













저자는 자유 및 오픈 소스 기금을 기부 대상으로 선정하였습니다.
소개
Flask는 파이썬 언어로 웹 애플리케이션을 만드는 데 유용한 도구와 기능을 제공하는 가벼운 Python 웹 프레임워크입니다. SQLAlchemy은 관계형 데이터베이스에 대한 효율적이고 고성능의 데이터베이스 액세스를 제공하는 SQL 툴킷입니다. SQLite, MySQL, PostgreSQL과 같은 여러 데이터베이스 엔진과 상호 작용하는 방법을 제공합니다. 데이터베이스의 SQL 기능에 액세스할 수 있습니다. 또한 단순한 Python 객체와 메서드를 사용하여 쿼리를 수행하고 데이터를 처리할 수 있도록 해주는 객체 관계 매퍼(ORM)도 제공합니다. Flask-SQLAlchemy은 Flask와 SQLAlchemy를 함께 사용하는 것을 더 쉽게 만드는 Flask 확장 기능으로, Flask 애플리케이션에서 SQLAlchemy를 통해 데이터베이스와 상호 작용하는 도구와 메서드를 제공합니다.
이 튜토리얼에서는 Flask와 Flask-SQLAlchemy를 사용하여 직원 관리 시스템을 만들 것입니다. 이 시스템은 직원을 위한 테이블을 가진 데이터베이스를 가지고 있습니다. 각 직원은 고유한 ID, 이름, 성, 고유한 이메일, 나이를 나타내는 정수 값, 회사에 입사한 날짜, 그리고 현재 활성 상태인지 아니면 사무실을 벗어났는지를 나타내는 부울 값이 있을 것입니다.
Flask 셸을 사용하여 테이블을 쿼리하고 열 값 (예 : 이메일)을 기준으로 테이블 레코드를 가져올 것입니다. 특정 조건에서 직원 레코드를 검색할 것이며, 이는 활성 직원만 가져오거나 사무실을 벗어난 직원 목록을 가져오는 등의 조건일 수 있습니다. 결과를 열 값에 따라 정렬하고 쿼리 결과를 계산하고 제한할 것입니다. 마지막으로 웹 응용 프로그램에서 페이지당 일정 수의 직원을 표시하기 위해 페이지네이션을 사용할 것입니다.
필수 구성 요소
-
로컬 Python 3 프로그래밍 환경. Python 3을 위한 로컬 프로그래밍 환경 설치 및 설정 튜토리얼 시리즈에서 해당하는 튜토리얼을 따르세요. 이 튜토리얼에서는 프로젝트 디렉토리를
flask_app으로 지정할 것입니다. -
라우트, 뷰 함수 및 템플릿과 같은 기본적인 Flask 개념을 이해하는 것이 중요합니다. Flask에 익숙하지 않은 경우, Flask와 Python을 사용하여 첫 번째 웹 애플리케이션을 만드는 방법
과 Flask 애플리케이션에서 템플릿 사용하는 방법을 확인하십시오.
-
기본 HTML 개념을 이해하는 것이 중요합니다. 배경 지식을 위해 HTML로 웹사이트를 만드는 방법 튜토리얼 시리즈를 검토할 수 있습니다.
-
Flask-SQLAlchemy의 기본 개념을 이해하고 데이터베이스 설정, 데이터베이스 모델 생성, 데이터베이스에 데이터 삽입 등을 할 수 있어야 합니다. 배경 지식은 플라스크 응용 프로그램에서 데이터베이스와 상호 작용하는 방법 Flask-SQLAlchemy 사용하기를 참조하십시오.
단계 1 — 데이터베이스 및 모델 설정
이 단계에서는 필요한 패키지를 설치하고 Flask 응용 프로그램, Flask-SQLAlchemy 데이터베이스, 그리고 직원 데이터를 저장할 employee 테이블을 나타내는 직원 모델을 설정합니다. 몇 명의 직원을 employee 테이블에 삽입하고, 응용 프로그램의 인덱스 페이지에 모든 직원이 표시되는 경로와 페이지를 추가할 것입니다.
먼저 가상 환경을 활성화한 상태에서 Flask와 Flask-SQLAlchemy를 설치하세요:
설치가 완료되면 다음과 같은 줄이 포함된 출력을 받게 됩니다:
Output
Successfully installed Flask-2.1.2 Flask-SQLAlchemy-2.5.1 Jinja2-3.1.2 MarkupSafe-2.1.1 SQLAlchemy-1.4.37 Werkzeug-2.1.2 click-8.1.3 greenlet-1.1.2 itsdangerous-2.1.2
필요한 패키지가 설치된 경우 flask_app 디렉터리에 app.py라는 새 파일을 엽니다. 이 파일에는 데이터베이스를 설정하고 Flask 라우트를 설정하는 코드가 포함됩니다:
다음 코드를 app.py에 추가합니다. 이 코드는 SQLite 데이터베이스와 employee 테이블에 저장할 직원 데이터를 나타내는 직원 데이터베이스 모델을 설정합니다:
파일을 저장하고 닫습니다.
여기서는 os 모듈을 가져와서 잡다한 운영 체제 인터페이스에 액세스합니다. 이를 사용하여 database.db 데이터베이스 파일의 파일 경로를 구성합니다.
flask 패키지에서 애플리케이션에 필요한 도우미를 가져옵니다: Flask 애플리케이션 인스턴스를 생성하는 Flask 클래스, 템플릿을 렌더링하는 render_template(), 요청을 처리하는 request 객체, URL을 구성하는 url_for(), 사용자를 리디렉션하는 redirect() 함수입니다. 라우트 및 템플릿에 대한 자세한 정보는 Flask 애플리케이션에서 템플릿 사용 방법을 참조하십시오.
그런 다음 Flask-SQLAlchemy 확장에서 SQLAlchemy 클래스를 가져와서 SQLAlchemy의 모든 함수 및 클래스에 액세스할 수 있습니다. 또한 Flask를 SQLAlchemy와 통합하는 도우미 및 기능을 제공합니다. 이를 사용하여 Flask 애플리케이션에 연결하는 데이터베이스 객체를 만듭니다.
데이터베이스 파일의 경로를 구성하려면 기본 디렉터리를 현재 디렉터리로 정의합니다. os.path.abspath() 함수를 사용하여 현재 파일의 디렉터리의 절대 경로를 가져옵니다. 특별한 __file__ 변수는 현재 app.py 파일의 경로를 보유합니다. 기본 디렉터리의 절대 경로를 basedir라는 변수에 저장합니다.
