













우리의 지난 기사에서는 ‘sort‘ 명령의 다양한 예제를 다루었습니다. 놓친 경우 아래 링크를 따라잡을 수 있습니다. 이 게시물에서는 이전 기사에서 남은 명령의 측면을 다루기 시작할 것입니다. 이렇게 함으로써 두 기사가 함께 리눅스 ‘sort‘ 명령의 포괄적인 안내서 역할을 할 것입니다.
더 진행하기 전에 ‘month.txt‘라는 텍스트 파일을 만들고 아래 제공된 데이터로 채워주세요.
echo -e "mar\ndec\noct\nsep\nfeb\naug" > month.txt cat month.txt

15. 월별 파일 내용 정렬
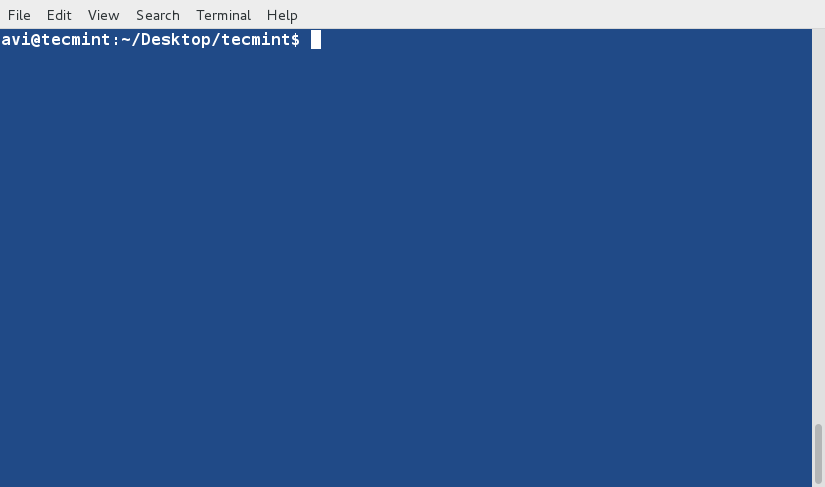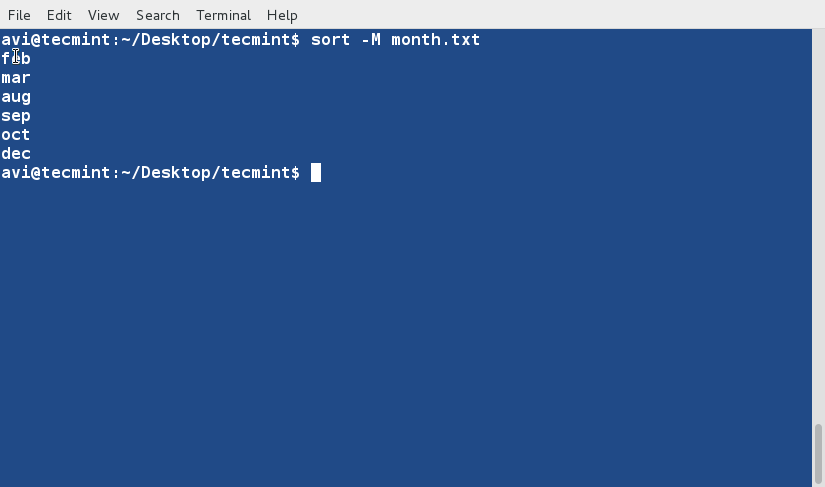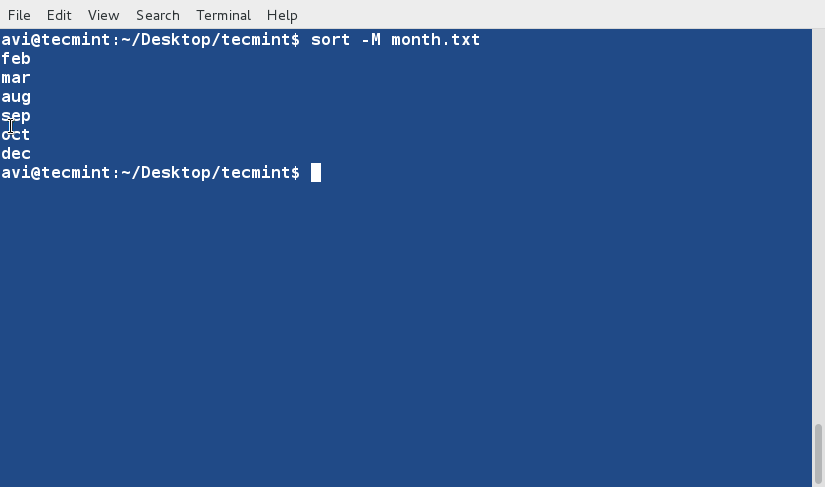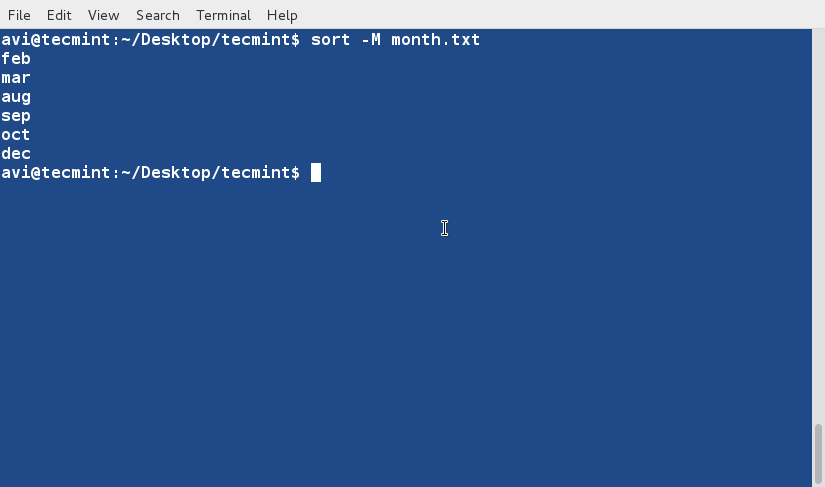
다음 명령은 “month.txt” 파일의 내용을 월 줄임말이나 이름을 기반으로 크로노로지컬 순서로 정렬하는 데 사용되며 데이터를 날짜로 처리하고 이에 따라 정렬하는 ‘sort‘ 명령에 ‘-M‘ 옵션을 사용합니다.
