













데이터 생성의 기하급수적인 증가로 특징지어지는 시대에, 조직은 경쟁 우위를 유지하기 위해 이 풍부한 정보를 효과적으로 활용해야 합니다. 고객 데이터를 효율적으로 검색하고 분석하는 것 — 예를 들어 영화 추천을 위한 사용자 선호도 파악 또는 감정 분석 — 는 정보에 기반한 의사 결정을 촉진하고 사용자 경험을 향상시키는 데 중요한 역할을 합니다. 예를 들어, 스트리밍 서비스는 벡터 검색을 활용하여 개인의 시청 기록과 평가에 맞춘 영화를 추천할 수 있으며, 소매 브랜드는 고객의 감정을 분석하여 마케팅 전략을 조정할 수 있습니다.
데이터 엔지니어로서 우리는 이러한 정교한 솔루션을 구현하는 임무를 맡고 있으며, 조직이 방대한 데이터 세트에서 실행 가능한 통찰을 도출할 수 있도록 보장합니다. 이 기사는 Elasticsearch를 사용한 벡터 검색의 복잡성을 탐구하며 성능 최적화를 위한 효과적인 기법과 모범 사례에 중점을 둡니다. 개인화된 마케팅을 위한 이미지 검색과 고객 감정 클러스터링을 위한 텍스트 분석에 대한 사례 연구를 살펴보면서 벡터 검색 최적화가 고객 상호작용 개선과 상당한 비즈니스 성장으로 이어질 수 있는 방법을 보여줍니다.
벡터 검색이란 무엇인가요?
벡터 검색은 고차원 공간에서 데이터를 벡터로 표현하여 데이터 포인트 간의 유사성을 식별하는 강력한 방법입니다. 이 접근 방식은 속성을 기반으로 유사한 항목을 신속하게 검색해야 하는 애플리케이션에 특히 유용합니다.
벡터 검색의 설명
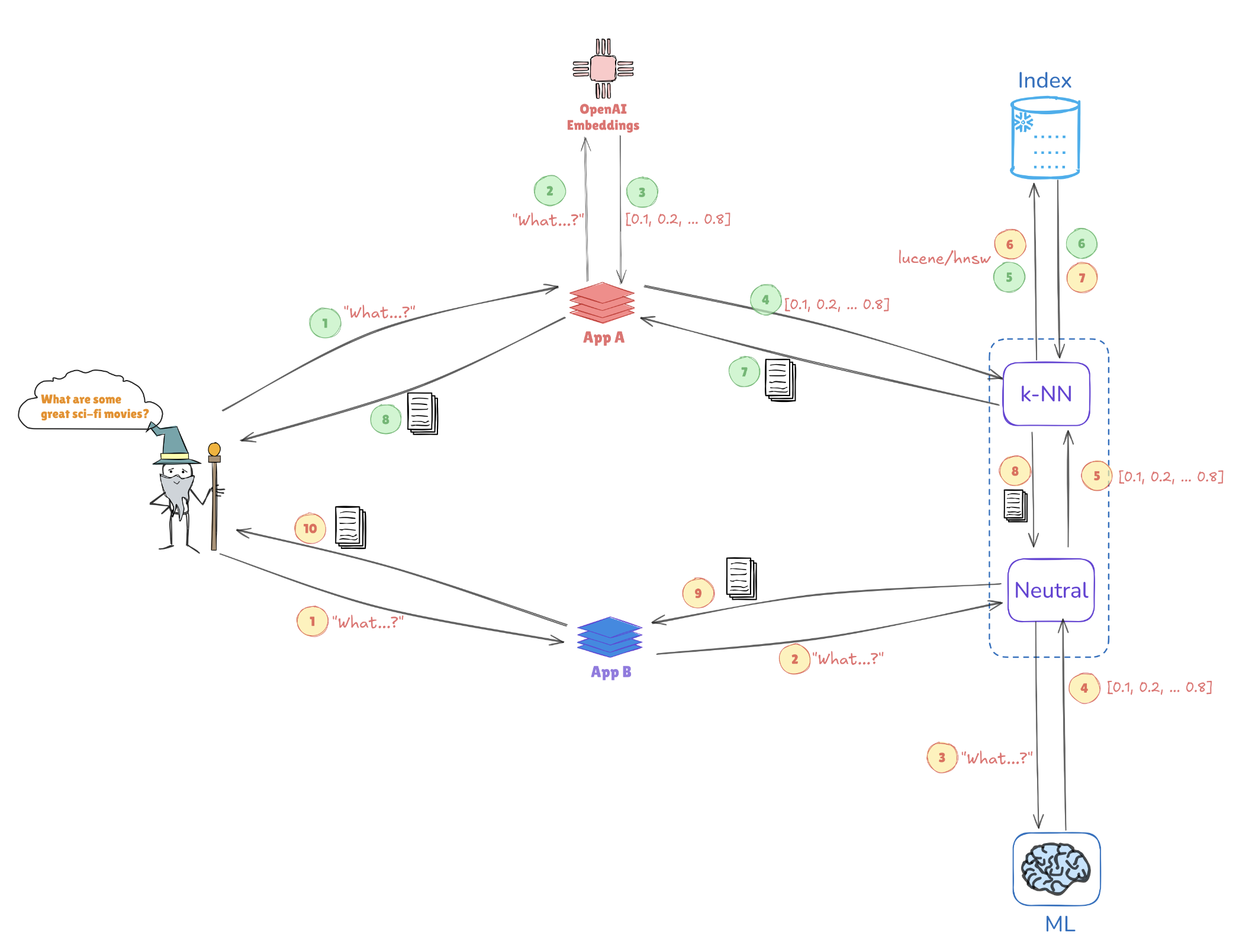
아래의 설명을 고려해 보십시오. 이는 벡터 표현이 유사성 검색을 어떻게 가능하게 하는지를 보여줍니다:
- 쿼리 임베딩: “훌륭한 SF 영화는 무엇인가요?”라는 쿼리는 [0.1, 0.2, …, 0.4]와 같은 벡터 표현으로 변환됩니다.