그런 다음 app이라는 Flask 애플리케이션 인스턴스를 만들고 Flask-SQLAlchemy 구성 키 두 개를 구성합니다:
-
SQLALCHEMY_DATABASE_URI: 연결을 설정하려는 데이터베이스를 지정하는 데이터베이스 URI입니다. 이 경우, URI는sqlite:///path/to/database.db형식을 따릅니다.os.path.join()함수를 사용하여 구성하고basedir변수에 저장된 기본 디렉터리를 지능적으로 결합하고database.db파일 이름을 사용합니다. 이렇게 하면flask_app디렉터리에 있는database.db데이터베이스 파일에 연결됩니다. 데이터베이스를 초기화하면 파일이 생성됩니다. -
SQLALCHEMY_TRACK_MODIFICATIONS: 객체 수정 추적을 활성화 또는 비활성화하는 설정입니다. 추적을 비활성화하려면False로 설정하십시오. 이렇게 하면 메모리를 더 적게 사용합니다. 자세한 내용은 Flask-SQLAlchemy 설명서의 구성 페이지를 참조하십시오.
데이터베이스 URI를 설정하고 추적을 비활성화하여 SQLAlchemy를 구성한 후, Flask 응용 프로그램을 SQLAlchemy와 연결하기 위해 응용 프로그램 인스턴스를 전달하여 데이터베이스 객체를 생성합니다. 데이터베이스 객체를 db라는 변수에 저장하고 데이터베이스와 상호 작용하는 데 사용합니다.
애플리케이션 인스턴스와 데이터베이스 객체를 설정한 후에는 db.Model 클래스에서 상속하여 Employee라는 데이터베이스 모델을 생성합니다. 이 모델은 employee 테이블을 나타내며 다음과 같은 열을 갖습니다:
id: 직원 ID, 정수 기본 키입니다.firstname: 직원의 이름, 최대 100자의 문자열입니다.nullable=False는 이 열이 비어 있으면 안 된다는 것을 나타냅니다.lastname: 직원의 성, 최대 100자의 문자열입니다.nullable=False는 이 열이 비어 있으면 안 된다는 것을 나타냅니다.email: 직원의 이메일, 최대 100자의 문자열입니다.unique=True는 각 이메일이 고유해야 함을 나타냅니다.nullable=False는 값이 비어 있으면 안 된다는 것을 나타냅니다.age: 직원의 나이, 정수 값입니다.hire_date: 직원이 고용된 날짜. 이를 날짜를 보유하는 열로 선언하기 위해db.Date를 열 유형으로 설정합니다.active: 현재 활성 상태인지 아닌지를 나타내는 부울 값이 들어갈 열입니다.
특별한 __repr__ 함수를 사용하면 디버깅 목적으로 각 객체에 문자열 표현을 지정할 수 있습니다. 이 경우 각 직원 객체를 식별하기 위해 직원의 이름과 성을 사용합니다.
이제 데이터베이스 연결과 직원 모델을 설정했으므로 데이터베이스를 만들고 employee 테이블을 생성하고 몇 가지 직원 데이터를 테이블에 채우는 Python 프로그램을 작성할 것입니다.
flask_app 디렉토리에 init_db.py라는 새 파일을 엽니다:
기존 데이터베이스 테이블을 삭제하고 깨끗한 데이터베이스에서 시작하려면 다음 코드를 추가하십시오. employee 테이블을 만들고 그 안에 아홉 명의 직원을 삽입합니다:
여기에서는 직원 입사 날짜를 설정하는 데 사용하기 위해 datetime 모듈에서 date() 클래스를 가져옵니다.
데이터베이스 객체와 Employee 모델을 가져옵니다. db.drop_all() 함수를 호출하여 이미 채워진 employee 테이블이 데이터베이스에 존재하는 경우 문제가 발생할 수 있는 가능성을 피하기 위해 모든 기존 테이블을 삭제합니다. 이는 init_db.py 프로그램을 실행할 때마다 모든 데이터베이스 데이터를 삭제합니다. 데이터베이스 테이블을 만들고 수정하고 삭제하는 방법에 대한 자세한 내용은 플라스크 응용 프로그램에서 데이터베이스와 상호 작용하는 Flask-SQLAlchemy 사용 방법을 참조하십시오.
그런 다음이 자습서에서 쿼리 할 직원을 나타내는 Employee 모델의 여러 인스턴스를 만들고 db.session.add_all() 함수를 사용하여 데이터베이스 세션에 추가합니다. 마지막으로 트랜잭션을 커밋하고 변경 사항을 데이터베이스에 적용합니다. db.session.commit(). 파일을 저장하고 닫습니다.
init_db.py 프로그램을 실행합니다.
데이터베이스에 추가 한 데이터를 확인하려면 가상 환경이 활성화되어 있는지 확인하고 Flask 셸을 열어 모든 직원을 쿼리하고 데이터를 표시합니다.
다음 코드를 실행하여 모든 직원을 쿼리하고 데이터를 표시합니다.
모든 직원을 얻으려면 query 속성의 all() 메서드를 사용합니다. 결과를 루프로 반복하여 직원 정보를 표시합니다. active 열에 대해 직원의 현재 상태 인 'Active' 또는 'Out of Office'를 표시하기 위해 조건문을 사용합니다.
다음 출력을받게됩니다.
OutputJohn Doe
Email: [email protected]
Age: 32
Hired: 2012-03-03
Active
----
Mary Doe
Email: [email protected]
Age: 38
Hired: 2016-06-07
Active
----
Jane Tanaka
Email: [email protected]
Age: 32
Hired: 2015-09-12
Out of Office
----
Alex Brown
Email: [email protected]
Age: 29
Hired: 2019-01-03
Active
----
James White
Email: [email protected]
Age: 24
Hired: 2021-02-04
Active
----
Harold Ishida
Email: [email protected]
Age: 52
Hired: 2002-03-06
Out of Office
----
Scarlett Winter
Email: [email protected]
Age: 22
Hired: 2021-04-07
Active
----
Emily Vill
Email: [email protected]
Age: 27
Hired: 2019-06-09
Active
----
Mary Park
Email: [email protected]
Age: 30
Hired: 2021-08-11
Active
----
데이터베이스에 추가 한 모든 직원이 올바르게 표시됩니다.
Flask 셸을 종료합니다.
다음으로 직원을 표시하는 Flask 라우트를 만듭니다. 편집을위한 app.py를 엽니 다.
파일 끝에 다음 경로를 추가하십시오.
파일을 저장하고 닫습니다.
이는 모든 직원을 쿼리하고 index.html 템플릿을 렌더링하고 가져 오는 라우트입니다. 그것을 전달합니다.
템플릿 디렉토리와 기본 템플릿을 생성하세요:기본 템플릿:
base.html에 다음을 추가하세요:
파일을 저장하고 닫으세요.
