













데이터베이스 샤딩은 데이터를 “샤드”라고 불리는 작은 조각으로 나누는 과정입니다. 샤딩은 쓰기를 확장해야 할 필요가 있을 때 일반적으로 도입됩니다. 성공적인 애플리케이션의 수명주기 동안 데이터베이스 서버는 처리 또는 용량 수준에서 수행할 수 있는 최대 쓰기 횟수에 도달합니다. 데이터를 여러 샤드로 자르고—각각이 자체 데이터베이스 서버에 있으면—각 개별 노드의 스트레스를 줄이고 전반적인 데이터베이스의 쓰기 용량을 효과적으로 늘립니다. 이것이 데이터베이스 샤딩입니다.
분산 SQL은 샤딩과 유사한 전략을 완전히 자동화하고 애플리케이션에 투명하게 관계형 데이터베이스를 확장하는 새로운 방법입니다. 분산 SQL 데이터베이스는 거의 선형으로 확장할 수 있도록 처음부터 설계되었습니다. 이 기사에서는 분산 SQL의 기본 사항과 시작하는 방법에 대해 알아보겠습니다.
데이터베이스 샤딩의 단점
샤딩은 다음과 같은 여러 가지 과제를 초래합니다:
- 데이터 분할: 여러 샤드에 데이터를 분할하는 방법을 결정하는 것은 데이터 인접성과 데이터 분포의 균형을 찾는 데 어려움을 겪을 수 있으며, 호환성을 피하기 위해 데이터 분포의 균형을 찾는 데 어려움을 겪을 수 있습니다.
- 장애 처리: 키 노드에 장애가 발생하여 부하를 감당할 수 있는 충분한 샤드가 없는 경우 어떻게 중지 없이 새 노드에 데이터를 가져올 수 있습니까?
- 쿼리 복잡성: 애플리케이션 코드가 데이터 분할 로직에 연결되어 있으며, 여러 노드의 데이터가 필요한 쿼리는 재조인해야 합니다.
- 데이터 일관성: 여러 샤드에서의 데이터 일관성을 보장하는 것은 동시에 업데이트가 이루어질 때 샤드 간 업데이트를 조정해야 하므로 어려울 수 있습니다. 서로 다른 쓰기 사이의 충돌을 해결해야 할 수도 있습니다.
- 탄력적 확장성: 데이터 양이나 쿼리 수가 증가함에 따라 데이터베이스에 추가 샤드를 추가해야 할 수 있습니다. 이는 데이터를 모든 샤드에 골고루 재배치하기 위한 수동 프로세스를 요구하는 복잡한 과정이며, 피할 수 없는 가동 중지 시간이 발생할 수 있습니다.
이러한 단점 중 일부는 다중 언어 지속성(다양한 작업에 다양한 데이터베이스 사용) 채택, 데이터베이스 기본 샤딩 기능을 갖춘 스토리지 엔진, 또는 데이터베이스 프록시를 사용하여 완화될 수 있습니다. 그러나 데이터베이스 샤딩의 일부 문제를 해결하는 데 도움이 되더라도 이러한 도구는 제한이 있으며 지속적인 관리가 필요한 복잡성을 초래합니다.
분산 SQL이란 무엇인가?
분산 SQL은 신세대 관계형 데이터베이스를 지칭합니다. 간단히 말해, 분산 SQL 데이터베이스는 응용 프로그램에게 단일 논리적 데이터베이스처럼 보이는 투명한 샤딩을 가진 관계형 데이터베이스입니다. 분산 SQL 데이터베이스는 공유 없는 아키텍처로 구현되며, 읽기와 쓰기 모두를 확장할 수 있는 스토리지 엔진을 갖추고 있으며, 진정한 ACID 준수와 고가용성을 유지합니다. 분산 SQL 데이터베이스는 2000년대에 인기를 얻은 NoSQL 데이터베이스의 확장성 기능을 갖추고 있지만, 일관성을 희생하지 않습니다. 관계형 데이터베이스의 이점을 유지하면서 다중 지역 내구성을 포함한 클라우드 호환성을 추가합니다.
A different but related term is NewSQL (coined by Matthew Aslett in 2011). This term also describes scalable and performant relational databases. However, NewSQL databases don’t necessarily include horizontal scalability.
분산 SQL은 어떻게 작동할까요?
