













소개
쿠버네티스 클러스터의 데이터는 다른 설정과 마찬가지로 손실될 수 있는 위험이 있습니다. 심각한 문제를 방지하려면 데이터 복구 계획이 필수적입니다. 이를 위한 간단하고 효과적인 방법은 백업을 만들어 예상치 못한 사건 발생 시 데이터를 안전하게 보호하는 것입니다. 백업은 일회성으로 실행하거나 예약할 수 있습니다. 최신 백업으로 쉽게 복구할 수 있도록 예약된 백업을 갖는 것이 좋습니다.
Velero – 쿠버네티스 클러스터의 백업 및 복원 작업을 지원하기 위해 설계된 오픈 소스 도구입니다. 재해 복구 사용 사례뿐만 아니라 클러스터에서 시스템 작업을 수행하기 전에 응용 프로그램 상태를 스냅샷으로 찍는 데 이상적입니다. 이 주제에 대한 자세한 내용은 Velero 작동 방식 공식 페이지를 참조하십시오.
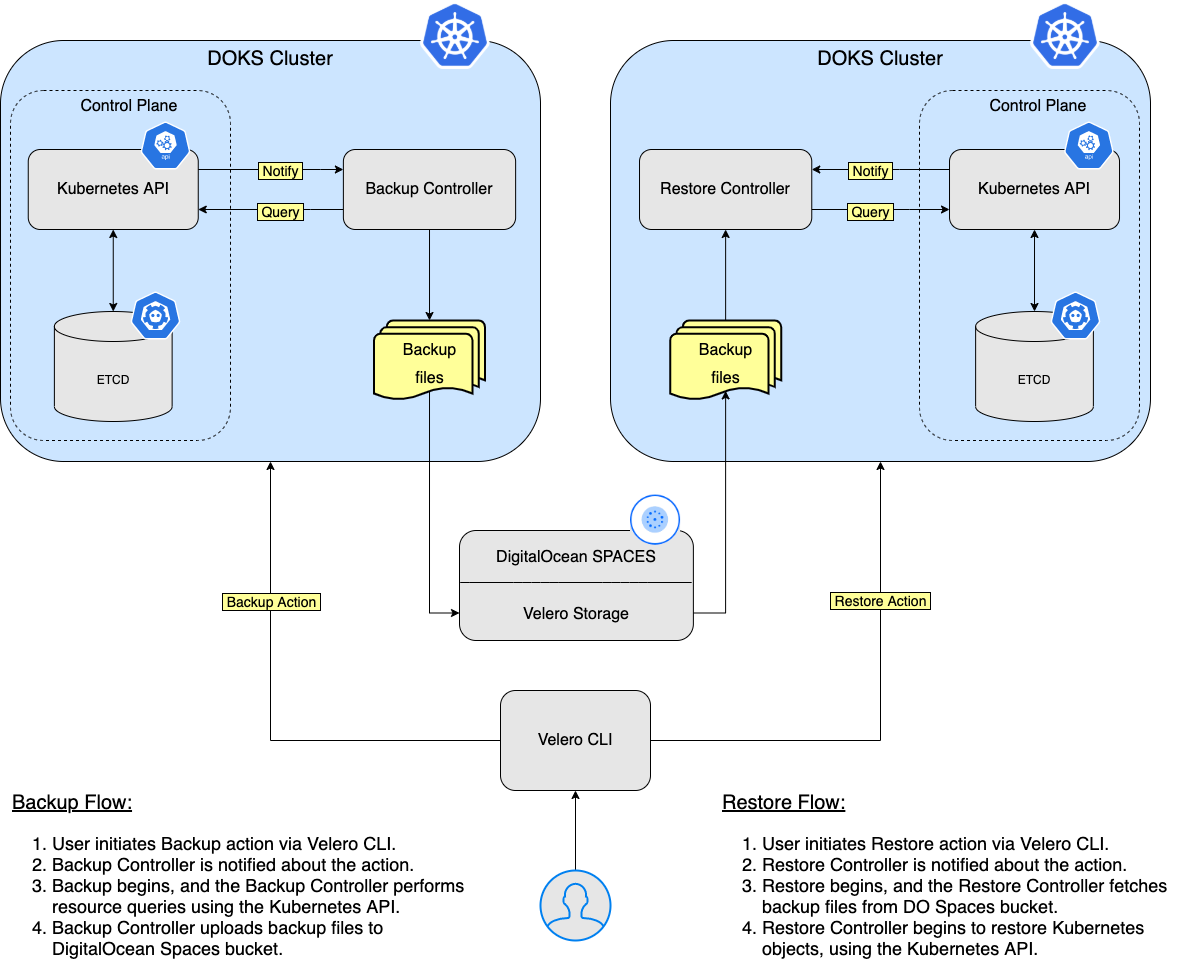
이 튜토리얼에서는 Velero를 쿠버네티스 클러스터에 배포하고 백업을 생성하며, 문제가 발생한 경우 백업에서 복구하는 방법을 배우게 됩니다. 전체 클러스터를 백업하거나 선택적으로 네임스페이스나 레이블 선택기를 선택하여 클러스터를 백업할 수 있습니다.
