













가정해보겠습니다. Node.js(또는 다른 플랫폼)으로 개발된 애플리케이션이 있습니다. 이 애플리케이션은 MongoDB 데이터베이스(NoSQL)에 연결하여 책에 대한 평가(주어진 별 수와 코멘트)를 저장합니다. 또한 Java(또는 Python, C#, TypeScript… 어떤 것이든)로 개발된 다른 애플리케이션이 있습니다. 이 애플리케이션은 MariaDB 데이터베이스(SQL, 관계형)에 연결하여 책 카탈로그를 관리합니다(제목, 출판년도, 페이지 수).
각 책의 제목과 평점 정보를 표시하는 보고서를 작성하도록 요청받았습니다. MongoDB 데이터베이스에는 책의 제목이 포함되어 있지 않으며, 관계형 데이터베이스에는 평가가 포함되어 있지 않다는 점에 유의하세요. NoSQL 애플리케이션에 의해 생성된 데이터를 SQL 애플리케이션에 의해 생성된 데이터와 결합해야 합니다.
A common approach to this is to query both databases independently (using different data sources) and process the data to match by, for example, ISBN (the id of a book) and put the combined information in a new object. This needs to be done in a programming language like Java, TypeScript, C#, Python, or any other imperative programming language that is able to connect to both databases.
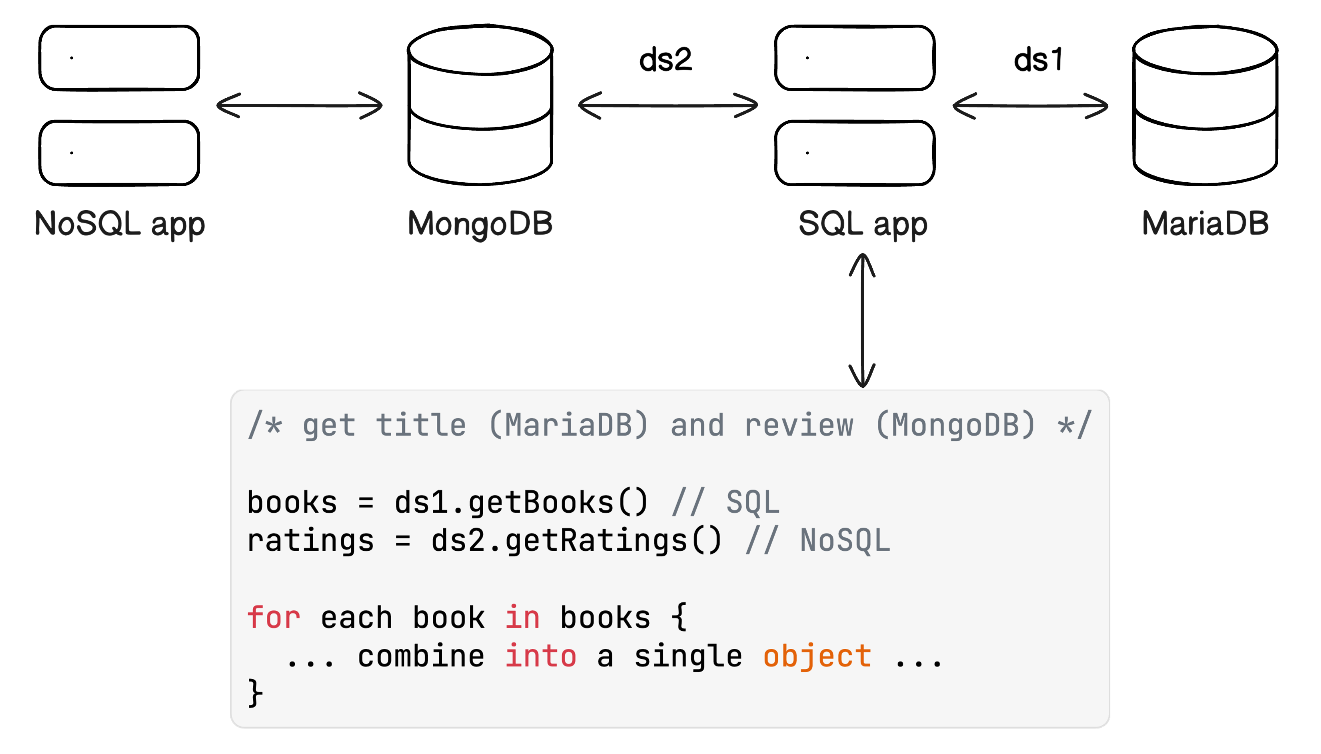
A polyglot application
이러한 접근 방식은 작동하지만, 조인 작업은 데이터베이스의 일입니다. 이러한 유형의 데이터 작업을 위해 설계되었습니다. 또한 이 접근 방식으로 인해 SQL 애플리케이션은 더 이상 SQL만을 사용하는 애플리케이션이 아니며, 데이터베이스 폴리글롯이 되어 유지 보수가 더 어려워집니다.
데이터베이스 프록시인 MaxScale와 같은 도구를 사용하면 SQL이 데이터를 다루는 가장 적합한 언어인 상황에서 데이터베이스 수준에서 이 데이터를 조인할 수 있습니다. SQL 애플리케이션은 폴리글롯이 될 필요가 없습니다.
이렇게 하면 인프라에 추가적인 요소가 필요하지만, 데이터베이스 프록시가 제공하는 모든 기능을 얻게 됩니다. 예를 들어 자동 장애 조치(failover), 투명한 데이터 마스킹, 토폴로지 격리, 캐시, 보안 필터 등이 있습니다.
MaxScale은 SQL과 NoSQL을 모두 이해하는 강력하고 지능적인 데이터베이스 프록시입니다. 또한 Kafka를 이해합니다(CDC나 데이터 수집을 위해), 하지만 이는 다른 때의 주제입니다. 간단히 말해서, MaxScale을 사용하면 NoSQL 애플리케이션을 완전히 ACID 호환 가능한 관계형 데이터베이스에 연결하여 다른 SQL 애플리케이션이 사용하는 테이블 옆에 데이터를 저장할 수 있습니다.
