













자바 HashMap은 자바에서 가장 인기있는 컬렉션 클래스 중 하나입니다. 자바 HashMap은 해시 테이블 기반의 구현입니다. 자바 HashMap은 Map 인터페이스를 구현하는 AbstractMap 클래스를 확장합니다.
자바 HashMap
 자바 HashMap에 대한 몇 가지 중요한 포인트는 다음과 같습니다;
자바 HashMap에 대한 몇 가지 중요한 포인트는 다음과 같습니다;
- 자바 HashMap은 null 키와 null 값 허용합니다.
- HashMap은 정렬되지 않은 컬렉션입니다. HashMap 항목을 키 집합을 통해 반복할 수 있지만, 항목들이 HashMap에 추가된 순서대로 보장되지는 않습니다.
- HashMap은 Hashtable과 거의 유사하지만, 동기화되지 않으며 null 키와 값이 허용됩니다.
- HashMap은 맵 항목을 저장하기 위해 내부 클래스 Node<K,V>를 사용합니다.
- HashMap은 다중 단일 연결 리스트인 버킷 또는 bin에 항목을 저장합니다. 기본 버킷 수는 16이며 항상 2의 제곱수입니다.
- HashMap은 get 및 put 작업에 키의 hashCode()와 equals() 메서드를 사용합니다. 따라서 HashMap 키 객체는 이러한 메서드의 좋은 구현을 제공해야 합니다. 이것이 변경할 수 없는 클래스가 키에 더 적합한 이유입니다. 예를 들어 String과 Integer입니다.
- 자바 HashMap은 스레드 안전하지 않으므로, 멀티스레드 환경에서는 ConcurrentHashMap 클래스를 사용하거나
Collections.synchronizedMap()메서드를 사용하여 동기화된 맵을 얻어야 합니다.
자바 HashMap 생성자
자바 HashMap은 네 가지 생성자를 제공합니다.
- public HashMap(): 가장 일반적으로 사용되는 HashMap 생성자입니다. 이 생성자는 기본 초기 용량 16과 로드 팩터 0.75로 빈 HashMap을 생성합니다.
- public HashMap(int initialCapacity): 이 HashMap 생성자는 초기 용량과 로드 팩터 0.75를 지정하는 데 사용됩니다. HashMap에 저장될 매핑 수를 알고 있다면 다시 해싱을 피하는 데 유용합니다.
- public HashMap(int initialCapacity, float loadFactor): 이 HashMap 생성자는 지정된 초기 용량과 로드 팩터로 빈 HashMap을 생성합니다. HashMap에 저장될 최대 매핑 수를 알고 있다면 사용할 수 있습니다. 보통의 경우 공간과 시간 비용 사이의 좋은 균형을 제공하는 로드 팩터 0.75를 사용하는 것이 좋습니다.
- public HashMap(Map<? extends K, ? extends V> m): 지정된 맵과 로드 팩터 0.75와 동일한 매핑을 가진 Map을 생성합니다.
자바 HashMap 생성자 예시
아래 코드 조각은 위의 모든 생성자를 사용하는 HashMap 예시를 보여줍니다.
Map<String, String> map1 = new HashMap<>();
Map<String, String> map2 = new HashMap<>(2^5);
Map<String, String> map3 = new HashMap<>(32,0.80f);
Map<String,String> map4 = new HashMap<>(map1);
자바 HashMap 메소드
자바에서 HashMap의 중요한 메소드를 살펴보겠습니다.
- public void clear(): 이 HashMap 메소드는 모든 매핑을 제거하고 HashMap이 비어있게 됩니다.
- public boolean containsKey(Object key): 이 메소드는 키가 존재하면 ‘true’를 반환하고 그렇지 않으면 ‘false’를 반환합니다.
- public boolean containsValue(Object value): 이 HashMap 메소드는 값이 존재하면 ‘true’를 반환하고 그렇지 않으면 ‘false’를 반환합니다.
- public Set<Map.Entry<K,V>> entrySet(): 이 메소드는 HashMap 매핑의 Set 뷰를 반환합니다. 이 set은 map에 의해 지원되므로 map의 변경 사항이 set에 반영되고 그 반대도 마찬가지입니다.
