













이전 글 “Learning the Basics: How to Use JSON in SQLite“에서 우리는 SQLite의 핵심 JSON 함수와 그 기능에 대해 자세히 살펴보았습니다. SQLite 데이터베이스 내에서 JSON을 구조화되지 않은 데이터로 사용하는 방법을 탐구했습니다. 중요한 것은, 데이터 저장 및 검색에서 SQLite JSON 함수의 역할을 논의하고, 실용적인 SQL 쿼리 예제를 살펴보았습니다. SQLite에서 JSON 데이터와 함께 작업하는 방법에 대한 기본적인 이해는 이 주제에 대한 고급 탐구를 위한 기초를 제공합니다.
시작합시다!
SQLite에서 JSON 처리를 완전히 이해하여 SQL과 NoSQL 기능 통합
SQLite의 JSON 처리 능력에 대한 지식을 발전시키면 SQL과 NoSQL의 장점을 결합하여 혼합 데이터 형식을 관리하기 위한 효율적인 일체형 솔루션을 제공합니다. SQLite에서 JSON 데이터 지원은 SQLite를 MongoDB와 같은 데이터베이스처럼 구조화되지 않은 데이터를 위한 강력한 도구로 만듭니다.
SQLite의 고급 JSON 통합은 JSON의 융통성과 SQLite의 강건성을 결합하여 오늘날 데이터 집중적인 애플리케이션에 이상적입니다. SQLite의 JSON 기능은 단순히 데이터를 저장하고 검색하는 것을 넘어서서 SQL과 유사한 작업을 JSON 데이터에 수행할 수 있도록 합니다. 이는 구조화된 데이터와 비구조화된 데이터 관리 사이에서 다리를 만들어 줍니다.
이 가이드는 실제 SQL 쿼리 예제를 통해 SQLite의 JSON 함수로 실무 기술을 채워나가는 데 초점을 맞춥니다. 각 섹션은 당신의 이해를 돕고 실제 세계에서 SQLite에서 JSON 데이터 조작을 시작하는 데 도움이 될 것입니다.
결국, 당신은 SQLite에서 JSON 데이터 처리를 위한 사용 가능한 도구 세트로 잘 무장해 어떤 JSON 데이터 구조도 해결할 수 있게 될 것입니다. 인덱스 적용, 경로 표현식으로 쿼리하기, 필터링, 데이터 유효성 검사 등 JSON 함수를 사용하여 구조화된 환경에서 동적 데이터를 처리하는 핵심 작업에 대해 배우게 될 것입니다.
1. SQLite 내에서 JSON을 통합하는 방법
SQLite의 내장 JSON 함수는 JSON과 SQLite를 통합하는 데 중요한 역할을 합니다. SQLite 버전 3.38.0부터, 2022년 2월 22일에 출시됨 JSON 함수가 기본적으로 포함되어 있으며, 이전에는 확장 기능이었습니다. 이는 이전 버전에서 SQLite의 이러한 JSON 함수가 선택 사항이었지만 이제는 기본적으로 사용 가능하며 컴파일 타임 옵션 설정을 통해 필요한 경우 비활성화할 수 있음을 의미합니다.
간단한 INSERT SQL 쿼리를 사용하여 JSON 데이터를 SQLite에 가져올 수 있습니다. 또는 타사 도구나 스크립팅 기술을 활용하여 대량으로 광범위한 JSON 데이터 세트를 가져올 수도 있습니다. JSON 데이터를 추출하려면 json_extract() 함수를 활용하여 JSON 데이터 열에서 특정 키와 연결된 값을 가져올 수 있습니다.
2. 고급 JSON 디코딩 및 SQL 쿼리를 위한 SQLite JSON 함수 활용
이 섹션에서는 SQLite에서 고급 JSON 함수와 그 기능을 탐색하고, 각각에 대한 SQL 쿼리 예제를 살펴볼 것입니다. 이 블로그 게시물에서는 movie라는 이름의 샘플 생성된 JSON 데이터를 참조로 사용하여 조사된 데이터로 사용할 것입니다:
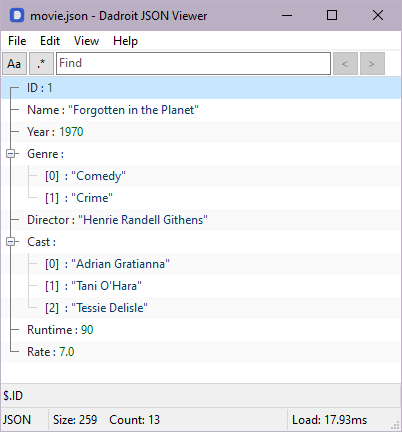
data라는 하나의 필드를 가진 movie라는 테이블에 데이터를 삽입한 후 이 샘플 쿼리들을 지금부터 실행할 수 있습니다. 다음 쿼리에서는 JSON 함수의 입력 텍스트를 사용하여 함수에 대한 설명을 직관적으로 하고, 그 후 섹션 3부터 데이터베이스에 삽입된 데이터로 돌아올 것입니다.