목차
- 필수 조건
- 단계 1 – Helm을 사용하여 Velero 설치
- 단계 2 – 네임스페이스 백업 및 복원 예제
- 단계 3 – 전체 클러스터 백업 및 복원 예제
- 단계 4 – 예약된 백업
- 단계 5 – 백업 삭제
필수 사항
이 튜토리얼을 완료하려면 다음이 필요합니다:
- A DO Spaces Bucket and access keys. Save the access and secret keys in a safe place for later use.
- A DigitalOcean API token for Velero to use.
- A Git client, to clone the Starter Kit repository.
- Velero 릴리스 및 업그레이드 관리를 위한 Helm.
- 디지털오션 API 상호 작용을 위한 Doctl.
- Kubernetes 상호 작용을 위한 Kubectl.
- Velero 백업 관리를 위한 Velero 클라이언트.
단계 1 – Helm을 사용하여 Velero 설치
이 단계에서는 Velero 및 모든 필요한 구성 요소를 배포하여 Kubernetes 클러스터 리소스(PV 포함)의 백업을 수행할 수 있도록합니다. 백업 데이터는 이전에 준비 사항 섹션에서 생성된 DO Spaces 버킷에 저장됩니다.
먼저 Starter Kit Git 저장소를 복제하고 로컬 사본으로 디렉토리를 변경합니다:
다음으로 Helm 저장소를 추가하고 사용 가능한 차트를 나열합니다:
출력은 다음과 유사합니다:
NAME CHART VERSION APP VERSION DESCRIPTION
vmware-tanzu/velero 2.29.7 1.8.1 A Helm chart for velero
관심 있는 차트는 vmware-tanzu/velero이며 이 차트는 클러스터에 Velero를 설치합니다. 이 차트에 대한 자세한 내용은 velero-chart 페이지를 방문하십시오.
그런 다음 Starter Kit 저장소에서 제공되는 Velero Helm 값 파일을 열고 검사하십시오(가능하면 YAML lint 지원이 있는 편집기 사용을 권장합니다).
다음으로, DO Spaces Velero 버킷에 대한 <> 자리 표시자를 교체하십시오(이름, 리전 및 시크릿과 같은). 반드시 DigitalOcean API 토큰을 제공하십시오 (DIGITALOCEAN_TOKEN 키).
마지막으로, helm을 사용하여 Velero를 설치하십시오:
A specific version of the Velero Helm chart is used. In this case 2.29.7 is picked, which maps to the 1.8.1 version of the application (see the output from Step 2.). It’s a good practice in general to lock on a specific version. This helps to have predictable results and allows versioning control via Git.
–create-namespace \
이제 다음을 실행하여 Velero 배포를 확인하십시오:
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
velero velero 1 2022-06-09 08:38:24.868664 +0300 EEST deployed velero-2.29.7 1.8.1
출력은 다음과 유사합니다(STATUS 열에 deployed가 표시되어야 함):
다음으로, Velero가 정상적으로 실행되는지 확인하십시오:
NAME READY UP-TO-DATE AVAILABLE AGE
velero 1/1 1 1 67s
출력은 다음과 유사합니다 (배포된 팟은 준비 상태여야 함):
더 자세히 살펴보고 싶다면, Velero의 서버 측 구성 요소를 볼 수 있습니다:
- Velero CLI 도움말 페이지를 탐색하여 사용 가능한 명령 및 하위 명령을 확인하세요. 각 명령에 대한 도움말은
--help플래그를 사용하여 얻을 수 있습니다: Velero의 모든 사용 가능한 명령을 나열합니다:
Velero의 백업 명령 옵션을 나열합니다:
Velero는 백업, 백업 일정 등과 같은 리소스를 나타내기 위해 여러 CRD (사용자 정의 리소스 정의)를 사용합니다. 튜토리얼의 다음 단계에서 각각을 발견하고 몇 가지 기본 예제를 함께 알아볼 것입니다.
