













Logs nemen vaak het grootste deel in van de gegevensbezittingen van een bedrijf. Voorbeelden van logs omvatten zakelijke logs (zoals gebruikersactiviteitenlogs) en Operationele en Onderhoudslogs van servers, databases, netwerken of IoT-apparaten.
Logs zijn de beschermengel van het bedrijfsleven. Enerzijds bieden ze systeemrisicowarningen en helpen ingenieurs snel de oorzaak van problemen te lokaliseren. Anderzijds kunnen, als je ze in een bepaalde tijdsperiode bekijkt, nuttige trends en patronen worden geïdentificeerd, laat staan dat zakelijke logs de basis vormen voor gebruikersinzichten.
Echter, logs kunnen een lastige zaak zijn omdat:
- Ze binnenstromen als een golf. Elke systeemgebeurtenis of klik van de gebruiker genereert een log. Een bedrijf produceert vaak tienduizenden miljarden nieuwe logs per dag.
- Ze zijn omvangrijk. Logs moeten blijven bestaan. Ze kunnen pas nuttig zijn als dat nodig is. Dus een bedrijf kan tot PBs aan loggegevens accumuleren, waarvan velen zelden bezocht worden maar toch grote opslagruimte innemen.
- Ze moeten snel laden en gevonden kunnen worden. Het lokaliseren van de doellog voor probleemoplossing is letterlijk zoeken naar een naald in een hooiberg. Mensen verlangen naar real-time logschrijven en real-time reacties op logqueries.
Nu krijg je een duidelijk beeld van wat een ideale logverwerkingssysteem is. Het zou de volgende ondersteuning moeten bieden:
- Hoge doorvoer real-time gegevensopname: Het zou in staat moeten zijn om logs in bulk te schrijven en ze onmiddellijk zichtbaar te maken.
- Kosteneffectieve opslag: Het zou in staat moeten zijn om grote hoeveelheden logs op te slaan zonder te veel middelen te verspillen.
- Real-time tekst zoeken: Het zou snelle tekstzoekmogelijkheden moeten hebben.