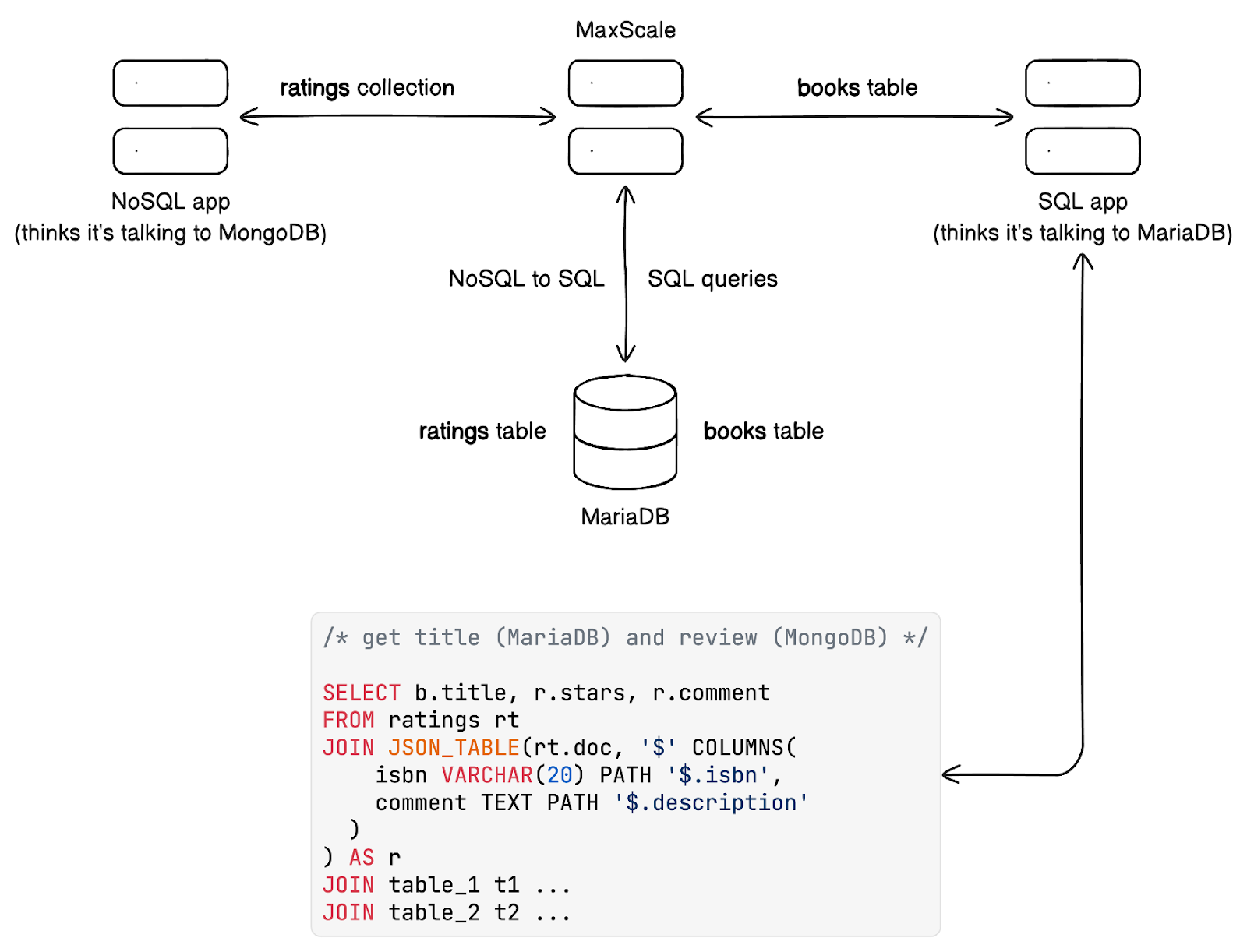
MaxScale을 통해 SQL 애플리케이션이 NoSQL 데이터를 소비할 수 있습니다.
이 마지막 접근 방식을 MaxScale을 사용하여 빠르고 간단한 실험으로 시도해 보겠습니다. 컴퓨터에 다음을 설치해야 합니다:
MariaDB 데이터베이스 설정
일반 텍스트 편집기를 사용하여 새 파일을 만들고 docker-compose.yml이라는 이름으로 저장합니다. 파일에는 다음이 포함되어야 합니다:
version: "3.9"
services:
mariadb:
image: alejandrodu/mariadb
environment:
- MARIADB_CREATE_DATABASE=demo
- MARIADB_CREATE_USER=user:Password123!
- MARIADB_CREATE_MAXSCALE_USER=maxscale_user:MaxScalePassword123!
maxscale:
image: alejandrodu/mariadb-maxscale
command: --admin_host 0.0.0.0 --admin_secure_gui false
ports:
- "3306:4000"
- "27017:27017"
- "8989:8989"
environment:
- MAXSCALE_USER=maxscale_user:MaxScalePassword123!
- MARIADB_HOST_1=mariadb 3306
- MAXSCALE_CREATE_NOSQL_LISTENER=user:Password123!이것은 Docker Compose 파일입니다. 이 파일은 Docker에 의해 생성될 서비스 세트를 설명합니다. 우리는 MariaDB 데이터베이스 서버와 MaxScale 데이터베이스 프록시라는 두 가지 서비스(또는 컨테이너)를 생성하고 있습니다. 이들은 로컬 컴퓨터에서 실행되지만 프로덕션 환경에서는 일반적으로 별도의 물리적 시스템에 배포됩니다. 이러한 Docker 이미지는 프로덕션에 적합하지 않습니다! 이들은 빠른 데모 및 테스트용으로 적합하도록 고안되었습니다. 이러한 이미지의 소스 코드는 GitHub에서 찾을 수 있습니다. MariaDB의 공식 Docker 이미지에 대해서는 Docker Hub의 MariaDB 페이지를 방문하세요.
