













면책 조항: 블로그에 표현된 모든 의견과 견해는 저자에게만 속하며 저자의 고용주 또는 다른 그룹이나 개인에게 반드시 속하지 않습니다. 이 기사는 어떤 클라우드/데이터 관리 플랫폼을 홍보하는 것이 아닙니다. 모든 이미지와 API는 Azure/Databricks 웹사이트에서 공개적으로 제공됩니다..
Databricks Lakehouse 모니터링이란 무엇인가?
제 다른 기사에서 Databricks와 Unity Catalog가 무엇인지, 스크립트를 사용하여 카탈로그를 처음부터 만드는 방법을 설명했습니다. 이번 기사에서는 Databricks 플랫폼의 일부로 제공되는 Lakehouse 모니터링 기능과 스크립트를 사용하여 해당 기능을 활성화하는 방법에 대해 설명하겠습니다.
Lakehouse 모니터링은 Lakehouse의 Delta Live Tables에 대한 데이터 프로파일링 및 데이터 품질 관련 지표를 제공합니다. Databricks Lakehouse 모니터링은 데이터 양의 변화, 수치 분포 변화, 열의 null 및 0의 비율, 시간에 따른 범주적 이상 탐지와 같은 데이터에 대한 종합적인 통찰력을 제공합니다.
왜 Lakehouse 모니터링을 사용해야 할까요?
데이터 및 ML 모델 성능을 모니터링하면 데이터 및 모델 성능의 품질과 일관성을 시간이 지남에 따라 추적하고 확인하는 데 도움이 되는 양적 측정값을 제공합니다.
다음은 주요 기능의 내용입니다:
- 데이터 품질 및 데이터 무결성 추적: 데이터의 흐름을 파이프라인을 통해 추적하여 데이터 무결성을 보장하고 데이터가 시간이 지남에 따라 어떻게 변경되었는지에 대한 가시성을 제공합니다. 수치 열의 90번째 백분위수, 널 및 제로 열의 비율 등을 추적합니다.
- 시간에 따른 데이터 드리프트: 현재 데이터와 알려진 베이스라인 또는 데이터의 연속적인 시간 창 간의 데이터 드리프트를 감지하는 메트릭을 제공합니다.
- 데이터의 통계적 분포: 시간이 지남에 따른 데이터의 수치적 분포 변화를 제공하여 범주형 열의 값 분포 및 이전과의 차이를 설명합니다.
- ML 모델 성능 및 예측 드리프트: ML 모델 입력, 예측 및 성능 트렌드를 시간에 따라 제공합니다.
작동 방식
Databricks Lakehouse Monitoring은 다음 종류의 분석을 제공합니다: 시계열, 스냅샷 및 추론.
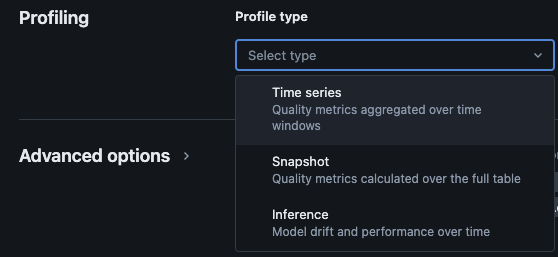
모니터링을 위한 프로필 유형
Unity 카탈로그에서 테이블에 Lakehouse 모니터링을 활성화하면 지정된 모니터링 스키마에 두 개의 테이블이 생성됩니다. 데이터의 통계 및 프로필 정보를 시간에 따라 포괄적으로 얻기 위해 테이블에서 쿼리하고 대시보드를 만들고(데이터브릭스는 기본 구성 가능한 대시보드를 제공합니다) 테이블에 대한 알림을 만들 수 있습니다.
- 드리프트 메트릭 테이블: 드리프트 메트릭 테이블에는 데이터의 시간 경과에 따른 통계 정보가 포함되어 있습니다. 카운트 차이, 평균 차이, % 널 및 0의 차이 등과 같은 정보를 캡처합니다.
- 프로필 메트릭 테이블: 프로필 메트릭 테이블에는 각 열과 각 시간 창, 슬라이스, 그룹화 열의 조합에 대한 요약 통계가 포함되어 있습니다. 추론 로그 분석을 위해 분석 테이블에는 모델 정확도 메트릭도 포함됩니다.
