













파트 1에서 우리는 여러 중요한 주제를 다루었습니다. 이를 읽어보시는 것을 추천드립니다, 다음 부분은 이를 기반으로 합니다.
간단한 복습으로, 파트 1에서 우리는 데이터를 거시적인 관점에서 고려하고 내부 데이터와 외부 데이터를 구분했습니다. 또한 스키마와 데이터 계약에 대해 논의하며 이들이 우리의 스트림을 시간에 따라 협상, 변경 및 발전시키는 수단을 제공한다는 점을 다루었습니다. 마지막으로, Fact(상태)와 Delta 이벤트 유형에 대해 다루었습니다. Fact 이벤트는 상태를 전달하고 시스템을 분리하는 데 가장 적합하며, Delta 이벤트는 주로 내부 데이터, 예를 들어 이벤트 소싱과 같은 긴밀하게 연결된 사용 사례에 더 많이 사용됩니다.
정규화된 테이블은 정규화된 스트림을 만든다
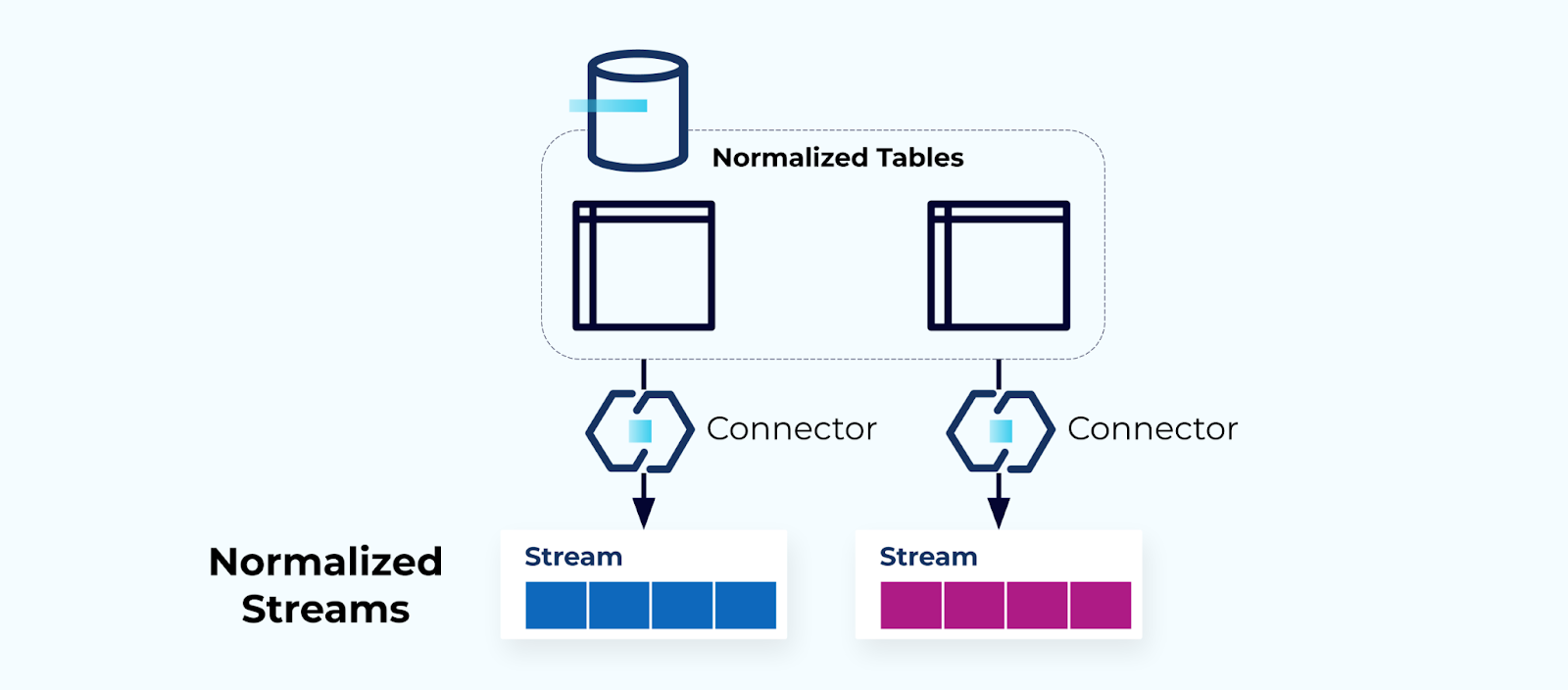
정규화된 테이블은 정규화된 이벤트 스트림을 초래합니다. 커넥터(예: CDC)는 데이터베이스에서 직접 데이터를 추출하여 미러링된 이벤트 스트림 집합으로 가져옵니다. 이는 이상적이지 않으며, 내부 데이터베이스 테이블과 외부 이벤트 스트림 간의 강한 결합을 만들어냅니다.
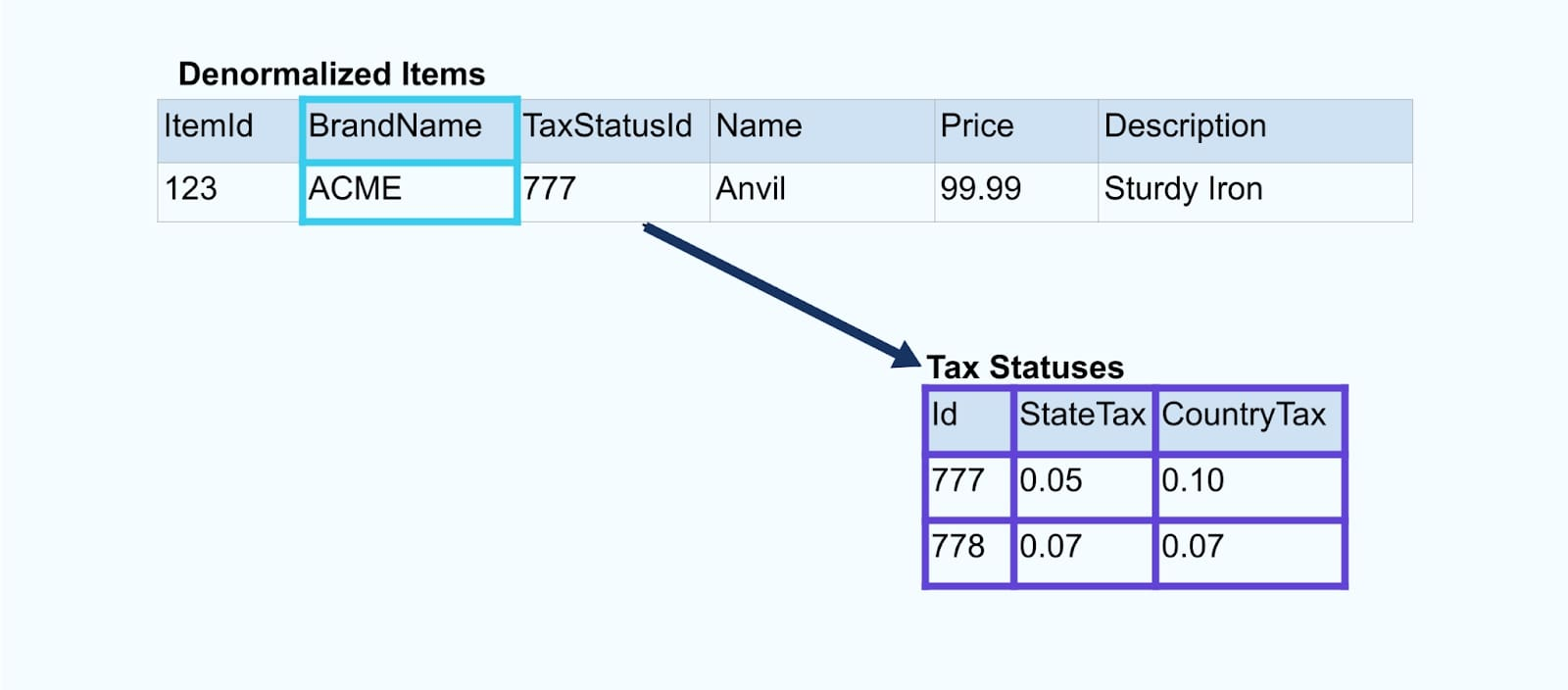
간단한 전자상거래 아이템과 관련된 브랜드 및 세금 상태 테이블을 고려해봅시다.
