













소개
컨테이너를 관리하기 위해 Kubernetes를 점 increasingly 사용하는 조직들은 분산 시스템의 상태를 모니터링할 수 있는 솔루션이 필요합니다. 이를 위해 Prometheus를 도입하게 되는데, 이는 K8s 공간에서 컨테이너화된 응용 프로그램을 모니터링하기 위한 강력한 오픈 소스 도구입니다.
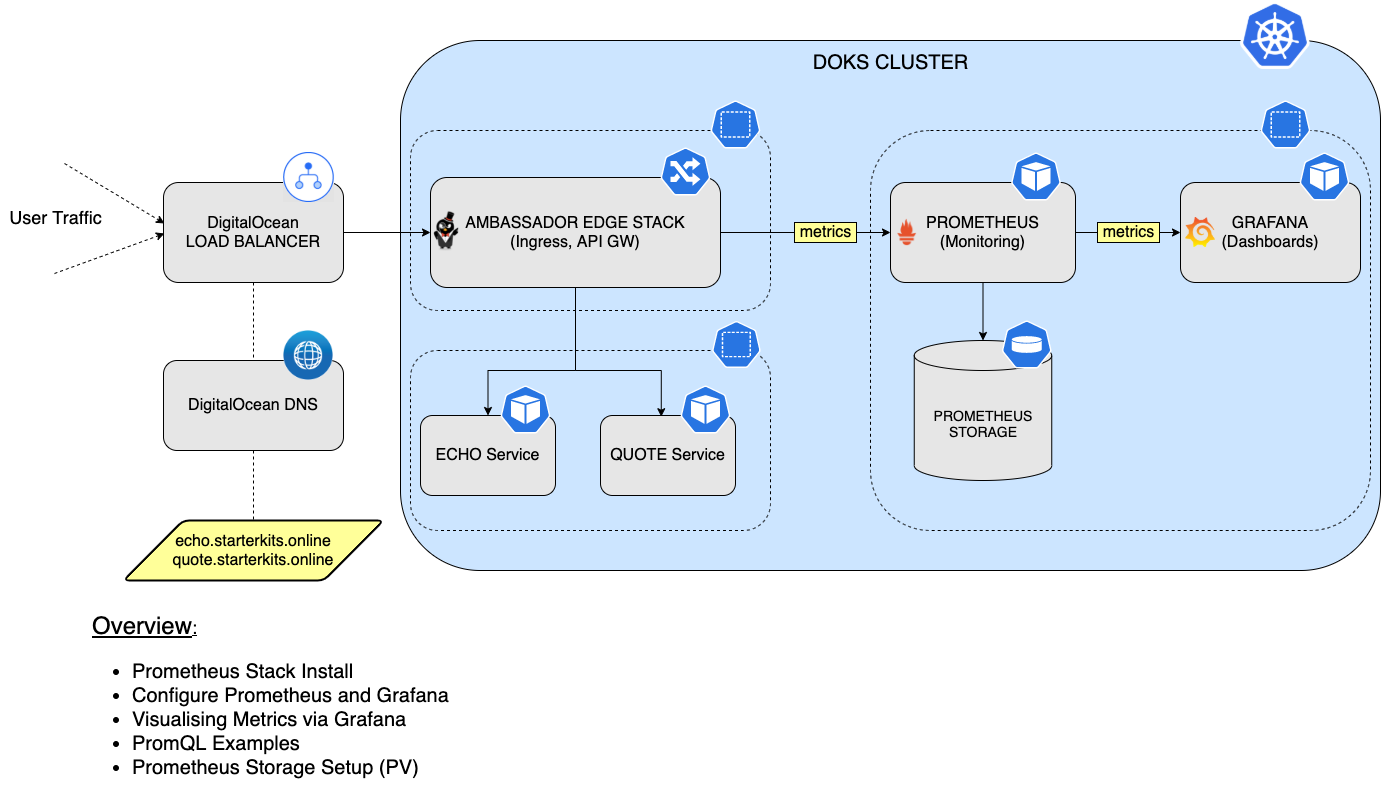
이 튜토리얼에서는 DOKS 클러스터의 모든 pod와 Kubernetes 클러스터 상태 메트릭을 모니터링하기 위해 Prometheus 스택을 설치하고 구성하는 방법을 배우게 됩니다. 그런 다음 Prometheus를 Grafana와 연결하여 모든 메트릭을 시각화하고 PromQL 언어를 사용하여 쿼리를 수행할 것입니다. 마지막으로 Prometheus 인스턴스에 지속적인 저장소를 구성하여 DOKS 클러스터 및 응용 프로그램 메트릭 데이터를 모두 저장할 것입니다.
