













Elke door data aangedreven organisatie heeft operationele en analytische workloads. Een best-of-breed benadering ontstaat met verschillende dataplatforms, waaronder datastreaming, data lake, data warehouse en lakehouse-oplossingen, en clouddiensten. Een open tabelindelingskader zoals Apache Iceberg is essentieel in de bedrijfsarchitectuur om betrouwbare gegevensbeheer en -deling te garanderen, naadloze schema-evolutie, efficiënte verwerking van grootschalige datasets en kostenefficiënte opslag, terwijl sterke ondersteuning wordt geboden voor ACID-transacties en tijdreisquery’s.
Dit artikel onderzoekt markttrends; de adoptie van tabelindelingskaders zoals Iceberg, Hudi, Paimon, Delta Lake en XTable; en de productstrategie van enkele van de toonaangevende leveranciers van dataplatforms zoals Snowflake, Databricks (Apache Spark), Confluent (Apache Kafka/Flink), Amazon Athena en Google BigQuery.
Wat is een open tabelindeling voor een dataplatform?
Een open tabelindeling helpt bij het behouden van gegevensintegriteit, het optimaliseren van queryprestaties en het garanderen van een duidelijk begrip van de gegevens die binnen het platform zijn opgeslagen.
De open tabelindeling voor dataplatforms omvat doorgaans een goed gedefinieerde structuur met specifieke componenten die ervoor zorgen dat gegevens georganiseerd, toegankelijk en gemakkelijk opvraagbaar zijn. Een typische tabelindeling bevat een tabelnaam, kolomnamen, gegevenstypen, primaire en vreemde sleutels, indexen en beperkingen.
Dit is geen nieuw concept. Jouw favoriete tientallen jaren oude database — zoals Oracle, IBM DB2 (zelfs op de mainframe) of PostgreSQL — maakt gebruik van dezelfde principes. Echter, de vereisten en uitdagingen zijn een beetje veranderd voor cloud data warehouses, data lakes en lakehouses met betrekking tot schaalbaarheid, prestaties en query-mogelijkheden.
Voordelen van een “Lakehouse Table Format” zoals Apache Iceberg
Iedereen binnen een organisatie wordt data-gedreven. Het gevolg is uitgebreide datasets, gegevensdeling met data producten over verschillende bedrijfsunits en nieuwe vereisten voor het verwerken van data bijna in real-time.
Apache Iceberg biedt veel voordelen voor enterprise architecture:
- Enkele opslag: Data wordt één keer opgeslagen (komend van verschillende gegevensbronnen), wat de kosten en complexiteit vermindert
- Interoperabiliteit: Toegang zonder integratie-inspanningen vanuit elke analytische engine
- Alle data: Verenig operationele en analytische workloads (transactiesystemen, big data logs/IoT/clickstream, mobiele APIs, third-party B2B interfaces, etc.)
- Leverancieronafhankelijkheid: Werk met elke favoriete analytische engine (ongeacht of het gaat om near real-time, batch of API-gebaseerd)
Apache Hudi en Delta Lake bieden dezelfde kenmerken. Hoewel, Delta Lake wordt voornamelijk gedreven door Databricks als een enkele leverancier.
Table Format en Catalog Interface
Het is belangrijk om te begrijpen dat discussies over Apache Iceberg of vergelijkbare tabelformaat frameworks twee concepten omvatten: tabelformaat en catalogusinterface! Als eindgebruiker van de technologie hebt u beide nodig!
Het Apache Iceberg-project implementeert het formaat, maar leveren ze alleen een specificatie (maar geen implementatie) voor de catalogus:
- De tabelformaat definieert hoe gegevens zijn georganiseerd, opgeslagen en beheerd binnen een tabel.
- De catalogusinterface beheert de metadata voor tabellen en biedt een abstraktieniveau voor het toegankelijk maken van tabellen in een data lake.
