













Amazon Simple Storage Service (S3)는 Amazon Web Services (AWS)에서 제공하는 고도로 확장 가능하고 내구성이 뛰어나며 안전한 객체 스토리지 서비스입니다. S3을 통해 기업들은 웹상의 어디서든 어떤 양의 데이터이든 저장하고 검색할 수 있으며, 기업용 서비스를 활용합니다. S3은 매우 상호 운용성이 높아 다른 Amazon Web Services (AWS) 및 타사 도구와 기술과 원활하게 통합되어 아마존 S3에 저장된 데이터를 처리합니다. 그 중 하나가 아마존 EMR (Elastic MapReduce)로, Spark와 같은 오픈 소스 도구를 사용하여 많은 양의 데이터를 처리할 수 있습니다.
Apache Spark는 대규모 데이터 처리를 위한 오픈 소스 분산 컴퓨팅 시스템입니다. Spark는 속도를 높이기 위해 구축되었으며 아마존 S3을 포함한 다양한 데이터 소스를 지원합니다. Spark는 많은 양의 데이터를 효율적으로 처리하고 짧은 시간에 복잡한 계산을 수행할 수 있는 방법을 제공합니다.
Memphis.dev는 기존 메시지 브로커의 차세대 대안입니다. 간단하면서도 강력하고 내구성이 뛰어난 클라우드 네이티브 메시지 브로커로, 전체 생태계를 감싸고 있어 현대 큐 기반 사용 사례를 빠르고 안정적으로 개발할 수 있습니다.
메시지 브로커의 일반적인 패턴은 정의된 보존 정책(시간/크기/메시지 수)을 지나면 메시지를 삭제하는 것입니다. Memphis는 저장된 메시지에 대해 더 길거나 무한한 보존을 위한 2차 스토리지 계층을 제공합니다. 메시지가 스테이션에서 배출되면 자동으로 AWS S3인 2차 스토리지 계층으로 이동합니다.
이 튜토리얼에서는 AWS S3에 연결된 2차 스토리지 클래스를 사용하여 멤피스 스테이션을 설정하는 과정을 안내해 드리겠습니다. 이를 위해 AWS 환경을 설정한 다음, S3 버킷 생성, EMR 클러스터 설정, 클러스터에서 Apache Spark 설치 및 구성, S3에서 데이터 준비, Apache Spark를 사용한 데이터 처리, 모범 사례 및 성능 튜닝을 진행하게 됩니다.
환경 설정
Memphis
- 시작하려면 먼저 Memphis 설치를 시작하세요.
- Memphis 통합 센터를 통해 AWS S3 통합을 활성화하세요.
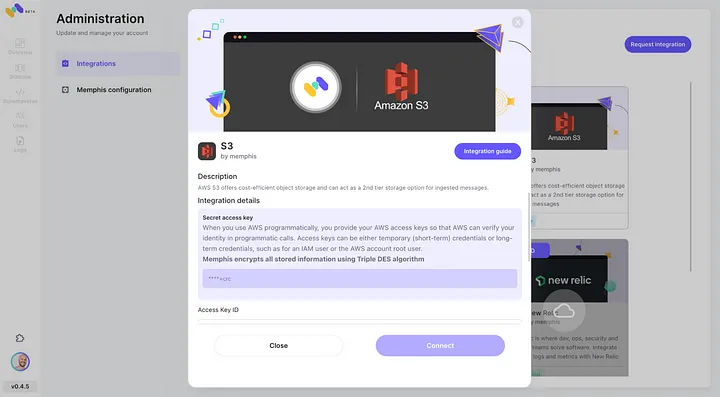
3. 스테이션(토픽)을 생성하고 보존 정책을 선택하세요.
4. 구성된 보존 정책을 통과하는 각 메시지는 S3 버킷에 오프로드됩니다.
