













De opkomst van agentic AI heeft opwinding veroorzaakt rond agents die autonoom taken uitvoeren, aanbevelingen doen en complexe workflows uitvoeren waarin AI wordt gecombineerd met traditionele computing. Maar het creëren van dergelijke agents in echte, op producten gerichte omgevingen brengt uitdagingen met zich mee die verder gaan dan de AI zelf.
Zonder een zorgvuldige architectuur kunnen afhankelijkheden tussen componenten bottlenekken creëren, schaalbaarheid beperken en onderhoud compliceren naarmate systemen evolueren. De oplossing ligt in het ontkoppelen van workflows, waarbij agents, infrastructuur en andere componenten vloeiend met elkaar communiceren zonder starre afhankelijkheden.
Deze flexibele, schaalbare integratie vereist een gedeelde “taal” voor gegevensuitwisseling – een robuuste event-driven architectuur (EDA) aangedreven door streams van gebeurtenissen. Door toepassingen rond gebeurtenissen te organiseren, kunnen agents werken in een responsief, ontkoppeld systeem waarin elk onderdeel onafhankelijk zijn werk doet. Teams kunnen technologische keuzes vrijelijk maken, schaalbaarheidsbehoeften afzonderlijk beheren en duidelijke grenzen tussen componenten behouden, waardoor echte flexibiliteit mogelijk is.
Om deze principes te testen, heb ik PodPrep AI ontwikkeld, een door AI aangedreven onderzoeksassistent die me helpt voor te bereiden op podcastinterviews op Software Engineering Daily en Software Huddle. In deze post zal ik ingaan op het ontwerp en de architectuur van PodPrep AI, waarbij ik laat zien hoe EDA en real-time gegevensstromen een effectief agentic systeem voeden.
Opmerking: Als je alleen naar de code wilt kijken, ga dan naar mijn GitHub repo hier.
Waarom een Event-Driven Architectuur voor AI?
In echte AI-toepassingen houdt een nauw gekoppeld, monolithisch ontwerp niet stand. Hoewel proefprojecten of demonstraties vaak gebruikmaken van een enkel, uniform systeem voor de eenvoud, wordt deze aanpak snel onpraktisch in productie, vooral in gedistribueerde omgevingen. Nauw gekoppelde systemen creëren knelpunten, beperken de schaalbaarheid en vertragen de iteratie — allemaal kritieke uitdagingen om te vermijden naarmate AI-oplossingen groeien.
Neem een typische AI-agent in overweging.
Deze moet mogelijk gegevens ophalen uit meerdere bronnen, prompt engineering en RAG-workflows beheren, en rechtstreeks communiceren met verschillende tools om deterministische workflows uit te voeren. De vereiste orkestratie is complex, met afhankelijkheden van meerdere systemen. En als de agent moet communiceren met andere agents, neemt de complexiteit alleen maar toe. Zonder een flexibele architectuur maken deze afhankelijkheden schaling en wijziging bijna onmogelijk.

In productie behandelen verschillende teams meestal verschillende delen van de stack: MLOps en data engineering beheren de RAG-pijplijn, datawetenschap selecteert modellen, en applicatieontwikkelaars bouwen de interface en backend. Een nauw gekoppelde opstelling dwingt deze teams in afhankelijkheden die de levering vertragen en schaling moeilijk maken. Idealiter zouden de applicatielagen de interne werking van de AI niet hoeven te begrijpen; ze zouden eenvoudigweg resultaten moeten consumeren wanneer dat nodig is.
Bovendien kunnen AI-toepassingen niet geïsoleerd werken. Voor echte waarde moeten AI inzichten naadloos stromen over klantgegevensplatforms (CDP’s), CRMs, analyses en meer. Klantinteracties zouden in real-time updates moeten activeren, die direct worden doorgevoerd naar andere tools voor actie en analyse. Zonder een verenigde aanpak wordt het integreren van inzichten over platforms heen een lappendeken die moeilijk te beheren is en onmogelijk om op te schalen.