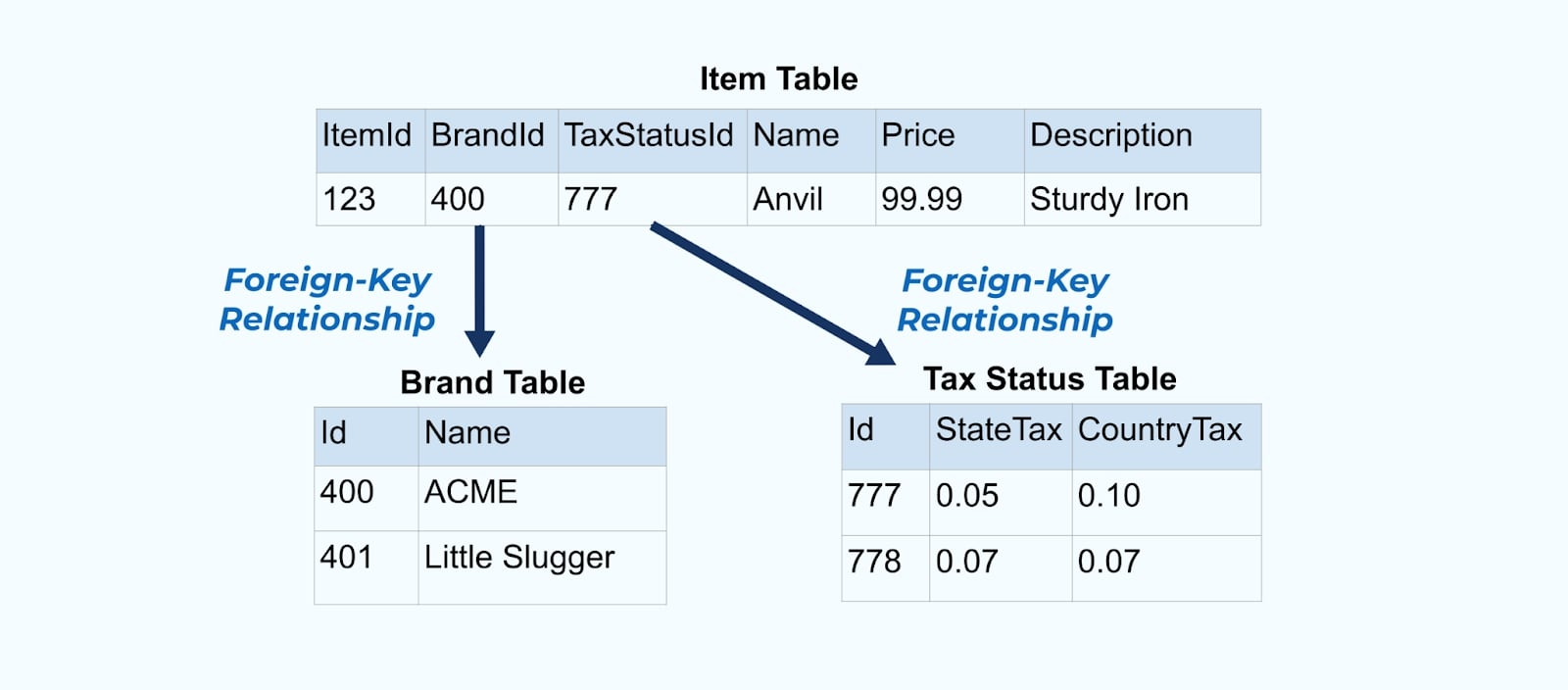
브랜드 및 세금 상태 테이블은 외래 키 관계를 통해 아이템 테이블과 관련됩니다. 테이블에 하나의 아이템만 표시되지만, 판매하는 제품에 따라 수천(혹은 수백만) 개의 아이템을 가질 가능성이 큽니다.
각 테이블에 대해 커넥터를 설정하고 테이블에서 데이터를 추출하여 이벤트로 구성한 다음 각 테이블을 전용 이벤트 스트림에 쓰는 것이 일반적입니다.
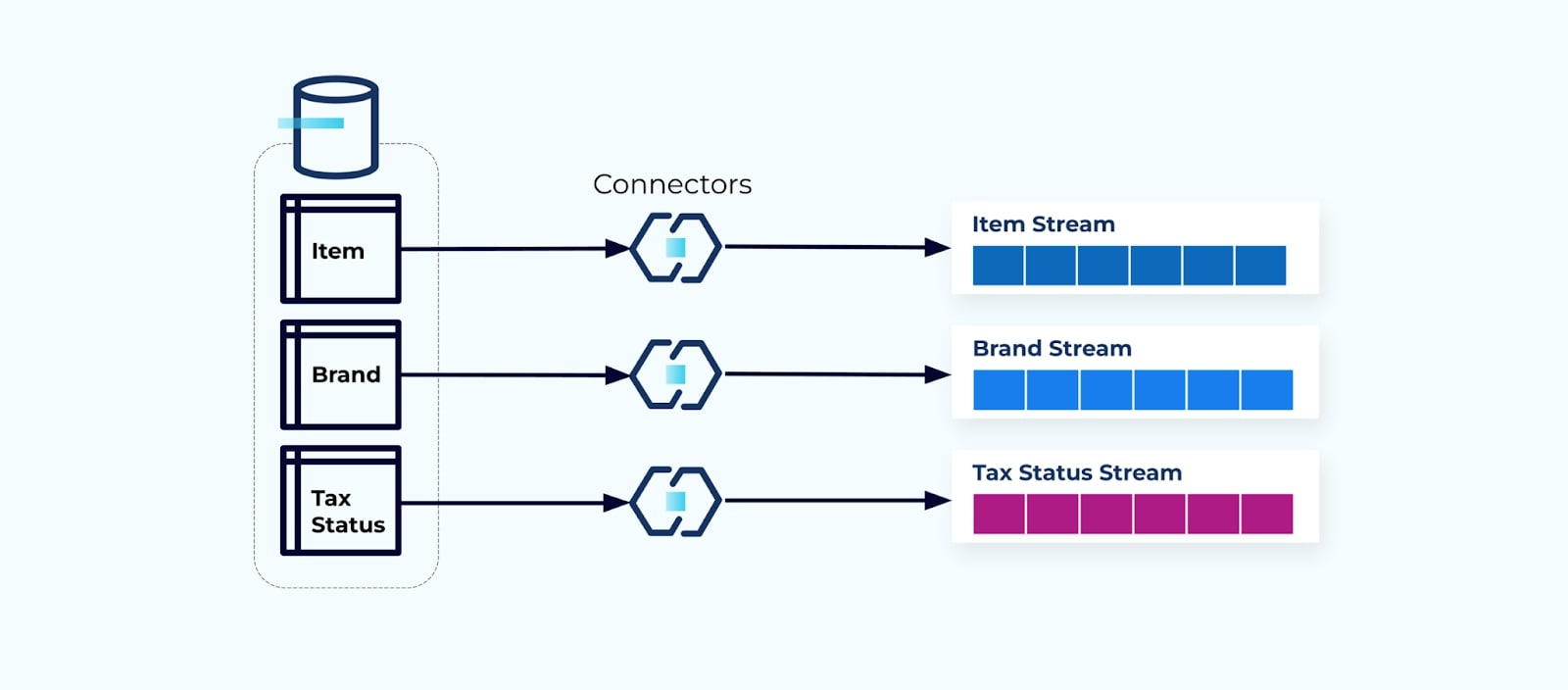
데이터베이스의 기본 테이블을 노출하면 테이블별로 해당 이벤트 스트림이 생성됩니다. 이 방식으로 시작하는 것은 쉽지만 여러 문제를 야기할 수 있으며, 이는 결합 문제 또는 비용 문제로 요약할 수 있습니다. 각 문제를 살펴보겠습니다.
문제: 소비자가 내부 모델에 결합됨
소스 아이템 테이블을 그대로 노출하면 소비자가 직접 이에 결합될 수밖에 없습니다. 소스 시스템의 데이터 모델 변경은 다운스트림 소비자에 영향을 미칩니다.
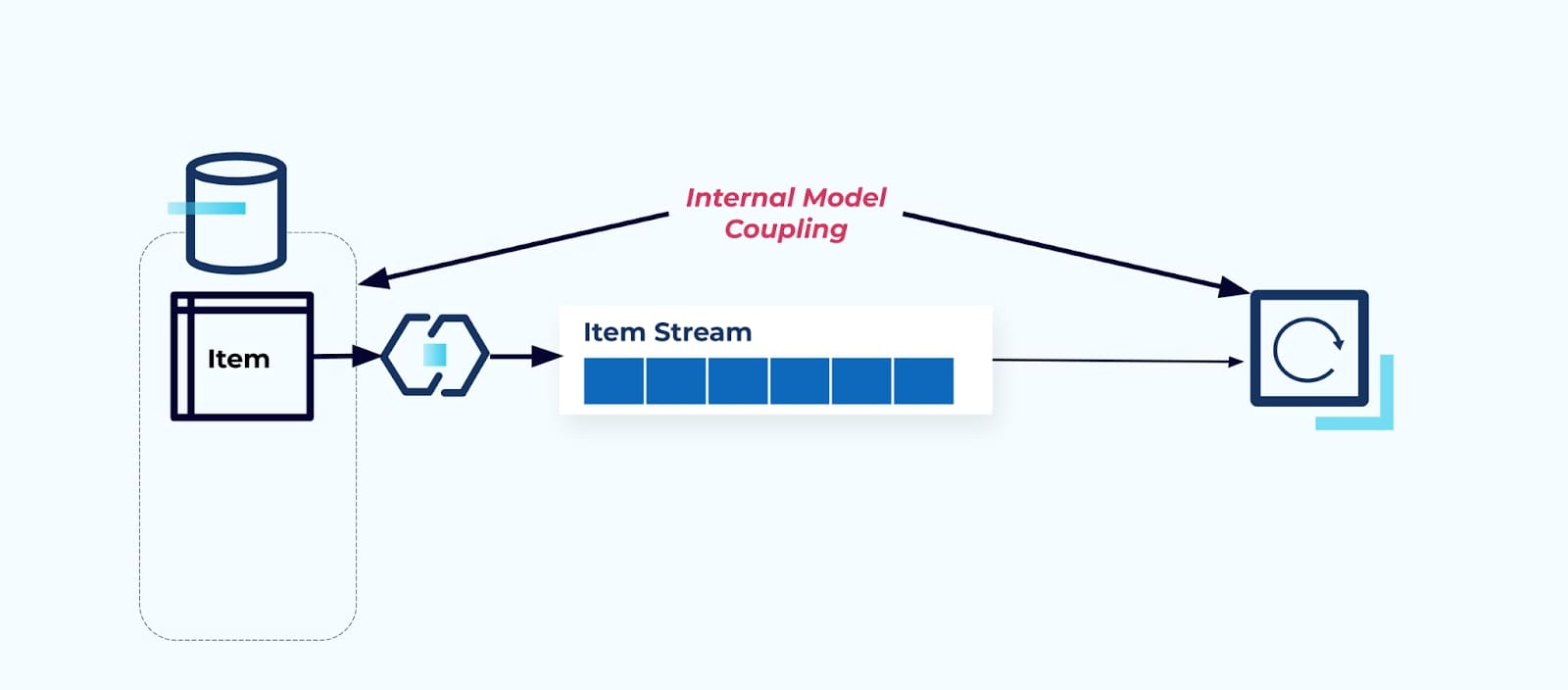
예를 들어, 아이템 테이블을 리팩토링하여 Pricing을 별도의 테이블로 추출한다고 가정해봅시다.
