













Dit is een deel van de digitale transformatie van een groot vastgoedbedrijf. Voor het oog van geheimhouding, ga ik geen bedrijfsgegevens onthullen, maar je krijgt een gedetailleerd overzicht van onze databank en onze optimalisatiestrategieën.
Laten we nu beginnen.
Architectuur
Logisch gezien kan onze data-architectuur in vier delen worden opgedeeld.
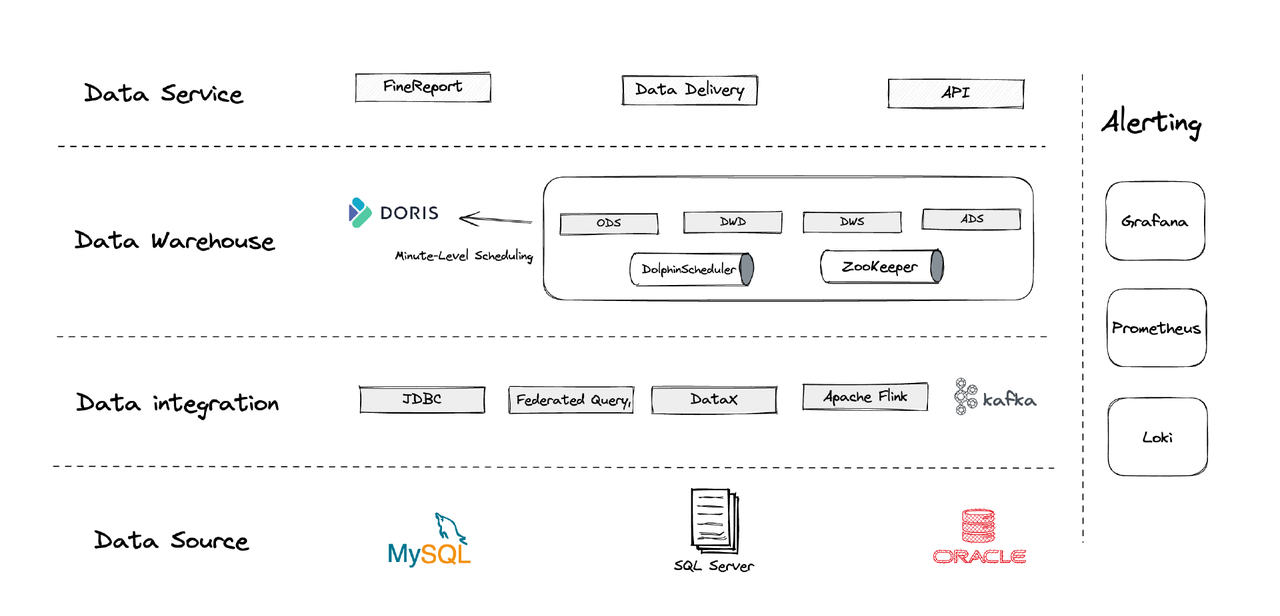
- Data-integratie: Dit wordt ondersteund door Flink CDC, DataX en de Multi-Catalog-functie van Apache Doris.
- Data-beheer: We gebruiken Apache Dolphinscheduler voor het levenscyclusbeheer van scripts, bevoegdheden in multi-tenantbeheer en data-kwaliteitsbewaking.
- Waarschuwingen: We gebruiken Grafana, Prometheus en Loki om componentresources en logs te bewaken.
- Data-diensten: Dit is waar BI-tools aan de slag gaan voor gebruikersinteractie, zoals data-query’s en analyse.
1. Tabellen
We maken onze dimensietabellen en feitstabellen rond elk besturingsentiteit in het bedrijf, inclusief klanten, huizen, enz. Als er een reeks activiteiten betreft dezelfde besturingsentiteit, moeten deze worden geregistreerd door één veld. (Dit is een les getrokken uit ons vorige chaotische data-beheersysteem.)