Met door EDA aangedreven AI worden deze uitdagingen aangepakt door een “centraal zenuwstelsel” voor data te creëren. Met EDA zenden toepassingen gebeurtenissen uit in plaats van te vertrouwen op gekoppelde commando’s. Dit ontkoppelt componenten, waardoor data asynchroon kan stromen waar dat nodig is, waardoor elk team onafhankelijk kan werken. EDA bevordert naadloze data-integratie, schaalbare groei en veerkracht – waardoor het een krachtige basis is voor moderne op AI gebaseerde systemen.
Het ontwerpen van een Schaalbare AI-Gedreven Onderzoeksagent
De afgelopen twee jaar heb ik honderden podcasts gehost op Software Engineering Daily, Software Huddle en Partially Redacted.
Om me voor te bereiden op elke podcast voer ik een grondig onderzoeksproces uit om een podcast-brief voor te bereiden die mijn gedachten, achtergrond van de gast en onderwerp bevat, en een reeks mogelijke vragen. Om deze brief op te stellen, doe ik meestal onderzoek naar de gast en het bedrijf waar ze voor werken, luister naar andere podcasts waar ze mogelijk aan hebben deelgenomen, lees blogposts die ze hebben geschreven en lees over het hoofdonderwerp waarover we zullen praten.
Ik probeer verbindingen te leggen met andere podcasts die ik heb gehost of met mijn eigen ervaring die verband houdt met het onderwerp of soortgelijke onderwerpen. Dit hele proces kost aanzienlijke tijd en moeite. Grote podcastbedrijven hebben toegewijde onderzoekers en assistenten die dit werk voor de presentator doen. Ik run niet dat soort operatie hier. Ik moet dit allemaal zelf doen.
Om hierop in te spelen, wilde ik een agent bouwen die dit werk voor mij kon doen. Op hoog niveau zou de agent er ongeveer uitzien als de onderstaande afbeelding.

Ik lever basisbronmateriaal zoals de naam van de gast, het bedrijf, de onderwerpen waarop ik me wil concentreren, enkele referentie-URL’s zoals blogposts en bestaande podcasts, en dan gebeurt er wat AI-magie en is mijn onderzoek compleet.
Dit eenvoudige idee leidde mij tot het creëren van PodPrep AI, mijn op AI gebaseerde onderzoeksassistent die mij alleen tokens kost.
De rest van dit artikel bespreekt het ontwerp van PodPrep AI, te beginnen met de gebruikersinterface.
Het bouwen van de gebruikersinterface van de agent
Ik heb de interface van de agent ontworpen als een webapplicatie waar ik eenvoudig bronmateriaal voor het onderzoeksproces kan invoeren. Dit omvat de naam van de gast, hun bedrijf, het onderwerp van het interview, eventuele aanvullende context, en links naar relevante blogs, websites en eerdere podcastinterviews.