이전 Docker Compose 파일은 demo라는 데이터베이스(또는 스키마; MariaDB에서 동의어)를 가진 MariaDB 데이터베이스 서버를 구성합니다. 또한 user라는 사용자 이름과 Password123!라는 비밀번호를 생성합니다. 이 사용자는 demo 데이터베이스에 적합한 권한을 가지고 있습니다. maxscale_user라는 이름과 MaxScalePassword123!라는 비밀번호를 가진 추가 사용자가 있습니다. 이것은 MaxScale 데이터베이스 프록시가 MariaDB 데이터베이스에 연결하는 데 사용할 사용자입니다.
Docker Compose 파일은 또한 HTTPS를 비활성화하여(프로덕션에서는 이렇게 하지 마세요!) 데이터베이스 프록시를 구성합니다. 이 파일은 일련의 포트를 노출시키고(잠시 후에 자세히 설명하겠습니다), 데이터베이스 사용자와 MariaDB 데이터베이스 프록시의 위치(일반적으로 IP 주소이지만, 여기서는 Docker 파일에서 이전에 정의한 컨테이너 이름을 사용할 수 있습니다)를 구성합니다. 마지막 줄에서는 기본 포트(27017)에서 MongoDB 클라이언트로 연결하는 데 사용할 NoSQL 리스너를 생성합니다.
명령 줄을 사용하여 서비스(컨테이너)를 시작하려면 Docker Compose 파일이 저장된 디렉토리로 이동하여 다음을 실행하세요:
docker compose up -d모든 소프트웨어를 다운로드하고 컨테이너를 시작한 후에는 이 실험을 위해 미리 구성된 MariaDB 데이터베이스와 MaxScale 프록시가 모두 있습니다.
MariaDB에서 SQL 테이블 생성
관계형 데이터베이스에 연결합시다. 명령 줄에서 다음을 실행하세요:
mariadb-shell --dsn mariadb://user:'Password123!'@127.0.0.1데이터베이스를 확인해보세요.demo:
show databases;demo 데이터베이스로 전환:
use demo;
MariaDB Shell을 사용하여 데이터베이스에 연결합니다.
books 테이블 생성:
CREATE TABLE books(
isbn VARCHAR(20) PRIMARY KEY,
title VARCHAR(256),
year INT
);일부 데이터를 삽입합니다. 저의 책을 삽입하는 것이 고전적인 방법입니다:
INSERT INTO books(title, isbn, year)
VALUES
("Vaadin 7 UI Design By Example", "978-1-78216-226-1", 2013),
("Data-Centric Applications with Vaadin 8", "978-1-78328-884-7", 2018),
("Practical Vaadin", "978-1-4842-7178-0", 2021);데이터베이스에서 책이 저장되었는지 확인하려면 다음을 실행하세요:
SELECT * FROM books;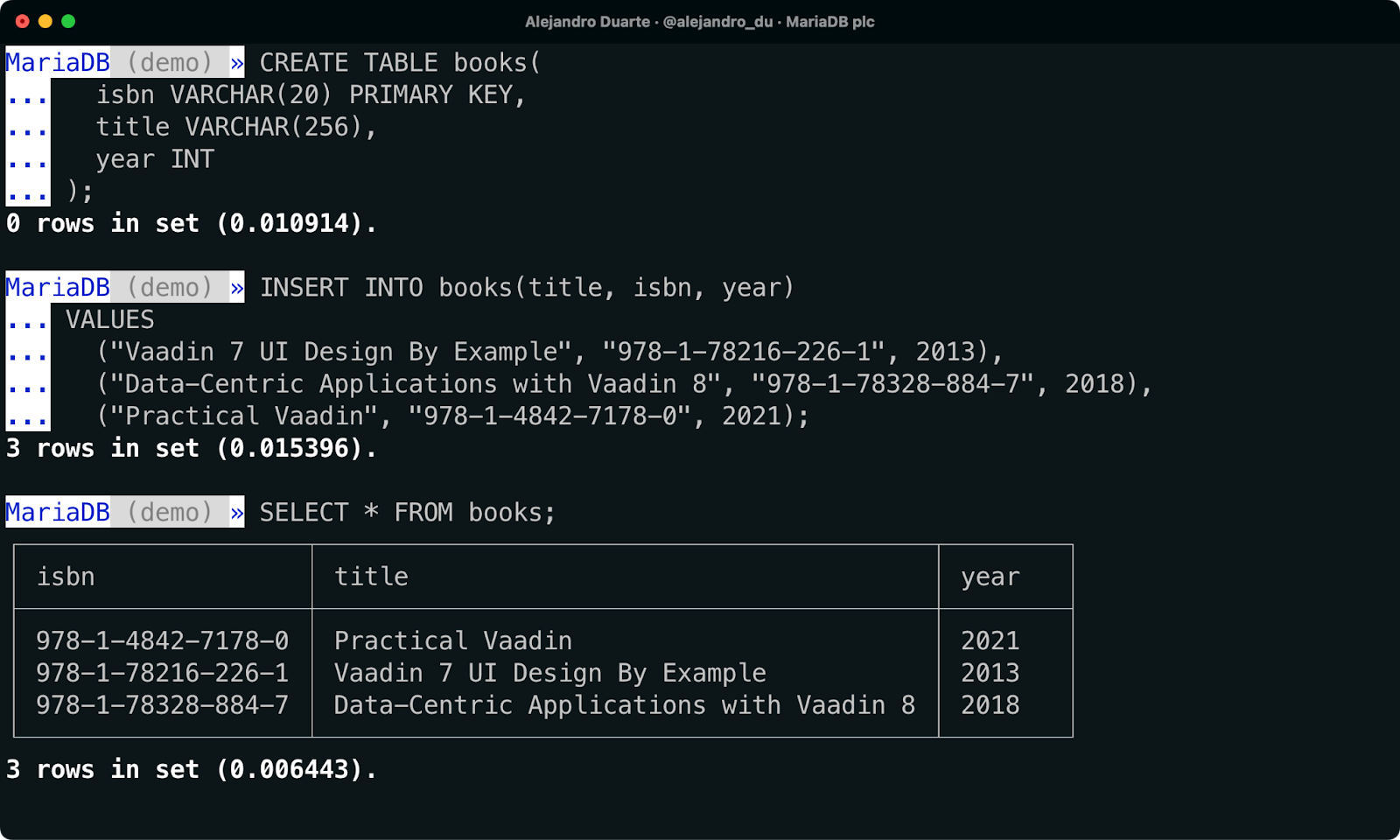
MariaDB Shell을 사용하여 데이터 삽입.