목차
- 필수 조건
- 단계 1 – Prometheus 스택 설치
- 단계 2 – Prometheus와 Grafana 구성
- 단계 3 – PromQL (Prometheus 쿼리 언어)
- 단계 4 – Grafana를 사용하여 메트릭 시각화
- 단계 5 – Prometheus를 위한 지속적인 저장소 구성
- 단계 6 – Grafana를 위한 지속적인 저장소 구성
- 결론
전제 조건
이 튜토리얼을 완료하기 위해 다음이 필요합니다:
- A Git client to clone the Starter Kit repository.
- Prometheus 스택 배포 및 업그레이드 관리를 위한
- Kubernetes 상호 작용을 위한
- 예제 테스트에 대한 Curl
- 클러스터에 배포된 Emojivoto 샘플 앱. 해당 리포지토리 README의 단계를 따르십시오.
kubectl 컨텍스트가 Kubernetes 클러스터를 가리키도록 구성되어 있는지 확인하십시오. DOKS 설정 튜토리얼의 단계 3 – DOKS 클러스터 생성를 참조하십시오.
단계 1 – 프로메테우스 스택 설치
이 단계에서는 쿠버네티스를 위한 의견이 분분한 완전한 모니터링 스택인 kube-prometheus 스택을 설치합니다. 이 스택에는 프로메테우스 오퍼레이터, kube-state-metrics, 미리 빌드된 매니페스트, 노드 익스포터, 메트릭 API, 알림 관리자 및 Grafana가 포함됩니다.
이 작업을 수행하기 위해 Helm 패키지 관리자를 사용할 것입니다. Helm 차트는 여기에서 공부할 수 있습니다.
먼저, Starter Kit 리포지토리를 복제하고 로컬 복사본의 디렉토리를 변경하십시오.
다음으로, Helm 리포지토리를 추가하고 사용 가능한 차트를 나열하십시오:
출력은 다음과 유사합니다:
NAME CHART VERSION APP VERSION DESCRIPTION
prometheus-community/alertmanager 0.18.1 v0.23.0 The Alertmanager handles alerts sent by client ...
prometheus-community/kube-prometheus-stack 35.5.1 0.56.3 kube-prometheus-stack collects Kubernetes manif...
...
관심 있는 차트는 클러스터에 프로메테우스, Promtail, Alertmanager 및 Grafana를 설치할 prometheus-community/kube-prometheus-stack입니다. 이 차트에 대한 자세한 내용은 kube-prometheus-stack 페이지를 방문하십시오.
그럼 선택한 편집기(가능하면 YAML 린트 지원)를 사용하여 스타터 킷 저장소에서 제공하는 04-setup-observability/assets/manifests/prom-stack-values-v35.5.1.yaml 파일을 열고 검사하세요. 기본적으로 kubeSched와 etcd 메트릭은 비활성화되어 있습니다. 이러한 구성 요소는 DOKS에 의해 관리되며 Prometheus에서 액세스할 수 없습니다. 저장소가 emptyDir로 설정되어 있습니다. 이는 Prometheus pod가 재시작되면 저장소가 삭제될 것을 의미합니다. (나중에 Prometheus에 대한 지속적인 저장소 구성 섹션에서 이를 수정할 것입니다).
[선택 사항] 만약 디지털오션 관리 쿠버네티스 클러스터 설정 가이드의 단계 4 – 관측용 전용 노드 추가를 따르셨다면, 스타터 킷 저장소에서 제공하는 04-setup-observability/assets/manifests/prom-stack-values-v35.5.1.yaml 파일을 편집하여 Grafana와 Prometheus 모두에 대한 affinity 섹션의 주석을 해제해야 합니다.
위 구성에 대한 설명:
preferredDuringSchedulingIgnoredDuringExecution– 스케줄러는 규칙을 충족하는 노드를 찾으려고 합니다. 일치하는 노드가 없으면 스케줄러는 여전히 Pod를 스케줄합니다.-
– 기준에 따라 특정 노드를 일치시키기 위해 사용되는 선택기입니다. 위의 예에서는 스케줄러에게 작업 부하 (예: Pod)를 키 – preferred및 값 –observability를 사용하여 라벨이 지정된 노드에 배치하도록 지시합니다.
