













소개
행과 열의 테이블로 데이터를 구성하는 관계형 데이터 모델은 데이터베이스 관리 도구에서 주류를 이룹니다. 오늘날에는 NoSQL과 NewSQL을 포함한 다른 데이터 모델이 있지만, 관계형 데이터베이스 관리 시스템(RDBMS)은 전 세계적으로 데이터를 저장하고 관리하는 데 지배적인 위치를 유지합니다.
본 문서에서는 가장 널리 사용되는 오픈 소스 RDBMS인 SQLite, MySQL, 그리고 PostgreSQL을 비교하고 대조합니다. 구체적으로 각 RDBMS가 사용하는 데이터 유형, 이점 및 단점, 그리고 최적화된 상황을 탐색할 것입니다.
A Bit About Database Management Systems
데이터베이스는 정보 또는 데이터의 논리적으로 모델링된 집합입니다. 반면에 데이터베이스 관리 시스템(DBMS)은 데이터베이스와 상호 작용하는 컴퓨터 프로그램입니다. DBMS를 사용하면 데이터베이스에 대한 액세스를 제어하고 데이터를 작성하고 쿼리를 실행하며 데이터베이스 관리와 관련된 기타 작업을 수행할 수 있습니다.
데이터베이스 관리 시스템은 종종 “데이터베이스”라고 불리지만, 두 용어는 서로 대체할 수 없습니다. 데이터베이스는 컴퓨터에 저장된 것뿐만 아니라 모든 데이터 모음일 수 있습니다. 반면에 DBMS는 특별히 데이터베이스와 상호 작용할 수 있게 해주는 소프트웨어를 가리킵니다.
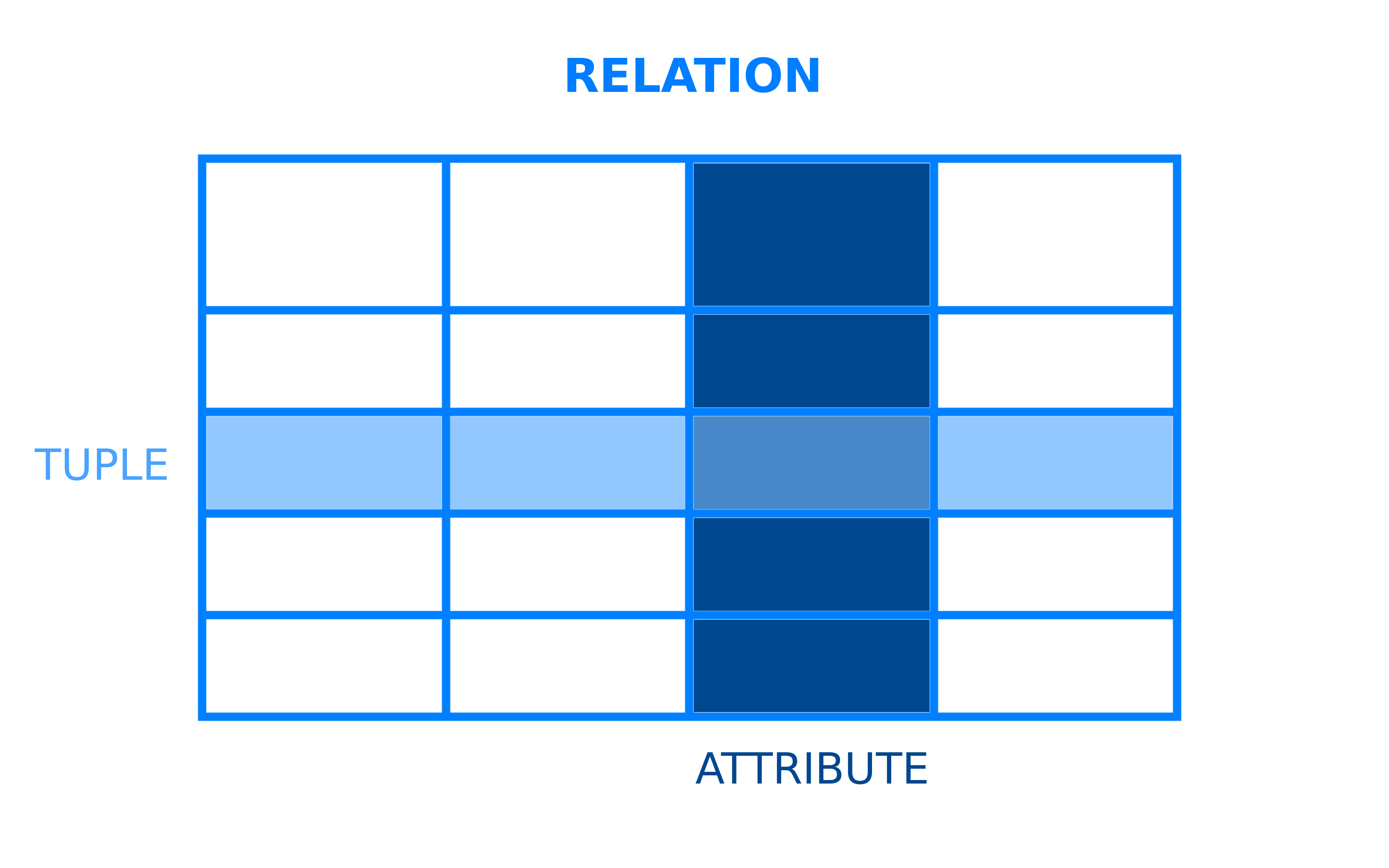
모든 데이터베이스 관리 시스템은 데이터가 저장되고 액세스되는 방식을 구조화하는 기본 모델이 있습니다. 관계형 데이터베이스 관리 시스템은 관계형 데이터 모델을 사용하는 DBMS입니다. 이 관계형 모델에서 데이터는 테이블로 구성됩니다. RDBMS의 맥락에서 테이블은 더 공식적으로 관계라고 합니다. 관계는 테이블의 행인 튜플의 집합이며, 각 튜플은 테이블의 열인 속성 집합을 공유합니다:
대부분의 관계형 데이터베이스는 데이터를 관리하고 쿼리하기 위해 구조화된 질의 언어(SQL)를 사용합니다. 그러나 많은 RDBMS는 자체 특정한 SQL 방언을 사용하며, 이는 특정한 제한 사항이나 확장을 가질 수 있습니다. 이러한 확장에는 일반적인 SQL로는 수행할 수 없는 복잡한 작업을 수행할 수 있도록 하는 추가 기능이 주로 포함됩니다.
참고: 이 가이드에서 “표준 SQL”이라는 용어가 여러 번 등장합니다. SQL 표준은 미국 국가 표준 협회(ANSI), 국제 표준화 기구(ISO), 국제 전기 기술 위원회(IEC)가 공동으로 유지합니다. 이 기사에서 “표준 SQL” 또는 “SQL 표준”이라고 언급할 때는 이들 단체가 발표한 현재 버전의 SQL 표준을 의미합니다.