분산 SQL이 어떻게 작동하는지 이해하기 위해 MariaDB Xpand의 사례를 살펴보겠습니다. 이는 오픈 소스 MariaDB 데이터베이스와 호환되는 분산 SQL 데이터베이스입니다. Xpand은 데이터와 인덱스를 노드 간에 분할하고 데이터 재조정 및 분산 쿼리 실행과 같은 작업을 자동으로 수행합니다. 쿼리는 지연 시간을 최소화하기 위해 병렬로 실행됩니다. 데이터는 단일 장애 지점이 없도록 자동으로 복제됩니다. 노드에 장애가 발생하면 Xpand은 생존하는 노드 간에 데이터를 재조정합니다. 새 노드가 추가될 때도 마찬가지입니다. rebalancer라는 구성 요소는 하나의 노드가 다른 노드에 비해 너무 많은 거래를 처리해야 하는 경우 발생하는 핫스팟이 없도록 보장합니다. 이는 수동 데이터베이스 샤딩의 문제점입니다.
예를 들어 봅시다. some_table과 여러 행을 가진 데이터베이스 인스턴스가 있다고 가정합니다:
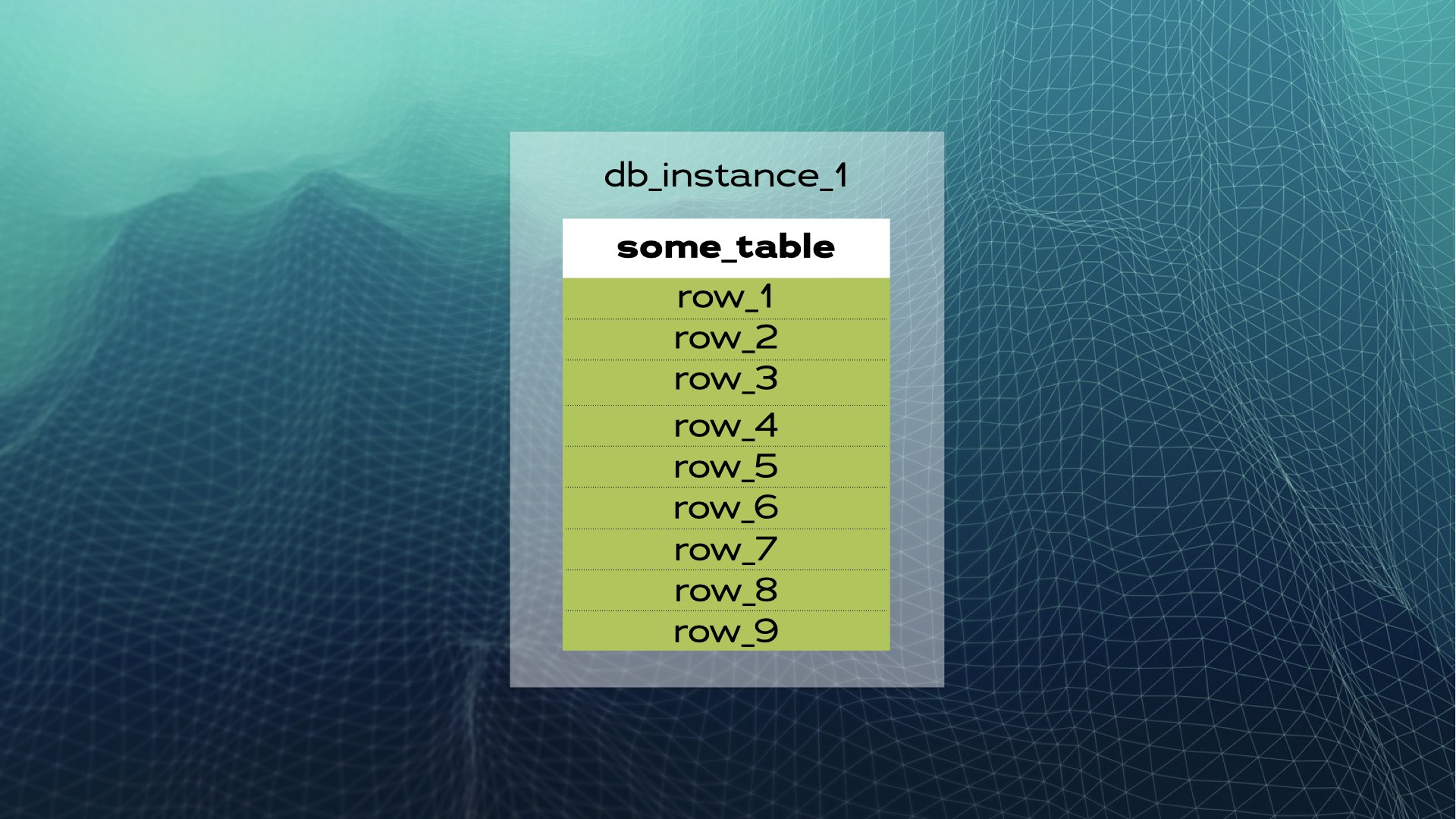
데이터를 세 조각(샤드)으로 나눌 수 있습니다:

그런 다음 각 데이터 조각을 별도의 데이터베이스 인스턴스로 이동합니다.