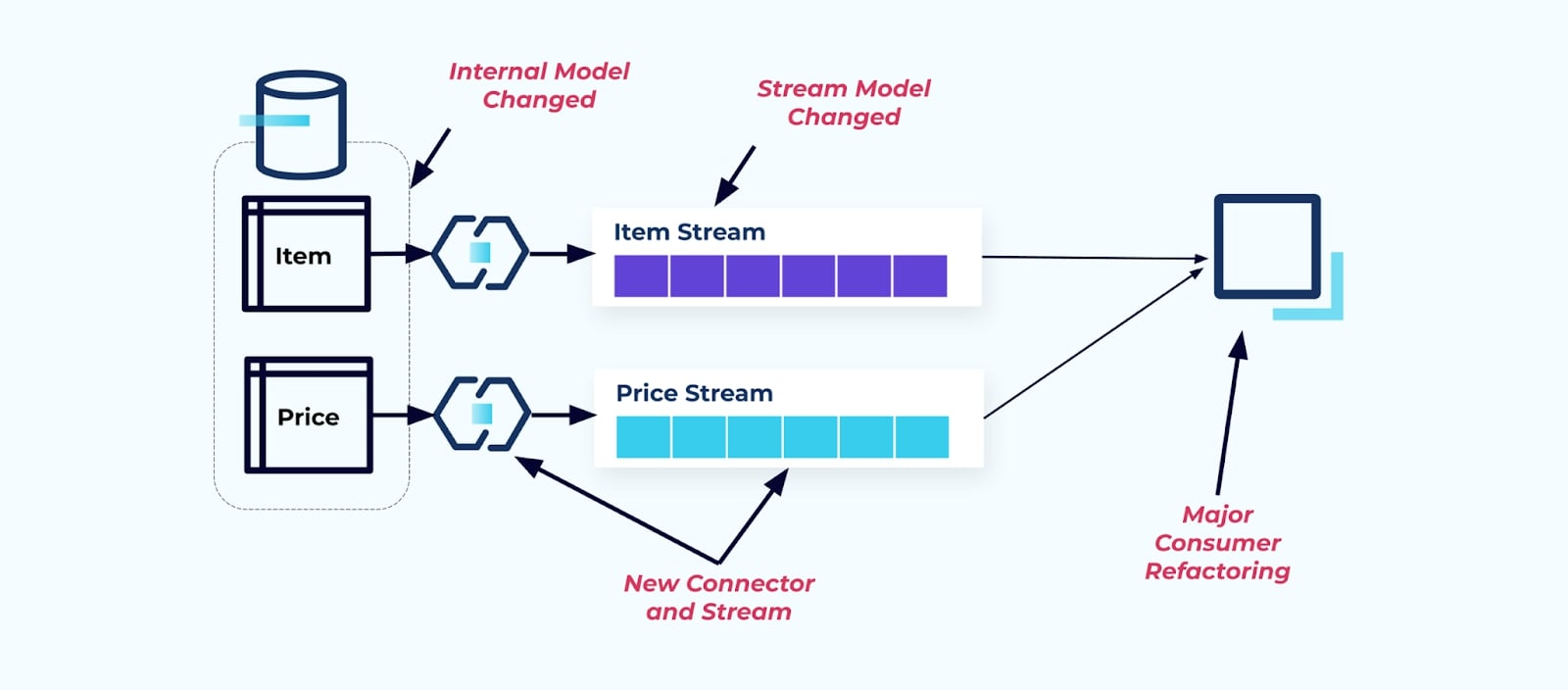
소스 테이블의 리팩토링 결과 데이터 계약이 깨짐이 발생합니다. 소비자는 더 이상 원래 기대했던 동일한 항목 데이터를 제공받지 못합니다. 또한 새로운 커넥터를 생성해야 합니다 — 새로운 Price 스트림 — 그리고 마지막으로 소비자 로직을 리팩토링하여 다시 실행할 수 있도록 해야 합니다. 컬럼 이름 변경, 기본값 변경 및 컬럼 유형 변경은 내부 데이터 모델의 긴밀한 결합으로 인해 도입된 다른 형태의 파괴적인 변경입니다.
문제: 스트리밍 조인은 (일반적으로) 비용이 많이 듦
관계형 데이터베이스는 조인을 빠르고 저렴하게 해결하기 위해 설계되었습니다. 하지만 스트리밍 조인은 그렇지 않습니다.
두 서비스가 Item, 그것의 Tax, 그리고 Brand 정보에 접근하려고 할 때를 고려해보세요. 데이터가 이미 해당 스트림에 기록되어 있다면, 각 소비자(아래 이미지에서 오른쪽에 있는)는 Item, Brand, 그리고 Tax를 정규화하기 위해 동일한 조인을 계산해야 합니다.
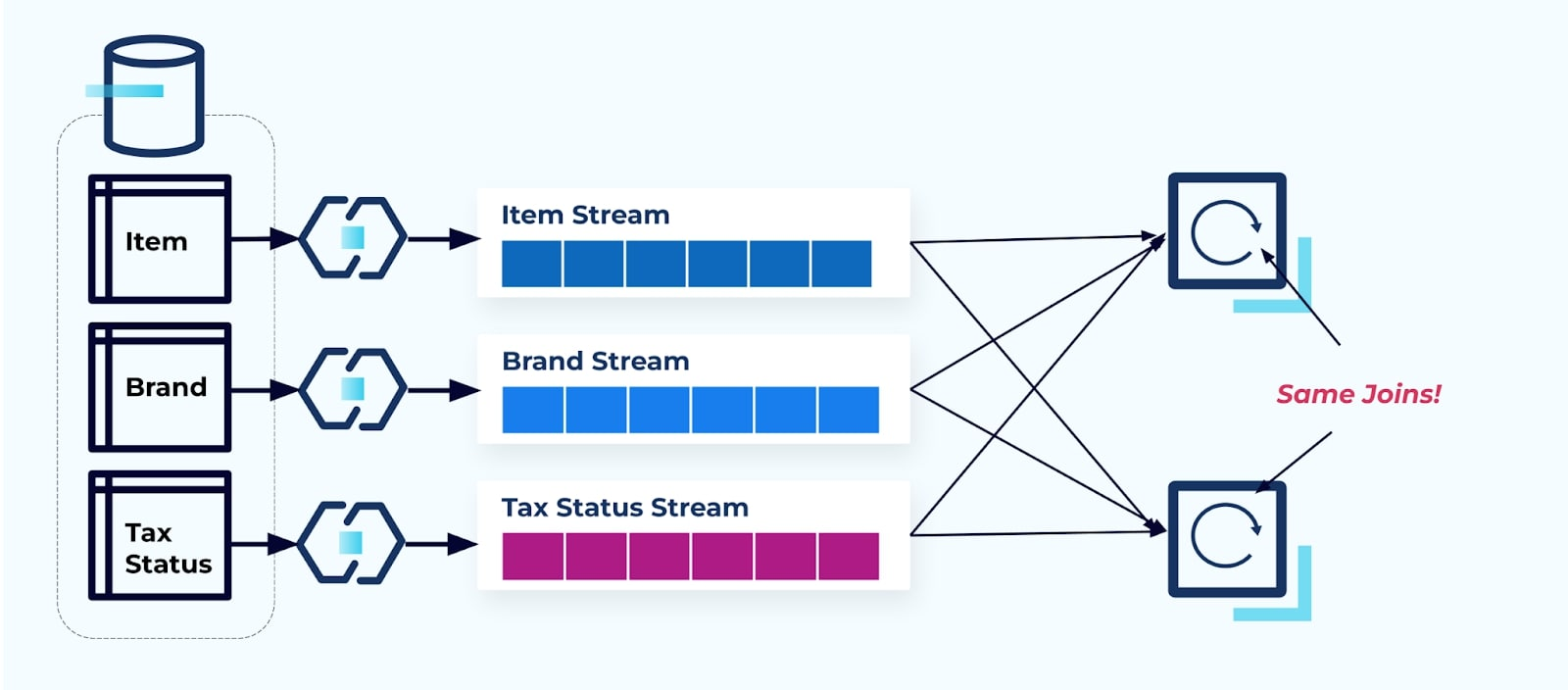
이 전략은 애플리케이션 작성에 소요되는 개발 시간과 조인을 계산하기 위한 서버 비용 모두에서 높은 비용을 발생시킬 수 있습니다. 대규모 스트리밍 조인을 해결하면 데이터의 많은 셔플링이 발생할 수 있으며, 이는 처리 능력, 네트워킹 및 저장 비용을 초래합니다. 또한 모든 스트림 처리 프레임워크가 조인을 지원하지는 않으며, 특히 외래 키에서 그렇습니다. 그 중에서도 Flink, Spark, KSQL 또는 Kafka Streams(예시로)와 같은 프레임워크는 프로그래밍 언어의 하위 집합(Java, Scala, Python)에 제한됩니다.
