













안드로이드(RAG)는 대형 언어 모델(LLM)에 대한 혁신적인 발전을 나타냅니다. 이는 변형자 구조의 생성적 능력과 동적 정보 검색을 결합합니다.
이러한 통합은 LLM이 텍스트 생성 도중 실시간으로 관련 외부 지식에 접근하고 통합할 수 있게 해서, 더 정확하고 문맥적이고 사실적으로 일관성 있는 출력을 만들어 냅니다.
초기 규칙 기반 시스템에서 BERT와 GPT-3와 같은 세련된 신경 모델로의 발전은 RAG를 가능하게 하는 동시에, 정적인 매개변수 메모리의 한계를 해결합니다. 또한 멀티모달 RAG의 등장으로 이미지, 오디오, 비디오와 같은 다양한 데이터 유형을 통합함으로써 생성된 콘텐츠의 풍부성과 관련성을 높입니다.
이러한 패러다임의 변화는 LLM 출력의 정확성과 해석 가능성을 향상시키는 것 뿐만 아니라, 다양한 분야에서 혁신적인 응용을 지원합니다.
우리가 다룰 내용은 다음과 같습니다:
- 제1장. RAG 소개
– 1.1 RAG란 무엇인가? 개요
– 1.2 RAG가 어떻게 복잡한 문제를 해결합니까? - 2장. 기술적 기반
– 2.1 신경 언어 모델에서 RAG로의 전환
– 2.2 RAG의 기억 이해: 매개 변수화 vs. 비매개 변수화
– 2.3 다중 모달 RAG: 여러 데이터 유형 통합 - 3장. 핵심 메커니즘
– 3.1 RAG에서 정보 검색과 생성의 결합력
– 3.2 검색기와 생성기의 통합 전략 - 4장. 응용 및 사용 사례
– 4.1 QA에서 창작 글쓰기까지 RAG의 활용
– 4.2 저자원 언어에 대한 RAG: 영향력과 기능 확장 - 제5장. 최적화 기술
– 5.1 RAG 시스템 최적화를 위한 고급 검색 기술 - 제6장. 도전과 혁신
– 6.1 RAG를 위한 현재 도전과 미래 방향
– 6.2 RAG 시스템의 하드웨어 가속화와 효율적인 배포 - 제7장. 마무리 생각
– 7.1 RAG의 미래: 결론과 반성
사전 요구사항
Retrieval-Augmented Generation (RAG)과 같은 대규모 언어 모델 (LLM)에 중점을 둔 콘텐츠를 다루기 위한 두 가지 필수 선행 조건은 다음과 같습니다:
- 머신 러닝 기초: 신경망 아키텍처에 적용되는 기본적인 머신 러닝 개념과 알고리즘을 이해하는 것이 중요합니다.
- 자연어 처리 (NLP): 텍스트 pretreatment, tokenization, embedding 사용 등이 있는 NLP 기술에 대한 지식은 언어 모델과 작업하는 데에 중요합니다.
chap.1: RAG 소개
Retrieval-Augmented Generation (RAG)는 정보 조회와 generative 모델을 결합하여 자연어 처리를 革命적으로 変え고 있습니다. RAG는 dynamically 外부 지식을 접근하여 생성된 텍스트의 정확성과 관련성을 향상시키는 역할을 합니다.
이 章은 RAG의 기계, 장점과 도전을 탐구합니다. 我們는 조회 기술, 생성 모델과의 통합, 다양한 응용 에의 영향을 깊이 있게 다룰 것입니다.
RAG는 幻觉 를 軽減하고, 최신 정보를 吸纳하며 複雑한 문제를 해결합니다. 我们은 효율적인 조회와 윤리적 문제를 讨论할 것입니다. 이 章은 RAG가 자연어 처리에서 革命적인 가능성을 이해하는 것을 도울 수 있습니다.
1.1 RAG은 무엇인가? 개요
Retrieval-Augmented Generation (RAG)는 자연어 처리에서 전통적인 언어 모델의 純粋하게 parametric memory의 한계를 극복하기 위해 정보 조회와 생성형 언어 모델의 장점을 통합하고 있습니다. RAG 시스템은 外부 지식 소스를 이용하여 생성된 텍스트의 정확성, 관련성, 및 동시에 coherence를 향상시키는 역할을 합니다. (Lewis et al., 2020)
동적으로 생성 과정에서 관련 정보를 조회하고 통합하여, RAG는 질문 답변, 대화 시스템에서 요약과 창의적 쓰기까지 다양한 응용에서 더 많은 문맥적 기반과 사실적 일관성을 가지는 输出行동을 가능하게 한다. (Petroni et al., 2021)
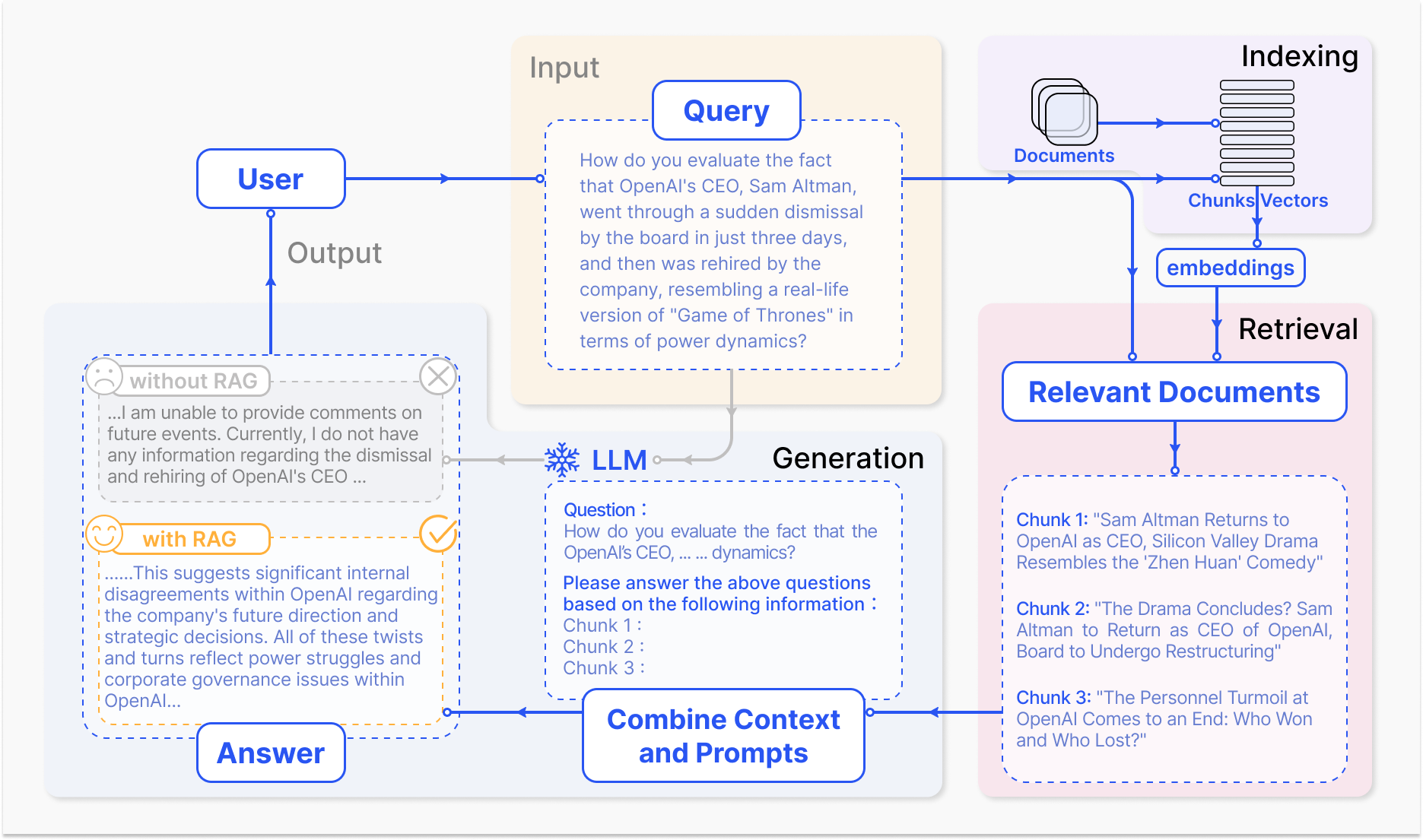
RAG 시스템의 작동 방법 – arxiv.org
RAG의 주요 机制은 두 가지 주요 요소로 구성되어 있다: 조회와 생성.
조회 요소는 입력 질의 또는 문맥에 따라 가장 pertinent information을 識別하기 위해 极大な 知識 베이스를 効率的하게 search through하는 것을 수행한다. inverted indexes와 term-based matching를 이용하는 sparse retrieval과 dense vector representations와 의미 차이를 이용하는 dense retrieval과 같은 기술을 사용하여 조회 과정을 최적화하고 있다. (Karpukhin et al., 2020)
그리고 조회한 정보는 generative model로 통합되며, GPT나 T5과 같은 대형 언어 모델로 구성되어 있으며, 해당하는 내용을 통합하여 cohérent and fluent response를 생성한다. (Izacard & Grave, 2021)
RAG의 인tegration 문제는 전통적인 언어 모델에 비해 여러 장점을 제공합니다. 생성된 텍스트를 외부 지식에 기반을 둔 것으로, RAG는 幻影나 사실적으로 incorrecT outputs의 발생 빈도를 Significantly reduce할 수 있습니다. (Shuster et al., 2021)
RAG은 또한 최신 정보를 포함하여 가능하며, 생성된 응답이 주어진 domaIn에 대한 最新の 지식과 발전을 반영하도록 보장합니다. (Lewis et al., 2020)이러한 적응性은 의료, 金融, scientific research 등의 域에서 정확하고 시간 지정적인 정보가 가장 중요한 것처럼 특히 중요합니다. (Petroni et al., 2021)
하지만 RAG 시스템의 개발과 배포는 또한 significant challenges를 제시합니다. 대规模의 지식 베이스에 대한 효율적인 인덱스 추출, 幻影 軽減, 다양한 데이터 모alities의 통합은 해결해야 하는 기술적인 препятствия입니다. (Izacard & Grave, 2021)
도메인과 관련된 этические 고려,如实의 보장과 공정한 정보 검색 및 생성,는 RAG 시스템의 책임 있게 운영하는 데至关重要(Bender et al., 2021). 검색 정확성과 생성 품질 사이의 상호 작용을 캡처하는 포괄적인 평가 지표 및 프레임워크를 개발하는 것은 RAG 시스템의 효과성을 평가하는 데 필수적입니다. (Lewis et al., 2020)
RAG 분야는 계속 발전하고 있으며, 미래의 연구 방향은 검색 프로세스의 최적화, 다중 모달 기능 확장, 모듈화된 아키텍처 개발, 및 견고한 평가 프레임워크의 설정을 중심으로합니다. (Izacard & Grave, 2021) 이러한 진행은 RAG 시스템의 효율성, 정확성, 및 적응성을 향상시키며, 자연어 처리의 더 지능적고 다재다능한 응용을 위한 길을 벌입니다.
다음은 LangChain 및 FAISS와 같은 인기 라이브러리를 사용한 검색 확장 생성(RAG) 설정을 보여주는 기본적인 Python 코드 예입니다.