sort -M month.txt
16. 용량 읽기 쉬운 형식으로 파일 크기 정렬
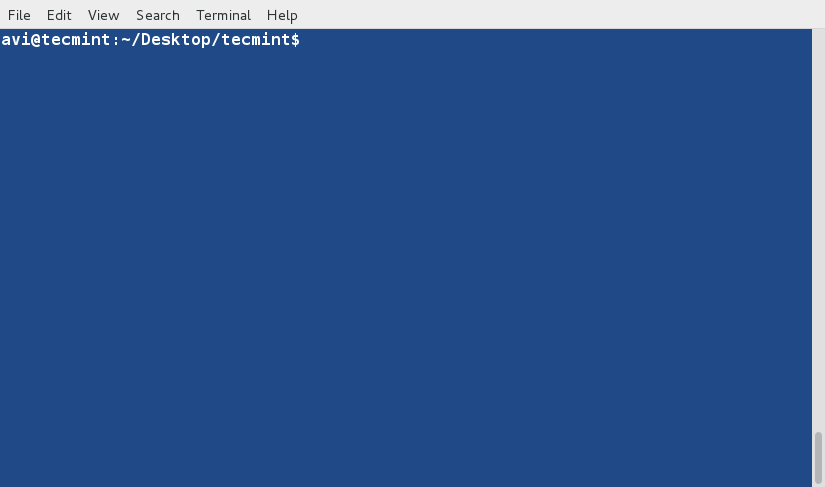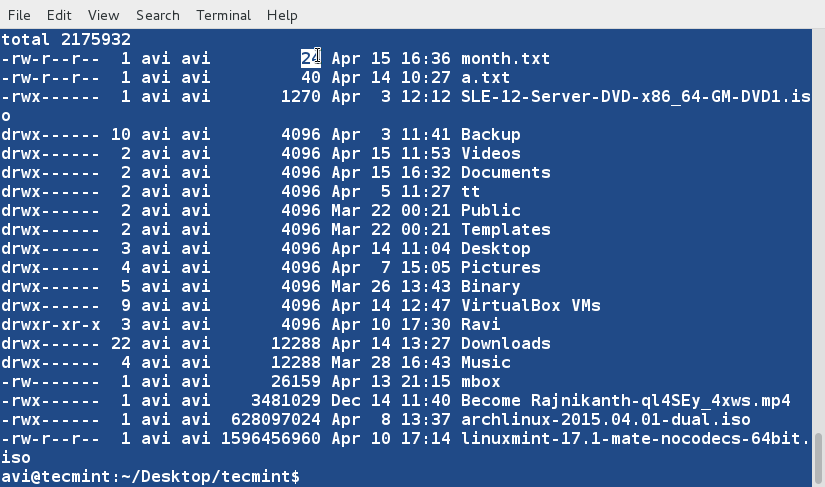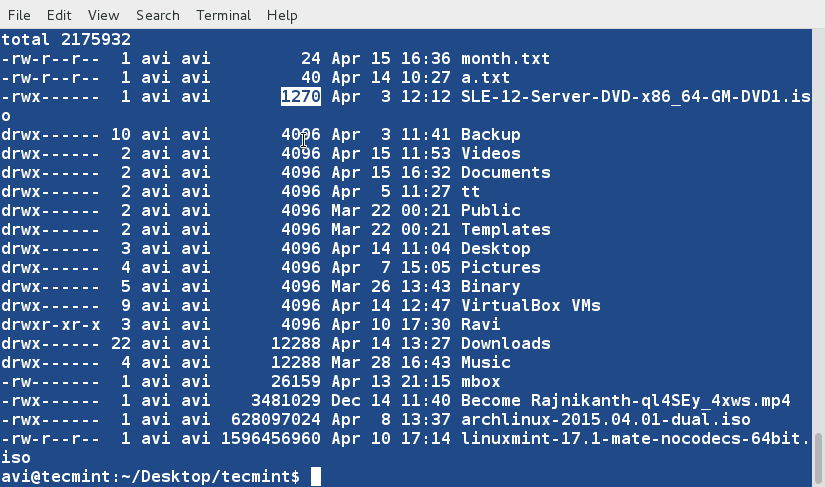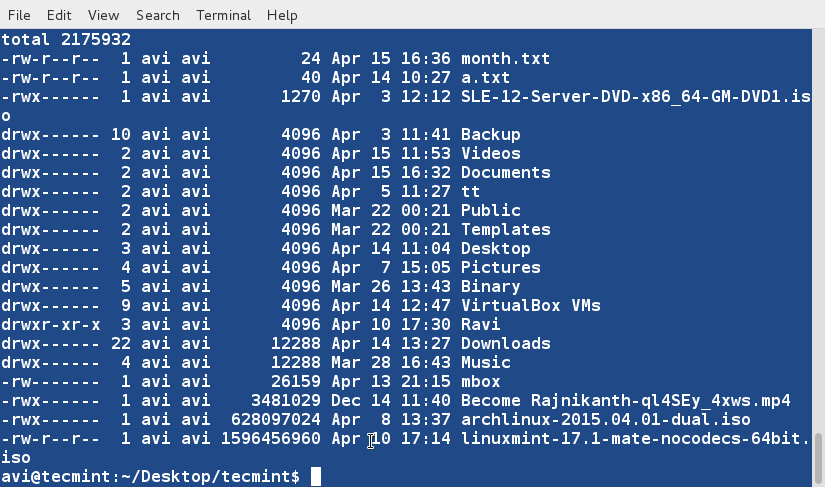
다음 명령은 ‘ls‘와 ‘sort‘ 명령을 결합하여 두 가지 작업을 수행합니다. 먼저 사용자의 홈 디렉터리의 내용을 긴 형식으로 나열한 다음 해당 디렉토리 목록을 ‘sort‘ 명령에 파이프하여 파일 크기를 인간이 읽기 쉬운 형식으로 인쇄하여 디렉터리에서 가장 크고 작은 파일을 식별하기 쉽게 합니다.
ls -l /home/$USER | sort -h -k5
17. 일관성을 위해 정렬 된
이전 글에서는 두 개의 텍스트 파일을 생성했습니다: 예제 번호 4에서 ‘sorted.txt’ 및 예제 번호 6에서 ‘lsl.txt’. ‘sorted.txt’은 이미 정렬되어 있음을 알고 있으며, ‘lsl.txt’은 아닙니다.
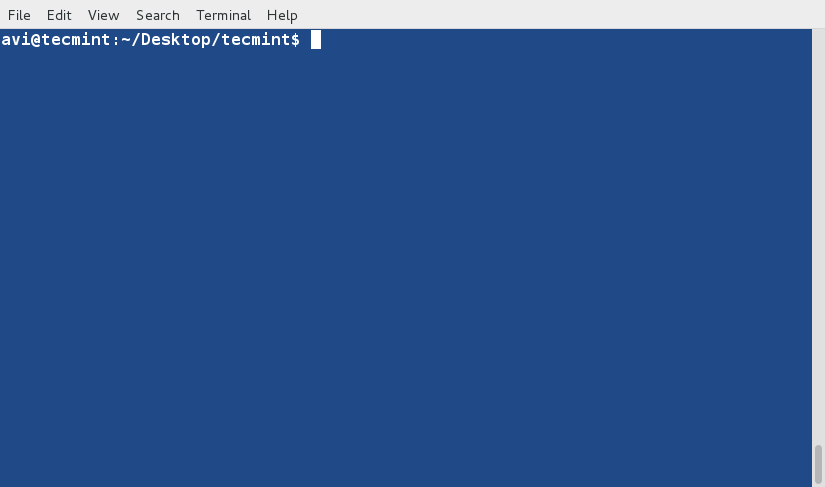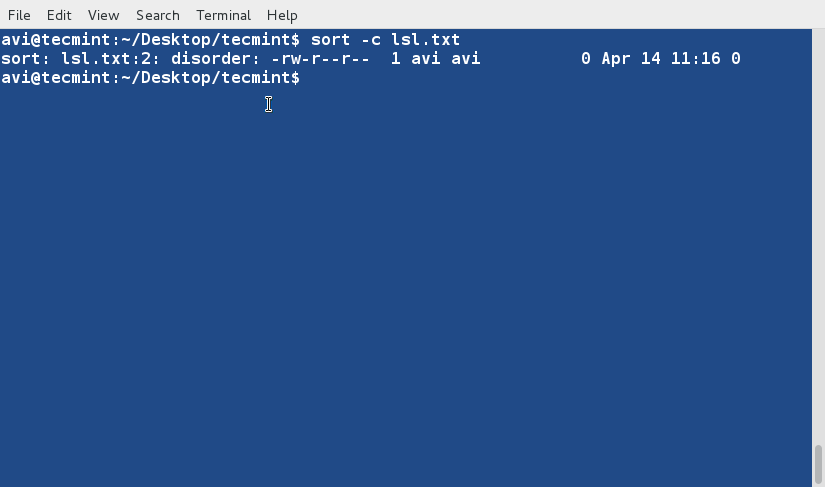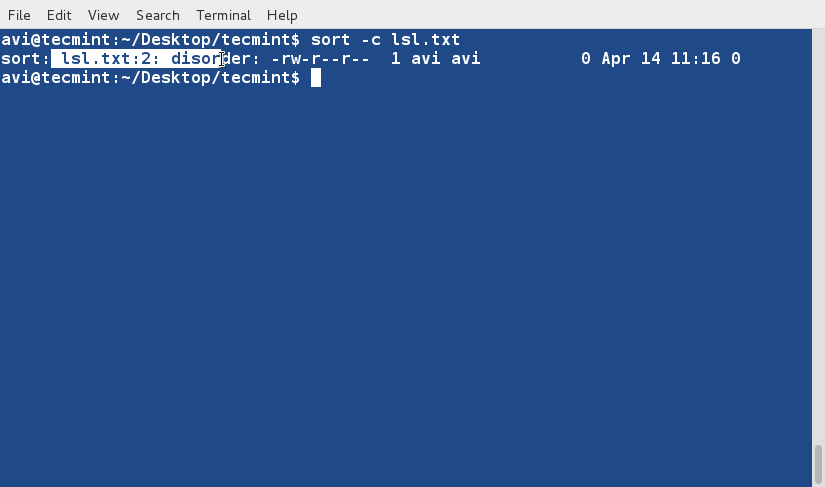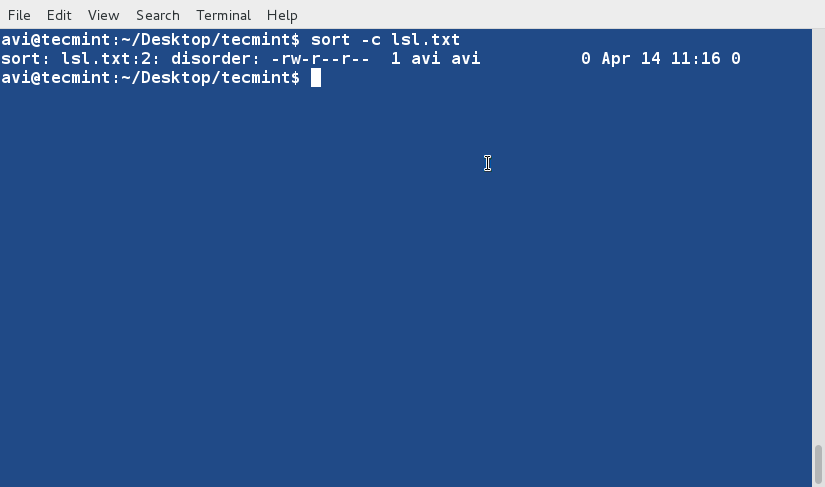
두 파일의 정렬 상태를 확인하기 위해 ‘sort’ 명령을 사용하여 ‘sorted.txt’가 올바른 순서로 유지되고 있는지, 그리고 ‘lsl.txt’가 정렬이 필요한지 확인할 수 있습니다.