De Apache Iceberg documentatie verkent de concepten veel gedetailleerder, gebaseerd op deze afbeelding:
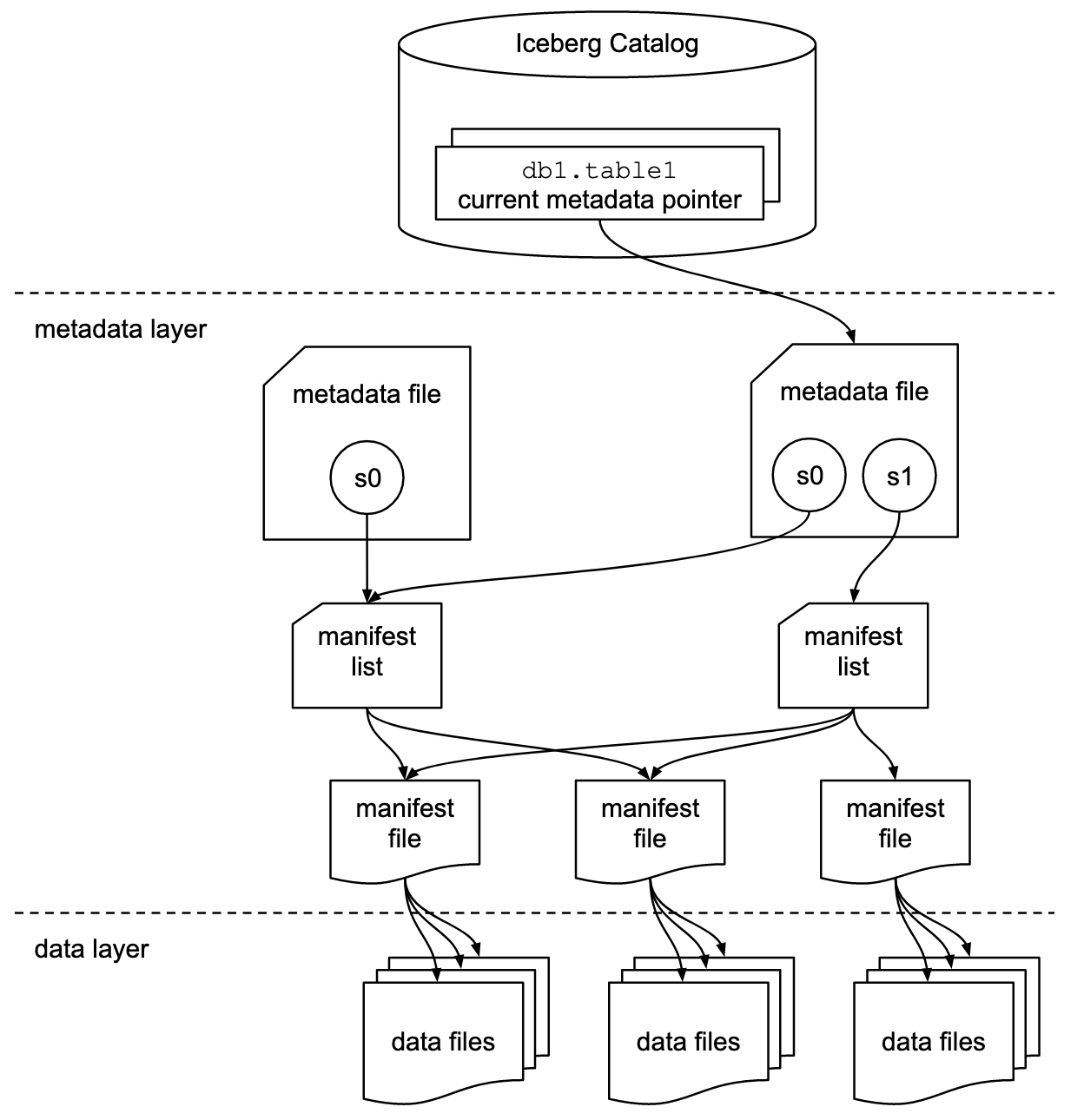
Organisaties gebruiken verschillende implementaties voor Iceberg’s catalogusinterface. Elk integreert met verschillende metadata stores en services. Belangrijke implementaties zijn:
- Hadoop catalogus: Gebruikt het Hadoop Distributed File System (HDFS) of andere compatible bestandssystemen om metadata op te slaan. Geschikt voor omgevingen die al Hadoop gebruiken.
- Hive catalogus: Integreert met de Apache Hive Metastore om tabelmetadata te beheren. Ideaal voor gebruikers die Hive gebruiken voor hun metadatabeheer.
- AWS Glue catalogus: Gebruikt AWS Glue Data Catalog voor metadata-opslag. Ontworpen voor gebruikers die binnen het AWS-ecosysteem werken.
- REST-catalogus: Biedt een RESTful interface voor catalogusoperaties via HTTP. Maakt integratie mogelijk met aangepaste of externe metadata-diensten.
- Nessie catalogus: Gebruikt Project Nessie, dat een Git-achtige ervaring biedt voor het beheren van gegevens.
De opmars en groeiende acceptatie van Apache Iceberg motiveert veel gegevensplatformleveranciers om hun eigen Iceberg-catalogus te implementeren. Ik bespreek enkele strategieën in het onderstaande gedeelte over gegevensplatform- en cloudleveranciersstrategieën, waaronder Snowflake’s Polaris, Databricks’ Unity en Confluent’s Tableflow.