Algemene oplossingen: Elasticsearch en Grafana Loki
Er zijn twee veelgebruikte oplossingen voor logboekverwerking in de industrie, geïllustreerd door Elasticsearch en Grafana Loki.
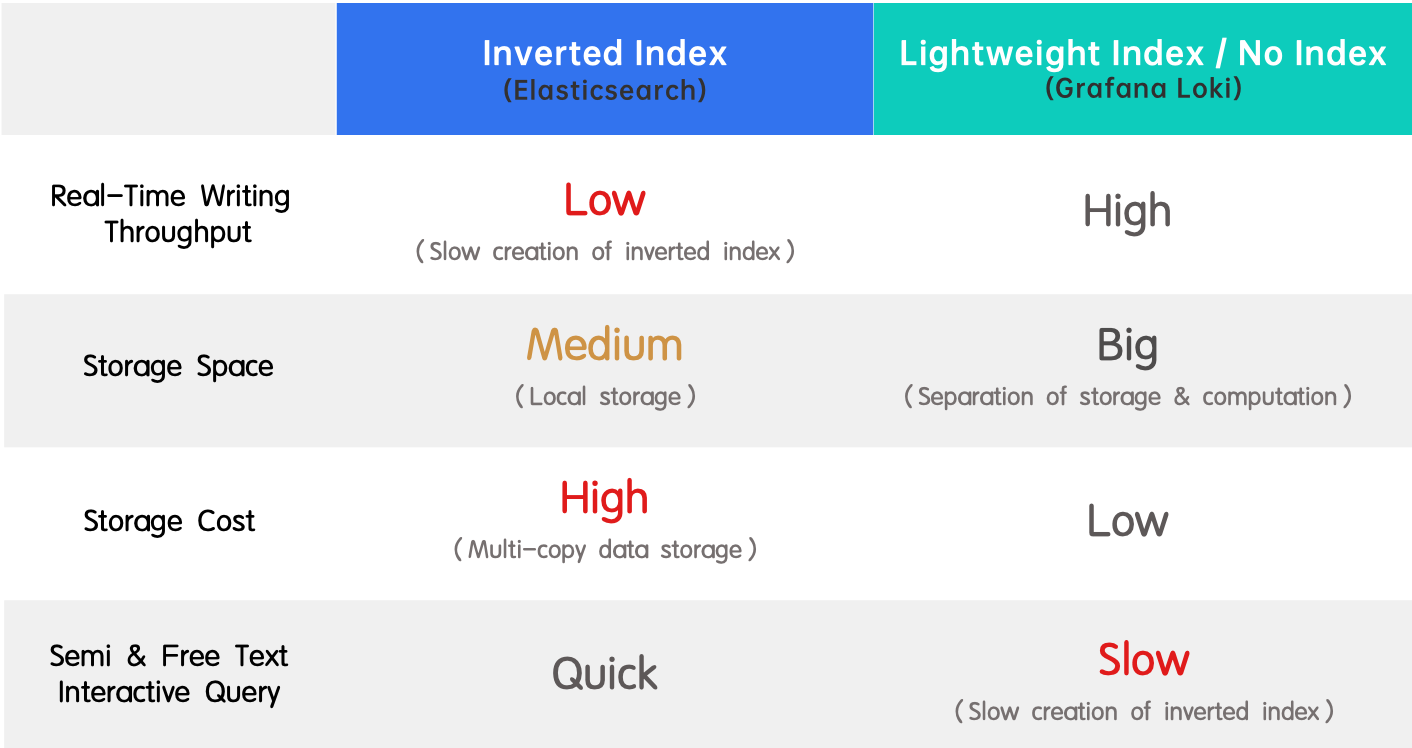
- Omgekeerde index (Elasticsearch): Het wordt breed aangenomen vanwege zijn ondersteuning voor volledige tekstzoekopdrachten en hoge prestaties. Het nadeel is de lage doorvoer bij realtime schrijven en de enorme hoeveelheid resources die nodig zijn voor het aanmaken van de index.
- Lichtgewicht index / geen index (Grafana Loki): Het is het tegenovergestelde van een omgekeerde index, omdat het een hoge realtime schrijfdoorvoer en lage opslagkosten heeft, maar trage query’s aflevert.
Inleiding tot omgekeerde index
A prominent strength of Elasticsearch in log processing is quick keyword search among a sea of logs. This is enabled by inverted indexes.
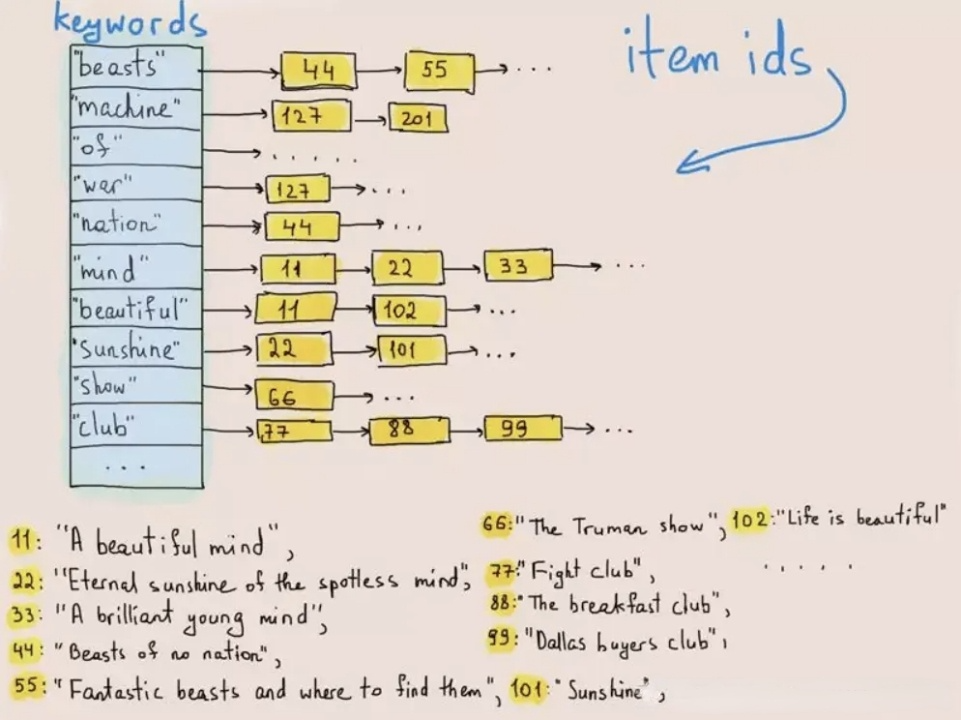
Omgekeerde indexering werd oorspronkelijk gebruikt om woorden of zinnen in teksten te vinden. Het onderstaande diagram toont hoe het werkt:
Bij het schrijven van gegevens worden teksten ge-tokenizeerd tot termen en deze termen worden opgeslagen in een postingslijst die termen koppelt aan de ID van de rij waar ze bestaan. Bij tekstzoekopdrachten vindt de database de overeenkomstige rij-ID van het trefwoord (term) in de postingslijst en haalt de doelrij op op basis van de rij-ID. Op deze manier hoeft het systeem niet door de hele dataset te doorzoeken en verbetert de zoeksnelheid met tientallen malen.
Bij de omgekeerde indexering van Elasticsearch komt snelle opvraging ten koste van schrijfsnelheid, schrijfdoorvoer en opslagruimte. Waarom? Ten eerste zijn tokenisatie, woordenboeksorteren en het maken van de omgekeerde index allemaal CPU- en geheugenintensieve operaties. Ten tweede moet Elasticssearch de oorspronkelijke gegevens, de omgekeerde index en een extra kopie van de gegevens opslaan die in kolommen zijn opgeslagen voor queryversnelling. Dat is drievoudige redundantie.