주의해야 할 점은 완전한 SQL 표준이 크고 복잡하다는 것입니다: 완전한 핵심 SQL:2011 준수에는 179개의 기능이 필요합니다. 이로 인해 대부분의 RDBMS는 전체 표준을 지원하지 않지만, 일부는 다른 것보다 더 가까이 완전한 준수에 다가가기도 합니다.
데이터 유형 및 제약
각 열에는 해당 열에 허용된 항목의 종류를 지시하는 데이터 유형이 할당됩니다. 서로 다른 RDBMS는 서로 다른 데이터 유형을 구현하며, 이는 항상 직접 교환할 수 없습니다. 일부 일반적인 데이터 유형에는 날짜, 문자열, 정수 및 부울이 포함됩니다.
데이터베이스에 정수를 저장하는 것은 테이블에 숫자를 넣는 것보다 미묘합니다. 숫자 데이터 유형은 양수와 음수를 모두 나타낼 수 있는 부호가 있는 것이거나, 오직 양수만을 나타낼 수 있는 부호가 없는 것일 수 있습니다. 예를 들어, MySQL의 tinyint 데이터 유형은 8비트의 데이터를 보유할 수 있으며, 이는 256개의 가능한 값과 동일합니다. 이 데이터 유형의 부호 있는 범위는 -128에서 127이며, 부호 없는 범위는 0에서 255까지입니다.
데이터베이스로 허용되는 데이터를 제어하는 것은 중요합니다. 때로는 데이터베이스 관리자가 테이블에 제한된 값만 입력할 수 있도록 제약 조건을 부과할 것입니다. 제약 조건은 일반적으로 한 특정 열에 적용되지만, 일부 제약 조건은 전체 테이블에도 적용될 수 있습니다. 여기 일반적으로 사용되는 몇 가지 제약 조건이 있습니다.
고유: 이 제약을 열에 적용하면 해당 열의 두 항목이 동일하지 않음이 보장됩니다.NOT NULL: 이 제약은 열이NULL항목을 포함하지 않도록 보장합니다.기본 키:UNIQUE와NOT NULL의 조합으로,기본 키제약은 열에 항목이NULL이 아니며 모든 항목이 고유하다는 것을 보장합니다.외래 키:외래 키는 다른 테이블의기본 키를 참조하는 한 테이블의 열입니다. 이 제약은 두 개의 테이블을 연결하는 데 사용됩니다.외래 키열에 대한 항목은 쓰기 프로세스가 성공하려면 부모기본 키열에 이미 존재해야 합니다.체크: 이 제약은 열에 입력할 수 있는 값의 범위를 제한합니다. 예를 들어, 응용 프로그램이 알래스카 거주자를 대상으로 하는 경우 ZIP 코드 열에체크제약을 추가하여 99501에서 99950 사이의 항목만 허용할 수 있습니다.