Eerste klas Iceberg-ondersteuning vs. Iceberg-connector
Let op dat het ondersteunen van Apache Iceberg (of Hudi/Delta Lake) veel meer inhoudt dan alleen het bieden van een connector en integratie met het tabelformaat via API. Leveranciers en cloudservices onderscheiden zich door geavanceerde functies zoals automatische mapping tussen gegevensformaten, cruciale SLA’s, terugreizen in de tijd, intuïtieve gebruikersinterfaces enzovoort.
Laten we naar een voorbeeld kijken: Integratie tussen Apache Kafka en Iceberg. Verschillende Kafka Connect connectors zijn al geïmplementeerd. Echter, hier zijn de voordelen van het gebruik van een eerste klas integratie met Iceberg (bijvoorbeeld Confluent’s Tableflow) in vergelijking met het gebruik van een Kafka Connect connector:
- Geen connector-configuratie
- Geen consumptie via connector
- Ingebouwde onderhoud (compactie, vuilverwijdering, snapshotbeheer)
- Automatische schemawijziging
- Synchronisatie van externe catalogusdienst
- Eenvoudigere operaties (in een volledig beheerde SaaS-oplossing is het serverloos en is er geen behoefte aan schalen of operaties door de eindgebruiker)
Soortgelijke voordelen zijn van toepassing op andere gegevensplatforms en potentiële first-class integratie in vergelijking met het bieden van eenvoudige connectors.
Open Table Format voor een Data Lake/Lakehouse met behulp van Apache Iceberg, Apache Hudi en Delta Lake
Het algemene doel van tabelformaat frameworks zoals Apache Iceberg, Apache Hudi en Delta Lake is om de functionaliteit en betrouwbaarheid van data lakes te verbeteren door zich te richten op veelvoorkomende uitdagingen die gepaard gaan met het beheren van grootschalige gegevens. Deze frameworks helpen om:
- De gegevensbeheer te verbeteren
- Om het gemakkelijker te maken om met gegevensinvoer, opslag en ophalen in data lakes om te gaan.
- Om efficiënte gegevensorganisatie en opslag te ondersteunen, die betere prestaties en schaalbaarheid mogelijk maken.
- De gegevensconsistentie waarborgen
- Om mechanismen te bieden voor ACID-transacties, die ervoor zorgen dat gegevens consistent en betrouwbaar blijven, zelfs tijdens gelijktijdige lees- en schrijfoperaties.
- Om snapshot isolatie te ondersteunen, die gebruikers in staat stelt om een consistente gegevensstatus op elk moment in de tijd te bekijken.
- Ondersteun schema evolutie
- Sta toe dat er wijzigingen worden aangebracht in de gegevensschema’s (zoals het toevoegen, hernoemen of verwijderen van kolommen) zonder de bestaande gegevens te verstoren of complexe migraties te vereisen.
- Optimaliseer query prestaties
- Implementeer geavanceerde indexering- en partitioneringsstrategieën om de snelheid en efficiëntie van gegevensqueries te verbeteren.
- Faciliteer efficiënt metadata beheer om grote gegevenssets en complexe queries effectief te behandelen.
- Verbeter gegevensbeheer
- Bied hulpmiddelen om beter de gegevenslijn, versiebeheer en auditing te volgen en beheren, wat cruciaal is voor het handhaven van gegevenskwaliteit en naleving.
Door deze doelen aan te pakken, helpen tabelformaatframes zoals Apache Iceberg, Apache Hudi en Delta Lake organisaties om robuustere, schaalbare en betrouwbare datalakes en lakehouses te bouwen. Data-engineers, data-scientists en bedrijfsanalisten maken gebruik van analysetools, AI/ML, of rapportage/visualisatietools bovenop het tabelformaat om grote hoeveelheden data te beheren en te analyseren.
Vergelijking van Apache Iceberg, Hudi, Paimon en Delta Lake
Ik zal hier geen vergelijking maken van de tabelformaatframes Apache Iceberg, Apache Hudi, Apache Paimon en Delta Lake. Veel experts hebben hier al over geschreven. Elk tabelformaatframe heeft unieke sterke punten en voordelen. Maar updates zijn elke maand vereist vanwege de snelle evolutie en innovatie, die nieuwe verbeteringen en mogelijkheden toevoegen binnen deze frameworks.
Hier is een samenvatting van wat ik zie in verschillende blogposts over de vier opties:
- Apache Iceberg: Schittert in schema- en partitie-evolutie, efficiënt metadata-beheer en brede compatibiliteit met verschillende databehandelingssystemen.
- Apache Hudi: Het beste geschikt voor real-time data-ingestie en upserts, met sterke change data capture-mogelijkheden en gegevensversiebeheer.