이 단계에서는 DOKS 클러스터에서 특정 네임스페이스인 ambassador의 전체 백업을 수행하고, 이후 모든 리소스가 재생성되도록 복원하는 방법을 배우게 됩니다.
먼저, 백업을 시작하십시오:
다음으로, 백업이 생성되었는지 확인하십시오:
NAME STATUS ERRORS WARNINGS CREATED EXPIRES STORAGE LOCATION SELECTOR
ambassador-backup Completed 0 0 2021-08-25 19:33:03 +0300 EEST 29d default <none>
출력은 다음과 유사합니다:
그런 다음 잠시 후에 확인할 수 있습니다:
Name: ambassador-backup
Namespace: velero
Labels: velero.io/storage-location=default
Annotations: velero.io/source-cluster-k8s-gitversion=v1.21.2
velero.io/source-cluster-k8s-major-version=1
velero.io/source-cluster-k8s-minor-version=21
Phase: Completed
Errors: 0
Warnings: 0
Namespaces:
Included: ambassador
Excluded: <none>
...
- 출력은 다음과 유사합니다:
Phase라인을 찾으십시오. 이것은Completed여야합니다.- 오류가 보고되지 않았는지도 확인하십시오.
새로운 Kubernetes 백업 객체가 생성됩니다:
~ kubectl get backup/ambassador-backup -n velero -o yaml
apiVersion: velero.io/v1
kind: Backup
metadata:
annotations:
velero.io/source-cluster-k8s-gitversion: v1.21.2
velero.io/source-cluster-k8s-major-version: "1"
velero.io/source-cluster-k8s-minor-version: "21"
...
마지막으로 DO Spaces 버킷을 확인하고 ambassador-backup에 대한 생성된 자산이 포함된 새로운 폴더 backups가 있는지 확인하십시오:
먼저, 의도적으로 ambassador 네임스페이스를 삭제하여 재해를 시뮬레이션하십시오:
다음으로, 네임스페이스가 삭제되었는지 확인하십시오(네임스페이스 목록에 ambassador가 출력되지 않아야 함):
마지막으로, echo 및 quote 백엔드 서비스 엔드포인트가 DOWN인지 확인하십시오. 스타터 킷 튜토리얼에서 사용된 백엔드 애플리케이션에 대해서는 대사관 엣지 스택 백엔드 서비스 생성를 참조하십시오. curl을 사용하여 테스트할 수 있습니다(또는 웹 브라우저를 사용할 수 있습니다):
ambassador-backup을 복원하십시오:
중요: ambassador 네임스페이스를 삭제하면 ambassador 서비스와 관련된 로드 밸런서 리소스도 삭제됩니다. 그러므로 ambassador 서비스를 복원할 때 디지털오션에서 로드 밸런서가 다시 생성됩니다. 여기서 문제는 로드 밸런서에 새로운 IP 주소가 할당된다는 것입니다. 따라서 클러스터에 호스팅된 도메인으로의 트래픽을 받기 위해 A 레코드를 조정해야 합니다.
ambassador-backup 복원 명령어의 출력에서 Phase 라인을 확인하여 ambassador 네임스페이스의 복원 여부를 확인합니다. 이 라인은 Completed라고 나와야 합니다(또한 경고 섹션을 주의해주세요. 문제가 있는 경우 알려줍니다):
다음으로, ambassador 네임스페이스에 대해 모든 리소스가 복원되었는지 확인합니다. ambassador pods, services, 그리고 deployments를 확인합니다.