Maar zonder een omgekeerde index, bijvoorbeeld Grafana Loki, ondervindt de gebruikerservaring hinder door trage query’s, wat het grootste probleem is voor ingenieurs bij loganalyse.
Simpel gezegd, Elasticsearch en Grafana Loki vertegenwoordigen verschillende afwegingen tussen hoge schrijfdoorvoer, lage opslagkosten en snelle queryprestaties. Wat als ik je vertel dat er een manier is om ze allemaal te hebben? We hebben omgekeerde indexes geïntroduceerd in Apache Doris 2.0.0 en hebben deze verder geoptimaliseerd om twee keer snellere logqueryprestaties te realiseren dan Elasticsearch met 1/5 van de opslagruimte die het gebruikt. Beide factoren gecombineerd, is het een 10 keer betere oplossing.
Omgekeerde Index in Apache Doris
Over het algemeen zijn er twee manieren om indexen te implementeren: externe indexsystemen of ingebouwde indexes.
Externe indexeringssysteem: Je verbindt een externe indexeringssysteem met je database. Tijdens de gegevensinname worden gegevens naar beide systemen geïmporteerd. Nadat het indexeringssysteem indices heeft gecreëerd, wordt de oorspronkelijke gegevens binnen zichzelf verwijderd. Wanneer gegevensgebruikers een query invoeren, biedt het indexeringssysteem de IDs van de relevante gegevens, waarna de database de doelgegevens opzoekt op basis van de IDs.
Het bouwen van een externe indexeringssysteem is gemakkelijker en minder inbreukmakend op de database, maar het heeft enkele vervelende nadelen:
- Het schrijven van gegevens naar twee systemen kan leiden tot gegevensinconsistentie en opslagredundantie.