- public V get(Object key): 지정된 키에 매핑된 값을 반환하거나 키에 대한 매핑이 없는 경우 null을 반환합니다.
- public boolean isEmpty(): 키-값 매핑이 없는 경우 true를 반환하는 유틸리티 메소드입니다.
- public Set<K> keySet(): 이 맵에 포함된 키의 Set 뷰를 반환합니다. 이 set은 map에 의해 지원되므로 map의 변경 사항이 set에 반영되고 그 반대도 마찬가지입니다.
- public V put(K key, V value): 이 맵에 지정된 키와 값의 매핑을 연결합니다. 맵에 이전에 키에 대한 매핑이 있었다면 이전 값은 대체됩니다.
- public void putAll(Map m): 이 맵에 지정된 맵의 모든 매핑을 복사합니다. 이 맵에 이미 있는 키의 경우, 이 맵의 매핑이 지정된 맵의 매핑으로 대체됩니다.
- public V remove(Object key): 지정된 키에 해당하는 매핑을 이 맵에서 제거합니다.
- public int size(): 이 맵의 키-값 매핑 수를 반환합니다.
- public Collection
values() : 이 맵에 포함된 값들의 컬렉션 뷰를 반환합니다. 이 컬렉션은 맵을 지원하므로 맵의 변경 사항이 컬렉션에 반영되고, 그 반대도 성립합니다.
Java 8에서 HashMap에는 많은 새로운 메소드가 도입되었습니다.
- public V computeIfAbsent(K key, Function mappingFunction): 지정된 키가 이미 값과 연결되어 있지 않거나(null에 매핑되어 있는 경우) 이 메소드는 주어진 매핑 함수를 사용하여 값을 계산하고 HashMap에 입력합니다.
- public V computeIfPresent(K key, BiFunction remappingFunction): 지정된 키에 대한 값이 존재하고 null이 아닌 경우, 현재 키와 매핑된 값에 대해 새 매핑을 계산하려고 시도합니다.
- public V compute(K key, BiFunction remappingFunction): 이 HashMap 메소드는 지정된 키와 현재 매핑된 값을 사용하여 매핑을 계산하려고 시도합니다.
- public void forEach(BiConsumer<? super K, ? super V> action): 이 메소드는 이 맵의 각 항목에 대해 지정된 동작을 수행합니다.
- public V getOrDefault(Object key, V defaultValue): 지정된 키에 대한 매핑이 없는 경우 get과 동일하지만 defaultValue가 반환됩니다.
- public V merge(K key, V value, BiFunction<? super V, ? super V, ? extends V> remappingFunction): 지정된 키가 이미 값과 연결되어 있지 않거나 null과 연결되어 있는 경우, 지정된 비 null 값과 연결합니다. 그렇지 않으면 지정된 리매핑 함수의 결과로 연결된 값으로 대체하거나 결과가 null인 경우 제거합니다.
- public V putIfAbsent(K key, V value): 지정된 키가 이미 값과 연결되어 있지 않은 경우 (또는 null에 매핑된 경우) 지정된 값과 연결하고 null을 반환하며, 그렇지 않으면 현재 값이 반환됩니다.
- public boolean remove(Object key, Object value): 지정된 키에 대한 항목을 지정된 값에만 매핑되어 있을 때에만 제거합니다.
- public boolean replace(K key, V oldValue, V newValue): 지정된 키에 대한 항목을 지정된 값에만 매핑되어 있을 때에만 대체합니다.
- public V replace(K key, V value): 지정된 키에 대한 항목을 현재 값에만 매핑되어 있을 때에만 대체합니다.
- public void replaceAll(BiFunction<? super K, ? super V, ? extends V> function): 각 항목의 값을 해당 항목에 대해 지정된 함수를 호출한 결과로 대체합니다.
