













빅 데이터는 2000년대 후반에 처음 등장한 이후 크게 발전해 왔습니다. 많은 조직이 빠르게 이 추세에 적응하여 Apache Hadoop과 같은 오픈 소스 도구를 사용하여 빅 데이터 플랫폼을 구축했습니다. 이후 이러한 기업들은 빠르게 변화하는 데이터 처리 요구 사항을 관리하는 데 어려움을 겪기 시작했습니다.
2010년대 초반에 대형 분산 시스템을 설계하는 동안 대형 기술 기업과 의료 고객을 위해 비슷한 도전에 직면했습니다. 일부 산업은 은행, 금융 및 의료 규정을 준수하기 위해 이러한 기능이 필요합니다. Netflix와 같은 고도로 데이터 중심적인 기업들도 비슷한 어려움을 겪었습니다. 그들은 “아이스버그”라는 테이블 형식을 발명했는데, 이는 기존 데이터 파일 위에 위치하여 아키텍처를 활용하여 주요 기능을 제공합니다. 이것은 데이터 커뮤니티에서 빠르게 관심을 끌며 최고의 ASF 프로젝트로 떠올랐습니다. 이 기사에서는 예시와 다이어그램을 활용하여 Apache Iceberg의 최상위 5가지 주요 기능을 살펴보겠습니다.
1. 시간 여행

그림 1: Apache Iceberg 테이블 형식의 시간 여행 (저자가 작성한 이미지)
이 기능은 데이터를 특정 시점에서 존재하는 그대로 쿼리할 수 있게 해줍니다. 이는 데이터 및 비즈니스 분석가들이 트렌드를 이해하고 데이터가 시간이 지남에 따라 어떻게 발전했는지를 파악할 수 있는 새로운 가능성을 열어줍니다. 오류가 발생할 경우 이전 상태로 손쉽게 롤백할 수 있습니다. 이 기능은 특정 시점의 데이터를 분석할 수 있게 해주어 감사 점검을 용이하게 합니다.
-- time travel to October 5th, 1978 at 07:00:00
SELECT * FROM prod.retail.cusotmers TIMESTAMP AS OF '1978-10-05 07:00:00';
-- time travel using a specific snapshot ID:
SELECT * FROM prod.retail.customers VERSON AS OF 949530903748831869;
2. 스키마 진화
Apache Iceberg의 스키마 진화는 대규모 노력이나 비싼 마이그레이션 없이 스키마 변경을 허용합니다. 비즈니스 요구 사항이 발전함에 따라 다음을 수행할 수 있습니다:
- 다운타임이나 테이블 재작성 없이 열을 추가하거나 제거합니다.
- 열 업데이트(넓히기).
- 열의 순서를 변경합니다.
- 기존 열의 이름을 변경합니다.
이러한 변경은 기본 데이터를 재작성할 필요 없이 메타데이터 수준에서 처리됩니다.
-- add a new column to the table
ALTER TABLE prod.retail.customers ADD COLUMNS (email_address STRING);
-- remove an existing column from the table
ALTER TABLE prod.retail.customers DROP COLUMN num_of_years;
-- rename an existing column
ALTER TABLE prod.retail.customers RENAME COLUMN email_address TO email;
-- iceberg allows updating column types from int to bigint, float to double
ALTER TABLE prod.retail.customers ALTER COLUMN customer_id TYPE bigint;
3. 파티션 진화
Apache Iceberg 테이블 형식을 사용하면 기본 테이블을 재작성하거나 데이터를 새로운 테이블로 마이그레이션하지 않고도 테이블 파티셔닝 전략을 변경할 수 있습니다. 이는 쿼리에서 Apache Hadoop처럼 파티션 값을 직접 참조하지 않기 때문에 가능합니다. Iceberg는 각 파티션 버전에 대한 메타데이터 정보를 별도로 유지합니다. 이는 데이터를 쿼리할 때 분할을 쉽게 가져올 수 있게 해줍니다. 예를 들어, 테이블이 월을 파티션 열로 사용하고(이전) 날짜 범위를 기반으로 테이블을 쿼리하면서 일(day)을 새로운 파티션 열로 사용하여(이후) 또 다른 분할로 만들 수 있습니다. 이를 분할 계획(split planning)이라고 합니다. 아래 예제를 참조하세요.