데이터베이스 관리 시스템에 대해 자세히 알아보려면, 비관계형 데이터베이스 관리 시스템과 모델 비교 기사를 확인하십시오.
이제 일반적으로 관계형 데이터베이스 관리 시스템을 다루었으니, 이 기사에서 다룰 세 가지 오픈 소스 관계형 데이터베이스 중 첫 번째인 SQLite로 이동해 보겠습니다.
SQLite
SQLite는 자체 포함형, 파일 기반 및 완전히 오픈 소스 RDBMS로 알려져 있으며 휴대성, 신뢰성 및 낮은 메모리 환경에서도 강력한 성능으로 유명합니다. 해당 트랜잭션은 ACID 규정을 준수하며 시스템이 충돌하거나 전원 공급이 중단된 경우에도 유지됩니다.
SQLite 프로젝트 웹사이트는 이를 “서버 없는” 데이터베이스로 설명합니다. 대부분의 관계형 데이터베이스 엔진은 프로그램이 요청을 중계하는 프로세스 간 통신을 통해 호스트 서버와 통신하는 서버 프로세스로 구현됩니다. 반면에 SQLite는 데이터베이스에 액세스하는 모든 프로세스가 데이터베이스 디스크 파일에 직접 읽고 쓸 수 있도록 허용합니다. 이로써 SQLite의 설치 과정이 단순화되며 서버 프로세스를 구성할 필요가 없어집니다. 마찬가지로, SQLite 데이터베이스를 사용할 프로그램에 대해 별도의 구성이 필요하지 않습니다. 그들이 필요로 하는 것은 디스크에 액세스하는 것뿐입니다.
SQLite는 무료이며 오픈 소스 소프트웨어이며 사용에 특별한 라이선스가 필요하지 않습니다. 그러나 프로젝트는 압축 및 암호화에 도움이 되는 여러 확장 기능을 각각 일시불로 제공하며, 프로젝트는 연간 요금으로 각종 상업용 지원 패키지도 제공합니다.
SQLite의 지원하는 데이터 유형
SQLite는 다양한 데이터 유형을 허용하며, 다음과 같은 저장 클래스로 구성됩니다:
| Data Type | Explanation |
|---|---|
null |
Includes any NULL values. |
integer |
Signed integers, stored in 1, 2, 3, 4, 6, or 8 bytes depending on the magnitude of the value. |
real |
Real numbers, or floating point values, stored as 8-byte floating point numbers. |
text |
Text strings stored using the database encoding, which can either be UTF-8, UTF-16BE or UTF-16LE. |
blob |
Any blob of data, with every blob stored exactly as it was input. |
SQLite의 맥락에서 “저장 클래스”와 “데이터 유형”이라는 용어는 서로 교환 가능한 것으로 간주됩니다. SQLite의 데이터 유형 및 SQLite 형 호환성에 대해 자세히 알아보려면 SQLite의 공식 문서를 확인하십시오.
SQLite의 장점
- 작은 풋프린트: 이름에서 알 수 있듯이, SQLite 라이브러리는 매우 가벼워요. 설치된 시스템에 따라 사용하는 공간이 다르지만, 600KiB 미만의 공간을 차지할 수 있습니다. 게다가 완전히 자체 포함되어 있으므로 SQLite가 작동하려면 시스템에 설치해야 하는 외부 종속성이 없습니다.
- 사용자 친화적: SQLite는 때로 “설정이 필요 없는” 데이터베이스로 설명되며 즉시 사용할 수 있는 상태로 제공됩니다. SQLite는 서버 프로세스로 실행되지 않기 때문에 멈추거나 시작하거나 다시 시작할 필요가 없으며 관리해야 할 구성 파일도 없습니다. 이러한 기능들은 SQLite를 설치에서부터 응용 프로그램과 통합하는 경로를 간소화하는 데 도움이 됩니다.
- 휴대용: 다른 데이터베이스 관리 시스템과 달리, 일반적으로 데이터를 여러 개의 별도 파일로 저장하는 대신 전체 SQLite 데이터베이스가 단일 파일에 저장됩니다. 이 파일은 디렉터리 계층구조 어디에서나 찾을 수 있으며 이동식 미디어나 파일 전송 프로토콜을 통해 공유할 수 있습니다.