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.document_loaders import TextLoader
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
1. 문서를 로드하고 내장하기
loader = TextLoader('your_documents.txt') 문서 소스를 대체하십시오
documents = loader.load()
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(documents, embeddings)
2. 관련 문서를 검색하기
def retrieve_docs(query):
return vectorstore.similarity_search(query)
3. RAG 체인 설정하기
llm = OpenAI(temperature=0.1) 응답 창의성을 위한 온도를 조정하십시오
chain = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=vectorstore.as_retriever())
4. RAG 모델 사용하기
def get_answer(query):
return chain.run(query)
예제 사용법
query = "What are the key features of Company X's latest product?"
answer = get_answer(query)
print(answer)
회사 연혁 예제 사용법
query = "When was Company X founded and who were the founders?"
answer = get_answer(query)
print(answer)
재무 성과 예제 사용법
query = "What were Company X's revenue and profit figures for the last quarter?"
answer = get_answer(query)
print(answer)
미래展望 예제 사용법
query = "What are Company X's plans for expansion or new product development?"
answer = get_answer(query)
print(answer)
검색과 생성의 기능을 활용함으로써, RAG는 우리가 정보와 상호 작용하는 방식을 변화시키는 데에 앞당겨지고 있으며, 다양한 영역을 혁신하고 인간-머신 상호작용의 미래를 그리고 있습니다.
1.2 RAG가 복잡한 문제를 해결하는 방법
Retrieval-Augmented Generation (RAG)는 전통적인 대형 언어 모델(LLM)이 어려워하는 복잡한 문제에 강력한 솔루션을 제공합니다. 특히 무결정 데이터가 엄청나게 많은 시나리오에서更是如此。
그 중 하나는 YouTube 동영상과 같은 특정 문서 또는 멀티미디어 콘텐츠에 대해 의미 있는 대화를 나눌 수 있는 능력입니다. 이를 위해 사전에 미리 조정하거나 명시적인 훈련을 받지 않아도 됩니다.
전통적인 LLMs는 놀라운 생성 능력을 가지고 있지만, 훈련 시점에 고정된 파라미etric 메모리로 제한되어 있습니다. (Lewis et al., 2020) 이는 그들이 훈련 데이터를 초과하여 새로운 정보를 직접 액세스하거나 통합할 수 없음을 의미하며, 보지 않은 문서나 동영상에 대한 정보성 있는 논의에 참여하기 어렵게 만듭니다.
결과적으로, LLMs는 특정 콘텐츠와 관련된 질문에 대해 불일치하거나, 관련 없는 것이나 사실적으로 틀린 응답을 생성할 수 있습니다. (Petroni et al., 2021)
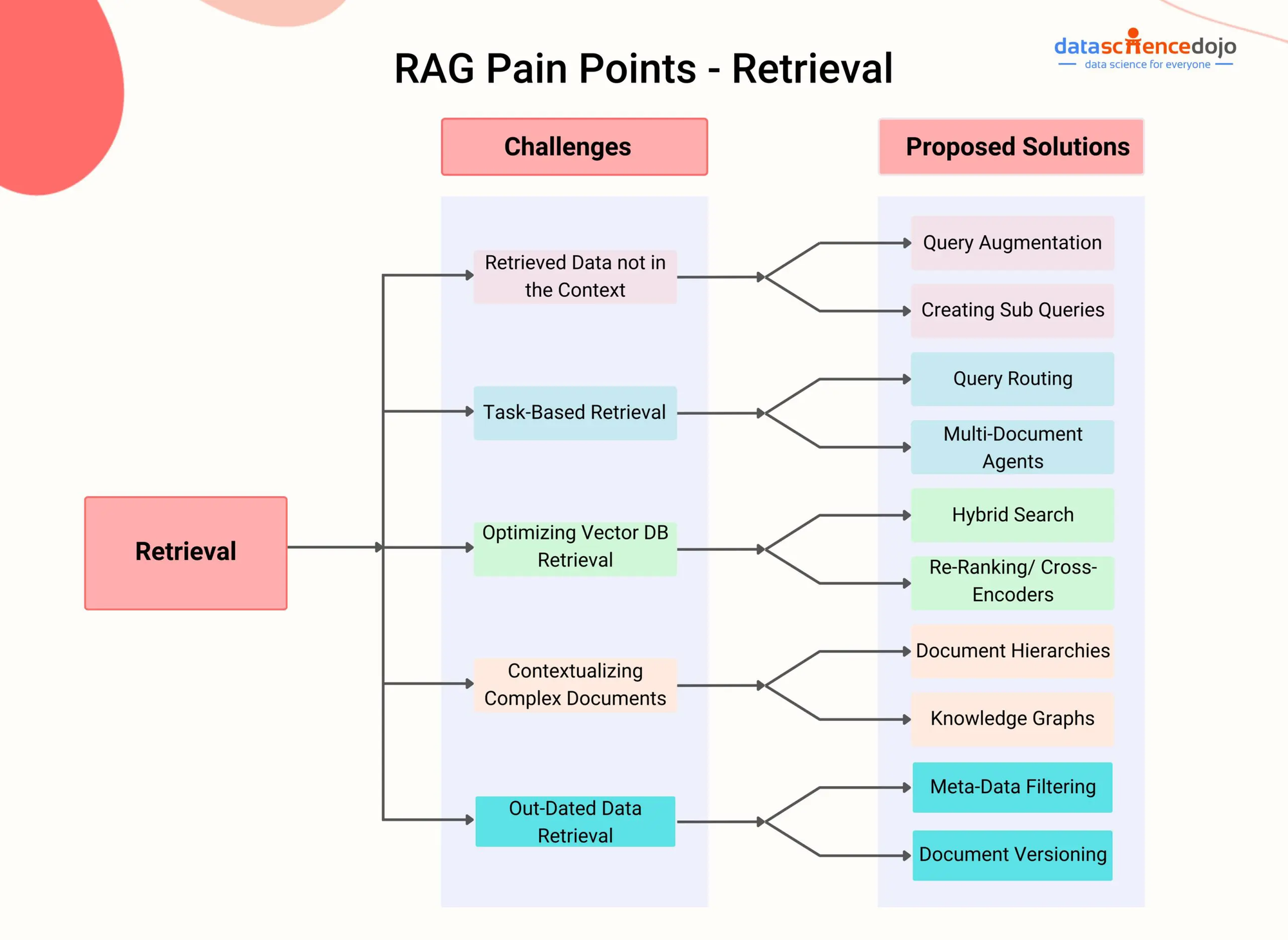
RAG Pain Points – DataScienceDojo
RAG는 생성 과정 동안 외부 지식 소스에서 관련 정보를 동적으로 액세스하고 통합할 수 있는 검색 구성 요소를 통합함으로써 이러한 한계를 극복합니다.
다양한 검색 기술을 활용하고자, 밀도 있는 문장 검색 (Karpukhin et al., 2020) 또는 하이브리드 검색 (Izacard & Grave, 2021)을 사용하는 RAG 시스템은 대화적 문맥에 따라 주어진 문서 또는 동영상에서 가장 관련 있는 문장이나 섹션을 효율적으로 식별할 수 있습니다.
특정 과학 주제에 관한 YouTube 비디오에 대한 대화를 나누고자 하는 사용자의 경우, RAG 시스템은 우선 비디오의 오디오 콘텐츠를 변환하고, 그 결과를 두꺼운 벡터 표현을 사용하여 색인한다.
그 후, 사용자가 비디오와 관련된 질문을提出하면, RAG 시스템의 검색 부분은 질문과 색인된 콘텐츠之间的语义相似性를 기반으로 변환문서에서 가장 관련성 있는 부분을 빠르게 식별한다.
검색된 부분은 생성 모델로 입력되어, 사용자의 질문을 직접적으로 해결하면서 답변을 비디오 콘텐츠에 근거지게 만든다. (Shuster et al., 2021)
이러한 접근법으로 RAG 시스템은 명시적인 微调을 필요로 하지 않고 다양한 문서와 멀티미디어 콘텐츠에 대한 지식丰富的 대화를 나눌 수 있다. 관련성 있는 정보를 동적으로 검색하고 통합함으로써, RAG는 전통적인 LLM와相比, 더 정확하고, 컨텍스트적으로 관련성 있고, 사실적으로 일관성 있는 응답을 생성할 수 있다. (Lewis et al., 2020)
RAG는 텍스트, 이미지, 오디오와 같은 다양한 모빌리티의 비구조화 데이터를 처리할 수 있는 능력으로, hetegeneous 정보 来源에 관한 복잡한 문제에 유용한 유용한 솔루션입니다. (Izacard & Grave, 2021) RAG 시스템은 발전하면서, 다양한 분야에서 복잡한 문제를 해결할 수 있는 잠재력이 커지고 있습니다.
고급 검색 기술과 다중 모빌리티 통합을 활용하여, RAG는 더 지능적고 문맥 인식하는 대화형 에이전트, 개인화된 추천 시스템, 지식 중심의 응용을 가능하게 합니다.
효율적인 색인, 교차 모빌리티 정렬, 검색-생성 통합과 같은 연구가 진행되는 경우, RAG는 얼마든지 논리 모델과 인공 지능의 경계를 넘어설 수 있음을 확실히 할 것입니다.
챕터 2: 기술 기반
이 장에서는 전통적인 텍스트 기반 모델의 한계를 극복하는 경지의 Multimodal Retrieval-Augmented Generation (RAG)에 대해 다뤄집니다.
이미지, 오디오, 비디오와 같은 다양한 데이터 모빌리티를 Large Language Models (LLMs)와 부드럽게 통합하는 Multimodal RAG는 AI 시스템이 더 풍부한 정보 지향을 통해 이유하게 할 수 있습니다.
이러한 통합의 메커니즘, 예를 들어 대조적 학습과 교차 모빌리티의 주의를 탐구하고, LLMs가 더 세련된 문맥적으로 관련된 응답을 생성할 수 있게 하는 방법을 살펴봅니다.
멀티모달 RAG은 정확도 향상과 비슷한 이미지 질문 대응 등의 새로운 사용 사례를 지원할 수 있는 기대치를 제시하는 동시에, 독특한 도전을 가지고 있습니다. 이러한 도전들은 대規模 멀티모달 dataset의 필요성, 计算机적 복잡도의 증가, 그리고 인formation을 검색하는 과정에서 편향성이 발생할 수 있다는 것을 포함합니다.
이 여행을 시작하며, 우리는 멀티모달 RAG의 이变异이 어떻게 발전하는지 발견하고자 하며, 앞으로 있는 어려움을 이해하고 있어 evolve하는 분야에 대한 깊은 이해를 도울 것입니다.
2.1 신경망 LM의 RAG
언어 모델의 발전은 早期에 규칙 기반 시스템에서 더 유연하고 고급한 통계적 및 신경망 기반 모델로 稳步 進展하였습니다.