해결책: 비정규화된 데이터 제공이 최선
원칙적으로, 이벤트 스트림을 소비자가 쉽게 사용할 수 있도록 만드세요. 추상화 계층을 사용하여 소비자에게 제공하기 전에 데이터를 비정규화하고 명시적인 외부 모델 데이터 계약 (외부 데이터)를 생성하여 소비자가 결합하도록 하세요.
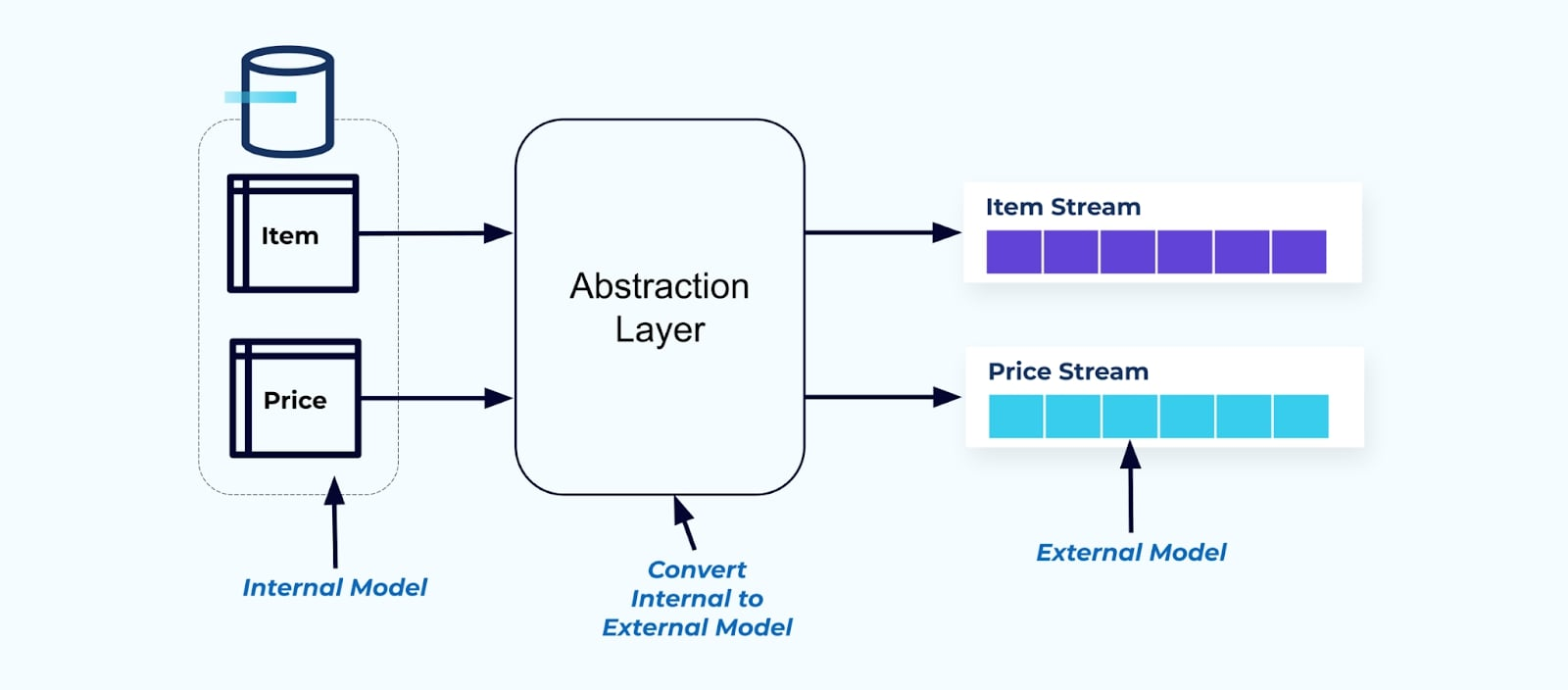
내부 모델의 변경 사항은 소스 시스템 내에서 격리됩니다. 소비자는 결합할 명확한 데이터 계약을 얻습니다. 소스 모델에 대한 변경 사항은 소스 시스템이 소비자를 위한 데이터 계약을 유지하는 한 원활하게 진행될 수 있습니다.
그러나 어디서 비정규화할까요? 두 가지 옵션이 있습니다:
- 소스 시스템 외부에서 목적을 위한 조인 서비스를 통해 재구성.
- 소스 시스템에서 이벤트 생성 중에 트랜잭션 아웃박스 패턴을 사용하여.
각 해결책을 차례로 살펴보겠습니다.
옵션 1: 목적을 위한 조인 서비스를 사용하여 비정규화
이 예에서 왼쪽의 스트림은 데이터베이스에서 왔던 테이블을 반영합니다.
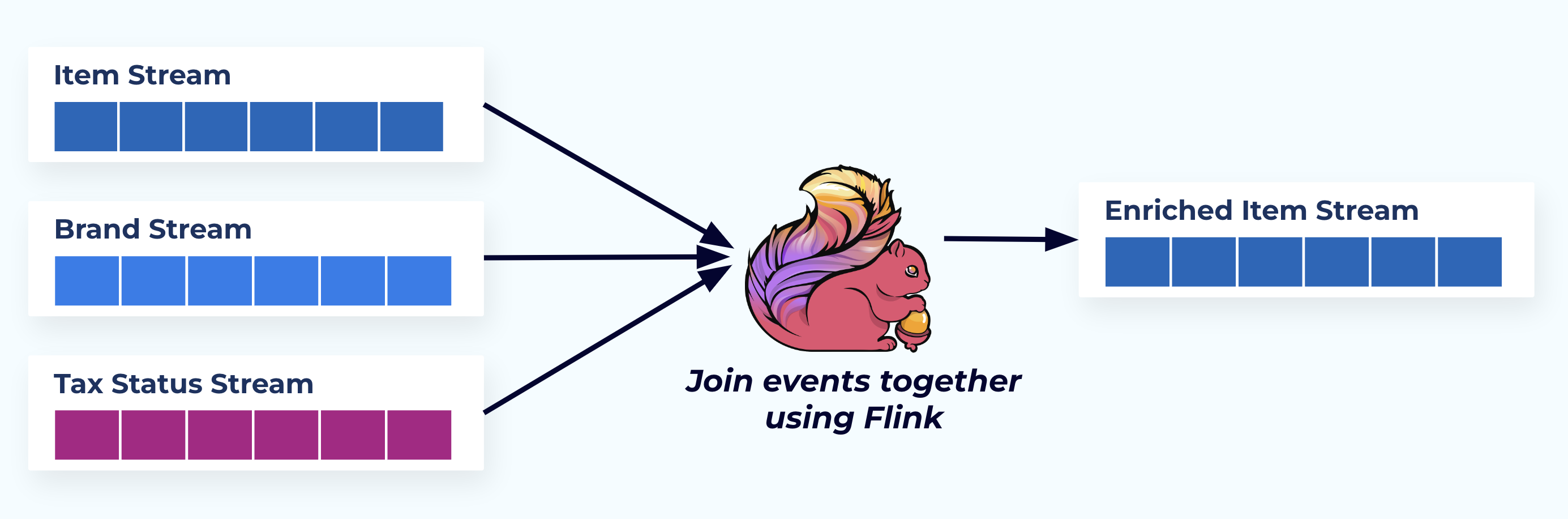
우리는 외래 키 관계를 기반으로 한 목적 구축 애플리케이션(또는 스트리밍 SQL 쿼리)을 사용하여 이벤트를 결합하고 단일 풍부한 항목 스트림을 방출합니다.

논리적으로, 우리는 관계를 해결하고 데이터를 단일 비정규화된 행으로 압축합니다.