마지막으로 Helm을 사용하여 kube-prometheus-stack을 설치하십시오:
A specific version of the Helm chart is used. In this case 35.5.1 was picked, which maps to the 0.56.3 version of the application (see output from Step 2.). It’s a good practice to lock on a specific version. This helps to have predictable results and allows versioning control via Git.
–create-namespace \
이제 Prometheus 스택 Helm 릴리스 상태를 확인하십시오:
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
kube-prom-stack monitoring 1 2022-06-07 09:52:53.795003 +0300 EEST deployed kube-prometheus-stack-35.5.1 0.56.3
출력은 다음과 유사합니다. STATUS 열 값에 유의하십시오 – deployed로 표시되어야 합니다.
Prometheus에 사용 가능한 Kubernetes 리소스를 확인하십시오:
NAME READY STATUS RESTARTS AGE
pod/alertmanager-kube-prom-stack-kube-prome-alertmanager-0 2/2 Running 0 3m3s
pod/kube-prom-stack-grafana-8457cd64c4-ct5wn 2/2 Running 0 3m5s
pod/kube-prom-stack-kube-prome-operator-6f8b64b6f-7hkn7 1/1 Running 0 3m5s
pod/kube-prom-stack-kube-state-metrics-5f46fffbc8-mdgfs 1/1 Running 0 3m5s
pod/kube-prom-stack-prometheus-node-exporter-gcb8s 1/1 Running 0 3m5s
pod/kube-prom-stack-prometheus-node-exporter-kc5wz 1/1 Running 0 3m5s
pod/kube-prom-stack-prometheus-node-exporter-qn92d 1/1 Running 0 3m5s
pod/prometheus-kube-prom-stack-kube-prome-prometheus-0 2/2 Running 0 3m3s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 3m3s
service/kube-prom-stack-grafana ClusterIP 10.245.147.83 <none> 80/TCP 3m5s
service/kube-prom-stack-kube-prome-alertmanager ClusterIP 10.245.187.117 <none> 9093/TCP 3m5s
service/kube-prom-stack-kube-prome-operator ClusterIP 10.245.79.95 <none> 443/TCP 3m5s
service/kube-prom-stack-kube-prome-prometheus ClusterIP 10.245.86.189 <none> 9090/TCP 3m5s
service/kube-prom-stack-kube-state-metrics ClusterIP 10.245.119.83 <none> 8080/TCP 3m5s
service/kube-prom-stack-prometheus-node-exporter ClusterIP 10.245.47.175 <none> 9100/TCP 3m5s
service/prometheus-operated ClusterIP None <none> 9090/TCP 3m3s
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
daemonset.apps/kube-prom-stack-prometheus-node-exporter 3 3 3 3 3 <none> 3m5s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/kube-prom-stack-grafana 1/1 1 1 3m5s
deployment.apps/kube-prom-stack-kube-prome-operator 1/1 1 1 3m5s
deployment.apps/kube-prom-stack-kube-state-metrics 1/1 1 1 3m5s
NAME DESIRED CURRENT READY AGE
replicaset.apps/kube-prom-stack-grafana-8457cd64c4 1 1 1 3m5s
replicaset.apps/kube-prom-stack-kube-prome-operator-6f8b64b6f 1 1 1 3m5s
replicaset.apps/kube-prom-stack-kube-state-metrics-5f46fffbc8 1 1 1 3m5s
NAME READY AGE
statefulset.apps/alertmanager-kube-prom-stack-kube-prome-alertmanager 1/1 3m3s
statefulset.apps/prometheus-kube-prom-stack-kube-prome-prometheus 1/1 3m3s
다음과 같은 리소스가 배포되어 있어야 합니다: prometheus-node-exporter, kube-prome-operator, kube-prome-alertmanager, kube-prom-stack-grafana, 및 kube-state-metrics. 출력은 다음과 유사합니다:
그런 다음, 로컬 머신으로 포트 포워딩하여 Grafana에 연결할 수 있습니다 (기본 자격 증명 사용: admin/prom-operator – prom-stack-values-v35.5.1 파일 참조):
default login/password로 Grafana를 공용 네트워크에 노출하지 마십시오 (예: 인그레스 매핑 또는 LB 서비스 생성).
Grafana 설치에는 여러 대시 보드가 함께 제공됩니다. localhost:3000에서 웹 브라우저를 엽니다. 들어간 후에는 대시 보드 -> 찾아보기로 이동하여 다양한 대시 보드를 선택할 수 있습니다.