- Apache Paimon: Een meer formalism dat een real-time lakehouse-architectuur mogelijk maakt met Flink en Spark voor zowel streaming als batchoperaties.
- Delta Lake: Biedt robuuste ACID-transacties, schema-afhandeling en tijdsreismogelijkheden, waardoor het ideaal is voor het handhaven van gegevenskwaliteit en integriteit.
Een belangrijk beslispunt kan zijn dat Delta Lake niet wordt aangedreven door een brede gemeenschap zoals Iceberg en Hudi, maar voornamelijk door Databricks als een enkele leverancier erachter.
Apache XTable als Interoperabel Cross-Table Framework Ondersteunend Iceberg, Hudi en Delta Lake
Gebruikers hebben veel keuzes. XTable, voorheen bekend als OneTable, is nog een incubeerende tabelamework onder de Apache opensource-licentie om naadloos cross-table interoperabiliteit te bieden tussen Apache Hudi, Delta Lake en Apache Iceberg.
Apache XTable:
- Biedt cross-table omnidirectionele interoperabiliteit tussen lakehouse tabelformaten.
- Is geen nieuwe of aparte format. Apache XTable biedt abstracties en hulpmiddelen voor de vertaling van lakehouse tabelformat metadata.
Misschien is Apache XTable het antwoord om opties te bieden voor specifieke dataplatforms en cloudleveranciers, terwijl toch eenvoudige integratie en interoperabiliteit wordt geboden.
Maar wees voorzichtig: Een wrapper bovenop verschillende technologieën is geen zilveren kogel. We hebben dit jaren geleden gezien toen Apache Beam opkwam. Apache Beam is een open-source, unified model en一套针对特定语言的 SDK,用于定义和执行数据摄取及数据处理工作流程。它支持多种流处理引擎,如 Flink, Spark en Samza. De belangrijkste drijfveer achter Apache Beam is Google, die migratieworkflows in Google Cloud Dataflow mogelijk maakt. Echter, de beperkingen zijn aanzienlijk, omdat zo’n wrapper de grootste gemene deler van ondersteunde functies moet vinden. En het belangrijkste voordeel van de meeste frameworks is het 20% dat niks past in zo’n wrapper. Om deze redenen, bijvoorbeeld, ondersteunt Kafka Streams met opzet niet Apache Beam, omdat het te veel ontwerpbeperkingen zou hebben vereist.
Marktacceptatie van Tabelformaat Frameworks
Eerst en vooral, we zijn nog steeds in de vroege stadia. We bevinden ons nog steeds in de innovatietrigger in termen van de Gartner Hype Cycle, aan het komen bij de piek van opgeblazen verwachtingen. De meeste organisaties zijn nog steeds aan het evalueren, maar hebben deze tabelformaten nog niet in productie geïmplementeerd over de hele organisatie.
Terugblik: De Container Oorlogen van Kubernetes tegen Mesosphere tegen Cloud Foundry
De discussie rond Apache Iceberg herinnert me aan de containeroorlogen een paar jaar geleden. De term “Container Oorlogen” verwijst naar de concurrentie en rivaliteit tussen verschillende containeriseringstechnologieën en platforms in het domein van softwareontwikkeling en IT-infrastructuur.
De drie concurrerende technologieën waren Kubernetes, Mesosphere en Cloud Foundry. Hier is waar het naartoe ging:

Cloud Foundry en Mesosphere waren vroeg, maar Kubernetes won toch de strijd. Waarom? Ik heb nooit alle technische details en verschillen begrepen. Uiteindelijk, als de drie frameworkspretty vergelijkbaar zijn, dan gaat het allemaal om:
- Community adoptie
- Juiste timing van functiereleases
- Goede marketing
- Luck
- En een paar andere factoren
Maar het is goed voor de software-industrie om één leidend open-source framework te hebben om oplossingen en bedrijfsmodellen op te bouwen in plaats van drie concurrerende.