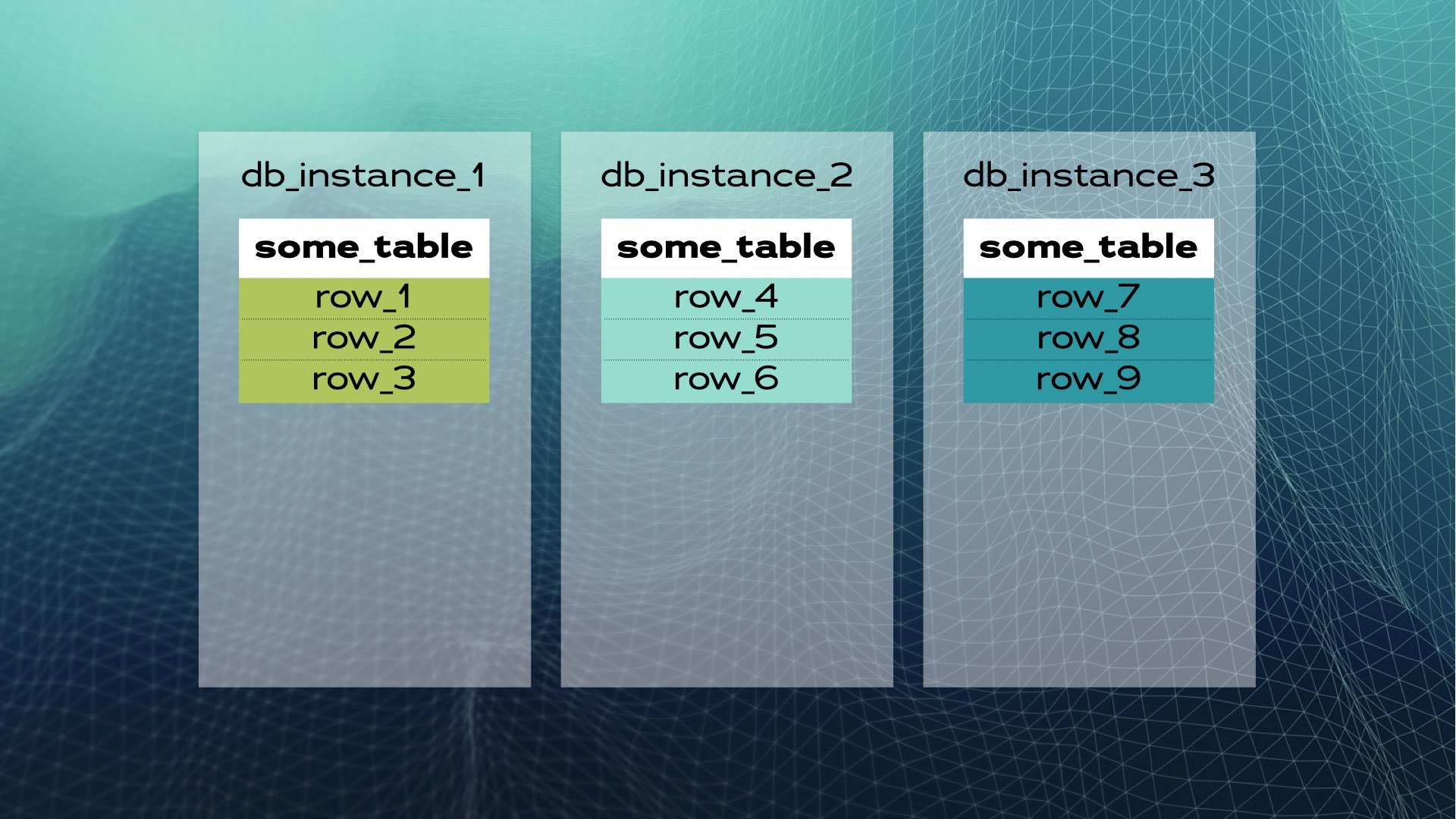
이것이 수동 데이터베이스 공유의 모습입니다. 분산 SQL은 이를 자동으로 수행해 줍니다. Xpand의 경우, 각 샤드는 조각이라고 불립니다. 행은 테이블 컬럼의 하위 집합에 대한 해시를 사용하여 조각화됩니다. 데이터뿐만 아니라 인덱스도 조각화되어 노드(데이터베이스 인스턴스) 간에 분산됩니다. 