













우버와 같은 회사에서 실시간 데이터는 고객 맞춤 서비스와 내부 서비스 모두의 생명선입니다. 고객은 실시간 데이터를 통해 편리하게 택시를 부르거나 음식을 주문합니다. 내부 팀도 최신 데이터에 의존하여 고객 맞춤 애플리케이션의 기반 인프라를 구동하는데, 이 중에서도 모바일 앱 크래시 분석을 모니터링하는 자체 도구에 중점을 둡니다.
우버는 이 자체 도구를 구동하기 위해 Apache Pinot으로 마이그레이션하여 이전 분석 엔진(Elasticsearch)에 비해 상당한 개선을 경험했습니다. Pinot으로 이전함으로써, 진정한 실시간 분석 플랫폼을 통해 우버는 다음과 같은 이점을 보았습니다:
- 인프라 비용 70% 감소(연간 $2M 이상 절감)
- CPU 코어 80% 감소
- 데이터 크기 66% 감소
- 페이지 로드 시간 64% 감소(14초에서 5초 미만으로)
- 데이터 수집 지연 감소(<10밀리초)
- 쿼리 타임아웃 감소 및 데이터 손실 문제 제거

지금 보기
이 블로그 내용은 Apache Pinot 사용자 스토리를 다룬 인문 미팅을 기반으로 합니다. 또한 우버 엔지니어링 팀의 블로그를 참조하여 모바일 앱 크래시에 대한 실시간 분석을 제공하는 방법을 다룹니다. 미팅을 시청하려면 여기를 클릭하세요:
또는 Apache Pinot으로 이러한 결과를 얻은 방법을 계속 읽어보세요.
우버가 모바일 앱 크래시에 대한 실시간 분석을 제공하는 방법
