













Shift-left는 소프트웨어 개발 및 운영에 초점을 맞추고, 테스팅, 모니터링, 자동화를 소프트웨어 개발 생명주기의 초기 단계에서 강조하는 접근 방식입니다. Shift-left 접근 방식의 목표는 문제가 발생하기 전에 빠르게 감지하고 해결하여 문제를 예방하는 것입니다.
초기에 확장성 문제나 버그를 파악하면 해결하기가 더 빠르고 비용 효율적입니다. 비효율적인 코드를 클라우드 컨테이너로 이동하는 것은 비용이 많이 들 수 있으며, 자동 확장이 활성화되어 월별 비용이 증가할 수 있습니다. 또한, 문제를 식별, 격리 및 수정할 수 있을 때까지 긴급 상태에 놓이게 됩니다.
문제 정의
I would like to demonstrate to you a case where we managed to avert a potential issue with an application that could have caused a major issue in a production environment.
I was reviewing the performance report of the UAT infrastructure following the recent application change. It was a Spring Boot microservice with MariaDB as the backend, running behind Apache reverse proxy and AWS application load balancer. The new feature was successfully integrated, and all UAT test cases are passed. However, I noticed the performance charts in the MariaDB performance dashboard deviated from pre-deployment patterns.
이벤트의 타임라인입니다.
8월 6일 오후 2시 13분, 내장된 Tomcat을 포함하는 새로운 Spring Boot jar 파일로 애플리케이션이 재시작되었습니다.
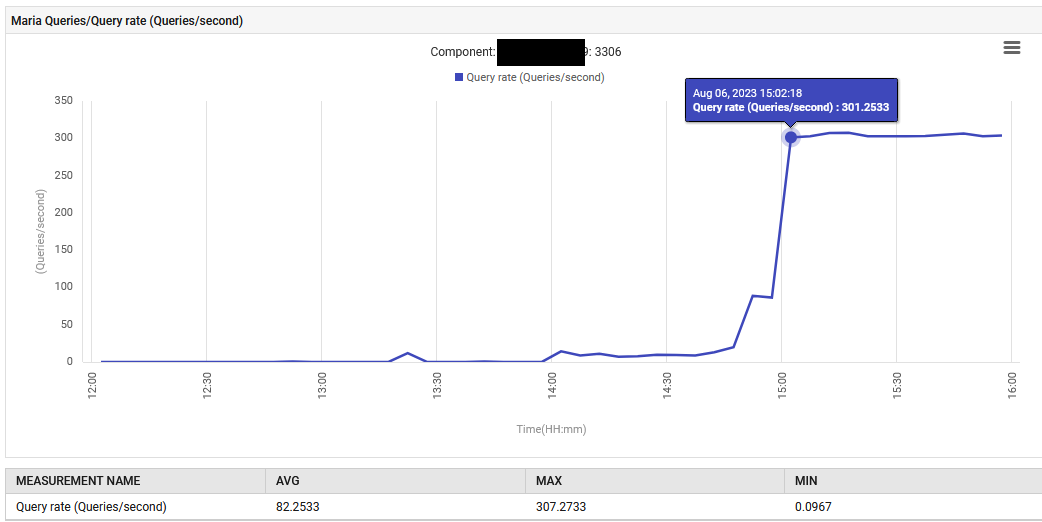
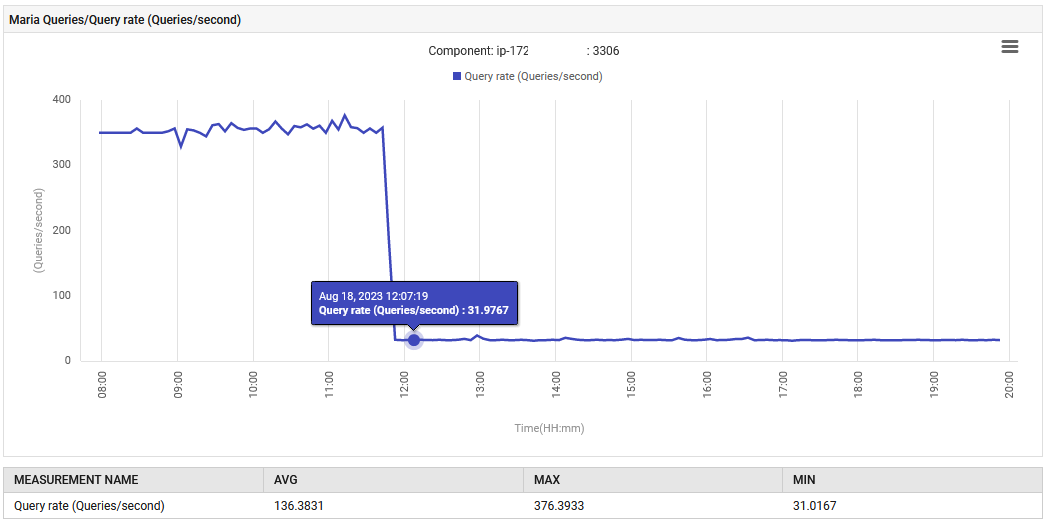
오후 2시 52분에 MariaDB의 쿼리 처리 속도가 초당 0.1에서 88건으로 증가한 후 초당 301건으로 상승했습니다.