초기 期的에, 언어 모델은 핸들crafter 규칙과 언어 지식을 기반으로 텍스트를 생성하였습니다. 이러한 것은 가벼워 제한적인 output이 나왔습니다. 통계적 모델, 예를 들어 n-gram 모델의 도입은 대량의 문서 集合에서 패턴을 学习하는 데이터 기반 접근法을 introduced, 이로 인해 자연스러운 하고 cohherent language generation을 실현할 수 있었습니다. (Redis)
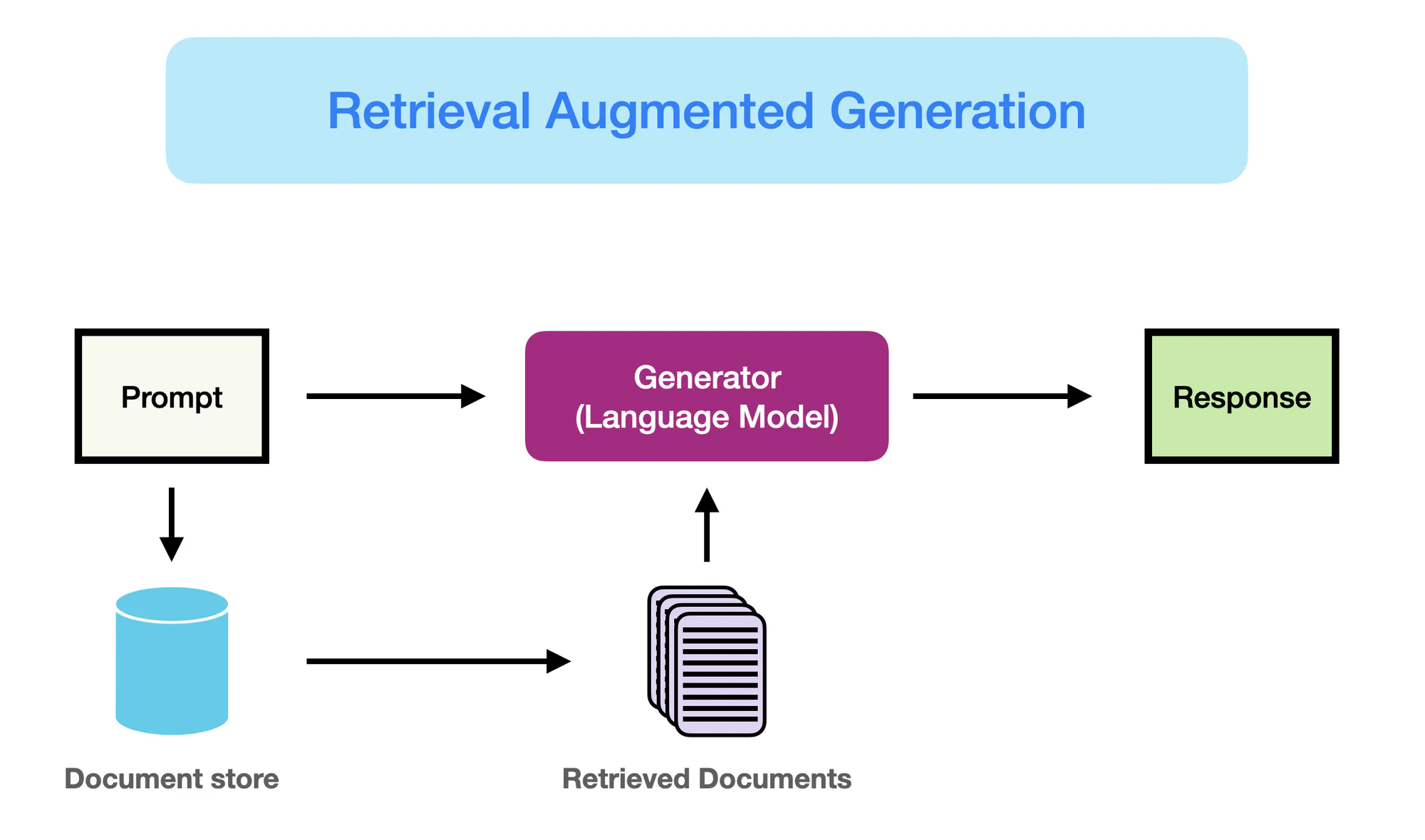
How RAG Works – promptingguide.ai
그러나 특정 신경망 기반 모델, 특히 BERT과 GPT-3과 같은 전문 변형 구조를 사용한 모델의 등장은 자연어 처리(NLP) 분야를 전体制裁적으로 일정했습니다.
이러한 모델들은 대型的 언어 모델 (Large Language Models, LLMs)로 불리며, 심층 leaning의 힘을 이용하여 複雑한 언어 패턴을 인지하고, 이전에 보지 않았던 정확성과 cohérence를 갖춘 인간 alike 텍스트를 생성하는 것을 목표로 합니다. (Yarnit) LLMs의 복잡도와 规模가 증가하며, GPT-3과 같은 모델은 175 억 이상의 파라미터를 자랑하는 것과 같이, 언어 traduction, 질문 답변, 컨텐츠 생성과 같은 任务에서 기능적인 능력을 보였습니다.
그러나 traditional LLMs는 순 parametric memory에 의존하는 것으로 인해 한계를 겪게 되었습니다. (StackOverflow) 이러한 모델에서 저장되는 지식은 static이며, それ들의 entraînement 데이터의 마감 날짜에 의한 제한을 겪게 됩니다.
그 결과, LLMs는 실제적인 정보나 最新 정보와 일관性없이 생성할 수 있는 결과를 낳을 수 있습니다. 또한, 내부적으로 external knowledge sources에 대한 명확한 접근이 없기 때문에, 지식을 적극적으로 사용하는 질문에 대해 정확하고 战术적인 응답을 제공할 수 있는 것을 제한합니다.
Retrieval Augmented Generation (RAG)는 이러한 한계를 극복하기 위한 paradigm-shifting 솔루션이며, LLMs의 생성적인 능력과 이를 통한 정보 汲汲를 동시에 통합하여 모델이 생성 과정 동안 external sources에서 pertinent knowledge를 동적으로 汲汲하고 이를 통한 것입니다.
이 파라미터 기반과 비파라미터 기반의 메모리의 통합은 RAG를 장착한 LLMs가 더 나은 플루ency와 일관성을 가지는 출력뿐만 아니라 사실적인 정확성과 문맥 정보를 갖춘 출력을 생산할 수 있게 해줍니다.
RAG는 언어 생성에 있어서의 중요한 신호를 보여주는 기술로서, LLMs의 강점과 외부 저장소에 있는 광범위한 지식을 결합합니다. 두 가지 세계의 장점을 모두 활용하는 RAG는 모델이 실제 세계의 지식과 더욱 일치하고 신뢰할 수 있는 정보를 가득한 텍스트를 생성할 수 있게 만듭니다.
이 패러다임 변화는 NLP 응용의 새로운 가능성을 열어줍니다. 질문 응답과 콘텐츠 생성에서는 물론, 보건, 금융, 과학 연구等领域의 지식이集中的 작업까지도 적용할 수 있습니다.
2.2 파라미터 기반 vs 비파라미터 기반 메모리
파라미터 기반 메모리는 BERT와 GPT-4와 같은 사전 훈련 언어 모델 내에 저장된 지식을 말합니다. 이러한 모델은 훈련 과정에서 대량의 텍스트 데이터에서 언어적 패턴과 관계를 학습하며, 이러한 지식을 백만 또는 십억의 파라미터로 인코딩합니다.
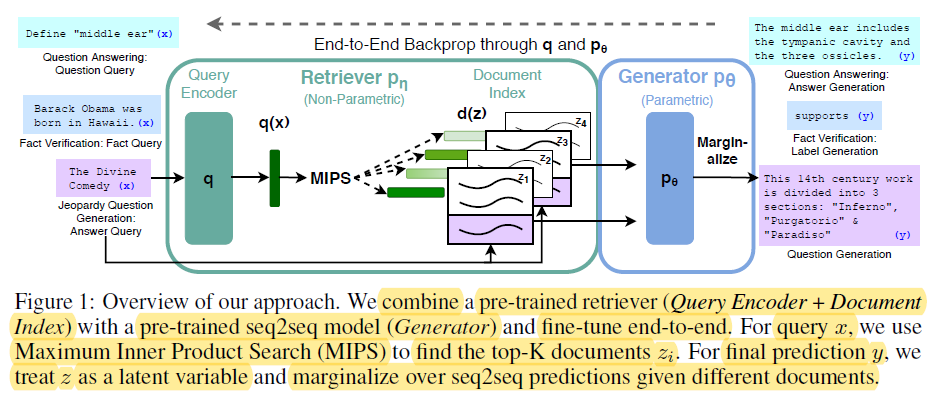
End-t-End Backprop through q and p0 – miro.medium.com
파라미터 기반 메모리의 강점은 다음과 같습니다:
- 流畅性: pretrained language models 인간like 텍스트를 뛰어난 fluency과 coherence로 생성하며, natural language의 finer points와 스타일을 捉えます. (Redis 및 Lewis et al.)
- 일반화: 모델 パarameters에 저장되어 있는 지식으로 새로운 任务과 도메인에 일반화하며, transfer learning 및 few-shot learning 능력을 갖추게 됩니다. (Redis 및 Lewis et al.)
그러나 パarametric memory는 중요한 한계를 가지고 있습니다.:
- 사실 오해: Language models는 그들이 트레이닝 한 data에 의해 지식이 제한되어 있기 때문에, 실제 세계의 사실과 일치하지 않는 산출물를 생성할 수 있습니다.
- 지난 지식: 모델의 パarameters에 저장되어 있는 지식은 시간이 지나면 좀 지칠 수 있으며, 트레이닝 할 때의 상태로 고정되어 실제 세계의 업데이트나 변화를 반영하지 않습니다.
- высокая computation cost: 대형 language models를 트레이닝하기 위해서는 대량의 computation resource와 에너지가 필요하며, 지식을 갱신하기는 Expensive하고 시간 consuming합니다.
- 일반 지식: 언어 모델로 捉えられ는 지식은 幅広く、일반적이며、많은 Domainspecific Application을 위해 필요한 깊さ와 특정성을 欠く합니다.
대안으로, Non-parametric Memory은 데이터베이스, 문서, 지식 그래프 등의 명시적 지식 소스를 사용하여 언어 모델에게 최신하고 정확한 정보를 제공하는 것을 指します. 이러한 외부 소스는 모델에게 relevent information를 접근하고 생성 과정에서 즉시에 이를 읽어들이는 보조 메모리로 활용되ます.
Non-parametric Memory의 이점에 대해서는 다음과 같습니다:
- 최신 정보: 외부 지식 소스를 쉽게 갱신하고 관리할 수 있으며, 모델이 가장 최근과 정확한 정보를 사용할 수 있도록 해줍니다.
- hallucination을 줄이는 것: “External sources로부터 관련 정보를 인도하여, RAG는 hallucination의 発生 또는 사실적으로 INCORRECT generative outputs를 значитель히 줄이게 합니다.” (Lewis et al.와 Guu et al.)
- 도메인 특화 지식: 비араметриetric 메모리는 모델이 도메인 특화된 소스에서 특화된 지식을 활용할 수 있도록 하며, 특정 응용에 대해 더 정확하고 문맥적으로 관련된 출력을 가능케 한다. (Lewis et al. 와 Guu et al.)
파라미etric 메모리의 한계는 언어 생성에서 패러다임 전환의 필요성을 강조한다.
RAG는 정보 검색 기술을 통합함으로써 생성 모델의 성능을 향상시켜 自然言語処理에 대한 중요한 발전을 나타냄. (Redis)
다음은 RAG의 문맥에서 파라미etric과 비파라미etric 메모리의 구별을 보여주는 파이썬 코드이며, 명확한 출력 강조가 포함되어 있다:
from sentence_transformers import SentenceTransformer
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import FAISS
from langchain.chains import RetrievalQAWithSourcesChain
from langchain.llms import OpenAI
# 샘플 문서 모음 (실제 시나리오에서는 더 복잡한 문서를 가정함)
documents = [
"The Large Hadron Collider (LHC) is the world's largest and most powerful particle accelerator.",
"The LHC is located at CERN, near Geneva, Switzerland.",
"The LHC is used to study the fundamental particles of matter.",
"In 2012, the LHC discovered the Higgs boson, a particle that gives mass to other particles.",
]
# 1. 비파라미etric 메모리 (임베딩을 사용한 검색)
model_name = "sentence-transformers/all-mpnet-base-v2"
embeddings = HuggingFaceEmbeddings(model_name=model_name)
vectorstore = FAISS.from_documents(documents, embeddings)
# 2. 파라미etric 메모리 (검색을 사용하는 언어 모델)
llm = OpenAI(temperature=0.1) # 응답의 창의성을 위해 온도를 조절
chain = RetrievalQAWithSourcesChain.from_chain_type(llm=llm, chain_type="stuff", retriever=vectorstore.as_retriever())
# --- 쿼리와 응답 ---
query = "What was discovered at the LHC in 2012?"
answer = chain.run(query)
print("Parametric (w/ Retrieval): ", answer["answer"])
query = "Where is the LHC located?"
docs = vectorstore.similarity_search(query)
print("Non-Parametric: ", docs[0].page_content)
출력:
Parametric (w/ Retrieval): The Higgs boson, a particle that gives mass to other particles, was discovered at the LHC in 2012.
Non-Parametric: The LHC is located at CERN, near Geneva, Switzerland.
이 코드에서는 다음과 같은 일이 일어난다:
Parametric Memory:
- LLM의 大局적인 지식을 활용하여 해당 질문에 대한 回答을 생성하며, Higgs boson이 다른 粒子들에 質量을 주는 중요한 사실을 포함합니다. LLM은 자신의 широ한 트레이닝 데이터로 “매개변수화”되어 있습니다.