다음 부분에서는 Prometheus를 설정하여 모니터링 대상을 찾는 방법을 알아볼 것입니다. 예를 들어 Emojivoto 샘플 애플리케이션을 사용할 것입니다. 또한 ServiceMonitor가 무엇인지도 배우게 될 것입니다.
단계 2 – Prometheus 및 Grafana 구성
이미 클러스터에 Prometheus와 Grafana를 배포했습니다. 이 단계에서는 ServiceMonitor를 사용하는 방법을 알아보게 될 것입니다. ServiceMonitor는 Prometheus에게 모니터링할 새 대상을 찾는 방법 중 하나입니다.
Emojivoto 배포는 전제 조건 섹션의 단계 5에서 기본적으로 포트 8801을 통해 /metrics 엔드포인트를 제공합니다.
다음으로, Prometheus가 소비하기 위해 메트릭 데이터를 노출하는 Emojivoto 서비스를 찾아보겠습니다. 문제의 서비스는 emoji-svc와 voting-svc입니다(emojivoto 네임 스페이스를 사용하는 것에 유의하세요):
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
emoji-svc ClusterIP 10.245.135.93 <none> 8080/TCP,8801/TCP 22h
voting-svc ClusterIP 10.245.164.222 <none> 8080/TCP,8801/TCP 22h
web-svc ClusterIP 10.245.61.229 <none> 80/TCP 22h
결과는 다음과 같습니다:
다음으로 메트릭을 검사하기 위해 port-forward를 수행하십시오:
노출된 지표는 웹 브라우저를 통해 localhost로 탐색하거나 curl을 통해 시각화할 수 있습니다:
출력은 다음과 유사합니다:
go_gc_duration_seconds{quantile="0"} 5.317e-05
go_gc_duration_seconds{quantile="0.25"} 0.000105305
go_gc_duration_seconds{quantile="0.5"} 0.000138168
go_gc_duration_seconds{quantile="0.75"} 0.000225651
go_gc_duration_seconds{quantile="1"} 0.016986437
go_gc_duration_seconds_sum 0.607979843
go_gc_duration_seconds_count 2097
# TYPE go_gc_duration_seconds summary
voting-svc 서비스의 메트릭을 검사하려면 emoji-svc 포트 포워드를 중지하고 두 번째 서비스에 대해 동일한 단계를 수행합니다.
- 그런 다음, Prometheus를 Emojivoto 메트릭 서비스에 연결합니다. 이를 수행하는 여러 가지 방법이 있습니다:
- <static_config> – 대상 목록과 공통 레이블 세트를 지정하는 것을 허용합니다.
- <kubernetes_sd_config> – Kubernetes REST API에서 스크래핑 대상을 검색하고 항상 클러스터 상태와 동기화할 수 있습니다.
Prometheus Operator – CRD를 통해 Kubernetes 클러스터 내에서 Prometheus 모니터링을 간소화합니다.
다음으로, Prometheus Operator가 노출한 ServiceMonitor CRD를 사용하여 모니터링을 위한 새 대상을 정의합니다.
먼저, Starter Kit Git 리포지토리가 클론된 디렉토리로 이동하십시오(이미 이동한 경우 제외):
다음으로, 선택한 텍스트 편집기(가능하면 YAML 린트 지원이 있는 것이 좋습니다)를 사용하여 스타터 킷 리포지토리에서 제공하는 04-setup-observability/assets/manifests/prom-stack-values-v35.5.1.yaml 파일을 엽니다. additionalServiceMonitors 섹션 주변의 주석을 제거하십시오. 출력은 다음과 유사합니다:
- 위의 구성에 대한 설명:
selector -> matchExpressions–ServiceMonitor에게 모니터링할 서비스를 알려줍니다. 이는 앱 라벨 키와 값이emoji-svc와voting-svc인 모든 서비스를 대상으로합니다. 라벨은 다음을 실행하여 가져올 수 있습니다:kubectl get svc --show-labels -n emojivotonamespaceSelector– 여기서는Emojivoto가 배포된 네임스페이스를 일치시키려고합니다.
endpoints -> port – 모니터링할 서비스의 포트를 참조합니다.