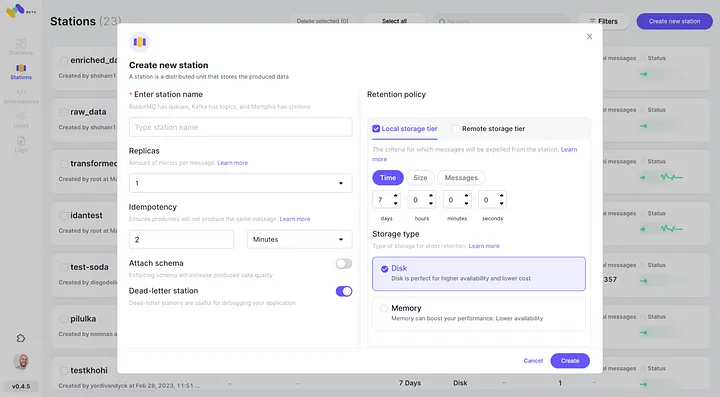
5. “연결”을 클릭하여 새로 구성된 AWS S3 통합을 2차 스토리지 클래스로 확인하세요.
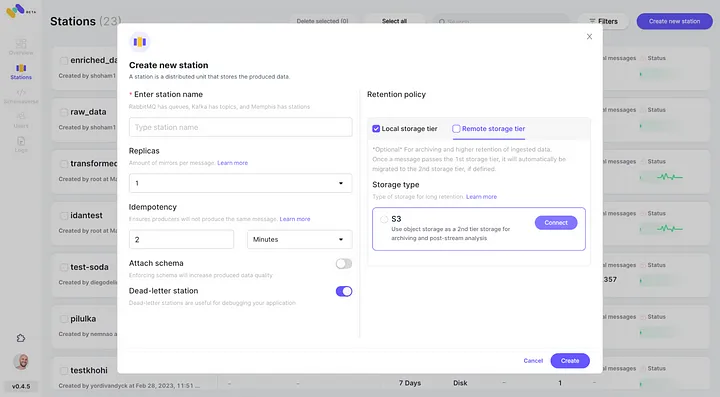
6. 새로 생성된 멤피스 스테이션에 이벤트를 생성하기 시작하세요.
AWS S3 버킷 생성
이미 수행하지 않았다면, 먼저 AWS 계정을 생성해야 합니다. 다음으로, 데이터를 저장할 S3 버킷을 생성합니다. AWS 관리 콘솔, AWS CLI 또는 SDK를 사용하여 버킷을 생성할 수 있습니다. 이 튜토리얼에서는 AWS 관리 콘솔을 사용합니다.
“버킷 생성”을 클릭하세요.
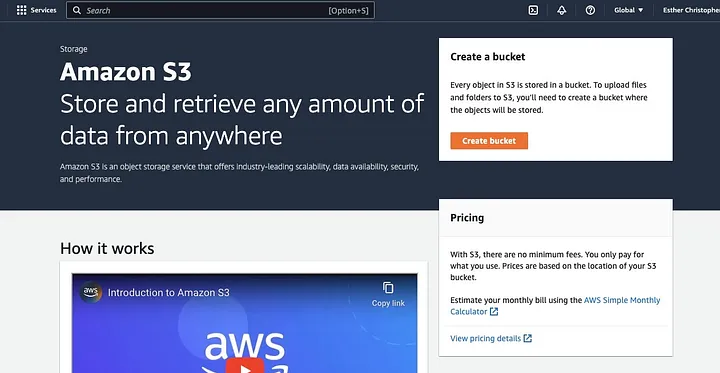
그런 다음 명명 규칙을 준수하는 버킷 이름을 생성하고 버킷이 위치할 지역을 선택합니다. “개체 소유권”과 “모든 공개 액세스 차단”을 사용 사례에 맞게 구성하세요.
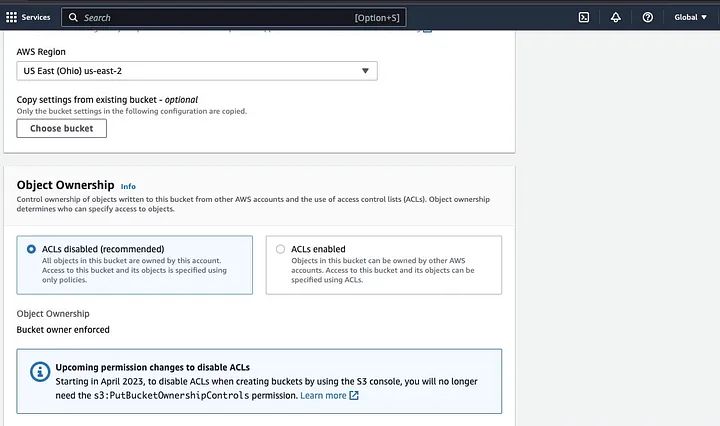
Spark 애플리케이션이 데이터에 액세스할 수 있도록 다른 버킷 권한을 구성하십시오. 마지막으로 “버킷 생성” 버튼을 클릭하여 버킷을 생성하세요.