Non-Parametric Memory:
- 벡터 공간内에서 유사도 search를 수행하여, 질문에 직면하여 답변을 제시하는 가장 relevant document을 찾습니다. 새로운 정보를 합성하는 것이 아닌, 이미 존재하는 사실을 재공하는 것뿐입니다.
Key Differences:
| Feature | Parametric Memory | Non-Parametric Memory |
|---|---|---|
| Knowledge Storage | 모델의 매개변수(무게)에 인코딩되어 leaned representations로 학습되었습니다. | 직접 raw text 또는 다른 형식(예: embedding)에 저장되었습니다. |
| Retrieval | 모델의 generative capabilities를 사용하여 learned knowledge에 따라 질의에 대한 pertinent text를 생성합니다. | 문서를 찾는 것은 질의와 가까운 문서를 찾는 것(예: 유사도 또는 키워드 matching)입니다. |
| Flexibility | 非常高립性与生焉, 새로운 응답을 생성할 수 있지만, 그러나 hallucination(오상한 정보 생성)이 발생할 수 있습니다. | 靈变性가 낮은 것은 있지만, 기존 데이터를 依っ하여 hallucination이 발생하는 것이 낮습니다. |
| Response Style | 더욱 elaborate and nuanced responses를 생성할 수 있지만, 그러나 더욱 irrelevance information을 포함할 수 있습니다. | 직관적이고 간단한 답변을 제공하지만, 上下文 또는 Expansion을 欠憾할 수 있습니다. |
| Computational Cost | 계산적으로 强하게 나는 것은 대형 모델의 경우에 특히 많습니다. | 특히 효율적인 인덱싱과 search 알고리즘을 사용하면 조회가 더 빨라집니다. |
parametric 및 non-parametric 메모리의 장점을 결합하여 RAG는 전통적인 언어 모델의 제한 사항을 극복하고 더욱 정확하고, 최신되고, 컨텍스트에 일치하는 产出을 생성할 수 있게 합니다. (Redis, Lewis et al., 그리고 Guu et al.)
2.3 멀티 모달 RAG: 텍스트
멀티 모달 RAG는 이미지, 오디오, 비디오 등의 다양한 데이터 모alities을 integrate하여 대형 언어 모델 (LLM)의 인기 있는 기능을 进一步增强시키ます.
contrastive learning 기술을 사용하여 멀티 모달 RAG 시스템은 다양한 데이터 유형을 공통 벡터 공간에 embedding하는 것을 배울 수 있습니다. 이러한 것은 멀티 모달 인덱싱을 실현하는 것입니다. LLM은 가部级 上下文에 대한 이asoning를 할 수 있게 해줍니다. 텍스트 정보를 이용하면 視的 및 听覚적 인자와 결합하여 더욱 错綜复杂하고 上下文에 일치하는 产出을 생성할 수 있습니다. (Shen et al.)
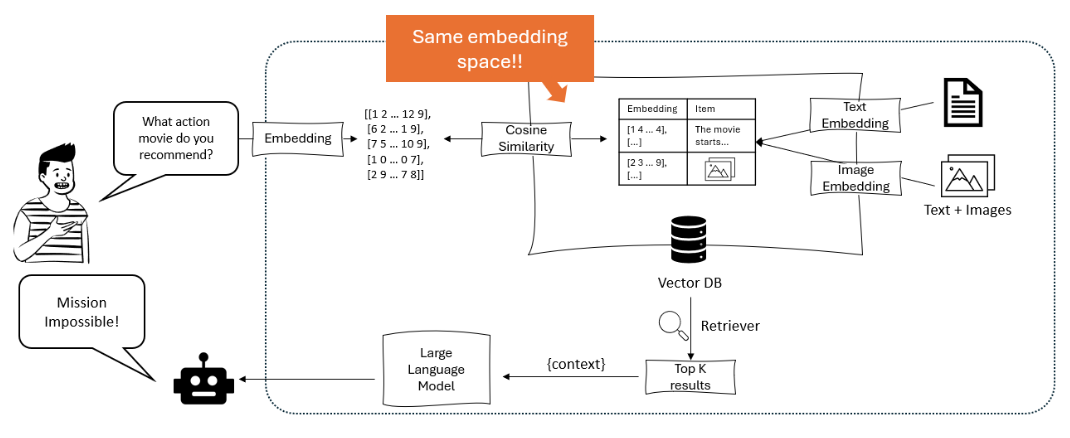
다이어그램은 대형 언어 모델이 사용자의 쿼리를 임베딩으로 처리하고, 이를 텍스트와 이미지 임베딩을 포함하는 벡터 데이터베이스 내에서 코사인 유사도를 사용하여 일치시켜 가장 관련성이 높은 항목을 추천하는 추천 시스템을 보여줍니다. – opendatascience.com
다중 모달 RAG의 주요 접근 방식 중 하나는 ViLBERT와 LXMERT와 같은 트랜스포머 기반 모델의 사용입니다. 이러한 모델은 텍스트를 생성하는 동안 이미지의 관련 영역이나 오디오/비디오의 특정 세그먼트에 주의를 기울일 수 있으며, 모달 간의 미세한 상호작용을 포착하여 시각적 및 문맥적으로 근거 있는 응답을 만들어 냅니다. 이는 시각적 질문 응답과 다중 모달 콘텐츠 생성과 같은 새로운 사용 사례를 지원하는 능력을 가지게 합니다. (Protecto.ai)
다른 모달리티 간의 의미적 표현 일치와 임베딩 프로세스 중 각 모달리티의 독특한 특성을 처리하는 것과 같은 다른 모달리티와 텍스트의 통합에는 일치시키는 도전이 따릅니다. 모달리티별 인코딩 및 교차 어텐션과 같은 기술을 사용하여 이러한 도전에 대응합니다. (Zhu et al.)
하지만 다중 모달 RAG의 잠재적 이점은 생성된 콘텐츠의 정확성, 제어 가능성, 해석 가능성의 향상뿐만 아니라 시각적 질문 응답 및 다중 모달 콘텐츠 생성과 같은 새로운 사용 사례를 지원할 수 있는 능력을 포함하여 상당합니다.
이 et al. (2020)는 시각적 질의 대답(VQA)를 위한 다중 모odal RAG 프레임워크를 제안했으며, 정확한 답변을 생성하기 위해 관련 이미지와 텍스트 정보를 검색하는 데 성능을 뛰어 넘었고, VQA v2.0와 CLEVR와 같은 벤치마크에서 이전의 최고 수준의 방법보다 우수한 성능을 보임(MyScale。
)에도 불구하고, 다중 모달 RAG는 새로운 도전을 던져 냅니다. 例如, 연산 복잡도의 증가, 대규모 다중 모달 데이터셋의 필요성, 검색된 정보에 대한 편향과 노이즈의 가능성 등이 있습니다。
연구자들은 효율적인 색인 구조, 데이터 증강 전략, 적대적 훈련 방법과 같은 기술을积极探索하여 이러한 문제를 완화하고 있습니다. (Sohoni et al.。
第三章: RAG의 핵심 메카니즘
이 장에서는 검색 강화 생성(RAG) 시스템에서 검색기와 생성 모델之间的複雑한 상호 작용을 탐구하며, 인덱싱, 검색, 정보 합성을 통해 정확하고 문맥적으로 관련된 응답을 생성하는 중요 역할을 강조합니다.
스파스 서치와 더enso 서치 기술의 미묘한 차이점을 파헤치며, 다른 시나리오에서의 강점과 약점을 비교합니다. 또한, 결합과 크로스-어텐션과 같은 검색된 정보를 생성 모델에 통합하는 다양한 전략을 탐구하고, RAG 시스템의 전체 효율성에 미친 영향을 논의합니다.
이러한 통합 strategiess를 이해하면, 특정 任务과 도메인에 따라 RAG 시스템을 최적화하는 방법에 대한 가치 있는 洞见을 얻을 수 있으며, 이를 통해 이 강력한 Paradigm의 더 인formed and 효과적인 사용을 铺路由 를 마련할 수 있습니다.
3.1 RAG에서 정보 检索과 생성의 combination의 힘
Retrieval-Augmented Generation (RAG)은 정보 检索과 생성 言語 모델을 쌍으로 통합시키는 強力한 Paradigm입니다. RAG은 이름에 따라 두 가지 주요 组成部分으로 구성되어 있습니다: 정보 检索과 생성입니다.
정보 检索 组成部分은 대량의 지식 仓储을 인덱스 하고 搜索하는 것을 담당하며, 생성 组成部分은 检索된 정보를 이용하여 战术적으로 관련이 있고 사실적으로 정확한 응답을 생성합니다. (Redis과 Lewis et al.)
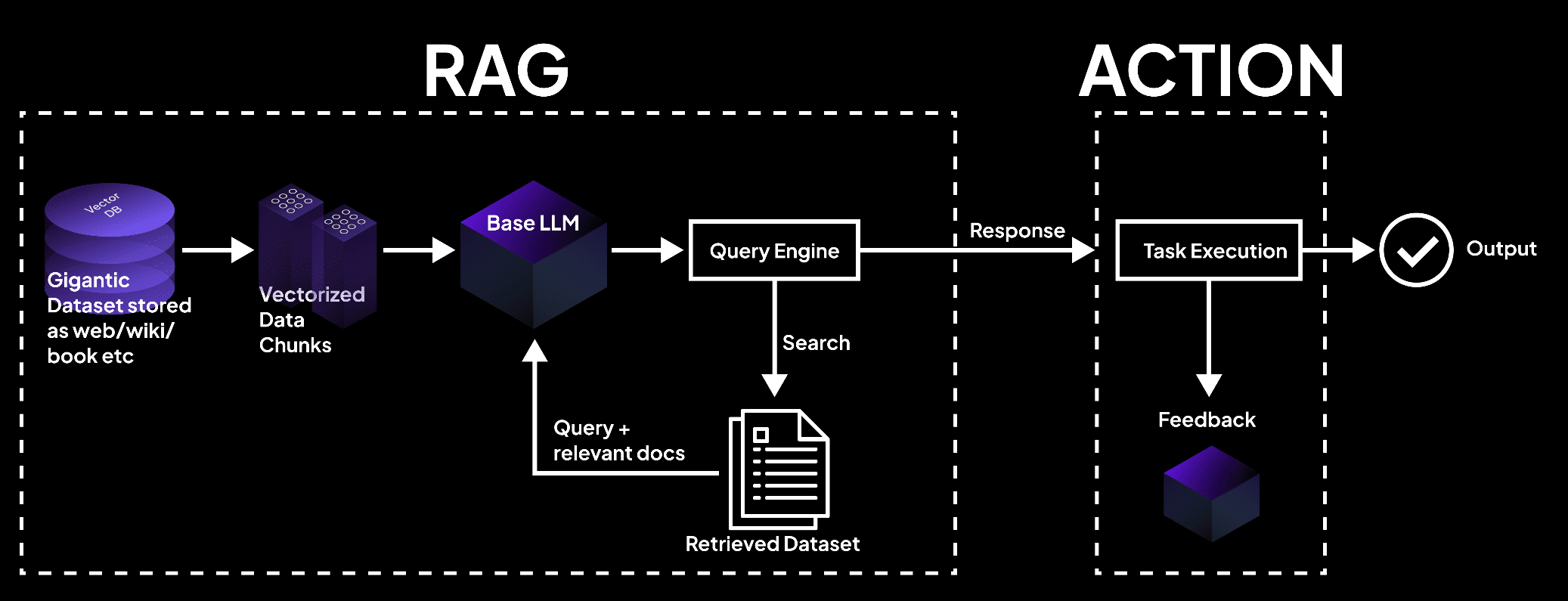
이 그림은 vector database가 데이터를 块으로 처리하여, 言語 모델로 인한 문서 检索을 통해 任务 실행과 정확한 产出을 위한 块을 의미합니다.- superagi.com
외부 지식 소스, 如火 Database, 문서, 웹 页面을 인덱스 하는 과정에서 시작하고 (Redis와 Lewis et al.) 인덱서와 RETRIEVER는 이 과정에서 중요한 역할을 합니다. 정보를 효율적으로 organizing 하고 저장하는 것을 도와, 빠른 searching 과 retrieval를 도울 수 있는 형태로 formatting 합니다.