우버는 앱 충돌을 추적하고 수사 데이터를 수집하는 자동화된 섭취 파이프라인을 보유하고 있습니다. 이 데이터 중 일부는 변환을 위해 Apache Flink에 섭취되어 Kafka 토픽에 다시 저장되어 다운스트림 소비를 위해 사용됩니다. Kafka의 이러한 원시 및 처리된 이벤트는 그런 다음 Apache Pinot에 의해 소비되어 분석 쿼리를 실행하고 결과는 Grafana 및 내부 시각화 도구를 통해 내부 사용자에게 전달됩니다. 파이프라인은 실시간 및 오프라인 데이터(표시되지 않음)를 모두 섭취하여 Apache Pinot의 하이브리드 테이블로 사용자의 전체 뷰를 생성합니다.
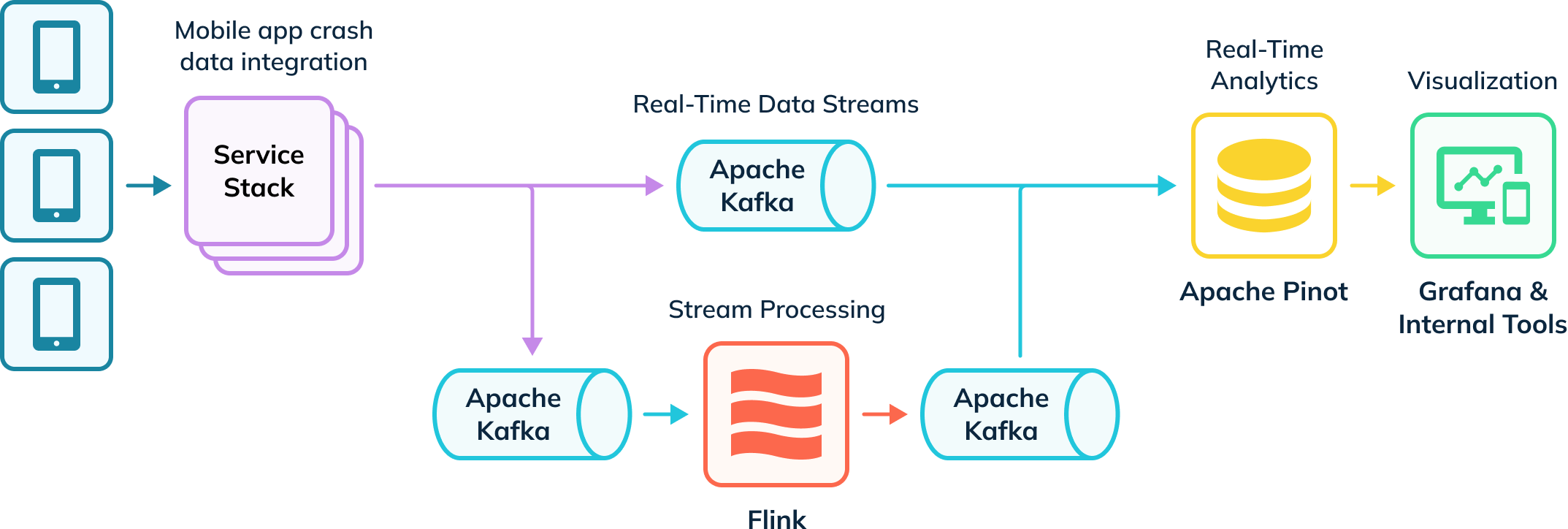
Apache Pinot을 통한 실시간 앱 충돌 분석
우버는 매주 약 11,000개의 새로운 코드 및 인프라 변경 사항을 배포하며, 충돌 문제를 감지하고 해결하는 데 도움이 되는 자체 도구(Healthline)에 의존합니다. Healthline을 통해 우버는 Mean Time To Detect(MTTD)를 더 잘 측정하고 달성할 수 있습니다. 예를 들어, 예기치 않은 앱 충돌을 일으키는 새로운 기능을 롤아웃할 수 있으며, 충돌 데이터를 파고들어 충돌의 원인을 신속하게 조사할 수 있어야 합니다.