- Interactie tussen de database en het indexeringssysteem brengt overheads met zich mee, dus bij een grote hoeveelheid doelgegevens kan de query tussen de twee systemen traag zijn.
- Het is uitputtend om twee systemen te onderhouden.
In Apache Doris kiezen we voor de andere weg. Ingebouwde omgekeerde indices zijn moeilijker te maken, maar zodra het is gedaan, is het sneller, gebruiksvriendelijker en onderhoudsvriendelijker.
In Apache Doris is de gegevensindeling als volgt. Indices worden opgeslagen in het Indexgebied:
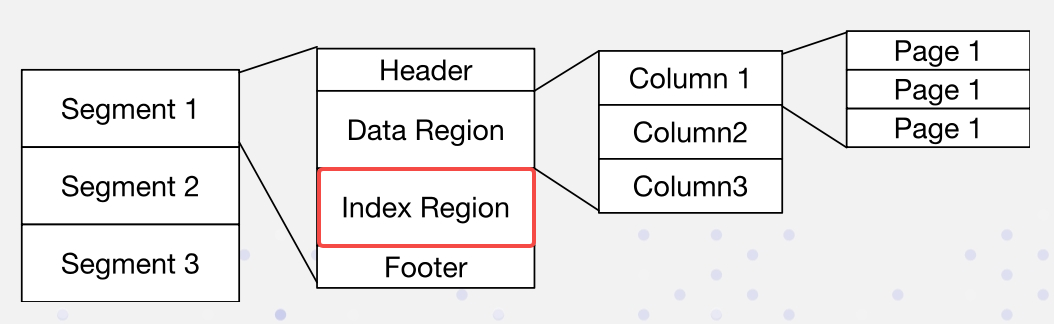
We implementeren omgekeerde indices op een niet-inbreukmakende manier:
- Gegevensinname en samenvoeging: Terwijl een segmentbestand in Doris wordt geschreven, zal ook een omgekeerd indexbestand worden geschreven. Het pad van het indexbestand wordt bepaald door de segment-ID en de index-ID. Rijen in segmenten correleren met de docs in indices, net zoals de RowID en de DocID.
- Vraag: Als de
whereclausule een kolom bevat met omgekeerde index, zal het systeem in het indexbestand zoeken, een DocID-lijst retourneren en deze lijst omzetten in een RowID Bitmap. Met het RowID-filteringsmechanisme van Apache Doris worden alleen de doelrijen gelezen. Zo worden query’s versneld.
