













Java Collections Framework은 자바 프로그래밍 언어의 핵심 API 중 하나입니다. 이는 자바 인터뷰 질문에 중요한 주제 중 하나입니다. 여기에는 인터뷰에서 도움이 되는 몇 가지 중요한 자바 컬렉션 인터뷰 질문과 답변이 나와 있습니다. 이 내용은 자바 프로그래밍에서의 14년 이상의 경험을 토대로 직접 작성되었습니다.
자바 컬렉션 인터뷰 질문
- 자바 8에서 컬렉션 관련 기능은 무엇입니까?
- 자바 컬렉션 프레임워크란 무엇이며, 컬렉션 프레임워크의 몇 가지 이점을 나열하십시오.
- 컬렉션 프레임워크에서 Generics의 이점은 무엇입니까?
- 자바 컬렉션 프레임워크의 기본 인터페이스는 무엇입니까?
- 컬렉션은 Cloneable 및 Serializable 인터페이스를 확장하지 않는 이유는 무엇입니까?
- 왜 Map 인터페이스는 Collection 인터페이스를 확장하지 않습니까?
- Iterator란 무엇입니까?
- Enumeration과 Iterator 인터페이스의 차이점은 무엇입니까?
- 컬렉션에 요소를 추가하는 Iterator.add()와 같은 메서드가 없는 이유는 무엇인가요?
- Iterator에는 커서를 이동하지 않고 다음 요소를 직접 가져오는 메서드가 없는 이유는 무엇인가요?
- Iterator와 ListIterator의 차이는 무엇인가요?
- 리스트를 반복하는 다른 방법은 무엇인가요?
- Iterator의 fail-fast 속성을 어떻게 이해하나요?
- fail-fast와 fail-safe의 차이는 무엇인가요?
- 컬렉션을 반복하는 동안 ConcurrentModificationException을 피하는 방법은 무엇인가요?
- Iterator 인터페이스의 구체적인 구현이 없는 이유는 무엇인가요?
- UnsupportedOperationException이란 무엇인가요?
- Java에서 HashMap은 어떻게 작동하나요?
- hashCode()와 equals() 메서드의 중요성은 무엇인가요?
- 어떤 클래스든지 Map 키로 사용할 수 있나요?
- Map 인터페이스에서 제공하는 다양한 Collection 뷰는 무엇인가요?
- HashMap과 Hashtable의 차이는 무엇인가요?
- HashMap과 TreeMap 중 어떤 것을 선택해야 할까요?
- ArrayList와 Vector의 유사점과 차이점은 무엇인가요?
- Array와 ArrayList의 차이점은 무엇이며, 언제 Array를 ArrayList 대신 사용하나요?
- ArrayList와 LinkedList의 차이점은 무엇인가요?
- 원소들에 대한 랜덤 액세스를 제공하는 컬렉션 클래스는 무엇인가요?
- EnumSet은 무엇인가요?
- 어떤 컬렉션 클래스가 스레드 안전한가요?
- 동시성 컬렉션 클래스란 무엇인가요?
- BlockingQueue는 무엇인가요?
- Queue와 Stack은 무엇이며, 그들의 차이점을 나열하세요.
- Collections 클래스는 무엇인가요?
- Comparable과 Comparator 인터페이스는 무엇인가요?
- Comparable과 Comparator 인터페이스의 차이점은 무엇인가요?
- 객체 목록을 어떻게 정렬할 수 있나요?
- 함수에 컬렉션을 인수로 전달할 때, 함수가 수정할 수 없도록 어떻게 할 수 있나요?
- 주어진 컬렉션에서 동기화된 컬렉션을 어떻게 생성할 수 있나요?
- 컬렉션 프레임워크에 구현된 일반적인 알고리즘은 무엇인가요?
- 빅오 표기법이란 무엇인가요? 몇 가지 예시를 들어주세요.
- Java Collections Framework와 관련된 최상의 관행은 무엇인가요?
- Java 우선순위 큐란 무엇인가요?
- 왜 코드를 다음과 같이 작성할 수 없을까요?
List<Number> numbers = new ArrayList<Integer>(); - 왜 제네릭 배열을 만들 수 없을까요? 또는 다음과 같이 코드를 작성할 수 없는 이유는 무엇인가요?