- 색인화: 이 벡터는 Elasticsearch에 저장된 사전 색인화된 벡터와 비교되어 유사한 쿼리나 데이터 포인트를 찾습니다 (예: AppA 및 AppB와 같은 애플리케이션에서).
- k-NN 검색: k-최근접 이웃(k-NN)과 같은 알고리즘을 사용하여 Elasticsearch는 색인화된 벡터에서 상위 일치를 효율적으로 검색하여 가장 관련성이 높은 정보를 신속하게 식별하는 데 도움을 줍니다.
이 메커니즘은 Elasticsearch가 추천 시스템, 이미지 검색 및 자연어 처리와 같은 사용 사례에서 뛰어난 성능을 발휘할 수 있게 해주며, 이 경우 맥락과 유사성을 이해하는 것이 핵심입니다.
Elasticsearch를 통한 벡터 검색의 주요 이점
고차원 지원
Elasticsearch는 AI 및 기계 학습 애플리케이션에 필수적인 복잡한 데이터 구조 관리에 탁월합니다. 이러한 기능은 이미지나 텍스트 데이터와 같은 다면적인 데이터 유형을 처리할 때 중요합니다.
확장성
이 아키텍처는 수평 확장을 지원하여 조직이 성능을 희생하지 않고도 지속적으로 증가하는 데이터 세트를 처리할 수 있게 합니다. 데이터 양이 계속 증가함에 따라 이는 매우 중요합니다.
통합
Elasticsearch는 Elastic 스택과 원활하게 작동하여 데이터 수집, 분석 및 시각화를 위한 포괄적인 솔루션을 제공합니다. 이 통합은 데이터 엔지니어가 다양한 데이터 처리 작업을 위해 통합 플랫폼을 활용할 수 있도록 보장합니다.
벡터 검색 성능 최적화를 위한 모범 사례
1. 벡터 차원 감소
벡터의 차원을 줄이면 검색 성능을 크게 향상시킬 수 있습니다. PCA(주성분 분석) 또는 UMAP(균일 다양체 근사 및 투영)와 같은 기술은 데이터 구조를 단순화하면서 필수 기능을 유지하는 데 도움이 됩니다.