MariaDB에서 JSON 컬렉션 생성
MongoDB를 아직 설치하지 않았지만 MongoDB 클라이언트(또는 애플리케이션)를 사용하여 컬렉션과 문서를 생성할 수 있습니다. 이를 통해 데이터는 강력하고, 완전히 ACID 규격을 준수하며, 확장 가능한 관계형 데이터베이스에 저장됩니다. 한 번 해보죠!
명령 줄에서 MongoDB 쉘 도구를 사용하여 MongoDB 서버에 연결합니다… 잠시만요… 이번에는 MariaDB 데이터베이스입니다! 다음을 실행하세요:
mongosh기본적으로 이 도구는 로컬 컴퓨터(127.0.0.1)에서 실행되는 MongoDB 서버(이번에는 MariaDB)에 기본 포트(20017)를 사용하여 연결을 시도합니다. 모든 것이 잘 진행된다면, 다음 명령을 실행할 때 demo 데이터베이스가 나열되어야 합니다:
show databasesdemo 데이터베이스로 전환:
use demo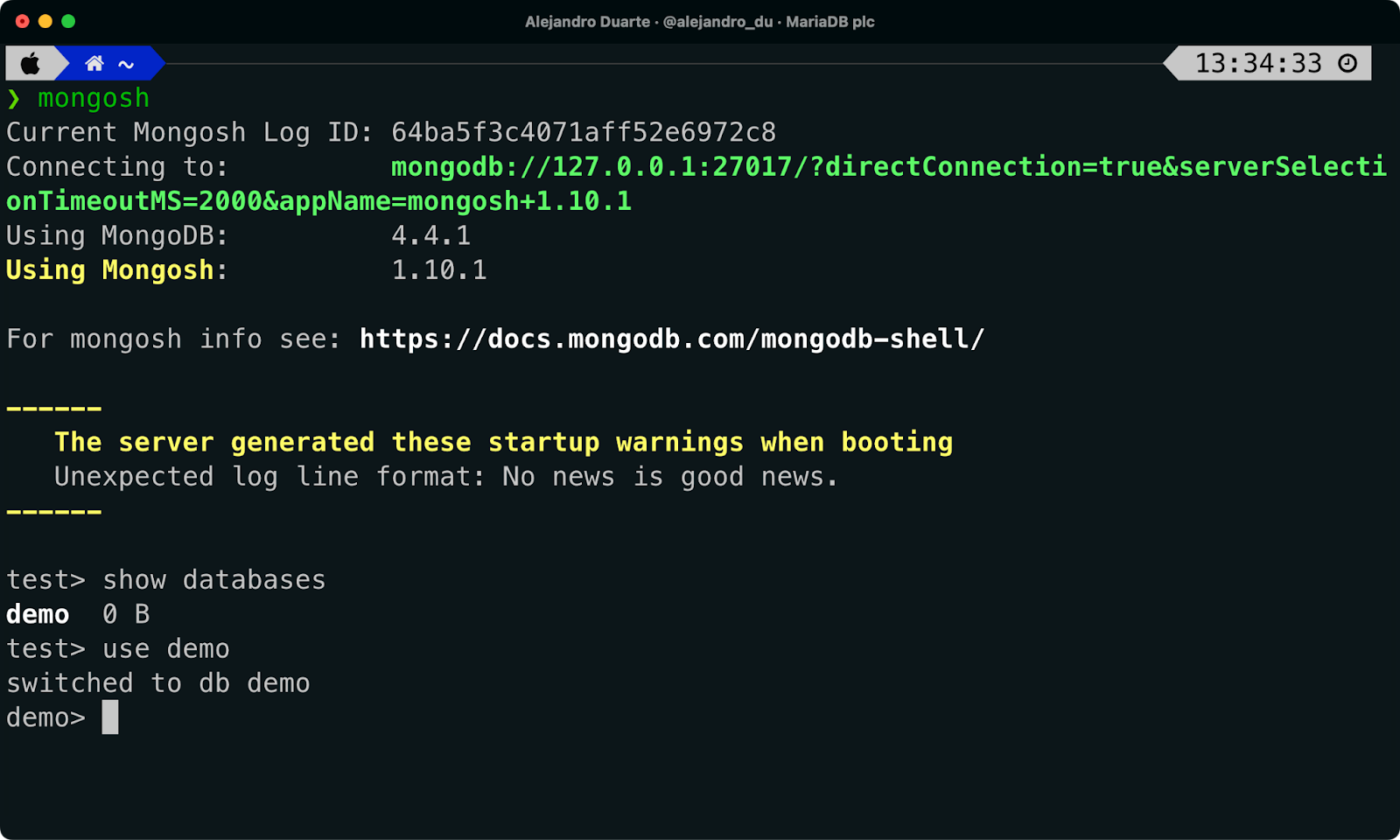
Mongo Shell을 사용하여 MariaDB에 연결.