여기서 제목 블록을 사용하고 일부 CSS 스타일을 추가합니다. 색인 페이지와 비활성화된 소개 페이지에 대한 두 항목이 있는 내비게이션 바를 추가합니다. 이 내비게이션 바는 이 기본 템플릿을 상속하는 템플릿에서 애플리케이션 전체에서 재사용됩니다. 콘텐츠 블록은 각 페이지의 콘텐츠로 대체됩니다. 템플릿에 대한 자세한 내용은 Flask 애플리케이션에서 템플릿 사용 방법을 확인하세요.
다음으로, app.py에서 렌더링한 새로운 index.html 템플릿을 엽니다:
다음 코드를 파일에 추가하세요:
여기서 직원을 반복하고 각 직원의 정보를 표시합니다. 직원이 활성 상태인 경우 (활성) 레이블을 추가하고, 그렇지 않으면 (근무 외) 레이블을 표시합니다.
파일을 저장하고 닫으세요.
flask_app 디렉토리에서 가상 환경을 활성화한 상태에서 애플리케이션(app.py 이 경우)을 Flask에 알려주세요. 이를 위해 FLASK_APP 환경 변수를 사용합니다. 그런 다음 애플리케이션을 개발 모드로 실행하고 디버거에 액세스하려면 FLASK_ENV 환경 변수를 development로 설정하세요. Flask 디버거에 대한 자세한 내용은 Flask 애플리케이션에서 오류 처리하는 방법을 참조하세요. 다음 명령을 사용하여 이 작업을 수행합니다:
다음으로 애플리케이션을 실행하세요:
개발 서버가 실행되면 브라우저를 사용하여 다음 URL을 방문하세요:
http://127.0.0.1:5000/
이 페이지에서 데이터베이스에 추가한 직원들을 다음과 비슷한 페이지에서 볼 수 있습니다:
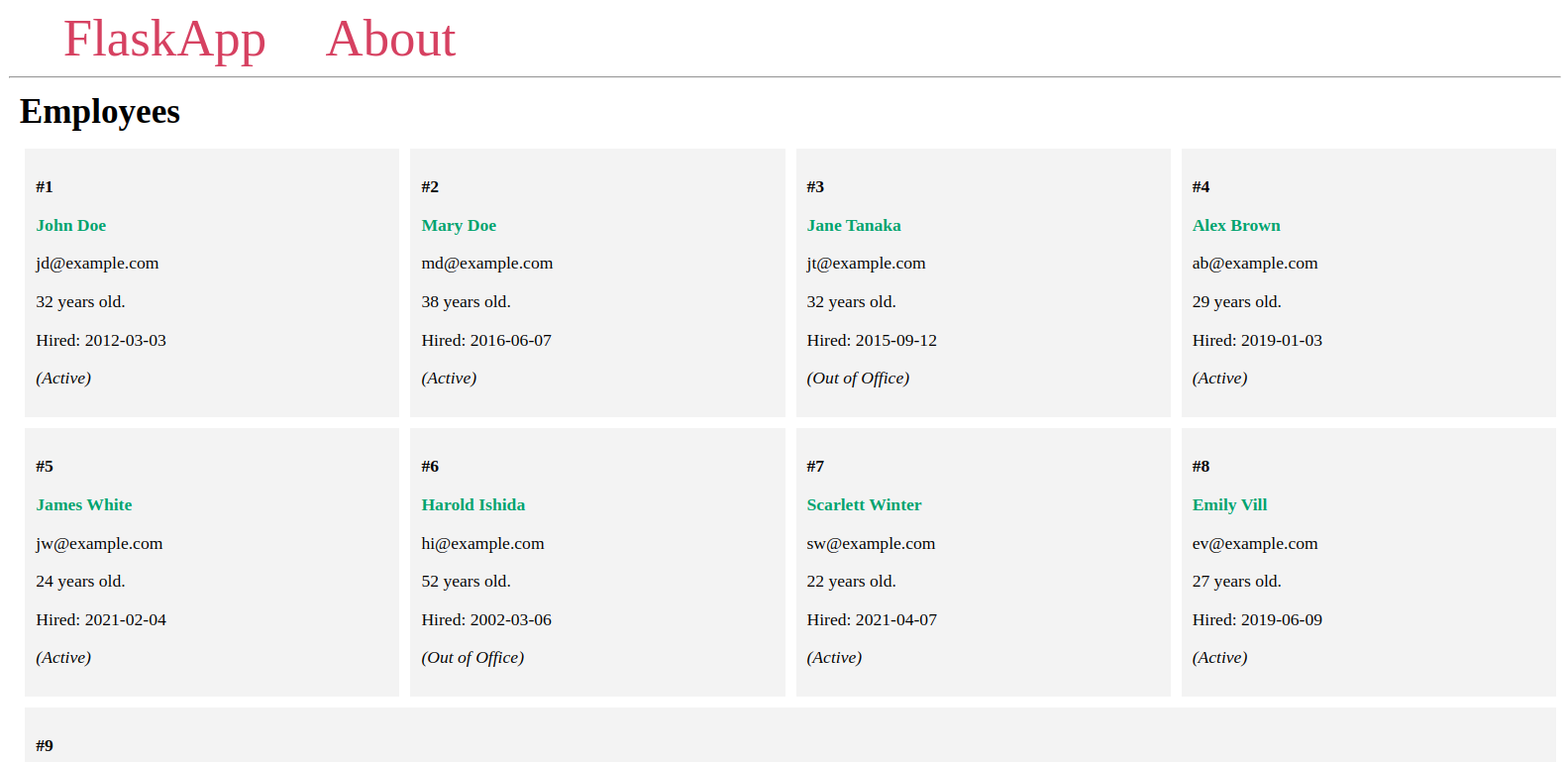
서버를 실행한 상태로 다른 터미널을 열고 다음 단계로 계속하세요.
데이터베이스에 있는 직원들을 인덱스 페이지에 표시했습니다. 다음으로 Flask 셸을 사용하여 다양한 방법으로 직원들을 쿼리할 것입니다.
단계 2 — 레코드 쿼리
이 단계에서는 Flask 셸을 사용하여 레코드를 쿼리하고 여러 방법과 조건을 사용하여 결과를 필터링하고 검색합니다.
