













소개
모든 컴퓨터 시스템은 적절한 관리와 모니터링을 통해 혜택을 받습니다. 시스템이 어떻게 작동하는지 주시하는 것은 문제를 발견하고 빠르게 해결하는 데 도움이 됩니다.
이러한 목적으로 만들어진 다양한 명령 줄 유틸리티가 있습니다. 이 가이드에서는 툴박스에 가장 유용한 응용 프로그램 중 일부를 소개합니다.
전제 조건
이 가이드를 따라하기 위해 Linux 기반 운영 체제가 실행되는 컴퓨터에 액세스해야 합니다. 이는 SSH로 연결한 가상 사설 서버이거나 로컬 머신일 수 있습니다. 이 튜토리얼은 Ubuntu 20.04를 실행하는 Linux 서버를 기반으로 하여 검증되었지만, 제시된 예제는 Linux 배포판의 모든 버전에서 작동할 것으로 예상됩니다.
이 가이드를 따라하기 위해 원격 서버를 사용할 계획이라면, 먼저 초기 서버 설정 가이드를 완료하는 것이 좋습니다. 이렇게 하면 비록 루트가 아닌 sudo 권한을 가진 사용자와 UFW로 구성된 방화벽이 있는 안전한 서버 환경이 구성되어 Linux 기술을 익히는 데 사용할 수 있습니다.
단계 1 – Linux에서 실행 중인 프로세스 보기 방법
서버에서 실행 중인 모든 프로세스를 볼 수 있습니다. 다음과 같이 top 명령을 사용하면 됩니다:
Outputtop - 15:14:40 up 46 min, 1 user, load average: 0.00, 0.01, 0.05
Tasks: 56 total, 1 running, 55 sleeping, 0 stopped, 0 zombie
Cpu(s): 0.0%us, 0.0%sy, 0.0%ni,100.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 1019600k total, 316576k used, 703024k free, 7652k buffers
Swap: 0k total, 0k used, 0k free, 258976k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1 root 20 0 24188 2120 1300 S 0.0 0.2 0:00.56 init
2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd
3 root 20 0 0 0 0 S 0.0 0.0 0:00.07 ksoftirqd/0
6 root RT 0 0 0 0 S 0.0 0.0 0:00.00 migration/0
7 root RT 0 0 0 0 S 0.0 0.0 0:00.03 watchdog/0
8 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 cpuset
9 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 khelper
10 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kdevtmpfs
출력의 처음 여러 줄은 CPU/메모리 부하 및 실행 중인 작업의 총 수와 같은 시스템 통계를 제공합니다.
실행 중인 프로세스가 1개 있고 CPU 사이클을 활발하게 사용하지 않기 때문에 잠자고 있는 것으로 간주되는 55개의 프로세스가 있음을 볼 수 있습니다.
표시된 출력의 나머지 부분에는 실행 중인 프로세스와 그 사용 통계가 표시됩니다. 기본적으로 top은 이러한 것들을 CPU 사용량에 따라 자동으로 정렬하므로 가장 바쁜 프로세스를 먼저 볼 수 있습니다. top은 표준 키 조합인 Ctrl+C를 사용하여 실행 중인 프로세스를 종료할 때까지 셸에서 계속 실행됩니다. 이것은 프로세스가 원활하게 중지할 수 있는 경우 kill 신호를 보냅니다.
htop이라는 향상된 버전의 top이 대부분의 패키지 저장소에서 사용할 수 있습니다. Ubuntu 20.04에서는 다음과 같이 설치할 수 있습니다:
그 후 htop 명령을 사용할 수 있게 됩니다:
Output Mem[||||||||||| 49/995MB] Load average: 0.00 0.03 0.05
CPU[ 0.0%] Tasks: 21, 3 thr; 1 running
Swp[ 0/0MB] Uptime: 00:58:11
PID USER PRI NI VIRT RES SHR S CPU% MEM% TIME+ Command
1259 root 20 0 25660 1880 1368 R 0.0 0.2 0:00.06 htop
1 root 20 0 24188 2120 1300 S 0.0 0.2 0:00.56 /sbin/init
311 root 20 0 17224 636 440 S 0.0 0.1 0:00.07 upstart-udev-brid
314 root 20 0 21592 1280 760 S 0.0 0.1 0:00.06 /sbin/udevd --dae
389 messagebu 20 0 23808 688 444 S 0.0 0.1 0:00.01 dbus-daemon --sys
407 syslog 20 0 243M 1404 1080 S 0.0 0.1 0:00.02 rsyslogd -c5
408 syslog 20 0 243M 1404 1080 S 0.0 0.1 0:00.00 rsyslogd -c5
409 syslog 20 0 243M 1404 1080 S 0.0 0.1 0:00.00 rsyslogd -c5
406 syslog 20 0 243M 1404 1080 S 0.0 0.1 0:00.04 rsyslogd -c5
553 root 20 0 15180 400 204 S 0.0 0.0 0:00.01 upstart-socket-br
htop은 여러 CPU 스레드의 시각화를 더 잘 제공하며, 현대적인 터미널에서의 색상 지원을 더 잘 인식하고, 다른 정렬 옵션 등을 제공합니다. top과 달리 기본적으로 항상 설치되어 있지는 않지만, 대체 가능한 도구로 간주될 수 있습니다. top과 마찬가지로 htop을 종료하려면 Ctrl+C를 누르면 됩니다.