RAG system에게 질문이 들어오면, 리턴기는 인덱스 되어 있는 지식 기반에서 가장 관련 있는 정보를 찾기 시작합니다. 이를 위해 쌍의 유사도와 다른 관련 metric을 사용합니다.
관련 정보를 리턴한 후, 생성 요소가 대신 들어가고 있습니다. 리턴한 내용은 생성적인 언어 모델을 자극하고 안내하는 것을 도와, 정확하고 정보 가득한 응답을 생성하기 위해 필요한 context와 factual grounding을 제공합니다.
언어 모델은 주목 机制과 transformer Architectures 과 같은 先进的 inferencing 기술을 사용하여 리턴된 정보와 사전 knowledge를 합하여 이를 시각적 및 연GLIDE를 생성합니다.
RAG system내에서 information flow를 이 下图과 같이 보여줍니다.
graph LR
A[Query] --> B[Retriever]
B --> C[Indexed Knowledge Base]
C --> D[Relevant Information]
D --> E[Generator]
E --> F[Response]
RAG은 다양한 장점이 있습니다:
이러한 검색과 생성 기능의 통합으로, 문맥적으로 적절한 응답 생성뿐만 아니라 가장 최신하고 정확한 정보를 기반으로 하는 응답을 만들 수 있게 되었습니다. (Guu et al.)
외부 지식 정보源的 활용으로 RAG는純粹하게 생성 모델의 특성적인 구멍인 허상 혹은 사실적으로 틀린 출력의 발생을 显著하게降低了합니다.
RAG는 또한 가장 최신의 정보를 통합할 수 있도록 하여, 생성된 응답이 주어진 분야에 대한 가장 최근의 지식과 발전을 반영할 수 있게 합니다. 이는 보건의료, 금융, 과학 연구와 같은 분야에서 정보의 정확性和 신속성이极端重要하기 때문에 특히 중요합니다. (Guu et al.와 NVIDIA)
RAG는 또한 뛰어난 적응성을 보여주며, 언어 모델이 다양한 작업들을 우수한 성능으로 처리할 수 있게 합니다. 특정 질의나 문맥에 따라 동적으로 관련 정보를 검색함으로써, RAG는 모델이 각 작업의 고유한 요구 사항에 맞춰 응답을 생성할 수 있게 만듭니다. 쿼estion 답변, 콘텐츠 생성, 도메인 전용 응용 등이 될 수 있습니다.
많은 연구들이 RAG가 생성 언어 모델의 사실적 정확도, 관련성, 적응성을 향상시키는 효과를 입증하였습니다.
Lewis et al. (2020)는 RAG가 독자적인 생성 모델들을 뛰어넘어 질문 답변 작업의 다양한 범위에서 최고의 성능을 보여주며, Natural Questions와 TriviaQA 같은 벤치마크에서 현재 최고의 결과를 달성했습니다.Lewis et al.
同样地,Izacard와 Grave (2021)는 RAG가 전통적인 언어 모델을 뛰어넘어 일관성 있고 사실적으로 일관된 긴 형식의 텍스트를 생성하는 데 우월함을 보여주었습니다.
검색-강화된 생성은 언어 생성에 대한 혁신적인 접근 방식으로, 정보 검색의 힘을 활용하여 생성 모델의 정확성, 관련성, 적응性를 향상시킵니다.
외부 지식을 사전에 존재하는 언어적 기능과 연결自如하게 통합함으로써, RAG는 자연어 처리에 새로운 가능성을 열어주고 더 지능적고 신뢰할 수 있는 언어 생성 시스템을 채택하는 길을 막론합니다.
3.2 검색기-생성기 통합 전략
검색-강화된 생성 (RAG) 시스템은 두 가지 주요 구성 요소에 의존합니다: 검색기와 생성 모델. 검색기는 대규모 지식 기반에서 효율적으로 검색하고 관련 정보를 검색하는 역할을 합니다.
“이를 위해 두 가지 주요 단계, 즉 색인(indexing)과 검색(searching)이 있습니다. 색인은 문서를 효율적인 검색을 위해 정리하며, 질적 검색을 위해 역색인(inverted indexes)을 사용하거나 밀집 벡터 인코딩(dense vector encoding)을 밀집 검색에 사용합니다.”Redis
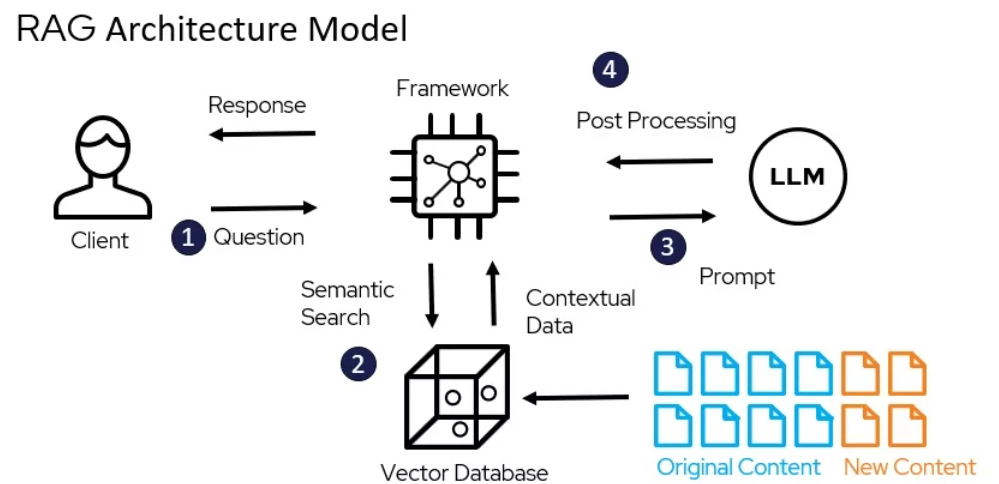
rag 아키텍처 모델 – miro.medium.com
TF-IDF와 BM25와 같은 줄기 추출 기술은 문서를 고차원의 줄기 벡터로 표현하며, 각 차원은 사전에 고유한 용어와 대응합니다. 문서가 쿼리에 대한 관련성은 용어의 중복과 그 중요성으로 가중된 것으로 결정됩니다.
예를 들어, 유명한 Elasticsearch 라이브러리를 사용하여 다음과 같이 TF-IDF 기반의 검색기를 구현할 수 있습니다:
from elasticsearch import Elasticsearch
es = Elasticsearch()
es.index(index="documents", doc_type="_doc", body={"text": "This is a sample document."})
query = "sample"
results = es.search(index="documents", body={"query": {"match": {"text": query}}})
밀집 추출 기술은 DPR(밀집 구간 추출)와 BERT 기반 모델과 같이 문서와 쿼리를 연속된 임베딩 공간의 밀집 벡터로 표현합니다. 관련성은 쿼리와 문서 벡터간의 코사인 유사도에 따라 결정됩니다.
DPR는 Hugging Face Transformers 라이브러리를 사용하여 다음과 같이 구현할 수 있습니다:
from transformers import DPRContextEncoder, DPRQuestionEncoder
context_encoder = DPRContextEncoder.from_pretrained("facebook/dpr-ctx_encoder-single-nq-base")
question_encoder = DPRQuestionEncoder.from_pretrained("facebook/dpr-question_encoder-single-nq-base")
context_embeddings = context_encoder(documents)
query_embedding = question_encoder(query)
scores = torch.matmul(query_embedding, context_embeddings.transpose(0, 1))
생성형 모델은 GPT와 T5와 같은 RAG에서 사용되어 추출된 정보를 기반으로 상호 연관이 있고 문맥적으로 관련성 있는 응답을 생성합니다. 이러한 모델을 도메인 특정 데이터에 미세 조정하고 프롬프트 엔지니어링 기술을 적용하면 RAG 시스템에서의 성능이 显著히 개선될 수 있습니다. (DEV Community)
통합 전략은 추출된 콘텐츠가 생성형 모델에 어떻게 결합되는지를 결정합니다.
.Generation 구성 요소는.prompting 및 inferencing 단계에서 추출된 콘텐츠를 활용하여 일관성 있고 문맥적으로 관련된 응답을 조성합니다. (Redis)
두 가지 일반적인 접근 방식은 연결(concatenation)과 크로스-어텐션(cross-attention)입니다.
연결은 추출된 텍스트를 입력 쿼리에 추가하여 생성 모델이 디코딩 과정에서 관련 정보를 주목할 수 있도록 합니다.
구현이 간단하지만, 이 방식은 긴 시퀀스와 불필요한 정보 처리에 어려움을 겪을 수 있습니다. (DEV Community) 크로스-어텐션 메커니즘은 RAG-Token과 RAG-Sequence와 같은 것으로, 생성 모델이 디코딩 단계마다 추출된 텍스트를 선택적으로 주목할 수 있게 해줍니다.
이를 통해 통합 과정을 더 세밀하게 제어할 수 있지만, 계산 복잡도가 증가합니다.
예를 들어, RAG-Token은 Hugging Face Transformers 라이브러리를 사용하여 구현할 수 있습니다:
from transformers import RagTokenizer, RagRetriever, RagSequenceForGeneration
tokenizer = RagTokenizer.from_pretrained("facebook/rag-token-nq")
retriever = RagRetriever.from_pretrained("facebook/rag-token-nq", index_name="exact", use_dummy_dataset=True)
model = RagSequenceForGeneration.from_pretrained("facebook/rag-token-nq")
input_ids = tokenizer(query, return_tensors="pt").input_ids
retrieved_docs = retriever(input_ids)
generated_output = model.generate(input_ids, retrieved_docs=retrieved_docs)
retriever, 생성 모델, 그리고 통합 전략의 선택은 RAG 시스템의 특정 요구 사항, 예를 들어 지식 베이스의 크기와 특성, 효율성과 효과성 사이의 밸런스, 그리고 대상 애플리케이션 도메인에 따라 다릅니다.
챕터 4: 응용 및 사용 사례
이 장에서는 얻기-강화된 생성(Retrieval-Augmented Generation, RAG)의 변혁적潛력을 살펴봅니다. RAG는 자원이 드문 언어와 다국어 응용을 혁신화하는 데에 있어서 중요한 역할을 합니다. 원문 문서를 자원이 풍부한 언어로 번역, 다국어 임베딩 활용, 그리고 데이터 제한과 언어적 차이를 극복하기 위해 연합 학습을 적용하는 등의 전략을 탐구합니다.
또한, 다국어 RAG 시스템에서의 허구 생성을 완화하는 중요한 도전을 다루어 정확하고 신뢰할 수 있는 콘텐츠 생성을 보장합니다. 이러한 혁신적 접근 방식을 탐구함으로써, 이 장은 RAG의 파워를 언어 처리의 포괄성과 다양성을 위해 이용하기 위한 포괄적인 가이드를 제공합니다.
4.1 RAG 응용: QA를 창의적인 쓰기로
RAG는 다양한 분야에서 많은 실용적인 응용을 찾아낸 데에 있어서, 우리가 정보와 상호작용하고 생성하는 방식을 혁신화하는 가능성을 보여주고 있습니다. 검색과 생성의 힘을 활용함으로써, RAG 시스템은 정확도, 관련성, 그리고 사용자 참여에 중요한 향상을 보여주었습니다.