프로그래밍 환경을 활성화한 상태에서 FLASK_APP 및 FLASK_ENV 변수를 설정하고 Flask 셸을 열어주세요:
db 객체와 Employee 모델을 가져옵니다:
모든 레코드 검색
이전 단계에서 본 것처럼 query 속성의 all() 메서드를 사용하여 테이블의 모든 레코드를 가져올 수 있습니다:
결과는 모든 직원을 나타내는 객체의 목록입니다:
Output
[<Employee John Doe>, <Employee Mary Doe>, <Employee Jane Tanaka>, <Employee Alex Brown>, <Employee James White>, <Employee Harold Ishida>, <Employee Scarlett Winter>, <Employee Emily Vill>, <Employee Mary Park>]
첫 번째 레코드 검색
마찬가지로, 첫 번째 레코드를 가져 오려면 first() 메서드를 사용할 수 있습니다:
결과는 첫 번째 직원 데이터를 보유하는 객체입니다:
Output<Employee John Doe>
ID로 레코드 검색
대부분의 데이터베이스 테이블에서 레코드는 고유한 ID로 식별됩니다. Flask-SQLAlchemy를 사용하면 get() 메서드를 사용하여 ID로 레코드를 검색할 수 있습니다:
Output<Employee James White> | ID: 5
<Employee Jane Tanaka> | ID: 3
열 값에 따라 레코드 또는 여러 레코드 검색
하나의 열 값 사용하여 레코드를 가져오려면 filter_by() 메소드를 사용합니다. 예를 들어, ID 값 사용하여 레코드를 가져오려면 get() 메소드와 유사합니다:
Output<Employee John Doe>
filter_by()를 사용하면 여러 결과가 반환될 수 있으므로 first()를 사용합니다.
참고: ID를 사용하여 레코드를 가져오는 경우 get() 메소드를 사용하는 것이 더 좋은 접근 방식입니다.
다른 예로, 나이를 사용하여 직원을 가져올 수 있습니다:
Output<Employee Harold Ishida>
쿼리 결과에 여러 일치하는 레코드가 포함된 예로, firstname 열과 이름이 Mary인 두 직원의 이름을 사용합니다:
Output[<Employee Mary Doe>, <Employee Mary Park>]
여기서 all()을 사용하여 전체 목록을 가져옵니다. 첫 번째 결과만 가져 오려면 first()를 사용할 수도 있습니다:
Output<Employee Mary Doe>
열 값에 따라 레코드를 가져왔습니다. 다음으로 논리 조건을 사용하여 테이블을 쿼리합니다.
단계 3 — 논리 조건을 사용하여 레코드 필터링
복잡하고 기능이 풍부한 웹 응용 프로그램에서는 종종 위치, 가용성, 역할 및 책임을 고려한 복잡한 조건을 사용하여 데이터베이스에서 레코드를 쿼리해야합니다. 이 단계에서는 조건 연산자를 사용하는 연습을 할 것입니다. 서로 다른 연산자를 사용하여 논리 조건을 사용하여 쿼리 결과를 필터링하는 query 속성의 filter() 메서드를 사용합니다. 예를 들어 현재 사무실을 비운 직원 목록을 가져 오거나 승진을 기다리는 직원 목록을 가져 오거나 직원 휴가 시간의 캘린더를 제공 할 수 있습니다.
동일
사용할 수있는 가장 간단한 논리 연산자는 등호 연산자 ==로 filter_by()와 유사한 방식으로 작동합니다. 예를 들어 firstname 열의 값이 Mary인 모든 레코드를 가져 오려면 다음과 같이 filter() 메서드를 사용할 수 있습니다:
여기에서는 Model.column == value 구문을 filter() 메서드의 인수로 사용합니다. filter_by() 메서드는 이 구문의 단축키입니다.
결과는 동일합니다. 동일한 조건으로 filter_by() 메서드의 결과와 동일합니다:
Output[<Employee Mary Doe>, <Employee Mary Park>]
filter_by()와 마찬가지로 첫 번째 결과를 가져 오려면 first() 메서드를 사용할 수도 있습니다:
Output<Employee Mary Doe>
동일하지 않음
filter() 메서드를 사용하면 != 파이썬 연산자를 사용하여 레코드를 가져올 수 있습니다. 예를 들어, 퇴근 중인 직원 목록을 얻으려면 다음 접근 방식을 사용할 수 있습니다:
Output[<Employee Jane Tanaka>, <Employee Harold Ishida>]
여기서는 결과를 필터링하기 위해 Employee.active != True 조건을 사용합니다.
미만
< 연산자를 사용하여 주어진 열의 값이 주어진 값보다 작은 레코드를 가져올 수 있습니다. 예를 들어, 32세 미만의 직원 목록을 얻으려면:
Output
Alex Brown
Age: 29
----
James White
Age: 24
----
Scarlett Winter
Age: 22
----
Emily Vill
Age: 27
----
Mary Park
Age: 30
----
주어진 값 이하인 레코드에는 <= 연산자를 사용하십시오. 예를 들어, 이전 쿼리에 32세인 직원을 포함하려면:
Output
John Doe
Age: 32
----
Jane Tanaka
Age: 32
----
Alex Brown
Age: 29
----
James White
Age: 24
----
Scarlett Winter
Age: 22
----
Emily Vill
Age: 27
----
Mary Park
Age: 30
----
초과
비슷하게, > 연산자는 주어진 열의 값이 주어진 값보다 큰 레코드를 가져옵니다. 예를 들어, 32세 이상의 직원을 얻으려면:
OutputMary Doe
Age: 38
----
Harold Ishida
Age: 52
----
>= 연산자는 주어진 값 이상인 레코드를 위해 사용됩니다. 예를 들어, 이전 쿼리에 32세인 직원을 다시 포함할 수 있습니다:
Output
John Doe
Age: 32
----
Mary Doe
Age: 38
----
Jane Tanaka
Age: 32
----
Harold Ishida
Age: 52
----
SQLAlchemy
는 열의 값이 주어진 값 목록에서의 값과 일치하는 레코드를 가져오는 방법을 제공하는데, 이는 열의 in_() 메서드를 사용하여 다음과 같이 수행할 수 있습니다:
Output[<Employee Mary Doe>, <Employee Alex Brown>, <Employee Emily Vill>, <Employee Mary Park>]
여기서는 다음과 같은 구문의 조건을 사용합니다: Model.column.in_(iterable), 여기서 iterable은 반복 가능한 객체입니다. 또 다른 예로, range() Python 함수를 사용하여 특정 연령대의 직원을 가져올 수 있습니다. 다음 쿼리는 30대의 모든 직원을 가져옵니다.
OutputJohn Doe
Age: 32
----
Mary Doe
Age: 38
----
Jane Tanaka
Age: 32
----
Mary Park
Age: 30
----
Not In
in_() 메서드와 유사하게, not_in() 메서드를 사용하여 열 값이 주어진 반복 가능한 객체에 포함되지 않는 레코드를 가져올 수 있습니다:
Output
[<Employee John Doe>, <Employee Jane Tanaka>, <Employee James White>, <Employee Harold Ishida>, <Employee Scarlett Winter>]
여기서는 names 목록에 있는 이름을 가진 직원을 제외한 모든 직원을 가져옵니다.
And
db.and_() 함수를 사용하여 여러 조건을 결합할 수 있습니다. 이 함수는 Python의 and 연산자와 같이 작동합니다.