다음은 htop을 더 효과적으로 사용하는 데 도움이 되는 몇 가지 키보드 단축키입니다:
- M: Sort processes by memory usage
- P: Sort processes by processor usage
- ?: 도움말에 접근
- k: Kill current/tagged process
- F2: htop 설정. 여기서 디스플레이 옵션을 선택할 수 있습니다.
- /:: 프로세스 검색
도움말이나 설정을 통해 액세스할 수 있는 많은 다른 옵션이 있습니다. 이것들은 htop의 기능을 탐색하는 데 첫 번째로 해야 할 일입니다. 다음 단계에서는 네트워크 대역폭을 모니터링하는 방법을 배우게 됩니다.
단계 2 – 네트워크 대역폭 모니터링 방법
네트워크 연결이 과다 사용되는 것으로 보이고 어떤 애플리케이션이 원인인지 확실하지 않은 경우, nethogs라는 프로그램을 사용하면 좋습니다.
Ubuntu에서는 다음 명령으로 nethogs를 설치할 수 있습니다:
이후, nethogs 명령을 사용할 수 있게 됩니다:
OutputNetHogs version 0.8.0
PID USER PROGRAM DEV SENT RECEIVED
3379 root /usr/sbin/sshd eth0 0.485 0.182 KB/sec
820 root sshd: root@pts/0 eth0 0.427 0.052 KB/sec
? root unknown TCP 0.000 0.000 KB/sec
TOTAL 0.912 0.233 KB/sec
nethogs는 각 애플리케이션의 네트워크 트래픽을 연결합니다.
아래 몇 가지 명령어만 사용하여 nethogs를 제어할 수 있습니다:
- M: Change displays between “kb/s”, “kb”, “b”, and “mb”.
- R: Sort by traffic received.
- S: Sort by traffic sent.
- Q: quit
iptraf-ng는 네트워크 트래픽을 모니터링하는 다른 방법입니다. 여러 가지 대화형 모니터링 인터페이스를 제공합니다.
참고: IPTraf는 적어도 80열 24행의 화면 크기가 필요합니다.
Ubuntu에서 다음 명령을 사용하여 iptraf-ng를 설치할 수 있습니다:
iptraf-ng를 루트 권한으로 실행해야 하므로 앞에 sudo를 붙여야 합니다:
인기 있는 명령 줄 인터페이스 프레임워크인 ncurses를 사용하는 메뉴가 표시됩니다.
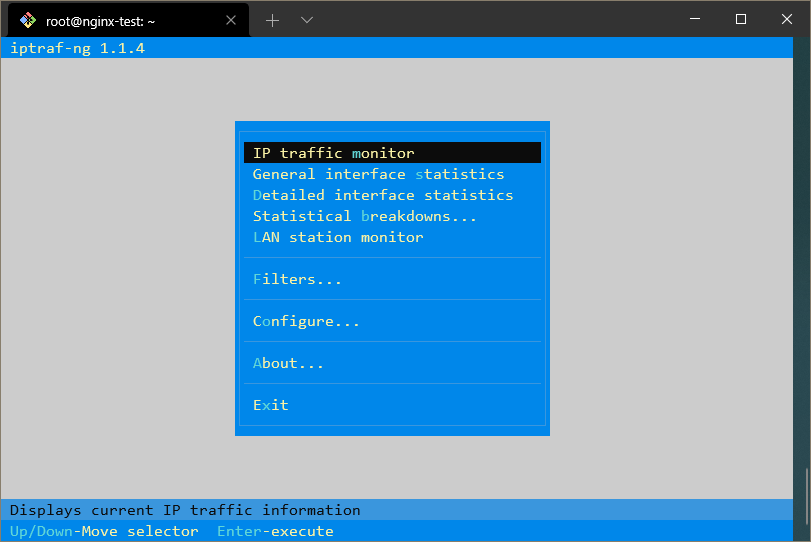
이 메뉴에서 액세스할 인터페이스를 선택할 수 있습니다.