Actueel: De Table Format Wars van Apache Iceberg vs. Hudi vs. Delta Lake
Google Trends is natuurlijk geen statistisch bewijs of geavanceerd onderzoek. Maar ik heb het in het verleden veel gebruikt als een intuïtieve, eenvoudige, gratis tool om markttrends te analyseren. Daarom heb ik deze tool ook gebruikt om te zien of Google-zoekopdrachten overeenkomen met mijn persoonlijke ervaring van de marktaanname van Apache Iceberg, Hudi en Delta Lake (Apache XTable is nog te klein om toegevoegd te worden):
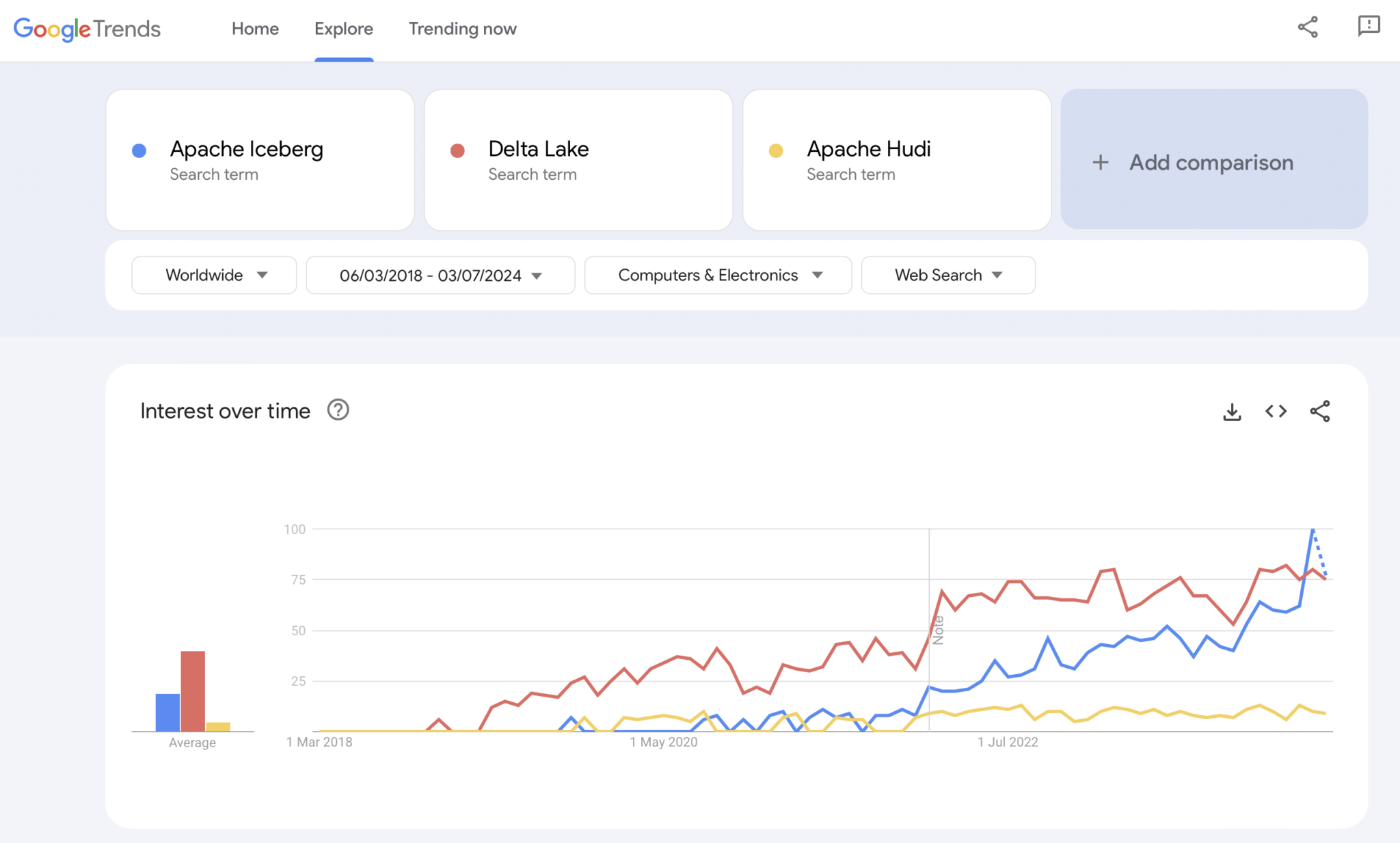
We zien duidelijk een vergelijkbaar patroon als de containeroorlogen enkele jaren geleden lieten zien. Ik heb geen idee waar dit naartoe gaat. En of één technologie wint, of de frameworks genoeg onderscheiden om te bewijzen dat er geen zilveren kogel is, de toekomst zal het ons laten zien.
Mijn persoonlijke mening? Ik denk dat Apache Iceberg de race zal winnen. Waarom? Ik kan geen technische redenen aanvoeren. Ik zie gewoon dat steeds meer klanten in alle sectoren erover praten. En steeds meer leveranciers beginnen het te ondersteunen. Maar we zullen zien. Eigenlijk kan het me niet schelen wie er wint. Echter, net als bij de containeroorlogen, denk ik dat het goed is om een enkele standaard te hebben, waarbij leveranciers zich onderscheiden met functies eromheen, zoals bij Kubernetes.