이 예제에서는 간단하게 하기 위해 첫 번째 JSON 데이터의 단순화된 버전을 사용할 것입니다:
{
"Name": "Naked of Truth",
"Year": 1979,
"Director": "Ellynn O'Brien",
"Producer": "Kayley Byron Tutt",
"Runtime": 183,
"Rate": 8.0,
"Description": "Donec pretium nec dolor in auctor."
}json_error_position() 함수를 사용한 SQLite에서의 오류 감지
json_error_position() 함수는 JSON 데이터의 구문 오류를 감지하는 데 사용할 수 있습니다. 입력 문자열이 유효한 JSON이면 0을 반환하고, 그렇지 않으면 첫 번째 오류의 문자 위치를 반환합니다.
예를 들어, 다음과 같이 이 함수의 입력으로 손상된 JSON 문자열이 있으면:
SELECT
json_error_position ( '{"Name":"Naked of Truth","Year":1979,' ) AS err_position이 쿼리를 실행한 결과로 발생한 구문 오류의 위치를 얻게 되며, 이 경우에는 끝에 누락된 “}”의 위치입니다.
| error_position |
|---|
| 38 |
SQLite에서 json_patch() 함수를 사용하여 JSON 객체 병합
json_patch() 함수는 두 개의 JSON 객체를 병합하면서 JSON 객체를 추가, 수정 및 삭제할 수 있게 해줍니다.
예를 들어, 이 쿼리는 두 개의 JSON 입력을 하나의 JSON으로 결합합니다:
SELECT
json_patch ( '{"Name":"Naked of Truth"}', '{"Year": 2011}' ) AS patched_json;결과는 다음과 같을 것입니다. 두 필드를 모두 포함하는 JSON 객체:
| patched_json |
|---|
| {“Name”:”Naked of Truth”,”Year”:2011} |
SQLite에서 json_set() 함수를 사용하여 JSON 필드 조작
json_set() 함수는 JSON 속성을 추가하거나 교체하는 데 사용됩니다. json_set()는 첫 번째 인수로 JSON 문자열을 받고 경로/값 인수의 쌍을 제공하여 값을 추가하거나 교체한 결과로 생성된 JSON 문자열을 반환합니다.
예를 들어, 이전 쿼리의 JSON 데이터를 기반으로 Director 필드를 JSON 데이터에 추가하려면 다음과 같은 쿼리를 작성할 수 있습니다:
SELECT
json_set ( '{"Name":"Naked of Truth","Year":2011}', '$.Director', 'Ellynn OBrien' ) AS json_data;그리고 결과는 다음과 같을 것입니다:
| json_data |
|---|
| {“Name”:”Naked of Truth”,”Year”:2011,”Director”:”Ellynn OBrien”} |
SQLite에서 json_quote() 함수
json_quote() 함수는 간단한 함수로, 입력 값을 쌍따옴표로 감싸서 유효한 JSON 문자열로 만듭니다. 이것의 간단한 쿼리 예시는 다음과 같습니다:
SELECT
json_quote ( 'Naked Of Truth' ) AS valid_json_string;그리고 결과는 다음과 같을 것입니다:
| valid_json_string |
|---|
| “Naked of Truth” |
SQLite에서 집계를 위해 json_group_object() 및 json_group_array() JSON 함수 사용법
이 세트의 SQLite에서의 JSON 함수들에 대해, 이전 예제들과 비교하여 샘플 JSON 데이터를 확장해야 합니다. 각 함수의 사용 사례를 이해하기 쉽게 설명하기 위해서입니다. 이것이 이 섹션 시작에서 언급한 movie 테이블이라고 가정합시다. 데이터베이스에서 하나의 필드인 data가 있습니다:
| data |
|---|
| {“ID”: 1, “Name”: “Forgotten in the Planet”, “Year”: 1970, “Genre”: [“Comedy”, “Crime”], “Director”: “Henrie Randell Githens”, “Cast”: [“Adrian Gratianna”, “Tani O’Hara”, “Tessie Delisle”], “Runtime”: 90, “Rate”: 7.0} |
| {“ID”: 2, “Name”: “The Obsessed’s Fairy”, “Year”: 1972, “Genre”: [“Adventure”], “Director”: “Susanne Uriel Lorimer”, “Cast”: [“Dacy Dex Elsa”, “Matilde Kenton Collins”], “Runtime”: 98, “Rate”: 9.5} |
| {“ID”: 3, “Name”: “Last in the Kiss”, “Year”: 1965, “Genre”: [“History”, “Animation”], “Director”: “Simone Mikey Bryn”, “Cast”: [“Margery Maximilianus Shirk”,”Harri Garwood Michelle”], “Runtime”: 106, “Rate”: 4.1} |
json_group_array() 집계 함수와 SQL 쿼리 예시
json_group_array() 함수는 SQLite에서 다른 집계 함수와 비슷하게, 여러 행의 데이터를 단일 JSON 배열로 그룹화합니다.
예를 들어, 이 쿼리는 Rate가 6보다 큰 모든 영화의 이름을 포함하는 JSON 배열을 반환합니다:
SELECT
json_group_array ( json_extract ( data, '$.Name' ) ) AS movie_names
FROM
movie
WHERE
json_extract ( data, '$.Rate' ) > 6그리고 결과는 다음과 같을 것입니다:
| movie_names |
|---|
| [“Forgotten in the Planet”, “The Obsessed’s Fairy”] |
json_group_object() JSON 함수와 SQL 쿼리 예시
json_group_object() 함수는 쿼리의 두 개의 열을 그룹화하여 JSON 객체를 생성합니다. 여기서 첫 번째 열은 키로 사용되고, 두 번째 열은 값으로 사용됩니다. 첫 번째는 JSON 필드의 키 이름으로 사용되며, 두 번째는 해당 값으로 사용됩니다.