SQLite의 단점
- 제한된 동시성: 여러 프로세스가 동시에 SQLite 데이터베이스에 액세스하고 쿼리할 수 있지만 한 번에 하나의 프로세스만 데이터베이스를 변경할 수 있습니다. 이는 SQLite가 대부분의 다른 내장형 데이터베이스 관리 시스템보다 더 큰 동시성을 지원하지만 MySQL이나 PostgreSQL과 같은 클라이언트/서버 RDBMS만큼은 지원하지 못한다는 것을 의미합니다.
- 사용자 관리 없음: 데이터베이스 시스템은 종종 데이터베이스와 테이블에 대한 미리 정의된 액세스 권한을 가진 사용자 또는 관리된 연결을 지원합니다. SQLite는 일반 디스크 파일에 직접 읽고 쓰기 때문에 적용 가능한 액세스 권한은 기본 운영 체제의 전형적인 액세스 권한뿐입니다. 이로 인해 SQLite는 특별한 액세스 권한을 필요로 하는 다중 사용자 애플리케이션에는 적합하지 않습니다.
- 보안: 서버를 사용하는 데이터베이스 엔진은 때로는 서버 없는 데이터베이스인 SQLite보다 클라이언트 애플리케이션의 버그로부터 더 나은 보호를 제공할 수 있습니다. 예를 들어, 클라이언트의 이동 포인터는 서버의 메모리를 손상시킬 수 없습니다. 또한, 서버가 단일 지속적인 프로세스이기 때문에 클라이언트-서버 데이터베이스는 더 정밀한 데이터 액세스를 제어하고 더 세밀한 잠금 및 더 나은 병행성을 가능하게 합니다.
SQLite를 사용해야 하는 경우
- 내장 애플리케이션: SQLite는 휴대성이 필요하고 미래의 확장이 필요하지 않은 애플리케이션에 대한 데이터베이스로 좋은 선택입니다. 예로는 단일 사용자 로컬 애플리케이션, 모바일 애플리케이션 또는 게임이 있습니다.
- 디스크 액세스 대체: 애플리케이션이 직접 디스크에 파일을 읽고 쓰는 경우 SQL을 사용하는 추가 기능과 단숨함을 활용하기 위해 SQLite를 사용하는 것이 유익할 수 있습니다.
- 테스트: 많은 응용 프로그램에서는 추가 서버 프로세스를 사용하는 DBMS로 기능을 테스트하는 것이 지나칠 수 있습니다. SQLite에는 실제 데이터베이스 작업의 오버헤드 없이 빠르게 테스트할 수 있는 인메모리 모드가 있어 테스트에 이상적인 선택지입니다.
SQLite를 사용하지 말아야 할 때
- 많은 양의 데이터를 처리할 때: SQLite는 이론적으로 디스크 드라이브와 파일 시스템이 데이터베이스 크기 요구 사항을 지원한다면 최대 140TB 크기의 데이터베이스를 지원할 수 있습니다. 그러나 SQLite 웹 사이트에서는 1TB에 가까운 데이터베이스는 중앙 집중식 클라이언트-서버 데이터베이스에 저장하는 것이 좋다고 권장합니다. 왜냐하면 해당 크기 이상의 SQLite 데이터베이스를 관리하기 어렵기 때문입니다.
- 높은 쓰기 볼륨: SQLite는 한 번에 하나의 쓰기 작업만 수행할 수 있으며, 이는 처리량을 크게 제한합니다. 응용 프로그램이 많은 쓰기 작업이나 병렬 작성자가 여럿 필요한 경우 SQLite는 적합하지 않을 수 있습니다.
- 네트워크 액세스가 필요합니다: SQLite는 서버가 없는 데이터베이스이기 때문에 데이터에 대한 직접적인 네트워크 액세스를 제공하지 않습니다. 이 액세스는 응용 프로그램에 내장되어 있어야 합니다. SQLite의 데이터가 응용 프로그램과 별도의 기계에 위치한 경우, 네트워크를 통한 엔진-디스크 링크가 필요합니다. 이는 비용이 많이 들며 비효율적인 솔루션이며, 이러한 경우 클라이언트-서버 DBMS가 더 나은 선택일 수 있습니다.
MySQL
DB-Engines Ranking에 따르면 MySQL은 2012년부터 데이터베이스 인기를 추적하기 시작한 이후 가장 인기 있는 오픈 소스 RDBMS입니다. Twitter, Facebook, Netflix 및 Spotify를 포함한 많은 세계 최대의 웹 사이트 및 응용 프로그램을 구동하는 기능이 풍부한 제품입니다. MySQL을 시작하는 것은 비교적 간단합니다. 이는 체계적인 설명서와 큰 개발자 커뮤니티 덕분에 가능하며 온라인에서 MySQL 관련 자료가 풍부하기 때문입니다.