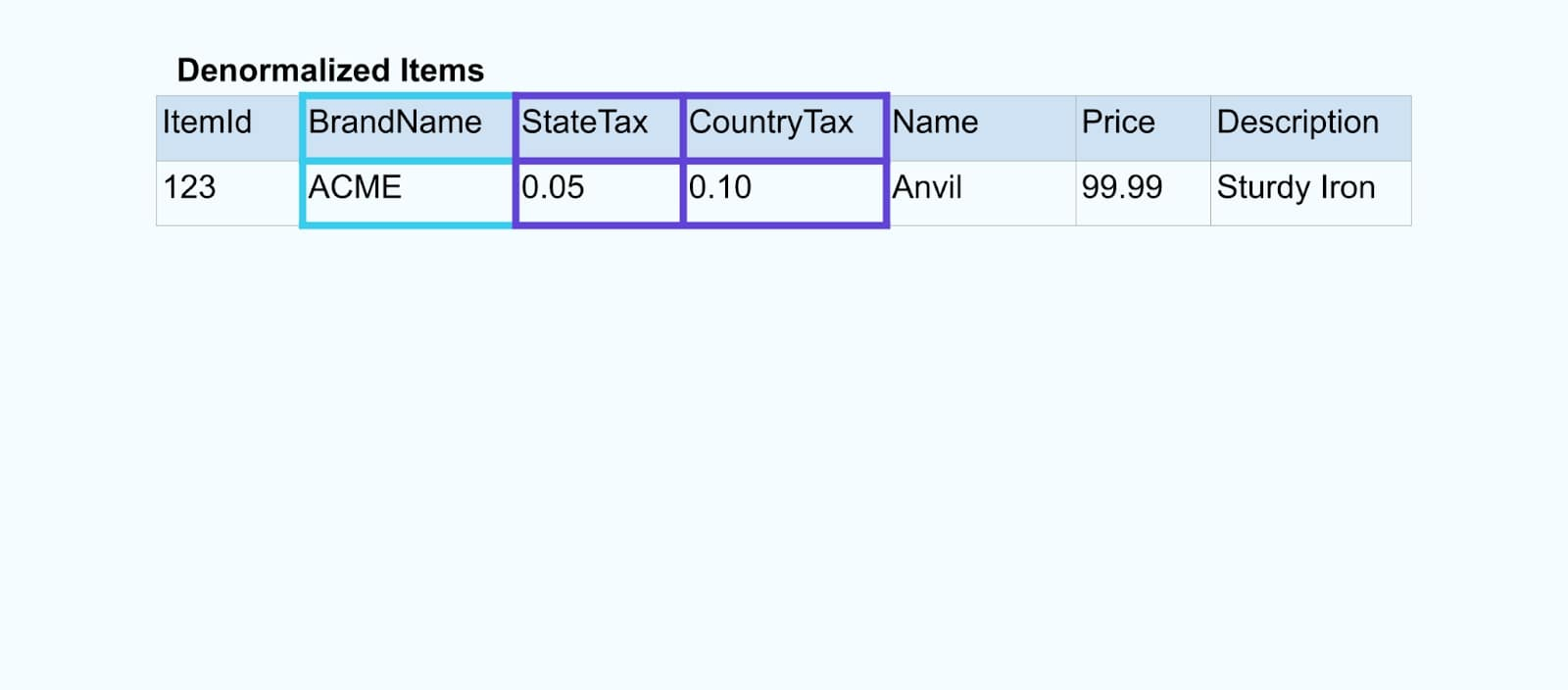
목적 구축 조인러는 Apache Kafka Streams와 Apache Flink와 같은 스트림 처리 프레임워크에 의존하여 기본 키와 외래 키 조인을 모두 해결합니다. 그들은 스트림 데이터를 내구성 있는 내부 테이블 형식으로 구체화하여, 조인러 애플리케이션이 임의의 기간 동안 이벤트를 결합할 수 있도록 합니다 – 시간 제한된 창에만 제한되지 않습니다.
Flink 또는 Kafka Streams를 사용하는 조인러는 또한 매우 확장 가능합니다 — 그들은 부하에 따라 확장 및 축소할 수 있으며 대량의 트래픽을 처리할 수 있습니다.
팁: 조인러에 어떤 비즈니스 로직도 넣지 마세요. 이 패턴에서 성공하려면 결합된 데이터가 단순히 비정규화된 결과로 소스를 정확하게 나타내야 합니다. 비정규화된 데이터를 단일 진실 소스로 사용하여 다운스트림 소비자가 자체 비즈니스 로직을 적용하게 하세요.
다운스트림 조인러를 사용하고 싶지 않다면 다른 옵션이 있습니다. 다음으로 트랜잭션 아웃박스 패턴을 살펴보겠습니다.
옵션 2: 트랜잭션 아웃박스 패턴
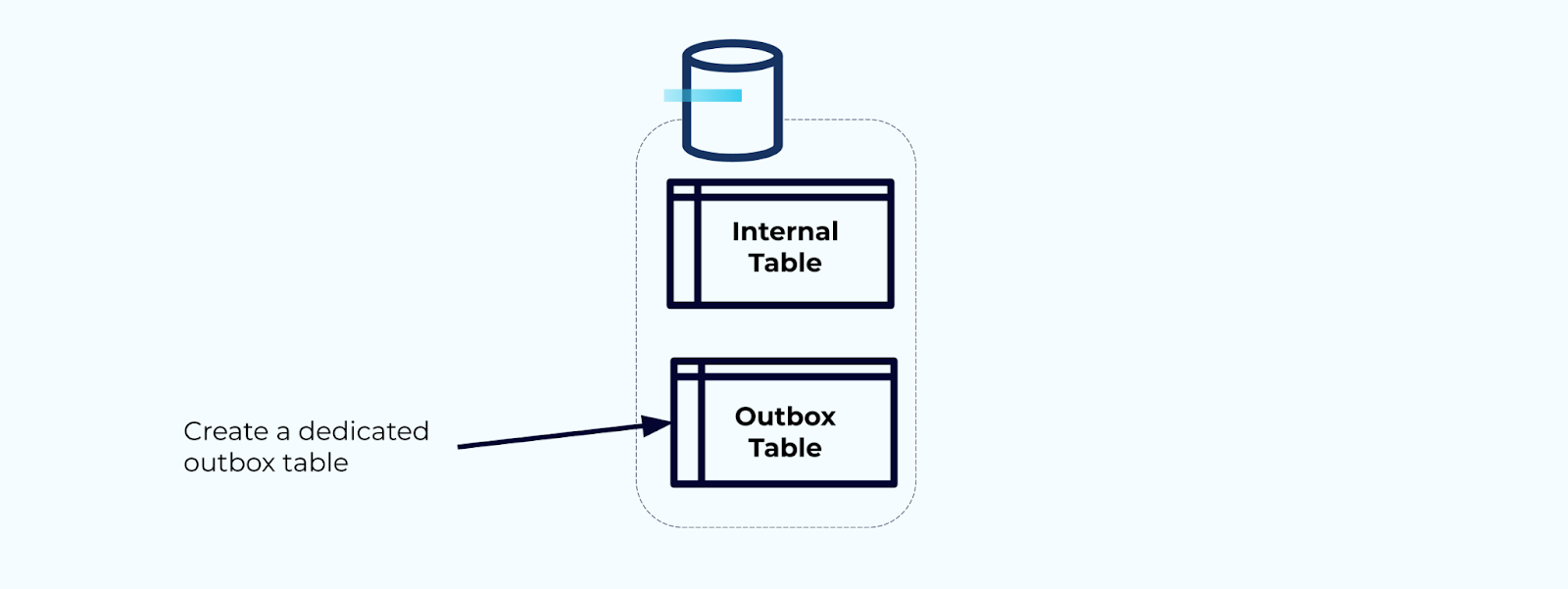
먼저, 스트림에 이벤트를 작성하기 위한 전용 아웃박스 테이블을 생성하세요.
두 번째, 모든 필요한 내부 테이블 업데이트를 트랜잭션 내에 포함시킵니다. 트랜잭션은 내부 테이블에 대한 모든 업데이트가 아웃박스 테이블에도 기록될 것을 보장합니다.
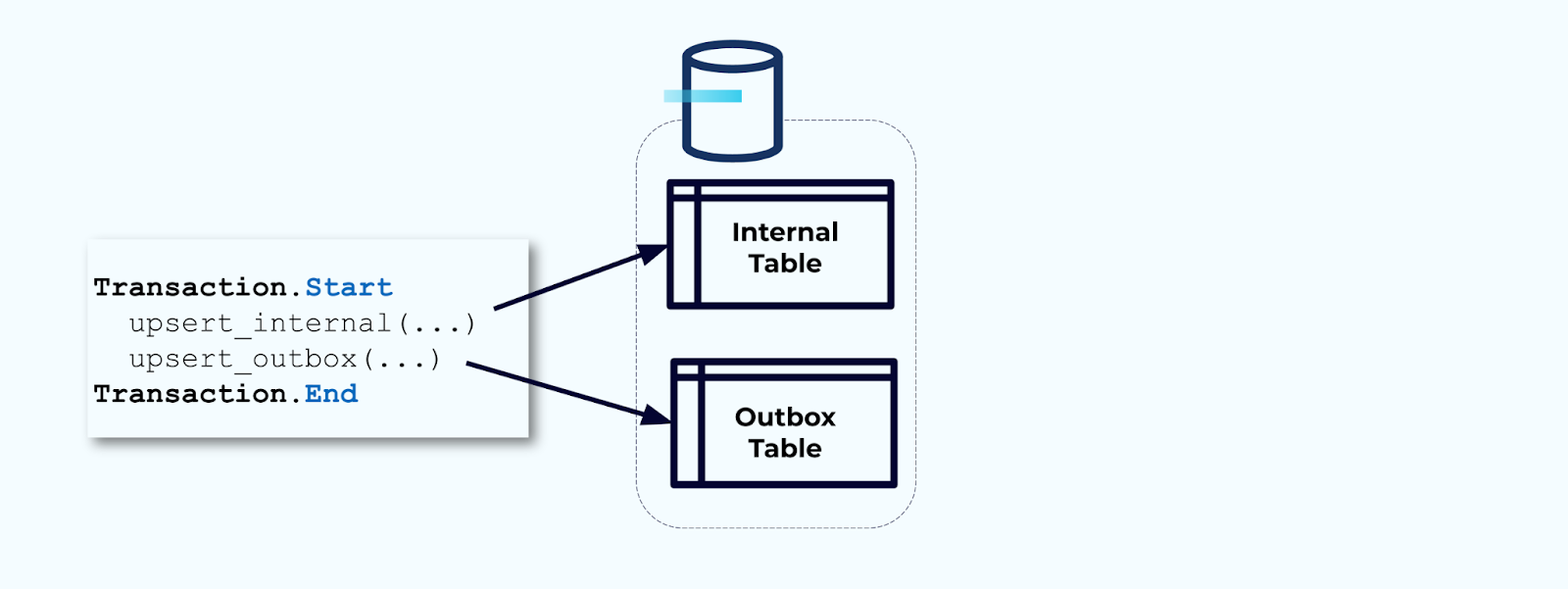
아웃박스는 내부 데이터 모델을 격리할 수 있게 해줍니다. 데이터를 아웃박스에 기록하기 전에 조인하고 변환할 수 있습니다. 아웃박스는 내부 데이터와 외부 데이터 간의 추상화 계층 역할을 하며, 소비자들을 위한 데이터 계약으로 작용합니다.