List<Integer>[] array = new ArrayList<Integer>[10];
Java Collections 인터뷰 질문과 답변
-
자바 8의 컬렉션 관련 기능은 무엇인가요?
자바 8에서는 컬렉션 API에 중요한 변경 사항이 있습니다. 일부 변경 사항은 다음과 같습니다:
- 자바 Stream API는 컬렉션 클래스에 대한 순차 및 병렬 처리를 지원합니다.
- Iterable 인터페이스는 forEach() 기본 메서드로 확장되어 컬렉션을 반복할 수 있습니다. 이는 람다 표현식과 함께 사용할 때 매우 유용합니다. 왜냐하면 해당 인수 Consumer가 함수 인터페이스이기 때문입니다.
- Iterator 인터페이스의
forEachRemaining(Consumer action)메서드, Map의replaceAll(),compute(),merge()메서드와 같은 기타 Collection API 개선 사항이 있습니다.
-
Java Collections Framework란 무엇인가요? Collections 프레임워크의 몇 가지 이점을 나열해 보세요.
모든 프로그래밍 언어에서는 컬렉션을 사용하며, 초기 자바 릴리스에는 몇 가지 컬렉션 클래스가 포함되어 있었습니다: Vector, Stack, Hashtable, Array. 그러나 더 넓은 범위와 사용을 고려하여 자바 1.2에서는 모든 컬렉션 인터페이스, 구현 및 알고리즘을 그룹화하는 Collections Framework가 도입되었습니다. 자바 컬렉션은 제네릭과 스레드 안전 작업을 위한 동시 컬렉션 클래스의 사용을 통해 긴 여정을 거쳤습니다. 또한 자바 동시 패키지에 있는 블로킹 인터페이스 및 이를 구현한 클래스도 포함되어 있습니다. Collections 프레임워크의 몇 가지 이점은 다음과 같습니다;
- 자체 컬렉션 클래스를 구현하는 대신 핵심 컬렉션 클래스를 사용함으로써 개발 노력을 줄일 수 있습니다.
- 잘 테스트된 컬렉션 프레임워크 클래스를 사용함으로써 코드 품질이 향상됩니다.
- JDK와 함께 제공되는 컬렉션 클래스를 사용함으로써 코드 유지 관리 노력을 줄일 수 있습니다.
- 재사용성과 상호 운용성
-
컬렉션 프레임워크에서 제네릭의 이점은 무엇입니까?
Java 1.5에서 제네릭이 도입되었으며 모든 컬렉션 인터페이스와 구현이 이를 많이 사용합니다. 제네릭을 사용하면 컬렉션이 포함할 수 있는 객체의 유형을 제공할 수 있으므로 다른 유형의 요소를 추가하려고하면 컴파일 시간 오류가 발생합니다. 이렇게하면 실행 중에 ClassCastException이 발생하는 것을 피할 수 있습니다. 또한 제네릭을 사용하면 캐스팅 및 instanceof 연산자를 사용할 필요가 없으므로 코드가 더 깔끔해집니다. 제네릭에 대한 더 나은 이해를 위해 Java 제네릭 튜토리얼을 권장합니다.
-
자바 컬렉션 프레임워크의 기본 인터페이스는 무엇인가요?
Collection은 컬렉션 계층구조의 루트입니다. 컬렉션은 요소라고 알려진 객체 그룹을 나타냅니다. 자바 플랫폼은이 인터페이스의 직접적인 구현을 제공하지 않습니다. Set은 중복 요소를 포함할 수 없는 컬렉션입니다. 이 인터페이스는 수학적인 집합 추상화를 모델링하며 카드 덱과 같은 세트를 나타내는 데 사용됩니다. List는 순서가 있는 컬렉션이며 중복 요소를 포함할 수 있습니다. 색인에서 어떤 요소든에 접근할 수 있습니다. 목록은 동적 길이의 배열과 유사합니다. Map은 키를 값에 매핑하는 객체입니다. 맵은 중복 키를 포함할 수 없습니다. 각 키는 최대 하나의 값에 매핑될 수 있습니다. 일부 다른 인터페이스는
Queue,Dequeue,Iterator,SortedSet,SortedMap및ListIterator입니다. -
Collection이 Cloneable 및 Serializable 인터페이스를 확장하지 않는 이유는 무엇인가요?