예를 들어, 이 쿼리는 movie의 Rate가 6보다 큰 경우에만 각 필드의 이름을 영화의 ID로, 필드의 값을 해당 Name으로 하는 JSON 객체를 반환합니다. 이로 인해 마지막 영화는 제외됩니다:
SELECT
json_group_object ( json_extract ( Data, '$.ID' ), json_extract ( Data, '$.Name' ) ) AS movie_rates
FROM
movie
WHERE
json_extract ( Data, '$.Rate' ) > 5결과는 다음과 같을 것입니다. 첫 번째와 두 번째 영화의 ID와 Name으로 구성된 JSON 객체이며, 이들은 Rate가 5보다 큽니다:
| movie_rates |
|---|
| {“1”: “Forgotten in the Planet”,”2″:”The Obsessed’s Fairy”} |
json_each() 및 json_tree()을 사용하여 SQLite에서 JSON 데이터 파싱
SQLite는 테이블 값 함수인 json_each()와 json_tree()를 제공하여 JSON 데이터와 작업할 수 있는 강력한 기능을 제공합니다. 이들은 경로 매개변수 유무에 따라 다양한 변형이 있어 서로 다른 깊이에서 JSON과 상호 작용할 수 있습니다.
가정해보세요. SQLite 데이터베이스의 영화 테이블에 데이터 필드에 삽입된 유일한 JSON 값이 이것이라고 합시다. 이제 집계 함수에 대해 설명하겠습니다.
| data |
|---|
| { “ID”: 1, “Name”: “Forgotten in the Planet”, “Year”: 1970, “Genre”: [“Comedy”, “Crime”], “Director”: “Henrie Randell Githens”, “Cast”: [“Adrian Gratianna”, “Tani O’Hara”, “Tessie Delisle”], “Runtime”: 90, “Rate”: 7.0 } |
SQLite에서 json_each() 함수와 SQL 쿼리 예제
SQLite의 json_each() 함수는 JSON 객체를 행으로 분해하여 각 행이 JSON 객체의 필드를 나타내며, 중첩된 JSON 필드의 1단계만 탐색합니다.
예를 들어, 이 쿼리는 JSON 데이터의 각 필드에 대해 8개의 행을 반환할 것입니다.
SELECT
key,
value,
type
FROM
movie,
json_each ( data )결과는 다음과 같습니다. JSON의 각 필드의 키와 값을 행으로 나열합니다. 보시다시피, 배열 필드 Genre와 Cast는 그대로 나열되어 있으며, 함수는 이들을 탐색하여 두 번째 수준의 항목을 나열하지 않았습니다.
| key | Value | Type |
|---|---|---|
| ID | 1 | integer |
| Name | Forgotten in the Planet | text |
| Year | 1970 | integer |
| Genre | [“Comedy”,”Crime”] | array |
| Director | Henrie Randell Githens | text |
| Cast | [“Adrian Gratianna”,”Tani O’Hara”,”Tessie Delisle”] | array |
| Runtime | 90 | integer |
| Rate | 7.0 | real |
SQLite에서 json_tree() 함수와 SQL 쿼리 예제
json_tree() 함수는 JSON 데이터를 완전히 탐색하고 구문 분석하는 데 사용되며, 즉 모든 중첩 수준을 통해 각 필드를 탐색합니다. json_tree() 함수는 JSON을 탐색하여 모든 부분을 살펴본 다음, 찾은 모든 요소를 자세히 설명하는 테이블을 제공합니다.
json_tree()는 결과를 행 집합으로 표시하여 가장 복잡한 중첩된 JSON 데이터조차도 명확한 보기를 제공합니다. 이 테이블은 각 요소의 이름, 데이터 유형, 값 및 JSON 구조 내의 위치를 알려줍니다.
따라서 이 쿼리는 JSON 객체의 구조를 설명하는 여러 행을 반환할 것입니다. 이 중 포함된 Cast 필드도 포함됩니다:
SELECT
key,
value,
type
FROM
movie,
json_tree ( data )위의 쿼리 결과는 다음과 같을 것입니다:
| key | Value | Type |
|---|---|---|
| {“ID”:1,”Name”:”Forgotten in the Planet”,”Year”:1970,”Genre”:[“Comedy”,”Crime”],”Director”:”Henrie Randell Githens”,”Cast”:[“Adrian Gratianna”,”Tani O’Hara”,”Tessie Delisle”],”Runtime”:90,”Rate”:7.0} | object | |
| ID | 1 | integer |
| Name | Forgotten in the Planet | text |
| Year | 1970 | integer |
| Genre | [“Comedy”,”Crime”] | array |
| 0 | Comedy | text |
| 1 | Crime | text |
| Director | Henrie Randell Githens | text |
| Cast | [“Adrian Gratianna”,”Tani O’Hara”,”Tessie Delisle”] | array |
| 0 | Adrian Gratianna | text |
| 1 | Tani O’Hara | text |
| 2 | Tessie Delisle | text |
| Runtime | 90 | integer |
| Rate | 7 | real |
경로 매개변수로 json_tree()는 JSON의 특정 부분에 초점을 맞출 수 있습니다. JSON에서 특정 경로를 두 번째 인수로 제공하면 그곳에서부터 탐색을 시작합니다.