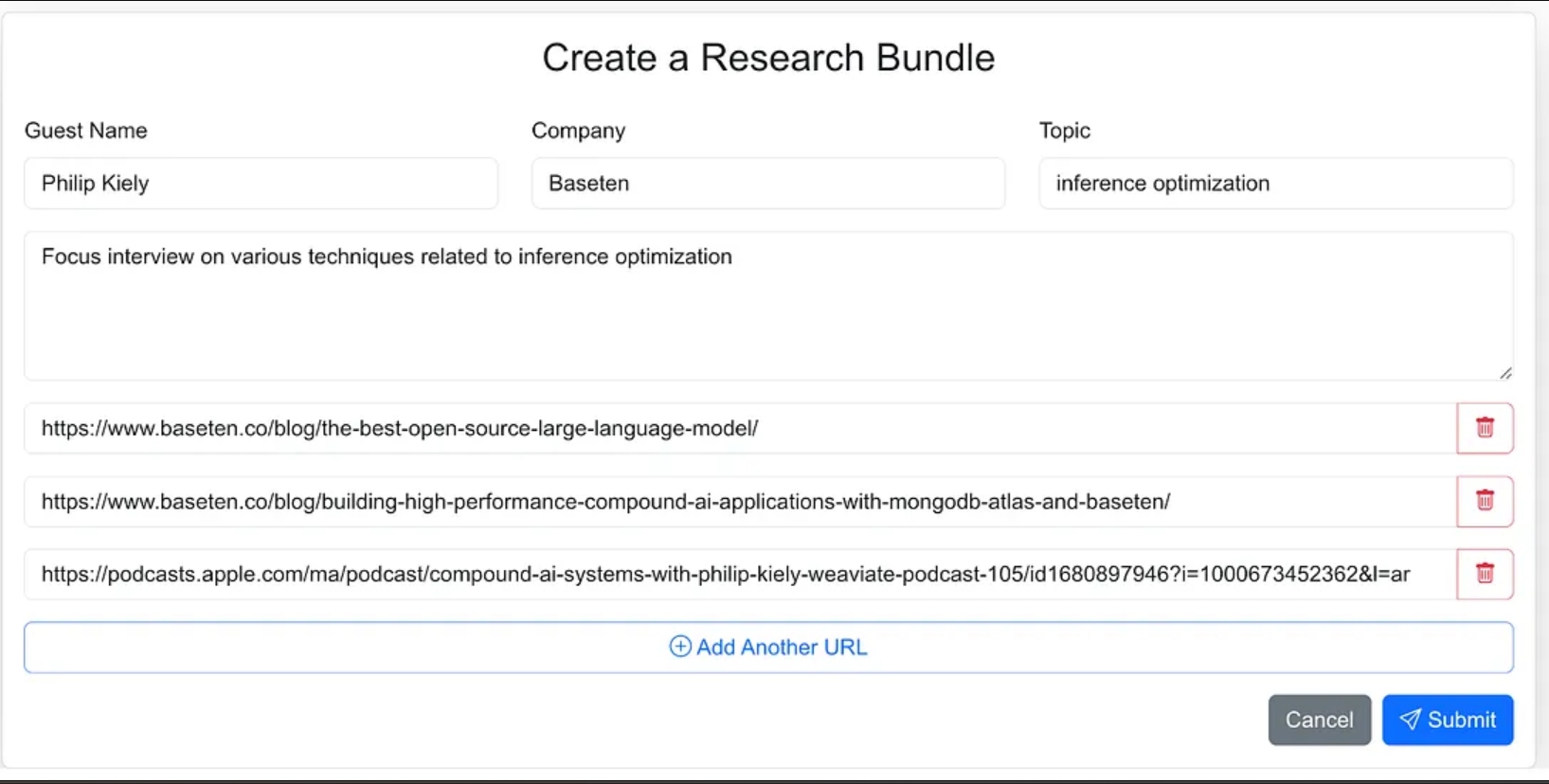
Ik had de agent minder richting kunnen geven en als onderdeel van de agentworkflow het de bronmaterialen laten vinden, maar voor versie 1.0 besloot ik de bron-URL’s te verstrekken.
De webapplicatie is een standaard driedelige app gebouwd met Next.js en MongoDB als de applicatiedatabase. Het weet niets van AI. Het stelt de gebruiker eenvoudig in staat om nieuwe onderzoeksbundels in te voeren en deze verschijnen in een verwerkingsstatus totdat het agentische proces de workflow heeft voltooid en een onderzoeksbrief in de applicatiedatabase heeft ingevuld.