Collection interface specifies group of Objects known as elements. How the elements are maintained is left up to the concrete implementations of Collection. For example, some Collection implementations like List allow duplicate elements whereas other implementations like Set don't. A lot of the Collection implementations have a public clone method. However, it doesn't make sense to include it in all implementations of Collection. This is because Collection is an abstract representation. What matters is the implementation. The semantics and the implications of either cloning or serializing come into play when dealing with the actual implementation; so concrete implementation should decide how it should be cloned or serialized, or even if it can be cloned or serialized. So mandating cloning and serialization in all implementations is less flexible and more restrictive. The specific implementation should decide as to whether it can be cloned or serialized.
Although Map interface and its implementations are part of the Collections Framework, Map is not collections and collections are not Map. Hence it doesn't make sense for Map to extend Collection or vice versa. If Map extends Collection interface, then where are the elements? The map contains key-value pairs and it provides methods to retrieve the list of Keys or values as Collection but it doesn't fit into the "group of elements" paradigm.
The Iterator interface provides methods to iterate over any Collection. We can get iterator instance from a Collection using _iterator()_ method. Iterator takes the place of Enumeration in the Java Collections Framework. Iterators allow the caller to remove elements from the underlying collection during the iteration. Java Collection iterator provides a generic way for traversal through the elements of a collection and implements **[Iterator Design Pattern](/community/tutorials/iterator-design-pattern-java "Iterator Design Pattern in Java – Example Tutorial")**.
Enumeration is twice as fast as Iterator and uses very little memory. Enumeration is very basic and fits basic needs. But the Iterator is much safer as compared to Enumeration because it always denies other threads to modify the collection object which is being iterated by it. Iterator takes the place of Enumeration in the Java Collections Framework. Iterators allow the caller to remove elements from the underlying collection that is not possible with Enumeration. Iterator method names have been improved to make its functionality clear.
The semantics are unclear, given that the contract for Iterator makes no guarantees about the order of iteration. Note, however, that ListIterator does provide an add operation, as it does guarantee the order of the iteration.
It can be implemented on top of current Iterator interface but since its use will be rare, it doesn't make sense to include it in the interface that everyone has to implement.
- We can use Iterator to traverse Set and List collections whereas ListIterator can be used with Lists only.
- Iterator can traverse in forward direction only whereas ListIterator can be used to traverse in both the directions.
- ListIterator inherits from Iterator interface and comes with extra functionalities like adding an element, replacing an element, getting index position for previous and next elements.
We can iterate over a list in two different ways - using iterator and using for-each loop.
```
List strList = new ArrayList<>();
// for-each 루프 사용
for(String obj : strList){
System.out.println(obj);
}
// 이터레이터 사용
Iterator it = strList.iterator();
while(it.hasNext()){
String obj = it.next();
System.out.println(obj);
}
```
Using iterator is more thread-safe because it makes sure that if underlying list elements are modified, it will throw `ConcurrentModificationException`.
Iterator fail-fast property checks for any modification in the structure of the underlying collection everytime we try to get the next element. If there are any modifications found, it throws `ConcurrentModificationException`. All the implementations of Iterator in Collection classes are fail-fast by design except the concurrent collection classes like ConcurrentHashMap and CopyOnWriteArrayList.
Iterator fail-safe property work with the clone of underlying collection, hence it's not affected by any modification in the collection. By design, all the collection classes in `java.util` package are fail-fast whereas collection classes in `java.util.concurrent` are fail-safe. Fail-fast iterators throw ConcurrentModificationException whereas fail-safe iterator never throws ConcurrentModificationException. Check this post for [CopyOnWriteArrayList Example](/community/tutorials/copyonwritearraylist-java).
We can use concurrent collection classes to avoid `ConcurrentModificationException` while iterating over a collection, for example CopyOnWriteArrayList instead of ArrayList. Check this post for [ConcurrentHashMap Example](/community/tutorials/concurrenthashmap-in-java).
Iterator interface declare methods for iterating a collection but its implementation is responsibility of the Collection implementation classes. Every collection class that returns an iterator for traversing has its own Iterator implementation nested class. This allows collection classes to chose whether iterator is fail-fast or fail-safe. For example ArrayList iterator is fail-fast whereas CopyOnWriteArrayList iterator is fail-safe.