비관계형 클라이언트에서 관계형 데이터베이스에 연결되었습니다! ratings 컬렉션을 생성하고 일부 데이터를 삽입합시다:
db.ratings.insertMany([
{
"isbn": "978-1-78216-226-1",
"starts": 5,
"comment": "A good resource for beginners who want to learn Vaadin"
},
{
"isbn": "978-1-78328-884-7",
"starts": 4,
"comment": "Explains Vaadin in the context of other Java technologies"
},
{
"isbn": "978-1-4842-7178-0",
"starts": 5,
"comment": "The best resource to learn web development with Java and Vaadin"
}
])데이터베이스에 평가가 유지되었는지 확인하십시오:
db.ratings.find()
Mongo Shell을 사용하여 MariaDB 데이터베이스 쿼리.
MariaDB에서 JSON 함수 사용
이 시점에서 우리는 외부에서 볼 때 NoSQL(MongoDB) 데이터베이스와 관계형(MariaDB) 데이터베이스처럼 보이는 단일 데이터베이스를 가지고 있습니다. 우리는 동일한 데이터베이스에 연결하고 MongoDB 클라이언트와 SQL 클라이언트에서 데이터를 쓰고 읽을 수 있습니다. 모든 데이터는 MariaDB에 저장되어 있으므로 MongoDB 클라이언트 또는 애플리케이션의 데이터와 MariaDB 클라이언트 또는 애플리케이션의 데이터를 조인하기 위해 SQL을 사용할 수 있습니다. MaxScale가 MariaDB에 MongoDB 데이터(컬렉션 및 문서)를 저장하는 방법을 살펴보겠습니다.
mariadb-shell과 같은 SQL 클라이언트를 사용하여 데이터베이스에 연결하고 데모 스키마의 테이블을 표시하십시오:
show tables in demo;books 및 ratings 테이블이 나열되어야 합니다. ratings는 MongoDB 컬렉션으로 생성되었습니다. MaxScale는 MongoDB 클라이언트에서 전송된 명령을 번역하고 테이블에 데이터를 저장하기 위해 테이블을 생성했습니다. 이 테이블의 구조를 살펴보겠습니다:
describe demo.ratings;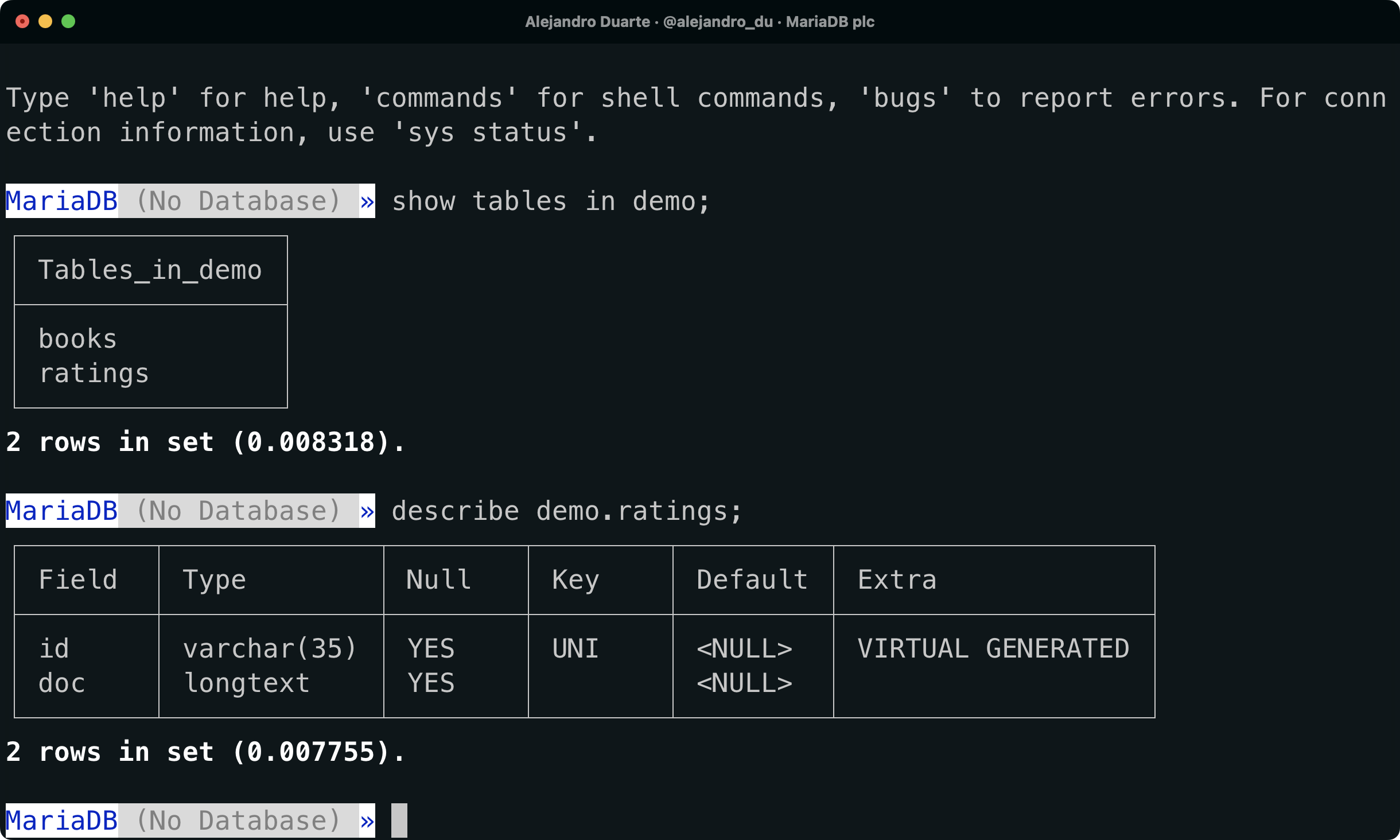
A NoSQL collection is stored as a MariaDB relational table.
ratings 테이블에는 두 개의 열이 포함되어 있습니다:
id: 개체 ID.doc: JSON 형식의 문서.