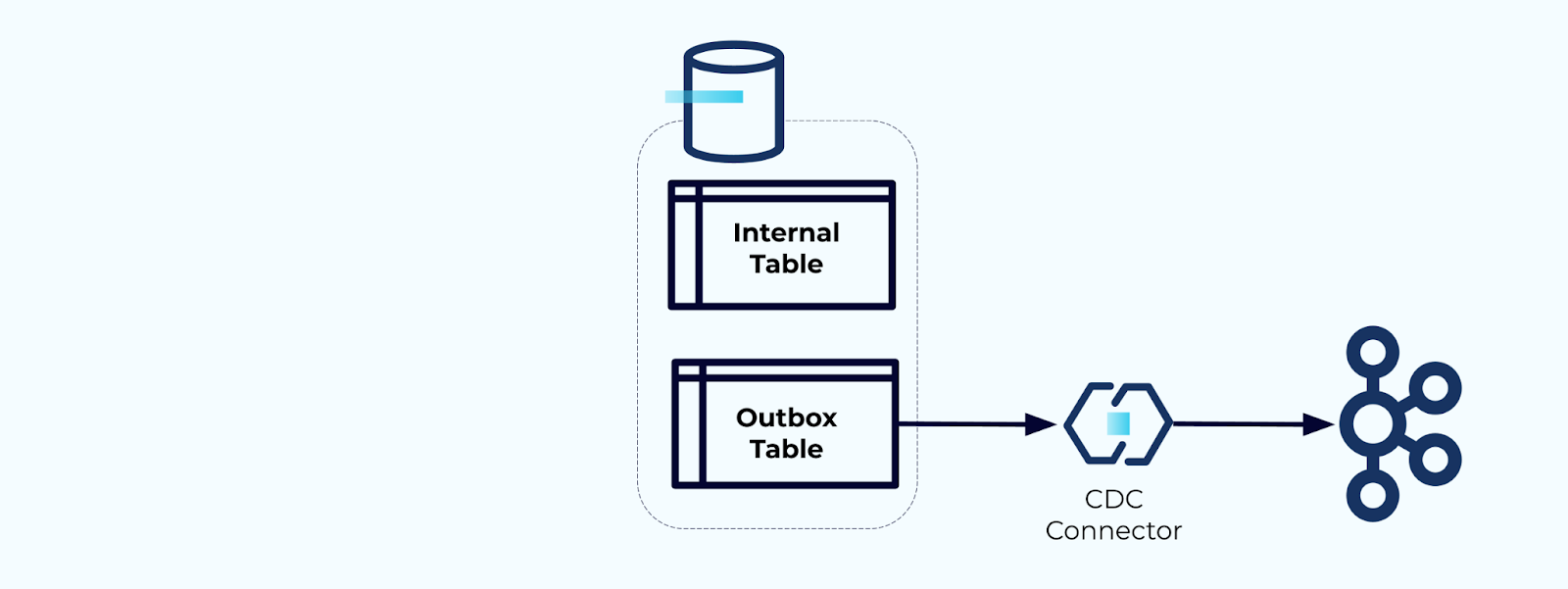
마지막으로, 커넥터를 사용하여 아웃박스에서 데이터를 추출하여 카프카로 전송할 수 있습니다.
아웃박스가 무한정 커지지 않도록 해야 합니다. CDC에 의해 데이터가 캡처된 후 삭제하거나 주기적으로 예약된 작업으로 삭제하십시오.
예시: 사용자 행동 추적 이벤트의 비정규화
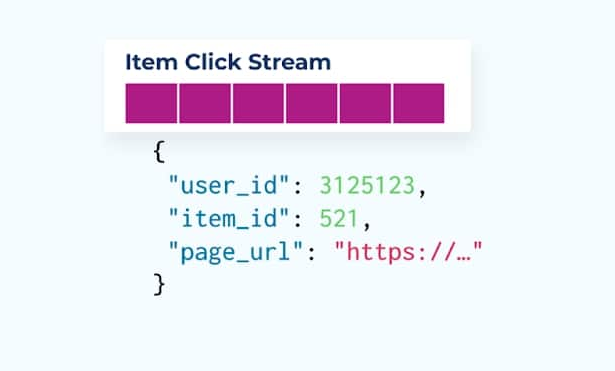
웹 페이지와 애플리케이션에서 사용자 행동을 추적하는 것은 정규화된 이벤트의 일반적인 출처입니다 – 예를 들어, 구글 애널리틱스 또는 첫 번째 파티 인하우스 옵션을 생각해보세요. 하지만 우리는 이벤트에 모든 정보를 포함시키지 않습니다. 대신, 식별자로 제한하여(더 빠르고, 더 작고, 더 저렴하게) 사실이 생성된 후 비정규화합니다.
전자상거래 항목을 탐색하는 동안 사용자가 항목을 클릭했을 때의 항목 클릭 이벤트 스트림을 고려해보세요. 이 항목 클릭 이벤트는 이름, 가격, 설명과 같은 더 풍부한 항목 정보를 포함하지 않고, 기본적인 ids만 포함합니다.
많은 클릭 스트림 소비자들이 처음으로 하는 일은 그것을 아이템 팩트 스트림과 조인하는 것입니다. 그리고 여러 클릭 이벤트를 다루기 때문에, 컴퓨팅 자원의 큰 양을 사용하게 된다는 것을 발견하게 됩니다. 목적에 맞게 빌드된 플링크 애플리케이션은 아이템 클릭을 상세 아이템 데이터와 조인하고, 이를 풍부해진 아이템 클릭 스트림으로 방출할 수 있습니다.
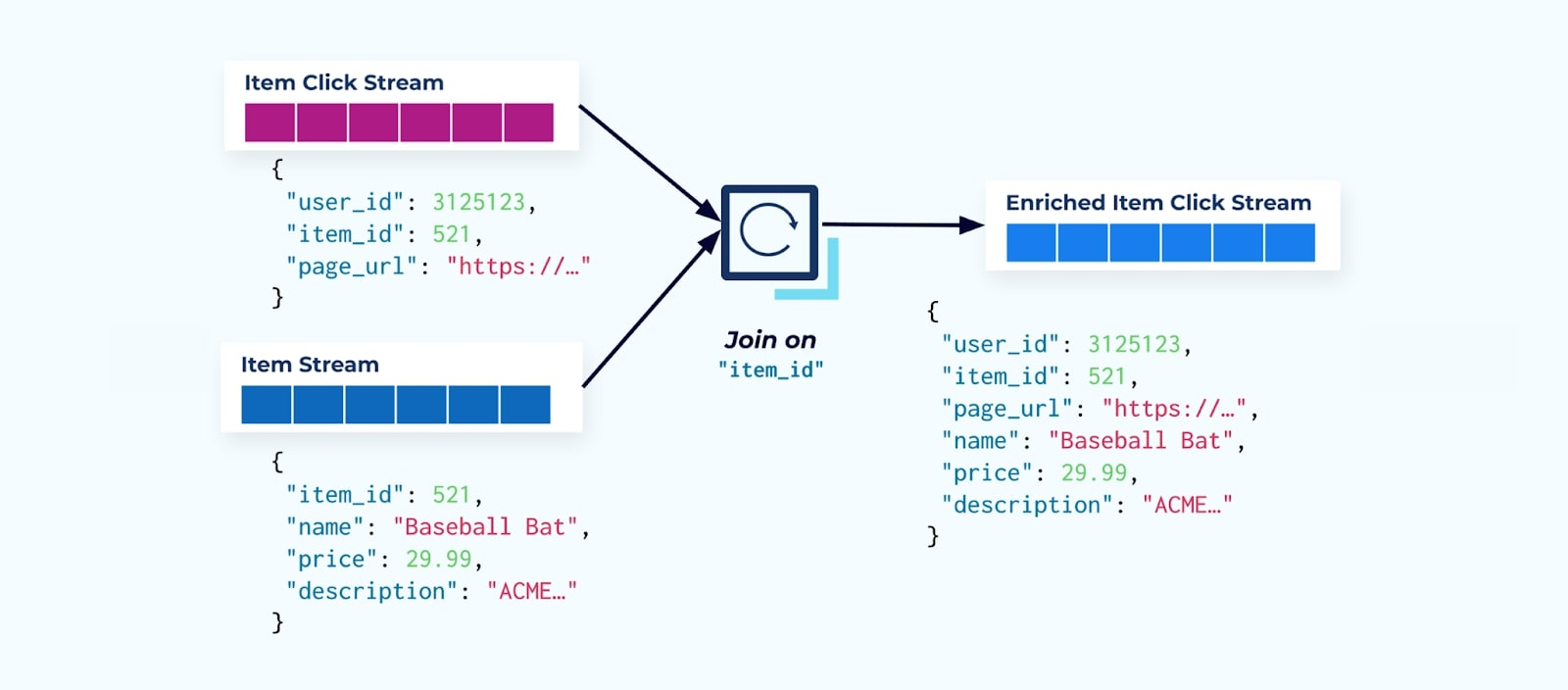
여러 부서(및 시스템)를 가진 더 큰 회사들은 데이터가 다른 소스에서 오는 것을 볼 가능성이 높으며, 스트림 조이너를 사용하여 사실 이후에 조인하는 것이 가장 вероят
느리게 변하는 차원에 대한 고려사항
우리는 이미 큰 데이터 세트(예: 큰 텍스트 블롭)를 포함하는 이벤트를 작성하는 성능 고려사항과 자주 변하는 데이터 도메인(예: 아이템 인벤토리)에 대해 논의했습니다. 이제 느리게 변하는 차원(SCDs)에 대해 살펴보겠습니다. 이는 외래 키 관계를 통해 나타나며, 이 또한 상당한 데이터 양의 원천이 될 수 있습니다.