Maar met dit in gedachten, laten we de huidige strategie van de toonaangevende dataplatforms en cloudproviders onderzoeken met betrekking tot tabelformaatondersteuning in hun platforms en clouddiensten.
Strategieën van Dataplatforms en Cloudleveranciers voor Apache Iceberg
Ik ga in dit gedeelte geen speculaties doen. De evolutie van de tabelformaatkaders beweegt snel, en leveranciersstrategieën veranderen snel. Raadpleeg de websites van de leveranciers voor de meest recente informatie. Maar hier is de status quo over de strategieën van dataplatforms en cloudleveranciers met betrekking tot de ondersteuning en integratie van Apache Iceberg.
- Snowflake:
- Ondersteunt Apache Iceberg al geruime tijd
- Regelmatig betere integraties en nieuwe functies toevoegen
- Interne en externe opslagopties (met afwegingen) zoals Snowflake’s opslag of Amazon S3
- Aangekondigd Polaris, een open-source catalogusimplementatie voor Iceberg, met de toezegging om community-gedreven, leverancier-onafhankelijke bi-directionele integratie te ondersteunen
- Databricks:
- Richt zich op Delta Lake als tabelformaat en (nu open source) Unity als catalogus
- Overnam Tabular, het leidende bedrijf achter Apache Iceberg
- Onduidelijke toekomststrategie voor ondersteuning van de open Iceberg-interface (in beide richtingen) of alleen om data te voeden naar zijn lakehouse-platform en technologieën zoals Delta Lake en Unity Catalog
- Confluent:
- Integreert Apache Iceberg als een first-class citizen in zijn data streaming platform (het product heet Tableflow)
- Converteert een Kafka Topic en gerelateerde schemametadaten (dus, gegevenscontract) naar een Iceberg-tabel
- Tweezijdige integratie tussen operationele en analytische workloads
- Analytics met ingesloten serverless Flink en zijn unified batch en streaming API of gegevensdeling met derde partijen analysemotoren zoals Snowflake, Databricks, of Amazon Athena
- Meer gegevensplatforms en open-source analytics engines:
- De lijst van technologieën en cloudservices die Iceberg ondersteunen groeit elke maand
- Enkele voorbeelden: Apache Spark, Apache Flink, ClickHouse, Dremio, Starburst met Trino (voorheen PrestoSQL), Cloudera met Impala, Imply met Apache Druid, Fivetran
- Cloudserviceproviders (AWS, Azure, Google Cloud, Alibaba):
- verschillende strategieën en integraties, maar alle cloudproviders vergroten hun ondersteuning voor Iceberg over hun services deze dagen, bijvoorbeeld:
- Object Storage: Amazon S3, Azure Data Lake Storage (ALDS), Google Cloud Storage
- Catalogi: Cloudspecifiek zoals AWS Glue Catalog of leverancieronafhankelijk zoals Project Nessie of Hive Catalog
- Analytics: Amazon Athena, Azure Synapse Analytics, Microsoft Fabric, Google BigQuery
- verschillende strategieën en integraties, maar alle cloudproviders vergroten hun ondersteuning voor Iceberg over hun services deze dagen, bijvoorbeeld:
Shift Left Architecture With Kafka, Flink, and Iceberg to Unify Operational and Analytical Workloads
De shift left architecture verplaatst gegevensverwerking dichter bij de gegevensbron, door gebruik te maken van real-time gegevensstreamingtechnologieën zoals Apache Kafka en Flink om gegevens direct na de ingang te verwerken. Deze aanpak vermindert latentie en verbetert gegevensconsistentie en gegevenskwaliteit.