테이블의 내용을 살펴보면, 평점에 대한 모든 데이터가 JSON 형식으로 doc 컬럼에 저장되어 있음을 알 수 있습니다:
SELECT doc FROM demo.ratings \G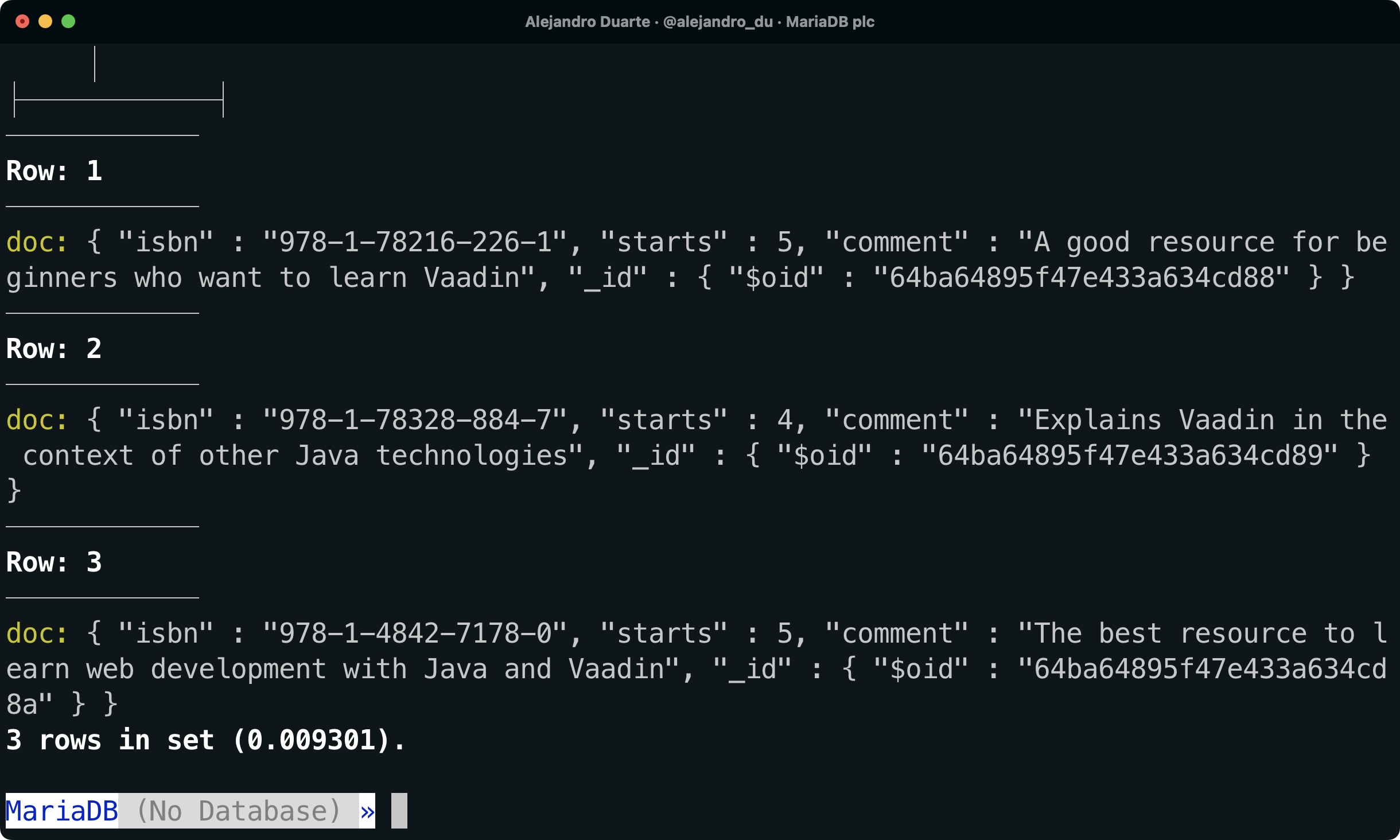
NoSQL 문서는 MariaDB 데이터베이스에 저장됩니다.
원래의 목표로 돌아가서—평점 정보와 함께 책 제목을 보여주기 위해 작업해 보겠습니다. 다음은 그렇지 않지만, 잠시 ratings 테이블이 stars와 comment 컬럼을 가진 일반 테이블이라고 가정해 보겠습니다. 그런 경우라면, 이 테이블을 books 테이블과 쉽게 조인할 수 있고, 우리의 작업은 끝났을 것입니다:
/* this doesn’t work */
SELECT b.title, r.stars, r.comment
FROM ratings r
JOIN books b USING(isbn)현실로 돌아가서. ratings 테이블의 doc 컬럼을 쿼리에서 사용할 수 있는 관계형 표현식으로 변환해야 합니다. 이와 비슷한 것이 필요합니다:
/* this still doesn’t work */
SELECT b.title, r.stars, r.comment
FROM ratings rt
JOIN ...something to convert rt.doc to a table... AS r
JOIN books b USING(isbn)그 무언가는 JSON_TABLE 함수입니다. MariaDB는 JSON 문자열을 조작하기 위한 포괄적인 JSON 함수 세트를 포함하고 있습니다. JSON_TABLE 함수를 사용하여 doc 컬럼을 관계형 형태로 변환하여 SQL 조인을 수행할 수 있습니다. JSON_TABLE 함수의 일반적인 구문은 다음과 같습니다:
JSON_TABLE(json_document, context_path COLUMNS (
column_definition_1,
column_definition_2,
...
)
) [AS] the_new_relational_table여기서:
json_document: 사용할 JSON 문서를 반환하는 문자열 또는 표현식입니다.context_path: a JSON Path 식으로, 행의 소스로 사용될 노드를 정의합니다.