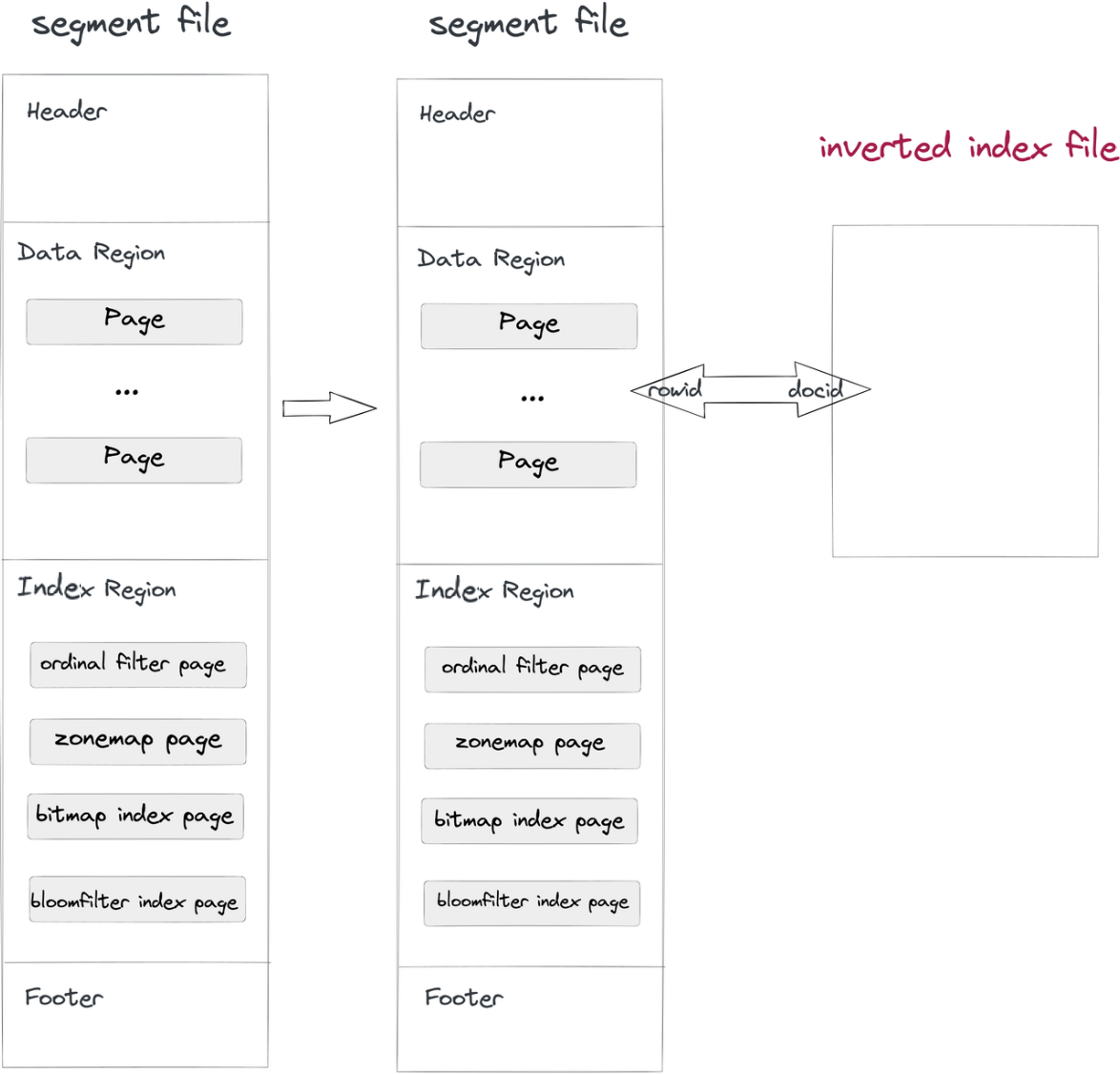
Een dergelijk niet-intrusief methode scheidt het indexbestand van de gegevensbestanden, zodat u eventuele wijzigingen aan de omgekeerde indices kunt aanbrengen zonder zorgen te maken over het beïnvloeden van de gegevensbestanden zelf of andere indices.
Optimalisaties voor Omgekeerde Index
Algemene Optimalisaties
C++ Implementation and Vectorization
In tegenstelling tot Elasticsearch, dat Java gebruikt, implementeert Apache Doris C++ in zijn opslagmodules, query uitvoerend systeem en omgekeerde indices. In vergelijking met Java biedt C++ betere prestaties, faciliteert gemakkelijker vectorisatie en produceert geen JVM GC-overhead. We hebben elke stap van omgekeerde indexering in Apache Doris gevectoriseerd, zoals tokenisatie, indexaanmaak en query’s. Om u een perspectief te geven, bij omgekeerde indexering schrijft Apache Doris gegevens met een snelheid van 20MB/s per kern, wat vier keer zo snel is als Elasticsearch (5MB/s).
Kolomgebaseerde Opslag en Compressie
Apache Lucene vormt de basis voor omgekeerde indices in Elasticsearch. Aangezien Lucene zelf is ontworpen om bestandsopslag te ondersteunen, slaat het gegevens op in een rij-georiënteerde indeling.