NAME READY STATUS RESTARTS AGE
pod/ambassador-5bdc64f9f6-9qnz6 1/1 Running 0 18h
pod/ambassador-5bdc64f9f6-twgxb 1/1 Running 0 18h
pod/ambassador-agent-bcdd8ccc8-8pcwg 1/1 Running 0 18h
pod/ambassador-redis-64b7c668b9-jzxb5 1/1 Running 0 18h
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/ambassador LoadBalancer 10.245.74.214 159.89.215.200 80:32091/TCP,443:31423/TCP 18h
service/ambassador-admin ClusterIP 10.245.204.189 <none> 8877/TCP,8005/TCP 18h
service/ambassador-redis ClusterIP 10.245.180.25 <none> 6379/TCP 18h
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/ambassador 2/2 2 2 18h
deployment.apps/ambassador-agent 1/1 1 1 18h
deployment.apps/ambassador-redis 1/1 1 1 18h
NAME DESIRED CURRENT READY AGE
replicaset.apps/ambassador-5bdc64f9f6 2 2 2 18h
replicaset.apps/ambassador-agent-bcdd8ccc8 1 1 1 18h
replicaset.apps/ambassador-redis-64b7c668b9 1 1 1 18h
출력은 다음과 유사합니다:
ambassador 호스트 가져오기:
NAME HOSTNAME STATE PHASE COMPLETED PHASE PENDING AGE
echo-host echo.starter-kit.online Ready 11m
quote-host quote.starter-kit.online Ready 11m
출력은 다음과 유사합니다:
STATE가 Ready이어야 하며 HOSTNAME 열은 완전한 호스트 이름을 가리켜야 합니다.
ambassador 매핑 가져오기:
NAME SOURCE HOST SOURCE PREFIX DEST SERVICE STATE REASON
ambassador-devportal /documentation/ 127.0.0.1:8500
ambassador-devportal-api /openapi/ 127.0.0.1:8500
ambassador-devportal-assets /documentation/(assets|styles)/(.*)(.css) 127.0.0.1:8500
ambassador-devportal-demo /docs/ 127.0.0.1:8500
echo-backend echo.starter-kit.online /echo/ echo.backend
quote-backend quote.starter-kit.online /quote/ quote.backend
출력은 다음과 유사합니다(echo-backend에 유의하십시오. 이것은 echo.starter-kit.online 호스트와 /echo/ 소스 접두사에 매핑되어 있으며, quote-backend에 대해서도 동일합니다.):
마지막으로 로드 밸런서와 DigitalOcean 도메인 설정을 다시 구성한 후에 echo 및 quote 백엔드 서비스 엔드포인트가 UP인지 확인하십시오. Ambassador Edge 스택 백엔드 서비스 생성을(를) 참조하십시오.
다음 단계에서는 DOKS 클러스터를 의도적으로 삭제하여 재해를 시뮬레이션합니다.
이 단계에서는 재해 복구 시나리오를 시뮬레이션합니다. 전체 DOKS 클러스터가 삭제되고 이전 백업에서 복원됩니다.
먼저 전체 DOKS 클러스터에 대한 백업을 생성하십시오:
다음으로, 백업이 생성되었는지 확인하고 오류가 보고되지 않았는지 확인하십시오. 다음 명령은 사용 가능한 모든 백업을 나열합니다:
NAME STATUS ERRORS WARNINGS CREATED EXPIRES STORAGE LOCATION SELECTOR
all-cluster-backup Completed 0 0 2021-08-25 19:43:03 +0300 EEST 29d default <none>
출력은 다음과 유사합니다:
마지막으로, 백업 상태 및 로그를 검사하십시오(오류가 보고되지 않았는지 확인하십시오):
중요: doctl 명령에 --dangerous 플래그를 지정하지 않고 DOKS 클러스터를 파괴하고 다시 만들면 동일한 로드 밸런서가 동일한 IP로 재생성됩니다. 따라서 DigitalOcean DNS A 레코드를 업데이트할 필요가 없습니다.
그러나 doctl 명령에 --dangerous 플래그가 적용되면 Velero가 인그레스 컨트롤러를 복원할 때 기존 로드 밸런서가 파괴되고 새로운 외부 IP가 있는 새로운 로드 밸런서가 생성됩니다. 따라서 DigitalOcean DNS A 레코드를 업데이트하십시오.
먼저, 전체 DOKS 클러스터를 삭제하십시오(<> 플레이스홀더를 적절히 대체하십시오).