-- create customers table partitioned by month of the create_date initially
CREATE TABLE local.retail.customer (
id BIGINT,
name STRING,
street STRING,
city STRING,
state STRING,
create_date DATE
USING iceberg
PARTITIONED BY (month(create_date));
-- insert some data into the table
INSERT INTO local.retail.customer VALUES
(1, 'Alice', '123 Maple St', 'Springfield', 'IL', DATE('2024-01-10')),
(2, 'Bob', '456 Oak St', 'Salem', 'OR', DATE('2024-02-15')),
(3, 'Charlie', '789 Pine St', 'Austin', 'TX', DATE('2024-02-20'));
-- change the partition scheme from month to date
ALTER TABLE local.retail.customer
REPLACE PARTITION FIELD month(create_date) WITH days(create_date);
-- insert couple more records
INSERT INTO local.retail.customer VALUES
(4, 'David', '987 Elm St', 'Portland', 'ME', DATE('2024-03-01')),
(5, 'Eve', '654 Birch St', 'Miami', 'FL', DATE('2024-03-02'));
-- select all columns from the table
SELECT * FROM local.retail.customer
WHERE create_date BETWEEN DATE('2024-01-01') AND DATE('2024-03-31');
-- output
1 Alice 123 Maple St Springfield IL 2024-01-10
5 Eve 654 Birch St Miami FL 2024-03-02
4 David 987 Elm St Portland ME 2024-03-01
2 Bob 456 Oak St Salem OR 2024-02-15
3 Charlie 789 Pine St Austin TX 2024-02-20
-- View parition details
SELECT partition, file_path, record_count
FROM local.retail.customer.files;
-- output
{"create_date_month":null,"create_date_day":2024-03-02} /Users/rellaturi/warehouse/retail/customer/data/create_date_day=2024-03-02/00000-6-ae2fdf0d-5567-4c77-9bd1-a5d9f6c83dfe-0-00002.parquet 1
{"create_date_month":null,"create_date_day":2024-03-01} /Users/rvellaturi/warehouse/retail/customer/data/create_date_day=2024-03-01/00000-6-ae2fdf0d-5567-4c77-9bd1-a5d9f6c83dfe-0-00001.parquet 1
{"create_date_month":648,"create_date_day":null} /Users/rvellaturi/warehouse/retail/customer/data/create_date_month=2024-01/00000-3-64c8b711-f757-45b4-828f-553ae9779d14-0-00001.parquet 1
{"create_date_month":649,"create_date_day":null} /Users/rvellaturi/warehouse/retail/customer/data/create_date_month=2024-02/00000-3-64c8b711-f757-45b4-828f-553ae9779d14-0-00002.parquet 2
4. ACID 트랜잭션
아이스버그는 원자성, 일관성, 격리성 및 지속성 (ACID) 측면에서 트랜잭션에 대한 강력한 지원을 제공합니다. 이는 여러 동시 쓰기 작업을 허용하여 데이터 일관성을 손상시키지 않으면서도 데이터 집약적인 작업에서 높은 처리량을 가능하게 합니다.
-- Start a transaction
START TRANSACTION;
-- Insert new records
INSERT INTO customers VALUES (1, 'John'), (2, 'Mike');
-- Update existing records
UPDATE customers SET column1 = 'Josh' WHERE id = 1;
-- Delete records
DELETE FROM customers WHERE id = 2;
-- Commit the transaction
COMMIT;
아이이즈버그의 모든 작업은 트랜잭셔널하여, 데이터의 실패나 동시 수정에도 불구하고 데이터가 일관성을 유지합니다.
-- Atomic update across multiple tables
START TRANSACTION;
UPDATE orders SET status = 'processed' WHERE order_id = 100;
INSERT INTO orders_processed SELECT * FROM orders WHERE order_id = 100;
COMMIT;
또한, 다양한 격리 수준을 지원하여 요구 사항에 따라 성능과 일관성을 조정할 수 있습니다.
-- Set isolation level (syntax may vary depending on the query engine)
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
-- Perform operations
SELECT * FROM customers WHERE id = 1;
UPDATE customers SET rec_status= 'updated' WHERE id = 1;
COMMIT;
다음은 아이스버그가 행 수준의 업데이트 및 삭제를 처리하는 방법을 보여주는 요약입니다.