MySQL은 속도와 신뢰성을 위해 설계되었으며 표준 SQL의 완전한 준수를 희생했습니다. MySQL 개발자들은 지속적으로 표준 SQL에 더 가까워지기 위해 노력하고 있지만 여전히 다른 SQL 구현에 뒤처지고 있습니다. 그러나 이는 가까운 준수로 이끄는 다양한 SQL 모드와 확장 기능을 제공합니다.
SQLite를 사용하는 애플리케이션과는 달리, MySQL 데이터베이스를 사용하는 애플리케이션은 별도의 데몬 프로세스를 통해 액세스합니다. 서버 프로세스가 데이터베이스와 다른 애플리케이션 사이에 위치하기 때문에 데이터베이스에 액세스할 수 있는 사용자를 보다 더 잘 제어할 수 있습니다.
MySQL은 기능을 확장하고 작업을 더욱 쉽게 만들어 주는 다양한 타사 애플리케이션, 도구 및 통합 라이브러리를 영감을 받았습니다. 이러한 타사 도구 중 일부는 phpMyAdmin, DBeaver, 그리고 HeidiSQL 등이 있습니다.
MySQL의 지원하는 데이터 유형
MySQL의 데이터 유형은 숫자 유형, 날짜 및 시간 유형, 문자열 유형으로 세 가지 넓은 범주로 구성될 수 있습니다.
숫자 유형:
| Data Type | Explanation |
|---|---|
tinyint |
A very small integer. The signed range for this numeric data type is -128 to 127, while the unsigned range is 0 to 255. |
smallint |
A small integer. The signed range for this numeric type is -32768 to 32767, while the unsigned range is 0 to 65535. |
mediumint |
A medium-sized integer. The signed range for this numeric data type is -8388608 to 8388607, while the unsigned range is 0 to 16777215. |
int or integer |
A normal-sized integer. The signed range for this numeric data type is -2147483648 to 2147483647, while the unsigned range is 0 to 4294967295. |
bigint |
A large integer. The signed range for this numeric data type is -9223372036854775808 to 9223372036854775807, while the unsigned range is 0 to 18446744073709551615. |
float |
A small (single-precision) floating-point number. |
double, double precision, or real |
A normal sized (double-precision) floating-point number. |
dec, decimal, fixed, or numeric |
A packed fixed-point number. The display length of entries for this data type is defined when the column is created, and every entry adheres to that length. |
bool or boolean |
A Boolean is a data type that only has two possible values, usually either true or false. |
bit |
A bit value type for which you can specify the number of bits per value, from 1 to 64. |
날짜 및 시간 유형:
| Data Type | Explanation |
|---|---|
date |
A date, represented as YYYY-MM-DD. |
datetime |
A timestamp showing the date and time, displayed as YYYY-MM-DD HH:MM:SS. |
timestamp |
A timestamp indicating the amount of time since the Unix epoch (00:00:00 on January 1, 1970). |
time |
A time of day, displayed as HH:MM:SS. |
year |
A year expressed in either a 2 or 4 digit format, with 4 digits being the default. |
문자열 유형:
| Data Type | Explanation |
|---|---|
char |
A fixed-length string; entries of this type are padded on the right with spaces to meet the specified length when stored. |
varchar |
A string of variable length. |
binary |
Similar to the char type, but a binary byte string of a specified length rather than a nonbinary character string. |
varbinary |
Similar to the varchar type, but a binary byte string of a variable length rather than a nonbinary character string. |
blob |
A binary string with a maximum length of 65535 (2^16 – 1) bytes of data. |
tinyblob |
A blob column with a maximum length of 255 (2^8 – 1) bytes of data. |
mediumblob |
A blob column with a maximum length of 16777215 (2^24 – 1) bytes of data. |
longblob |
A blob column with a maximum length of 4294967295 (2^32 – 1) bytes of data. |
text |
A string with a maximum length of 65535 (2^16 – 1) characters. |
tinytext |
A text column with a maximum length of 255 (2^8 – 1) characters. |
mediumtext |
A text column with a maximum length of 16777215 (2^24 – 1) characters. |
longtext |
A text column with a maximum length of 4294967295 (2^32 – 1) characters. |
enum |
An enumeration, which is a string object that takes a single value from a list of values that are declared when the table is created. |
set |
Similar to an enumeration, a string object that can have zero or more values, each of which must be chosen from a list of allowed values that are specified when the table is created. |
MySQL의 장점
- 인기와 사용 편의성: 세계에서 가장 인기 있는 데이터베이스 시스템 중 하나로, MySQL을 다루는 경험이 있는 데이터베이스 관리자가 부족하지 않습니다. 마찬가지로 MySQL 데이터베이스를 설치하고 관리하는 방법에 대한 인쇄 및 온라인 문서가 풍부하게 있습니다. 이에는 데이터베이스를 시작하는 과정을 단순화하기 위한 여러 서드파티 도구 — 예를 들어 phpMyAdmin — 도 포함됩니다.