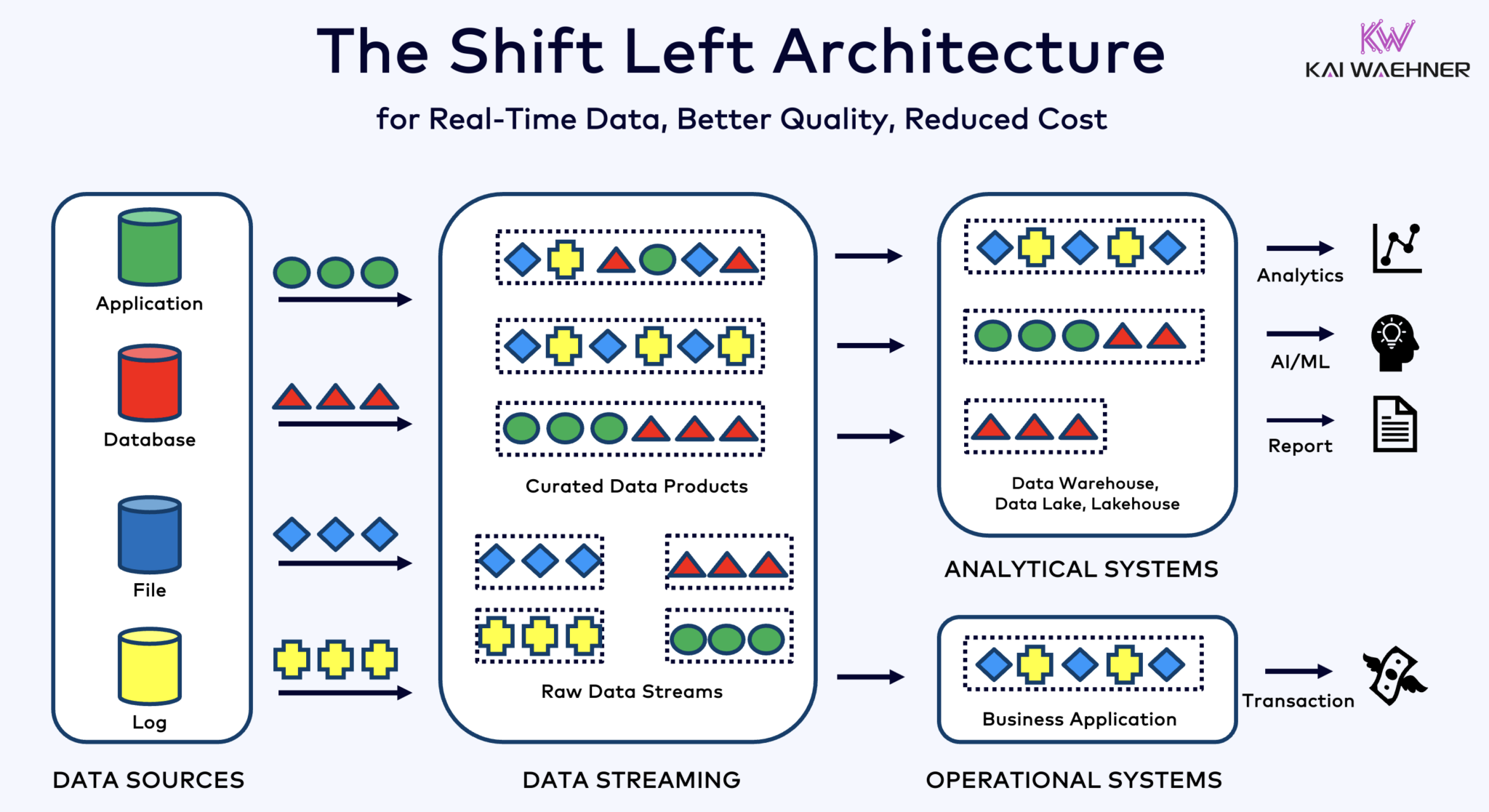
In tegenstelling tot ETL en ELT, die batchverwerking met rustende gegevens betreffen, stelt de shift left-architectuur real-time gegevensvangst en transformatie mogelijk. Het past in het zero-ETL-concept door gegevens onmiddellijk bruikbaar te maken. Maar in tegenstelling tot zero-ETL, voorkomt het verplaatsen van gegevensverwerking naar de linkerkant van de enterprise-architectuur een complexe, moeilijk te onderhouden spaghetti-architectuur met veel punt-naar-punt-verbindingen.
Shift left-architectuur vermindert ook de noodzaak voor reverse ETL door ervoor te zorgen dat data direct bruikbaar is in real-time voor zowel operationele als analytische systemen. Over het algemeen verbetert deze architectuur de actualiteit van data, verlaagt kosten en versnelt de time-to-market voor datagedreven toepassingen. Lees meer over dit concept in mijn blogpost over “De Shift Left Architectuur.”