그리고 컬럼 정의들(column_definition_1, column_definition_2 등…)은 다음과 같은 구문을 가지고 있습니다:
new_column_name sql_type PATH path_in_the_json_doc [on_empty] [on_error]이 지식을 결합하여, 우리의 SQL 쿼리는 다음과 같아집니다:
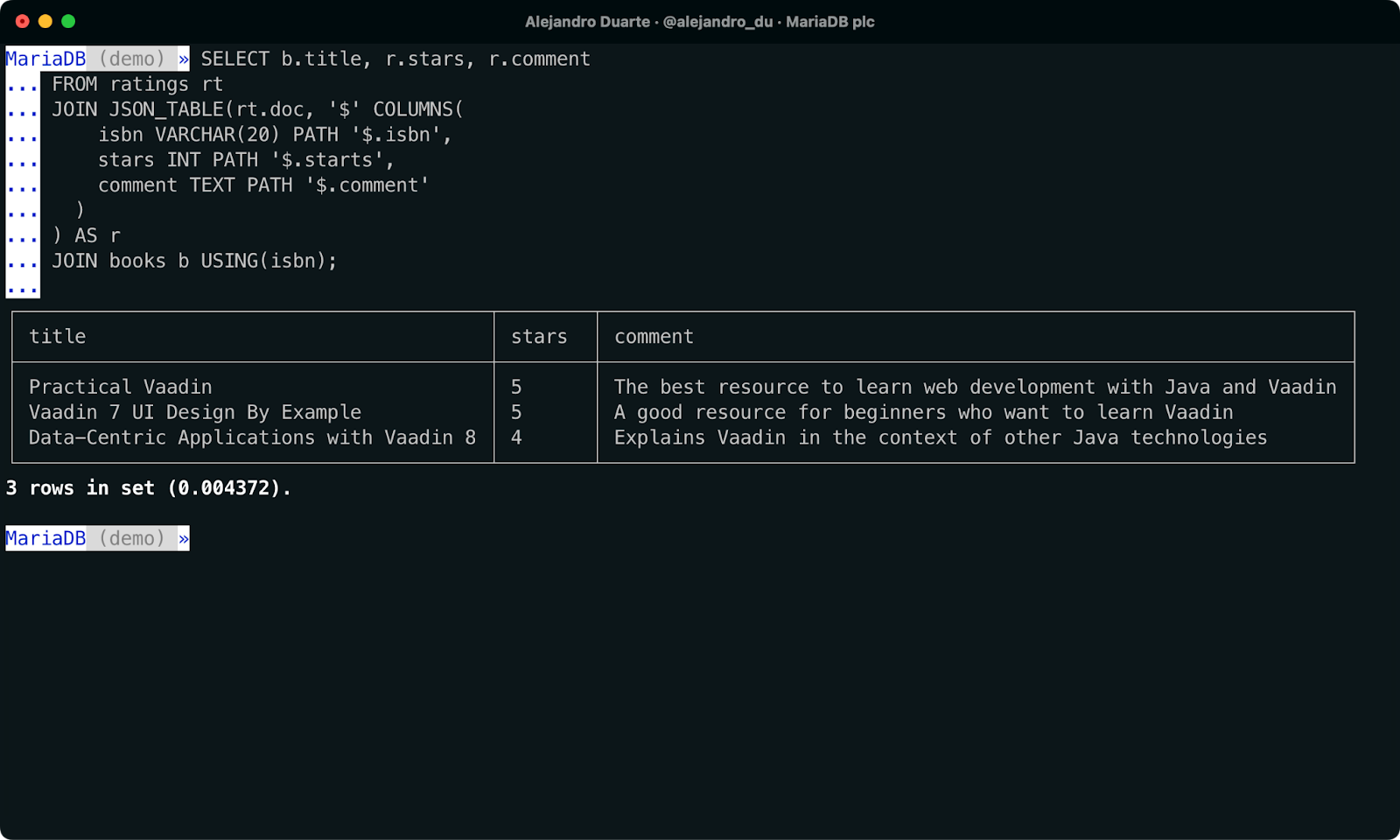
SELECT b.title, r.stars, r.comment
FROM ratings rt
JOIN JSON_TABLE(rt.doc, '$' COLUMNS(
isbn VARCHAR(20) PATH '$.isbn',
stars INT PATH '$.starts',
comment TEXT PATH '$.comment'
)
) AS r
JOIN books b USING(isbn);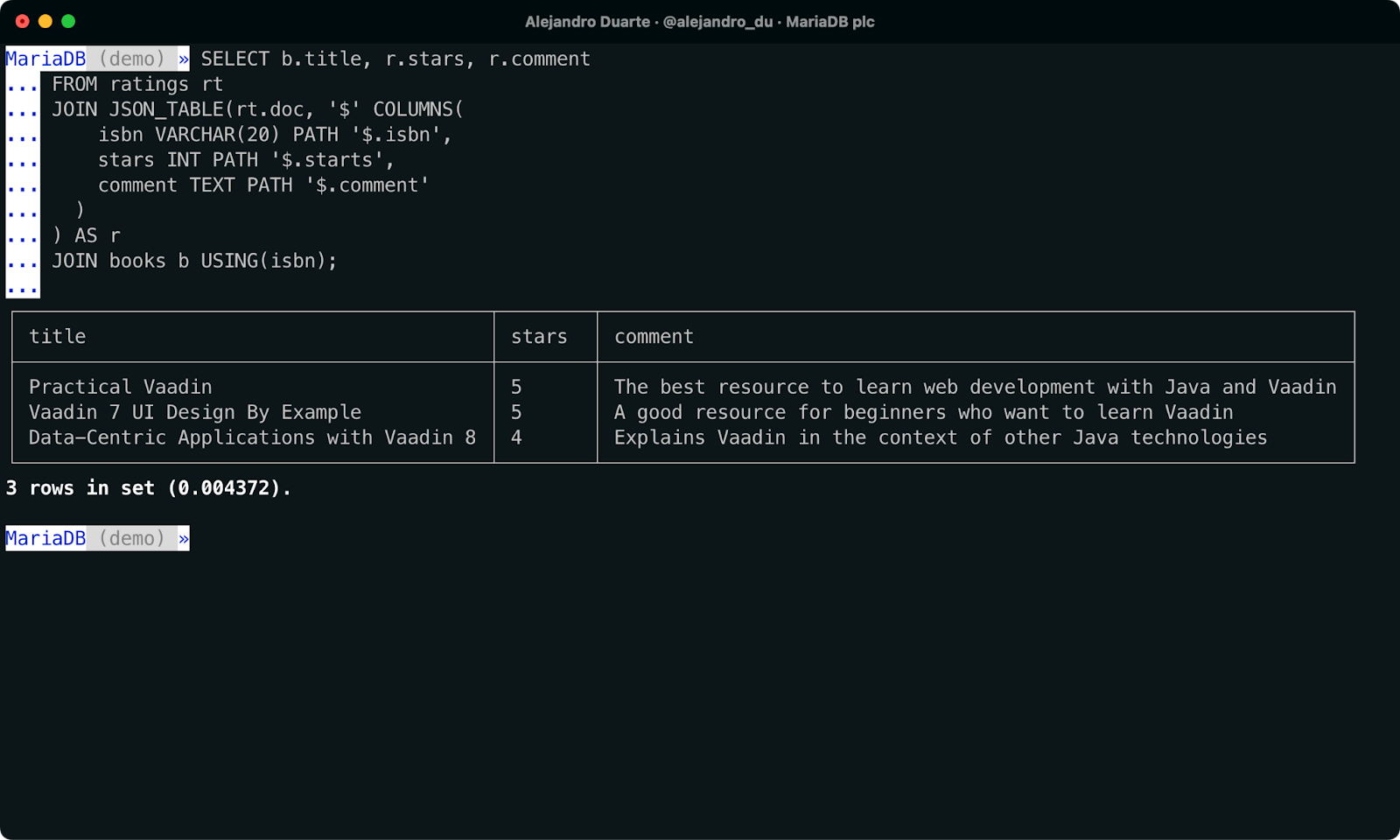
NoSQL과 SQL 데이터를 하나의 SQL 쿼리로 결합.
우리는 ISBN 값을 MongoDB ObjectID로 사용하고, 따라서 ratings 테이블의 id 컬럼으로 사용할 수 있었지만, 이를 연습문제로 남겨두겠습니다(힌트: MongoDB 클라이언트나 앱을 사용할 때 _id를 사용하는 대신 isbn을 사용하세요).
A Word on Scalability