- 보안: MySQL은 설치된 스크립트를 통해 데이터베이스의 보안을 향상시키는 데 도움을 줍니다. 이를 통해 설치의 암호 보안 수준을 설정하고 root 사용자에 대한 암호를 정의하고 익명 계정을 제거하며 모든 사용자가 기본적으로 액세스할 수 있는 테스트 데이터베이스를 제거할 수 있습니다. 또한 SQLite와 달리 MySQL은 사용자 관리를 지원하며 사용자별로 액세스 권한을 부여할 수 있습니다.
- 속도: 특정 SQL 기능을 구현하지 않고 선택함으로써 MySQL 개발자들은 속도를 우선시킬 수 있었습니다. 최근의 벤치마크 테스트는 PostgreSQL과 같은 다른 RDBMS가 속도 측면에서 MySQL과 일치하거나 적어도 가까이 미칠 수 있다는 것을 보여줍니다. 그럼에도 불구하고 MySQL은 여전히 뛰어난 빠른 데이터베이스 솔루션으로 평가받고 있습니다.
- 복제: MySQL은 신뢰성, 가용성 및 오류 허용성을 향상시키기 위해 두 개 이상의 호스트 간에 정보를 공유하는 여러 유형의 복제를 지원합니다. 이것은 데이터베이스 백업 솔루션을 설정하거나 수평 확장을 위한 데이터베이스를 설정하는 데 도움이 됩니다.
MySQL의 단점
- 알려진 제한 사항: MySQL은 전체 SQL 규정 준수보다는 속도와 사용 편의성을 고려하여 설계되었기 때문에 특정 기능적 제한이 있습니다. 예를 들어,
FULL JOIN절을 지원하지 않습니다. - 라이선싱 및 전용 기능: MySQL은 무료 및 오픈 소스 커뮤니티 에디션인 GPLv2로 라이선스가 부여된 듀얼 라이선스 소프트웨어이며, 여러 유료 상용 에디션은 전용 라이선스로 출시됩니다. 이로 인해 일부 기능 및 플러그인은 전용 에디션에서만 사용할 수 있습니다.
- 개발 지연: 2008년 MySQL 프로젝트가 Sun Microsystems에 인수되고, 이후 2009년 Oracle Corporation에 인수된 이후로, DBMS에 대한 개발 프로세스가 크게 둔화되었다는 사용자들의 불만이 있었습니다. 커뮤니티가 문제에 빠르게 대응하고 변경 사항을 구현할 수 있는 권한을 더 이상 가지고 있지 않기 때문입니다.
MySQL을 사용해야 할 때
- 분산 작업: MySQL의 복제 지원으로 인해 기본-보조 또는 기본-기본 아키텍처와 같은 분산 데이터베이스 설정에 좋은 선택입니다.기본-보조 또는 기본-기본 아키텍처입니다.
- 웹사이트 및 웹 애플리케이션: MySQL은 인터넷 전역의 많은 웹사이트 및 애플리케이션을 구동합니다. 이는 MySQL 데이터베이스를 설치하고 설정하는 것이 얼마나 쉬운지, 그리고 장기적으로 전반적인 속도와 확장성 때문입니다.
- 예상되는 미래 성장: MySQL의 복제 지원은 수평 스케일링을 용이하게 할 수 있습니다. 또한, 상용 MySQL 제품인 MySQL Cluster로 업그레이드하는 과정은 상당히 간단합니다. MySQL Cluster는 자동 샤딩을 지원하며, 이는 또 다른 수평 스케일링 프로세스입니다.
MySQL을 사용하지 말아야 할 때
- SQL 규정 준수가 필요한 경우: MySQL은 완전한 SQL 표준을 구현하려고 하지 않기 때문에 이 도구는 완전히 SQL 준수가 아닙니다. 완전하거나 거의 완전한 SQL 준수가 사용 사례에 필수적인 경우, 더 완전히 준수하는 DBMS를 사용하는 것이 좋습니다.
- 동시성 및 대량의 데이터 볼륨: MySQL은 일반적으로 읽기 중심 작업에서 잘 수행되지만, 동시에 읽기-쓰기 작업을 수행하는 것은 문제가 될 수 있습니다. 응용 프로그램에 한 번에 많은 사용자가 데이터를 쓰는 경우, PostgreSQL과 같은 다른 RDBMS가 데이터베이스로 더 나은 선택일 수 있습니다.