In Apache Doris zijn de omgekeerde indices voor verschillende kolommen van elkaar gescheiden, en de omgekeerde indexbestanden gebruiken kolomgebaseerde opslag om vectorisatie en gegevenscompressie te vergemakkelijken.
Door gebruik te maken van Zstandardcompressie, realiseert Apache Doris een compressieratio variërend van 5:1 tot 10:1, snellere compressiesnelheden en 50% minder ruimtegebruik dan GZIPcompressie.
BKD Bomen voor Numerieke / Datumtijd Kolommen
Apache Doris past BKD bomen toe voor numerieke en datumtijd kolommen. Dit verhoogt niet alleen de prestaties van range queries, maar is ook een meer ruimtebesparende methode dan het omzetten van die kolommen naar vaste-lengte strings. Andere voordelen hiervan omvatten:
- Efficiënte range queries: Het kan snel de doelgegevensbereik in numerieke en datumtijd kolommen lokaliseren.
- Minder opslagruimte: Het verzamelt en comprimeert aangrenzende gegevensblokken om de opslagkosten te verlagen.
- Ondersteuning voor meerdimensionale gegevens: BKD bomen zijn schaalbaar en aanpasbaar voor meerdimensionale gegevenstypen, zoals GEO punten en bereiken.
Naast BKD bomen hebben we de queries op numerieke en datumtijd kolommen verder geoptimaliseerd.
- Optimalisatie voor lage cardinaliteit scenario’s: We hebben de compressie-algoritme voor lage cardinaliteit scenario’s aangepast, zodat het ontleden en deserialiseren van grote hoeveelheden omgekeerde lijsten minder CPU-bronnen zal verbruiken.
- Voorbereiding: Voor scenario’s met een hoge treffer-rate passen we voorbereiding toe. Als de treffer-rate een bepaald drempelwaarde overschrijdt, zal Doris de indexeringsproces overslaan en met gegevensfiltrering beginnen.
Aangepaste Optimalisaties voor OLAP
Over het algemeen is loganalyse een eenvoudige vorm van query waar geen geavanceerde functies (zoals relevantie-scorings in Apache Lucene) voor nodig zijn. De kernvaardigheid van een logverwerkingshulpmiddel is snelle query’s en lage opslagkosten. Daarom hebben we in Apache Doris de omgekeerde indexstructuur gestroomlijnd om aan de behoeften van een OLAP-database te voldoen.
- Bij het opnemen van gegevens voorkomen we dat meerdere threads gegevens in dezelfde index schrijven, waardoor we de overhead veroorzaakt door lock-concurrentie vermijden.
- We laten voorwaartse indexbestanden en Norm-bestanden weg om opslagruimte vrij te maken en I/O-overhead te verminderen.
- We vereenvoudigen de berekeningslogica van relevantie-scorings en rangschikking om verdere overhead te verminderen en prestaties te verhogen.
In het licht van het feit dat logs zijn gepartitioneerd op tijdsbereik en historische logs minder vaak worden bezocht, zijn we van plan om in toekomstige versies van Apache Doris meer gedetailleerde en flexibele indexbeheer te bieden:
- Maak een omgekeerde index voor een bepaalde gegevenspartitie: maak een index aan voor logs van de afgelopen zeven dagen, enzovoort.
- Verwijder de omgekeerde index voor een bepaalde gegevenspartitie: verwijder index voor logs van meer dan een maand geleden, enzovoort (om indexruimte vrij te maken).
BenchMarking
We hebben Apache Doris getest op openbaar beschikbare datasets tegenover Elasticsearch en ClickHouse.
Voor een eerlijke vergelijking zorgen we voor uniformiteit van testomstandigheden, inclusief benchmarkingtool, datasets en hardware.
Apache Doris vs. Elasticsearch
- Benchmarking tool: ES Rally, het officiële testgereedschap voor Elasticsearch
- Dataset: HTTP-serverlogs van het WK 1998 (zelfstandig dataset in ES Rally)
- Gegevensgrootte (voor compressie): 32G, 247 miljoen rijen, 134 bytes per rij (gemiddeld)
- Query: 11 query’s, inclusief zoekwoordzoekopdrachten, bereikquery’s, aggregaties en ranking; Elke query wordt 100 keer achter elkaar uitgevoerd.