예를 들어, 모든 네트워크 트래픽의 개요를 보려면 첫 번째 메뉴를 선택한 다음 “모든 인터페이스”를 선택하면 됩니다. 다음과 같은 화면이 표시됩니다:
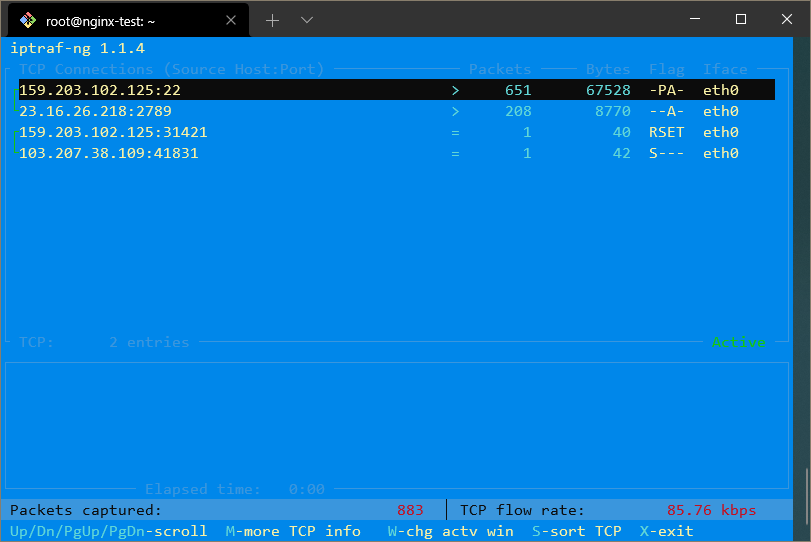
여기서 모든 네트워크 인터페이스에서 통신 중인 IP 주소를 확인할 수 있습니다.
이 IP 주소를 도메인으로 해석하려면 트래픽 화면을 종료한 다음 구성을 선택하고 역방향 DNS 조회를 토글하면 됩니다.
또한 포트 번호 대신 실행되는 서비스의 이름을 보려면 TCP/UDP 서비스 이름을 활성화할 수도 있습니다.
이 두 옵션을 모두 활성화하면 화면이 다음과 같이 표시될 수 있습니다:
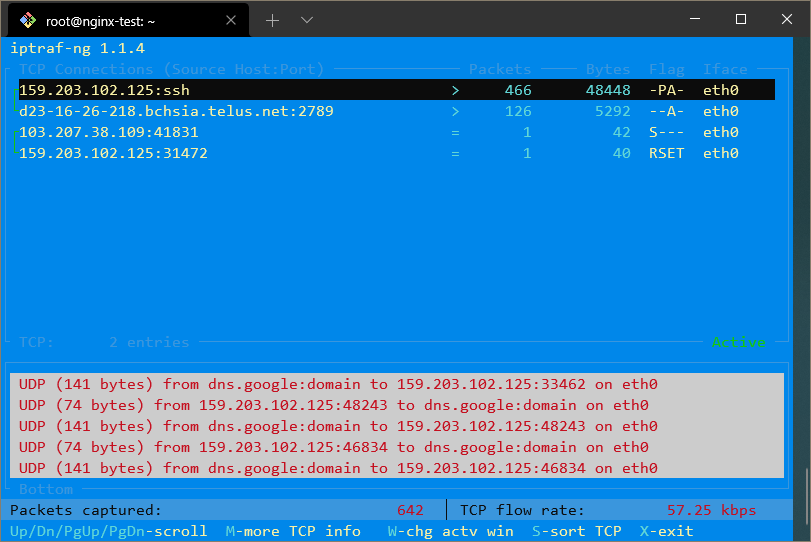
netstat 명령은 네트워크 정보를 수집하는 다른 다목적 도구입니다.