Spark가 설치된 EMR 클러스터 설정
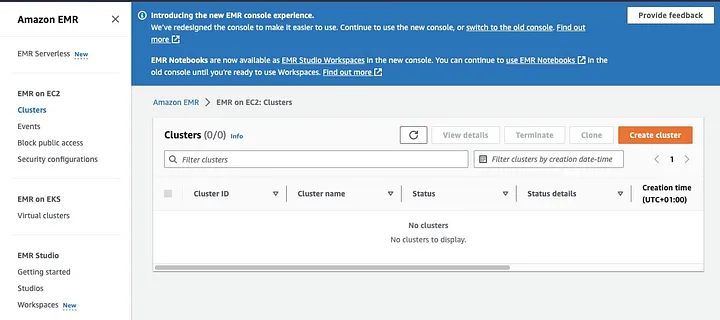
Amazon Elastic MapReduce (EMR)는 Apache Hadoop을 기반으로 하는 웹 서비스로, 사용자가 빅데이터 기술을 사용하여 막대한 양의 데이터를 비용 효율적으로 처리할 수 있도록 합니다. 이 중에는 Apache Spark도 포함되어 있습니다. Spark가 설치된 EMR 클러스터를 생성하려면 EMR 콘솔을 열고 페이지 왼쪽의 “EMR on EC2” 아래에서 “Clusters”를 선택하세요.
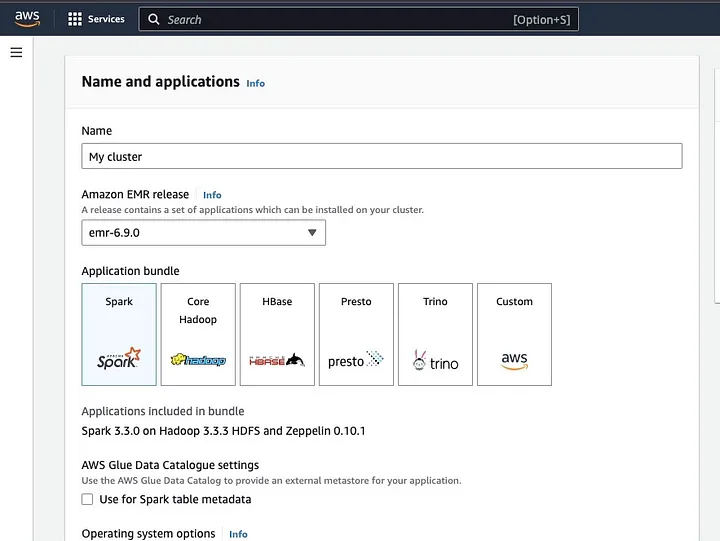
“클러스터 생성”을 클릭하고 클러스터에 대한 설명적인 이름을 지정하세요. “Application bundle” 아래에서 Spark를 선택하여 클러스터에 설치하세요.
아래로 스크롤하여 “클러스터 로그” 섹션으로 이동하고 Amazon S3에 클러스터별 로그 게시를 선택하는 체크박스를 선택하세요.