sort -c sorted.txt
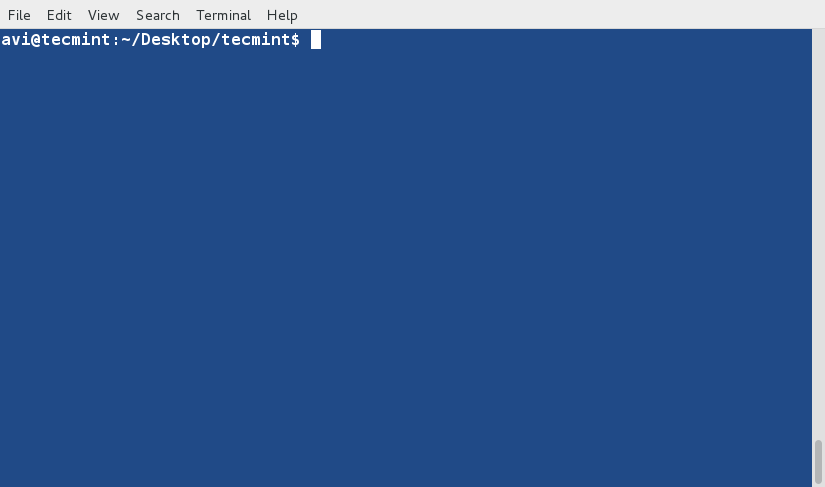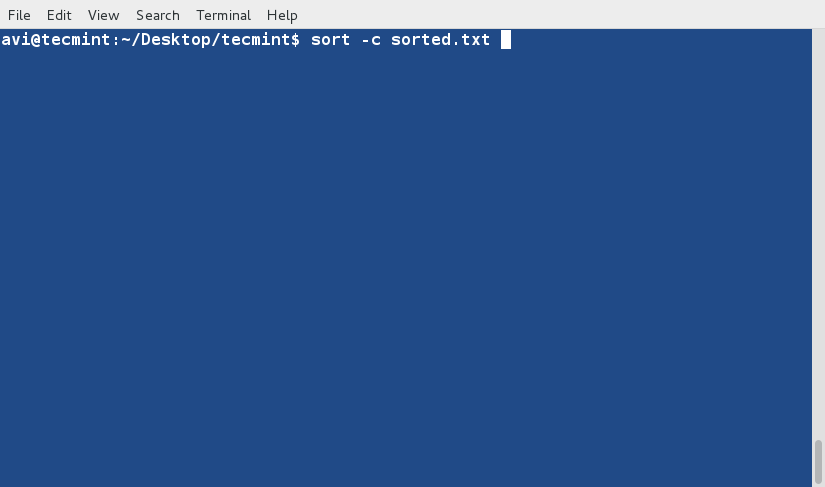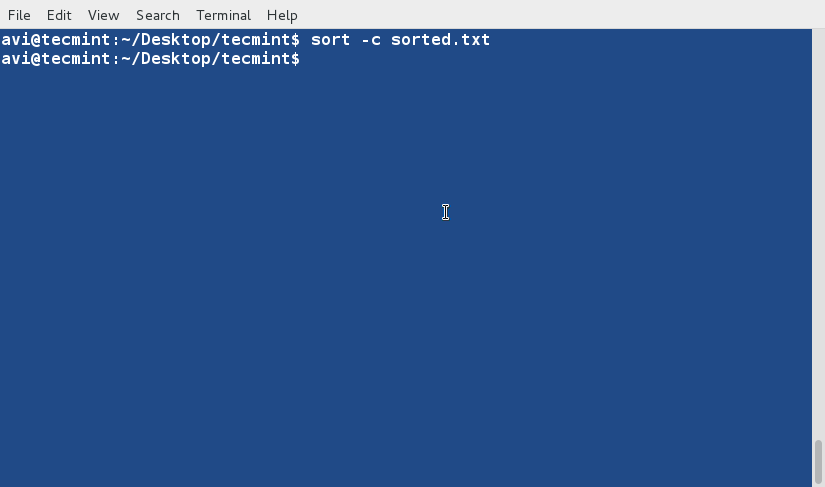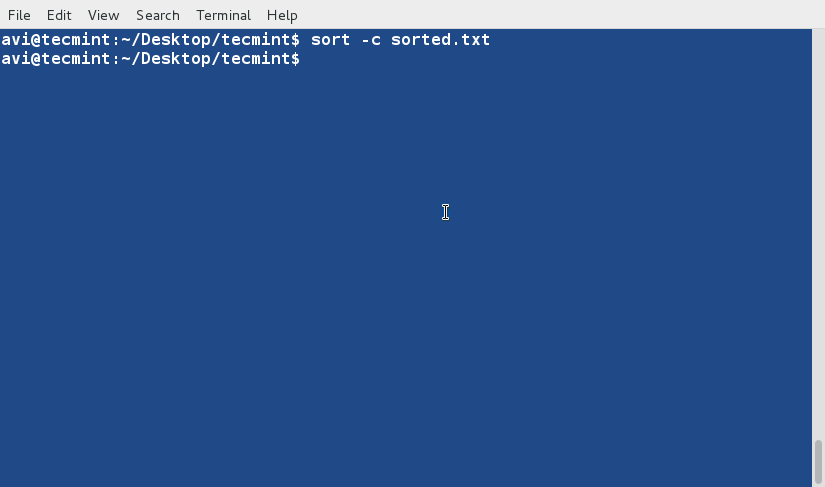
만약 0이 반환된다면, 파일이 정렬되어 있고 충돌이 없음을 의미합니다.
sort -c lsl.txt
18. 파일에서 공백을 사용하지 않을 때 구분 기호 처리
단어 사이의 구분 기호 (분리자)가 공백인 경우, ‘sort’ 명령은 수평 공백 뒤의 모든 것을 새로운 단어로 해석합니다. 그러나 구분 기호가 공백이 아닌 경우에는 어떻게 될까요?
구분 기호가 공백이 아닌 다른 것으로 구분된 텍스트 파일을 고려해보세요. 예를 들어 '|' 또는 '\' 또는 '+' 또는 '.' 또는 ...</code.