예를 들어, 이 쿼리는 Cast 필드 외부의 모든 것을 무시하고 이 중첩된 JSON 배열에 대한 집중적인 보기를 제공합니다:
SELECT
key,
value,
type
FROM
movie,
json_tree ( data, '$.Cast' )위의 쿼리 결과는 다음과 같을 것입니다:
| key | Value | Type |
|---|---|---|
| 0 | Adrian Gratianna | text |
| 1 | Tani O’Hara | text |
| 2 | Tessie Delisle | text |
재미있는 사실: SQLite의 공식 JSON 문서 URL의 ‘1’을 보고 이야기가 있는지 궁금해 하신 적 있나요? SQLite에서 JSON 지원이 처음 출시된 2015년, 제작자는 ‘JSON1’이 단순히 시리즈의 시작일 뿐이라고 예상했습니다—JSON2, JSON3 등. 하지만 재미있는 부분은 ‘JSON1’이 너무 효과적이고 효율적이어서 ‘JSON2’나 ‘JSON3’을 만들 필요가 없었다는 것입니다. 따라서 ‘JSON1’의 ‘1’은 단순한 버전 표시자가 아니라 성공의 표시입니다!
3. SQLite에서 어떤 복잡한 JSON 데이터를 쿼리하기 위한 실용적인 접근 방식
SQLite의 JSON 함수를 SQLite의 내장 함수와 협력하여 사용하면 보다 복잡한 데이터 쿼리를 수행할 수 있습니다. 여기 집계, 필터링 및 경로 표현식을 포함하여 이러한 예제 중 일부를 볼 수 있습니다.
게시물 시작 부분에서 언급했듯이 예제의 나머지 섹션에 대한 movie 테이블의 JSON 데이터는 다음과 같습니다:
| data |
|---|
| {“ID”: 1, “Name”: “Forgotten in the Planet”, “Year”: 1970, “Genre”: [“Comedy”, “Crime”], “Director”: “Henrie Randell Githens”, “Cast”: [“Adrian Gratianna”, “Tani O’Hara”, “Tessie Delisle”], “Runtime”: 90, “Rate”: 7.0} |
| {“ID”: 2, “Name”: “The Obsessed’s Fairy”, “Year”: 1972, “Genre”: [“Comedy”, “Adventure”], “Director”: “Susanne Uriel Lorimer”, “Cast”: [“Dacy Dex Elsa”, “Matilde Kenton Collins”], “Runtime”: 98, “Rate”: 9.5} |
| {“ID”: 3, “Name”: “Last in the Kiss”, “Year”: 1965, “Genre”: [“History”, “Animation”], “Director”: “Simone Mikey Bryn”, “Cast”: [“Margery Maximilianus Shirk”,”Harri Garwood Michelle”], “Runtime”: 106, “Rate”: 4.1} |
SQLite에서 JSON 함수로 집계 SQL 쿼리 작성
이 방법은 JSON 함수와 SQLite의 내장 집계 함수를 함께 사용하여 JSON 데이터에 대한 계산을 수행하는 것을 포함합니다. 예를 들어, 코미디 카테고리의 영화의 평균 런타임을 계산하기 위해 다음 쿼리를 사용할 수 있습니다:
SELECT
AVG( json_extract ( data, '$.Runtime' ) ) AS average_runtime
FROM
movie AS M,
json_each ( json_extract ( M.data, '$.Genre' ) ) AS T
WHERE
T.value = 'Comedy';위의 쿼리 결과는 데이터베이스에 코미디 장르의 영화가 두 개이고 그 런타임이 90과 98이므로 그 평균은 다음과 같습니다:
| average_runtime |
|---|
| 94 |
다중 조건으로 JSON 데이터 디코딩 및 필터링
SQLite에서 json_extract() 함수를 사용하여 SQL 쿼리의 WHERE 절에서 자세한 필터링을 수행할 수 있습니다. 예를 들어, 두 명 이상의 배우를 가지고 있고 Rate가 특정 값보다 높은 영화를 필터링할 수 있습니다.
SELECT
json_extract ( data, '$.Name' ) AS movie_name,
json_extract ( data, '$.Rate' ) AS movie_rate,
json_array_length ( json_extract ( data, '$.Cast' ) ) AS cast_size
FROM
movie
WHERE
json_array_length ( json_extract ( data, '$.Cast' ) ) >= 2
AND json_extract ( data, '$.Rate' ) > 8;위의 쿼리 결과는 다음과 같습니다:
| movie_name | movie_rate | cast_size |
|---|---|---|
| The Obsessed’s Fairy | 9.5 | 2 |
SQLite에서 JSON 데이터에서 특정 값을 추출하기 위해 경로 표현식 사용
경로 표현식을 사용하면 특정 주소의 중첩된 JSON 데이터에 접근할 수 있습니다. 이 예시는 역사와 같은 특정 장르의 영화를 감독한 movie directors의 모든 목록을 반환합니다.