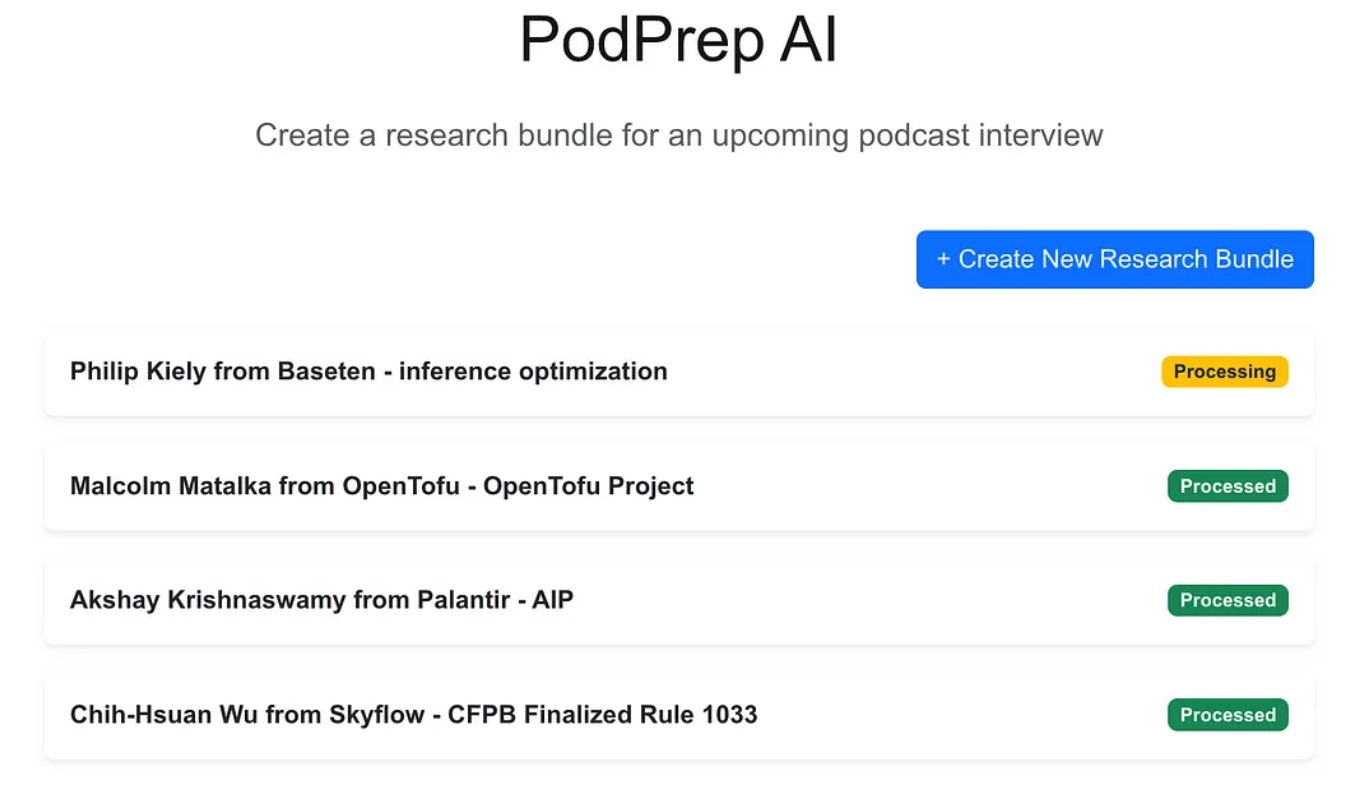
Zodra de AI-magie compleet is, kan ik een briefingdocument voor de invoer openen zoals hieronder weergegeven.

Het creëren van de agentische workflow
Voor versie 1.0 wilde ik in staat zijn om drie primaire acties uit te voeren om de onderzoeksbrief op te bouwen:
- Voor elke website-URL, blogpost of podcast, de tekst of samenvatting ophalen, de tekst in redelijke formaten splitsen, embeddings genereren en de vectorrepresentatie opslaan.
- Voor alle tekst die is geëxtraheerd uit de onderzoeksbron-URL’s, de meest interessante vragen eruit halen en deze opslaan.
- Een podcast-onderzoeksbrief genereren die de meest relevante context combineert op basis van de embeddings, de beste eerder gestelde vragen en alle andere informatie die deel uitmaakte van de bundelinvoer.
De afbeelding hieronder toont de architectuur van de webapplicatie naar de agentische workflow.