또한 고가용성을 유지하기 위해 조각은 다른 노드에 복제됩니다(노드당 복제본 수는 구성 가능). 이것은 자동으로 발생합니다:
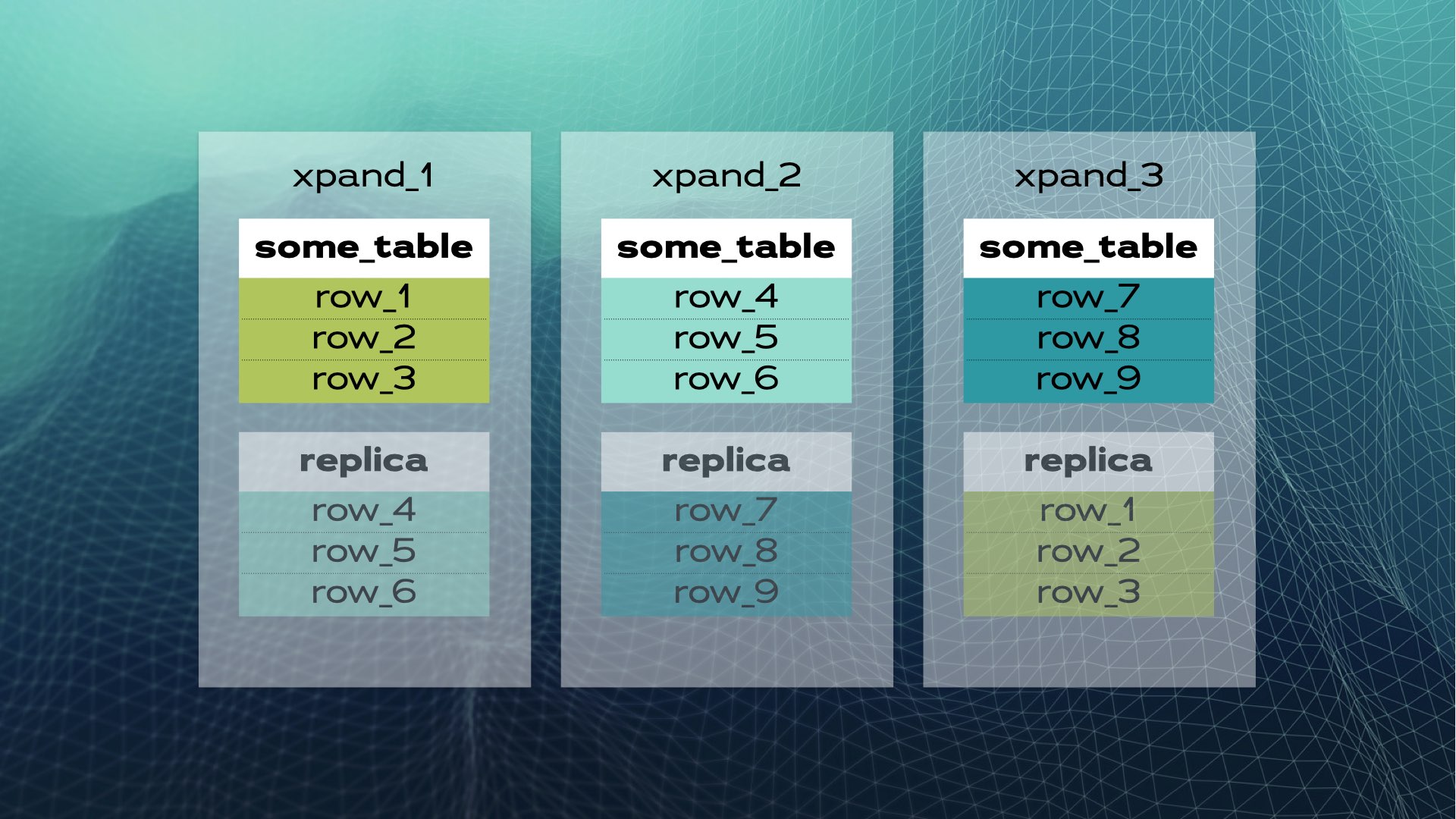
클러스터에 새 노드가 추가되거나 한 노드에 장애가 발생할 때, Xpand은 수동 개입 없이 데이터를 자동으로 재배치합니다. 이전 클러스터에 노드가 추가될 때 발생하는 상황은 다음과 같습니다:

일부 행이 새 노드로 이동되어 전반적인 시스템 용량을 늘립니다. 다만, 다이어그램에는 표시되지 않았지만 인덱스와 복제본도 함께 이동되고 업데이트됩니다. 이전 클러스터에 대한 조금 더 완전한 뷰(데이터 재배치가 약간 다른)는 다음 다이어그램에 나와 있습니다:
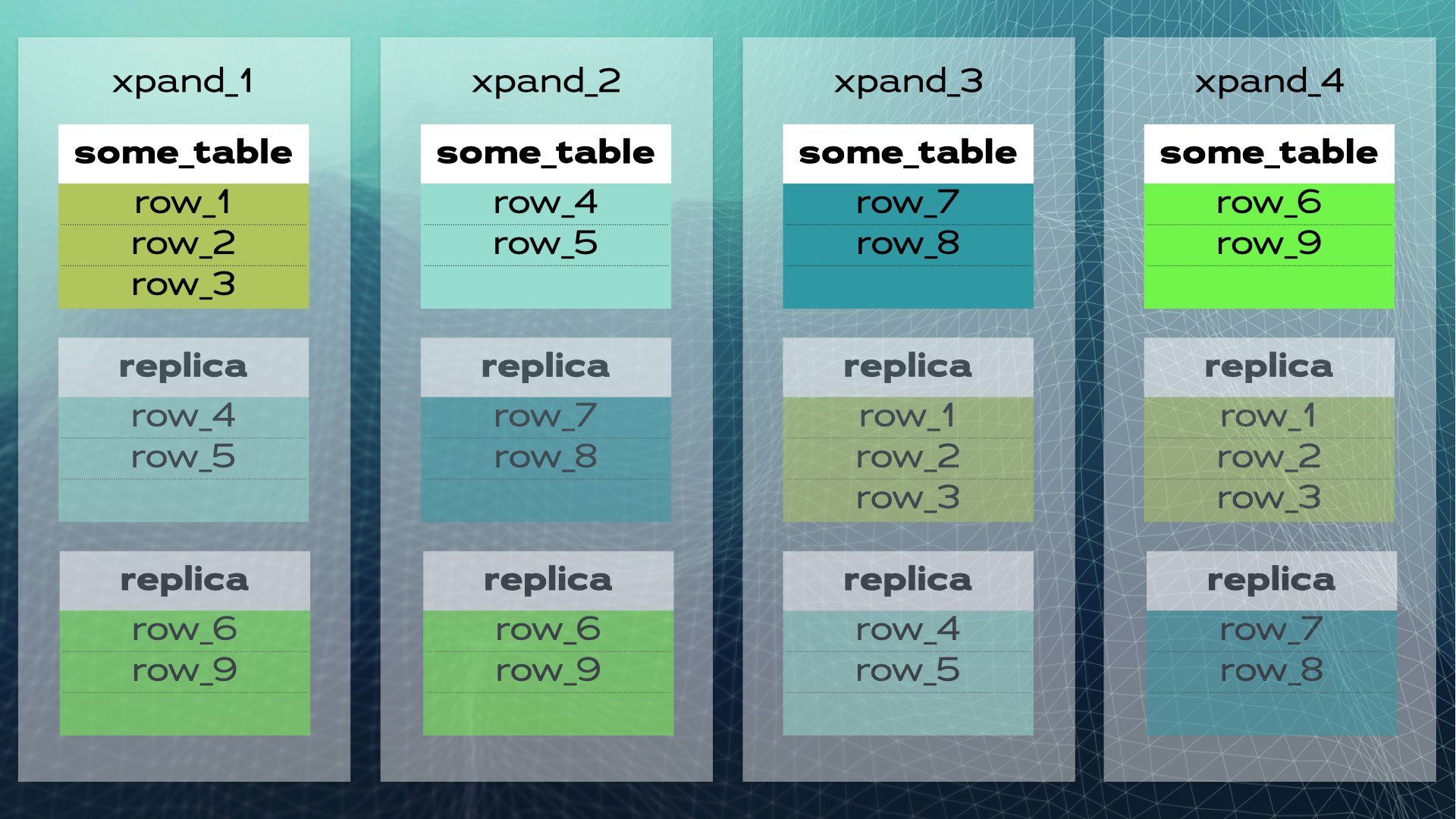
이러한 아키텍처는 거의 선형적인 확장성을 가능하게 합니다. 애플리케이션 수준에서 수동 개입이 필요하지 않습니다. 