2. Lagen
Onze databank is opgedeeld in vijf conceptuele lagen. We gebruiken Apache Doris en Apache DolphinScheduler om de DAG-scripts tussen deze lagen te plannen.

Elke dag ondergaan de lagen een algehele update naast incrementele updates in geval van veranderingen in historische statusvelden of onvolledige gegevenssynchronisatie van ODS-tabellen.
3. Incrementele Update-strategieën
(1) Stel where >= "activity time -1 dag of -1 uur" in plaats vanwhere >= "activity time
De reden hiervoor is om gegevensverschuiving te voorkomen die wordt veroorzaakt door de tijdsgaten van scripts plannen. Stel je voor, met de uitvoeringsinterval ingesteld op 10 minuten, dat het script wordt uitgevoerd om 23:58:00 en een nieuw stuk gegevens arriveert om 23:59:00. Als we where >= "activity time instellen, wordt dat stuk gegevens van de dag gemist.
(2) Haal de ID van de grootste primaire sleutel van de tabel voor elke scriptuitvoering, sla de ID op in de hulptabel en stelwhere >= "ID in hulptabel"
Dit is om gegevensduplicatie te voorkomen. Gegevensduplicatie kan optreden als u het Unique Key-model van Apache Doris gebruikt en een set primaire sleutels aanwijst, omdat als er wijzigingen zijn in de primaire sleutels in de bron tabel, de wijzigingen worden geregistreerd en de relevante gegevens worden geladen. Deze methode kan dat oplossen, maar is alleen van toepassing als de bron tabellen automatisch incrementele primaire sleutels hebben.
(3) Partitie de tabellen
Wat betreft tijdsgebaseerde automatisch verhogen van gegevens, zoals logtabellen, zijn er mogelijk minder wijzigingen in historische gegevens en status, maar het gegevensvolume is groot, dus er kan een enorme rekenbelasting zijn op algehele updates en het maken van snapshots. Daarom is het beter om dergelijke tabellen te partitioneren, zodat we voor elke incrementele update slechts één partitie hoeven te vervangen. (Let ook op mogelijke gegevensverschuiving.)
4. Algemene Update Strategieën
(1) Tabellen Truncate
Verwijder de tabel en ververs vervolgens alle gegevens van de bron tabel. Dit is toepasbaar voor kleine tabellen en scenario’s waarbij er ’s nachts geen gebruikersactiviteit is.
(2) ALTER TABLE tbl1 REPLACE WITH TABLE tbl2
Dit is een atoomoperatie en is aan te raden voor grote tabellen. Voordat elke scriptuitvoering plaatsvindt, creëren we een tijdelijke tabel met hetzelfde schema, laden we alle gegevens erin, en vervangen we de oorspronkelijke tabel door deze.
Toepassing
- ETL taak: elke minuut
- Configuratie voor eerste implementatie: 8 knooppunten, 2 frontends, 8 backends, hybride implementatie
- Knooppuntconfiguratie: 32C * 60GB * 2TB SSD
Dit is onze configuratie voor TBs aan legacygegevens en GBs aan incrementele gegevens. U kunt dit als referentie gebruiken en uw cluster hierop baseren. De implementatie van Apache Doris is eenvoudig. U heeft geen andere componenten nodig.
1. Om offline gegevens en loggegevens te integreren, gebruiken we DataX, dat CSV-indeling ondersteunt en lezers van veel relationele databases, en Apache Doris biedt een DataX-Doris-Writer.

2. We gebruiken Flink CDC om gegevens van brontabellen te synchroniseren. Vervolgens aggregaten we de real-time metrieken met behulp van het gematerialiseerde weergave of het aggregatiemodel van Apache Doris. Aangezien we slechts een deel van de metrieken in realtime hoeven te verwerken en we niet te veel databaseverbindingen willen genereren, gebruiken we één Flink-taak om meerdere CDC-brontabellen te onderhouden. Dit wordt gerealiseerd door de functies voor het samenvoegen van meerdere bronnen en volledige databasesynchronisatie van Dinky, of u kunt zelf een Flink DataStream-taak voor het samenvoegen van meerdere bronnen implementeren. Het is vermeldenswaard dat Flink CDC en Apache Doris Schema Change ondersteunen.