마지막으로 Helm을 사용하여 변경 사항을 적용하십시오:
다음으로, Prometheus에서 스크래핑을 위해 Emojivoto 대상이 추가되었는지 확인하십시오. 포트 9090에서 Prometheus에 대한 포트 포워드를 생성하십시오:
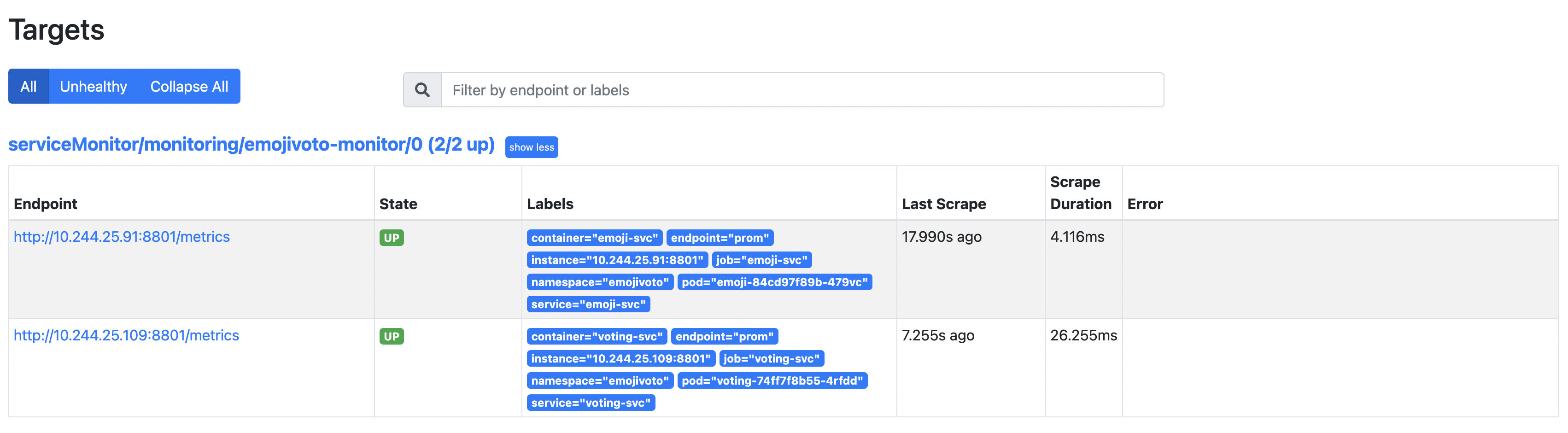
localhost:9090에서 웹 브라우저를 엽니다. 그런 다음 상태 -> 대상 페이지로 이동하여 결과를 검사하십시오 (serviceMonitor/monitoring/emojivoto-monitor/0 경로에 주목하십시오):
Emojivoto 배포는 메트릭 엔드포인트를 노출하는 서비스가 2개이므로 발견된 대상 아래에 2개의 항목이 있습니다.
다음 단계에서는 시작할 때 필요한 몇 가지 간단한 예제와 함께 PromQL을 발견할 것입니다.
단계 3 – PromQL (Prometheus Query Language)
이 단계에서는 Prometheus Query Language (PromQL)의 기본을 배우게 될 것입니다. PromQL을 사용하면 DOKS 클러스터에서 모든 Pod 및 애플리케이션에서 나오는 다양한 지표에 대한 쿼리를 수행할 수 있습니다.
PromQL은 Prometheus를 위해 특별히 구축된 DSL 또는 도메인별 언어로, 지표에 대한 쿼리를 수행할 수 있습니다. 전체 표현식은 최종 값을 정의하며, 중첩된 표현식은 인수 및 피연산자에 대한 값을 나타냅니다. 더 깊이 들어가는 설명은 공식 PromQL 페이지를 참조하십시오.
다음으로, Emojivoto 메트릭 중 하나인 emojivoto_votes_total을 검사할 것입니다. 이는 총 투표수를 나타내는 카운터 값으로, Emojivoto 투표 엔드포인트에 대한 각 요청마다 증가합니다.
