK’s voor alle meest gebruikte programmeertalen, waaronder maar niet beperkt tot Java, Python, enz.
Het indexeren van een nieuw document met Elasticsearch betekent het aanmaken ervan met een POST-verzoek tegen een speciale RESTful API-endpoint genaamd _doc. Bijvoorbeeld, het volgende verzoek zal een nieuwe Elasticsearch-index aanmaken en een nieuwe klantinstantie erin opslaan.
POST customers/_doc/
{
"id": 10,
"firstName": "John",
"lastName": "Doe",
"email": {
"address": "[email protected]",
"personal": "John Doe",
"encodedPersonal": "John Doe",
"type": "personal",
"simple": true,
"group": true
},
"addresses": [
{
"street": "75, rue Véronique Coulon",
"city": "Coste",
"country": "France"
},
{
"street": "Wulfweg 827",
"city": "Bautzen",
"country": "Germany"
}
]
}Het uitvoeren van het bovenstaande verzoek met curl of de Kibana console (zoals we later zullen zien) zal het volgende resultaat produceren:
{
"_index": "customers",
"_id": "ZEQsJI4BbwDzNcFB0ubC",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 1,
"_primary_term": 1
}
Dit is het standaard antwoord van Elasticsearch op een POST aanvraag. Het bevestigt dat de index genaamd customers is gemaakt, en dat er een nieuwe customer document is, geïdentificeerd door een automatisch gegenereerde ID (in dit geval, ZEQsJI4BbwDzNcFB0ubC).
Andere interessante parameters zoals _version en vooral _shards komen hier naar voren. Zonder al te veel detail te gåan, maakt Elasticsearch indexes aan als logische verzamelingen van documenten. Net als het bewaren van papieren documenten in een archiefkist, houdt Elasticsearch documenten in een index. Elke index bestaat uit shards, die fysieke instanties zijn van Apache Lucene, de motor achter de schermen die verantwoordelijk is voor het in of uit de opslag krijgen van gegevens. Ze kunnen zowel primair zijn, en documenten opslaan, of replica’s, en kopieën van de primaire shards opslaan, zoals de naam al suggereert. Meer daarover in de Elasticsearch-documentatie – voor nu moeten we opmerken dat onze index genaamd customers bestaat uit twee shards: waarvan één uiteraard primair is.
A final notice: the POST request above doesn’t mention the ID value as it is automatically generated. While this is probably the most common use case, we could have provided our own ID value. In each case, the HTTP request to be used isn’t POST anymore, but PUT.
Terugkerend naar ons domeinmodel diagram, zoals je kunt zien, is het centrale document Order, opgeslagen in een dedicated collectie genaamd Orders. Een Order is een aggregaat van OrderItem documenten, waarbij elk verwijst naar zijn geassocieerde Product. Een Order document verwijst ook naar de Customer die het heeft geplaatst. In Java wordt dit als volgt geïmplementeerd:
public class Customer
{
private Long id;
private String firstName, lastName;
private InternetAddress email;
private Set<Address> addresses;
...
}
Het bovenstaande codefragment toont een deel van de Customer-klasse. Dit is een eenvoudige POJO (Plain Old Java Object) met eigenschappen zoals klant-ID, voornaam en achternaam, e-mailadres en een verzameling postadressen.
Laten we nu naar het Order-document kijken.
public class Order
{
private Long id;
private String customerId;
private Address shippingAddress;
private Address billingAddress;
private Set<String> orderItemSet = new HashSet<>()
...
}
Hier kun je enkele verschillen opmerken ten opzichte van de MongoDB-versie. In feite, met MongoDB gebruikten we een verwijzing naar de klantinstantie die aan deze bestelling is gekoppeld. Deze notie van verwijzing bestaat niet in Elasticsearch en dus gebruiken we deze document-ID om een associatie te maken tussen de bestelling en de klant die deze heeft geplaatst. Hetzelfde geldt voor de orderItemSet-eigenschap die een associatie creëert tussen de bestelling en haar items.