예를 들어, 32세이고 현재 활성화된 모든 직원을 얻고 싶다고 가정해보겠습니다. 먼저, filter_by() 메소드를 사용하여 32세인 누구인지 확인할 수 있습니다(filter()도 사용할 수 있습니다):
Output<Employee John Doe>
Age: 32
Active: True
-----
<Employee Jane Tanaka>
Age: 32
Active: False
-----
여기에서는 존과 제인이 32세인 직원임을 확인할 수 있습니다. 존은 활성화되어 있고, 제인은 외근 중입니다.
32세이고 활성화된 직원을 얻으려면, filter() 메소드를 사용하여 두 가지 조건을 사용합니다:
Employee.age == 32Employee.active == True
이 두 조건을 결합하려면 db.and_() 함수를 사용하세요:
Output[<Employee John Doe>]
여기에서는 filter(db.and_(조건1, 조건2)) 구문을 사용합니다.
쿼리에 all()을 사용하면 두 조건과 일치하는 모든 레코드 목록을 반환합니다. 첫 번째 결과를 얻으려면 first() 메소드를 사용할 수 있습니다:
Output<Employee John Doe>
보다 복잡한 예제로, 특정 기간에 고용된 직원을 얻기 위해 db.and_()와 date() 함수를 함께 사용할 수 있습니다. 이 예에서는 2019년에 고용된 모든 직원을 가져옵니다:
Output<Employee Alex Brown> | Hired: 2019-01-03
<Employee Emily Vill> | Hired: 2019-06-09
여기에서는 date() 함수를 가져오고, 다음 두 가지 조건을 결합하기 위해 db.and_() 함수를 사용하여 결과를 필터링합니다:
Employee.hire_date >= date(year=2019, month=1, day=1): 이 조건은 2019년 1월 1일 이후에 고용된 직원에 대해True입니다.Employee.hire_date < date(year=2020, month=1, day=1): 이것은 2020년 1월 1일 이전에 고용된 직원들에 대해True입니다.
두 조건을 결합하면 2019년 1월 1일부터 2020년 1월 1일 이전까지 고용된 직원들을 가져옵니다.
또는
db.and_()와 유사하게, db.or_() 함수는 두 조건을 결합하며, 파이썬의 or 연산자와 같은 방식으로 작동합니다. 두 조건 중 하나를 충족하는 모든 레코드를 가져옵니다. 예를 들어, 나이가 32세인 또는 52세인 직원을 얻으려면 다음과 같이 두 조건을 db.or_() 함수로 결합할 수 있습니다:
Output<Employee John Doe> | Age: 32
<Employee Jane Tanaka> | Age: 32
<Employee Harold Ishida> | Age: 52
startswith() 및 endswith() 메서드를 사용하여 filter() 메서드에 전달되는 조건에서 문자열 값의 시작 및 끝을 확인할 수도 있습니다. 예를 들어, 이름이 문자열 'M'으로 시작하고 성이 문자열 'e'로 끝나는 모든 직원을 가져오려면:
Output<Employee John Doe>
<Employee Mary Doe>
<Employee James White>
<Employee Mary Park>
다음 두 조건을 결합합니다:
Employee.firstname.startswith('M'): 이름이'M'으로 시작하는 직원과 일치합니다.Employee.lastname.endswith('e'): 성이'e'로 끝나는 직원과 일치합니다.
이제 Flask-SQLAlchemy 애플리케이션에서 논리적 조건을 사용하여 쿼리 결과를 필터링할 수 있습니다. 다음으로 데이터베이스에서 결과를 정렬, 제한 및 계산할 것입니다.
단계 4 – 결과 주문, 제한 및 계산
웹 애플리케이션에서 결과를 표시할 때 종종 레코드를 정렬해야 합니다. 예를 들어, 각 부서의 최신 입사자를 표시하는 페이지가 있을 수 있습니다. 나머지 팀원들에게 새로운 입사자를 알려줍니다. 또는 고용 기간이 긴 직원들을 인식하기 위해 가장 오래된 입사자부터 정렬할 수도 있습니다. 또한 특정 경우에는 결과를 제한해야 합니다. 예를 들어, 작은 사이드바에 최신 세 명의 입사자만 표시해야 할 수 있습니다. 그리고 종종 질의 결과를 계산해야 합니다. 예를 들어 현재 활동 중인 직원 수를 표시해야 할 수 있습니다. 이 단계에서는 결과를 주문하고 제한하고 계산하는 방법을 배우게 됩니다.
결과 주문
특정 열의 값으로 결과를 정렬하려면 order_by() 메서드를 사용하십시오. 예를 들어, 직원의 성을 기준으로 결과를 정렬하려면 다음과 같이 사용하십시오:
Output[<Employee Alex Brown>, <Employee Emily Vill>, <Employee Harold Ishida>, <Employee James White>, <Employee Jane Tanaka>, <Employee John Doe>, <Employee Mary Doe>, <Employee Mary Park>, <Employee Scarlett Winter>]
출력에서 볼 수 있듯이 결과는 직원의 성에 따라 알파벳순으로 정렬됩니다.
다른 열로도 정렬할 수 있습니다. 예를 들어, 성을 사용하여 직원을 정렬할 수 있습니다:
Output[<Employee Alex Brown>, <Employee John Doe>, <Employee Mary Doe>, <Employee Harold Ishida>, <Employee Mary Park>, <Employee Jane Tanaka>, <Employee Emily Vill>, <Employee James White>, <Employee Scarlett Winter>]
고용 날짜에 따라 직원을 정렬할 수도 있습니다:
Output
Harold Ishida 2002-03-06
John Doe 2012-03-03
Jane Tanaka 2015-09-12
Mary Doe 2016-06-07
Alex Brown 2019-01-03
Emily Vill 2019-06-09
James White 2021-02-04
Scarlett Winter 2021-04-07
Mary Park 2021-08-11
출력이 보여 주는 대로, 이것은 가장 일찍 고용된 사람부터 가장 최근 고용된 사람까지 결과를 정렬합니다. 순서를 반대로하여 최근 고용된 사람부터 가장 일찍 고용된 사람까지 내림차순으로 만들려면 다음과 같이 desc() 메서드를 사용하십시오:
OutputMary Park 2021-08-11
Scarlett Winter 2021-04-07
James White 2021-02-04
Emily Vill 2019-06-09
Alex Brown 2019-01-03
Mary Doe 2016-06-07
Jane Tanaka 2015-09-12
John Doe 2012-03-03
Harold Ishida 2002-03-06
order_by() 메서드를 filter() 메서드와 결합하여 필터링된 결과를 정렬할 수도 있습니다. 다음 예제는 2021년에 고용된 모든 직원을 가져와 나이순으로 정렬합니다:
OutputScarlett Winter 2021-04-07 | Age 22
James White 2021-02-04 | Age 24
Mary Park 2021-08-11 | Age 30
여기서 두 가지 조건을 사용하여 db.and_() 함수를 사용합니다: 2021년 1월 1일 이후에 고용된 직원을 위한 Employee.hire_date >= date(year=2021, month=1, day=1) 및 2022년 1월 1일 이전에 고용된 직원을 위한 Employee.hire_date < date(year=2022, month=1, day=1)입니다. 그런 다음 결과 직원을 나이순으로 정렬하기 위해 order_by() 메서드를 사용합니다.