먼저, 포트 9090에서 Prometheus에 대한 포트 포워드를 생성하십시오:
다음으로, 표현 브라우저를 엽니다.
emojivoto_votes_total{container="voting-svc", emoji=":100:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 20
emojivoto_votes_total{container="voting-svc", emoji=":bacon:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 17
emojivoto_votes_total{container="voting-svc", emoji=":balloon:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 21
emojivoto_votes_total{container="voting-svc", emoji=":basketball_man:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 10
emojivoto_votes_total{container="voting-svc", emoji=":beach_umbrella:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 10
emojivoto_votes_total{container="voting-svc", emoji=":beer:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 11
쿼리 입력 필드에 emojivoto_votes_total을 붙여넣고 enter 키를 누르십시오. 출력은 다음과 유사합니다:
홈페이지에서 100 이모지를 클릭하여 해당 이모지에 투표하십시오.
emojivoto_votes_total{container="voting-svc", emoji=":100:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 21
emojivoto_votes_total{container="voting-svc", emoji=":bacon:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 17
emojivoto_votes_total{container="voting-svc", emoji=":balloon:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 21
emojivoto_votes_total{container="voting-svc", emoji=":basketball_man:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 10
emojivoto_votes_total{container="voting-svc", emoji=":beach_umbrella:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 10
emojivoto_votes_total{container="voting-svc", emoji=":beer:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 11
3단계의 쿼리 결과 페이지로 이동하여 실행 버튼을 클릭하십시오. 100 이모지의 카운터가 하나 증가하는 것을 확인할 수 있습니다. 출력은 다음과 유사합니다:
PromQL은 벡터라고 불리는 유사한 데이터를 그룹화합니다. 위에서 볼 수 있듯이, 각 벡터는 서로를 구별하는 속성 집합을 가지고 있습니다. 관심 있는 속성을 기준으로 결과를 그룹화할 수 있습니다. 예를 들어, voting-svc 서비스에서 온 요청에만 관심이 있다면, 쿼리 필드에 다음을 입력하십시오:
emojivoto_votes_total{container="voting-svc", emoji=":100:", endpoint="prom", instance="10.244.6.91:8801", job="voting-svc", namespace="emojivoto", pod="voting-6548959dd7-hssh2", service="voting-svc"} 492
emojivoto_votes_total{container="voting-svc", emoji=":bacon:", endpoint="prom", instance="10.244.6.91:8801", job="voting-svc", namespace="emojivoto", pod="voting-6548959dd7-hssh2", service="voting-svc"} 532
emojivoto_votes_total{container="voting-svc", emoji=":balloon:", endpoint="prom", instance="10.244.6.91:8801", job="voting-svc", namespace="emojivoto", pod="voting-6548959dd7-hssh2", service="voting-svc"} 521
출력은 다음과 유사합니다 (조건과 일치하는 결과만 선택됨에 유의하세요):
위 결과는 메트릭을 발생시키는 Emojivoto 배포의 각 Pod에 대한 총 요청을 보여줍니다 (2개의 메트릭으로 구성됨).
위는 PromQL이 무엇이며 무엇을 할 수 있는지에 대한 매우 간단한 소개입니다. 그러나 메트릭을 계산하거나 미리 정의된 간격으로 비율을 계산하는 등 더 많은 작업을 수행할 수 있습니다. 더 많은 언어 기능에 대해서는 공식 PromQL 페이지를 방문하십시오.
다음 단계에서는 Grafana를 사용하여 Emojivoto 샘플 애플리케이션의 메트릭을 시각화하는 방법을 배우게 됩니다.
Prometheus에는 데이터를 시각화하는 데 사용할 수 있는 내장 지원이 있지만, 이를 수행하는 더 나은 방법은 모니터링 및 관측을 위한 오픈 소스 플랫폼 인 Grafana를 통해 하는 것입니다. 이 플랫폼은 클러스터 상태를 시각화하고 탐색할 수 있게 해줍니다.
공식 페이지에서는 다음을 할 수 있다고 설명되어 있습니다:
데이터를 쿼리하고 시각화하고 경고를 생성하고 이해하십시오. 저장 위치와 관계없이 데이터를.
그라파나를 설치하려면 추가 단계가 필요하지 않습니다. 왜냐하면 단계 1 – 프로메테우스 스택 설치에서 이미 그라파나를 설치했기 때문입니다. 아래와 같이 포트 포워딩만 수행하면 됩니다. 그리고 대시 보드에 즉시 액세스할 수 있습니다 (기본 자격 증명 : admin/prom-monitor):
Emojivoto 지표를 모두 보려면 Grafana에 기본 설치된 대시 보드 중 하나를 사용하게 됩니다.
Grafana 대시 보드 섹션으로 이동합니다.
다음으로, 일반/Kubernetes/컴퓨팅 리소스/네임 스페이스(포드) 대시 보드를 검색하고 액세스합니다.