PostgreSQL
PostgreSQL은 “세계에서 가장 진보된 오픈 소스 관계형 데이터베이스”로 소개됩니다. PostgreSQL은 고도로 확장 가능하고 표준을 준수하는 것을 목표로 만들어졌습니다. PostgreSQL은 객체-관계형 데이터베이스로, 주로 관계형 데이터베이스이지만 테이블 상속 및 함수 오버로딩과 같은 기능을 포함하고 있습니다.
Postgres는 동시에 여러 작업을 효율적으로 처리할 수 있는 능력을 갖추고 있으며, 이를 동시성이라고 합니다. 이는 읽기 잠금을 사용하지 않고 Multiversion Concurrency Control (MVCC)를 구현하여 이루어지며, 이는 트랜잭션의 원자성, 일관성, 격리성 및 지속성을 보장하여 ACID 호환성으로 알려져 있습니다.
PostgreSQL은 MySQL만큼 널리 사용되지는 않지만, pgAdmin 및 Postbird와 같은 PostgreSQL 작업을 간편하게 만드는 제3자 도구 및 라이브러리가 여럿 있습니다.
PostgreSQL 지원 데이터 유형
PostgreSQL은 MySQL과 유사하게 숫자, 문자열, 날짜 및 시간 데이터 유형을 지원합니다. 또한, 기하학적 모양, 네트워크 주소, 비트 문자열, 텍스트 검색 및 JSON 항목을 위한 데이터 유형뿐만 아니라 여러 독특한 데이터 유형도 지원합니다.
숫자 유형:
| Data Type | Explanation |
|---|---|
bigint |
A signed 8 byte integer. |
bigserial |
An auto-incrementing 8 byte integer. |
double precision |
An 8 byte double precision floating-point number. |
integer |
A signed 4 byte integer. |
numeric or decimal |
A number of selectable precision, recommended for use in cases where exactness is crucial, such as monetary amounts. |
real |
A 4 byte single precision floating-point number. |
smallint |
A signed 2 byte integer. |
smallserial |
An auto-incrementing 2 byte integer. |
serial |
An auto-incrementing 4 byte integer. |
문자 유형:
| Data Type | Explanation |
|---|---|
character |
A character string with a specified fixed length. |
character varying or varchar |
A character string with a variable but limited length. |
text |
A character string of a variable, unlimited length. |
날짜 및 시간 유형:
| Data Type | Explanation |
|---|---|
date |
A calendar date consisting of the day, month, and year. |
interval |
A time span. |
time or time without time zone |
A time of day, not including the time zone. |
time with time zone |
A time of day, including the time zone. |
timestamp or timestamp without time zone |
A date and time, not including the time zone. |
timestamp with time zone |
A date and time, including the time zone. |
기하학적 유형:
| Data Type | Explanation |
|---|---|
box |
A rectangular box on a plane. |
circle |
A circle on a plane. |
line |
An infinite line on a plane. |
lseg |
A line segment on a plane. |
path |
A geometric path on a plane. |
point |
A geometric point on a plane. |
polygon |
A closed geometric path on a plane. |
네트워크 주소 유형:
| Data Type | Explanation |
|---|---|
cidr |
An IPv4 or IPv6 network address. |
inet |
An IPv4 or IPv6 host address. |
macaddr |
A Media Access Control (MAC) address. |
비트 문자열 유형:
| Data Type | Explanation |
|---|---|
bit |
A fixed-length bit string. |
bit varying |
A variable-length bit string. |
텍스트 검색 유형:
| Data Type | Explanation |
|---|---|
tsquery |
A text search query. |
tsvector |
A text search document. |
JSON 유형:
| Data Type | Explanation |
|---|---|
json |
Textual JSON data. |
jsonb |
Decomposed binary JSON data. |
다른 데이터 유형:
| Data Type | Explanation |
|---|---|
boolean |
A logical Boolean, representing either true or false. |
bytea |
Short for “byte array”, this type is used for binary data. |
money |
An amount of currency. |
pg_lsn |
A PostgreSQL Log Sequence Number. |
txid_snapshot |
A user-level transaction ID snapshot. |
uuid |
A universally unique identifier. |
xml |
XML data. |
PostgreSQL의 장점
- SQL 준수: SQLite나 MySQL보다 더 SQL 표준을 엄격히 준수하려는 PostgreSQL의 목표입니다. 공식 PostgreSQL 문서에 따르면, PostgreSQL은 전체 SQL:2011 준수를 위해 필요한 179개 기능 중 160개를 지원하며 선택적 기능 목록도 있습니다.
- 오픈 소스 및 커뮤니티 주도: 완전한 오픈 소스 프로젝트인 PostgreSQL의 소스 코드는 대규모이고 헌신적인 커뮤니티에 의해 개발됩니다. 비슷하게, Postgres 커뮤니티는 공식 문서, PostgreSQL 위키, 여러 온라인 포럼을 포함한 DBMS 작업 방법을 설명하는 다양한 온라인 리소스를 유지 및 기여합니다.