EXECUTE CDCSOURCE demo_doris WITH (
'connector' = 'mysql-cdc',
'hostname' = '127.0.0.1',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'checkpoint' = '10000',
'scan.startup.mode' = 'initial',
'parallelism' = '1',
'table-name' = 'ods.ods_*,ods.ods_*',
'sink.connector' = 'doris',
'sink.fenodes' = '127.0.0.1:8030',
'sink.username' = 'root',
'sink.password' = '123456',
'sink.doris.batch.size' = '1000',
'sink.sink.max-retries' = '1',
'sink.sink.batch.interval' = '60000',
'sink.sink.db' = 'test',
'sink.sink.properties.format' ='json',
'sink.sink.properties.read_json_by_line' ='true',
'sink.table.identifier' = '${schemaName}.${tableName}',
'sink.sink.label-prefix' = '${schemaName}_${tableName}_1'
);3. We gebruiken SQL-scripts of “Shell + SQL”-scripts en we voeren scriptlevenscyclusbeheer uit. Op het ODS-niveau schrijven we een algemeen DataX-taakbestand en passen we parameters toe voor elke broninname in plaats van voor elke brontabel een DataX-taak te schrijven. Op deze manier maken we het onderhoud veel eenvoudiger. We beheren de ETL-scripts van Apache Doris op DolphinScheduler, waar we ook versiebeheer uitvoeren. In geval van fouten in de productieomgeving kunnen we altijd terugrollen.
4. Nadat we gegevens hebben ingenomen met ETL-scripts, maken we een pagina aan in onze rapportagetool. We kennen verschillende privileges toe aan verschillende accounts met behulp van SQL, inclusief het privilege om rijen, velden en globale woordenboeken te wijzigen. Apache Doris ondersteunt geprivilegieerde controle over accounts, wat hetzelfde werkt als in MySQL.
We gebruiken ook Apache Doris gegevensback-up voor rampenherstel, Apache Doris auditlogboeken om de efficiëntie van SQL-uitvoering te controleren, Grafana+Loki voor waarschuwingen over cluster metrische gegevens en Supervisor om de daemonprocessen van knooppuntcomponenten te controleren.
Optimalisatie
Gegevensopname
We gebruiken DataX om offline gegevens te streamen. Het stelt ons in staat om de grootte van elke batch aan te passen. De Stream Load-methode retourneert resultaten synchroon, wat aan de behoeften van ons architectuur voldoet. Als we asynchrone gegevensimport uitvoeren met DolphinScheduler, kan het systeem aannemen dat het script is uitgevoerd, en dat kan voor problemen zorgen. Als u een andere methode gebruikt, raden we u aan om show load in het shellscript uit te voeren en de status van regex-filtering te controleren om te zien of de opname is geslaagd.
Gegevensmodel
We gebruiken voor de meeste van onze tabellen het Unique Key-model van Apache Doris. Het Unique Key-model zorgt voor de idempotentie van gegevensscripts en voorkomt effectief duplicatie van upstreamgegevens.
Lezen van externe gegevens
We gebruiken de Multi-Catalog-functie van Apache Doris om verbinding te maken met externe gegevensbronnen. Het stelt ons in staat om op Catalog-niveau toewijzingen van externe gegevens te maken.
Queryoptimalisatie
We raden u aan om de meest gebruikte velden van niet-karaktertypen (zoals int en where-clausules) in de eerste 36 bytes te plaatsen, zodat u deze velden binnen milliseconden kunt filteren in point-queries.