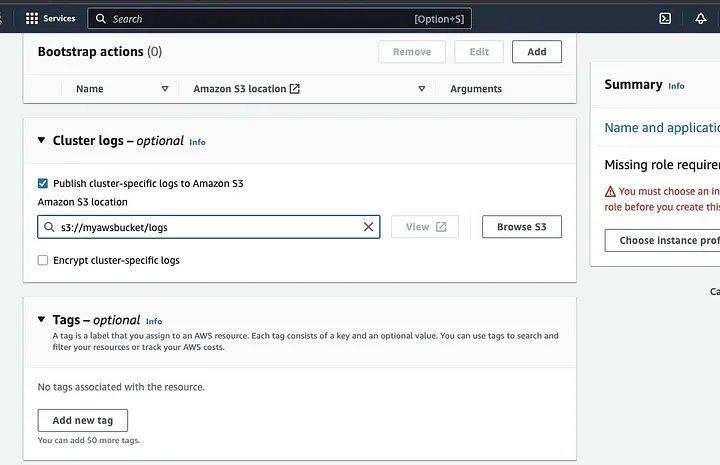
이렇게 하면 S3 버킷 이름을 사용하여 Amazon S3 위치를 입력하라는 프롬프트가 생성됩니다. 이전 단계에서 생성한 버킷 이름 뒤에 /logs를 추가하여 s3://myawsbucket/logs와 같이 입력합니다. Amazon은 클러스터의 로그 파일을 복사할 버킷 내의 새 폴더를 생성하기 위해 /logs를 필요로 합니다.
다음으로 “보안 구성 및 권한 섹션”으로 이동하여 EC2 키 페어를 입력하거나 새로 생성하는 옵션을 선택하세요.
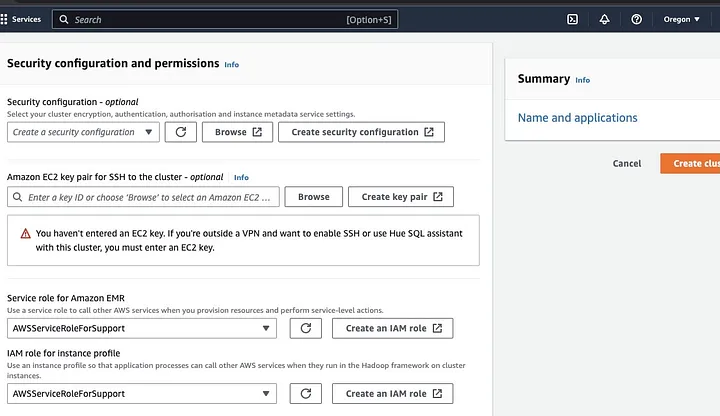
그런 다음 “Amazon EMR에 대한 서비스 역할” 드롭다운 옵션을 클릭하고 AWSServiceRoleForSupport를 선택하세요. “인스턴스 프로필에 대한 IAM 역할”에도 동일한 드롭다운 옵션을 선택하고 필요한 경우 아이콘을 새로 고치세요.
마지막으로 “클러스터 생성” 버튼을 클릭하여 클러스터를 시작하고 클러스터 상태를 모니터링하여 생성되었는지 확인하세요.
EMR 클러스터에서 Apache Spark 설치 및 구성
EMR 클러스터를 성공적으로 생성한 후 다음 단계는 EMR 클러스터에서 Apache Spark를 구성하는 것입니다. EMR 클러스터는 AWS 인프라에서 Spark 애플리케이션을 실행하기 위한 관리형 환경을 제공하여 클라우드에서 Spark 클러스터를 시작하고 관리하는 것을 간단하게 만듭니다. 데이터 및 처리 요구 사항과 함께 Spark를 구성한 다음 클러스터에 Spark 작업을 제출하여 데이터를 처리합니다.
Apache Spark를 클러스터에 보안 셸(SSH) 프로토콜로 구성할 수 있습니다. 하지만 먼저 EMR 클러스터를 생성할 때 기본적으로 설정된 SSH 보안 연결을 클러스터에 허용해야 합니다. SSH 연결을 허용하는 방법에 대한 안내서는 여기에서 찾을 수 있습니다.
SSH 연결을 생성하려면 클러스터 생성 시 선택한 EC2 키 페어를 지정해야 합니다. 그런 다음 주 노드에 연결하여 Spark 셸을 사용하여 EMR 클러스터에 연결합니다. 먼저 AWS 콘솔의 왼쪽에서 EMR on EC2로 이동하여 클러스터를 선택한 다음 원하는 퍼블릭 DNS 이름의 클러스터를 선택하여 주 노드의 마스터 퍼블릭 DNS를 가져와야 합니다.