애플리케이션에게 클러스터는 단일 논리적 데이터베이스처럼 보입니다. 애플리케이션은 로드 밸런서(MariaDB MaxScale)를 통해 데이터베이스에 연결합니다:
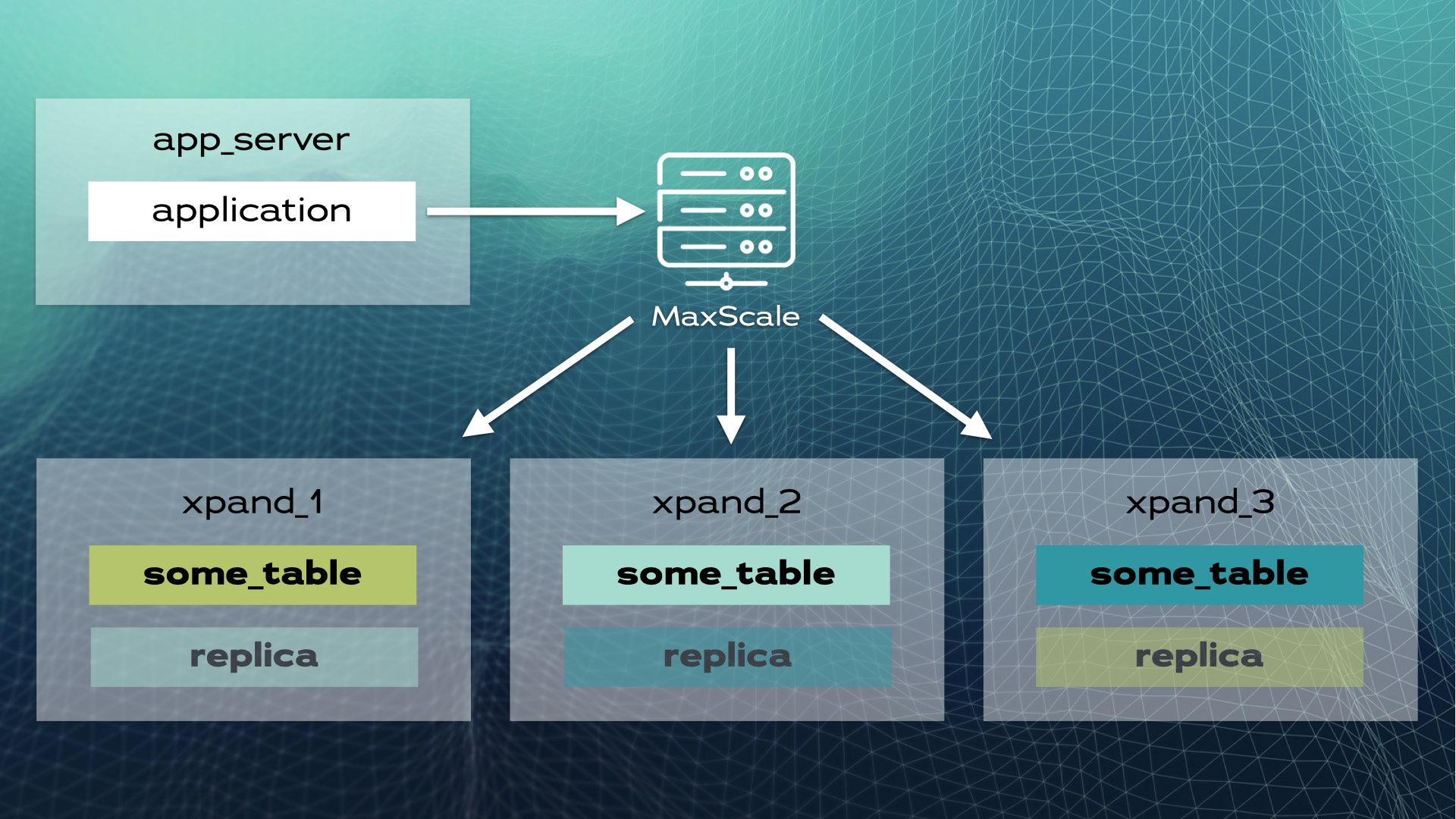
애플리케이션이 쓰기 작업(예: INSERT 또는 UPDATE)을 보낼 때, 해시가 계산되어 정확한 조각으로 전송됩니다. 여러 쓰기 작업은 병렬로 여러 노드에 전송됩니다.