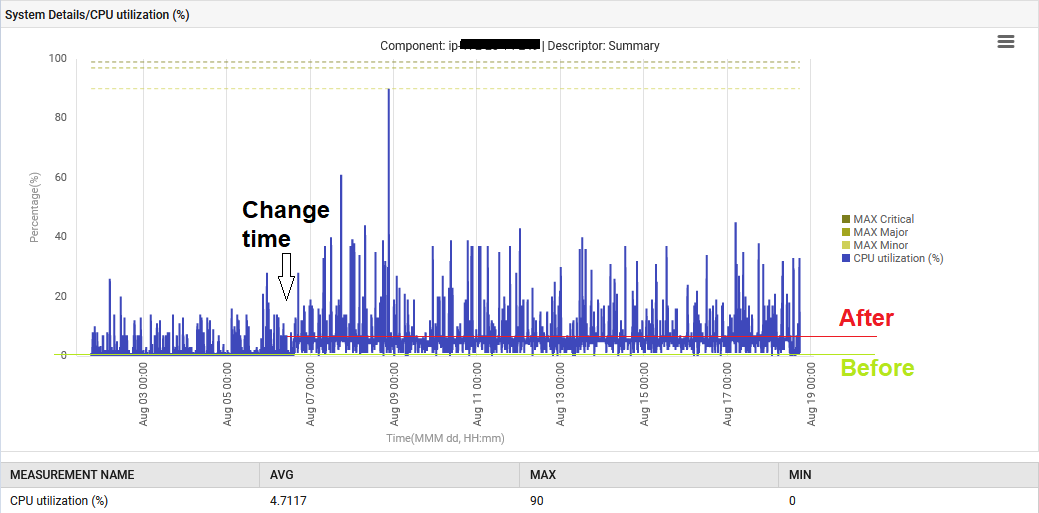
또한 시스템 CPU가 1%에서 6%로 상승했습니다.
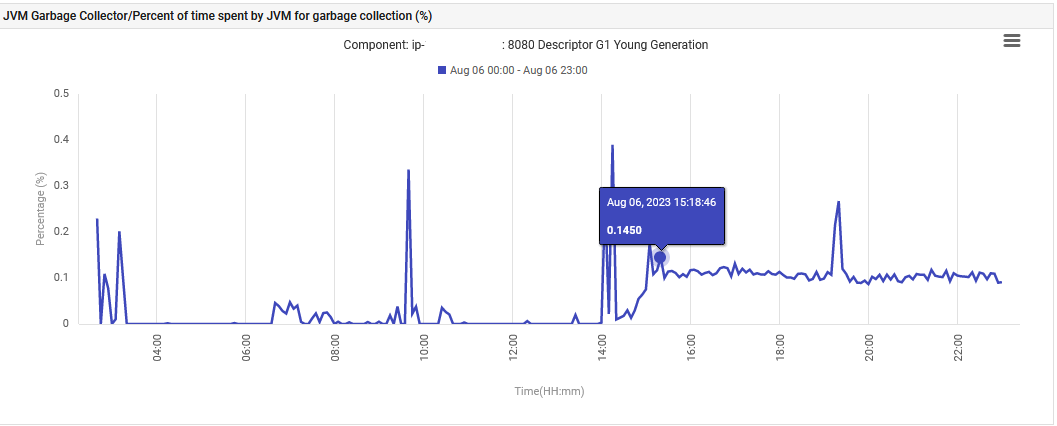
마지막으로, JVM이 G1 Young Generation Garbage Collection에 소비하는 시간이 0%에서 0.1%로 증가하여 그 수준을 유지했습니다.
애플리케이션은 UAT 단계에서 비정상적으로 초당 300개의 쿼리를 발행하고 있으며, 이는 설계 범위를 훨씬 초과하고 있습니다. 새로운 기능으로 인해 데이터베이스 연결이 증가하여 쿼리 증가가 급격한 이유입니다. 그러나 모니터링 대시보드에서는 문제가 있는 측정치가 새 버전이 배포되기 전에 정상이었다고 표시되었습니다.