다시 우리의 아이템 예제로 돌아가 보겠습니다. 아이템 테이블을 업데이트하는 작업이 있다고 가정해봅시다. 아이템의 이름을 Anvil에서 Iron Anvil로 변경하려고 합니다.
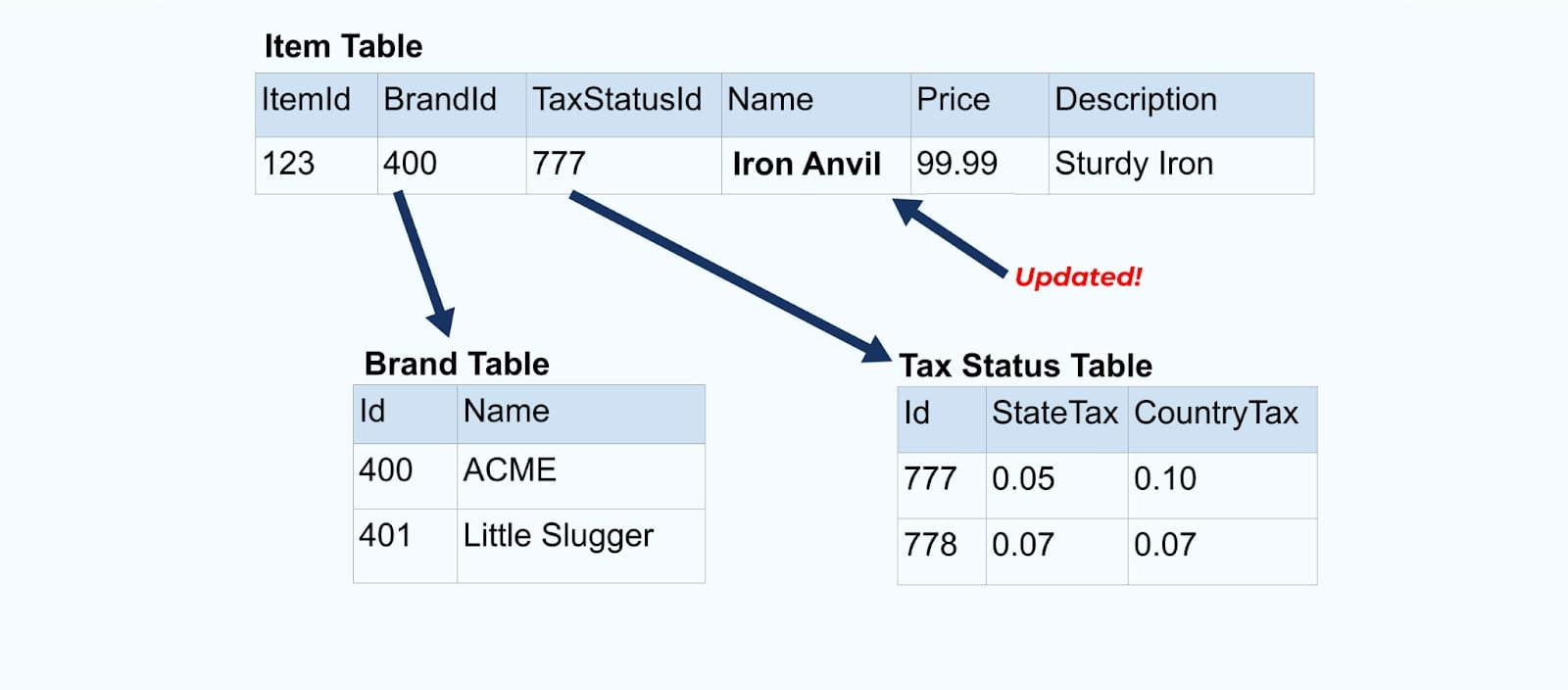
데이터베이스에서 데이터를 업데이트할 때, 우리는 또한 (예를 들어 아웃박스 패턴을 통해) 정규화되지 않은 세금 상태와 브랜드 테이블을 포함한 업데이트된 아이템을 방출합니다.
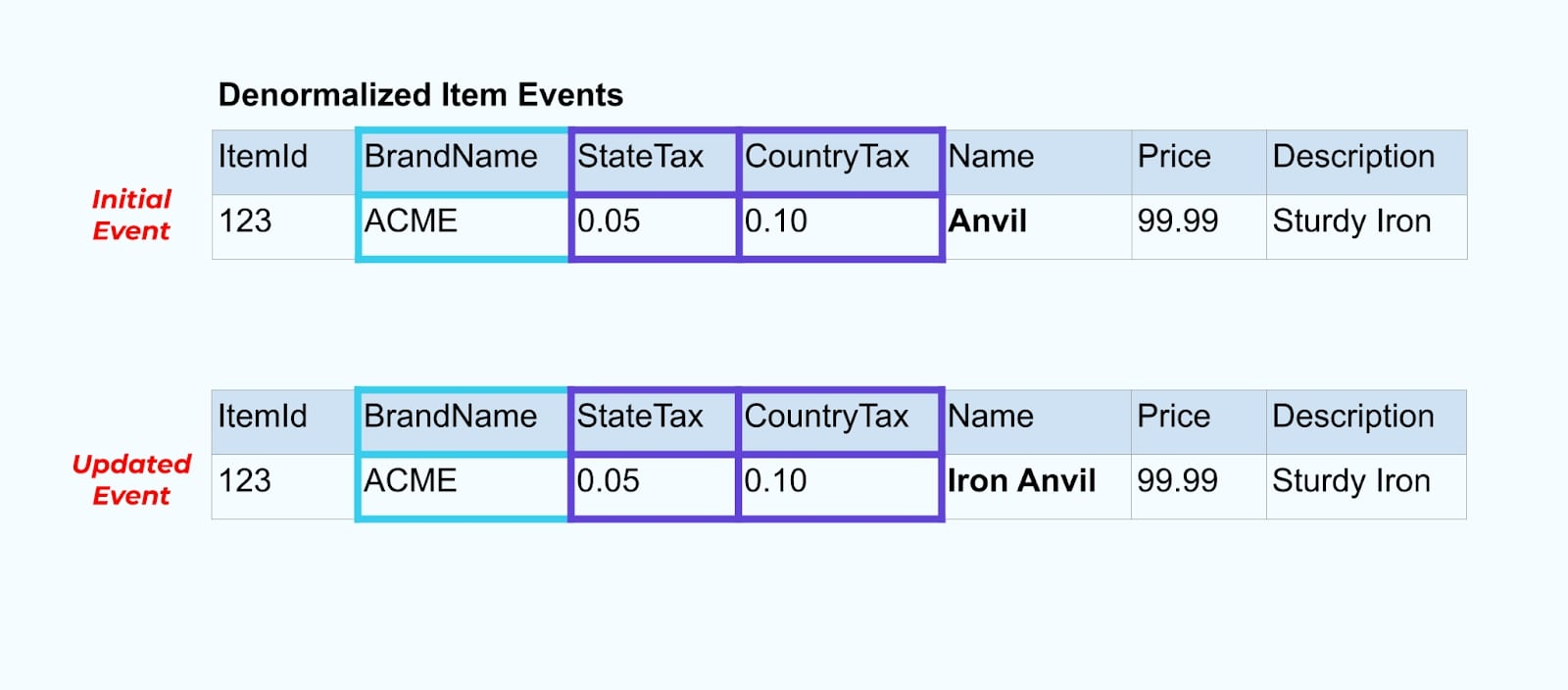
그러나 브랜드나 세금 테이블의 값들을 변경할 때 어떤 일이 발생하는지도 고려해야 합니다. 이러한 느리게 변하는 차원 중 하나를 업데이트하면, 영향을 받는 모든 아이템에 대해 상당히 큰 수의 업데이트가 발생할 수 있습니다.