De rest van ons domeinmodel is vrij vergelijkbaar en gebaseerd op dezelfde normalisatie-ideeën. Bijvoorbeeld, het OrderItem-document:
public class OrderItem
{
private String id;
private String productId;
private BigDecimal price;
private int amount;
...
}
Hier moeten we het product associëren dat het object is van het huidige bestelitem. Tot slot hebben we het Product-document:
public class Product
{
private String id;
private String name, description;
private BigDecimal price;
private Map<String, String> attributes = new HashMap<>();
...
}De Data Repositories
Quarkus Panache极大地简化了数据持久化过程,支持活动记录和仓库设计模式。在第一部分中,我们使用了Quarkus Panache扩展来为MongoDB实现数据仓库,但目前还没有相应的Quarkus Panache扩展用于Elasticsearch。因此,在等待可能的将来Quarkus扩展支持Elasticsearch的同时,我们必须手动使用Elasticsearch专用客户端来实现我们的数据仓库。
Elasticsearch是用Java编写的,因此它提供原生支持,使用Java客户端库调用Elasticsearch API并不奇怪。这个库基于流畅API构建器设计模式,并提供同步和异步处理模型。它至少需要Java 8。
那么,基于流畅API构建器的数据仓库看起来是什么样的呢?下面是CustomerServiceImpl类的摘录,它充当Customer文档的数据仓库。
@ApplicationScoped
public class CustomerServiceImpl implements CustomerService
{
private static final String INDEX = "customers";
@Inject
ElasticsearchClient client;
@Override
public String doIndex(Customer customer) throws IOException
{
return client.index(IndexRequest.of(ir -> ir.index(INDEX).document(customer))).id();
}
...
正如我们所看到的,我们的数据仓库实现必须是一个具有应用程序作用域的CDI豆。Elasticsearch Java客户端只是通过quarkus-elasticsearch-java-client Quarkus扩展注入。这种方式避免了我们否则必须使用的许多花哨的东西。我们需要做的唯一事情是声明以下属性,以便能够注入客户端:
quarkus.elasticsearch.hosts = elasticsearch:9200Hier, elasticsearch is de DNS-naam (Domain Name Server) die we associëren met de Elastic search database server in het docker-compose.yaml bestand. 9200 is het TCP-poortnummer dat de server gebruikt om verbindingen te luisteren.
De methode doIndex() hierboven creëert een nieuwe index genaamd customers als die niet bestaat en indexeert (opslaat) daarin een nieuw document dat een instantie van de klasse Customer vertegenwoordigt. Het indexeren wordt uitgevoerd op basis van een IndexRequest die de indexnaam en het documentbody als invoerargumenten accepteert. Wat betreft de document-ID, deze wordt automatisch gegenereerd en teruggestuurd naar de aanroeper voor verdere referentie.
De volgende methode maakt het mogelijk om de klant te verkrijgen die wordt geïdentificeerd door de opgegeven ID als invoerargument:
...
@Override
public Customer getCustomer(String id) throws IOException
{
GetResponse<Customer> getResponse = client.get(GetRequest.of(gr -> gr.index(INDEX).id(id)), Customer.class);
return getResponse.found() ? getResponse.source() : null;
}
...
Het principe is hetzelfde: door gebruik te maken van deze fluent API builder pattern, bouwen we een GetRequest instantie op een vergelijkbare manier zoals we dat deden met de IndexRequest, en we voeren het uit tegen de Elasticsearch Java client. De andere endpoints van onze gegevensopslag, die ons in staat stellen om volledige zoekoperaties uit te voeren of klanten bij te werken en te verwijderen, zijn op dezelfde manier ontworpen.
Neem de tijd om de code te bekijken om te begrijpen hoe dingen werken.