관련 로드 밸런서를 파괴하지 않고 Kubernetes 클러스터를 삭제하려면 다음을 실행하십시오:
또는 관련 로드 밸런서와 함께 Kubernetes 클러스터를 삭제하려면:
다음으로, DigitalOcean Kubernetes 설정에 설명된 대로 클러스터를 재생성하세요. 새로운 DOKS 클러스터 노드 수가 원래 것과 동일하거나 더 많은지 확인하는 것이 중요합니다.
그런 다음, 전제 조건 섹션 및 단계 1 – Helm을 사용하여 Velero 설치에 설명된대로 Velero CLI 및 서버를 설치하세요. 동일한 Helm 차트 버전을 사용하는 것이 중요합니다.
마지막으로 다음 명령을 실행하여 모든 것을 복원하세요:
먼저, all-cluster-backup 복원 설명 명령의 Phase 줄을 확인하세요. (대응하는 <> 자리 표시자를 교체하세요). 이것은 Completed라고 나와야 합니다.
이제 다음을 실행하여 모든 클러스터 리소스를 확인하세요:
이제 백엔드 애플리케이션은 HTTP 요청에 응답해야 합니다. Starter Kit 튜토리얼에서 사용된 백엔드 애플리케이션에 대한 자세한 내용은 Ambassador Edge Stack 백엔드 서비스 생성를 참조하십시오.
다음 단계에서는 DOKS 클러스터 응용 프로그램에 대한 예약 (또는 자동) 백업을 수행하는 방법을 배우게 됩니다.
일정에 따라 백업을 자동으로 수행하는 것은 매우 유용한 기능입니다. 이 기능을 사용하면 시스템을 이전에 작동하던 상태로 되돌릴 수 있어서 문제가 발생할 경우에 유용합니다.
예약된 백업을 생성하는 것은 매우 간단한 프로세스입니다. 1 분 간격의 예시가 아래에 제공되었습니다 (kube-system 네임스페이스가 선택되었습니다).
먼저 일정을 만듭니다:
schedule="*/1 * * * *"
Linux cronjob 형식도 지원됩니다:
다음으로 일정이 생성되었는지 확인합니다:
NAME STATUS CREATED SCHEDULE BACKUP TTL LAST BACKUP SELECTOR
kube-system-minute-backup Enabled 2021-08-26 12:37:44 +0300 EEST @every 1m 720h0m0s 32s ago <none>
출력은 다음과 유사합니다:
그런 다음 1 분 정도 지난 후 모든 백업을 검사합니다:
NAME STATUS ERRORS WARNINGS CREATED EXPIRES STORAGE LOCATION SELECTOR
kube-system-minute-backup-20210826093916 Completed 0 0 2021-08-26 12:39:20 +0300 EEST 29d default <none>
kube-system-minute-backup-20210826093744 Completed 0 0 2021-08-26 12:37:44 +0300 EEST 29d default <none>
출력은 다음과 유사합니다:
먼저 백업 중 하나에서 Phase 라인을 확인합니다 (반드시 <> 자리 표시자를 적절히 대체하십시오). Completed로 표시되어야 합니다.
일전부터 백업을 복원하려면, 이 튜토리얼의 이전 단계에서 배운 것과 동일한 단계를 따르십시오. 이는 지금까지 축적된 경험을 실습하고 테스트하는 좋은 방법입니다.
다음 단계에서는 시간이 경과함에 따라 만들어진 특정 백업을 수동 또는 자동으로 삭제하는 방법을 배우게 됩니다.
이전 백업이 필요하지 않은 경우 쿠버네티스 클러스터 및 Velero DO Spaces 버킷에서 일부 리소스를 확보할 수 있습니다.
먼저, 예를 들어 1분 전의 백업을 선택하고 다음 명령을 실행하십시오 (올바른 <> 플레이스홀더로 대체하십시오):
이제 velero backup get 명령의 출력에서 삭제되었는지 확인하십시오. DO Spaces 버킷에서도 삭제되어야합니다.
다음으로, selector를 사용하여 여러 백업을 한 번에 삭제합니다. velero backup delete 하위 명령에는 --selector라는 플래그가 제공됩니다. 이를 사용하면 Kubernetes 라벨을 기반으로 한 번에 여러 백업을 삭제할 수 있습니다.