아래 대시보드는 하나의 모바일 앱과 운영 체제의 한 버전에 대한 일주일 분량의 충돌 데이터를 보여줍니다. 이 예에서 세션 이벤트는 초당 수십만 번까지 발생하며 충돌은 초당 15,000에서 20,000까지의 이벤트를 측정합니다. 우버는 이러한 메트릭을 결합하여 치명적 충돌이 없는 비율을 계산하여 애플리케이션의 상태를 나타냅니다(목표는 100%에 가까워지는 것임).
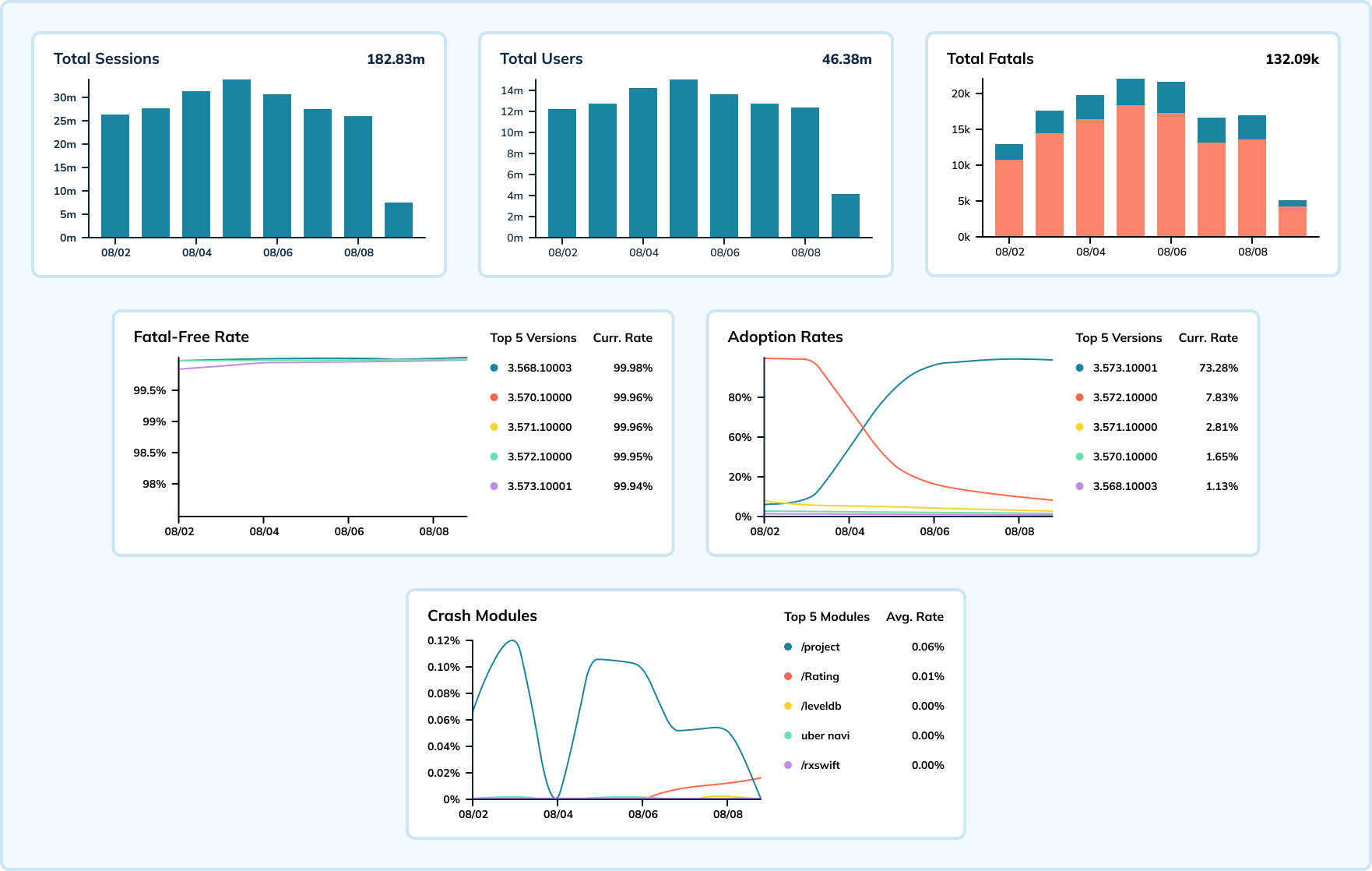
Elasticsearch를 사용하면 일반 목적 검색 엔진은 충돌 빈도의 급증으로 인해 섭취 지연이 발생하고 문제 식별에 대한 팀의 대응을 지연시킵니다. 거대한 규모의 실시간 분석을 위해 특별히 설계된 Apache Pinot으로 이전하면서 팀은 섭취 지연의 수와 심각성이 감소했습니다.
충돌 데이터 심층 분석
충돌 데이터의 고도대 개요 외에도 Uber은 충돌 수준 분석을 제공합니다. 운영 체제 및 버전별 충돌 횟수, 버전별 충돌 분포 등 다양한 차원에서 충돌 지표를 집계합니다. 이 사용 사례는 특정 유형의 충돌이 발생한 시기, 영향을 받는 버전, 발생 횟수 및 영향을 받는 사용자 및 기기 수를 공유하기 위해 여러 Pinot 인덱스(범위, 역전, 텍스트)를 활용합니다.
심층 분석을 위해 Uber은 충돌 오류 메시지를 읽을 수 있는 텍스트 검색 기능이 필수적이었습니다. Pinot의 텍스트 인덱스는 Lucene을 기반으로 하며 충돌 메시지, 클래스 이름, 스택 추적 등으로 충돌을 검색할 수 있는 기능을 제공합니다.