`UnsupportedOperationException` is the exception used to indicate that the operation is not supported. It's used extensively in [JDK](/community/tutorials/difference-jdk-vs-jre-vs-jvm "Difference between JDK, JRE and JVM in Java") classes, in collections framework `java.util.Collections.UnmodifiableCollection` throws this exception for all `add` and `remove` operations.
HashMap stores key-value pair in `Map.Entry` static nested class implementation. HashMap works on hashing algorithm and uses hashCode() and equals() method in `put` and `get` methods. When we call `put` method by passing key-value pair, HashMap uses Key hashCode() with hashing to find out the index to store the key-value pair. The Entry is stored in the LinkedList, so if there is an already existing entry, it uses equals() method to check if the passed key already exists, if yes it overwrites the value else it creates a new entry and stores this key-value Entry. When we call `get` method by passing Key, again it uses the hashCode() to find the index in the array and then use equals() method to find the correct Entry and return its value. The below image will explain these detail clearly. [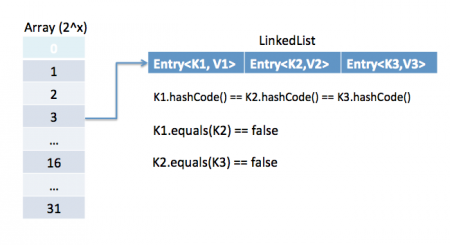](https://journaldev.nyc3.cdn.digitaloceanspaces.com/2013/01/java-hashmap-entry-impl.png) The other important things to know about HashMap are capacity, load factor, threshold resizing. HashMap initial default capacity is **16** and load factor is 0.75. The threshold is capacity multiplied by load factor and whenever we try to add an entry if map size is greater than the threshold, HashMap rehashes the contents of the map into a new array with a larger capacity. The capacity is always the power of 2, so if you know that you need to store a large number of key-value pairs, for example in caching data from the database, it's a good idea to initialize the HashMap with correct capacity and load factor.
HashMap uses the Key object hashCode() and equals() method to determine the index to put the key-value pair. These methods are also used when we try to get value from HashMap. If these methods are not implemented correctly, two different Key's might produce the same hashCode() and equals() output and in that case, rather than storing it at a different location, HashMap will consider the same and overwrite them. Similarly all the collection classes that doesn't store duplicate data use hashCode() and equals() to find duplicates, so it's very important to implement them correctly. The implementation of equals() and hashCode() should follow these rules.
- If `o1.equals(o2)`, then `o1.hashCode() == o2.hashCode()`should always be `true`.
- If `o1.hashCode() == o2.hashCode` is true, it doesn't mean that `o1.equals(o2)` will be `true`.
We can use any class as Map Key, however following points should be considered before using them.
- If the class overrides equals() method, it should also override hashCode() method.
- The class should follow the rules associated with equals() and hashCode() for all instances. Please refer earlier question for these rules.
- If a class field is not used in equals(), you should not use it in hashCode() method.
- Best practice for user defined key class is to make it immutable, so that hashCode() value can be cached for fast performance. Also immutable classes make sure that hashCode() and equals() will not change in future that will solve any issue with mutability. For example, let's say I have a class `MyKey` that I am using for the HashMap key.
```
// 전달된 MyKey 이름 인수는 equals() 및 hashCode()에 사용됩니다.
MyKey key = new MyKey("Pankaj"); //assume hashCode=1234
myHashMap.put(key, "Value");
// 아래 코드는 키의 hashCode() 및 equals()를 변경합니다.
// 그러나 위치는 변경되지 않습니다.
key.setName("Amit"); //assume new hashCode=7890
// 아래 코드는 키가 변경되었기 때문에 HashMap이 키를 찾으려고 할 때 null을 반환합니다.
// 저장된 위치와 동일한 인덱스에서 키를 찾으려고하지만 키가 변조되었기 때문에 일치하는 항목이 없습니다.
// 따라서 null을 반환합니다.
myHashMap.get(new MyKey("Pankaj"));
```
This is the reason why String and Integer are mostly used as HashMap keys.
Map interface provides three collection views:
1. **Set<K> keySet()**: Returns a Set view of the keys contained in this map. The set is backed by the map, so changes to the map are reflected in the set, and vice-versa. If the map is modified while an iteration over the set is in progress (except through the iterator's remove operation), the results of the iteration are undefined. The set supports element removal, which removes the corresponding mapping from the map, via the Iterator remove, Set.remove, removeAll, retainAll, and clear operations. It does not support the add or addAll operations.