결과 제한
대부분의 실제 상황에서 데이터베이스 테이블을 쿼리할 때 수백만 개의 일치하는 결과를 얻을 수 있으며, 때로는 결과를 특정 수로 제한하는 것이 필요할 수 있습니다. Flask-SQLAlchemy에서 결과를 제한하려면 limit() 메서드를 사용할 수 있습니다. 다음 예제는 employee 테이블을 쿼리하고 처음 세 개의 일치하는 결과만 반환합니다:
Output[<Employee John Doe>, <Employee Mary Doe>, <Employee Jane Tanaka>]
limit()를 filter 및 order_by와 함께 사용할 수 있습니다. 예를 들어, 다음과 같이 limit() 메서드를 사용하여 2021년에 고용된 마지막 두 명의 직원을 가져올 수 있습니다:
OutputScarlett Winter 2021-04-07 | Age 22
James White 2021-02-04 | Age 24
여기에서는 이전 섹션에서 사용한 동일한 쿼리에 limit(2) 메서드 호출을 추가하여 사용합니다.
결과 계수
쿼리의 결과 수를 계산하려면 count() 메서드를 사용할 수 있습니다. 예를 들어, 데이터베이스에 현재 있는 직원 수를 가져오려면:
Output9
count() 메서드를 limit()와 유사한 다른 쿼리 메서드와 결합할 수 있습니다. 예를 들어, 2021년에 고용된 직원 수를 얻으려면:
Output3
여기에서는 이전에 2021년에 고용된 모든 직원을 얻는 데 사용한 동일한 쿼리를 사용합니다. 그리고 항목 수를 검색하기 위해 count()를 사용합니다. 그 수는 3입니다.
당신은 Flask-SQLAlchemy에서 쿼리 결과를 정렬, 제한 및 계산했습니다. 다음으로, Flask 애플리케이션에서 쿼리 결과를 여러 페이지로 나누고 페이지네이션 시스템을 만드는 방법을 배우게 될 것입니다.
단계 5 — 여러 페이지에 긴 레코드 목록 표시하기
이 단계에서는 메인 루트를 수정하여 색인 페이지가 직원 목록을 여러 페이지에 표시하여 직원 목록 탐색을 쉽게 만듭니다.
먼저 Flask 쉘을 사용하여 Flask-SQLAlchemy에서 페이지네이션 기능을 사용하는 방법을 시연합니다. Flask 쉘을 이미 열지 않았다면 열어주세요:
테이블의 직원 레코드를 여러 페이지로 나누어 각 페이지당 두 개의 항목으로 나누려고 합니다. 다음과 같이 paginate() 쿼리 메서드를 사용할 수 있습니다:
Output<flask_sqlalchemy.Pagination object at 0x7f1dbee7af80>
[<Employee John Doe>, <Employee Mary Doe>]
paginate() 쿼리 메서드의 page 매개변수를 사용하여 액세스할 페이지를 지정합니다. 이 경우 첫 번째 페이지입니다. per_page 매개변수는 각 페이지에 포함되어야 하는 항목 수를 지정합니다. 이 경우 각 페이지에 두 개의 항목이 있도록 2로 설정합니다.
여기서 page1 변수는 페이지네이션 객체로, 페이지네이션을 관리하는 데 사용할 속성 및 메서드에 액세스할 수 있습니다.
items 속성을 사용하여 페이지의 항목에 액세스할 수 있습니다.
다음 페이지에 액세스하려면 페이지네이션 객체의 next() 메서드를 사용할 수 있습니다. 반환된 결과도 페이지네이션 객체입니다:
Output[<Employee Jane Tanaka>, <Employee Alex Brown>]
<flask_sqlalchemy.Pagination object at 0x7f1dbee799c0>
이전 페이지에 대한 페이지네이션 객체는 prev() 메서드를 사용하여 가져올 수 있습니다. 다음 예제에서는 네 번째 페이지의 페이지네이션 객체에 액세스한 다음, 이전 페이지인 세 번째 페이지의 페이지네이션 객체에 액세스합니다:
Output[<Employee Scarlett Winter>, <Employee Emily Vill>]
[<Employee James White>, <Employee Harold Ishida>]
page 속성을 사용하여 현재 페이지 번호에 액세스할 수 있습니다:
Output1
2
페이지 총 수를 얻으려면 페이지네이션 객체의 pages 속성을 사용하십시오. 다음 예제에서는 page1.pages와 page2.pages가 동일한 값을 반환합니다. 왜냐하면 페이지의 총 수는 상수이기 때문입니다:
Output5
5
항목의 총 수를 얻으려면 페이지네이션 객체의 total 속성을 사용하십시오:
Output9
9
여기에서는 모든 직원을 쿼리하므로 페이지네이션의 항목 총 수는 데이터베이스에 9명의 직원이 있기 때문에 9입니다.
다음은 페이지네이션 객체가 가지고 있는 다른 속성 몇 가지입니다:
prev_num: 이전 페이지 번호입니다.next_num: 다음 페이지 번호입니다.has_next: 다음 페이지가 있으면True입니다.has_prev: 이전 페이지가 있으면True입니다.per_page: 페이지 당 항목 수입니다.
또한 페이지네이션 객체에는 페이지 번호에 액세스하기 위해 루프를 돌 수 있는 iter_pages() 메서드가 있습니다. 예를 들어 다음과 같이 모든 페이지 번호를 출력할 수 있습니다:
Output1
2
3
4
5
다음은 페이지네이션 객체와 iter_pages() 메서드를 사용하여 모든 페이지와 해당 항목에 액세스하는 방법을 시연한 것입니다:
Output
PAGE 1
-
[<Employee John Doe>, <Employee Mary Doe>]
--------------------
PAGE 2
-
[<Employee Jane Tanaka>, <Employee Alex Brown>]
--------------------
PAGE 3
-
[<Employee James White>, <Employee Harold Ishida>]
--------------------
PAGE 4
-
[<Employee Scarlett Winter>, <Employee Emily Vill>]
--------------------
PAGE 5
-
[<Employee Mary Park>]
--------------------
여기에서는 첫 번째 페이지부터 시작하는 페이지네이션 객체를 생성합니다. iter_pages() 페이지네이션 메서드를 사용하여 페이지를 루프로 반복합니다. 페이지 번호와 페이지 항목을 출력하고 next() 메서드를 사용하여 현재 페이지의 pagination 객체를 다음 페이지의 페이지네이션 객체로 설정합니다.