예: PCA를 통한 차원 축소
Scikit-learn을 사용하여 Python에서 PCA를 구현하는 방법은 다음과 같습니다:
from sklearn.decomposition import PCA
import numpy as np
# Sample high-dimensional data
data = np.random.rand(1000, 50) # 1000 samples, 50 features
# Apply PCA to reduce to 10 dimensions
pca = PCA(n_components=10)
reduced_data = pca.fit_transform(data)
print(reduced_data.shape) # Output: (1000, 10)
2. 효율적으로 인덱싱하기
근사 최근접 이웃(ANN) 알고리즘을 활용하면 검색 시간을 크게 단축할 수 있습니다. 다음과 같은 방법을 고려해 보세요:
- HNSW (Hierarchical Navigable Small World): 성능과 정확성의 균형으로 알려져 있습니다.
- FAISS (Facebook AI Similarity Search): 대규모 데이터셋에 최적화되어 GPU 가속을 활용할 수 있습니다.
예: Elasticsearch에 HNSW 구현하기
다음과 같이 Elasticsearch에서 인덱스 설정을 정의하여 HNSW를 활용할 수 있습니다:
PUT /my_vector_index
{
"settings": {
"index": {
"knn": true,
"knn.space_type": "l2",
"knn.algo": "hnsw"
}
},
"mappings": {
"properties": {
"my_vector": {
"type": "knn_vector",
"dimension": 10 // Adjust based on your data
}
}
}
}
3. 일괄 쿼리
효율성을 높이기 위해 여러 쿼리를 단일 요청에서 일괄 처리하면 오버헤드를 최소화할 수 있습니다. 이는 특히 높은 사용자 트래픽을 갖는 애플리케이션에 유용합니다.
예: Elasticsearch에서 일괄 처리
일괄 쿼리에는 _msearch 엔드포인트를 사용할 수 있습니다:
POST /_msearch
{ "index": "my_vector_index" }
{ "query": { "match_all": {} } }
{ "index": "my_vector_index" }
{ "query": { "match": { "category": "sci-fi" } } }
4. 캐싱 사용
자주 액세스되는 쿼리에 대해 캐싱 전략을 구현하여 계산 부하를 줄이고 응답 시간을 개선할 수 있습니다.
5. 성능 모니터링
정기적으로 성능 메트릭을 분석하는 것은 병목 현상을 식별하는 데 중요합니다. Kibana와 같은 도구를 사용하여 데이터를 시각화하여 Elasticsearch 구성에 대한 정보를 통찰력 있게 조정할 수 있습니다.
향상된 성능을 위한 HNSW 매개변수 조정
HNSW 최적화에는 대규모 데이터셋에서 더 나은 성능을 달성하기 위해 특정 매개변수를 조정하는 것이 포함됩니다:
M(최대 연결 수): 이 값을 높이면 검색률이 향상되지만 더 많은 메모리가 필요할 수 있습니다.EfConstruction(구성 중 동적 목록 크기): 높은 값은 더 정확한 그래프를 만들지만 색인 시간을 증가시킬 수 있습니다.EfSearch(검색 중 동적 목록 크기): 이를 조정하면 속도-정확도 교환 관계에 영향을 미칩니다. 더 큰 값은 더 나은 회수를 제공하지만 계산하는 데 더 오랜 시간이 걸립니다.
예: HNSW 매개변수 조정
다음과 같이 HNSW 매개변수를 색인 생성 중에 조정할 수 있습니다:
PUT /my_vector_index
{
"settings": {
"index": {
"knn": true,
"knn.algo": "hnsw",
"knn.hnsw.m": 16, // More connections
"knn.hnsw.ef_construction": 200, // Higher accuracy
"knn.hnsw.ef_search": 100 // Adjust for search accuracy
}
},
"mappings": {
"properties": {
"my_vector": {
"type": "knn_vector",
"dimension": 10
}
}
}
}
사례 연구: 고객 데이터 응용 프로그램에서 차원 축소가 HNSW 성능에 미치는 영향
맞춤 마케팅을 위한 이미지 검색
차원 축소 기술은 고객 데이터 응용 프로그램 내에서 이미지 검색 시스템을 최적화하는 데 중요한 역할을 합니다. 한 연구에서 연구자들은 고객 데이터 응용 프로그램 내에서 이미지를 HNSW 네트워크로 인덱싱하기 전에 주성분 분석(PCA)을 적용했습니다. PCA는 검색 속도를 현저히 향상시켰으며, 많은 양의 고객 데이터를 처리하는 응용 프로그램에서 필수적인 속도 향상을 제공했습니다. 그러나 이는 정보 축소로 인한 미세한 정확도 손실을 야기했습니다. 이를 해결하기 위해 연구자들은 대안으로 Uniform Manifold Approximation and Projection (UMAP)도 조사했습니다. UMAP은 지역 데이터 구조를 더 효과적으로 보존하여 맞춤형 마케팅 추천에 필요한 복잡한 세부 정보를 유지했습니다. PCA보다 더 많은 계산 능력이 필요했지만, UMAP은 높은 정확도를 유지하면서 검색 속도를 균형있게 유지하여 정확도가 중요한 작업에 적합한 선택지가 되었습니다.