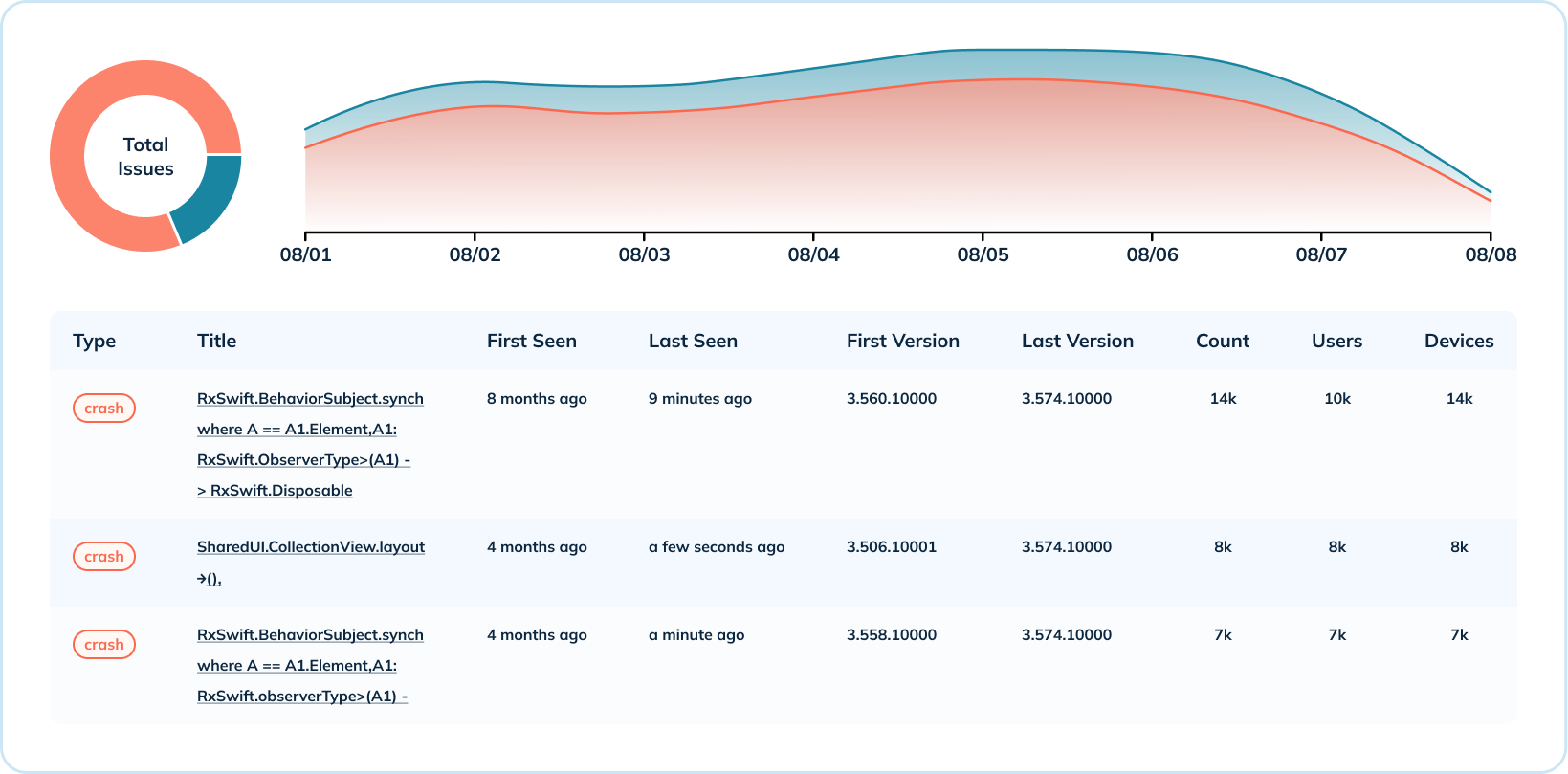
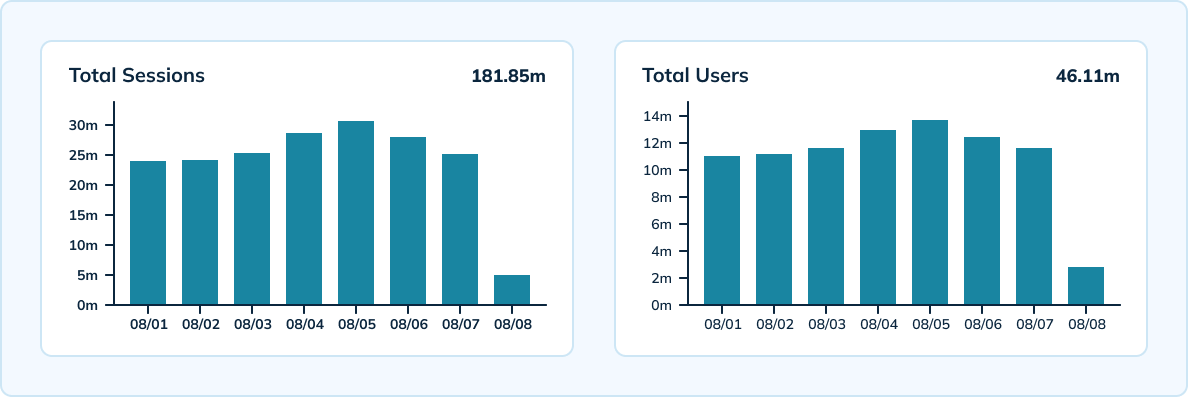
규모에 따른 세션 측정
Uber은 또한 Pinot을 사용하여 기기, 버전, 운영 체제 및 시간별로 고유 세션을 규모에 맞게 측정합니다. Pinot은 Uber의 초당 30만 건의 분석 이벤트를 처리할 수 있는 고처리량의 실시간 처리를 제공합니다. 팀은 10분 간격과 3일 데이터 보존을 갖춘 실시간 테이블과 시간 및 일별 간격과 45일 데이터 보존을 갖춘 오프라인 테이블을 포함한 하이브리드 설정을 갖추고 있습니다.
아파치 핀올의 하이퍼로그로그를 활용하면 팀은 저장되는 이벤트의 수를 줄일 수 있고, 이벤트 간에 훨씬 적은 고유 집계를 수행할 수 있습니다. 핀올은 매우 낮은 지연 시간도 제공합니다 — p99.5 지연 시간은 100 밀리초 이하입니다.
인프라 비용 절감
Uber의 계산에 따르면, 핀올로 마이그레이션하면 매년 2백만 달러 이상의 인프라 비용을 절감할 수 있습니다. 핀올 설정을 통해 Elasticsearch에 비해 인프라 비용이 70% 감소했습니다. 또한 CPU 코어를 80% 감소시키고 데이터 피트프린트를 66% 감소시켰습니다.