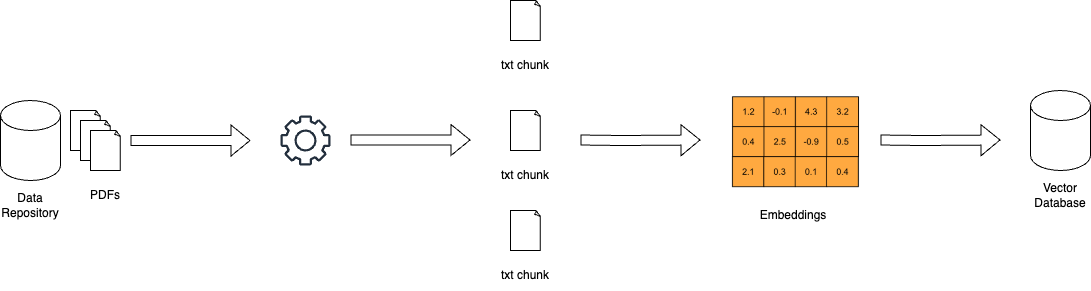
RAG의 작동 방식 – miro.medium.com
질문 대답
RAG는 질문 응답 분야에서 혁신적인 역할을 하였습니다. 외부 지식 소스에서 관련 정보를 검색하고 생성 과정에 통합하는 RAG 시스템은 사용자 질의에 더 정확하고 문맥적으로 관련된 답변을 제공할 수 있습니다. (LangChain와 Django Stars)
예를 들어, Izacard와 Grave (2021)는 Natural Questions와 TriviaQA를 포함한 여러 질문 응답 기준에서 상태-of-the-арт 성능을 달성한 RAG 기반 모델인 Fusion-in-Decoder (FiD)를 제안했습니다. (Izacard and Grave)
FiD는 밀집 검색기를 사용하여 관련 문장을 가져오고 생성 모델을 사용하여 검색된 정보를 일관성 있게 합성하여, 단순히 생성 모델을 뛰어 넘었습니다. (Izacard and Grave)
대화 시스템
RAG는 더욱 사람을 참여시키고 정보를富含시키는 대화형 에이전트 생성에도 응용되었습니다. 검색을 통해 외부 지식을 결합하면, RAG 기반 대화 시스템은 문맥적으로 적절한 반응뿐만 아니라 사실적으로 제어된 반응을 생성할 수 있습니다. (LlamaIndex와 MyScale)
Shuster 등 (2021)는 BlenderBot 2.0라는 RAG 기반 대화 시스템을 소개하고, 이를前身와 비교하여 대화 능력이 향상되었다고 제시했습니다. (Shuster 등)
BlenderBot 2.0는 Wikipedia, 뉴스 기사, 소셜 미디어를 포함한 다양한 지식 소스에서 관련 정보를 검색하여, 광범위한 주제에 대해 더욱 자세하고 일관성 있는 대화를 나눌 수 있게 합니다. (Shuster 등)
요약
RAG는 다양한 소스에서 관련 정보를 결합함으로써 생성된 요약의 품질을 향상시키는 것에 가능성을 보여주었습니다. (Hyperight) Pasunuru 등 (2021)는 PEGASUS-X라는 RAG 기반 요약 모델을 제안했으며, 이는 외부 문서에서 관련 지문을 검색하여 통합하여 더욱 정보적이고 일관성 있는 요약을 생성합니다.
PEGASUS-X는 일반적인 생성型 모델보다 several summarization benchmarks에서 이점을 보여 주었으며, 이는 인덱스를 사용하여 생성된 요약의 사실적 정확성과 관련성을 改善시키는 효과를 보여준다.
가상 쓰기
RAG의 가능성은 사실적인 영역을 벗어나 가상 쓰기의 영역으로 확장되었다. 다양한 文学 corpora에서 관련 텍스트를 인덱스로 가져와, RAG 시스템은 새롭고 魅力的な 이야기나 記事을 생성할 수 있다.
Rashkin et al. (2020)는 RAG를 기반으로 가상 쓰기 모델로 CTRL-RAG을 introduced하였으며, 대规模의 가상 데이터셋에서 관련 텍스트를 인덱스로 가져와 생성 과정에 통합시켰다. CTRL-RAG은 cohherent and stylistically consistent stories를 생성할 수 있는 능력을 보여주었고, RAG가 창의적 응용에서 가능한 потенциал을 보였다.
사례 연구
여러 연구 论文과 프로젝트가 RAG의 효과를 여러 영역에 보였다.
예를 들어, Lewis et al. (2020)는 RAG 프레임 workout을 introduced하고 오픈 영역의 질문 답변에 적용했다. 이들은 Natural Questions benchmark에서 최신 기술의 성과를 달성했다. (Lewis et al.) 그들은 효율적인 인덱스 할 수 있는 도전과 생성型 모델을 인덱스에 따라 미세 조정하는 중요성을 강조했다.
다른 케이스 스터디에서, Petroni 등 (2021)는 RAG를 사실 확인 작업에 적용하여 관련 증거를 검색하고 정확한 판결을 생성하는 능력을 보여주었습니다. 그들은 RAG가 오해 정보와 신뢰할 수 있는 정보 시스템을 향상시키는 잠재력을 보여주었습니다.
RAG가用户体验와 비지니스 메트릭에 미친 영향은 显著하였습니다. 더 정확하고 정보성 있는 응답을 제공함으로써, RAG 기반 시스템은 사용자 만족度和 参与도를 향상시켰습니다. (LlamaIndex와 MyScale)
대화형 에이전트의 경우, RAG는 더 자연스러운 대화를 가능하게 하여 사용자의 保持와 忠诚度를 높였습니다. (LlamaIndex와 MyScale) 창의적인 쓰기 분야에서 RAG는 콘텐츠 생성 과정을 교육하고 새로운 아이디어를 생성하는 데 있어 잠재력을 가지고 있으며, 비즈니스에 시간과 자원을 절약할 수 있습니다.
그래서 당신이 볼 수 있듯이, RAG의 실용적인 응용은 질문 답변과 대화 시스템에서 요약과 창의적인 쓰기까지 광범위한 분야에 걸칩니다. 검색과 생성의 힘을 활용하면 정확도, 관련성, 그리고 사용자 참여도에서 显著한 향상을 가져올 수 있습니다.
필드가 계속 발전함에 따라 우리는 RAG(검색 증강 생성)의 더욱 창의적인 응용을 예상할 수 있으며, 다양한 문맥에서 정보를 대화하고 생성하는 방식을 변형할 것입니다.
4.2 저자원 언어와 다국어 설정을 위한 RAG
검색 증강 생성(RAG)의 힘을 저자원 언어와 다국어 설정에서 활용하는 것은 단지 기회뿐만 아니라 필수입니다. 전 세계에 7,000여 가지의 언어가 사용되고 있으며, 그 중 많은 언어가 디지털 자원을 충분히 갖추고 있지 않습니다. 따라서 이러한 언어가 디지털 시대에서 뒤지지 않도록 하는 것이 어떤 것인가요?
번역이 다리가 되다
한가지 효과적인 전략은 인덱싱하기 전에 소스 문서를 더 자원이 풍부한 언어로 번역하는 것입니다. 이 접근 방식은 英语과 같은 언어에서 사용할 수 있는 광범위한 语料库를 활용하여 검색 정확성과 관련성을 显著的으로 향상시킵니다.
문서를 英语로 번역하면, 이미 고자원 언어에 대해 개발된 광범위한 자원과 고급 검색 기술을 활용할 수 있어서, 저자원 문맥에서 RAG 시스템의 성능을 향상시킵니다.
다국어 임베딩
최근 다국어 단어 임베딩의 발전은 또 다른-promising 솔루션을 제시합니다. 여러 언어를 공유하는 임베딩 공간을 생성하면, 매우 저자원 언어에서의 다국어 성능을 향상시킬 수 있습니다.
간접적으로 고품질의 임베딩을 가진 언어를 결합하면, 멀리 떨어진 언어 쌍之间的差距를弥补하며, 다국어 임베딩의 총 질을 향상시키는 것으로 연구되었습니다.
이 방법은 검색 정확性를 향상시키는 것 뿐만 아니라 생성된 콘텐츠가 문맥적으로 관련성 있고 언어적으로 일관성을 유지하도록 보장합니다.
페더레이션 러닝
페더레이션 러닝은 데이터 공유의 제약과 언어적 차이를 극복하는 새로운 접근법을 제시합니다.分散된 데이터 소스에서 모델을 微調(micro-tuning)하면 사용자의 사생활 보호를 동시에 다양한 언어에서 모델의 성능을 향상시킬 수 있습니다.
이 방법은 전통적인 방법에 비해 6.9% 높은 정확성과 99%의 학습 매개 변수 감소를 보여주었고, 다국어 RAG 시스템에 대한 효율적이고 효과적인 솔루션입니다.
Hallucinations 줄이기
다국어 환경에서 RAG 시스템을 배포할 때의 중요한 도전之一는 hallucinations를 줄이는 것입니다. 모델이 사실적으로 틀린 또는 관련 없는 정보를 생성하는 경우입니다.
고급 RAG 기술인 Modular RAG gibi은 이 문제를 해결하기 위해 새로운 모듈과 微調(micro-tuning) 전략을 도입합니다. 지식 기반을 지속적으로 업데이트하고 엄격한 평가 지표를 적용하면 hallucinations의 발생을 显著(reduce)적으로 줄일 수 있으며 생성된 콘텐츠의 정확性和 신뢰성을 보장합니다.
실제 구현
이러한 전략을 효과적으로 구현하려면 다음과 같은 실제 단계를 고려하세요:
- 번역 활용: 인덱싱 전에 자원이 드문 언어의 문서를 영어와 같은 자원이 풍부한 언어로 번역합니다.
- 多义词嵌入 활용 : 중간 언어와 고품질의嵌入을 결합하여 다국어间的 성능을 향상시키세요.
- 연합 학습 채택 :分散된 데이터 소스에서 모델을 미세 조정하여 성능을 향상시키면서 개인정보를 보호하세요.
- 환각.Suppress : 고급 RAG 기술 및 지속적인 지식 베이스 업데이트를 사용하여 사실적 정확성을 보장하세요.
이러한 전략을 채택함으로써, RAG 시스템의 소자원 및 다국어 환경에서의 성능을 显著的으로 향상시키며, 디지털 혁명에서 어떤 언어도 두기하지 않게 할 수 있습니다.
第五章: 최적화 기술
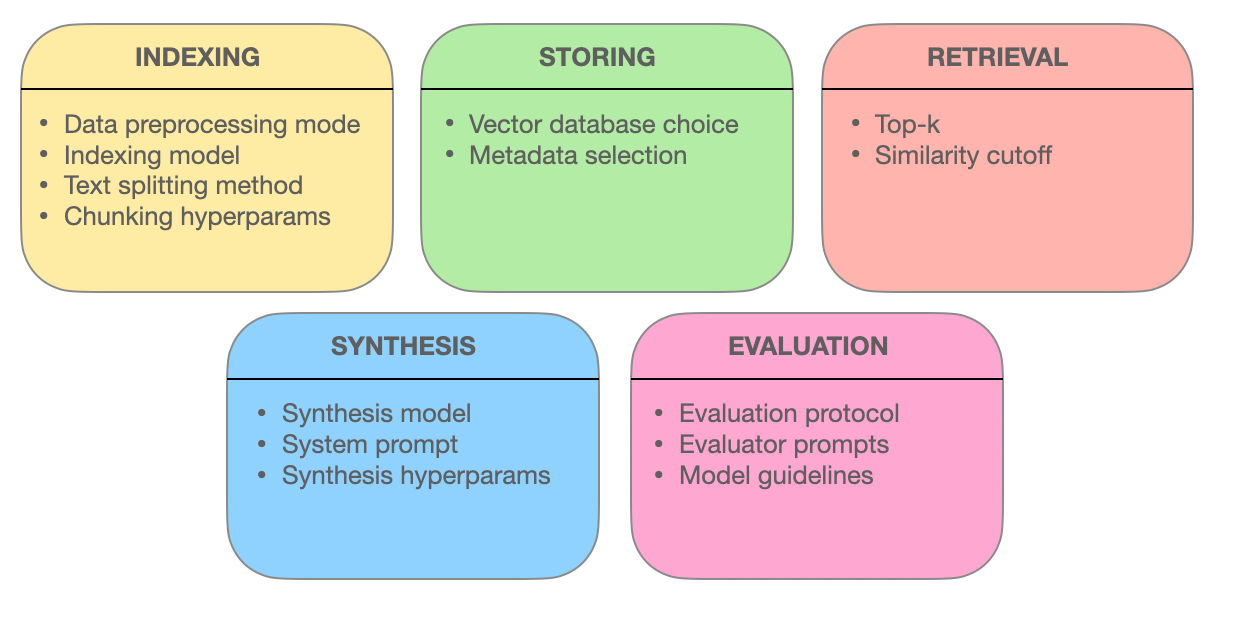
이 장에서는 추출 강화 생성 (RAG) 시스템의 효과성을支える 고급 추출 기술을 탐구합니다. 청크 최적화, 메타데이터 통합, 그래프 기반 색인, 정렬 기술, 하이브리드 검색, 재랭크 등이 정보 추출의 정확성, 관련성, 완전성을 향상시키는 방법을 알아봅니다.