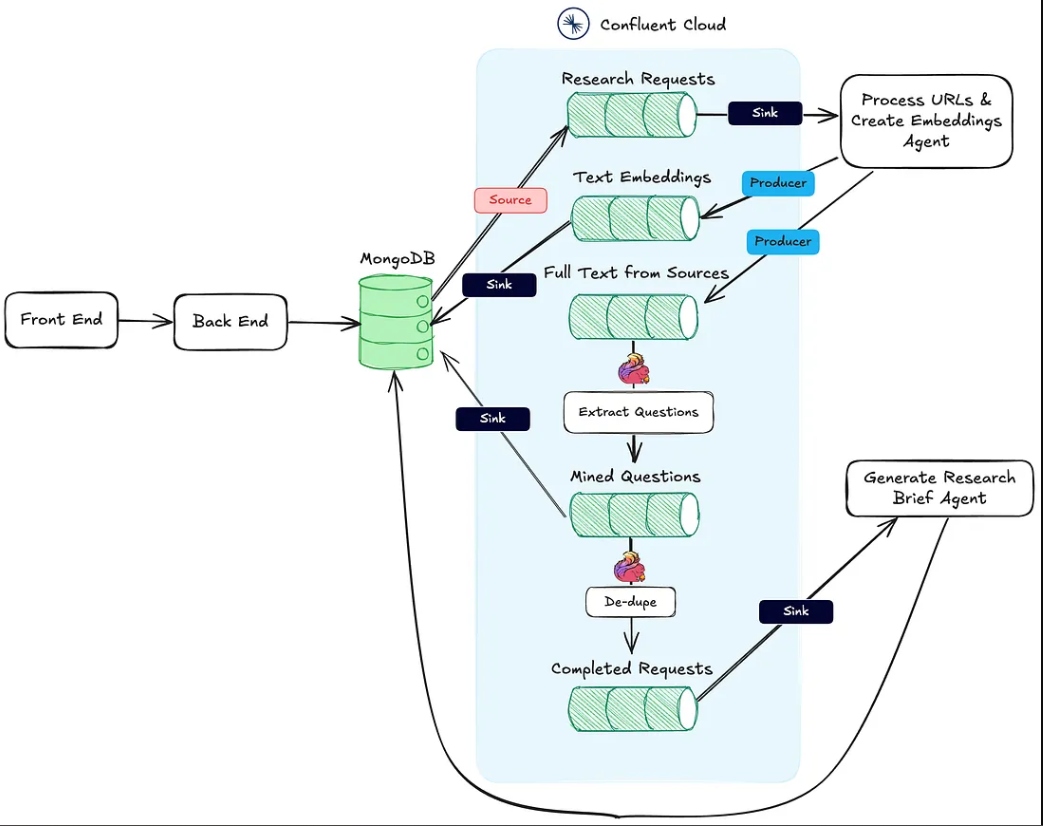
Actie #1 van hierboven wordt ondersteund door de Process URLs & Create Embeddings Agent HTTP sink-eindpunt.
Actie #2 wordt uitgevoerd met behulp van Flink en de ingebouwde AI-modelondersteuning in Confluent Cloud.
Ten slotte wordt Actie #3 uitgevoerd door de Generate Research Brief Agent, ook een HTTP-sink endpoint, dat wordt aangeroepen zodra de eerste twee acties zijn voltooid.
In de volgende secties bespreek ik elk van deze acties in detail.
De Process URLs en Create Embeddings Agent
Deze agent is verantwoordelijk voor het ophalen van tekst van de onderzoeksbron-URL’s en de vector embedding-pijplijn. Hieronder staat de high-level flow van wat er achter de schermen gebeurt om het onderzoeks materiaal te verwerken.

Wanneer een onderzoeksbundel door de gebruiker is gemaakt en is opgeslagen in MongoDB, produceert een MongoDB-bronconnector berichten naar een Kafka-topic genaamd research-requests. Dit is wat de agentische workflow start.
Elke postaanroep naar het HTTP-endpoint bevat de URL’s van het onderzoeksverzoek en de primaire sleutel in de MongoDB-collectie van onderzoeksbundels.
