













하이버네이트
하이버네이트 자체는 전문 검색 기능을 제공하지 않습니다. 데이터베이스 엔진 지원이나 타사 솔루션에 의존해야 합니다.
하이버네이트 검색이라는 확장 기능은 하이버네이트 검색이 아파치 루씨엔 또는 엘라스틱서치와 통합되어 있습니다(OpenSearch와의 통합도 있음).
포스트그레스
포스트그레스는 버전 7.3부터 전문 검색 기능을 갖추었습니다. 엘라스틱서치나 루씨엔과 같은 검색 엔진과 경쟁할 수는 없지만, 어휘 분석, 순위 매기기, 인덱싱과 같은 기능을 통해 애플리케이션 사용자의 요구를 충족시킬 수 있는 유연하고 강력한 솔루션을 제공합니다.
포스트그레스에서 전문 검색을 수행하는 방법에 대해 간단히 설명하겠습니다. 자세한 내용은 포스트그레스 문서를 참조하시기 바랍니다. 기본 텍스트 일치의 경우 가장 중요한 부분은 수학 연산자 @@입니다.
문서(유형 tsvector의 객체)가 쿼리(유형 tsquery의 객체)와 일치하면 true를 반환합니다.
연산자에 대한 순서는 중요하지 않습니다. 따라서 문서를 연산자의 왼쪽에 쿼리를 오른쪽에 두든 순서를 바꾸든 상관없습니다.
더 나은 설명을 위해, 우리는 tweet라는 데이터베이스 테이블을 사용합니다.
create table tweet (
id bigint not null,
short_content varchar(255),
title varchar(255),
primary key (id)
)이러한 데이터가 있습니다:
INSERT INTO tweet (id, title, short_content) VALUES (1, 'Cats', 'Cats rules the world');
INSERT INTO tweet (id, title, short_content) VALUES (2, 'Rats', 'Rats rules in the sewers');
INSERT INTO tweet (id, title, short_content) VALUES (3, 'Rats vs Cats', 'Rats and Cats hates each other');
INSERT INTO tweet (id, title, short_content) VALUES (4, 'Feature', 'This project is design to wrap already existed functions of Postgres');
INSERT INTO tweet (id, title, short_content) VALUES (5, 'Postgres database', 'Postgres is one of the widly used database on the market');
INSERT INTO tweet (id, title, short_content) VALUES (6, 'Database', 'On the market there is a lot of database that have similar features like Oracle');이제 각 레코드에 대한 short_content 열의 tsvector 객체가 어떻게 보이는지 살펴보겠습니다.
SELECT id, to_tsvector('english', short_content) FROM tweet;출력:
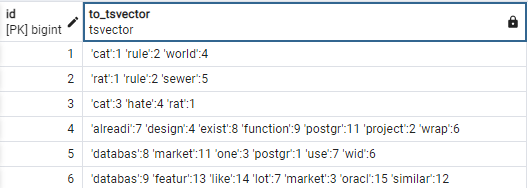
출력은 to_tsvcector가 텍스트 열을 ‘english‘ 텍스트 검색 구성에 대한 tsvector 객체로 변환하는 방법을 보여줍니다.
Text Search Configuration
위의 예에서 to_tsvector 함수에 전달된 첫 번째 매개변수는 텍스트 검색 구성의 이름이었습니다. 그 경우에는 “english“였습니다. Postgres 문서에 따르면 텍스트 검색 구성은 다음과 같습니다:
… 전체 텍스트 검색 기능에는 특정 단어(정지 단어)를 인덱싱하지 않고, 동의어를 처리하고, 공백 이상을 기준으로 하여 정교한 구문 분석을 사용할 수 있는 기능이 포함되어 있습니다. 이 기능은 text search configurations에 의해 제어됩니다.