OS 터미널에서 다음 명령어를 입력하세요.
ssh hadoop@ec2-###-##-##-###.compute-1.amazonaws.com -i ~/mykeypair.pem마스터 퍼블릭 DNS의 이름으로 ec2-###-##-##-###.compute-1.amazonaws.com를 교체하고 ~/mykeypair.pem을 .pem 파일의 파일 및 경로 이름으로 교체하세요 (이 가이드를 따라 .pem 파일을 얻으세요). 메시지가 표시되면 응답은 yes여야 하며 — SSH 명령을 닫으려면 exit를 입력하세요.
Spark를 사용하여 데이터 처리를 준비하고 S3 버킷에 업로드하기
데이터 처리를 위해 스파크가 쉽게 처리할 수 있는 형식으로 데이터를 업로드하기 전에 준비해야 합니다. 사용하는 형식은 가지고 있는 데이터의 유형과 수행할 분석에 따라 달라집니다. 사용되는 일부 형식에는 CSV, JSON 및 Parquet가 있습니다.
새로운 스파크 세션을 생성하고 관련 API를 사용하여 데이터를 스파크에 로드합니다. 예를 들어 CSV 파일을 스파크 데이터프레임으로 읽기 위해 spark.read.csv() 메서드를 사용할 수 있습니다.
데이터 처리를 위해 클러스터를 설정하고, 튜닝하고, 유지 관리할 필요가 줄어드는 관리형 Hadoop 생태계 클러스터인 Amazon EMR을 사용할 수 있습니다. 또한 Amazon SageMaker와 같은 다른 통합도 제공하며, Amazon EMR의 스파크 파이프라인에서 SageMaker 모델 훈련 작업을 시작할 수 있습니다.
데이터가 준비되면 DataFrame.write.format("s3") 메서드를 사용하여 Amazon S3 버킷의 CSV 파일을 스파크 데이터프레임으로 읽을 수 있습니다. AWS 자격 증명을 구성하고 S3 버킷에 대한 쓰기 권한이 있어야 합니다.
데이터를 저장하려는 S3 버킷 및 경로를 지정합니다. 예를 들어 df.write.format("s3").save("s3://my-bucket/path/to/data") 메서드를 사용하여 지정된 S3 버킷에 데이터를 저장할 수 있습니다.
데이터가 S3 버킷에 저장되면 다른 스파크 애플리케이션이나 도구에서 액세스하거나 추가 분석 또는 처리를 위해 다운로드할 수 있습니다. 버킷을 업로드하려면 폴더를 생성하고 처음 생성한 버킷을 선택하세요. 액션 버튼을 선택하고 드롭다운 항목에서 “폴더 만들기”를 클릭하세요. 이제 새 폴더의 이름을 지정할 수 있습니다.
버킷에 데이터 파일을 업로드하려면 데이터 폴더의 이름을 선택하세요.
업로드 — “파일 마법사”를 선택하고 파일 추가를 선택하세요.
Amazon S3 콘솔 방향에 따라 파일을 업로드하고 “업로드 시작”을 선택하세요.
데이터를 S3 버킷에 업로드하기 전에 데이터 보안에 가장 좋은 방법을 고려하고 확인하는 것이 중요합니다.
데이터 형식 및 스키마 이해
데이터 형식과 스키마는 데이터 관리에서 관련성이 있지만 완전히 다르고 중요한 개념입니다. 데이터 형식은 데이터베이스 내에서 데이터의 구성 및 구조를 나타냅니다. CSV, JSON, XML, YAML 등 다양한 형식으로 데이터를 저장할 수 있습니다. 이러한 형식은 데이터가 어떻게 구조화되어야 하는지와 다양한 유형의 데이터 및 적용 가능한 응용 프로그램을 정의합니다. 반면에 데이터 스키마는 데이터베이스 자체의 구조입니다. 데이터베이스의 레이아웃을 정의하고 데이터가 적절하게 저장되도록 합니다. 데이터베이스 스키마는 뷰, 테이블, 인덱스, 유형 및 기타 요소를 지정합니다. 이러한 개념은 분석 및 데이터베이스 시각화에 중요합니다.
S3에서 데이터 정제 및 전처리
데이터 처리 전에 오류를 확인하는 것이 필수적입니다. 시작하려면 S3 버킷에 데이터 파일을 저장한 데이터 폴더에 접근하고 로컬 시스템에 다운로드하세요. 다음으로, 데이터를 데이터 처리 도구에 로드하여 데이터를 정제하고 전처리합니다. 이 튜토리얼에서 사용하는 전처리 도구는 Amazon Athena로, Amazon S3에 저장된 비정형 및 정형 데이터를 분석하는 데 도움이 됩니다.