2. **Collection<V> values()**: Returns a Collection view of the values contained in this map. The collection is backed by the map, so changes to the map are reflected in the collection, and vice-versa. If the map is modified while an iteration over the collection is in progress (except through the iterator's remove operation), the results of the iteration are undefined. The collection supports element removal, which removes the corresponding mapping from the map, via the Iterator remove, Collection.remove, removeAll, retainAll, and clear operations. It does not support the add or addAll operations.
3. **Set<Map.Entry<K, V>> entrySet()**: Returns a Set view of the mappings contained in this map. The set is backed by the map, so changes to the map are reflected in the set, and vice-versa. If the map is modified while an iteration over the set is in progress (except through the iterator's remove operation, or the setValue operation on a map entry returned by the iterator) the results of the iteration are undefined. The set supports element removal, which removes the corresponding mapping from the map, via the Iterator remove, Set.remove, removeAll, retainAll, and clear operations. It does not support the add or addAll operations.
HashMap and Hashtable both implements Map interface and looks similar, however, there is the following difference between HashMap and Hashtable.
1. HashMap allows null key and values whereas Hashtable doesn't allow null key and values.
2. Hashtable is synchronized but HashMap is not synchronized. So HashMap is better for single threaded environment, Hashtable is suitable for multi-threaded environment.
3. `LinkedHashMap` was introduced in Java 1.4 as a subclass of HashMap, so incase you want iteration order, you can easily switch from HashMap to LinkedHashMap but that is not the case with Hashtable whose iteration order is unpredictable.
4. HashMap provides Set of keys to iterate and hence it's fail-fast but Hashtable provides Enumeration of keys that doesn't support this feature.
5. Hashtable is considered to be legacy class and if you are looking for modifications of Map while iterating, you should use ConcurrentHashMap.
For inserting, deleting, and locating elements in a Map, the HashMap offers the best alternative. If, however, you need to traverse the keys in a sorted order, then TreeMap is your better alternative. Depending upon the size of your collection, it may be faster to add elements to a HashMap, then convert the map to a TreeMap for sorted key traversal.
ArrayList and Vector are similar classes in many ways.
1. Both are index based and backed up by an array internally.
2. Both maintains the order of insertion and we can get the elements in the order of insertion.
3. The iterator implementations of ArrayList and Vector both are fail-fast by design.
4. ArrayList and Vector both allows null values and random access to element using index number.
These are the differences between ArrayList and Vector.
1. Vector is synchronized whereas ArrayList is not synchronized. However if you are looking for modification of list while iterating, you should use CopyOnWriteArrayList.
2. ArrayList is faster than Vector because it doesn't have any overhead because of synchronization.
3. ArrayList is more versatile because we can get synchronized list or read-only list from it easily using Collections utility class.
Arrays can contain primitive or Objects whereas ArrayList can contain only Objects. Arrays are fixed-size whereas ArrayList size is dynamic. Arrays don't provide a lot of features like ArrayList, such as addAll, removeAll, iterator, etc. Although ArrayList is the obvious choice when we work on the list, there are a few times when an array is good to use.
- If the size of list is fixed and mostly used to store and traverse them.
- For list of primitive data types, although Collections use autoboxing to reduce the coding effort but still it makes them slow when working on fixed size primitive data types.
- If you are working on fixed multi-dimensional situation, using \[\]\[\] is far more easier than List<List<>>
ArrayList and LinkedList both implement List interface but there are some differences between them.
1. ArrayList is an index based data structure backed by Array, so it provides random access to its elements with performance as O(1) but LinkedList stores data as list of nodes where every node is linked to its previous and next node. So even though there is a method to get the element using index, internally it traverse from start to reach at the index node and then return the element, so performance is O(n) that is slower than ArrayList.
2. Insertion, addition or removal of an element is faster in LinkedList compared to ArrayList because there is no concept of resizing array or updating index when element is added in middle.
3. LinkedList consumes more memory than ArrayList because every node in LinkedList stores reference of previous and next elements.
ArrayList, HashMap, TreeMap, Hashtable, and Vector classes provide random access to its elements. Download [java collections pdf](https://journaldev.nyc3.cdn.digitaloceanspaces.com/2013/01/java-collections-framework.pdf) for more information.