내용이 +로 구분된 텍스트 파일을 만들어보세요. 파일의 내용을 확인하기 위해 cat 명령어를 사용하세요.
echo -e "21+linux+server+production\n11+debian+RedHat+CentOS\n131+Apache+Mysql+PHP\n7+Shell Scripting+python+perl\n111+postfix+exim+sendmail" > delimiter.txt
$ cat delimiter.txt

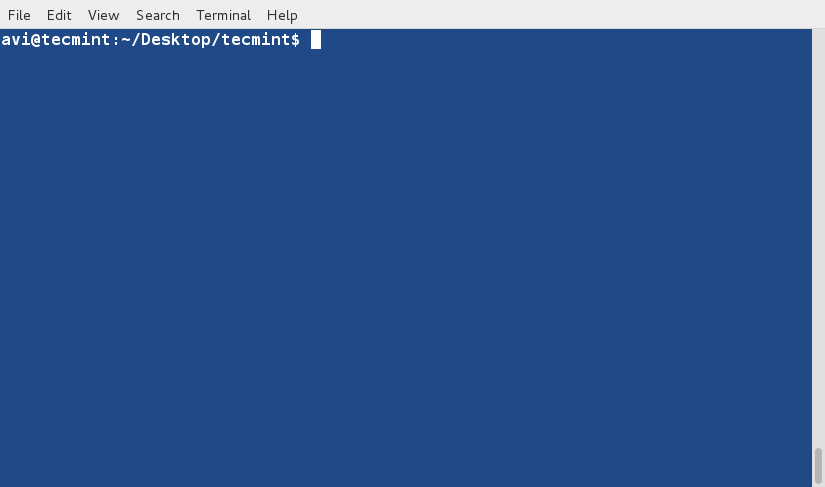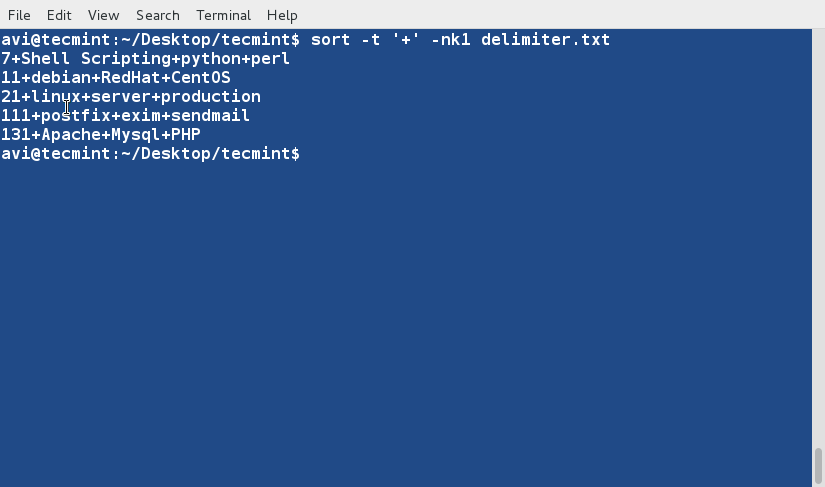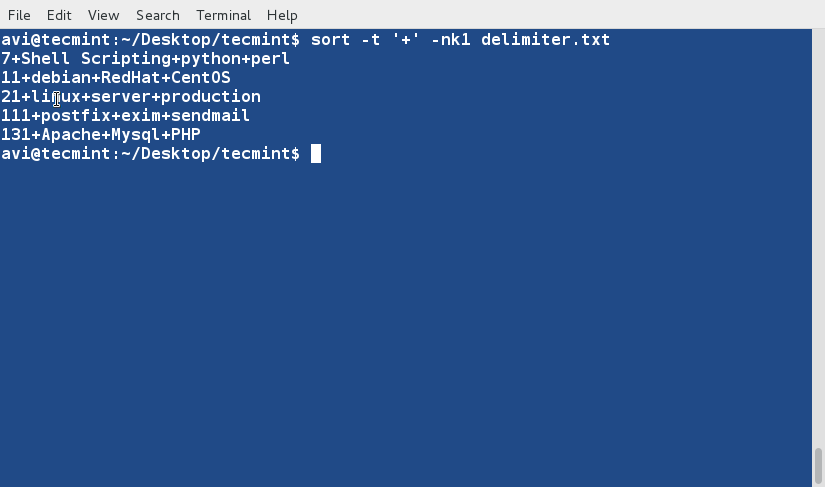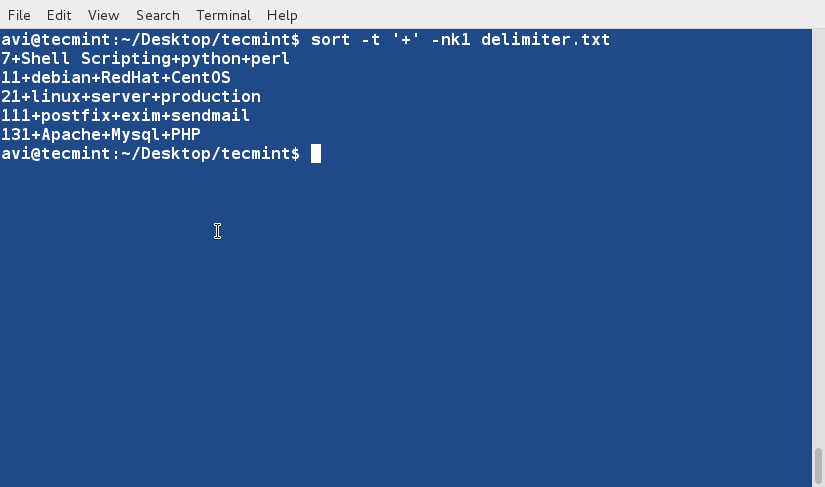
이제 이 파일을 숫자로 구성된 1번째 필드를 기준으로 정렬하십시오.
sort -t '+' -nk1 delimiter.txt
두 번째는 숫자가 아닌 4번째 필드를 기준으로 합니다.