AWS 콘솔에서 Amazon Athena로 이동합니다.
새 테이블을 생성하려면 “Create”를 클릭하고 “CREATE TABLE”을 선택하세요.
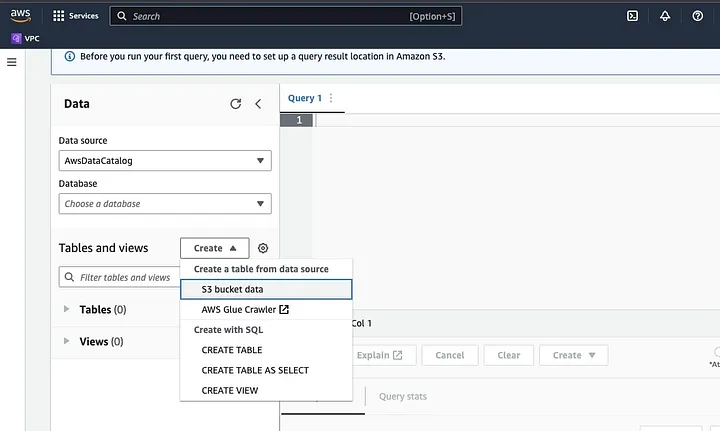
LOCATION으로 강조 표시된 부분에 데이터 파일의 경로를 입력하세요.
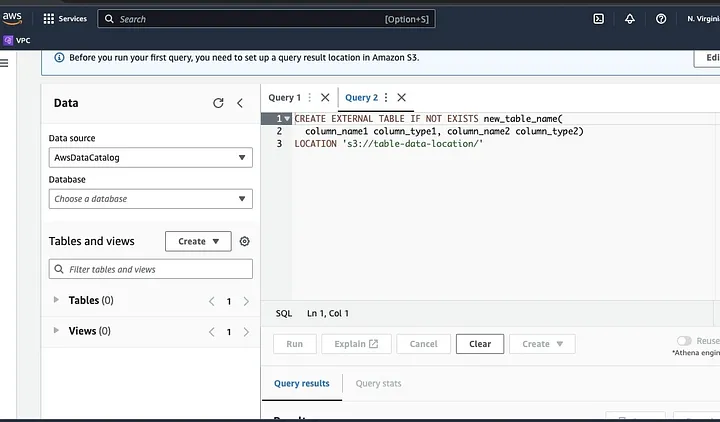
데이터의 스키마를 정의하고 테이블을 저장하기 위해 프롬프트에 따라 진행하세요. 이제 데이터가 올바르게 로드되었는지 확인하기 위해 쿼리를 실행하고 데이터를 정리하고 전처리할 수 있습니다
예시:
이 쿼리는 데이터에 중복이 있는지 식별합니다.
SELECT row1, row2, COUNT(*)
FROM table
GROUP row, row2
HAVING COUNT(*) > 1;이 예시는 중복 없이 새 테이블을 생성합니다:
CREATE TABLE new_table AS
SELECT DISTINCT *
FROM table;마지막으로 S3 버킷으로 정리된 데이터를 내보내기 위해 S3 버킷과 업로드할 폴더로 이동하세요.
Spark 프레임워크 이해하기
Spark 프레임워크는 개방형 소스, 간단하고 표현력이 풍부한 클러스터 컴퓨팅 시스템으로, 빠른 개발을 위해 구축되었습니다. 자바 프로그래밍 언어를 기반으로 하며 다른 자바 프레임워크의 대안으로 사용됩니다. Spark의 핵심 기능은 대용량 데이터 세트의 처리 속도를 높이는 메모리 내 데이터 컴퓨팅 능력입니다.