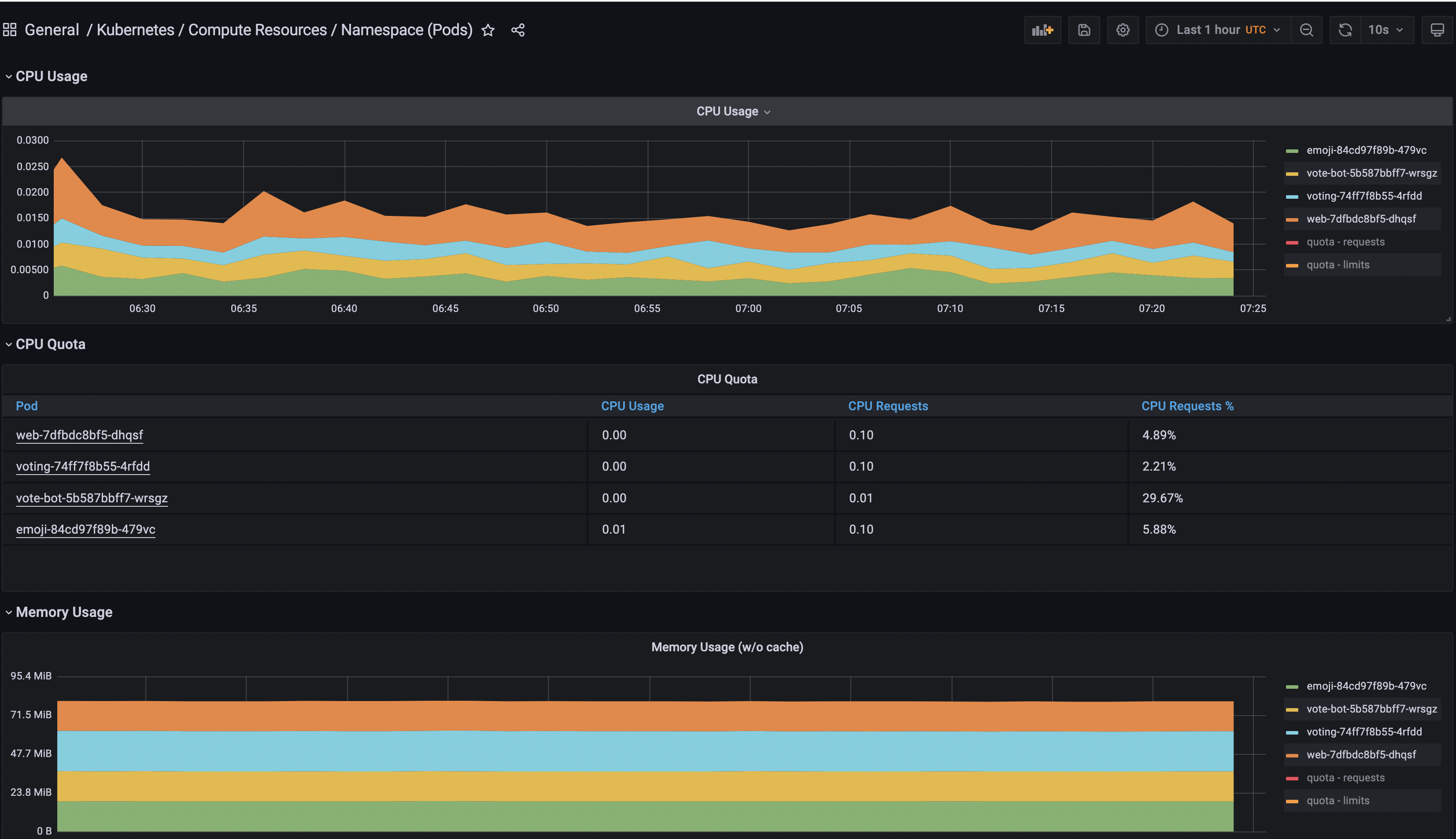
마지막으로 Prometheus 데이터 소스를 선택하고 emojivoto 네임 스페이스를 추가하십시오.
Grafana에서 다른 데이터 소스를 시각화하기 위해 패널을 추가하고 범위에 따라 그룹화할 수 있습니다. 또한 Grafana kube-mixin 프로젝트에서 Kubernetes용 사용 가능한 대시보드를 탐색할 수 있습니다.
다음 단계에서는 DOKS와 응용 프로그램 메트릭을 서버 재시작이나 클러스터 실패 시에도 유지하기 위해 DigitalOcean 블록 스토리지를 사용하여 Prometheus에 대한 영구 저장소를 구성합니다.