Gegevenswoordenboek
Voor ons is het belangrijk om een datadictarisatie te creëren omdat dit in grote mate de kosten van personeelcommunicatie vermindert, wat een hoofdpijn kan zijn bij een groot team. We gebruiken de information_schema in Apache Doris om een datadictarisatie te genereren. Met deze kunnen we snel inzicht krijgen in het geheel van tabellen en velden, en daarmee de ontwikkelingsefficiëntie verhogen.
Prestaties
Offline data-ingestietijd: Binnen enkele minuten
Query latentie: Voor tabellen met meer dan 100 miljoen rijen reageert Apache Doris binnen één seconde op ad-hoc queries en binnen vijf seconden op gecompliceerde queries.
Bronnengebruik: Het kost slechts een klein aantal servers om deze databank op te zetten. De compressieratio van 70% van Apache Doris bespaart ons veel opslagbronnen.
Ervaring en conclusie
Eigenlijk, voordat we ons huidige databeheer ontwikkelden, probeerden we Hive, Spark en Hadoop om een offline databank op te zetten. Het bleek dat Hadoop overdreven was voor een traditioneel bedrijf zoals ons, aangezien we niet te veel data te verwerken hadden. Het is belangrijk om het juiste component te vinden dat het beste bij je past.
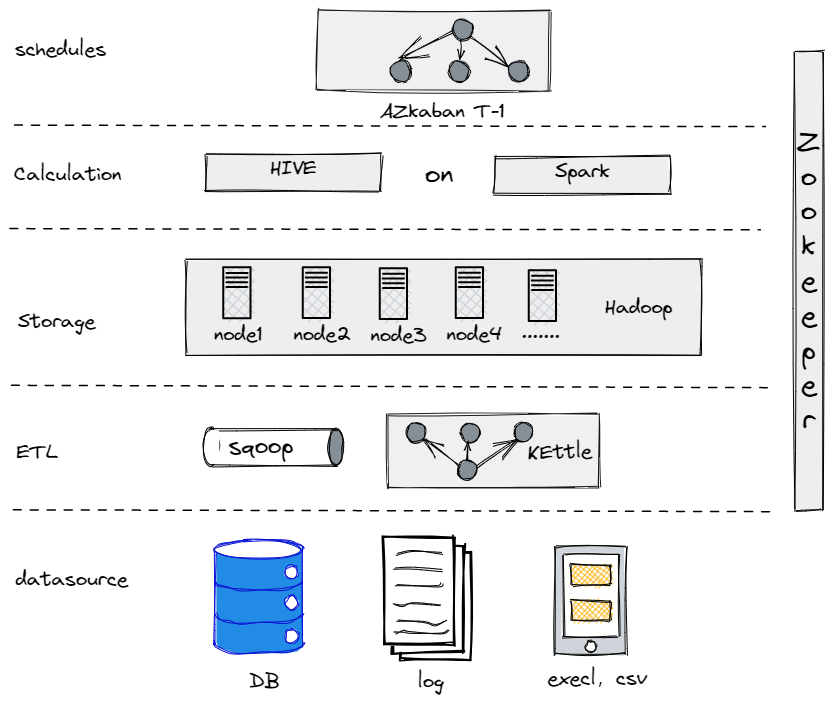
Onze oude offline databank
Aan de andere kant, om onze overgang naar big data zo soepel mogelijk te laten verlopen, moeten we ons gegevensplatform zo eenvoudig mogelijk maken wat betreft gebruik en onderhoud. Daarom kozen we voor Apache Doris. Het is compatibel met het MySQL-protocol en biedt een uitgebreide verzameling functies, zodat we onze eigen UDF’s niet hoeven te ontwikkelen. Bovendien bestaat het uit slechts twee soorten processen: frontends en backends, waardoor het gemakkelijk te schalen en te volgen is.
Source:
https://dzone.com/articles/building-a-data-warehouse-for-traditional-industry