고객 감성 클러스터링을 위한 텍스트 분석
고객 감정 분석 분야에서, 다른 연구에서는 UMAP이 PCA보다 유사한 텍스트 데이터를 클러스터링하는 데 더 우수하다는 결과를 발견했습니다. UMAP은 HNSW 모델이 고객 감정을 더 높은 정확도로 클러스터링할 수 있게 하여, 고객 피드백을 이해하고 보다 개인화된 응답을 제공하는 데 이점이 되었습니다. UMAP의 사용은 HNSW에서 더 작은 EfSearch 값들을 가능하게 하여, 검색 속도와 정밀도를 향상시켰습니다. 이 개선된 클러스터링 효율성은 관련 고객 감정을 더 빠르게 식별할 수 있게 하여, 타겟 마케팅 노력과 감정 기반 고객 세분화를 강화했습니다.
자동화 최적화 기술 통합
차원 축소 및 HNSW 매개변수 최적화는 고객 데이터 시스템의 성능을 극대화하는 데 필수적입니다. 자동화 최적화 기술은 이 조정 프로세스를 간소화하여, 선택된 구성 요소가 다양한 애플리케이션에서 효과적임을 보장합니다:
- 그리드 및 랜덤 검색: 이러한 방법들은 폭넓고 체계적인 매개변수 탐색을 제공하여, 적합한 구성을 효율적으로 식별합니다.
- 베이지안 최적화: 이 기술은 평가를 줄이면서 최적의 매개변수에 접근하여, 계산 자원을 절약합니다.
- 교차 검증: 교차 검증은 다양한 데이터 세트에서 매개변수를 검증하는 데 도움을 주어, 서로 다른 고객 데이터 맥락에 대한 일반화를 보장합니다.
자동화에서의 도전 과제 해결
차원 축소 및 HNSW 워크플로에 자동화를 통합하면, 계산 요구 사항을 관리하고 오버피팅을 피하는 데 어려움이 생길 수 있습니다. 이러한 어려움을 극복하기 위한 전략은 다음과 같습니다:
- 계산 오버헤드 감소: 병렬 처리를 사용하여 작업 부하를 분산시켜 최적화 시간을 줄이고 워크플로 효율성을 향상시킵니다.
- 모듈식 통합: 모듈식 접근 방식은 기존 워크플로에 자동화 시스템을 원활하게 통합하여 복잡성을 줄입니다.
- 오버피팅 방지: 교차 검증을 통한 견고한 검증은 최적화된 매개변수가 데이터 집합 간에 일관되게 작동하여 오버피팅을 최소화하고 고객 데이터 응용 프로그램의 확장성을 향상시킵니다.
결론
Elasticsearch에서 벡터 검색 성능을 최대로 활용하려면, 차원 축소, 효율적인 인덱싱 및 신중한 매개변수 튜닝을 결합하는 전략 채택이 필수적입니다. 이러한 기술을 통합함으로써 데이터 엔지니어는 빠르고 정확한 데이터 검색 시스템을 만들 수 있습니다. 자동화된 최적화 방법은 검색 매개변수와 인덱싱 전략을 지속적으로 개선할 수 있도록 지원하여 이 프로세스를 더욱 개선합니다. 기관이 대용량 데이터 세트에서 실시간 통찰력에 점점 의존함에 따라 이러한 최적화는 의사 결정 능력을 크게 향상시키며 더 빠르고 관련성 높은 검색 결과를 제공합니다. 이러한 접근 방식을 채택하면 미래 확장성과 개선된 응답성을 위한 기반을 마련하여 검색 능력을 진화하는 비즈니스 요구 사항과 데이터 성장에 부합시킵니다.
Source:
https://dzone.com/articles/optimizing-vector-search-performance-with-elasticsearch