`java.util.EnumSet` is Set implementation to use with enum types. All of the elements in an enum set must come from a single enum type that is specified, explicitly or implicitly, when the set is created. EnumSet is not synchronized and null elements are not allowed. It also provides some useful methods like copyOf(Collection c), of(E first, E… rest) and complementOf(EnumSet s). Check this post for [java enum tutorial](/community/tutorials/java-enum).
Vector, Hashtable, Properties and Stack are synchronized classes, so they are thread-safe and can be used in multi-threaded environment. Java 1.5 Concurrent API included some collection classes that allows modification of collection while iteration because they work on the clone of the collection, so they are safe to use in multi-threaded environment.
Java 1.5 Concurrent package (`java.util.concurrent`) contains thread-safe collection classes that allow collections to be modified while iterating. By design Iterator implementation in `java.util` packages are fail-fast and throws ConcurrentModificationException. But Iterator implementation in `java.util.concurrent` packages are fail-safe and we can modify the collection while iterating. Some of these classes are `CopyOnWriteArrayList`, `ConcurrentHashMap`, `CopyOnWriteArraySet`.
Read these posts to learn about them in more detail.
- [Avoid ConcurrentModificationException](/community/tutorials/java-util-concurrentmodificationexception)
- [CopyOnWriteArrayList Example](/community/tutorials/copyonwritearraylist-java)
- [HashMap vs ConcurrentHashMap](/community/tutorials/concurrenthashmap-in-java)
`java.util.concurrent.BlockingQueue` is a Queue that supports operations that wait for the queue to become non-empty when retrieving and removing an element, and wait for space to become available in the queue when adding an element. BlockingQueue interface is part of the java collections framework and it’s primarily used for implementing the producer-consumer problem. We don’t need to worry about waiting for the space to be available for producer or object to be available for consumers in BlockingQueue as it’s handled by implementation classes of BlockingQueue. Java provides several BlockingQueue implementations such as ArrayBlockingQueue, LinkedBlockingQueue, PriorityBlockingQueue, SynchronousQueue, etc. Check this post for use of BlockingQueue for [producer-consumer problem](/community/tutorials/java-blockingqueue-example).
Both Queue and Stack are used to store data before processing them. `java.util.Queue` is an interface whose implementation classes are present in java concurrent package. Queue allows retrieval of element in First-In-First-Out (FIFO) order but it's not always the case. There is also Deque interface that allows elements to be retrieved from both end of the queue. The stack is similar to queue except that it allows elements to be retrieved in Last-In-First-Out (LIFO) order. Stack is a class that extends Vector whereas Queue is an interface.
`java.util.Collections` is a utility class consists exclusively of static methods that operate on or return collections. It contains polymorphic algorithms that operate on collections, “wrappers”, which return a new collection backed by a specified collection, and a few other odds and ends. This class contains methods for collection framework algorithms, such as binary search, sorting, shuffling, reverse, etc.
Java provides a Comparable interface which should be implemented by any custom class if we want to use Arrays or Collections sorting methods. The comparable interface has a compareTo(T obj) method which is used by sorting methods. We should override this method in such a way that it returns a negative integer, zero, or a positive integer if “this” object is less than, equal to, or greater than the object passed as an argument. But, in most real-life scenarios, we want sorting based on different parameters. For example, as a CEO, I would like to sort the employees based on Salary, an HR would like to sort them based on age. This is the situation where we need to use `Comparator` interface because `Comparable.compareTo(Object o)` method implementation can sort based on one field only and we can’t choose the field on which we want to sort the Object. Comparator interface `compare(Object o1, Object o2)` method need to be implemented that takes two Object argument, it should be implemented in such a way that it returns negative int if the first argument is less than the second one and returns zero if they are equal and positive int if the first argument is greater than the second one. Check this post for use of Comparable and Comparator interface to [sort objects](/community/tutorials/comparable-and-comparator-in-java-example).
Comparable and Comparator interfaces are used to sort collection or array of objects. Comparable interface is used to provide the natural sorting of objects and we can use it to provide sorting based on single logic. Comparator interface is used to provide different algorithms for sorting and we can choose the comparator we want to use to sort the given collection of objects.
If we need to sort an array of Objects, we can use `Arrays.sort()`. If we need to sort a list of objects, we can use `Collections.sort()`. Both these classes have overloaded sort() methods for natural sorting (using Comparable) or sorting based on criteria (using Comparator). Collections internally uses Arrays sorting method, so both of them have same performance except that Collections take sometime to convert list to array.