단계 5 – Prometheus를 위한 영구 저장소 구성
이 단계에서는 Prometheus에 대한 영구 저장소를 활성화하여 메트릭 데이터가 서버 재시작 시에 유지되거나 클러스터 실패 시에 유지되는 방법을 배웁니다.
먼저 진행하려면 스토리지 클래스가 필요합니다. 사용 가능한 스토리지 클래스를 확인하려면 다음 명령을 실행하세요.
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
do-block-storage (default) dobs.csi.digitalocean.com Delete Immediate true 4d2h
출력은 다음과 유사해야 합니다. DigitalOcean 블록 스토리지를 사용할 수 있다는 것을 주목하세요.
다음으로, 시작 키트 Git 저장소가 이미 복제된 디렉토리로 변경하십시오.
다음으로, 04-setup-observability/assets/manifests/prom-stack-values-v35.5.1.yaml 파일을 선택한 텍스트 편집기(가능하면 YAML 린트 지원이 있는 것이 좋습니다)로 엽니다. storageSpec 줄을 찾아서 Prometheus에 필요한 섹션을 주석 처리 해제하십시오. storageSpec 정의는 다음과 같아야 합니다:
- 위 설정에 대한 설명은 다음과 같습니다:
volumeClaimTemplate– 새로운 PVC를 정의합니다.storageClassName– 스토리지 클래스를 정의합니다(kubectl get storageclass명령어 출력에서 동일한 값을 사용해야 함).
resources – 스토리지 요청 값을 설정합니다. 이 경우, 새 볼륨에 대해 총 5 기가바이트의 용량을 요청합니다.
마지막으로 Helm을 사용하여 설정을 적용하십시오:
위 단계를 완료한 후 PVC 상태를 확인하십시오:
NAME STATUS VOLUME CAPACITY ACCESS MODES AGE
kube-prome-prometheus-0 Bound pvc-768d85ff-17e7-4043-9aea-4929df6a35f4 5Gi RWO do-block-storage 4d2h
A new Volume should appear in the Volumes web page from your DigitalOcean account panel:

출력은 다음과 유사합니다. STATUS 열은 Bound를 표시해야 합니다.
단계 6 – Grafana를 위한 지속적인 저장소 구성
이 단계에서는 그라파나에 대한 지속적인 저장을 활성화하여 서버 재시작이나 클러스터 장애 발생 시에도 그래프가 유지되도록 합니다. 디지털오션 블록 스토리지를 사용하여 5 Gi 지속적인 볼륨 클레임 (PVC)을 정의합니다. 다음 단계는 프로메테우스를 위한 지속적인 저장 구성 단계 5와 동일합니다.
먼저 선택한 텍스트 편집기를 열고 스타터 킷 저장소에서 제공된 04-setup-observability/assets/manifests/prom-stack-values-v35.5.1.yaml 파일을 엽니다(가능하면 YAML 린트 지원이 있는 텍스트 편집기를 사용하십시오). 그라파나의 지속성 저장 섹션은 다음과 같아야합니다:
그런 다음 Helm을 사용하여 설정을 적용합니다:
위의 단계를 완료한 후 PVC 상태를 확인하십시오:
NAME STATUS VOLUME CAPACITY ACCESS MODES AGE
kube-prom-stack-grafana Bound pvc-768d85ff-17e7-4043-9aea-4929df6a35f4 5Gi RWO do-block-storage 4d2h
A new Volume should appear in the Volumes web page from your DigitalOcean account panel:

출력은 다음과 유사해야합니다. STATUS 열은 Bound를 표시해야합니다.
- 귀하의 요구에 따라 볼륨에 필요한 크기를 계산하려면 공식 문서의 권고사항과 공식을 따르십시오:
- 프로메테우스는 샘플 당 평균 1-2바이트만 저장합니다. 따라서 프로메테우스 서버의 용량을 계획하기 위해 대략적인 공식을 사용할 수 있습니다:
필요한 디스크 공간 = 보존 시간(초) * 초당 소화된 샘플 수 * 샘플 당 바이트 수
소화된 샘플의 속도를 줄이려면 스크랩하는 시계열의 수를 줄이거나(더 적은 대상 또는 대상 당 더 적은 시리즈), 스크랩 간격을 늘릴 수 있습니다. 그러나 시리즈의 수를 줄이는 것이 시리즈 내 샘플의 압축으로 인해 더 효과적일 가능성이 높습니다.