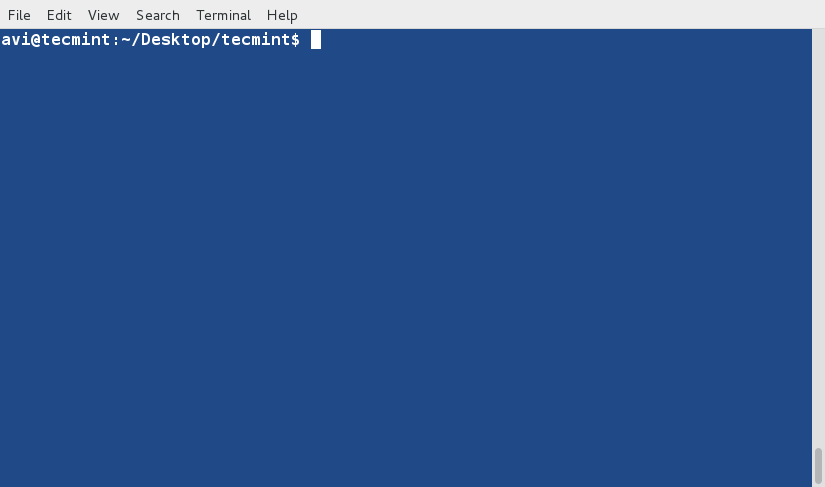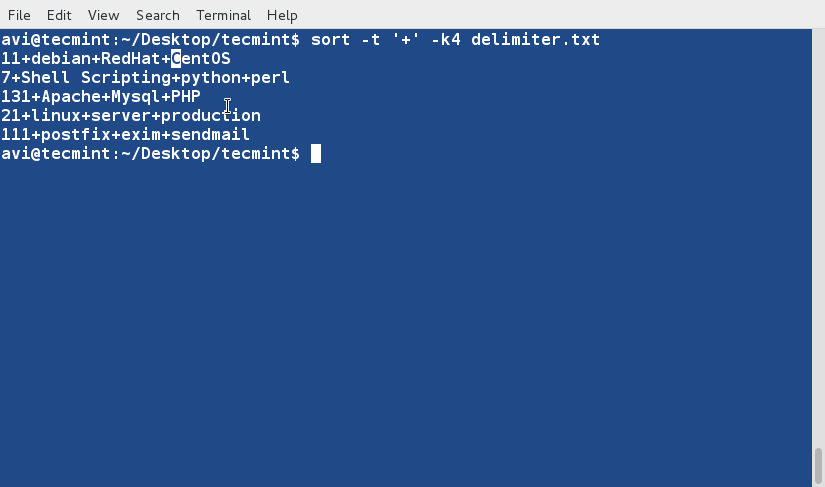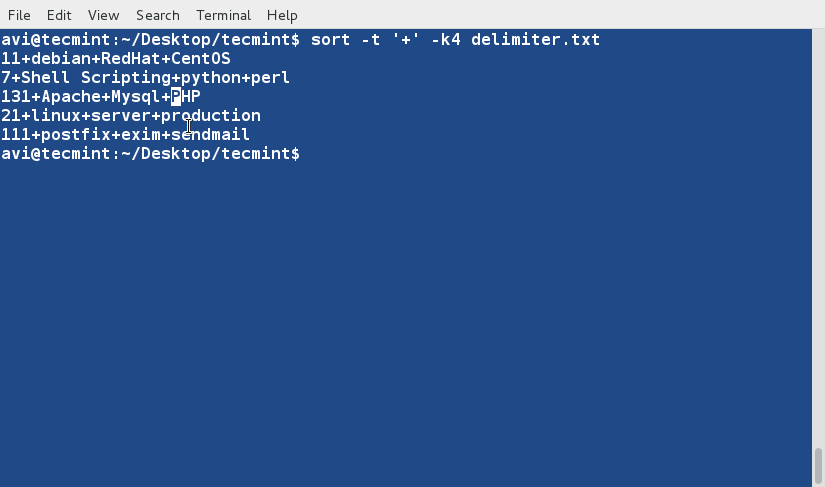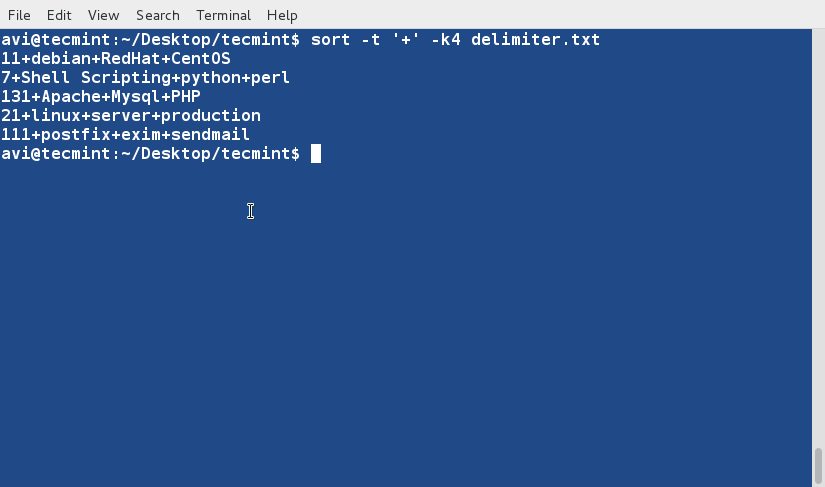
만약 구분자가 '+' 대신에 $'\t'을 사용할 수 있습니다. 이는 위의 예시에서 보여진 것과 같습니다.
19. 파일 크기에 따라 출력을 무작위로 정렬하기
홈 디렉토리의 ls -l 명령의 출력을 다섯 번째 열에 따라 정렬하십시오. 이 열은 ‘데이터 양’을 나타냅니다. 이를 무작위로 정렬하십시오.
ls -l /home/avi/ | sort -k5 -R
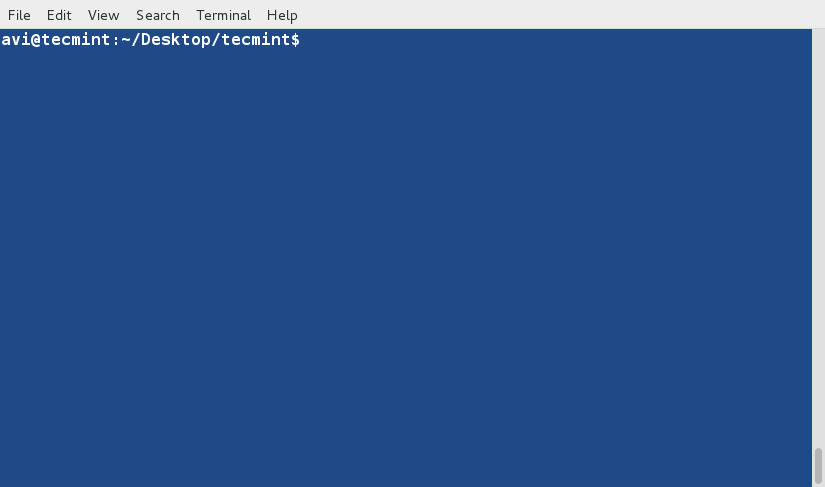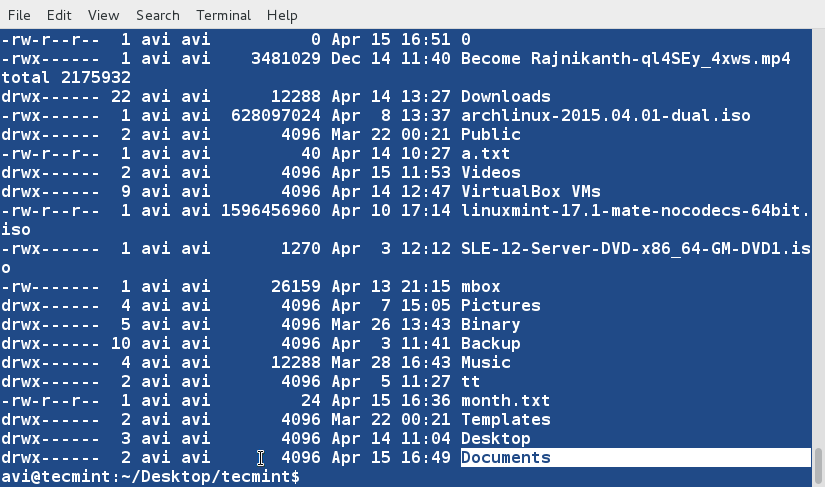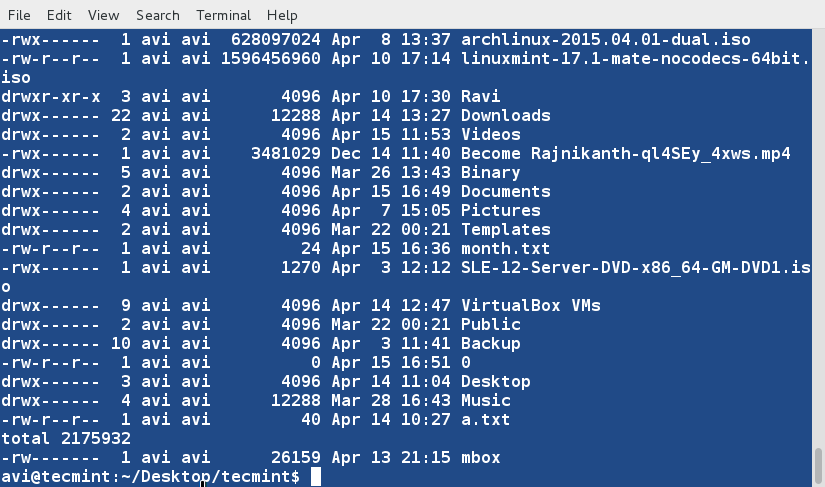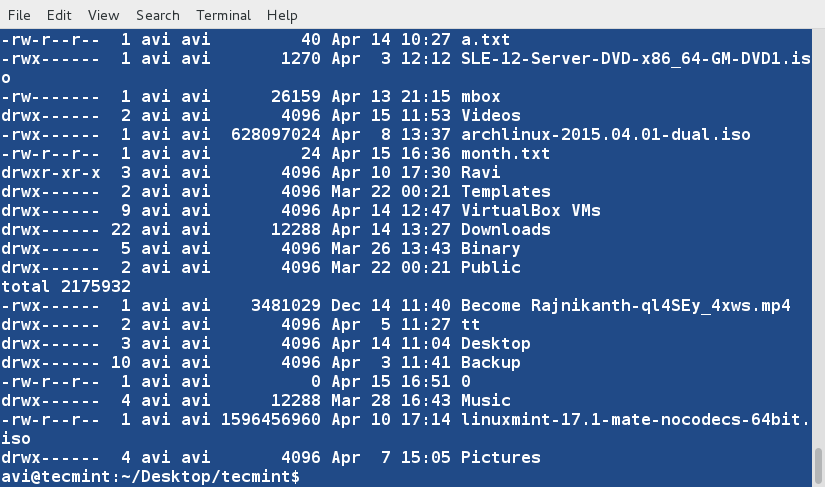
위의 스크립트를 실행할 때마다 결과가 다르게 생성될 가능성이 높습니다. 결과는 무작위로 생성됩니다.