netstat는 대부분의 최신 시스템에 기본으로 설치되어 있지만, 서버의 기본 패키지 저장소에서 다운로드하여 직접 설치할 수 있습니다. 대부분의 Linux 시스템, Ubuntu를 포함한 시스템에서 netstat을 포함하는 패키지는 net-tools입니다:
netstat 명령어를 단독으로 실행하면 열린 소켓의 목록이 표시됩니다:
OutputActive Internet connections (w/o servers)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 192.241.187.204:ssh ip223.hichina.com:50324 ESTABLISHED
tcp 0 0 192.241.187.204:ssh rrcs-72-43-115-18:50615 ESTABLISHED
Active UNIX domain sockets (w/o servers)
Proto RefCnt Flags Type State I-Node Path
unix 5 [ ] DGRAM 6559 /dev/log
unix 3 [ ] STREAM CONNECTED 9386
unix 3 [ ] STREAM CONNECTED 9385
. . .
-a 옵션을 추가하면 모든 포트, 수신 및 수신하지 않는 포트가 나열됩니다:
OutputActive Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 *:ssh *:* LISTEN
tcp 0 0 192.241.187.204:ssh rrcs-72-43-115-18:50615 ESTABLISHED
tcp6 0 0 [::]:ssh [::]:* LISTEN
Active UNIX domain sockets (servers and established)
Proto RefCnt Flags Type State I-Node Path
unix 2 [ ACC ] STREAM LISTENING 6195 @/com/ubuntu/upstart
unix 2 [ ACC ] STREAM LISTENING 7762 /var/run/acpid.socket
unix 2 [ ACC ] STREAM LISTENING 6503 /var/run/dbus/system_bus_socket
. . .
TCP 또는 UDP 연결만 보려면 각각 -t 또는 -u 플래그를 사용하세요:
OutputActive Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 *:ssh *:* LISTEN
tcp 0 0 192.241.187.204:ssh rrcs-72-43-115-18:50615 ESTABLISHED
tcp6 0 0 [::]:ssh [::]:* LISTEN
“-s” 플래그를 전달하여 통계를 확인하세요:
OutputIp:
13500 total packets received
0 forwarded
0 incoming packets discarded
13500 incoming packets delivered
3078 requests sent out
16 dropped because of missing route
Icmp:
41 ICMP messages received
0 input ICMP message failed.
ICMP input histogram:
echo requests: 1
echo replies: 40
. . .
출력을 계속 업데이트하려면 -c 플래그를 사용할 수 있습니다. netstat에서 사용 가능한 많은 다른 옵션이 있으며, 이를 확인하려면 해당 매뉴얼 페이지를 검토하십시오.
다음 단계에서는 디스크 사용량을 모니터링하는 몇 가지 유용한 방법을 배우게 됩니다.
단계 3 – 디스크 사용량 모니터링 방법
연결된 드라이브에 남은 디스크 공간을 간단히 확인하려면 df 프로그램을 사용할 수 있습니다.
어떤 옵션도 지정하지 않으면, 출력은 다음과 같습니다:
OutputFilesystem 1K-blocks Used Available Use% Mounted on
/dev/vda 31383196 1228936 28581396 5% /
udev 505152 4 505148 1% /dev
tmpfs 203920 204 203716 1% /run
none 5120 0 5120 0% /run/lock
none 509800 0 509800 0% /run/shm
이는 바이트 단위의 디스크 사용량을 출력하며, 이는 조금 읽기 어려울 수 있습니다.
이 문제를 해결하려면 인간이 읽기 쉬운 형식으로 출력을 지정할 수 있습니다:
OutputFilesystem Size Used Avail Use% Mounted on
/dev/vda 30G 1.2G 28G 5% /
udev 494M 4.0K 494M 1% /dev
tmpfs 200M 204K 199M 1% /run
none 5.0M 0 5.0M 0% /run/lock
none 498M 0 498M 0% /run/shm
모든 파일 시스템에서 사용 가능한 총 디스크 공간을 보려면 --total 옵션을 전달할 수 있습니다. 이렇게 하면 아래쪽에 요약 정보가 있는 행이 추가됩니다:
OutputFilesystem Size Used Avail Use% Mounted on
/dev/vda 30G 1.2G 28G 5% /
udev 494M 4.0K 494M 1% /dev
tmpfs 200M 204K 199M 1% /run
none 5.0M 0 5.0M 0% /run/lock
none 498M 0 498M 0% /run/shm
total 32G 1.2G 29G 4%
df는 유용한 개요를 제공할 수 있습니다. 다른 명령어인 du는 디렉토리별로 분석을 제공합니다.
du는 현재 디렉토리와 모든 하위 디렉토리에 대한 사용량을 분석합니다. 거의 비어 있는 홈 디렉토리에서 실행되는 du의 기본 출력은 다음과 같습니다:
Output4 ./.cache
8 ./.ssh
28 .