filter() 및 order_by() 메서드를 paginate() 메서드와 함께 사용하여 필터링 및 정렬된 쿼리 결과를 페이지별로 나눌 수 있습니다. 예를 들어, 삼십 대 이상의 직원을 가져와 나이로 결과를 정렬하고 다음과 같이 결과를 페이지별로 나눌 수 있습니다:
OutputPAGE 1
-
<Employee John Doe> | Age: 32
<Employee Jane Tanaka> | Age: 32
--------------------
PAGE 2
-
<Employee Mary Doe> | Age: 38
<Employee Harold Ishida> | Age: 52
--------------------
Flask-SQLAlchemy에서 페이지네이션 작동 방식을 확실히 이해했으므로, 응용 프로그램의 인덱스 페이지를 편리한 탐색을 위해 여러 페이지에 걸쳐 직원을 표시하도록 편집할 것입니다.
Flask 셸을 종료하십시오:
다른 페이지에 액세스하려면 URL 매개변수 또는 URL 쿼리 문자열을 사용할 것입니다. 이것들은 URL을 통해 응용 프로그램에 정보를 전달하는 방법입니다. 매개변수는 URL의 ? 기호 뒤에 응용 프로그램으로 전달됩니다. 예를 들어, 다음과 같은 URL을 사용하여 page 매개변수에 다른 값을 전달할 수 있습니다:
http://127.0.0.1:5000/?page=1
http://127.0.0.1:5000/?page=3
여기서 첫 번째 URL은 page URL 매개변수에 값을 1로 전달합니다. 두 번째 URL은 동일한 매개변수에 값을 3으로 전달합니다.
app.py 파일을 엽니다:
인덱스 라우트를 다음과 같이 수정합니다:
여기서는 request.args 객체와 그의 get() 메서드를 사용하여 page URL 매개변수의 값을 가져옵니다. 예를 들어 /?page=1에서는 page URL 매개변수에서 값 1을 가져옵니다. 기본값으로 1을 전달하고, 값이 정수임을 확인하기 위해 int Python 유형을 type 매개변수에 전달합니다.
다음으로 pagination 객체를 만들고, 쿼리 결과를 이름순으로 정렬합니다. page URL 매개변수 값을 paginate() 메서드에 전달하고, per_page 매개변수에 값 2를 전달하여 페이지당 두 항목으로 결과를 분할합니다.
마지막으로, 생성한 pagination 객체를 렌더링된 index.html 템플릿에 전달합니다.
파일을 저장하고 닫으십시오.
다음으로, index.html 템플릿을 수정하여 페이지네이션 항목을 표시합니다:
현재 페이지를 나타내는 h2 제목을 추가하고, 더 이상 사용할 수 없는 employees 객체 대신 pagination.items 객체를 순회하는 for 루프를 변경하십시오:
파일을 저장하고 닫으십시오.
이전에 FLASK_APP 및 FLASK_ENV 환경 변수를 설정하지 않았다면 개발 서버를 실행하십시오:
이제 page URL 매개변수에 대해 다른 값으로 색인 페이지로 이동하십시오:
http://127.0.0.1:5000/
http://127.0.0.1:5000/?page=2
http://127.0.0.1:5000/?page=4
http://127.0.0.1:5000/?page=19
이전 Flask 셸에서 본 것처럼 각각 두 개의 항목이 있는 다른 페이지를 볼 수 있습니다.
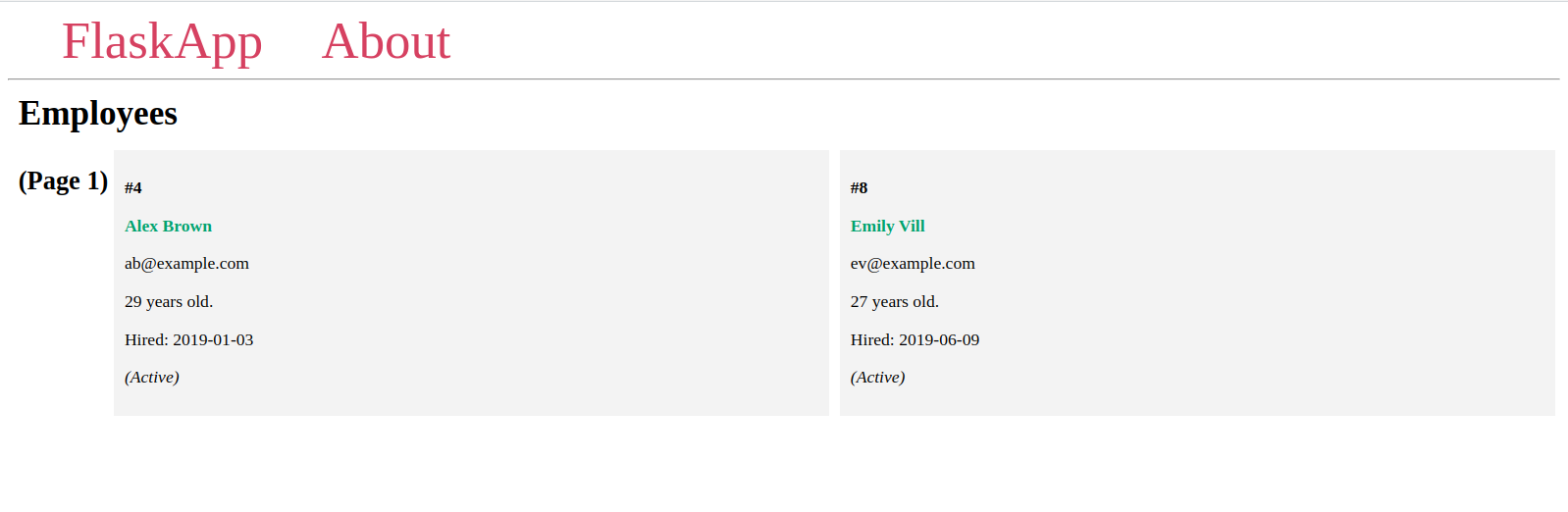
주어진 페이지 번호가 존재하지 않으면 404 Not Found HTTP 오류가 발생합니다. 앞서 나열한 URL 목록에서 마지막 URL이 해당됩니다.