분산 SQL 사용 시 고려사항
데이터베이스 샤딩은 성능을 향상시키지만 노드 간 통신 수준에서 추가적인 오버헤드를 초래합니다. 데이터베이스가 제대로 구성되지 않았거나 쿼리 라우터가 최적화되지 않은 경우 성능이 느려질 수 있습니다. 분산 SQL은 초당 10K 쿼리 미만 또는 초당 5K 트랜잭션 미만의 애플리케이션에서 가장 좋은 대안은 아닙니다. 또한 데이터베이스가 대부분 작은 테이블로 구성되어 있다면 모놀리식 데이터베이스가 더 나은 성능을 보일 수 있습니다.
분산 SQL 시작하기
분산 SQL 데이터베이스는 애플리케이션에게 하나의 논리적 데이터베이스처럼 보이기 때문에 시작하기 간단합니다. 필요한 것은 다음과 같습니다:
Docker는 두 번째 부분을 쉽게 만듭니다. 예를 들어, MariaDB는 평가, 테스트 및 개발을 위해 단일 노드 Xpand 데이터베이스를 시작할 수 있는 mariadb/xpand-single Docker 이미지를 제공합니다.
Xpand 컨테이너를 시작하려면 다음 명령을 실행하십시오:
docker run --name xpand \
-d \
-p 3306:3306 \
--ulimit memlock=-1 \
mariadb/xpand-single \
--user "user" \
--passwd "password"Docker 이미지 상세 내용은 문서화를 참조하세요.
참고: 이 글을 작성하는 시점에서 mariadb/xpand-single Docker 이미지는 ARM 아키텍처에서 사용할 수 없습니다. 이러한 아키텍처(예: M1 프로세서를 탑재한 Apple 시스템)에서는 UTM을 사용하여 가상 머신(VM)을 생성하고, 예를 들어 Debian을 설치합니다. 호스트 이름을 할당하고 SSH를 사용하여 VM에 연결하여 Docker를 설치하고 MariaDB Xpand 컨테이너를 생성합니다.
데이터베이스 연결
Xpand 데이터베이스에 연결하는 것은 MariaDB 커뮤니티 또는 엔터프라이즈 서버에 연결하는 것과 동일합니다. mariadb CLI 도구를 설치한 경우 다음을 실행하면 됩니다.