따라서, 구성은 과정의 중요한 부분이며 전체 텍스트 검색 결과에 필수적입니다. 다양한 구성에 따라 Postgres 엔진은 다른 결과를 반환할 수 있습니다. 이는 다양한 언어의 사전 사이에서 반드시 그런 것은 아닙니다. 예를 들어, 같은 언어에 대해 두 가지 구성을 가질 수 있지만, 하나는 숫자를 포함하는 이름(예: 일부 시리얼 번호)을 무시합니다. 우리가 찾고자 하는 특정 시리얼 번호를 쿼리로 전달하는 경우, 이는 필수적이므로, 숫자가 포함된 단어를 무시하는 구성에서는 해당 기록을 찾을 수 없습니다. 데이터베이스에 그러한 기록이 있더라도, 자세한 내용은 구성 문서를 확인하십시오.
텍스트 쿼리
텍스트 쿼리는 & (AND), | (OR), ! (NOT), 그리고 <-> (FOLLOWED BY)와 같은 연산자를 지원합니다. 처음 세 연산자는 별도의 설명이 필요하지 않습니다. <-> 연산자는 단어가 존재하는지 여부와 특정 순서로 배치되어 있는지 확인합니다. 따라서 예를 들어, “rat <-> cat” 쿼리의 경우, “cat” 단어가 “rat” 다음에 존재할 것으로 예상됩니다.
예시
- 다음 내용에는 rat 과 cat:가 포함되어 있습니다.
SELECT t.id, t.short_content FROM tweet t WHERE to_tsvector('english', t.short_content) @@ to_tsquery('english', 'Rat & cat');
- 다음 내용에는 데이터베이스 와 시장, 그리고 시장이 “데이터베이스” 다음에 세 번째 단어로 존재합니다:
SELECT t.id, t.short_content FROM tweet t WHERE to_tsvector('english', t.short_content) @@ to_tsquery('english', 'database <3> market');
- 다음 내용에는 데이터베이스 가 포함되어 있지만 Postgres:는 포함되어 있지 않습니다.
SELECT t.id, t.short_content FROM tweet t WHERE to_tsvector('english', t.short_content) @@ to_tsquery('english', 'database & !Postgres');
- 내용에는 Postgres 또는 Oracle:
SELECT t.id, t.short_content FROM tweet t WHERE to_tsvector('english', t.short_content) @@ to_tsquery('english', 'Postgres | Oracle');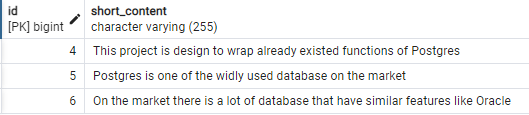
래퍼 함수
이 기사에서 이미 언급된 텍스트 쿼리를 생성하는 래퍼 함수 중 하나는 to_tsquery입니다. 이와 같은 다른 함수들도 있습니다:
plainto_tsqueryphraseto_tsquerywebsearch_to_tsquery
plainto_tsquery
plainto_tsquery는 전달된 모든 단어를 & (AND) 연산자로 결합된 쿼리로 변환합니다. 예를 들어, plainto_tsquery('english', 'Rat cat')의 동등한 것은 to_tsquery('english', 'Rat & cat')입니다.
다음과 같이 사용하면:
SELECT t.id, t.short_content FROM tweet t WHERE to_tsvector('english', t.short_content) @@ plainto_tsquery('english', 'Rat cat');아래와 같은 결과를 얻게 됩니다:

phraseto_tsquery
phraseto_tsquery는 전달된 모든 단어를 <-> (FOLLOW BY) 연산자로 결합된 쿼리로 변환합니다. 예를 들어, phraseto_tsquery('english', 'cat rule')의 동등한 것은 to_tsquery('english', 'cat <-> rule')입니다.
다음과 같이 사용하면:
SELECT t.id, t.short_content FROM tweet t WHERE to_tsvector('english', t.short_content) @@ phraseto_tsquery('english', 'cat rule');아래와 같은 결과를 얻게 됩니다:

websearch_to_tsquery
websearch_to_tsquery는 유효한 텍스트 쿼리를 생성하기 위해 대체 구문을 사용합니다.
