













Elasticsearch란?
Elasticsearch는 Apache Lucene 검색 라이브러리 위에 구축된 고도로 확장 가능하고 분산 검색 및 분석 엔진입니다. 구조화된, 반구조화된, 비구조화된 대량의 데이터를 처리하도록 설계되어 있어 검색 엔진, 로그 분석, 이커머스, 보안 분석 등 다양한 사용 사례에 적합합니다.
Elasticsearch는 클러스터 내의 여러 노드에 걸쳐 대량의 데이터를 저장하고 처리할 수 있는 분산 아키텍처를 사용합니다. 데이터는 확장성과 내결함성을 향상시키기 위해 노드에 걸쳐 분산된 샤드에 인덱싱되고 저장됩니다. Elasticsearch는 실시간 검색 및 분석을 지원하므로 사용자는 거의 실시간으로 데이터를 쿼리하고 분석할 수 있습니다.
Elasticsearch의 핵심 기능 중 하나는 강력한 검색 기능입니다. 전문 검색, 지리 공간 검색 등 다양한 검색 쿼리를 지원합니다. 또한 집계, 메트릭, 데이터 시각화와 같은 고급 분석 기능도 지원합니다.
Elasticsearch는 일반적으로 Logstash를 데이터 수집 및 처리용으로, Kibana를 데이터 시각화 및 분석용으로 함께 사용됩니다. 이러한 도구들은 함께 다양한 애플리케이션과 사용 사례를 위한 포괄적인 검색 및 분석 솔루션을 제공합니다.
Apache Lucene이란?
Apache Lucene은 강력한 텍스트 검색 및 인덱싱 기능을 제공하는 오픈 소스 검색 라이브러리입니다. 개발자와 기관에 의해 검색 애플리케이션을 구축하는 데 널리 사용되며, 검색 엔진부터 이커머스 플랫폼에 이르기까지 다양합니다.
Lucene는 문서의 텍스트 내용을 인덱싱하고 검색이 효율적으로 이루어질 수 있는 구조화된 형식으로 인덱스를 저장하는 방식으로 작동합니다. 인덱스는 용어와 해당 용어를 포함하는 문서 간의 매핑을 제공하는 역 목록의 시퀀스로 구성됩니다. 검색 쿼리가 제출되면 Lucene는 인덱스를 사용하여 쿼리와 일치하는 문서를 신속하게 검색합니다.
검색 및 인덱싱 기능뿐만 아니라 Lucene는 퍼지 검색 및 공간 검색을 지원하는 등의 고급 기능을 제공합니다. 또한 검색 결과를 강조 표시하고 관련성에 따라 검색 결과를 순위 매기는 도구도 제공합니다.
Lucene는 Elasticsearch를 포함한 다양한 기관과 프로젝트에서 사용하고 있습니다. 풍부한 기능, 유연성 및 확장성으로 인해 다양한 종류의 검색 애플리케이션을 구축하는 데 인기 있는 선택입니다.
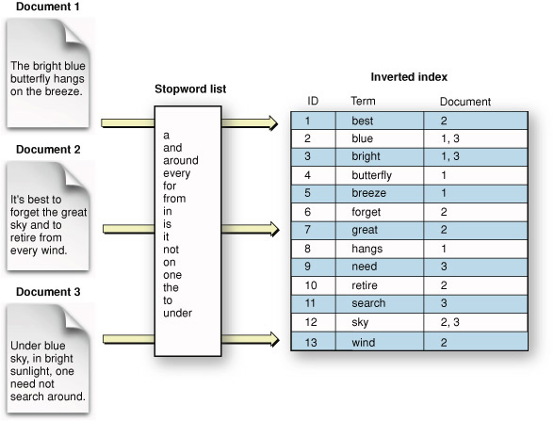
역 인덱스란 무엇인가?
Lucene의 역 인덱스는 문서 컬렉션에서 텍스트 데이터를 효율적으로 검색하고 검색하는 데 사용되는 데이터 구조입니다. 역 인덱스는 Lucene의 중심 특징으로, 인덱스를 구성하는 용어와 해당 용어를 포함하는 문서를 저장하는 데 사용됩니다.