마지막 기사의 규칙 번호 – 2에서 명확하게 나타나듯이, sort 명령은 대문자로 시작하는 줄을 소문자로 시작하는 줄보다 선호합니다. 또한 마지막 기사의 예제 3에서는 문자열 ‘laptop‘이 문자열 ‘LAPTOP‘보다 먼저 나타납니다.
20. 기본 정렬 기본값 재정의하기
기본 정렬 기본값을 어떻게 재정의할까요? 기본 정렬 기본값을 재정의하기 전에 환경 변수 'LC_ALL'을 'C'로 내보내야 합니다.
이를 위해 명령 줄 프롬프트에서 아래 코드를 실행하십시오.
export LC_ALL=C
그런 다음 텍스트 파일 ‘tecmint.txt‘을 기본 정렬 기본값을 재정의하여 정렬하십시오.
$ sort tecmint.txt
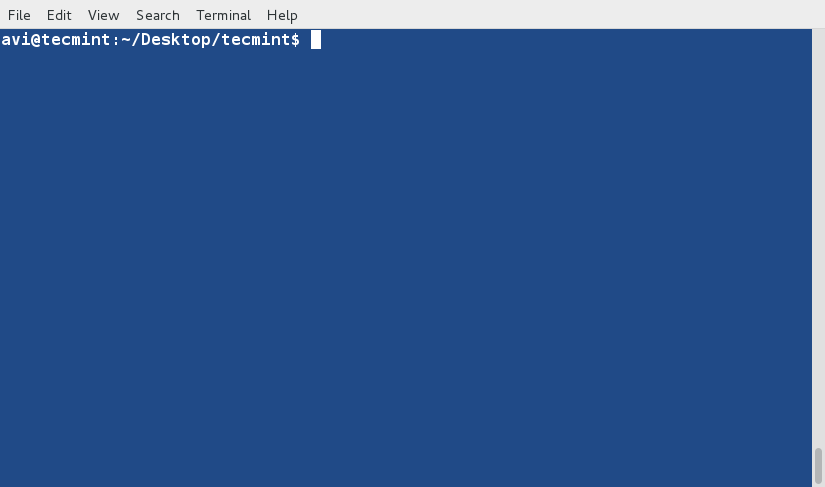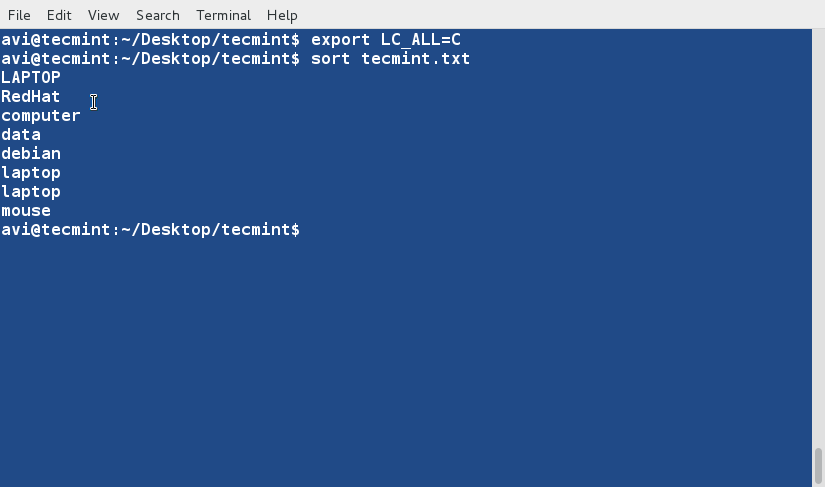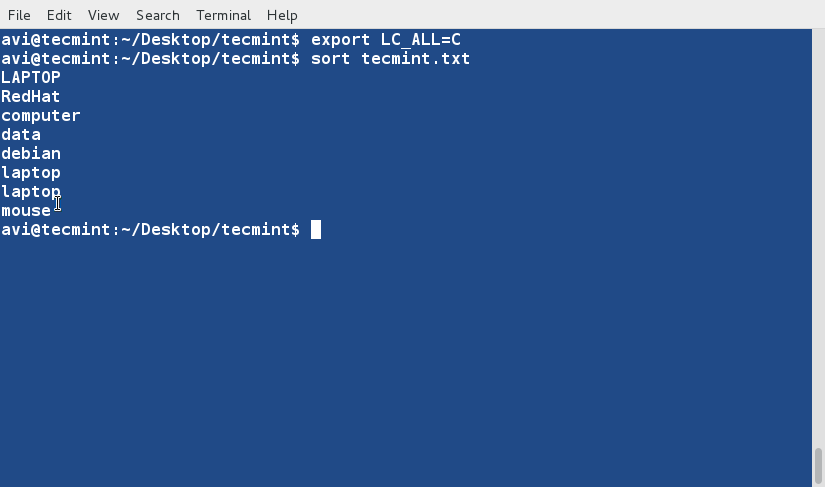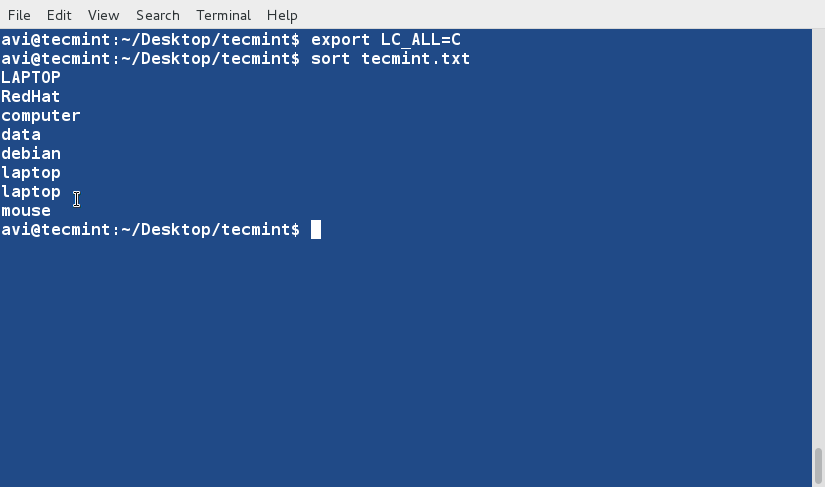