De agent doorloopt elke URL en als het geen Apple-podcast is, haalt hij de volledige HTML-pagina op. Aangezien ik de structuur van de pagina niet ken, kan ik niet vertrouwen op HTML-parserbibliotheken om de relevante tekst te vinden. In plaats daarvan stuur ik de paginatekst naar het gpt-4o-mini model met een temperatuur van nul, met behulp van de onderstaande prompt om te krijgen wat ik nodig heb.
`Here is the content of a webpage:
${text}
Instructions:
- If there is a blog post within this content, extract and return the main text of the blog post.
- If there is no blog post, summarize the most important information on the page.`
Voor podcasts moet ik wat meer werk verzetten.
Reverse Engineering Apple Podcast URLs
Om gegevens uit podcastafleveringen te halen, moeten we eerst de audio omzetten in tekst met behulp van het Whisper-model. Maar voordat we dat kunnen doen, moeten we het daadwerkelijke MP3-bestand voor elke podcastaflevering vinden, het downloaden en splitsen in stukken van 25 MB of minder (de maximale grootte voor Whisper).
Het probleem is dat Apple geen directe MP3-link levert voor zijn podcastafleveringen. De MP3-bestand is echter beschikbaar in de oorspronkelijke RSS-feed van de podcast, en we kunnen deze feed programmatisch vinden met behulp van de Apple podcast-ID.
Bijvoorbeeld, in de onderstaande URL, is het numerieke deel na /id de unieke Apple ID van de podcast:
https://podcasts.apple.com/us/podcast/deep-dive-into-inference-optimization-for-llms-with/id1699385780?i=1000675820505
Met behulp van de Apple API kunnen we de podcast-ID opzoeken en een JSON-respons ophalen met de URL voor de RSS-feed:
https://itunes.apple.com/lookup?id=1699385780&entity=podcast
Zodra we de RSS-feed XML hebben, doorzoeken we deze om de specifieke aflevering te vinden. Aangezien we alleen de afleverings-URL van Apple hebben (en niet de werkelijke titel), gebruiken we de titelslug van de URL om de aflevering binnen de feed te lokaliseren en de MP3-URL op te halen.
async function getMp3DownloadUrl(url) {
let podcastId = extractPodcastId(url);
let titleToMatch = extractAndFormatTitle(url);
if (podcastId) {
let feedLookupUrl = `https://itunes.apple.com/lookup?id=${podcastId}&entity=podcast`;
const itunesResponse = await axios.get(feedLookupUrl);
const itunesData = itunesResponse.data;
// Check if results were returned
if (itunesData.resultCount === 0 || !itunesData.results[0].feedUrl) {
console.error("No feed URL found for this podcast ID.");
return;
}
// Extract the feed URL
const feedUrl = itunesData.results[0].feedUrl;
// Fetch the document from the feed URL
const feedResponse = await axios.get(feedUrl);
const rssContent = feedResponse.data;
// Parse the RSS feed XML
const rssData = await parseStringPromise(rssContent);
const episodes = rssData.rss.channel[0].item; // Access all items (episodes) in the feed
// Find the matching episode by title, have to transform title to match the URL-based title
const matchingEpisode = episodes.find(episode => {
return getSlug(episode.title[0]).includes(titleToMatch);
}
);
if (!matchingEpisode) {
console.log(`No episode found with title containing "${titleToMatch}"`);
return false;
}
// Extract the MP3 URL from the enclosure tag
return matchingEpisode.enclosure[0].$.url;
}
return false;
}
Met de tekst uit blogposts, websites en MP3-bestanden die beschikbaar zijn, gebruikt de agent LangChain’s recursieve tekstsplitsing van karakters om de tekst op te delen in brokken en de embeddings van deze brokken te genereren. De brokken worden gepubliceerd naar het onderwerp text-embeddings en naar MongoDB geleid.