mariadb -h 127.0.0.1 -u user -pSQL 데이터베이스의 GUI를 사용하여 데이터베이스에 연결할 수 있습니다. 예를 들면 DBeaver, DataGrip 또는 IDE용 SQL 확장 프로그램(예: 이것은 VS Code용입니다)과 같은 것들이 있습니다. 우리는 DbGate라는 무료이자 오픈 소스 SQL 클라이언트를 사용할 것입니다. DbGate를 다운로드하여 데스크톱 애플리케이션으로 실행하거나, Docker를 사용하고 있다면 웹 브라우저를 통해 어디서든지 접근할 수 있는 웹 애플리케이션으로 배포할 수 있습니다(인기 있는 phpMyAdmin과 유사합니다). 다음 명령어를 실행하세요:
docker run -d --name dbgate -p 3000:3000 dbgate/dbgate컨테이너가 시작되면 브라우저를 http://localhost:3000/으로 이동하세요. 연결 정보를 입력하세요:
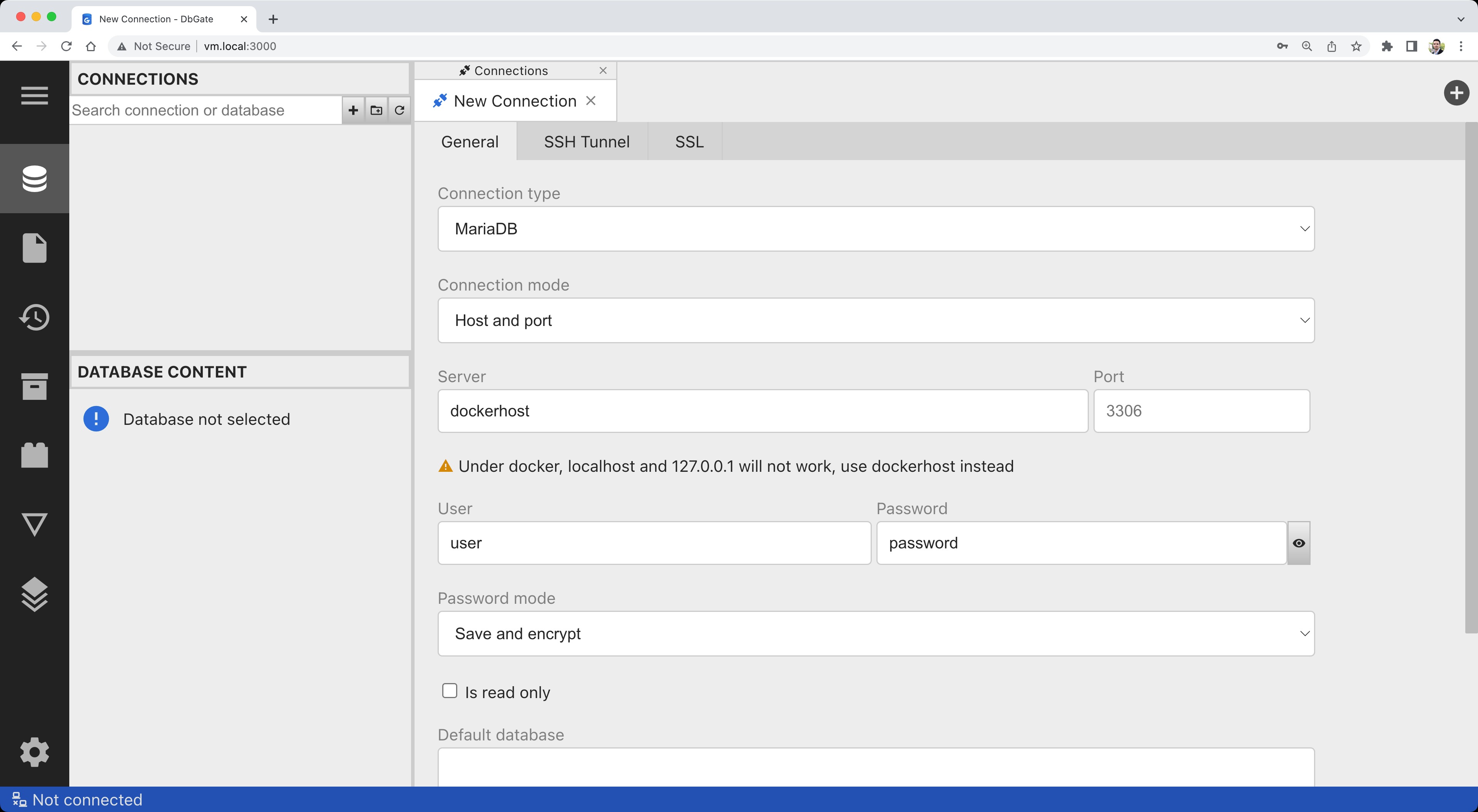
연결이 성공적인지 확인하려면 Test를 클릭하세요:

Save를 클릭하고 왼쪽 패널에서 연결을 우클릭하여 Create database를 선택하여 새 데이터베이스를 만드세요. 테이블을 생성하거나 SQL 스크립트를 가져와 보거나, 단순히 시험해 보고 싶다면 Nation 또는 Sakila는 좋은 예시 데이터베이스입니다.
Java, JavaScript, Python, C++에서 연결
Xpand에 애플리케이션으로부터 연결하려면 MariaDB 커넥터를 사용할 수 있습니다. 다양한 프로그래밍 언어와 지속성 프레임워크의 조합이 가능합니다. 이 문서의 범위를 벗어나지만, 시작하고 싶거나 실제로 보고 싶다면 이 빠른 시작 페이지를 살펴보세요. 여기에는 Java, JavaScript, Python, C++용 코드 예제가 있습니다.
분산 SQL의 진정한 힘
이 문서에서는 개발 및 테스트 목적으로 단일 노드 Xpand을 시작하는 방법을 배웠습니다. 이는 프로덕션 작업 부하와는 반대입니다. 그러나 분산 SQL 데이터베이스의 진정한 힘은 데이터를 최적으로 재배치하는 재배치기를 통해 노드를 추가하여 읽기(고전적인 데이터베이스 샤딩처럼)뿐만 아니라 쓰기도 확장할 수 있는 기능에 있습니다. Xpand을 다중 노드 토폴로지에서 배포할 수 있지만, 프로덕션에서 가장 쉽게 사용하는 방법은 SkySQL을 통해서입니다.
분산 SQL 및 MariaDB Xpand에 대해 자세히 알고 싶으시면 다음은 유용한 자료 목록입니다:
Source:
https://dzone.com/articles/distributed-sql-an-alternative-to-sharding