이러한 선진 기술을 이해함으로써, RAG 시스템이 간단한 검색 엔진에서는 아닌 복잡한 질의를 이해하고 정확하고 문맥적으로 관련된 응답을 제공할 수 있는 지능적인 정보 제공자로 발전하는 방식을 이해할 수 있습니다.
5.1 RAG 시스템 최적화를 위한 고급 추출 기술
추출 강화 생성 (RAG) 시스템은 우리가 정보에 접근하고 활용하는 방식을 혁신시킵니다. 이러한 시스템의 핵심은 관련 정보를 효과적으로 추출하는 능력입니다.
다음과 같이 한국어로 번역합니다.
진보된 검색 기술에 대해 더욱 깊이 있게 탐구하여 RAG 시스템이 정확하고 문맥적으로 관련이 있고 종합적인 응답을 제공할 수 있도록 강화합니다.
청크 최적화: 그래너리 트리버스를 통한 관련성 극대화
RAG 시스템의 세계에서는 대형 문서가 어려워질 수 있습니다. 청크 최적화는 이러한 도전을 극복하고자 광범위한 텍스트를 더 작고 관리하기 쉬운 유닛인 청크로 나누는 것입니다. 이러한 그래너리 트리버스는 검색 시스템이 질의어와 일치하는 특정 텍스트 부분을 명확하게 찾을 수 있도록 만들어 정확성과 효율성을 향상시킵니다.
청크 최적화의 핵은理想的한 청크 크기와 중복을 결정하는 것입니다. 너무 작은 청크는 문맥을 잃을 수 있고, 너무 큰 청크는 관련성을 떨어트릴 수 있습니다. 동적 청크화는 콘텐츠의 구조와 의미를 기반으로 청크 크기를 조정하는 기술로, 각 청크가 일관성 있고 문맥적으로 의미 있게 됩니다.
메타데이터 통합: 정보 태그의 힘을 활용
문서와 함께 오는 종종 놓치는 메타데이터는 검색 시스템의 골드 마인입니다. 문서 유형, 저자, 발행 일자, 주제 태그와 같은 메타데이터를 통합하면 RAG 시스템은 더 명확한 검색을 수행할 수 있습니다.
메타데이터 통합으로 가능한 자기 질의 검색은 시스템이 초기 결과를 기반으로 추가적인 질의를 생성할 수 있게 만들어집니다. 이 반복적인 과정은 검색을 세분화하여, 검색된 문서가 질의와 일치하는 것 뿐만 아니라 사용자의 특정 요구 사항과 문맥적인 필요를 충족시키도록 합니다.
고급 인덱싱 구조: 복잡한 질의를 위한 그래프 기반 네트워크
전통적인 색인 방법들은, 예를 들어 역색인과 밀집 벡터 인코딩은 다수의 엔티티와 그들의 관계를 가지고 복잡한 쿼리를 처리할 때 한계가 있다. 그래프 기반의 색인은 문서와 그들의 연결을 그래프 구조로 정리함으로써 해결책을 제시한다.
이러한 그래프 모양의 조직은 복잡한 시나리오에서도 관련 문서를 효율적으로 탐색하고 검색할 수 있게 해준다. 계층적인 색인과 近似최근접ighbor 검색은 그래프 기반의 검색 시스템의 확장성과 속도를 더욱 강화한다.
정렬 기술: 정확성 보장과 허상 감소
RAG 시스템의 신뢰성은 정확한 정보를 제공하는 능력에 달려 있다. 반대사례 학습 같은 정렬 기술은 이 문제를 해결한다. 가상의 시나리오에 모델을 노출시키는 반대사례 학습은 실제 세계의 사실과 생성된 정보를 구별하게 해, 허상을 줄여준다.
다중 모달 RAG 시스템은 텍스트와 이미지와 같은 다양한 소스의 정보를 통합한다. 대조적 학습은 중요한 역할을 한다. 이 기술은 서로 다른 데이터 모달итি의 의미 表現을 정렬시키는데, 검색된 정보가 일관성 있고 문맥적으로 통합되었는지 보장한다.
하이브리드 검색: 키워드 정밀도와 의미 이해의 결합
하이브리드 검색은 키워드 기반 검색의 속도와 정밀도와 벡터 검색의 의미 이해를 결합한 최고의 것을 제공한다. 초기에는 키워드 기반 검색이 문서의 잠재적인 풀을 빠르게 좁힌다.
다음과 같은 결과를 기반으로 벡터 기반의 검색은 의미 유사성을 통해 결과를 정제합니다. 이 방식은 정확한 키워드 일치가 중요한 경우 특히 효과적이며, 쿼리의 의도를 더 깊이 이해하는 것이 정확한 검색을 위해 필수적입니다.
재랭킹: 최적의 응답을 위한 관련성 정제
검색의 마지막 단계에서는 재랭킹을 통해 결과를 더 가공합니다. 크로스-인코더와 같은 기계 학습 모델은 검색된 문서의 관련성 점수를 재评估합니다. 쿼리와 문서를 함께 처리하면 이 모델은 관계를 더 깊이 이해합니다.
이러한 미묘한 비교는 가장 높은 랭크를 받은 문서가 사용자의 쿼리와 문맥과 진실로 일치하는지 보장합니다. 이를 통해 더 만족스러운 및 정보성 있는 검색 경험을 제공합니다.
RAG 시스템의 가치는 정보를 부드럽게 검색하고 제공하는 능력에 있습니다. 이러한 고급 검색 기술 – 청크 최적화, 메타데이터 통합, 그래프 기반 인덱싱, 정렬 기법, 하이브리드 검색, 재랭킹 – 을 적용하면 RAG 시스템은 단순한 검색 엔진 이상으로 발전합니다. 복잡한 쿼리를 이해하고, 미묘한 차이를辨识하며, 정밀하고, 관련성 있고, 신뢰할 수 있는 응답을 제공할 수 있는 지능형 정보 제공자가 됩니다.
第六章: 도전과 혁신
이 장에서는 검색 증강 생성 (RAG) 시스템의 개발과 배포에 있어서의 중요한 도전과 미래의 방향에 대해 다룹니다.
RAG 시스템의 평가에 대한 복잡성을 탐구하고, 기본적인 지표와 적응型 프레임웍을 사용하여 그들의 성능을 정확하게 평가하는 必要性을 address하며, 정보 조회 및 생성에 대한 伦理性 인식과 편향 軽減, Fairness를 중심으로 다루고자 합니다.
하드웨어 성능 개선 및 효율적인 배포 전략에 관심을 가지고 있으며, 특수 하드웨어와 오PTimum과 같은 オPTimation 도구를 사용하여 パフォーマンス 및 スケーラビリ티를 향상시키는 것을 higlight합니다.
이러한 도전을 이해하고 가능한 솔루션을 탐구하는 것으로부터 시작하여, 이 섹션은 RAG 기술의 계속적인 발전과 负责的인 実装을 위한 모범 도로를 제시합니다.
6.1 도전과 未来发展
Retrieval-Augmented Generation (RAG) 시스템은 생성된 텍스트의 정확성, 관련성, 및 일관성을 향상시키는 데에 Remarkable 潜力을 보였습니다. 하지만, RAG 시스템의 開発과 배포는 그들의 潜力을 完全하게 실현하기 위한 중요한 도전을 가지고 있습니다.
“RAG 시스템의 평가는 특정 구성 요소와 전체 시스템 평가의 복잡성을 고려해야합니다.” (Salemi et al.)
RAG 시스템 평가에 대한 도전
RAG의 주요 기술적 도전 사항 중 하나는 대규모 지식 베이스에서 관련 정보의 효율적인 검색을 보장하는 것입니다. (Salemi et al.와 Yu et al.)
지식 소스의 크기와 多様性가 지속적으로 증가함에 따라, 스케일 가능하고 견고한 검색 메커니즘의 개발이 점점 더 중요해지고 있습니다. 계층적 인덱싱, 근사한 최근접 이웃 검색, 적응형 검색 전략과 같은 기술을 탐구하여 검색 프로세스를 최적화해야 합니다.
RAG 시스템에 관련된 요소 일부 – miro.medium.com
또 다른 중요한 도전 사항은 발생하는 정보가 사실적으로 틀릴 때나 일관성 없을 때의 환각 문제를 완화하는 것입니다.
예를 들어, RAG 시스템은 실제로 발생하지 않은 역사적 사건을 생성하거나 과학 발견을 잘못 식별할 수 있습니다. 검색은 생성된 텍스트를 사실적 지식에 근거지만, 생성 출력의 신뢰성과 일관성을 보장하는 것은 여전히 복잡한 문제입니다.
예를 들어, RAG 시스템은 Wikipedia와 같은 신뢰할 수 있는 소스에서 과학 발견에 대한 정확한 정보를 검색할 수 있지만, 생성 모델이 이 정보를 잘못 결합하거나 존재하지 않는 세부 사항을 추가할 수 있습니다.
사이버 안전 기반 인공지능 시스템의 개발에 있어서 가상적인 것을 감지하고 예방하는 효율적인 기계적 제어 机制 개발이 활동적인 연구 분야입니다. 외부 데이터베이스를 사용해 사실 확인하는 기술과 다양한 자료를 cross-referencing 하여 일치성 검사를 실시하는 기술은 Active 연구 중입니다. 이러한 방법은 인덱스 추출과 생성 과정을 조합하는 inherently challenging 과정에서 생성 내용이 정확하고 신뢰할 만한 것처럼 유지되도록 하는 것입니다.
RAG 시스템에서 구조화된 데이터베이스, 불구조化的 텍스트, 다양한 형태의 다양한 자료 souces 를 통합하는 것은 extra 한 도전을 제시합니다. (Yu et al. 과 Zilliz) 다양한 자료 모alities 과 지식 형식 사이에서 표현과 의미를 일치시키는 것은 错綜複雑한 기술, 예를 들어 cross-modal attention 과 knowledge graph embedding 이 필요합니다. 다양한 지식 소스 사이의 호환성과 interoperability를 보장하는 것은 RAG 시스템이 有效的하게 기능하는 것이 중요합니다. (Zilliz)
기술적 도전 이외에 RAG 시스템은 중요한 윤리적 고려 사항을 쫓는다. unfair information retrieval and generation 을 보장하는 것은 결정적인 懸念이다. RAG 시스템은 훈련 데이터 또는 지식 소스에 있는 편향을 inoadvertently amplify 할 수 있다는 것이 discriminatory 또는 misleading outputs 를 일으키는 것과 같다. (Salemi et al. 와 Banafa)
biases 를 detect 하고 mitigate 하는 기술, 如火如荼 training 과 fairness-aware retrieval 과 같은 것을 開発する 것은 중요한 연구 방향이다. (Banafa)
Future Research Directions
RAG 시스템의 도전을 대응하기 위해서는 여러 가능한 해결 方案과 연구 방향을 探求할 수 있다.
retrieval accuracy 과 generative quality 사이의 상호 작용을 捕获하는 모든 평가 지표를 개발하는 것은 중요하다. (Salemi et al.)