- Opmerking: Ik heb ervoor gekozen om MongoDB te gebruiken als zowel mijn applicatiedatabase als vector database. Echter, vanwege de EDA-benadering die ik heb gekozen, kunnen dit gemakkelijk afzonderlijke systemen zijn, en het is slechts een kwestie van het omwisselen van de sink-connector van de Text Embeddings-onderwerp.
Naast het creëren en publiceren van de embeddings, publiceert de agent ook de tekst van de bronnen naar een onderwerp genaamd full-text-from-sources. Publiceren naar dit onderwerp start Actie #2.
Vragen Extractie Met Flink en OpenAI
Apache Flink is een open-source stream processing framework dat is gebouwd om grote hoeveelheden data in real-time te verwerken, ideaal voor toepassingen met hoge doorvoer en lage latentie. Door Flink te combineren met Confluent, kunnen we LLM’s zoals OpenAI’s GPT direct in streaming workflows integreren. Deze integratie maakt real-time RAG workflows mogelijk, waardoor het vraagextractieproces werkt met de meest actuele beschikbare data.
Het hebben van de oorspronkelijke brontekst in de stream stelt ons ook in staat om later nieuwe workflows in te voeren die dezelfde data gebruiken, wat het proces van het genereren van onderzoeksbriefingen verbetert of het doorsturen naar downstream-diensten zoals een datawarehouse. Deze flexibele opzet stelt ons in staat om in de loop van de tijd extra AI- en niet-AI-functies toe te voegen zonder de kernpipeline opnieuw te hoeven ontwerpen.
In PodPrep AI gebruik ik Flink om vragen te extraheren uit tekst die van bron-URL’s is gehaald.
Het opzetten van Flink om een LLM aan te roepen, omvat het configureren van een verbinding via de CLI van Confluent. Hieronder staat een voorbeeldcommando voor het opzetten van een OpenAI-verbinding, hoewel er meerdere opties beschikbaar zijn.
confluent flink connection create openai-connection \
--cloud aws \
--region us-east-1 \
--type openai \
--endpoint https://api.openai.com/v1/chat/completions \
--api-key <REPLACE_WITH_OPEN_AI_KEY>
Zodra de verbinding is tot stand gebracht, kan ik een model aanmaken in zowel de Cloud Console als de Flink SQL-shell. Voor de extractie van vragen stel ik het model dienovereenkomstig in.
-- Creates model for pulling questions from research source material
CREATE MODEL `question_generation`
INPUT (text STRING)
OUTPUT (response STRING)
WITH (
'openai.connection'='openai-connection',
'provider'='openai',
'task'='text_generation',
'openai.model_version' = 'gpt-3.5-turbo',
'openai.system_prompt' = 'Extract the most interesting questions asked from the text. Paraphrase the questions and seperate each one by a blank line. Do not number the questions.'
);
Met het model klaar gebruik ik de ingebouwde ml_predict functie van Flink om vragen te genereren uit het bronmateriaal, waarbij de output naar een stream genaamd mined-questions wordt geschreven, die synchroniseert met MongoDB voor later gebruik.
-- Generates questions based on text pulled from research source material
INSERT INTO `mined-questions`
SELECT
`key`,
`bundleId`,
`url`,
q.response AS questions
FROM
`full-text-from-sources`,
LATERAL TABLE (
ml_predict('question_generation', content)
) AS q;
Flink helpt ook bij het bijhouden wanneer al het onderzoeks materiaal is verwerkt, wat de generatie van het onderzoeksrapport activeert. Dit gebeurt door te schrijven naar een completed-requests stream zodra de URL’s in mined-questions overeenkomen met die in de full-text bronnen stream.
-- Writes the bundleId to the complete topic once all questions have been created
INSERT INTO `completed-requests`
SELECT '' AS id, pmq.bundleId
FROM (
SELECT bundleId, COUNT(url) AS url_count_mined
FROM `mined-questions`
GROUP BY bundleId
) AS pmq
JOIN (
SELECT bundleId, COUNT(url) AS url_count_full
FROM `full-text-from-sources`
GROUP BY bundleId
) AS pft
ON pmq.bundleId = pft.bundleId
WHERE pmq.url_count_mined = pft.url_count_full;
Als berichten worden geschreven naar completed-requests, wordt de unieke ID voor het onderzoeksbundel verzonden naar de Genereer Onderzoeksrapport Agent.