스크립트를 통해 Lakehouse 모니터링 활성화하는 방법
사전 조건
- Unity 카탈로그, 스키마 및 델타 라이브 테이블이 있어야 합니다.
- 사용자는 델타 라이브 테이블의 소유자여야 합니다.
- 개인 Azure Databricks 클러스터의 경우, 서버리스 컴퓨팅에서의 개인 연결이 구성되어 있어야 합니다.
단계 1: 노트북 만들기 및 데이터브릭스 SDK 설치
Databricks 작업 공간에 노트북을 만듭니다. 작업 공간에 노트북을 만들려면 사이드바의 “+” 새로 만들기를 클릭한 다음 노트북을 선택합니다.
빈 노트북이 작업 공간에 열립니다. 노트북 언어로 Python이 선택되어 있는지 확인하세요.
아래의 코드 스니펫을 노트북 셀에 복사하여 실행합니다.
%pip install databricks-sdk --upgrade
dbutils.library.restartPython()
단계2: 변수 생성
아래의 코드 스니펫을 노트북 셀에 복사하여 실행합니다.
catalog_name = "catalog_name" #Replace the catalog name as per your environment.
schema_name = "schema_name" #Replace the schema name as per your environment.
monitoring_schema = "monitoring_schema" #Replace the monitoring schema name as per your preferred name.
refresh_schedule_cron = "0 0 0 * * ?" #Replace the cron expression for the refresh schedule as per your need.
단계3: 모니터링 스키마 생성
아래의 코드 스니펫을 노트북 셀에 복사하여 실행합니다. 이 스니펫은 이미 존재하지 않는 경우 모니터링 스키마를 생성합니다.
%sql
USE CATALOG `${catalog_name}`;
CREATE SCHEMA IF NOT EXISTS `${monitoring_schema}`
단계 4: 모니터 생성
아래의 코드 스니펫을 노트북 셀에 복사하여 실행합니다. 이 스니펫은 스키마 내의 모든 테이블에 대해 Lakehouse 모니터링을 생성합니다.
import time
from databricks.sdk import WorkspaceClient
from databricks.sdk.errors import NotFound, ResourceDoesNotExist
from databricks.sdk.service.catalog import MonitorSnapshot, MonitorInfo, MonitorInfoStatus, MonitorRefreshInfoState, MonitorMetric, MonitorCronSchedule
databricks_url = 'https://adb-xxxx.azuredatabricks.net/' # replace the url with your workspace url
api_token = 'xxxx' # replace the token with your personal access token for the workspace. Best practice - store the token in Azure KV and retrieve the token using key-vault scope.
w = WorkspaceClient(host=databricks_url, token=api_token)
all_tables = list(w.tables.list(catalog_name=catalog_name, schema_name=schema_name))
for table in all_tables:
table_name = table.full_name
info = w.quality_monitors.create(
table_name = table_name,
assets_dir = "/Shared/databricks_lakehouse_monitoring/", # Creates monitoring dashboards in this location
output_schema_name = f"{catalog_name}.{monitoring_schema}",
snapshot = MonitorSnapshot(),
schedule = MonitorCronSchedule(quartz_cron_expression = refresh_schedule_cron, timezone_id = "PST") # update timezone as per your need.
)
# Wait for monitor to be created
while info.status == MonitorInfoStatus.MONITOR_STATUS_PENDING:
info = w.quality_monitors.get(table_name=table_name)
time.sleep(10)
assert info.status == MonitorInfoStatus.MONITOR_STATUS_ACTIVE, "Error creating monitor"
유효성 검사
스크립트가 성공적으로 실행된 후에는 카탈로그 -> 스키마 -> 테이블로 이동하여 테이블의 “품질” 탭으로 이동하여 모니터링 세부 정보를 볼 수 있습니다.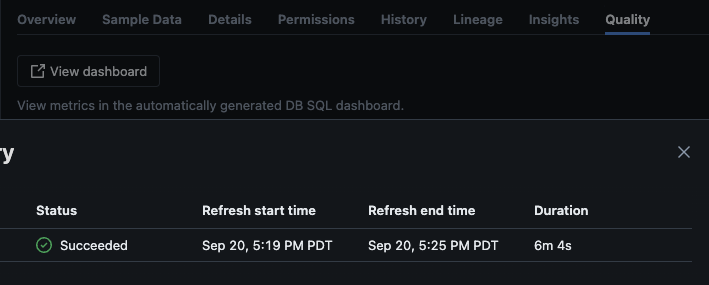
“대시보드 보기” 버튼을 클릭하면 모니터링 페이지의 왼쪽 상단에 기본 모니터링 대시보드가 열립니다. 처음에는 데이터가 비어 있을 것입니다. 일정한 주기로 모니터링이 실행되면 시간이 지남에 따라 모든 통계, 프로필 및 데이터 품질 값이 채워질 것입니다.