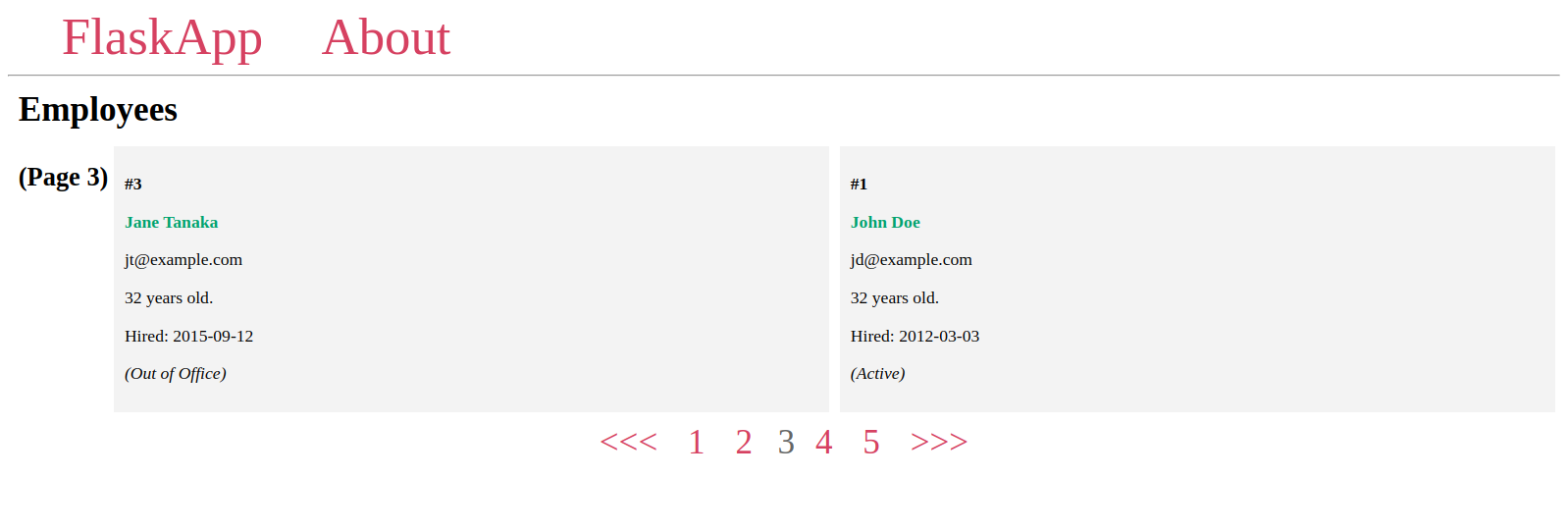
다음으로 페이지네이션 위젯을 만들어 페이지 간을 탐색할 것입니다. 페이지네이션 객체의 몇 가지 속성 및 메서드를 사용하여 모든 페이지 번호를 표시하고 각 번호가 해당 페이지로 연결되도록하며, 현재 페이지에 이전 페이지가 있으면 뒤로 가기 버튼인 <<< 버튼 및 다음 페이지가 있는 경우 다음 페이지로 이동하는 >>> 버튼을 사용할 것입니다.
페이지네이션 위젯은 다음과 같이 보일 것입니다:

추가하려면 index.html을 엽니다:
다음을 강조 표시된 div 태그를 콘텐츠 div 태그 아래에 추가하여 파일을 편집합니다:
파일을 저장하고 닫습니다.
여기서 조건문 if pagination.has_prev을 사용하여 현재 페이지가 첫 번째 페이지가 아닌 경우 이전 페이지로 이동하는 <<< 링크를 추가합니다. url_for('index', page=pagination.prev_num) 함수 호출을 사용하여 이전 페이지로 링크하고, 여기서는 pagination.prev_num 값을 page URL 매개변수에 전달하여 index 뷰 함수로 연결합니다.
사용 가능한 모든 페이지 번호에 대한 링크를 표시하려면 pagination.iter_pages() 메서드의 항목을 루프로 반복하여 각 루프에서 페이지 번호를 얻습니다.
현재 페이지 번호가 현재 루프의 번호와 같지 않은지 확인하기 위해 if pagination.page != number 조건을 사용합니다. 조건이 참이면 사용자가 현재 페이지를 다른 페이지로 변경할 수 있도록 페이지에 링크를 제공합니다. 그렇지 않으면 현재 페이지가 루프 번호와 같은 경우 링크 없이 번호를 표시합니다. 이를 통해 사용자가 페이지네이션 위젯에서 현재 페이지 번호를 알 수 있습니다.
마지막으로 현재 페이지가 다음 페이지를 가지고 있는지 확인하기 위해 pagination.has_next 조건을 사용하여 url_for('index', page=pagination.next_num) 호출과 >>> 링크를 사용하여 해당 페이지에 링크를 제공합니다.
브라우저에서 인덱스 페이지로 이동하십시오: http://127.0.0.1:5000/
페이지네이션 위젯이 완전히 작동하는 것을 확인할 수 있습니다:
여기서 >>>는 다음 페이지로 이동하기 위해 사용되고 <<<는 이전 페이지로 이동하기 위해 사용됩니다. 하지만 >와 < 또는 <img> 태그의 이미지와 같은 다른 문자도 사용할 수 있습니다.
여러 페이지에서 직원을 표시하고 Flask-SQLAlchemy에서 페이지네이션을 처리하는 방법을 배웠습니다. 이제 다른 Flask 응용 프로그램에서도 페이지네이션 위젯을 사용할 수 있습니다.
결론
Flask-SQLAlchemy를 사용하여 직원 관리 시스템을 만들었습니다. 테이블을 쿼리하고 열 값 및 간단하고 복잡한 논리적 조건을 기반으로 결과를 필터링했습니다. 쿼리 결과를 정렬, 계산 및 제한했습니다. 그리고 웹 애플리케이션에서 각 페이지에 일정한 수의 레코드를 표시하고 페이지 간에 탐색할 수 있는 페이지네이션 시스템을 만들었습니다.
이 튜토리얼에서 배운 내용을 기존의 Flask-SQLAlchemy 튜토리얼 중 일부에서 설명된 개념과 결합하여 직원 관리 시스템에 더 많은 기능을 추가할 수 있습니다:
- Flask 응용 프로그램에서 데이터베이스와 상호 작용하는 방법에 Flask-SQLAlchemy 사용하기 직원을 추가, 편집 또는 삭제하는 방법을 배우십시오.
- Flask-SQLAlchemy를 사용한 일대다 데이터베이스 관계 사용 방법 일대다 관계를 사용하여 각 직원을 속한 부서에 연결하는 부서 테이블을 만드는 방법을 배우십시오.
- Flask-SQLAlchemy를 사용하여 다대다 데이터베이스 관계를 사용하는 방법을 배우고 각 직원이 많은 작업을 가지고 있고 각 작업이 여러 직원에게 할당되는
tasks테이블을 만들고employee테이블에 연결하는 방법을 알아보세요.
Flask에 대해 더 많이 알아보고 싶다면, Flask로 웹 애플리케이션을 만드는 방법 시리즈의 다른 자습서를 확인하세요.