관련성, 일관성, 사실적 정확성을 평가하는 지표를 설정할 필요가 있으며, 검색성능의 효과성도 고려해야 합니다. (Salami et al.) BLEU와 ROUGE 같은 전통적인 지표를 넘어 인간의 평가와 작업특정 측정을 포함하는 종합적인 접근이 필요합니다.
적응형과 실시간 평가 프레임워크를 탐구하는 것은 또 다른 유망한 방향입니다.
RAG 시스템은 지식 来源과 사용자 요구사항이 시간이 지나면서 변화할 수 있는 동적 환경에서 운영됩니다. (Yu et al.) 이러한 변화에 적응할 수 있고 시스템 성능에 대한 실시간 피드백을 제공하는 평가 프레임워크를 개발하는 것이 지속적인 개선과 모니터링에 필수입니다.
이를 위해 온라인 학습, 액티브 학습, 강화학습과 같은 기술을 사용하여 사용자 피드백과 시스템 동작에 따라 평가 지표와 모델을 업데이트할 수 있습니다. (Yu et al.)
학문적 연구자, 산업 현장 전문가, 그리고 관련 지식 분야 전문가들之间的협력이 RAG 평가 분야의 발전에 필수적입니다. 표준화된 벤치마크, 데이터셋, 평가 프로토콜을 설정함으로써 RAG 시스템을 여러 가지 도메인과 응용 사례에서 비교하고 재현할 수 있게 해줄 수 있습니다. (Salami et al.와 Banafa)
최종 사용자, 정책 결정자를 포함한 관련자들과의 소통은 RAG 시스템의 개발과 배포가 사회 가치 및 윤리 원칙과 일치하도록 보장하는데至关重要합니다. (Banafa)
RAG 시스템은 极大的潛力를 보였지만, 평가에 있어서의 어려움을 해결하는 것은 그들의 광범위한 채용과 신뢰를 위해 필수입니다. 포괄적인 평가 지표를 개발하고, 적응형 및 실시간 평가 프레임워크를 탐구하고 협력을 격려함으로써 더 신뢰할 수 있고, 고독성 없고 효과적인 RAG 시스템을 마련할 수 있습니다.
이 분야가 계속 발전함에 따라, RAG의 기술적 능력을 향상시키는 연구 노력뿐만 아니라 실제 응용 사례에서 책임감 있고 윤리적으로 배포되는 것을 보장하는 연구를 우선적으로 하는 것이 중요합니다.
6.2 하드웨어 가속화와 RAG 시스템의 효율적 배포
하드웨어 가속을 활용하는 것은 검색 증강 생성(RAG) 시스템의 효율적인 배포에 필수적입니다. 계산 집약적인 작업을 특수 하드웨어로 오프로드하면 RAG 모델의 성능과 확장성을 크게 향상시킬 수 있습니다.
특수 하드웨어 활용
Optimum의 하드웨어별 최적화 도구는 상당한 이점을 제공합니다. 예를 들어, Habana Gaudi 프로세서에서 RAG 시스템을 배포하면 추론 지연 시간이 현저히 감소할 수 있으며, Intel Neural Compressor 최적화는 지연 시간 메트릭을 더욱 개선할 수 있습니다. Optimum Neuron을 통해 최적화된 AWS Inferentia 하드웨어는 처리 능력을 향상시켜 RAG 시스템을 더 반응적이고 효율적으로 만듭니다.
자원 활용 최적화
효율적인 자원 활용은 매우 중요합니다. Optimum ONNX Runtime 최적화는 메모리 사용 효율성을 높일 수 있으며, BetterTransformer API는 CPU 및 GPU 활용을 개선할 수 있습니다. 이러한 최적화를 통해 RAG 시스템이 최대 효율로 운영되도록 하여 운영 비용을 절감하고 성능을 향상시킵니다.
확장성 및 유연성
Optimum은 다양한 하드웨어 가속기 간의 원활한 전환을 지원하여 동적 확장성을 가능하게 합니다. 이러한 다중 하드웨어 지원은 큰 재구성 없이도 다양한 계산 요구에 적응할 수 있게 합니다. 또한 Optimum의 모델 양자화 및 가지치기 기능은 더 효율적인 모델 크기를 촉진하여 배포를 더 쉽고 비용 효율적으로 만듭니다.
사례 연구 및 실세계 응용 프로그램
의료 정보 조회 분야에서 Optimum의 적용을 고려하십시오. RAG 시스템은 하드웨어 specifi c 優化 사항을 이용하여 大数据셋을 효율적으로 처리하며 정확하고 时刻에 따라 정보 조회를 제공합니다. 이는 의료 서비스의 질을 改善하는 뿐만 아니라 전체 사용자 경험을 향상시키ます.
실용적인 실행 단계
- 적절한 하드웨어 선택: specific performance requirements에 따라 Habana Gaudi나 AWS Inferentia 과 같은 hardware accelerators를 선택합니다.
- 優化 도구 사용: Optimum의 optimization tools를 적용하여 딜레이, throughput, 리소스 utilization을 향상 시키십시오.
- 스케일ability 보장: multi-hardware support를 이용하여 RAG system을 필요에 따라 동적으로 스케일링 시키십시오.
- 모델 크기 優化: model quantization과 pruning을 사용하여 연산 오버ヘッド을 감소시키고 更容易 하게 배포를 지원하십시오.
이러한 전략을 통합하면 RAG system의 パフォーマンス, スケーラビリティ, 및 效率을 顕著하게 향상시키고, 複雑한, 실제 세계적인 응용에 적합한 장비가 되는 것을 보장할 수 있습니다.
결론: RAG의 변화적 잠재력
Retrieval-Augmented Generation (RAG)는 자연어 처리에서 변화적 paradigms를 represent하며, 정보 조회의 힘과 대형 언어 모델의 생성적 능력을 Integration하는 것을 seamles sly 실현합니다.
By leveraging external knowledge sources, RAG 시스템들은 질문 응답 및 대화 시스템을 비롯한 많은 응용 프로그램에서 생성된 텍스트의 정확성, 관련성, 그리고 일관성에 뛰어난 개선을 보여주었습니다.
언어 모델의 발전, 초기의 규칙 기반 시스템에서 BERT와 GPT-3와 같은 최신 신경 아키텍처로의 변화는 RAG의 등장을 가능하게 만들었습니다. 전통적인 언어 모델에서의 파라미etric 메모리의 한계, 예를 들어 지식의 갈切段 기록과 사실적인 불일치,은 검색 메커니즘을 통해 비파라미etric 메모리의 결합으로 효과적으로 해결되었습니다.
RAG 시스템의 핵심 구성 요소인 검색기(retrievers)와 생성 모델(generative models)은 상호 협력하여 문맥상 관련성이 있고 사실적으로 고정된 출력을 생산합니다.
검색기는 스파스(sparse) 및 밀집(dense) 검색과 같은 기술을 사용하여 광대한 지식 기반을 효율적으로 탐색하여 가장 관련성 있는 정보를 식별합니다. 생성 모델은 GPT와 T5와 같은 아키텍처를 활용하여 검색된 내용을 일관성 있고 흐름이 잘되는 텍스트로 합성합니다.
결합 стратег이들, 예를 들어 연결(concatenation)과 교차_Attention(cross-attention), 검색된 정보가 생성 과정에 어떻게 결합되는지 결정합니다.
RAG의 실제 응용은 다양한 분야를 가로지르며, 다양한 산업을 혁신시킬 수 있는 잠재력을 보여주고 있습니다.
질문 응답에서 RAG는 응답의 정확성과 관련성을 크게 향상시켜 더 많은 정보를 제공하고 신뢰할 수 있는 정보 검색을 가능케 하였습니다. 대화 시스템은 RAG로부터 혜택을 받아 더 매혹적이고 일관된 대화를 이루고 있습니다. 요약 작업은 다수의 소스로부터 관련 정보를 통합함으로써 향상된 품질과 일관성을 보고 있습니다. 창의적 작문조차도 RAG 시스템에 의해 탐구되어 새롭고 스타일적으로 일관된 이야기를 창출하고 있습니다.
하지만 RAG 시스템의 개발 및 평가는 상당한 과제를 제시합니다. 대규모 지식 베이스로부터의 효율적인 검색, 환각의 완화, 다양한 데이터 모달리티의 통합 등 기술적 장벽들이 극복되어야 합니다. 바이어스 없는 공정한 정보 검색 및 생성을 보장하는 윤리적 고려 사항이 RAG 시스템의 책임 있는 배포에 중요합니다.
RAG의 잠재력을 완전히 발휘하기 위해, 향후 연구 방향은 검색 정확성과 생성 품질 간의 상호작용을 포착하는 포괄적인 평가 지표 개발에 초점을 맞추어야 합니다.
동적인 RAG 시스템의 성격을 다룰 수 있는 적응형 및 실시간 평가 프레임워크는 지속적인 개선과 모니터링을 위해 필수적입니다. 연구자, 산업 실무자 및 전문가들 간의 협력적 노력은 표준화된 기준, 데이터셋 및 평가 프로토콜을 확립하기 위해 필수적입니다.
RAG 분야가 지속적으로 발전하며 우리가 정보에 대한 인터랙션 및 생성을 어떻게 変えるか에 대한 immense promise를 보여줍니다. 인덱스 추출 및 생성의 힘을 사용하는 RAG 시스템은 정보 인덱스 추출, 대화 エージェン트에서 コンテンツ 생성과 知識 発見まで 다양한 domains를 혁신시키는 잠재력을 가지고 있습니다.
Retrieval-Augmented Generation은 더 지능적, 정확하고 контекстуально 유용한 언어 생성 방법으로 가까이 오는 道上에 중요な milestone을 represent합니다.
パラメ틱 메모리와 非パラメ틱 메모리 사이의 沟を 桥渡した RAG 시스템은 自然言語処理과 その 응용에 대한 새로운 posibilities를 개방하였습니다.
研究和 도전을 해결하면서 진행되면 RAG이 인간과 기계의 대화 및 知識 생성의 futur shapeshaping에 더욱 중요한 역할을 하게 될 것입니다.
著者 정보
Vahe Aslanyan, computer science, data science, and AI의 枢纽에 있습니다. vaheaslanyan.com를 방문하여 정밀과 진전을 物語는 포트폴리오를 보십시오. 전 스택 개발과 AI 제품 최적화를 桥渡す 경험을 가지고 있으며, 새로운 방법으로 문제를 해결하는 것이 drive하고 있습니다.
领先的数据分析引导营를 기획하고 산업 トップ 전문가들과 협력한 이력을 가지고 있으며, 저는 기술 교육을 모두가 이해하는 표준으로 提升了하는 것에 주목합니다.
你想更深入地学习吗?
이 가이드를 공부한 후, 더 깊이 있고 구성 적은 학습이 당신의 스타일인 경우, LunarTech에서 개인 과정과 데이터 과학, 기계 leaning, AI 引导营을 제공합니다.
우리는 이론의 깊은 이해, practical implementation, 멋진 실습 자료, AND 맞춤형 면접 준비를 제공하여 당신의 단계에 따라 성공을 준비하도록 도와드리고 있습니다.
최고의 데이터 과학 부캠프를 확인하시고 먼저 컨텐츠를 체험해보시기 위해 무료 트라이얼을 신청하세요. 이 부캠프는 2023년 최고의 데이터 과학 부캠프로 인정 받으며, 포브스, 야후, 엔터프레너 등 우수한 언론出版物에 소개되었습니다. 이곳은 혁신과 지식을 향한 열정을 가진 커뮤니티에 가입할 수 있는 기회입니다. 환영 메시지입니다!
나와 연결하세요.

로unarTech 뉴스레터
데이터과학, 머신 러닝 및 AI를 주력하는 경력에 대한 자세한 정보를 원하시거나 데이터과학 일자리를 확보하는 방법을 배우고자 한다면, 이 데이터과학 및 AI 경력 핸드북을 무료로 다운로드하세요.
Source:
https://www.freecodecamp.org/news/retrieval-augmented-generation-rag-handbook/