- 미인용 텍스트:
plainto_tsquery와 같은 방식으로 구문의 일부를 변환합니다. - 인용된 텍스트:
phraseto_tsquery와 같은 방식으로 구문의 일부를 변환합니다. - OR: “
|” (OR) 연산자로 변환합니다. - “
-“: “!” (NOT) 연산자와 동일합니다.
예를 들어, websearch_to_tsquery('english', '"cat rule" or database -Postgres')의 동등한 것은 to_tsquery('english', 'cat <-> rule | database & !Postgres')입니다.
다음과 같은 사용법에 대해:
SELECT t.id, t.short_content FROM tweet t WHERE to_tsvector('english', t.short_content) @@ websearch_to_tsquery('english', '"cat rule" or database -Postgres');아래와 같은 결과를 얻게 됩니다:

Postgres와 Hibernate 네이티브 지원
문서에서 언급한 바와 같이, Hibernate만으로는 전체 텍스트 검색 지원이 완전하지 않습니다. 데이터베이스 엔진 지원에 의존해야 합니다. 즉, 아래 예제와 같이 네이티브 SQL 쿼리를 실행할 수 있다는 의미입니다.
plainto_tsquery
public List<Tweet> findBySinglePlainQueryInDescriptionForConfigurationWithNativeSQL(String textQuery, String configuration) {
return entityManager.createNativeQuery(String.format("select * from tweet t1_0 where to_tsvector('%1$s', t1_0.short_content) @@ plainto_tsquery('%1$s', :textQuery)", configuration), Tweet.class).setParameter("textQuery", textQuery).getResultList();
}websearch_to_tsquery
public List<Tweet> findCorrectTweetsByWebSearchToTSQueryInDescriptionWithNativeSQL(String textQuery, String configuration) {
return entityManager.createNativeQuery(String.format("select * from tweet t1_0 where to_tsvector('%1$s', t1_0.short_content) @@ websearch_to_tsquery('%1$s', :textQuery)", configuration), Tweet.class).setParameter("textQuery", textQuery).getResultList();
}posjsonhelper 라이브러리를 사용한 Hibernate
posjsonhelper 라이브러리는 PostgreSQL JSON 함수 및 전체 텍스트 검색을 위한 Hibernate 쿼리를 지원하는 오픈 소스 프로젝트입니다.
Maven 프로젝트에서는 다음 종속성을 추가해야 합니다:
<dependency>
<groupId>com.github.starnowski.posjsonhelper.text</groupId>
<artifactId>hibernate6-text</artifactId>
<version>0.3.0</version>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-core</artifactId>
<version>6.4.0.Final</version>
</dependency>
posjsonhelper 라이브러리 내의 구성 요소를 사용하려면 Hibernate 컨텍스트에 등록해야 합니다.
이는 특정 org.hibernate.boot.model.FunctionContributor 구현이 있어야 함을 의미합니다. 라이브러리는 이 인터페이스의 구현체인 com.github.starnowski.posjsonhelper.hibernate6.PosjsonhelperFunctionContributor를 제공합니다.
A file with the name “org.hibernate.boot.model.FunctionContributor” under the “resources/META-INF/services” directory is required to use this implementation.
또 다른 posjsonhelper 구성 요소를 등록하는 방법은 프로그래밍 가능한 방식으로 가능합니다. 그 방법을 알아보려면 이 링크를 확인하세요.
이제 Hibernate 쿼리에서 전체 텍스트 검색 연산자를 사용할 수 있습니다.