- Omgeving: 3 × 16C 64G cloud virtuele machines
Resultaten van Apache Doris:
- Schrijfsnelheid: 550 MB/s,4,2 keer die van Elasticsearch
- Compressieverhouding: 10:1
- Opslaggebruik: 20% van Elasticsearch
- Reactietijd: 43% van Elasticsearch

Apache Doris vs. ClickHouse
Omdat ClickHouse een omgekeerde index lanceerde als experimentele functie in v23.1, hebben we Apache Doris getest met dezelfde dataset en SQL zoals beschreven in de ClickHouse blog en vergeleken de prestaties van de twee onder dezelfde testbronnen, gevallen en gereedschap.
- Data: 6,7G, 28,73 miljoen rijen, de Hacker News dataset, Parquet formaat
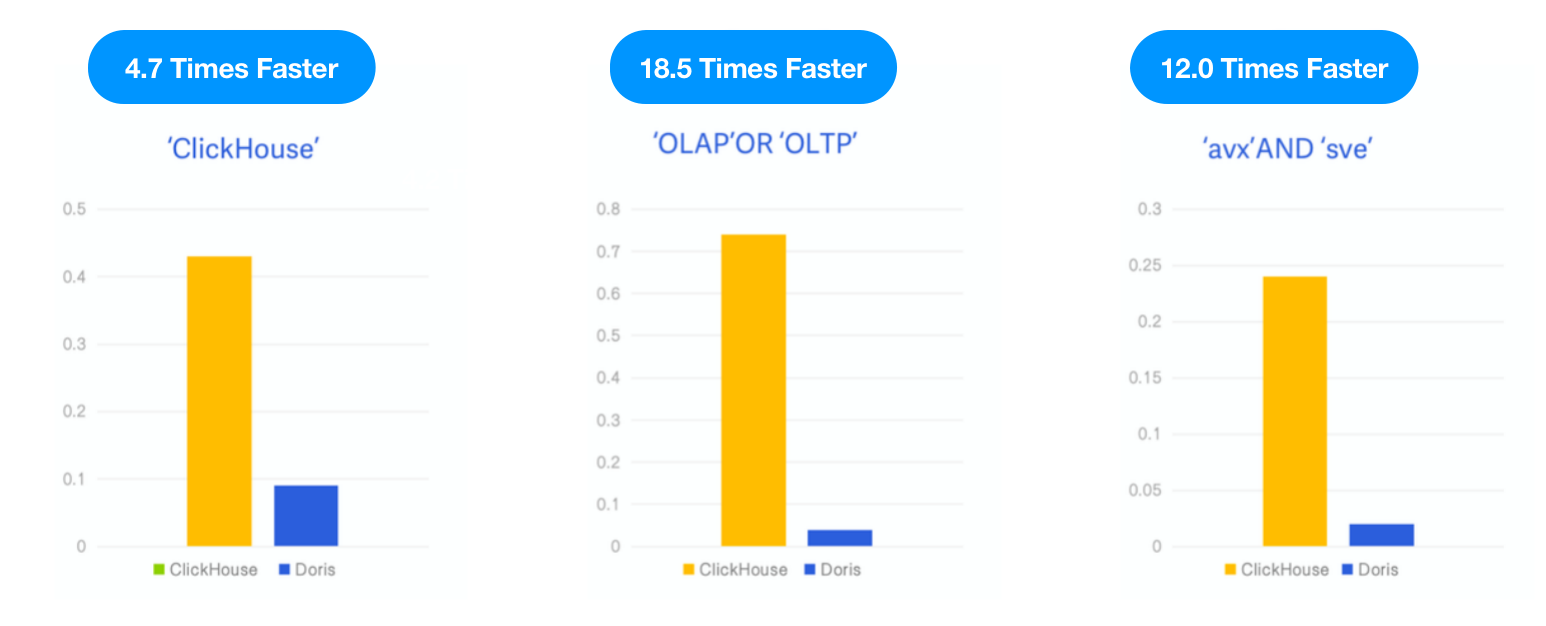
- Query: 3 zoekwoordzoekopdrachten, tellen het aantal voorkomens van de zoekwoorden “ClickHouse,” “OLAP,” OR “OLTP,” en “avx” AND “sve”.