SELECT DISTINCT
json_extract ( data, '$.Director' ) AS movie_director
FROM
movie,
json_each ( json_extract ( data, '$.Genre' ) )
WHERE
value = 'History';위 쿼리의 결과는 다음과 같습니다:
| movie_director |
|---|
| Simone Mikey Bryn |
4. SQLite에서 자신의 JSON 데이터 스키마를 확인하는 방법
SQLite에서의 JSON 데이터 스키마 확인은 데이터의 구조와 일관성을 보장하고, 미래의 오류 처리를 개선하며, 복잡한 데이터 조작을 단순화하는 방법입니다. SQLite에는 스키마 유효성 검사를 위한 기본 제공 함수가 없지만, JSON과 CHECK 함수를 사용하여 이를 수행할 수 있습니다.
json_type() 및 check() SQLite 함수로 JSON 구조 확인
json_type() 함수를 사용하여 JSON 데이터의 필드 유형을 확인할 수 있습니다. 예를 들어, 이전에 영화 테이블을 생성한 것을 기반으로 영화의 JSON 데이터를 저장하기 위해 테이블을 생성할 때, 각 항목에 Name과 Year 필드가 있고, Year이 정수인지 확인하려면 테이블 생성에 json_type() 함수와 CHECK() 제약 조건을 사용할 수 있습니다.
CREATE TABLE movie ( data TEXT CHECK ( json_type ( data, '$.Name' ) IS NOT NULL AND json_type ( data, '$.Year' ) = 'integer' ) );여기서 json_type()는 JSON 데이터에서 지정된 필드, 즉 Name과 Year의 유형을 확인합니다. Name이 존재하지 않거나 Year이 정수가 아닌 경우 새로운 삽입 또는 업데이트 작업을 시도하면 CHECK() 제약 조건이 실패하고 작업이 거부됩니다. 이는 movie 테이블의 JSON 데이터에서 데이터 무결성을 유지하는 데 도움이 됩니다.
SQLite에서 json_valid() 함수를 사용하여 JSON 데이터 검증
json_valid() 함수는 JSON 표준 형식의 관점에서 JSON 데이터의 유효성을 확인하며, 스키마 유효성 검사의 정도를 제공합니다. 예를 들어, 삽입 전에 JSON 데이터의 무결성을 보장하기 위해 다음과 같은 유효성 검사를 적용할 수 있습니다:
INSERT INTO movie ( data ) SELECT
'{"Name":"Naked of Truth","Year":1979}' AS movie_input
WHERE
json_valid ( movie_input );이 문장에서 json_valid()는 제공된 JSON 문자열이 유효한지 확인합니다. 그렇다면 데이터가 movie 테이블에 삽입되고, 그렇지 않으면 작업이 건너뜁니다. 이러한 안전장치는 모양이 맞지 않은 JSON 데이터의 삽입을 방지합니다.
두 가지 규칙을 결합한 또 다른 예를 생각해 보겠습니다. movie 테이블의 생성 단계에서의 제약 조건과 삽입 시 json_valid() 검사입니다. 다음 쿼리를 고려해 보십시오:
INSERT INTO movie ( data ) SELECT
'{"Year":"1979"}' AS movie_input
WHERE
json_valid ( movie_input );이 쿼리의 결과는 입력 값이 Name 필드를 가지고 있지 않고 Year 필드가 정수가 아니기 때문에 “CHECK constraint failed” 에러 메시지가 발생합니다. 따라서 삽입이 실패하게 되며, 제공된 JSON 데이터가 유효한 JSON이라도 마찬가지입니다.
또한, 복잡하고 중첩된 JSON 데이터에 대한 더 철저한 스키마 유효성 검사를 위해 Python의 JSONschema 라이브러리를 고려할 수도 있습니다.
5. SQLite에서 중첩된 JSON 데이터 관리 방법
SQLite에서 중첩된 계층적 JSON 데이터를 탐색하는 것은 몇 가지 과제를 안고 있습니다. 그러나 SQLite의 내장 JSON 함수는 이 과정을 간소화하고 관리 가능하게 만듭니다. 여기 중첩된 JSON을 관리하기 위한 몇 가지 전략을 살펴보겠습니다.
SQL 쿼리를 사용하여 계층적 JSON 데이터 펼치기
SQLite의 json_each() 및 json_extract() 함수를 사용하면 중첩된 JSON 데이터의 레이어를 탐색할 수 있습니다. 다음 쿼리를 고려하세요. 이 쿼리는 json_each()를 사용하여 데이터를 파싱하고 json_extract()를 사용하여 필요한 정보를 선택적으로 추출합니다.