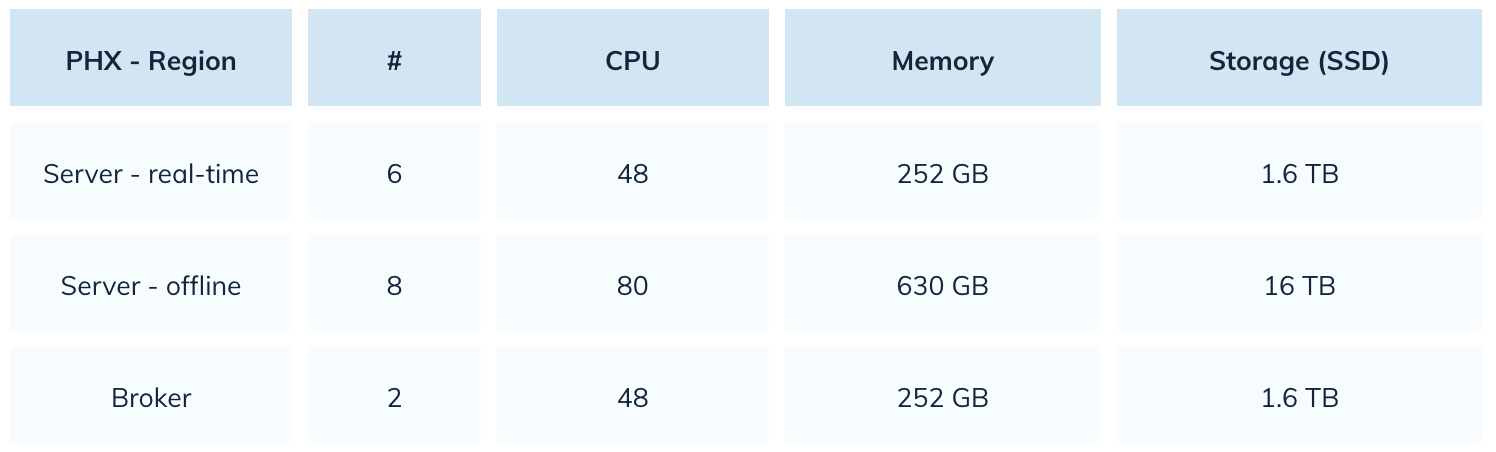
Elasticsearch를 사용했을 때 Uber는 22,000 코어의 CPU를 사용했습니다. 핀올을 사용하면 이 숫자를 80% 감소시킬 수 있습니다. 다음은 그들의 핀올 설정의 스냅샷입니다:
쿼리 성능 및 사용자 경험 향상
아파치 핀올을 사용하면 Uber는 더 빠른 페이지 로딩과 향상된 신뢰성으로 더 나은 사용자 경험을 제공할 수 있습니다. 핀올로 마이그레이션하면 페이지 로드 시간을 64% 감소시켰습니다, 14초에서 5초 이하로. 핀올은 부하의 폭증에 더 잘 견딜 수 있어 더 빠른 지연 회복을 가능하게 합니다. 팀이 삽입 지연을 발견하더라도, 핀올은 몇 분 내에 빠르게 회복할 수 있습니다.
Elasticsearch에 비해 핀올은 쿼리 시간초과와 데이터 손실에 있어 显著한 향상을 보였습니다. 모바일 애플리케이션이 Elasticsearch를 사용하는 동안 재난이 발생하면, 해당 인덱스에 관련된 쿼리가 시간초과됩니다. Uber는 핀올을 사용하여 세그먼트 크기를 제어함으로써 이 문제를 해결했습니다. 팀은 또한 핀올을 사용할 때 Elasticsearch와 달리 삽입 처리량이 증가할 때 자주 발생하는 데이터 손실 문제를 겪지 않습니다.
Uber의 핀올 설정의 다음 이터레이션
다음으로, Uber는 모바일 충돌 데이터에 대한 기본 텍스트 인덱싱으로 마이그레이션을 계획하고 있습니다. 모바일 충돌 데이터는 많은 양의 구조화된 데이터를 포함하고 있어, 팀이 모든 사용 사례를 기본 텍스트 인덱스로 마이그레이션할 수 있게 되었습니다. 이러한 전환으로 인해 데이터 저장 비용을 절감하고 데이터 쿼리에 소요되는 시간을 줄일 수 있습니다.
Uber만이 Elasticsearch에서 Pinot으로 마이그레이션하여 성공을 거둔 조직이 아닙니다.
Uniqode(이전의 Beaconstac)는 Elasticsearch에서 Pinot으로 전환하면서 전반적인 쿼리 성능이 10배 개선되었습니다. Cisco Webex 또한 높은 대기 시간 문제를 겪고 나서 실시간 분석 및 관찰 가능성을 Pinot으로 마이그레이션하였습니다. Webex 팀은 Apache Pinot이 Elasticsearch보다 5배에서 150배까지 낮은 대기 시간을 제공한다는 것을 발견했습니다.
Source:
https://dzone.com/articles/real-time-app-crash-analytics-with-apache-pinot