자바 HashMap 예제
다음은 HashMap의 일반적으로 사용되는 메소드에 대한 간단한 자바 프로그램입니다.
package com.journaldev.examples;
import java.util.Collection;
import java.util.HashMap;
import java.util.Map;
import java.util.Map.Entry;
import java.util.Set;
public class HashMapExample {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("1", "1"); // put example
map.put("2", "2");
map.put("3", "3");
map.put("4", null); // null value
map.put(null, "100"); // null key
String value = map.get("3"); // get example
System.out.println("Key = 3, Value = " + value);
value = map.getOrDefault("5", "Default Value");
System.out.println("Key = 5, Value=" + value);
boolean keyExists = map.containsKey(null);
boolean valueExists = map.containsValue("100");
System.out.println("keyExists=" + keyExists + ", valueExists=" + valueExists);
Set<Entry<String, String>> entrySet = map.entrySet();
System.out.println(entrySet);
System.out.println("map size=" + map.size());
Map<String, String> map1 = new HashMap<>();
map1.putAll(map);
System.out.println("map1 mappings= " + map1);
String nullKeyValue = map1.remove(null);
System.out.println("map1 null key value = " + nullKeyValue);
System.out.println("map1 after removing null key = " + map1);
Set<String> keySet = map.keySet();
System.out.println("map keys = " + keySet);
Collection<String> values = map.values();
System.out.println("map values = " + values);
map.clear();
System.out.println("map is empty=" + map.isEmpty());
}
}
아래는 위의 자바 HashMap 예제 프로그램의 출력입니다.
Key = 3, Value = 3
Key = 5, Value=Default Value
keyExists=true, valueExists=true
[null=100, 1=1, 2=2, 3=3, 4=null]
map size=5
map1 mappings= {null=100, 1=1, 2=2, 3=3, 4=null}
map1 null key value = 100
map1 after removing null key = {1=1, 2=2, 3=3, 4=null}
map keys = [null, 1, 2, 3, 4]
map values = [100, 1, 2, 3, null]
map is empty=true
자바에서 HashMap은 어떻게 작동하나요?
Java에서의 HashMap은 매핑을 저장하기 위해 내부 클래스 Node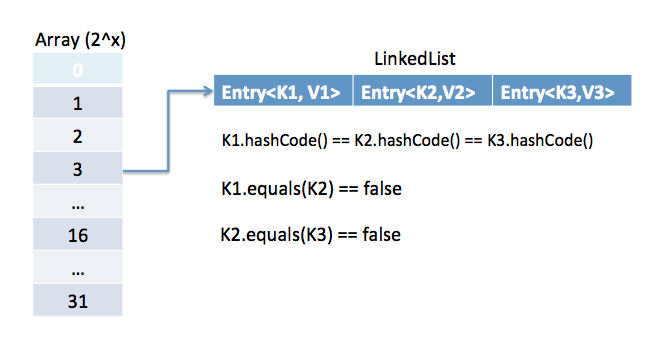 추천 독서: Java에서의 hashCode와 equals 메서드의 중요성
추천 독서: Java에서의 hashCode와 equals 메서드의 중요성
Java HashMap Load Factor
로드 팩터는 HashMap이 재해시되고 버킷 크기가 증가할 때 사용됩니다. 기본 버킷 또는 용량 값은 16이고 로드 팩터 값은 0.75입니다. 재해시하는 임계값은 용량과 로드 팩터를 곱하여 계산됩니다. 따라서 기본 임계값은 12가 됩니다. 따라서 HashMap에 12개 이상의 매핑이 있는 경우 재해시되고 빈의 수는 2의 다음 제곱으로 증가합니다. HashMap의 용량은 항상 2의 제곱입니다. 기본 로드 팩터 0.75는 공간과 시간 복잡성 사이의 좋은 균형을 제공합니다. 그러나 요구 사항에 따라 다른 값으로 설정할 수 있습니다. 공간을 절약하려면 값을 0.80이나 0.90으로 늘릴 수 있지만 그러면 get/put 작업에 더 많은 시간이 걸립니다.