예를 들어, 이 쿼리는 data 필드의 각 JSON 레코드에서 Cast 배열을 파고들어 movie 테이블에서 movies를 나열하며, 2명 이상의 Cast 멤버를 가진 영화를 찾습니다:
SELECT
key,
json_extract ( data, '$.Name' ) AS movie_name,
json_extract ( data, '$.Year' ) AS movie_year,
json_array_length ( json_extract ( data, '$.Cast' ) ) AS cast_size
FROM
movie,
json_each ( data )
WHERE
type = 'array'
AND cast_size > 2
GROUP BY
movie_name;위의 쿼리의 결과는 다음과 같습니다:
| key | movie_name | movie_year | cast_size |
|---|---|---|---|
| Simone Mikey Bryn | Forgotten in the Planet | 1970 | 3 |
SQL 쿼리를 통한 JSON 배열 탐색
JSON 객체는 배열 형태로 중요한 정보를 보유할 수 있으며, json_tree()와 json_extract()를 결합하여 이러한 중첩된 배열을 반복하고 데이터를 추출할 수 있습니다.
예를 들어, 이 쿼리는 각 영화 레코드의 Cast 배열에서 각 Actor의 이름을 가져옵니다:
SELECT
json_extract ( data, je.fullkey ) AS actor,
json_extract ( data, '$.Name' ) AS movie_name,
json_array_length ( data, '$.Cast' ) AS cast_size
FROM
movie,
json_tree ( data ) AS je
WHERE
( je.type = 'text' )
AND ( je.fullkey LIKE '%Cast%' );이 쿼리의 결과는 다음과 같습니다:
| actor | movie_name | cast_size |
|---|---|---|
| Adrian Gratianna | Forgotten in the Planet | 3 |
| Tani O’Hara | Forgotten in the Planet | 3 |
| Tessie Delisle | Forgotten in the Planet | 3 |
| Dacy Dex Elsa | The Obsessed’s Fairy | 2 |
| Matilde Kenton Collins | The Obsessed’s Fairy | 2 |
| Margery Maximilianus Shirk | Last in the Kiss | 2 |
| Harri Garwood Michelle | Last in the Kiss | 2 |
| Adrian Gratianna | Forgotten in the Planet | 3 |
| Tani O’Hara | Forgotten in the Planet | 3 |
| Tessie Delisle | Forgotten in the Planet | 3 |
SQLite에서 json_each() 함수를 사용하여 JSON 데이터 평면화
때로는 중첩된 JSON 구조를 단순화하기 위해 평면화하는 것이 JSON 객체에 대한 복잡한 쿼리를 해결하는 실용적인 방법일 수 있습니다. SQLite의 json_tree() 함수는 JSON 객체를 평면화하는 데 사용할 수 있습니다.
예를 들어, 이 쿼리는 json_tree()를 사용하여 JSON 데이터를 완전히 평면화된 키-값 쌍의 테이블로 변환하고, 첫 번째 영화 레코드의 각 기본 값 유형을 가져옵니다.
SELECT
jt.fullkey,
jt.key,
jt.value
FROM
movie,
json_tree ( data ) AS jt
WHERE
( jt.key<> '' )
AND ( jt.type IN ( 'integer', 'text', 'real' ) )
AND json_extract ( data, '$.ID' ) = 1이 쿼리의 결과는 다음과 같습니다:
| fullkey | key | value |
|---|---|---|
| $.ID | ID | 1 |
| $.Name | Name | Forgotten in the Planet |
| $.Year | Year | 1970 |
| $.Genre[0] | 0 | Comedy |
| $.Genre[1] | 1 | Crime |
| $.Director | Director | Henrie Randell Githens |
| $.Cast[0] | 0 | Adrian Gratianna |
| $.Cast[1] | 1 | Tani O’Hara |
| $.Cast[2] | 2 | Tessie Delisle |
| $.Runtime | Runtime | 90 |
| $.Rate | Rate | 7 |
이러한 방법을 채택함으로써 SQLite에서 복잡한 JSON 데이터를 효율적으로 구문 분석, 관리 및 디코딩할 수 있으며, 이는 복잡한 JSON 데이터를 다룰 때 매우 귀중합니다.
6. SQLite에서 JSON 데이터에 대한 쿼리 최적화를 위한 인덱싱 사용 방법
JSON 데이터를 SQLite에서 인덱싱하는 것은 검색 작업을 최적화하고 쿼리 성능을 향상시키는 효과적인 방법입니다. 특히 대용량 데이터셋의 경우에 더욱 그러합니다. 특정 JSON 속성을 기반으로 인덱스를 생성함으로써 JSON 열에 대한 검색 작업을 크게 가속화할 수 있습니다.
이 접근 방식의 원리는 간단합니다. 각 행의 JSON을 파싱하고 전체 테이블 스캔을 수행하는 대신, 이는 자원을 많이 소모할 수 있습니다. SQLite는 인덱스를 활용하여 관심 있는 행을 빠르게 찾을 수 있습니다.
SQLite에서 JSON 데이터에 SQL 인덱싱 추가하는 방법
실용적인 예를 들어 movie 데이터셋을 살펴보겠습니다. 예를 들어, Name으로 영화를 자주 검색하는 경우 이 속성에 인덱스를 생성하는 것이 유리합니다:
CREATE INDEX idx_name ON movie ( json_extract ( data, '$.item.Name' ) );여기서 data는 JSON 데이터가 있는 열이고, movie는 테이블입니다. json_extract() 함수는 각 Name을 추출하고, SQLite는 이 값을 사용하여 인덱스를 생성합니다.movie의 JSON 데이터입니다.