역색인은 다른 검색 전략에 비해 여러 가지 이점을 제공합니다. 첫째, 검색어를 기반으로 문서를 빠르고 효율적으로 검색할 수 있습니다. 둘째, 많은 양의 텍스트 데이터를 처리할 수 있어 많은 양의 문서 컬렉션을 가진 사용 사례에 적합합니다. 마지막으로, 퍼지 일치와 동그라미 등과 같은 다양한 고급 검색 기능을 지원하므로 검색 결과의 정확성과 관련성을 향상시킬 수 있습니다.
왜 Elasticsearch인가?
엘라스틱서치가 검색 및 분석 애플리케이션 구축에 인기 있는 선택지인 몇 가지 이유가 있습니다.
쉬운 확장(분산형): 엘라스틱서치는 기본적으로 수평으로 확장되도록 설계되었습니다. 용량이 필요할 때마다 노드를 추가하고 클러스터가 추가 하드웨어를 활용하도록 자동으로 재구성되도록 합니다.
한 서버는 하나 이상의 인덱스 또는 인덱스의 일부를 보유할 수 있으며 새 노드가 클러스터에 추가될 때마다 파티에 추가되는 것입니다. 이러한 각 인덱스 또는 그 일부를 샤드라고 하며 엘라스틱서치 샤드는 클러스터 내에서 매우 쉽게 이동할 수 있습니다.
모든 것이 한 번의 JSON 호출 거리에 있음(RESTful API): 엘라스틱서치는 API 기반입니다. 거의 모든 작업을 JSON 및 HTTP를 사용하는 간단한 RESTful API로 수행할 수 있습니다. 응답은 항상 JSON 형식입니다.
루씨네 파워 언릴레시드: 엘라스틱서치는 내부적으로 루씨를 사용하여 최첨단 분산 검색 및 분석 기능을 구축합니다. 루씨는 안정적이고 검증된 기술로서 끊임없이 더 많은 기능과 모범 사례를 추가하고 있으므로 엘라스틱서치를 구동하는 기본 엔진으로 루씨를 갖추고 있습니다.
우수한 쿼리 DSL: REST API는 매우 복잡하고 강력한 쿼리 DSL을 노출시키며 사용하기 매우 쉽습니다. 모든 쿼리는 실제로 모든 유형의 쿼리 또는 여러 쿼리를 결합할 수 있는 JSON 개체입니다. 필터링된 쿼리를 사용하여 일부 쿼리를 루씨 필터로 표현하면 캐싱을 활용하여 일반적인 쿼리나 재사용할 수 있는 부분이 있는 복잡한 쿼리를 빠르게 처리할 수 있습니다.
멀티 테넌시: 여러 인덱스를 하나의 엘라스틱서치 설치 – 노드 또는 클러스터에 저장할 수 있습니다. 좋은 점은 하나의 간단한 쿼리로 여러 인덱스를 쿼리할 수 있다는 것입니다.
고급 검색 기능 지원(전문 검색): 엘라스틱서치는 내부적으로 루씨를 사용하여 오픈 소스 제품 중 가장 강력한 전문 검색 기능을 제공합니다. 검색은 다국어 지원, 강력한 쿼리 언어, 지리적 위치 지원, 상황에 맞는 검색 제안, 자동 완성 및 검색 요약을 제공합니다. 필터 및 점수 계산기에 스크립트 지원.
구성 가능하고 확장 가능: 엘라스틱서치가 실행 중인 동안 많은 구성을 변경할 수 있지만 일부는 다시 시작(그리고 일부 경우 재인덱싱)이 필요합니다. 대부분의 구성은 REST API를 사용하여 변경할 수 있습니다.
문서 지향: 복잡한 현실 세계 개체를 구조화된 JSON 문서로 Elasticsearch에 저장합니다. 모든 필드는 기본적으로 색인화되며, 모든 인덱스는 단일 쿼리에서 결과를 순식간에 반환할 수 있습니다.
스키마 프리: Elasticsearch를 사용하면 쉽게 시작할 수 있습니다. JSON 문서를 보내면 데이터 구조를 자동으로 감지하고 데이터를 색인화하여 검색 가능하게 만듭니다.