Java HashMap keySet
Java HashMap keySet 메서드는 HashMap의 키에 대한 Set 뷰를 반환합니다. 이 Set 뷰는 HashMap에 의해 지원되며 HashMap의 변경 사항은 Set에 반영되고 그 반대도 마찬가지입니다. 아래는 HashMap keySet 예제와 맵에 의해 지원되지 않는 keySet을 얻는 방법을 보여주는 간단한 프로그램입니다.
package com.journaldev.examples;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Map;
import java.util.Set;
public class HashMapKeySetExample {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("1", "1");
map.put("2", "2");
map.put("3", "3");
Set<String> keySet = map.keySet();
System.out.println(keySet);
map.put("4", "4");
System.out.println(keySet); // keySet is backed by Map
keySet.remove("1");
System.out.println(map); // map is also modified
keySet = new HashSet<>(map.keySet()); // copies the key to new Set
map.put("5", "5");
System.out.println(keySet); // keySet is not modified
}
}
위 프로그램의 출력은 keySet이 맵에 의해 지원되는지를 명확히 보여줍니다.
[1, 2, 3]
[1, 2, 3, 4]
{2=2, 3=3, 4=4}
[2, 3, 4]
Java HashMap 값
Java HashMap 값 메소드는 맵 안의 값들의 컬렉션 뷰를 반환합니다. 이 컬렉션은 HashMap에 의해 지원되므로 HashMap에서의 변경 사항은 값 컬렉션에 반영되며 그 반대도 마찬가지입니다. 아래의 간단한 예제는 HashMap 값 컬렉션의 이러한 동작을 확인합니다.
package com.journaldev.examples;
import java.util.Collection;
import java.util.HashMap;
import java.util.Map;
public class HashMapValuesExample {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("1", "1");
map.put("2", "2");
map.put("3", null);
map.put("4", null);
map.put(null, "100");
Collection<String> values = map.values();
System.out.println("map values = " + values);
map.remove(null);
System.out.println("map values after removing null key = " + values);
map.put("5", "5");
System.out.println("map values after put = " + values);
System.out.println(map);
values.remove("1"); // changing values collection
System.out.println(map); // updates in map too
}
}
위 프로그램의 출력은 아래와 같습니다.
map values = [100, 1, 2, null, null]
map values after removing null key = [1, 2, null, null]
map values after put = [1, 2, null, null, 5]
{1=1, 2=2, 3=null, 4=null, 5=5}
{2=2, 3=null, 4=null, 5=5}
Java HashMap entrySet
Java HashMap entrySet 메소드는 매핑의 Set 뷰를 반환합니다. 이 entrySet은 HashMap에 의해 지원되므로 맵에서의 변경 사항은 entry set에 반영되고 그 반대도 마찬가지입니다. HashMap entrySet 예제를 위한 아래의 예제 프로그램을 살펴보세요.
package com.journaldev.examples;
import java.util.AbstractMap;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Map.Entry;
import java.util.Set;
public class HashMapEntrySetExample {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("1", "1");
map.put("2", null);
map.put(null, "100");
Set<Entry<String,String>> entrySet = map.entrySet();
Iterator<Entry<String, String>> iterator = entrySet.iterator();
Entry<String, String> next = null;
System.out.println("map before processing = "+map);
System.out.println("entrySet before processing = "+entrySet);
while(iterator.hasNext()){
next = iterator.next();
System.out.println("Processing on: "+next.getValue());
if(next.getKey() == null) iterator.remove();
}
System.out.println("map after processing = "+map);
System.out.println("entrySet after processing = "+entrySet);
Entry<String, String> simpleEntry = new AbstractMap.SimpleEntry<String, String>("1","1");
entrySet.remove(simpleEntry);
System.out.println("map after removing Entry = "+map);
System.out.println("entrySet after removing Entry = "+entrySet);
}
}
위 프로그램에 의해 생성된 출력은 아래와 같습니다.
map before processing = {null=100, 1=1, 2=null}
entrySet before processing = [null=100, 1=1, 2=null]
Processing on: 100
Processing on: 1
Processing on: null
map after processing = {1=1, 2=null}
entrySet after processing = [1=1, 2=null]
map after removing Entry = {2=null}
entrySet after removing Entry = [2=null]
Java HashMap putIfAbsent
A simple example for HashMap putIfAbsent method introduced in Java 8.