해결책
이는 Spring Boot 애플리케이션으로 JPA를 사용하여 MariaDB에 쿼리를 보내고 있습니다. 애플리케이션은 최소 부하를 위해 두 개의 컨테이너에서 실행되도록 설계되었지만 최대 10개까지 확장될 수 있습니다.
단일 컨테이너가 초당 300개의 쿼리를 생성할 수 있다면, 모든 10개의 컨테이너가 작동 중일 때 초당 3000개의 쿼리를 처리할 수 있습니까? 데이터베이스는 애플리케이션의 다른 부분들의 요구를 충족시킬 수 있는 충분한 연결을 가질 수 있습니까?
다른 선택지가 없이 개발자의 책상으로 돌아가 Git에서 변경 사항을 검사해야 했습니다.
새로운 변경으로 인해 테이블에서 몇 개의 레코드를 가져와 처리하는 것을 관찰했습니다. 이것이 서비스 클래스에서 관찰한 내용입니다.
List<X> findAll = this.xRepository.findAll();
아니요, 스프링의 CrudRepository에서 페이징 없이 findAll() 메서드를 사용하는 것은 효율적이지 않습니다. 페이징은 데이터베이스에서 데이터를 검색하는 데 걸리는 시간을 줄이기 위해 검색되는 데이터의 양을 제한하는 데 도움이 됩니다. 이는 우리의 기본 RDBMS 교육이 가르쳤던 내용입니다. 또한, 페이징은 데이터 과부하로 인한 애플리케이션 충돌을 방지하기 위해 메모리 사용량을 낮추고, 위에서 언급한 문제 설명에서 언급한 자바 가상 머신의 가비지 컬렉션 노력을 감소시킵니다.
이 테스트는 한 컨테이너에서 단지 2,000개의 레코드만 사용하여 수행되었습니다. 이 코드가 프로덕션으로 이동하게 되면, 최대 10개의 컨테이너에 약 20만 개의 레코드가 있을 경우, 그날 팀에게 많은 스트레스와 걱정을 야기할 수 있었습니다.
애플리케이션은 메서드에 WHERE 절을 추가하여 재구축되었습니다.
List<X> findAll = this.xRepository.findAllByY(Y);
정상적인 기능이 복원되었습니다. 초당 쿼리 수가 300에서 30으로 감소하였고, 가비지 컬렉션에 대한 노력이 원래 수준으로 돌아왔습니다. 또한 시스템의 CPU 사용량이 감소했습니다.
학습 및 요약
SRE (SRE) 분야에서 일하는 누구든지 이 발견의 중요성을 인정할 것입니다. 이를 바탕으로 행동할 수 있었으며, Severity 1 신호를 올릴 필요가 없었습니다. 이 결함이 있는 패키지가 프로덕션에 배포되었다면, 고객의 오토스케일링 임계치를 트리거하여 추가 사용자 부하 없이도 새로운 컨테이너가 시작될 수 있었을 것입니다.
이 이야기에서 주요한 세 가지 교훈이 있습니다.
첫째, 초기부터 관찰 가능성 솔루션을 활성화하는 것이 모범 사례입니다. 이는 잠재적 문제를 식별하는 데 사용할 수 있는 이벤트 기록을 제공할 수 있습니다. 이 기록이 없었다면 0.1%의 Garbage Collection 비율과 6%의 CPU 소비를 심각하게 여기지 않았을 수도 있으며, 코드가 치명적인 결과를 초래하면서 프로덕션에 릴리스되었을 수도 있었습니다. 모니터링 솔루션의 범위를 UAT 서버로 확장하여 팀은 잠재적 근본 원인을 식별하고 문제가 발생하기 전에 예방할 수 있었습니다.
둘째, 성능과 관련된 테스트 사례는 테스트 프로세스에 존재해야 하며, 이를 관찰 가능성에 대한 경험이 있는 사람이 검토해야 합니다. 이를 통해 코드의 기능뿐만 아니라 성능도 테스트됩니다.
셋째, 클라우드 네이티브 성능 추적 기술은 높은 사용률, 가용성 등에 대한 경고를 받는 데 좋습니다. 관찰 가능성을 달성하려면 적절한 도구와 전문 지식이 필요할 수 있습니다. 즐거운 코딩!
Source:
https://dzone.com/articles/shift-left-monitoring-approach-for-cloud-apps-in-c