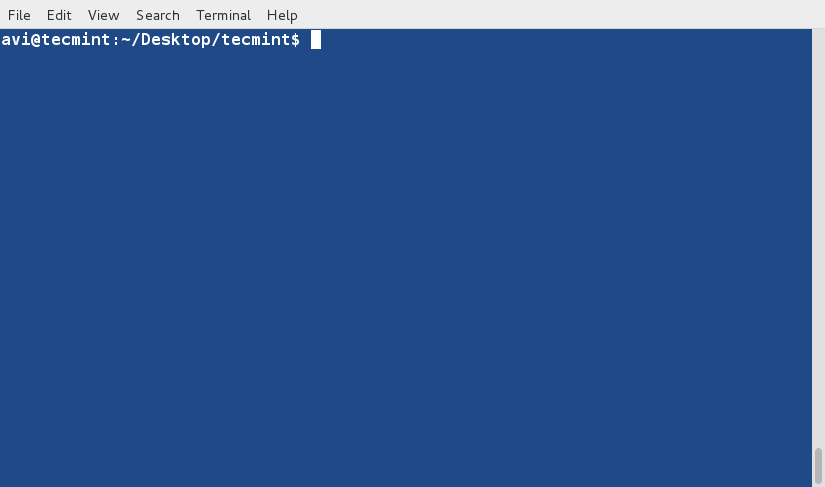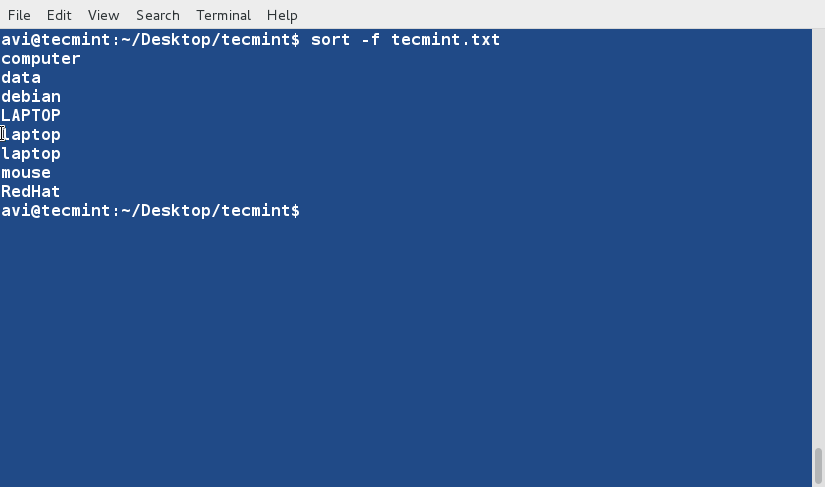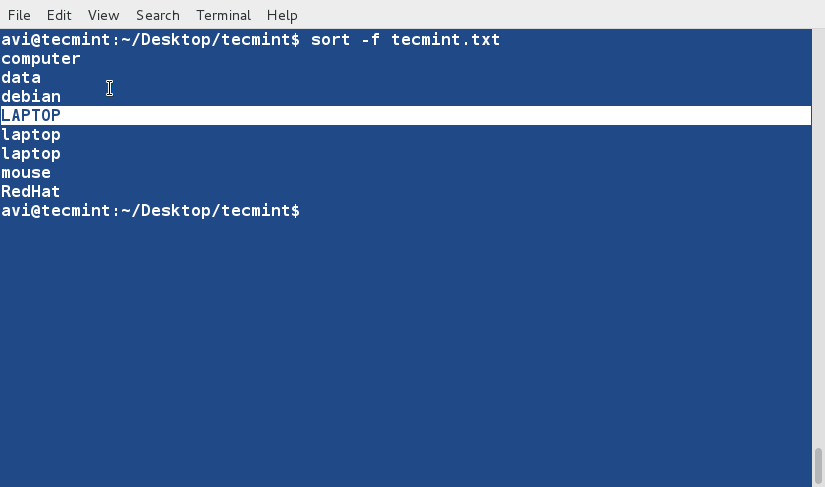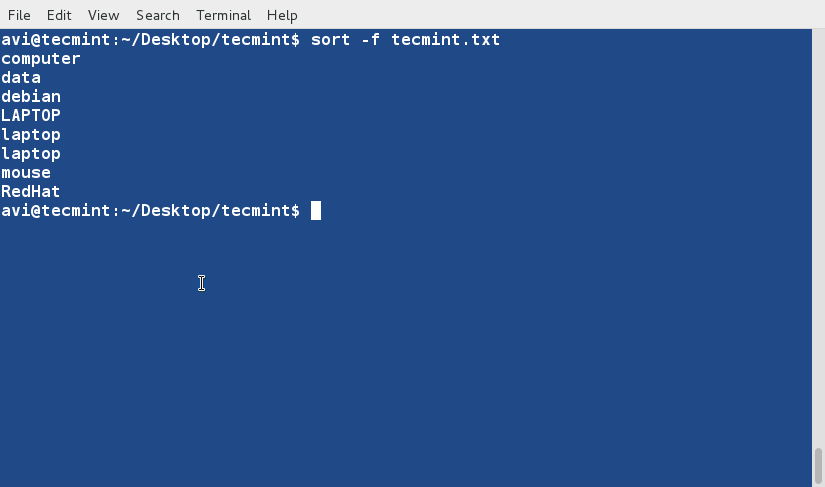
예제 3에서 얻은 출력과 비교하는 것을 잊지 마시고, ‘-f‘ 또는 ‘--ignore-case‘ 옵션을 사용하여 훨씬 조직화된 출력을 얻을 수 있습니다.
$ sort -f tecmint.txt
21. 단일 작업에서 두 입력 파일 결합하기
‘sort‘를 두 입력 파일에서 실행하고 한 번에 결합하는 것은 어떨까요?
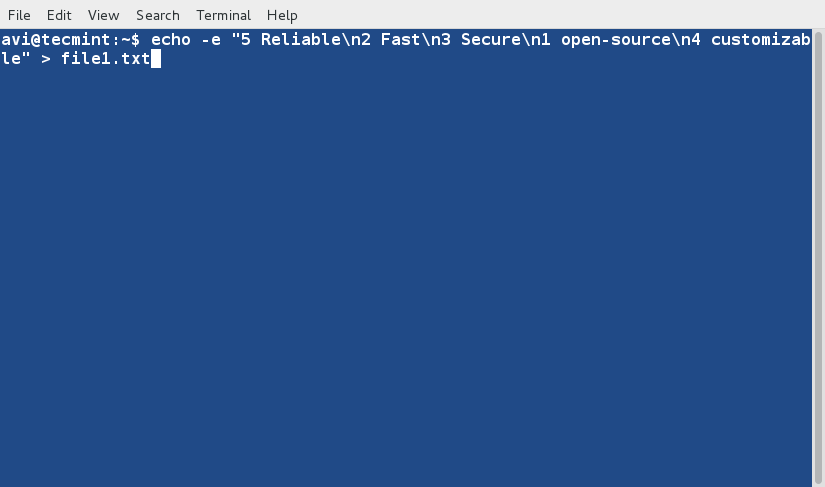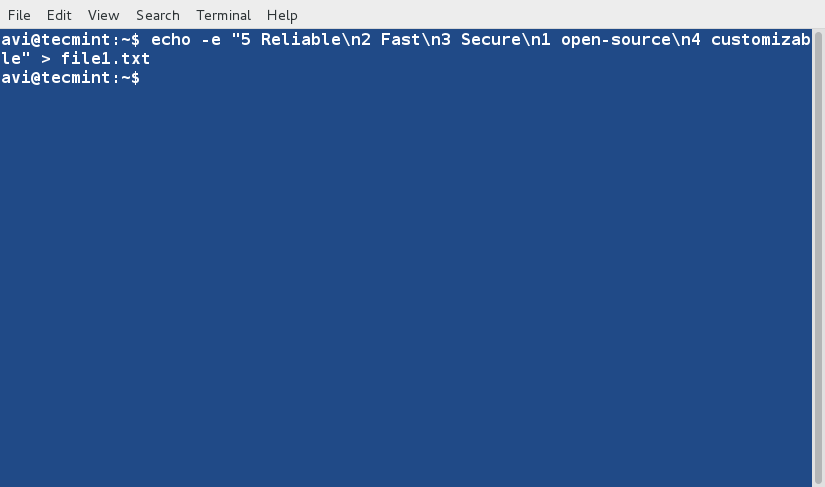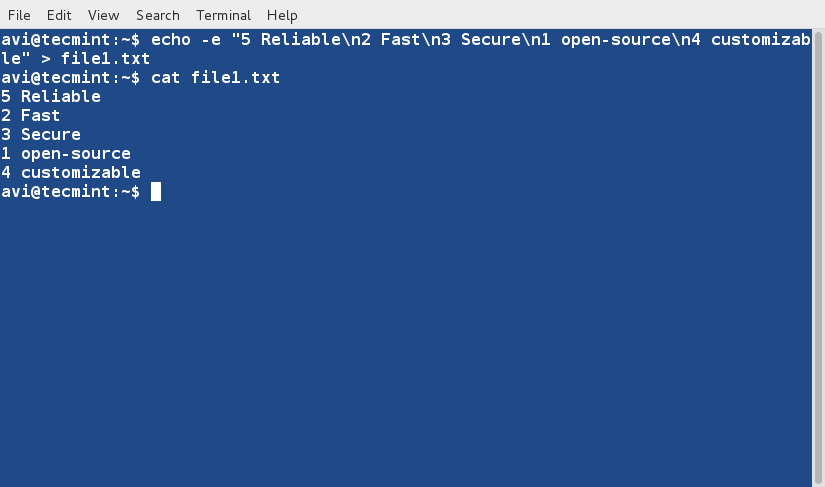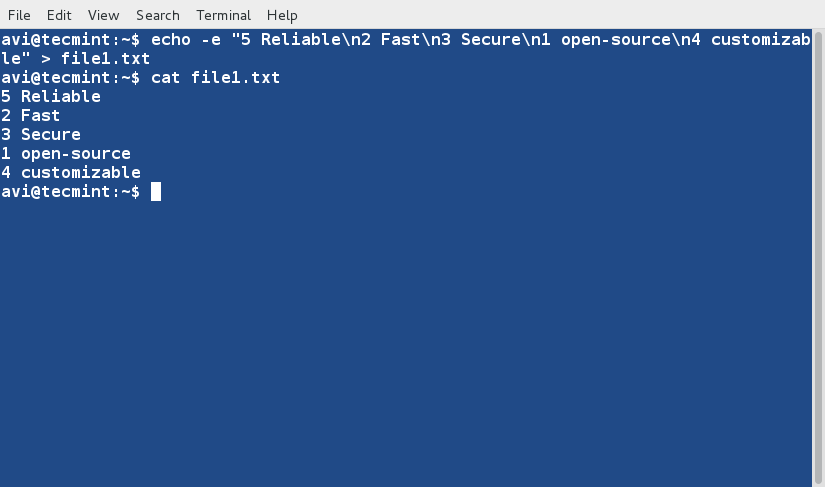
두 개의 텍스트 파일, 즉 ‘file1.txt’와 ‘file2.txt’를 생성하고 데이터를 채워봅시다. ‘file1.txt’에는 아래와 같이 숫자를 추가합니다. 또한 파일 내용을 검사하기 위해 cat 명령어를 사용할 것입니다.