충돌 관리: 필요한 경우 낙관적 버전 관리를 사용하여 다중 프로세스에서 발생하는 충돌로 인해 데이터가 손실되지 않도록 보장할 수 있습니다.
능동적인 커뮤니티: 커뮤니티는 좋은 도구와 플러그인을 개발하는 것 외에도 매우 도움이 되며 지원적입니다. 전반적인 분위기는 훌륭하며, 이는 OSS 프로젝트의 중요한 지표입니다. 현재 커뮤니티 멤버들이 쓰고 있는 책들도 있으며, 여러 블로그 게시물들을 통해 경험과 지식을 공유하고 있습니다.
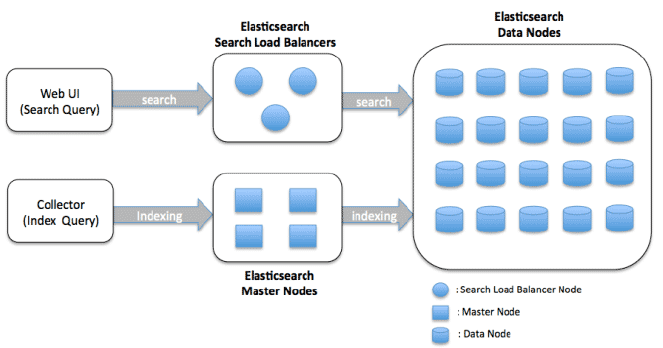
Elasticsearch 아키텍처
Elasticsearch 아키텍처의 주요 구성 요소는 다음과 같습니다:
노드: 노드는 Elasticsearch의 인스턴스로서 데이터를 저장하고 검색 및 색인화 기능을 제공합니다. 노드는 마스터 노드 또는 데이터 노드 또는 둘 다로 구성할 수 있습니다. 마스터 노드는 클러스터 전체 관리를 담당하며, 데이터 노드는 데이터를 저장하고 검색 작업을 수행합니다.
클러스터: 클러스터는 데이터를 저장하고 처리하기 위해 함께 작동하는 하나 이상의 노드 그룹입니다. 클러스터는 여러 인덱스(문서의 컬렉션)와 샤드(여러 노드에 데이터를 분산하는 방법)를 포함할 수 있습니다.
색인: 색인은 유사한 구조를 공유하는 문서들의 모음입니다. 각 문서는 JSON 객체로 표현되며, 한 개 이상의 필드를 포함합니다. Elasticsearch는 기본적으로 모든 필드를 색인화하여 데이터 검색 및 분석을 쉽게 할 수 있습니다.
shard: 색인은 여러 개의 shard로 나뉠 수 있으며, 이는 색인의 더 작은 부분들입니다. sharding은 데이터의 병렬 처리와 여러 노드에 걸친 분산 저장을 가능하게 합니다.
레플리카: Elasticsearch는 각 shard의 레플리카를 생성하여 장애 tolerance와 높은 가용성을 제공할 수 있습니다. 레플리카는 원본 shard의 사본으로, 다른 노드에 위치할 수 있습니다.
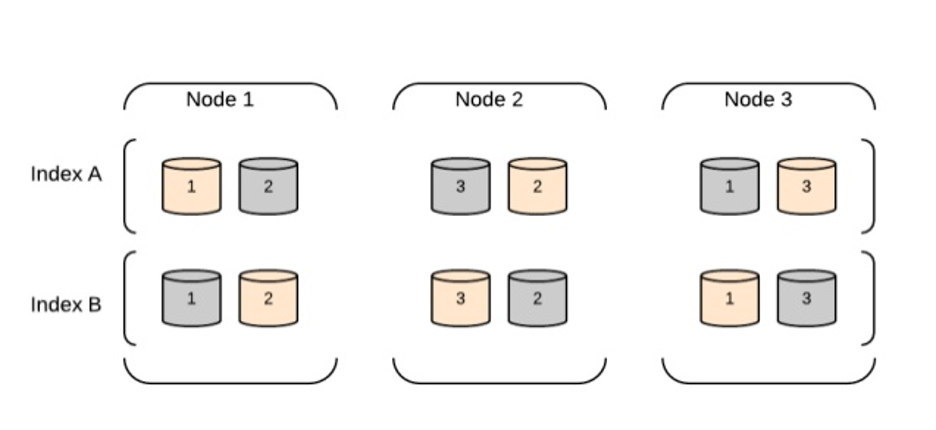
데이터 노드 클러스터 아키텍처
데이터 노드는 데이터 저장과 색인화, 그리고 검색 및 집계 연산을 수행하는 역할을 합니다. 이 아키텍처는 확장 가능하고 분산된 설계로, 클러스터에 노드를 추가하여 수평 확장이 가능합니다.