De REST API
Onze MongoDB REST API interface was eenvoudig te implementeren, dankzij de quarkus-mongodb-rest-data-panache uitbreiding, waarin de annotatieprocessor automatisch alle benodigde endpoints gegenereerde. Met Elasticsearch profiteren we nog niet van hetzelfde comfort en daarom moeten we het handmatig implementeren. Dat is geen groot probleem, omdat we de eerdere dataverpositories kunnen injecteren, zoals hieronder wordt getoond:
@Path("customers")
@Produces(APPLICATION_JSON)
@Consumes(APPLICATION_JSON)
public class CustomerResourceImpl implements CustomerResource
{
@Inject
CustomerService customerService;
@Override
public Response createCustomer(Customer customer, @Context UriInfo uriInfo) throws IOException
{
return Response.accepted(customerService.doIndex(customer)).build();
}
@Override
public Response findCustomerById(String id) throws IOException
{
return Response.ok().entity(customerService.getCustomer(id)).build();
}
@Override
public Response updateCustomer(Customer customer) throws IOException
{
customerService.modifyCustomer(customer);
return Response.noContent().build();
}
@Override
public Response deleteCustomerById(String id) throws IOException
{
customerService.removeCustomerById(id);
return Response.noContent().build();
}
}Dit is de implementatie van de klant REST API. De andere geassocieerde ones met bestellingen, bestelitems en producten zijn vergelijkbaar.
Laten we nu zien hoe we het geheel kunnen uitvoeren en testen.
Uitvoeren en Testen van Onze Microservices
Nu we naar de details van onze implementatie hebben gekeken, laten we zien hoe we het kunnen uitvoeren en testen. We hebben ervoor gekozen om dit namens de docker-compose hulpmiddel te doen. Hier is het geassocieerde docker-compose.yml bestand:
version: "3.7"
services:
elasticsearch:
image: elasticsearch:8.12.2
environment:
node.name: node1
cluster.name: elasticsearch
discovery.type: single-node
bootstrap.memory_lock: "true"
xpack.security.enabled: "false"
path.repo: /usr/share/elasticsearch/backups
ES_JAVA_OPTS: -Xms512m -Xmx512m
hostname: elasticsearch
container_name: elasticsearch
ports:
- "9200:9200"
- "9300:9300"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- node1-data:/usr/share/elasticsearch/data
networks:
- elasticsearch
kibana:
image: docker.elastic.co/kibana/kibana:8.6.2
hostname: kibana
container_name: kibana
environment:
- elasticsearch.url=http://elasticsearch:9200
- csp.strict=false
ulimits:
memlock:
soft: -1
hard: -1
ports:
- 5601:5601
networks:
- elasticsearch
depends_on:
- elasticsearch
links:
- elasticsearch:elasticsearch
docstore:
image: quarkus-nosql-tests/docstore-elasticsearch:1.0-SNAPSHOT
depends_on:
- elasticsearch
- kibana
hostname: docstore
container_name: docstore
links:
- elasticsearch:elasticsearch
- kibana:kibana
ports:
- "8080:8080"
- "5005:5005"
networks:
- elasticsearch
environment:
JAVA_DEBUG: "true"
JAVA_APP_DIR: /home/jboss
JAVA_APP_JAR: quarkus-run.jar
volumes:
node1-data:
driver: local
networks:
elasticsearch:
Dit bestand instrueert het docker-compose hulpmiddel om drie services uit te voeren:
- A service named
elasticsearchrunning the Elasticsearch 8.6.2 database - A service named
kibanarunning the multipurpose web console providing different options such as executing queries, creating aggregations, and developing dashboards and graphs - A service named
docstorerunning our Quarkus microservice
Nu kunt u controleren of alle benodigde processen draaien:
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
005ab8ebf6c0 quarkus-nosql-tests/docstore-elasticsearch:1.0-SNAPSHOT "/opt/jboss/containe…" 3 days ago Up 3 days 0.0.0.0:5005->5005/tcp, :::5005->5005/tcp, 0.0.0.0:8080->8080/tcp, :::8080->8080/tcp, 8443/tcp docstore
9678c0a04307 docker.elastic.co/kibana/kibana:8.6.2 "/bin/tini -- /usr/l…" 3 days ago Up 3 days 0.0.0.0:5601->5601/tcp, :::5601->5601/tcp kibana
805eba38ff6c elasticsearch:8.12.2 "/bin/tini -- /usr/l…" 3 days ago Up 3 days 0.0.0.0:9200->9200/tcp, :::9200->9200/tcp, 0.0.0.0:9300->9300/tcp, :::9300->9300/tcp elasticsearch
$
Om te bevestigen dat de Elasticsearch server beschikbaar is en queries kan uitvoeren, kunt u verbinding maken met Kibana op http://localhost:601. Na naar beneden te scrollen op de pagina en Dev Tools te selecteren in het voorkeurenmenu, kunt u queries uitvoeren zoals hieronder wordt getoond:
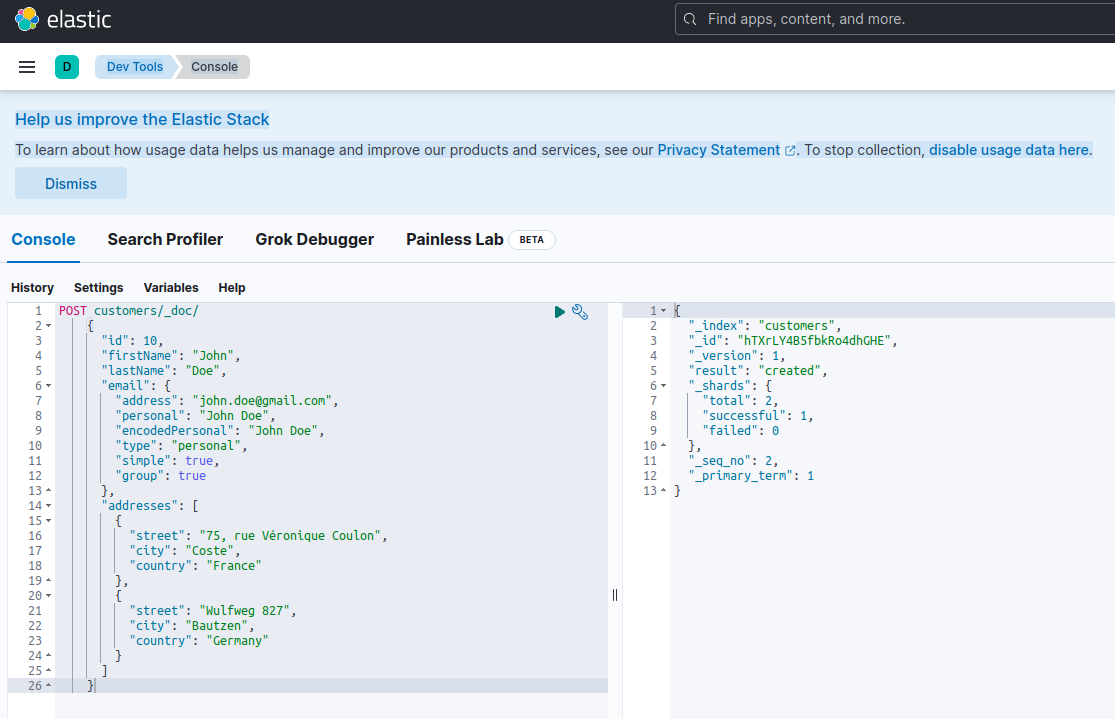
Om de microservices te testen, ga als volgt te werk:
1. Kloon de geassocieerde GitHub repository:
$ git clone https://github.com/nicolasduminil/docstore.git2. Ga naar het project:
$ cd docstore3. Checkout de juiste branch:
$ git checkout elastic-search4. Bouw:
$ mvn clean install5. Voer de integratietests uit:
$ mvn -DskipTests=false failsafe:integration-testDeze laatste opdracht zal de 17 geleverde integratietests uitvoeren, die allemaal moeten slagen. Je kunt ook de Swagger UI-interface gebruiken voor testdoeleinden door je voorkeursbrowser te openen op http://localhost:8080/q:swagger-ui. Vervolgens kun je de payload gebruiken in de JSON-bestanden die zich bevinden in de src/resources/data map van het docstore-api project.
Geniet ervan!
Source:
https://dzone.com/articles/cruding-nosql-data-with-quarkus-part-two-elasticse