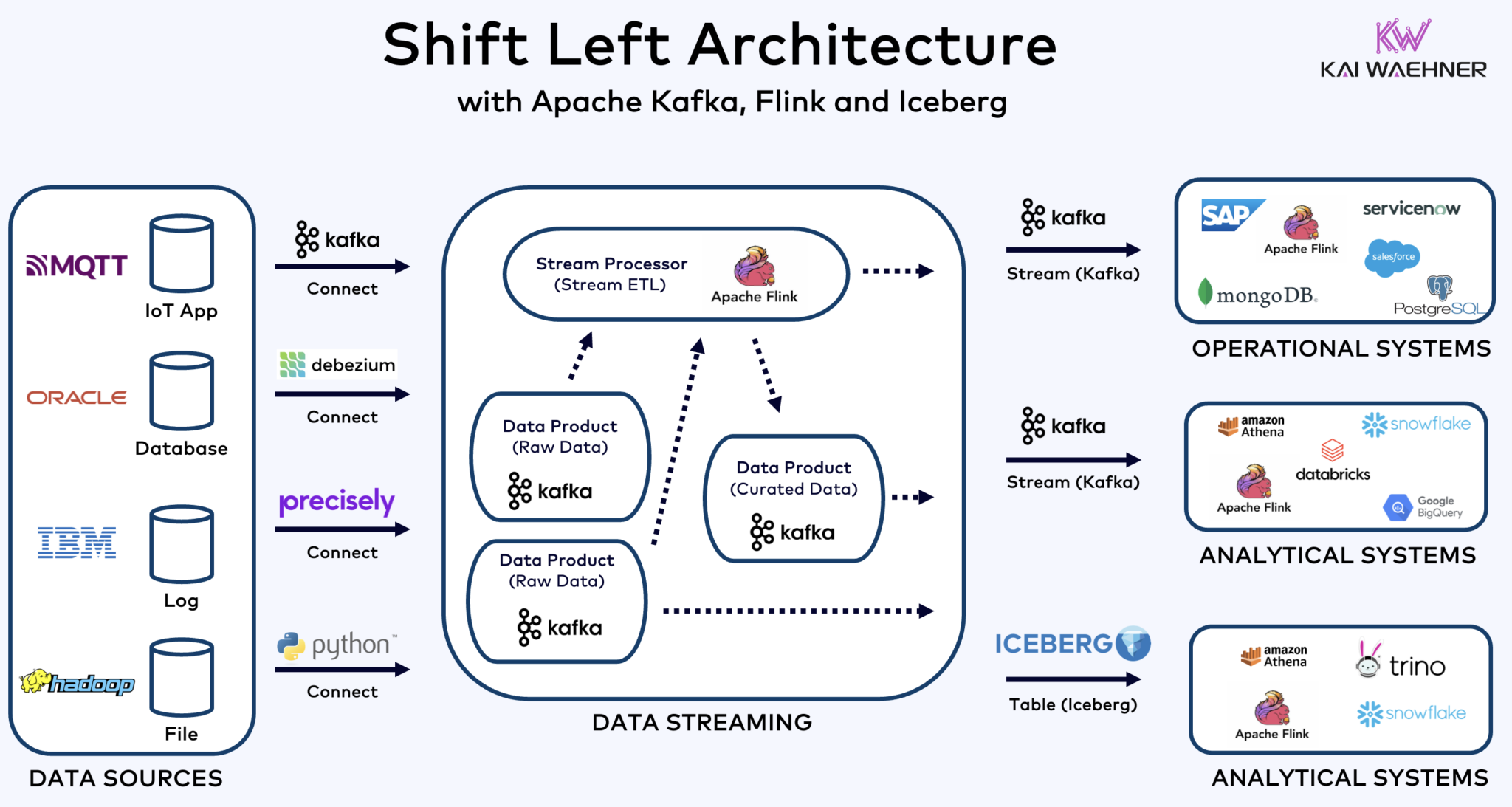
Apache Iceberg als Open Table Format en Catalogus voor Naadloze Data Deling Over Analytische Motoren
Een open table format en catalogus introduceert enorme voordelen in de enterprise-architectuur:
- Interoperabiliteit
- Vrijheid van keuze van de analytische motoren
- Snellere time-to-market
- Verlaagde kosten
Apache Iceberg lijkt de facto standaard te worden över vendors en cloud providers. Echter, het bevindt zich nog in een vroeg stadium en concurrerende en wrapper-technologieën zoals Apache Hudi, Apache Paimon, Delta Lake en Apache XTable proberen ook momentum te krijgen.
Hartberg en andere open tafelformats zijn niet alleen een huge win voor single storage en integratie met meerdere analytics/data/AI/ML-platforms zoals Snowflake, Databricks, Google BigQuery, et cetera, maar ook voor de vereniging van operationele en analytische workloads met behulp van data streaming en technologieën zoals Apache Kafka en Flink. Shift left architecture is een aanzienlijk voordeel om inspanningen te verminderen, de gegevenskwaliteit en consistentie te verbeteren, en real time in plaats van batchtoepassingen en inzichten mogelijk te maken.
Tot slot, als je je nog afvraagt wat de verschillen zijn tussen data streaming en lakehouses (en hoe ze elkaar aanvullen), kijk dan deze tien minuten durende video:
Wat is jouw tafelformaatstrategie? Welke technologieën en cloudservices verbind je? Laten we verbinden op LinkedIn en erover discussiëren!
Source:
https://dzone.com/articles/apache-iceberg-open-table-format-lakehouses-data-streaming