package com.journaldev.examples;
import java.util.HashMap;
import java.util.Map;
public class HashMapPutIfAbsentExample {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("1", "1");
map.put("2", null);
map.put(null, "100");
System.out.println("map before putIfAbsent = "+map);
String value = map.putIfAbsent("1", "4");
System.out.println("map after putIfAbsent = "+map);
System.out.println("putIfAbsent returns: "+value);
System.out.println("map before putIfAbsent = "+map);
value = map.putIfAbsent("3", "3");
System.out.println("map after putIfAbsent = "+map);
System.out.println("putIfAbsent returns: "+value);
}
}
위 프로그램의 출력은 다음과 같습니다;
map before putIfAbsent = {null=100, 1=1, 2=null}
map after putIfAbsent = {null=100, 1=1, 2=null}
putIfAbsent returns: 1
map before putIfAbsent = {null=100, 1=1, 2=null}
map after putIfAbsent = {null=100, 1=1, 2=null, 3=3}
putIfAbsent returns: null
Java HashMap forEach
HashMap forEach 메소드는 Java 8에서 도입되었습니다. 이 메소드는 맵의 각 항목에 대해 주어진 동작을 수행하는 데 매우 유용합니다. 모든 항목이 처리되거나 동작이 예외를 throw할 때까지 처리합니다.
package com.journaldev.examples;
import java.util.HashMap;
import java.util.Map;
import java.util.function.BiConsumer;
public class HashMapForEachExample {
public static void main(String[] args) {
Map map = new HashMap<>();
map.put("1", "1");
map.put("2", null);
map.put(null, "100");
BiConsumer action = new MyBiConsumer();
map.forEach(action);
//람다 표현식 예제
System.out.println("\nHashMap forEach lambda example\n");
map.forEach((k,v) -> {System.out.println("Key = "+k+", Value = "+v);});
}
}
class MyBiConsumer implements BiConsumer {
@Override
public void accept(String t, String u) {
System.out.println("Key = " + t);
System.out.println("Processing on value = " + u);
}
}
위의 HashMap forEach 예제 프로그램의 출력은 다음과 같습니다;
Key = null
Processing on value = 100
Key = 1
Processing on value = 1
Key = 2
Processing on value = null
HashMap forEach lambda example
Key = null, Value = 100
Key = 1, Value = 1
Key = 2, Value = null
Java HashMap replaceAll
HashMap replaceAll 메소드는 각 항목의 값을 주어진 함수를 호출하여 결과로 대체하는 데 사용할 수 있습니다. 이 메소드는 Java 8에서 추가되었으며 이 메소드의 인수에 람다 표현식을 사용할 수 있습니다.
package com.journaldev.examples;
import java.util.HashMap;
import java.util.Map;
import java.util.function.BiFunction;
public class HashMapReplaceAllExample {
public static void main(String[] args) {
Map map = new HashMap<>();
map.put("1", "1");
map.put("2", "2");
map.put(null, "100");
System.out.println("map before replaceAll = " + map);
BiFunction function = new MyBiFunction();
map.replaceAll(function);
System.out.println("map after replaceAll = " + map);
//람다 표현식을 사용한 replaceAll
map.replaceAll((k, v) -> {
if (k != null) return k + v;
else return v;});
System.out.println("map after replaceAll lambda expression = " + map);
}
}
class MyBiFunction implements BiFunction {
@Override
public String apply(String t, String u) {
if (t != null)
return t + u;
else
return u;
}
}
위의 HashMap replaceAll 프로그램의 출력은 다음과 같습니다;
map before replaceAll = {null=100, 1=1, 2=2}
map after replaceAll = {null=100, 1=11, 2=22}
map after replaceAll lambda example = {null=100, 1=111, 2=222}
Java HashMap computeIfAbsent
HashMap computeIfAbsent 메소드는 키가 맵에 없을 경우에만 값을 계산합니다. 값이 계산된 후에 값이 null이 아닌 경우에만 맵에 넣습니다.
package com.journaldev.examples;
import java.util.HashMap;
import java.util.Map;
import java.util.function.Function;
public class HashMapComputeIfAbsent {
public static void main(String[] args) {
Map map = new HashMap<>();
map.put("1", "10");
map.put("2", "20");
map.put(null, "100");
Function function = new MyFunction();
map.computeIfAbsent("3", function); //key not present
map.computeIfAbsent("2", function); //key already present
//람다 방식
map.computeIfAbsent("4", v -> {return v;});
map.computeIfAbsent("5", v -> {return null;}); //null value won't get inserted
System.out.println(map);
}
}
class MyFunction implements Function {
@Override
public String apply(String t) {
return t;
}
}
위의 프로그램의 출력은 다음과 같습니다;
{null=100, 1=10, 2=20, 3=3, 4=4}
Java HashMap computeIfPresent
Java HashMap computeIfPresent 메서드는 지정된 키가 존재하고 값이 널이 아닌 경우 값을 다시 계산합니다. 함수가 null을 반환하면 매핑이 제거됩니다.