- Omgeving: 1 × 16C 64G cloud virtuele machine
Resultaat: Apache Doris was 4,7 keer, 18,5 keer en 12 keer sneller dan ClickHouse in de drie query’s, respectievelijk.
Gebruik en Voorbeeld
- Gegevensset: één miljoen commentaarrecords van Hacker News
Stap 1: Geef de omgekeerde index op bij het maken van de gegevenseenheid.
Parameters:
- INDEX idx_comment (
comment): maak een index met de naam “idx_comment” commentaar voor de “commentaar” kolom - USING INVERTED: specificeer omgekeerde index voor de tabel
- PROPERTIES(“parser” = “english”): specificeer de taal voor tokenisatie naar Engels
CREATE TABLE hackernews_1m
(
`id` BIGINT,
`deleted` TINYINT,
`type` String,
`author` String,
`timestamp` DateTimeV2,
`comment` String,
`dead` TINYINT,
`parent` BIGINT,
`poll` BIGINT,
`children` Array<BIGINT>,
`url` String,
`score` INT,
`title` String,
`parts` Array<INT>,
`descendants` INT,
INDEX idx_comment (`comment`) USING INVERTED PROPERTIES("parser" = "english") COMMENT 'inverted index for comment'
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 10
PROPERTIES ("replication_num" = "1");(Opmerking: U kunt een index toevoegen aan een bestaande tabel via ADD INDEX idx_comment ON hackernews_1m(commentaar) USING INVERTED PROPERTIES("parser" = "english"). Anders dan bij een slimme index en secundaire index, betreft de creatie van een omgekeerde index alleen het lezen van de commentaarkolom, dus het kan veel sneller zijn.)
Stap 2: Haal de woorden “OLAP” en “OLTP” op in de commentaarkolom met MATCH_ALL. De reactietijd hier was 1/10 van die bij harde overeenkomst met like. (De prestatiekloof neemt toe naarmate het gegevensvolume toeneemt.)
mysql> SELECT count() FROM hackernews_1m WHERE comment LIKE '%OLAP%' AND comment LIKE '%OLTP%';
+---------+
| count() |
+---------+
| 15 |
+---------+
1 row in set (0.13 sec)
mysql> SELECT count() FROM hackernews_1m WHERE comment MATCH_ALL 'OLAP OLTP';
+---------+
| count() |
+---------+
| 15 |
+---------+
1 row in set (0.01 sec)
Voor meer functie-introductie en gebruiksaanwijzing, zie documentatie: Omgekeerde Index
Samenvatting
Kortom, wat bijdraagt aan de 10-voudig hogere kosteneffectiviteit van Apache Doris in vergelijking met Elasticsearch, zijn de op OLAP afgestemde optimalisaties voor omgekeerde indexering, ondersteund door de kolomgebaseerde opslagmotor, massale parallelle verwerkingsframework, vectorisatie-queryengine en de kostengebaseerde optimalisator van Apache Doris.
Zeer trots als we zijn op ons eigen oplossing voor omgekeerde indexering, begrijpen we dat zelfgepubliceerde benchmarks controversieel kunnen zijn, dus zijn we open voor feedback van derden en kijken we ernaar uit hoe Apache Doris zich gedraagt in echte gevallen.
Source:
https://dzone.com/articles/building-a-log-analytics-solution-10-times-more-co