인덱스가 설정되면 SQLite는 Name으로 영화를 쿼리할 때 데이터를 빠르게 검색할 수 있습니다. 이 쿼리는 idx_name 인덱스가 있는 경우 훨씬 빠를 것입니다. 따라서 SQLite에서 JSON 데이터에 인덱싱을 추가하면 강력한 최적화 기능을 제공하므로 큰 JSON 데이터 세트를 관리하는 효율적인 방법입니다.
SQLite에서 JSON 데이터의 여러 필드에 대해 하나의 인덱스를 생성하는 방법
다른 예를 생각해 보겠습니다. 이 경우 하나 이상의 필드를 기반으로 특정 데이터를 자주 쿼리합니다. 예를 들어, movies의 이름과 연도로 자주 검색하는 경우 이러한 속성에 대해 인덱스를 함께 생성하는 것이 유용합니다. SQLite에서는 계산된 표현식에 대해 인덱스를 생성할 수 있습니다.
CREATE INDEX idx_name_year ON movie ( json_extract ( data, '$.Item.Name' ), json_extract ( data, '$.Item.Year' ) );이 인덱스가 다시 설정되면 SQLite는 이름과 연도로 영화를 쿼리할 때 데이터를 빠르게 검색할 수 있습니다.
SQLite에서의 Json5 지원
JSON5가 도입되어 ECMA 호환 구문을 지원하고 JSON을 구성 언어로 사용하기에 조금 더 적합하게 만들었습니다. SQLite는 JSON5 확장 지원을 버전 3.42.0에서 시작했습니다. SQLite는 JSON5 확장을 포함한 JSON 텍스트를 읽고 해석할 수 있지만, SQLite의 함수가 생성하는 모든 JSON 텍스트는 정식 JSON의 정의에 엄격하게 부합합니다. 다음은 JSON5 확장이 SQLite의 JSON 지원에 추가하는 몇 가지 주요 기능입니다.
SQLite JSON에서 주석이 달린 JSON 개체
JSON5는 단일(//…) 및 다중 줄(/…/) 주석을 허용합니다. 이는 JSON 데이터 내에서 직접 컨텍스트나 설명을 추가하는 데 특히 유용할 수 있습니다. 다음은 JSON 개체에서 주석의 예입니다:
/* A
multi-line
comment
in JSON5 */
{
"key": "value" // A single-line comment in JSON5
}SQLite JSON에서 따옴표 없는 개체 키
JSON5에서 개체 키는 인용되지 않은 식별자일 수 있으며, 이는 JSON 구문을 간소화합니다. 그러나 이는 JSON 표준을 엄격하게 준수하는 시스템과의 호환성을 제한할 수 있다는 점에 유의해야 합니다.
{ key: "value" }JSON 개체의 다중 줄 문자열
JSON5는 줄 바꿈 문자를 이스케이프하여 다중 줄 문자열을 지원합니다. 이는 큰 문자열을 다룰 때나 문자열을 보다 읽기 쉽게 포맷할 때 유용합니다.
{ key: "This is a \\\\\\\\ multiline string" }SQLite에서 Json5와 정식 JSON 유효성 검사 비교
여기서는 JSON5와 정식 JSON 객체에 대한 완전한 유효성 검사 기술을 살펴보고, SQLite 데이터베이스에서 정확한 SQL 쿼리 예제로 지원하는 방법을 설명할 것입니다.
문자열이 유효한 JSON5인지 확인하려면 json_error_position() 함수를 사용할 수 있습니다. 이 함수는 문자열이 잘 구성되지 않은 JSON 또는 JSON5인 경우 0이 아닌 값을 반환합니다. 다음은 예시입니다:
SELECT
json_error_position ( '{ key: "value"}' ) AS error_position;이 쿼리의 결과는 0이 되며, 여기서 키가 인용되지 않았음에도 불구하고 이것이 JSON5의 유효한 확장이므로 오류가 감지되지 않음을 나타냅니다.
| error_position |
|---|
| 0 |
반면에 JSON5 문자열을 정식 JSON으로 변환하려면 json() 함수를 사용할 수 있습니다. 이 함수는 JSON5 입력을 인식하고 처리하지만 정식 JSON만 출력합니다. 이는 정식 JSON을 기대하는 시스템과의 호환성을 유지할 수 있게 해줍니다. 다음은 예시입니다:
SELECT
JSON ( '{key: "value"}' ) AS canonical_json;이 쿼리의 결과는 여기서 키가 인용되어 있음을 나타내는 JSON5 형식에서 변환된 정식 JSON이 될 것입니다.
| canonical_json |
|---|
| {“key”: “value”} |
그러나 json_valid() 함수는 입력이 정식 JSON이 아니더라도 유효한 JSON5인 경우에도 계속해서 거짓을 보고한다는 점에 유의하십시오. 이는 SQLite에서 정식 JSON과 JSON5를 모두 작업할 때 중요한 구별입니다. 예를 들어 다음 쿼리를 고려하십시오:
SELECT
json_valid ( '{key: "value"}' ) AS valid_json;이 쿼리의 결과는 0이 되며, 이는 키가 인용되지 않았으므로 정식 JSON 형식에 위배되어 유효한 JSON이 아님을 나타냅니다.
| valid_json |
|---|
| {“key”: “value”} |
8. SQLite에서 JSON 작업 시 자주 발생하는 실수 및 문제 해결
SQLite에서 JSON 데이터를 처리할 때는 특정 메커니즘에 대한 깊은 이해를 통해 피할 수 있는 몇 가지 일반적인 함정이 있습니다. 예를 들어 함수의 올바른 사용 등이 그런 것들입니다. 다음은 몇 가지 주요 고려 사항입니다.