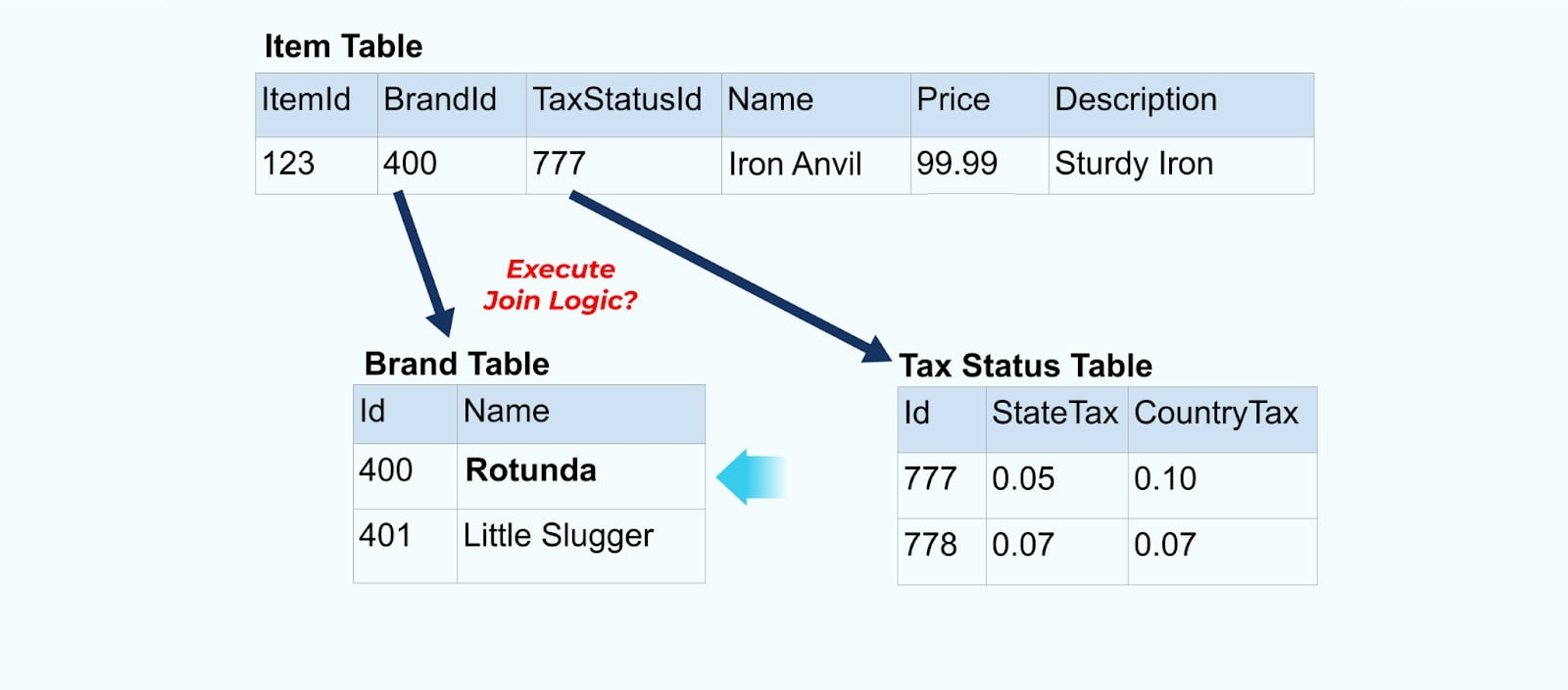
예를 들어, ACME 회사는 리브랜딩을 거치고 새로운 브랜드 이름을 제안하여 ACME에서 Rotunda로 변경합니다. 우리는 ItemId=123에 대한 또 다른 이벤트를 생성합니다.
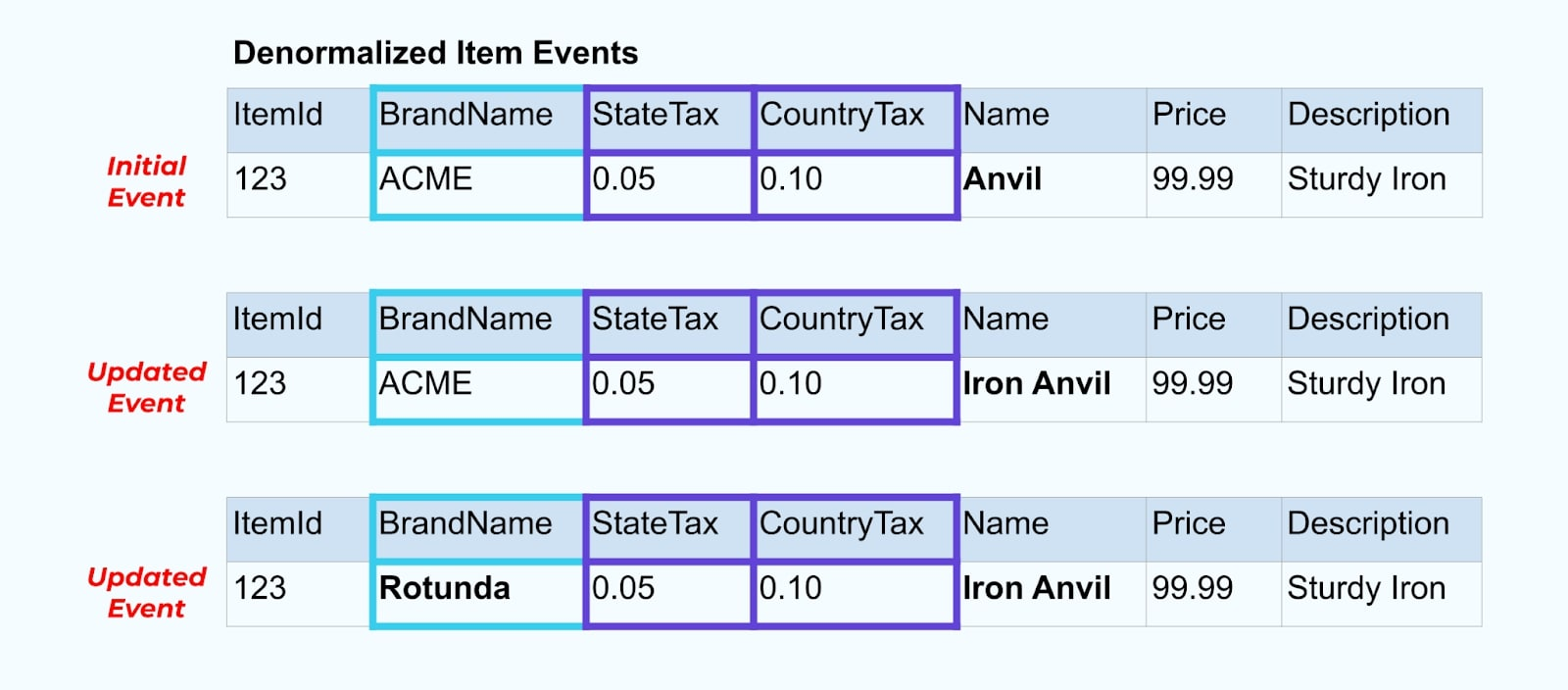
그러나 Rotunda(옛 ACME)는 이 변경으로 인해 수백 개(혹은 수천 개)의 항목도 업데이트될 가능성이 높으며, 이에 따라 업데이트된 풍부한 항목 이벤트의 수가 동일하게 증가합니다.
SCD와 외래 키 관계를 정규화하지 않을 때, SCD의 변경이 전체 이벤트 스트림에 미칠 영향을 염두에 두어야 합니다. SCD를 변경하면 수백만 개 또는 수십억 개의 업데이트된 이벤트가 발생하는 경우, 정규화를 포기하고 소비자에게 맡기는 것이 좋을 수 있습니다.
요약
정규화하지 않음은 소비자가 데이터를 사용하기 쉽게 만들지만, 상류 처리가 더 많이 필요하고 포함할 데이터를 신중하게 선택해야 하는 대가가 따릅니다. 소비자는 애플리케이션을 구축하는 데 더 쉽게 접근할 수 있으며, 스트리밍 조인을 네이티브로 지원하지 않는 기술을 포함한 더 넓은 범위의 기술을 선택할 수 있습니다.
데이터가 작고 드물게 업데이트될 때 상류에서 데이터를 정규화하는 것이 잘 작동합니다. 더 큰 이벤트 크기, 빈번한 업데이트 및 SCD는 상류에서 정규화할 것과 소비자가 스스로 처리할 것을 결정할 때 주의해야 할 요소입니다.
결국, 이벤트에 포함할 데이터와 제외할 데이터를 선택하는 것은 소비자의 요구, 생산자의 능력 및 고유한 데이터 모델 관계 간의 균형을 맞추는 작업입니다. 그러나 시작하기 가장 좋은 곳은 소비자의 요구를 이해하고 소스 시스템의 내부 데이터 모델을 격리하는 것입니다.
Source:
https://dzone.com/articles/how-to-design-event-streams-part-2