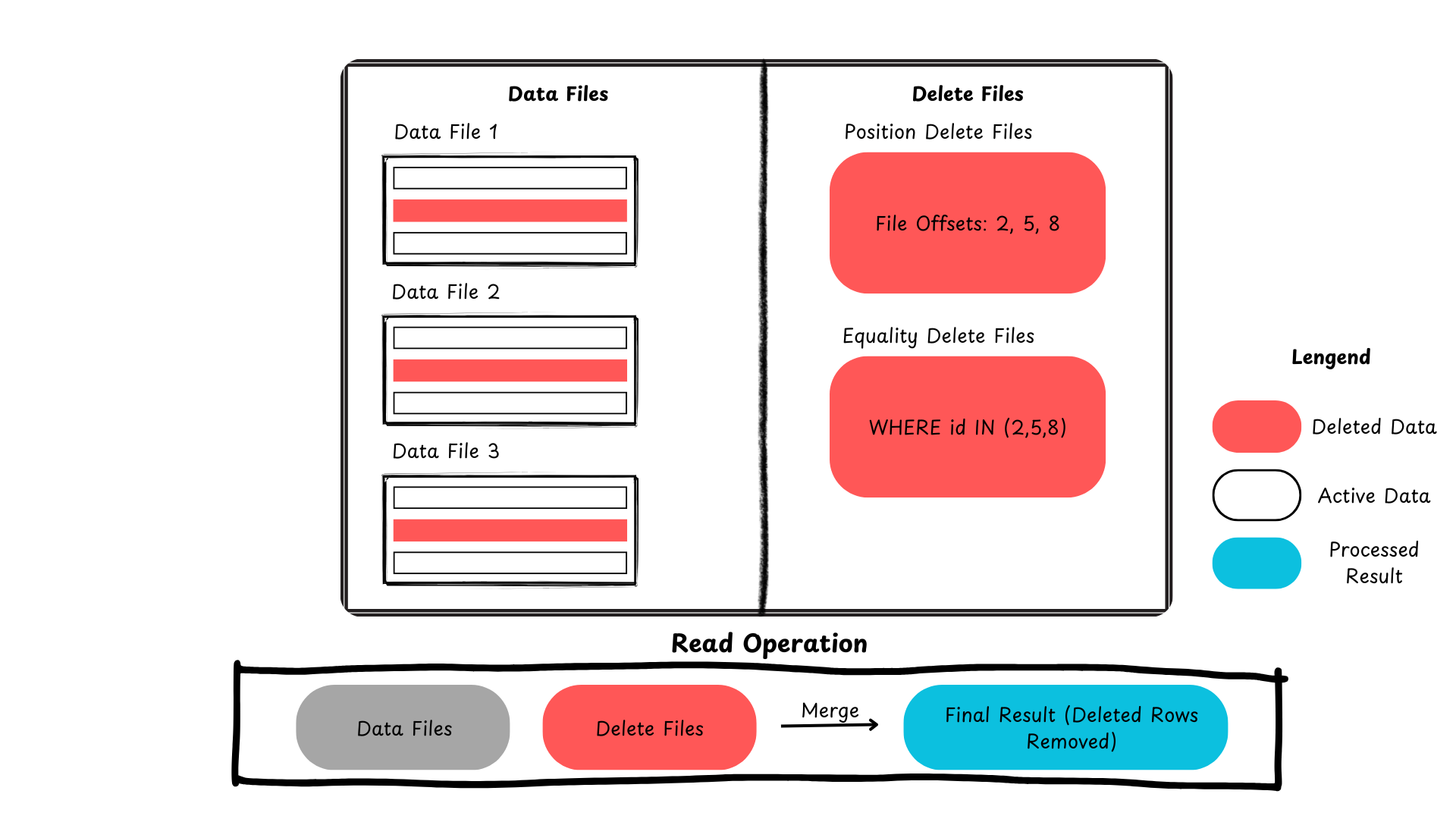
그림 2: 아파치 아이스버그에서의 기록 삭제 과정 (저자 제작 이미지)
5. 고급 테이블 작업
아이이즈버그는 다음과 같은 고급 테이블 작업을 지원합니다:
- 테이블 스냅샷 생성/관리: 이는 강력한 버전 관리를 가능하게 합니다.
- 고도로 최적화된 메타데이터를 통해 빠른 쿼리 계획 및 실행
- 압축 및 고아 파일 정리를 위한 내장 도구
아이스버그는 AWS S3, GCS 및 Azure Blob Storage와 같은 모든 주요 클라우드 스토리지와 함께 작동하도록 설계되었습니다. 또한, 아이스버그는 Spark, Presto, Trino 및 Hive와 같은 데이터 처리 엔진과 쉽게 통합됩니다.
최종 생각
이러한 강조된 기능들은 회사들이 현대적이고 유연하며 확장 가능하며 효율적인 데이터 호수를 구축할 수 있도록 해줍니다. 이 데이터 호수는 시간 여행이 가능하며 스키마 변경을 쉽게 처리하고 ACID 트랜잭션을 지원하며 파티션 진화를 지원합니다.
Source:
https://dzone.com/articles/key-features-of-apache-iceberg-for-data-lakes