첫째, 사용 가능한 백업을 나열하십시오:
NAME STATUS ERRORS WARNINGS CREATED EXPIRES STORAGE LOCATION SELECTOR
ambassador-backup Completed 0 0 2021-08-25 19:33:03 +0300 EEST 23d default <none>
backend-minute-backup-20210826094116 Completed 0 0 2021-08-26 12:41:16 +0300 EEST 24d default <none>
backend-minute-backup-20210826094016 Completed 0 0 2021-08-26 12:40:16 +0300 EEST 24d default <none>
backend-minute-backup-20210826093916 Completed 0 0 2021-08-26 12:39:16 +0300 EEST 24d default <none>
backend-minute-backup-20210826093816 Completed 0 0 2021-08-26 12:38:16 +0300 EEST 24d default <none>
backend-minute-backup-20210826093716 Completed 0 0 2021-08-26 12:37:16 +0300 EEST 24d default <none>
backend-minute-backup-20210826093616 Completed 0 0 2021-08-26 12:36:16 +0300 EEST 24d default <none>
backend-minute-backup-20210826093509 Completed 0 0 2021-08-26 12:35:09 +0300 EEST 24d default <none>
출력은 다음과 유사합니다:
다음으로, 모든 backend-minute-backup-* 자산을 삭제하려고합니다. 목록에서 백업을 선택하고 Labels를 검사하십시오:
Name: backend-minute-backup-20210826094116
Namespace: velero
Labels: velero.io/schedule-name=backend-minute-backup
velero.io/storage-location=default
Annotations: velero.io/source-cluster-k8s-gitversion=v1.21.2
velero.io/source-cluster-k8s-major-version=1
velero.io/source-cluster-k8s-minor-version=21
Phase: Completed
Errors: 0
Warnings: 0
Namespaces:
Included: backend
Excluded: <none>
...
출력은 다음과 같습니다(주목할 점은 velero.io/schedule-name 라벨 값입니다):
다음으로, velero.io/schedule-name 라벨의 backend-minute-backup 값과 일치하는 모든 백업을 삭제할 수 있습니다:
마지막으로, velero backup get 명령의 출력 및 DO Spaces 버킷에서 모든 backend-minute-backup-* 자산이 사라졌는지 확인하십시오.
- 백업을 생성할 때
--ttl플래그를 사용하여 TTL(Time To Live)을 지정할 수 있습니다. Velero는 기존 백업 리소스가 만료되었다는 것을 감지하면 다음을 제거합니다: - The
Backupresource - The 백업 파일 from cloud object
storage - All
PersistentVolume스냅샷
All associated Restores
TTL 플래그를 사용하면 사용자는 시간, 분 및 초로 지정된 값으로 백업 보존 기간을 지정할 수 있습니다. 형식은 --ttl 24h0m0s입니다. 지정되지 않으면 기본 TTL 값으로 30일이 적용됩니다.
먼저 TTL 값이 3분인 ambassador 백업을 생성합니다:
다음으로 ambassador 백업을 검사합니다:
Name: ambassador-backup-3min-ttl
Namespace: velero
Labels: velero.io/storage-location=default
Annotations: velero.io/source-cluster-k8s-gitversion=v1.21.2
velero.io/source-cluster-k8s-major-version=1
velero.io/source-cluster-k8s-minor-version=21
Phase: Completed
Errors: 0
Warnings: 0
Namespaces:
Included: ambassador
Excluded: <none>
Resources:
Included: *
Excluded: <none>
Cluster-scoped: auto
Label selector: <none>
Storage Location: default
Velero-Native Snapshot PVs: auto
TTL: 3m0s
...
A new folder should be created in the DO Spaces Velero bucket as well, named ambassador-backup-3min-ttl.
출력은 다음과 유사한 모습입니다(Namespaces -> Included 섹션을 주목하세요 – ambassador가 표시되어야 하며 TTL 필드는 3ms0으로 설정되어 있어야 합니다):
마지막으로, 세 분 후 백업 및 관련 리소스가 자동으로 삭제됩니다. 백업 객체가 파괴되었는지 확인할 수 있습니다: velero backup describe ambassador-backup-3min-ttl. 더 이상 백업이 존재하지 않음을 나타내는 오류가 발생해야 합니다. 해당하는 ambassador-backup-3min-ttl 폴더는 DO Spaces Velero 버킷에서도 삭제됩니다.