echo -e “5 Reliable\n2 Fast\n3 Secure\n1 open-source\n4 customizable” > file1.txt cat file1.txt
두 번째 파일 ‘file2.txt’에도 데이터를 추가합니다.
echo -e “3 RedHat\n1 Debian\n5 Ubuntu\n2 Kali\n4 Fedora” > file2.txt cat file2.txt

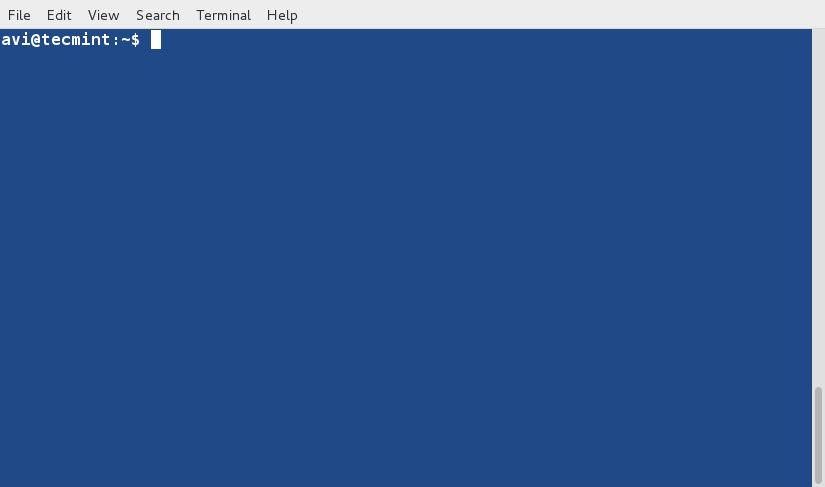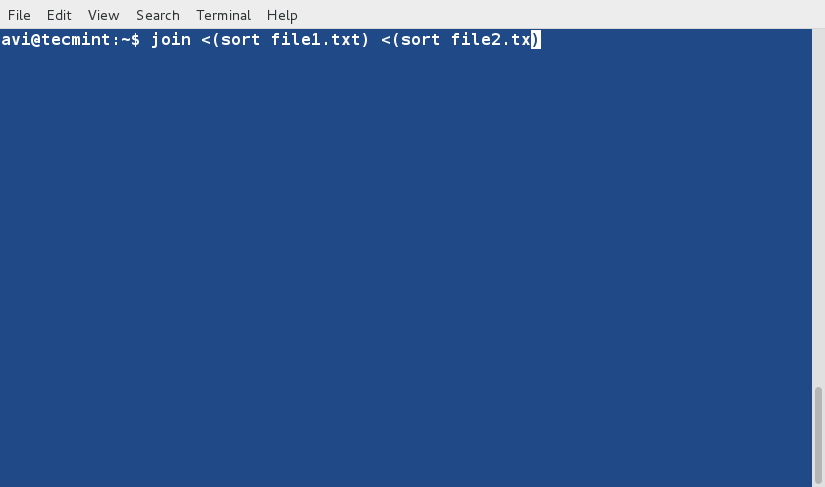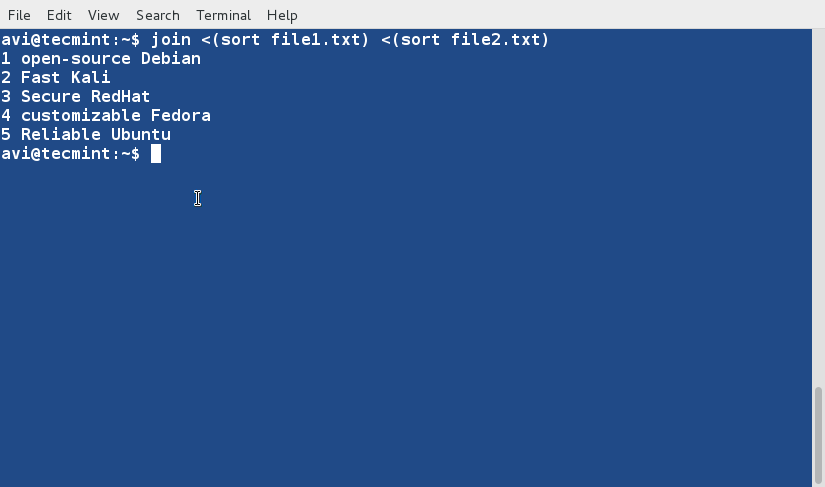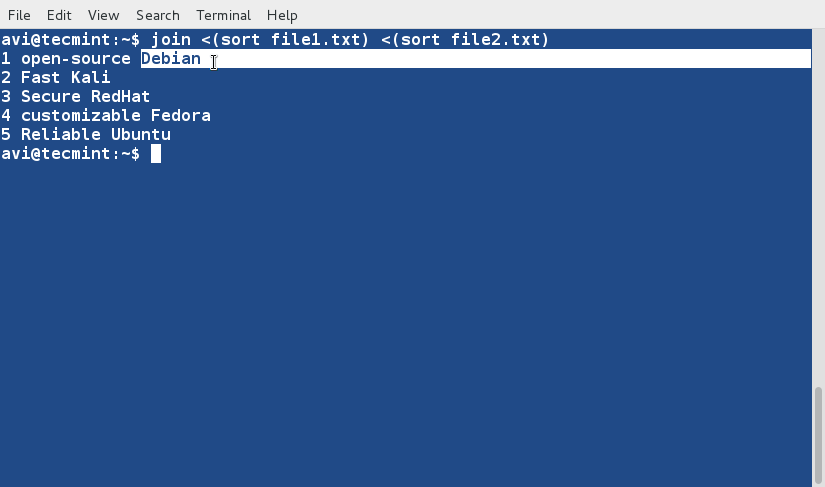
이제 두 파일의 출력을 정렬하고 결합하세요.
join <(sort -n file1.txt) <(sort file2.txt)
결론
이 문서에서는 리눅스의 ‘sort’ 명령어의 다양한 측면을 탐색했습니다. 우리는 알파벳 순으로 기본 정렬을 시작으로 숫자 및 날짜 기반 정렬으로 나아가고 심지어 사용자 지정 구분 기호에 대해 다루었습니다. 또한 우리는 기본 정렬 기준을 무시하고 필요에 맞게 재정의하는 방법을 배웠습니다.
게다가, 파일이 이미 정렬되어 있는지 확인하는 기술과 여러 입력 파일에 대한 ‘sort’ 작업을 결합하는 기술에 대해 논의했습니다. 여기서 얻은 지식으로 리눅스 환경에서 데이터를 효율적으로 정렬하고 구성하는 강력한 도구를 손에 넣었습니다.
이 문서가 여러분의 명령 줄 노력에 유익하고 유용했기를 바랍니다. 계속해서 리눅스 기술을 향상시키기 위해 ‘sort’의 기술을 탐색하고 배우고 숙달해 나가세요.
Source:
https://www.tecmint.com/linux-sort-command-examples/