Spark를 S3와 함께 작동하도록 구성하기
Spark를 S3와 함께 작동하도록 구성하려면 Spark 애플리케이션에 Hadoop AWS 종속성을 추가하여 시작하세요. 이렇게 하려면 다음 줄을 빌드 파일(예: Scala의 build.sbt 또는 Java의 pom.xml)에 추가하세요:
libraryDependencies += "org.apache.hadoop" % "hadoop-aws" % "3.3.1"Spark 애플리케이션에 AWS 액세스 키 ID와 비밀 액세스 키를 입력하려면 다음 구성 속성을 설정하세요:
spark.hadoop.fs.s3a.access.key <ACCESS_KEY_ID>
spark.hadoop.fs.s3a.secret.key <SECRET_ACCESS_KEY>코드에서 SparkConf 객체를 사용하여 다음 속성을 설정하세요:
val conf = new SparkConf()
.set("spark.hadoop.fs.s3a.access.key", "<ACCESS_KEY_ID>")
.set("spark.hadoop.fs.s3a.secret.key", "<SECRET_ACCESS_KEY>")Spark 애플리케이션에서 S3 엔드포인트 URL을 설정하려면 다음 구성 속성을 설정하세요:
spark.hadoop.fs.s3a.endpoint s3.<REGION>.amazonaws.com
<REGION>을 S3 버킷이 위치한 AWS 리전으로 교체하세요(예: us-east-1).
Hadoop의 S3 클라이언트가 S3 요청에 대한 액세스 권한을 부여하기 위해 DNS 호환 버킷 이름이 필요합니다. 버킷 이름에 점이나 밑줄이 포함된 경우 Hadoop의 S3 클라이언트에서 가상 호스트 스타일을 사용하므로 경로 스타일 액세스를 사용하도록 설정해야 할 수도 있습니다. 다음 구성 속성을 설정하여 경로 액세스를 활성화하세요:
spark.hadoop.fs.s3a.path.style.access true
마지막으로 S3 구성으로 Spark 세션을 생성하려면 Spark 구성에서 spark.hadoop 접두사를 설정하세요:
val spark = SparkSession.builder()
.appName("MyApp")
.config("spark.hadoop.fs.s3a.access.key", "<ACCESS_KEY_ID>")
.config("spark.hadoop.fs.s3a.secret.key", "<SECRET_ACCESS_KEY>")
.config("spark.hadoop.fs.s3a.endpoint", "s3.<REGION>.amazonaws.com")
.getOrCreate()
<ACCESS_KEY_ID>, <SECRET_ACCESS_KEY>, <REGION> 필드를 각각 사용자의 AWS 자격 증명과 S3 리전으로 교체하세요.
Spark에서 S3의 데이터를 읽으려면 spark.read 메서드를 사용하고 S3 경로를 입력 소스로 지정하세요.
다음은 S3에서 CSV 파일을 DataFrame으로 읽는 방법을 보여주는 예시 코드입니다:
val spark = SparkSession.builder()
.appName("ReadDataFromS3")
.getOrCreate()
val df = spark.read
.option("header", "true") // Specify whether the first line is the header or not
.option("inferSchema", "true") // Infer the schema automatically
.csv("s3a://<BUCKET_NAME>/<FILE_PATH>")
이 예제에서 <BUCKET_NAME>을 사용자의 S3 버킷 이름으로, <FILE_PATH>를 버킷 내의 CSV 파일 경로로 교체하세요.
Spark로 데이터 변환하기
스파크를 사용한 데이터 변환은 일반적으로 데이터를 정리, 필터링, 집계, 그리고 데이터를 조인하는 작업을 의미합니다. 스파크는 데이터 변환을 위한 다양한 API를 제공합니다. 이들에는 DataFrame, Dataset, RDD API가 포함됩니다. 스파크에서 일반적인 데이터 변환 작업에는 필터링, 열 선택, 데이터 집계, 데이터 조인, 데이터 정렬이 있습니다.
다음은 데이터 변환 작업의 한 예입니다:
데이터 정렬: 이 작업은 하나 이상의 열을 기준으로 데이터를 정렬하는 것을 포함합니다. DataFrame이나 Dataset에서 orderBy나 sort 메서드를 사용하여 하나 이상의 열을 기준으로 데이터를 정렬합니다. 예를 들어:
val sortedData = df.orderBy(col("age").desc)마지막으로, 결과를 S3에 다시 쓰기 위해 결과를 저장해야 할 수도 있습니다.
스파크는 DataFrameWriter, DatasetWriter, RDD.saveAsTextFile과 같은 S3에 데이터를 쓰기 위한 다양한 API를 제공합니다.