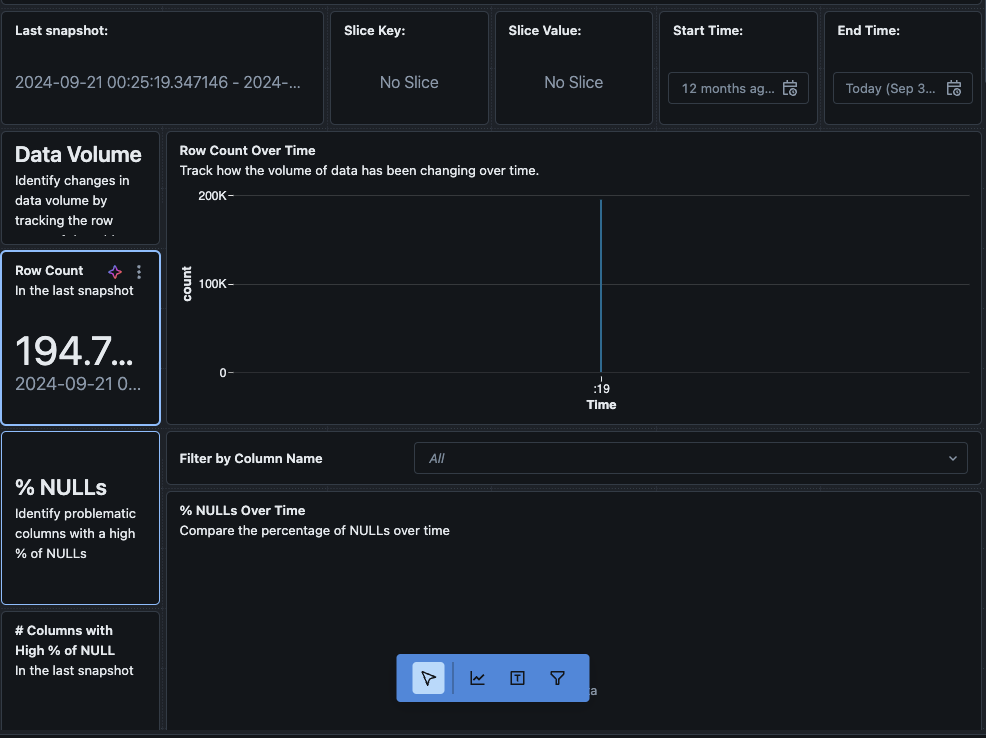
대시보드에서 “데이터” 탭으로 이동할 수도 있습니다. Databricks는 드리프트 및 기타 프로필 정보를 얻기 위한 쿼리 목록을 제공합니다. 또한 데이터의 종합적인 보기를 얻기 위해 필요에 따라 자체 쿼리를 만들 수도 있습니다.
결론
Databricks Lakehouse Monitoring은 데이터 품질, 프로필 지표 추적 및 시간 경과에 따른 데이터 드리프트 감지를 위한 구조화된 방법을 제공합니다. 이 기능을 스크립트를 통해 활성화함으로써 팀은 데이터 동작에 대한 통찰력을 얻고 데이터 파이프라인의 신뢰성을 보장할 수 있습니다. 이 기사에서 설명한 설정 프로세스는 데이터 무결성을 유지하고 지속적인 데이터 분석 노력을 지원하는 기초를 제공합니다.
Source:
https://dzone.com/articles/how-to-enable-azure-databricks-lakehouse-monitoring