Elasticsearch 데이터 노드 클러스터 아키텍처의 주요 구성 요소는 다음과 같습니다:
데이터 노드: 노드는 데이터를 저장하고 검색 및 색인 기능을 제공하는 Elasticsearch의 인스턴스입니다. 데이터 노드 클러스터에서 각 노드는 색인 데이터의 일부를 저장하고 해당 데이터에 대한 검색 쿼리를 처리하는 역할을 합니다.
클러스터 상태: 클러스터 상태는 클러스터에 대한 정보를 포함하는 데이터 구조로, 노드 목록, 색인, shard 및 그들의 위치를 포함합니다. 마스터 노드는 클러스터 상태를 유지하고 클러스터의 모든 다른 노드에 이를 분산시키는 역할을 합니다.
발견 및 전송: Elasticsearch 클러스터의 노드들은 서로 두 가지 프로토콜을 사용하여 통신합니다: 발견 및 전송입니다. 발견 프로토콜은 클러스터에 새로 참여하거나 클러스터에서 떠난 노드를 발견하는 데 책임이 있습니다. 전송 프로토콜은 노드 간에 데이터를 보내고 받는 데 책임이 있습니다.
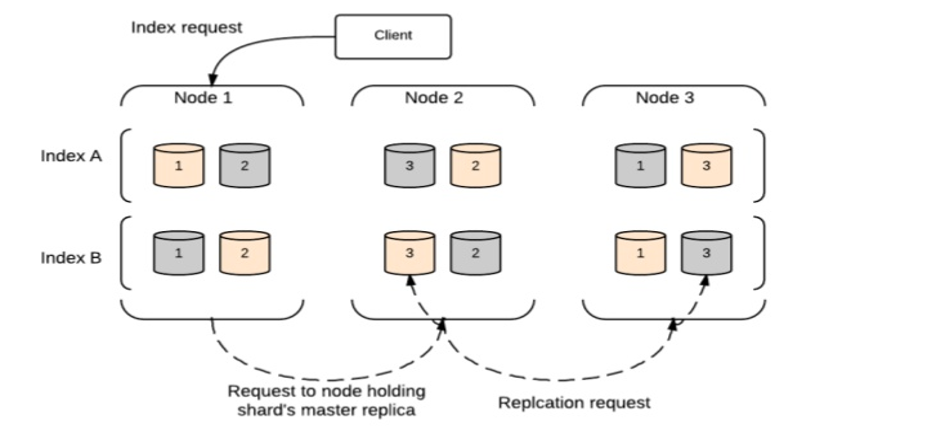
인덱스 요청
인덱스 요청은 Elasticsearch에서 다음과 같은 블록 다이어그램으로 실행됩니다.
Elasticsearch를 누가 사용하나요?
Elasticsearch를 사용하는 몇 명의 회사 및 기관:
넷플릭스: 넷플릭스는 Elasticsearch를 사용하여 검색 및 추천 엔진을 구동하여 사용자가 빠르게 시청할 콘텐츠를 찾을 수 있게 합니다.
GitHub: GitHub는 Elasticsearch를 사용하여 코드 저장소, 문제 및 풀 요청에 걸쳐 빠르고 효율적인 검색 기능을 제공합니다.
우버: Uber는 Elasticsearch를 사용하여 실시간 분석 플랫폼을 구동하여 실시간으로 데이터를 추적하고 분석할 수 있습니다.
위키백과: 위키백과는 Elasticsearch를 사용하여 검색 엔진을 구동하고 사용자에게 빠르고 정확한 검색 결과를 제공합니다.
Source:
https://dzone.com/articles/introduction-to-elasticsearch-1