PlainToTSQueryFunction
이 구성 요소는 plainto_tsquery 함수를 감싸고 있습니다.
public List<Tweet> findBySinglePlainQueryInDescriptionForConfiguration(String textQuery, String configuration) {
CriteriaBuilder cb = entityManager.getCriteriaBuilder();
CriteriaQuery<Tweet> query = cb.createQuery(Tweet.class);
Root<Tweet> root = query.from(Tweet.class);
query.select(root);
query.where(new TextOperatorFunction((NodeBuilder) cb, new TSVectorFunction(root.get("shortContent"), configuration, (NodeBuilder) cb), new PlainToTSQueryFunction((NodeBuilder) cb, configuration, textQuery), hibernateContext));
return entityManager.createQuery(query).getResultList();
}
값이 'english'인 구성에서는 다음 문장을 생성합니다:
select
t1_0.id,
t1_0.short_content,
t1_0.title
from
tweet t1_0
where
to_tsvector('english', t1_0.short_content) @@ plainto_tsquery('english', ?);PhraseToTSQueryFunction
이 구성 요소는 phraseto_tsquery 함수를 감싸고 있습니다.
public List<Tweet> findBySinglePhraseInDescriptionForConfiguration(String textQuery, String configuration) {
CriteriaBuilder cb = entityManager.getCriteriaBuilder();
CriteriaQuery<Tweet> query = cb.createQuery(Tweet.class);
Root<Tweet> root = query.from(Tweet.class);
query.select(root);
query.where(new TextOperatorFunction((NodeBuilder) cb, new TSVectorFunction(root.get("shortContent"), configuration, (NodeBuilder) cb), new PhraseToTSQueryFunction((NodeBuilder) cb, configuration, textQuery), hibernateContext));
return entityManager.createQuery(query).getResultList();
}설정 값으로 'english'을 사용할 경우, 아래와 같은 문장을 생성할 것입니다:
select
t1_0.id,
t1_0.short_content,
t1_0.title
from
tweet t1_0
where
to_tsvector('english', t1_0.short_content) @@ phraseto_tsquery('english', ?)WebsearchToTSQueryFunction
이 구성 요소는 websearch_to_tsquery 함수를 감싸고 있습니다.
public List<Tweet> findCorrectTweetsByWebSearchToTSQueryInDescription(String phrase, String configuration) {
CriteriaBuilder cb = entityManager.getCriteriaBuilder();
CriteriaQuery<Tweet> query = cb.createQuery(Tweet.class);
Root<Tweet> root = query.from(Tweet.class);
query.select(root);
query.where(new TextOperatorFunction((NodeBuilder) cb, new TSVectorFunction(root.get("shortContent"), configuration, (NodeBuilder) cb), new WebsearchToTSQueryFunction((NodeBuilder) cb, configuration, phrase), hibernateContext));
return entityManager.createQuery(query).getResultList();
}설정 값으로 'english'을 사용할 경우, 아래와 같은 문장을 생성할 것입니다:
select
t1_0.id,
t1_0.short_content,
t1_0.title
from
tweet t1_0
where
to_tsvector('english', t1_0.short_content) @@ websearch_to_tsquery('english', ?)HQL 쿼리
언급된 모든 구성 요소는 HQL 쿼리에서 사용할 수 있습니다. 이를 어떻게 수행할 수 있는지 확인하려면 링크를 클릭하세요.
Hibernate로 기본 접근 방식을 사용할 수 있는데 왜 posjsonhelper 라이브러리를 사용해야 하나요?
동적으로 문자열을 연결하여 HQL 또는 SQL 쿼리로 사용하는 것은 쉬울 수 있지만, 예상되는 동작을 구현하는 것이 더 좋은 방법입니다. 특히 API에서 동적 속성을 기반으로 검색 기준을 처리해야 할 때 말이죠.
결론
이전 글에서 언급했듯이, Postgres의 전체 텍스트 검색 지원은 일부 경우 Elasticsearch나 Lucene과 같은 거대한 검색 엔진에 대한 좋은 대안이 될 수 있습니다. 이를 통해 기술 스택에 타사 솔루션을 추가하는 결정으로부터 벗어날 수 있으며, 이는 더 많은 복잡성과 추가 비용을 초래할 수 있습니다.
Source:
https://dzone.com/articles/postgres-full-text-search-with-hibernate-6