De Genereer Onderzoeksrapport Agent
Deze agent neemt al het meest relevante onderzoeks materiaal dat beschikbaar is en gebruikt een LLM om een onderzoeksrapport te creëren. Hieronder staat de hoge-lijn stroom van gebeurtenissen die plaatsvinden om een onderzoeksrapport te creëren.

Stroomschema voor de Genereer Onderzoeksrapport agent
Laten we een paar van deze stappen ontleden. Om de prompt voor de LLM samen te stellen, combineer ik de geminede vragen, onderwerp, naam van de gast, naam van het bedrijf, een systeemprompt voor begeleiding, en de context die is opgeslagen in de vector database die het meest semantisch vergelijkbaar is met het podcast onderwerp.
Omdat het onderzoeksbundel beperkte contextuele informatie heeft, is het een uitdaging om de meest relevante context direct uit de vectoropslag te halen. Om dit aan te pakken, laat ik de LLM een zoekopdracht genereren om de best passende inhoud te vinden, zoals weergegeven in de “Create Search Query” node in het diagram.
async function getSearchString(researchBundle) {
const userPrompt = `
Guest:
${researchBundle.guestName}
Company:
${researchBundle.company}
Topic:
${researchBundle.topic}
Context:
${researchBundle.context}
Create a natural language search query given the data available.
`;
const systemPrompt = `You are an expert in research for an engineering podcast. Using the
guest name, company, topic, and context, create the best possible query to search a vector
database for relevant data mined from blog posts and existing podcasts.`;
const messages = [
new SystemMessage(systemPrompt),
new HumanMessage(userPrompt),
];
const response = await model.invoke(messages);
return response.content;
}
Met de door de LLM gegenereerde zoekopdracht maak ik een embedding en zoek ik in MongoDB via een vectorindex, waarbij ik filter op de bundleId om de zoekopdracht te beperken tot materialen die relevant zijn voor de specifieke podcast.
Met de beste contextinformatie geïdentificeerd, bouw ik een prompt en genereer ik het onderzoeksrapport, waarbij ik het resultaat opsla in MongoDB zodat de webapplicatie dit kan weergeven.
Dingen om op te letten bij de implementatie
Ik heb zowel de front-end applicatie voor PodPrep AI als de agents in Javascript geschreven, maar in een echte situatie zou de agent waarschijnlijk in een andere taal zoals Python zijn. Bovendien, ter vereenvoudiging, bevinden zowel de Process URLs & Create Embeddings Agent als Generate Research Brief Agent zich binnen hetzelfde project dat op dezelfde webserver draait. In een echt productiesysteem zouden deze serverless functies kunnen zijn, die onafhankelijk draaien.
Eindgedachten
Het bouwen van PodPrep AI benadrukt hoe een gebeurtenisgestuurde architectuur echte AI-toepassingen in staat stelt om soepel op te schalen en zich aan te passen. Met Flink en Confluent heb ik een systeem gecreëerd dat gegevens in real-time verwerkt en een AI-gedreven workflow aandrijft zonder rigide afhankelijkheden. Deze ontkoppelde benadering stelt componenten in staat om onafhankelijk te opereren, maar toch verbonden te blijven via gebeurtenisstromen – essentieel voor complexe, gedistribueerde applicaties waarbij verschillende teams verschillende delen van de stack beheren.
In de huidige AI-gedreven omgeving is het essentieel om toegang te hebben tot verse, real-time gegevens over systemen heen. EDA fungeert als een “centraal zenuwstelsel” voor gegevens, waardoor naadloze integratie en flexibiliteit mogelijk zijn naarmate het systeem opschaalt.
Source:
https://dzone.com/articles/build-a-research-assistant-with-kafka-flink