- 확장 가능: 사용자는 PostgreSQL을 카탈로그 기반 작업과 동적 로딩을 통해 프로그래밍적으로 실시간으로 확장할 수 있습니다. 사용자는 공유 라이브러리와 같은 객체 코드 파일을 지정하고 PostgreSQL이 필요할 때 로드하도록 할 수 있습니다.
PostgreSQL의 단점
- 메모리 성능: 각 새로운 클라이언트 연결마다, PostgreSQL은 새로운 프로세스를 분기합니다. 각 새로운 프로세스에는 약 10MB의 메모리가 할당되며, 이는 많은 연결을 갖는 데이터베이스의 경우 빠르게 누적될 수 있습니다. 따라서 단순한 읽기 중심의 작업의 경우, PostgreSQL은 일반적으로 MySQL과 같은 다른 RDBMS보다 성능이 낮을 수 있습니다.
- 인기: 최근 몇 년간 더 많이 사용되고 있지만, PostgreSQL은 역사적으로 MySQL보다 인기 측면에서 뒤쳐지고 있습니다. 이로 인한 한 가지 결과는 아직도 PostgreSQL 데이터베이스를 관리하는 데 도움이 되는 서드파티 도구가 더 적다는 것입니다. 마찬가지로 MySQL 경험이 있는 데이터베이스 관리자보다 PostgreSQL 경험이 있는 관리자가 적습니다.
언제 PostgreSQL을 사용해야 하는가
- 데이터 무결성이 중요한 경우: PostgreSQL은 2001년부터 완전한 ACID 호환성을 갖추고 있으며, 데이터가 일관성을 유지하도록 다중 버전 동시성 제어를 구현합니다. 따라서 데이터 무결성이 중요한 경우 RDBMS로 강력한 선택지가 됩니다.
- 다른 도구들과의 통합: PostgreSQL은 다양한 프로그래밍 언어 및 플랫폼과 호환됩니다. 따라서 데이터베이스를 다른 운영 체제로 이전하거나 특정 도구와 통합해야 할 경우, PostgreSQL 데이터베이스를 사용하면 다른 DBMS보다 더 쉽게 처리할 수 있습니다.
- 복잡한 작업: Postgres는 여러 CPU를 활용한 쿼리 계획을 지원하여 더 빠른 속도로 쿼리에 응답할 수 있습니다. 이는 다중 동시 작성자를 강력하게 지원함으로써 데이터 웨어하우징 및 온라인 트랜잭션 처리와 같은 복잡한 작업에 적합한 선택으로 만듭니다.
PostgreSQL을 사용하지 않아야 할 때
- 속도가 중요한 경우: 속도를 희생하고 PostgreSQL은 확장성과 호환성을 염두에 두고 설계되었습니다. 프로젝트가 가능한 빠른 읽기 작업을 필요로 할 경우, PostgreSQL은 최적의 DBMS 선택이 아닐 수 있습니다.
- 간단한 설정: Postgres는 큰 기능 세트와 표준 SQL에 대한 강력한 준수 때문에 간단한 데이터베이스 설정에는 적합하지 않을 수 있습니다. 속도가 필요한 읽기 중심 작업의 경우, 일반적으로 MySQL이 더 실용적인 선택입니다.
- 복잡한 복제: PostgreSQL은 복제에 강력한 지원을 제공하지만, 이 기능은 여전히 비교적 새로운 기능입니다. 일부 구성(예: 주-주 아키텍처)은 확장 기능으로만 가능합니다. 복제는 MySQL에서 더 성숙한 기능으로, 많은 사용자들이 MySQL의 복제가 구현하기 쉽다고 보고 있으며, 특히 데이터베이스 및 시스템 관리 경험이 부족한 사용자들에게는 더욱 그렇습니다.
결론
오늘날 SQLite, MySQL 및 PostgreSQL은 세계에서 가장 인기 있는 오픈 소스 관계형 데이터베이스 관리 시스템입니다. 각각은 고유한 기능과 한계가 있으며 특정 시나리오에서 뛰어납니다. RDBMS를 선택할 때는 여러 가지 변수가 작용하며, 가장 빠르거나 가장 많은 기능을 제공하는 것만으로 선택하는 것은 거의 없습니다. 다음으로 관계형 데이터베이스 솔루션이 필요할 때에는 깊이 있는 연구를 통해 여러 도구 중에서 가장 적합한 것을 찾도록 합니다.
SQL 데이터베이스 관리 방법치트 시트를 참조하시기 바랍니다. 반면에, 비관계형(또는 NoSQL) 데이터베이스에 대해 배우고 싶다면, NoSQL 데이터베이스 관리 시스템 비교를 확인해주세요.