다음은 DataFrame을 S3에 Parquet 형식으로 쓰는 방법을 보여주는 코드 예제입니다:
val outputS3Path = "s3a://<BUCKET_NAME>/<OUTPUT_DIRECTORY>"
df.write
.mode(SaveMode.Overwrite)
.option("compression", "snappy")
.parquet(outputS3Path)입력 필드인 <BUCKET_NAME>을 사용자의 S3 버킷 이름으로 대체하고, <OUTPUT_DIRECTORY>를 버킷 내의 출력 디렉토리 경로로 대체하세요.
mode 메서드는 쓰기 모드를 지정하며, 이는 Overwrite, Append, Ignore, ErrorIfExists 중 하나일 수 있습니다. option 메서드는 압축 코덱과 같은 출력 형식에 대한 다양한 옵션을 지정하는 데 사용할 수 있습니다.
CSV, JSON, Avro와 같은 다른 형식으로 S3에 데이터를 쓸 수도 있으며, 출력 형식을 변경하고 적절한 옵션을 지정하면 됩니다.
Spark에서 데이터 분할 이해하기
간단히 말해, Spark에서 데이터 분할은 데이터셋을 클러스터 내에서 더 작고 관리하기 쉬운 부분으로 나누는 것을 말합니다. 이 목적은 성능을 최적화하고, 확장성을 감소시키며 결국 데이터베이스 관리 가능성을 향상시키는 것입니다. Spark에서 데이터는 여러 클러스터에서 병렬로 처리됩니다. 이는 거대하고 복잡한 데이터 컬렉션인 회복성 있는 분산 데이터셋(RDD)으로 가능합니다. 기본적으로 RDD는 그 크기 때문에 여러 노드에 걸쳐 분할됩니다.
최적의 성능을 달성하기 위해, Spark를 구성하여 작업이 빠르게 실행되고 리소스가 효과적으로 관리되도록 할 수 있습니다. 이러한 방법 중 일부로는 캐싱, 메모리 관리, 데이터 직렬화, 그리고 mapPartitions()를 map()보다 사용하는 것이 있습니다.
Spark UI는 웹 기반의 그래픽 사용자 인터페이스로, Spark 애플리케이션의 성능과 리소스 사용에 대한 자세한 정보를 제공합니다. 개요, 실행자, 단계, 작업 등 다양한 측면의 Spark 작업에 대한 정보를 제공하는 여러 페이지를 포함합니다. Spark UI는 Spark 애플리케이션을 모니터링하고 디버깅하는 데 필수적인 도구로, 성능 병목 현상과 리소스 제약을 식별하고 오류를 해결하는 데 도움이 됩니다. 완료된 작업 수, 작업 기간, CPU 및 메모리 사용량, 셔플 데이터 읽기 및 쓰기와 같은 메트릭을 검사함으로써 사용자는 그들의 Spark 작업을 최적화하고 효율적으로 실행되도록 할 수 있습니다.
결론
요약하자면, AWS S3에서 Apache Spark를 사용하여 데이터를 처리하는 것은 거대한 데이터 세트를 분석하는 효과적이고 확장 가능한 방법입니다. AWS S3와 Apache Spark의 클라우드 기반 스토리지 및 컴퓨팅 리소스를 활용하면 사용자들은 아키텍처 관리에 대해 걱정하지 않고 데이터를 빠르고 효과적으로 처리할 수 있습니다.
이 튜토리얼에서는 AWS EMR에서 S3 버킷과 Apache Spark 클러스터를 설정하고, Spark를 AWS S3와 함께 작동하도록 구성하며, 데이터 처리를 위한 Spark 애플리케이션을 작성하고 실행하는 방법을 살펴보았습니다. 또한 Spark에서의 데이터 파티셔닝, Spark UI 및 Spark에서의 성능 최적화에 대해서도 다루었습니다.
참조
Spark를 최적의 성능으로 구성하는 방법에 대해 더 깊이 알고 싶다면 여기를 참조하세요.
https://docs.aws.amazon.com/emr/latest/ManagementGuide/emr-connect-master-node-ssh.html
Source:
https://dzone.com/articles/stateful-stream-processing-with-memphis-and-apache-spark