관계형 데이터베이스는 수평적으로(더 많은 노드 추가) 확장되지 않는다고 생각하는 오해가 있지만, 관계형 데이터베이스는 ACID 특성을 희생하지 않고 확장합니다. MariaDB는 다양한 작업 부하에 맞는 여러 스토리지 엔진을 갖추고 있습니다. 예를 들어, Spider의 도움으로 데이터 샤딩을 구현함으로써 MariaDB 데이터베이스를 확장할 수 있습니다. 또한 각 테이블 별로 다양한 작업 부하를 처리할 수 있는 다양한 스토리지 엔진을 사용할 수 있습니다. 단일 SQL 쿼리 내에서 엔진 간 조인이 가능합니다.
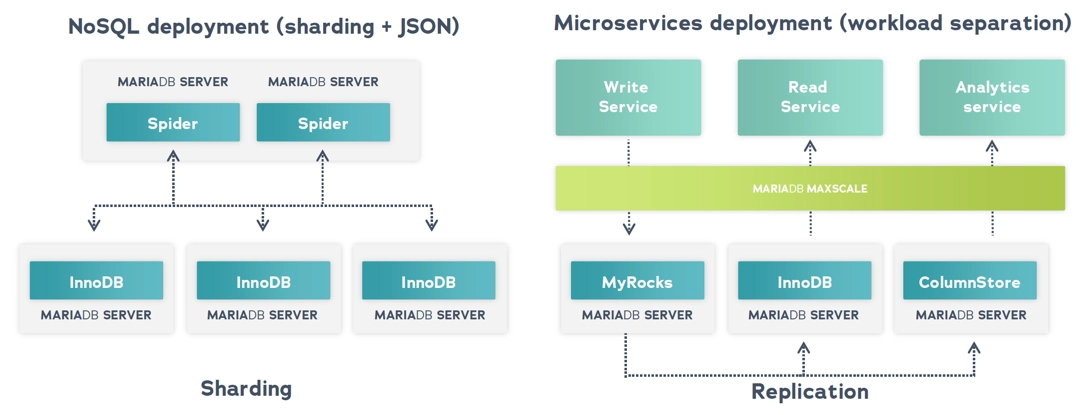
단일 논리 MariaDB 데이터베이스에서 다중 스토리지 엔진 결합.
또 다른 더 현대적인 대안은 분산 SQL과 MariaDB Xpand입니다. 분산 SQL 데이터베이스는 투명한 샤딩을 통해 애플리케이션에서 단일 논리적 관계형 데이터베이스로 보입니다. 읽기와 쓰기 모두 확장 가능한 공유 없는 아키텍처를 사용합니다.
A distributed SQL database deployment.
결론
우리의 임무는 여기서 완료되었습니다! 이제 시스템은 SQL 또는 NoSQL 애플리케이션에 의해 생성된 데이터에 관계없이 ACID 규격을 준수하는 확장 가능한 360도 데이터 보기를 갖출 수 있습니다. NoSQL에서 SQL로 앱을 마이그레이션하거나 SQL 앱을 데이터베이스 다중 언어 사용자로 만들어야 하는 필요성이 줄었습니다. MaxScale의 다른 기능에 대해 자세히 알고 싶다면 이 비디오를 시청하거나 문서를 방문하세요.
Source:
https://dzone.com/articles/mixing-sql-and-nosql-with-mariadb-and-mongodb