We can create a read-only collection using `Collections.unmodifiableCollection(Collection c)` method before passing it as argument, this will make sure that any operation to change the collection will throw `UnsupportedOperationException`.
We can use `Collections.synchronizedCollection(Collection c)` to get a synchronized (thread-safe) collection backed by the specified collection.
Java Collections Framework provides algorithm implementations that are commonly used such as sorting and searching. Collections class contain these method implementations. Most of these algorithms work on List but some of them are applicable for all kinds of collections. Some of them are sorting, searching, shuffling, min-max values.
The Big-O notation describes the performance of an algorithm in terms of the number of elements in a data structure. Since Collection classes are data structures, we usually tend to use Big-O notation to chose the collection implementation to use based on time, memory and performance. Example 1: ArrayList `get(index i)` is a constant-time operation and doesn't depend on the number of elements in the list. So its performance in Big-O notation is O(1). Example 2: A linear search on array or list performance is O(n) because we need to search through entire list of elements to find the element.
- Chosing the right type of collection based on the need, for example if size is fixed, we might want to use Array over ArrayList. If we have to iterate over the Map in order of insertion, we need to use LinkedHashMap. If we don't want duplicates, we should use Set.
- Some collection classes allows to specify the initial capacity, so if we have an estimate of number of elements we will store, we can use it to avoid rehashing or resizing.
- Write program in terms of interfaces not implementations, it allows us to change the implementation easily at later point of time.
- Always use Generics for type-safety and avoid ClassCastException at runtime.
- Use immutable classes provided by JDK as key in Map to avoid implementation of hashCode() and equals() for our custom class.
- Use Collections utility class as much as possible for algorithms or to get read-only, synchronized or empty collections rather than writing own implementation. It will enhance code-reuse with greater stability and low maintainability.
PriorityQueue is an unbounded queue based on a priority heap and the elements are ordered in their natural order or we can provide [Comparator](/community/tutorials/comparable-and-comparator-in-java-example) for ordering at the time of creation. PriorityQueue doesn't allow null values and we can't add any object that doesn't provide natural ordering or we don't have any comparator for them for ordering. Java PriorityQueue is not [thread-safe](/community/tutorials/thread-safety-in-java) and provided O(log(n)) time for enqueing and dequeing operations. Check this post for [java priority queue example](/community/tutorials/java-priority-queue-priorityqueue-example "Java Priority Queue (PriorityQueue) Example").
Generics doesn't support sub-typing because it will cause issues in achieving type safety. That's why List<T> is not considered as a subtype of List<S> where S is the super-type of T. To understanding why it's not allowed, let's see what could have happened if it has been supported.
```
List<Long> listLong = new ArrayList<Long>();
listLong.add(Long.valueOf(10));
List<Number> listNumbers = listLong; // compiler error
listNumbers.add(Double.valueOf(1.23));
```
As you can see from above code that IF generics would have been supporting sub-typing, we could have easily add a Double to the list of Long that would have caused `ClassCastException` at runtime while traversing the list of Long.
We are not allowed to create generic arrays because array carry type information of its elements at runtime. This information is used at runtime to throw `ArrayStoreException` if elements type doesn't match to the defined type. Since generics type information gets erased at compile time by Type Erasure, the array store check would have been passed where it should have failed. Let's understand this with a simple example code.
```
List<Integer>[] intList = new List<Integer>[5]; // compile error
Object[] objArray = intList;
List<Double> doubleList = new ArrayList<Double>();
doubleList.add(Double.valueOf(1.23));
objArray[0] = doubleList; // this should fail but it would pass because at runtime intList and doubleList both are just List
```
Arrays are covariant by nature i.e S\[\] is a subtype of T\[\] whenever S is a subtype of T but generics doesn't support covariance or sub-typing as we saw in the last question. So if we would have been allowed to create generic arrays, because of type erasure we would not get an array store exception even though both types are not related. To know more about Generics, read **[Java Generics Tutorial](/community/tutorials/java-generics-example-method-class-interface)**.
I will keep on adding more questions on java collections framework as and when I found them, if you found it useful please share it with others too, it motivates me in writing more like these. 🙂 Please let me know if I have missed any important question, I will include that to list.
Source:
https://www.digitalocean.com/community/tutorials/java-collections-interview-questions-and-answers