SQLite의 JSON 파싱 단계에서 JSON 데이터의 구문 오류를 디버깅하는 방법
JSON 데이터는 SQLite 데이터베이스에서 파싱 및 처리되기 위해 특정 표준 구문을 준수하고 올바르게 형식화되어야 합니다. JSON 문자열이 잘못 형식화된 경우 SQLite는 해석할 수 없으며 오류를 일으킬 것입니다. 예를 들어 괄호가 맞지 않거나, 따옴표를 잘못 사용하거나, 쉼표가 잘못 배치되었을 수 있습니다.
SQLite는 이름에서 알 수 있듯이 JSON 문자열을 검증하기 위한 json_valid() 함수를 제공합니다. json_valid() 함수는 입력이 잘 형식화된 JSON 문자열인 경우 1을 반환하고 그렇지 않으면 0을 반환합니다. 다음은 예시입니다.
SELECT json_valid('{"Name":"Naked of Truth","Year":1979}');JSON 문자열에 구문 오류가 있는 경우 json_error_position() 함수를 사용하여 오류가 발생한 문자열 내의 위치를 식별할 수 있습니다.
SELECT json_error_position('{"Name":"Naked of Truth","Year":1979}');JSON 데이터에 대해 쿼리할 때 JSON 함수의 잘못된 사용
JSON 함수의 잘못된 사용은 또 다른 일반적인 문제로서, SQLite에서 JSON 함수와 그 사용에 대한 확실한 이해가 데이터 처리를 성공적으로 수행하는 데 중요합니다. 예를 들어 SQLite의 JSON 배열의 0부터 시작하는 인덱스 시스템을 고려하지 않고 잘못된 경로를 사용하거나 사용하는 경우 오류나 잘못된 데이터 검색이 발생할 수 있습니다.
SQLite에서 JSON 함수에서 BLOB 지원 안 함
SQLite에서 JSON 함수와 함께 BLOB를 사용하려고 하지 마십시오. 현재 SQLite의 모든 JSON 함수는 인수 중 하나가 BLOB이고 유효한 JSON이 아닐 경우 오류를 발생시킵니다. SQLite는 현재 JSON의 어떤 이진 인코딩도 지원하지 않으며, 이는 잠재적인 미래 개선 사항입니다.
SQLite에서 JSON 데이터를 SQL 쿼리하는 동안 JSON 유효성 검사 방법
SQLite에서 json() 함수는 주로 따옴표를 추가하고, 필요한 문자를 이스케이프하는 등 문자열의 JSON 형식을 강제하는 데 사용됩니다. json() 함수를 잘못 사용하면 오류 포착이 부족하고 잠재적인 데이터 불일치가 발생할 수 있습니다.
그러나 이것은 JSON을 검증하도록 설계되지 않았습니다. JSON 문자열을 검증하거나 구문 오류를 찾으려면 이전에 논의된 json_valid() 및 json_error_position() 함수를 사용하십시오.
마무리
이 포괄적인 가이드에서는 JSON과 SQLite의 강력한 통합을 탐색하며 이 조합이 제공하는 광범위한 기회에 대한 통찰력을 제공했습니다. SQLite의 JSON 함수에 대한 개요와 SQL 쿼리 예제와 함께 자세한 사용 사례부터 시작했습니다.
우리는 SQLite 내에서 계층적 JSON 데이터를 처리하는 등 고급 쿼리 기술을 탐색했습니다. 여행은 JSON 데이터의 디코딩 및 관리 메커니즘으로 깊어졌으며, json_each() 및 json_tree()와 같은 SQLite 함수의 유용성을 강조했습니다. 또한 JSON 데이터를 평면화하는 것의 가치를 다루었습니다. 이는 데이터 처리를 효율적으로 만듭니다.
그런 다음, 종종 간과되는 중요한 영역으로 이동했습니다: 인덱싱을 통한 성능 향상. 이 강력한 최적화는 쿼리 성능을 크게 가속화하고 JSON으로 SQLite 경험을 향상시킬 수 있습니다. 그런 다음 더 많은 유연성을 제공하는 차세대 JSON5 확장을 논의했습니다. JSON 데이터 형식.
마지막으로, 일반적인 실수와 문제 해결 팁을 다루어 SQLite의 JSON을 통한 여행을 부드럽게 하고, JSON 구문의 정확성과 SQLite JSON 함수의 적절한 사용의 중요성을 강조했습니다.
기억하세요, 학습과 실험은 SQLite에서 JSON의 전체 잠재력을 활용하는 열쇠입니다. 이러한 기술을 프로젝트에 적용할 때 유사한 여정을 하는 다른 사람들을 돕기 위해 경험을 공유하세요. 그러니 SQLite에서 JSON으로 학습과 경계 확장을 계속하세요. 좋은 JSON 사용 되세요!
Source:
https://dzone.com/articles/how-to-master-advanced-json-querying-in-sqlite