다시 한번, -h를 전달하여 사람이 읽을 수 있는 출력을 지정할 수 있습니다:
Output4.0K ./.cache
8.0K ./.ssh
28K .
파일 크기뿐만 아니라 디렉토리도 보려면 다음을 입력하세요:
Output0 ./.cache/motd.legal-displayed
4 ./.cache
4 ./.ssh/authorized_keys
8 ./.ssh
4 ./.profile
4 ./.bashrc
4 ./.bash_history
28 .
하단에 총합을 보려면 -c 옵션을 추가할 수 있습니다:
Output4 ./.cache
8 ./.ssh
28 .
28 total
전체적인 내용이 아니라 총계에만 관심이 있다면 다음을 사용할 수 있습니다:
Output28 .
du에 대한 ncurses 인터페이스도 있으며, 이를 ncdu라고 합니다. 이를 설치할 수 있습니다:
이것은 디스크 사용량을 그래픽으로 나타냅니다:
Output--- /root ----------------------------------------------------------------------
8.0KiB [##########] /.ssh
4.0KiB [##### ] /.cache
4.0KiB [##### ] .bashrc
4.0KiB [##### ] .profile
4.0KiB [##### ] .bash_history
위아래 화살표를 사용하여 파일 시스템을 이동하고, Enter를 눌러 모든 디렉토리 항목에서 이동할 수 있습니다.
마지막 섹션에서는 메모리 사용량을 모니터링하는 방법을 배우게 됩니다.
단계 4 – 메모리 사용량 모니터링 방법
현재 시스템의 메모리 사용량을 확인할 수 있습니다.
사용하지 않고 출력할 때 결과는 다음과 같습니다:
Output total used free shared buff/cache available
Mem: 1004896 390988 123484 3124 490424 313744
Swap: 0 0 0
더 가독성 있게 표시하려면 출력을 메가바이트 단위로 표시하려면 -m 옵션을 전달할 수 있습니다:
Output total used free shared buff/cache available
Mem: 981 382 120 3 478 306
Swap: 0 0 0
Mem 라인에는 버퍼링 및 캐싱에 사용된 메모리가 포함되어 있으며 필요시 다른 목적을 위해 즉시 해제됩니다. Swap은 활성 메모리를 보존하기 위해 디스크의 스왑 파일에 작성된 메모리입니다.
마지막으로, vmstat 명령은 메모리, 스왑, 디스크 IO 및 CPU 정보를 포함한 시스템에 대한 다양한 정보를 출력할 수 있습니다.
메모리 사용에 대한 다른 관점을 얻으려면 명령을 사용할 수 있습니다:
Outputprocs -----------memory---------- ---swap-- -----io---- -system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa
1 0 0 99340 123712 248296 0 0 0 1 9 3 0 0 100 0
단위를 지정하여 메가바이트 단위로 볼 수 있습니다. -S 플래그를 사용합니다:
Outputprocs -----------memory---------- ---swap-- -----io---- -system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa
1 0 0 96 120 242 0 0 0 1 9 3 0 0 100 0
메모리 사용에 대한 일반 통계를 얻으려면 다음을 입력하십시오:
Output 495 M total memory
398 M used memory
252 M active memory
119 M inactive memory
96 M free memory
120 M buffer memory
242 M swap cache
0 M total swap
0 M used swap
0 M free swap
. . .
개별 시스템 프로세스의 캐시 사용에 대한 정보를 얻으려면 다음을 입력하십시오:
OutputCache Num Total Size Pages
ext4_groupinfo_4k 195 195 104 39
UDPLITEv6 0 0 768 10
UDPv6 10 10 768 10
tw_sock_TCPv6 0 0 256 16
TCPv6 11 11 1408 11
kcopyd_job 0 0 2344 13
dm_uevent 0 0 2464 13
bsg_cmd 0 0 288 14
. . .
이렇게 하면 캐시에 저장된 정보의 유형에 대한 세부 정보를 제공합니다.
결론
이러한 도구를 사용하면 명령줄에서 서버를 모니터링할 수 있는 능력을 갖추기 시작할 수 있습니다. 다른 목적으로 사용되는 많은 다른 모니터링 유틸리티가 있지만 이것들은 좋은 시작점입니다.
그다음에는 ps, kill, 그리고 nice를 사용한 Linux 프로세스 관리에 대해 배우실 수도 있습니다.