package com.journaldev.examples;
import java.util.HashMap;
import java.util.Map;
import java.util.function.BiFunction;
public class HashMapComputeIfPresentExample {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("1", "10");
map.put("2", "20");
map.put(null, "100");
map.put("10", null);
System.out.println("map before computeIfPresent = " + map);
BiFunction<String, String, String> function = new MyBiFunction1();
for (String key : map.keySet()) {
map.computeIfPresent(key, function);
}
System.out.println("map after computeIfPresent = " + map);
map.computeIfPresent("1", (k,v) -> {return null;}); // mapping will be removed
System.out.println("map after computeIfPresent = " + map);
}
}
class MyBiFunction1 implements BiFunction<String, String, String> {
@Override
public String apply(String t, String u) {
return t + u;
}
}
HashMap computeIfPresent 예제의 출력은 다음과 같습니다;
map before computeIfPresent = {null=100, 1=10, 2=20, 10=null}
map after computeIfPresent = {null=null100, 1=110, 2=220, 10=null}
map after computeIfPresent = {null=null100, 2=220, 10=null}
Java HashMap compute
키와 값에 기반하여 모든 매핑에 함수를 적용하려면 compute 메서드를 사용해야 합니다. 이 메서드를 사용하고 매핑이 없는 경우 compute 함수에 대한 값은 null이 됩니다.
package com.journaldev.examples;
import java.util.HashMap;
import java.util.Map;
public class HashMapComputeExample {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("1", "1");
map.put("2", "2");
map.put(null, "10");
map.put("10", null);
System.out.println("map before compute = "+map);
for (String key : map.keySet()) {
map.compute(key, (k,v) -> {return k+v;});
}
map.compute("5", (k,v) -> {return k+v;}); //key not present, v = null
System.out.println("map after compute = "+map);
}
}
HashMap compute 예제의 출력은 다음과 같습니다;
map before compute = {null=10, 1=1, 2=2, 10=null}
map after compute = {null=null10, 1=11, 2=22, 5=5null, 10=10null}
Java HashMap merge
지정된 키가 존재하지 않거나 null과 연결된 경우 주어진 널이 아닌 값으로 연결합니다. 그렇지 않으면 주어진 재매핑 함수의 결과로 연결된 값을 바꾸거나 결과가 null인 경우 제거합니다.
package com.journaldev.examples;
import java.util.HashMap;
import java.util.Map;
import java.util.Map.Entry;
public class HashMapMergeExample {
public static void main(String[] args) {
Map map = new HashMap<>();
map.put("1", "1");
map.put("2", "2");
map.put(null, "10");
map.put("10", null);
for (Entry entry : map.entrySet()) {
String key = entry.getKey();
String value = entry.getValue();
//merge는 키 또는 값이 null인 경우 NullPointerException을 throw합니다.
if(key != null && value != null)
map.merge(entry.getKey(), entry.getValue(),
(k, v) -> {return k + v;});
}
System.out.println(map);
map.merge("5", "5", (k, v) -> {return k + v;}); // key not present
System.out.println(map);
map.merge("1", "1", (k, v) -> {return null;}); // method return null, so remove
System.out.println(map);
}
}
위 프로그램의 출력은 다음과 같습니다;
{null=10, 1=11, 2=22, 10=null}
{null=10, 1=11, 2=22, 5=5, 10=null}
{null=10, 2=22, 5=5, 10=null}
Java에서의 HashMap에 대한 설명은 여기까지입니다. 중요한 내용을 빠뜨리지 않았으면 좋겠습니다. 만약 이 글을 좋아하셨다면 다른 사람들과 공유해주세요. 참고문헌: API 문서
Source:
https://www.digitalocean.com/community/tutorials/java-hashmap