













이 시리즈의 Part 1에서는 가장 신뢰성 있고 견고한 문서 중심의 NoSQL 데이터베이스 중 하나인 MongoDB를 살펴보았습니다. 여기 Part 2에서는 또 다른 피할 수 없는 NoSQL 데이터베이스인 Elasticsearch를 탐구해보겠습니다.
mere히 인기 있고 강력한 오픈 소스 분산형 NoSQL 데이터베이스를 넘어, Elasticsearch는 우선 검색 및 분석 엔진입니다. 이는 가장 유명한 검색 엔진 Apache Lucene Java 라이브러리 위에 구축되었으며, 구조화된 데이터와 비구조화된 데이터에 대한 실시간 검색 및 분석 작업을 수행할 수 있습니다. 대량의 데이터를 효율적으로 처리할 수 있도록 설계되었습니다.
다시 한번 이 짧은 글은 Elasticsearch 튜토리얼이 아님을 명확히 하겠습니다. 따라서 독자는 공식 문서를 광범위하게 활용하며, Madhusudhan Konda 저의 “Elasticsearch in Action“(Manning, 2023)과 같은 훌륭한 책을 통해 제품의 아키텍처와 운영에 대해 더 배우는 것이 강력히 권장됩니다. 여기서는 이전과 같은 사용 사례를 다시 구현하는 것으로, 이번에는 MongoDB 대신 Elasticsearch를 사용합니다.
그럼 시작해보겠습니다!
도메인 모델
아래 다이어그램은 우리의 *customer-order-product* 도메인 모델을 보여줍니다:
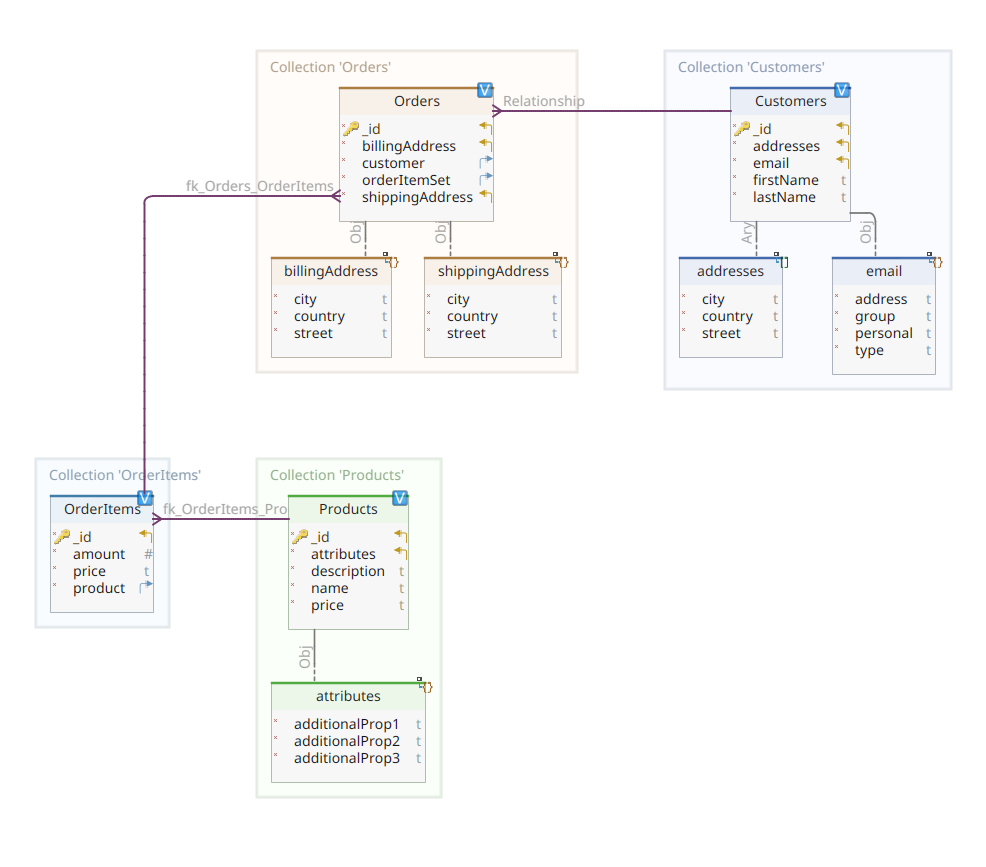
이 다이어그램은 Part 1에서 제시된 것과 동일합니다. MongoDB와 마찬가지로 Elasticsearch는 문서 데이터 저장소이며, 따라서 문서는 JSON 표기법으로 제시되어야 합니다. 유일한 차이는 Elasticsearch가 데이터를 처리하기 위해서는 인덱싱이 필요하다는 점입니다.
Elasticsearch 데이터 저장소에서 데이터를 인덱싱하는 방법은 여러 가지가 있습니다; 예를 들어, 관계형 데이터베이스에서 파이프를 통해 가져오거나 파일시스템에서 추출하거나 실시간 소스에서 스트리밍하는 등입니다. 하지만 데이터 흡수 방법이 무엇이든, 결국 Elasticsearch RESTful API를 전용 클라이언트를 통해 호출하는 것으로 구성됩니다. 이러한 전용 클라이언트는 두 가지 범주로 나눌 수 있습니다:
- REST 기반 클라이언트는
curl,Postman, Java, JavaScript, Node.js 등의 HTTP 모듈입니다. - 프로그래밍 언어 SDKs(소프트웨어 개발 킷): Elasticsearch는 Java, Python 등 가장 많이 사용되는 프로그래밍 언어 모두에 대해 SDK를 제공합니다.
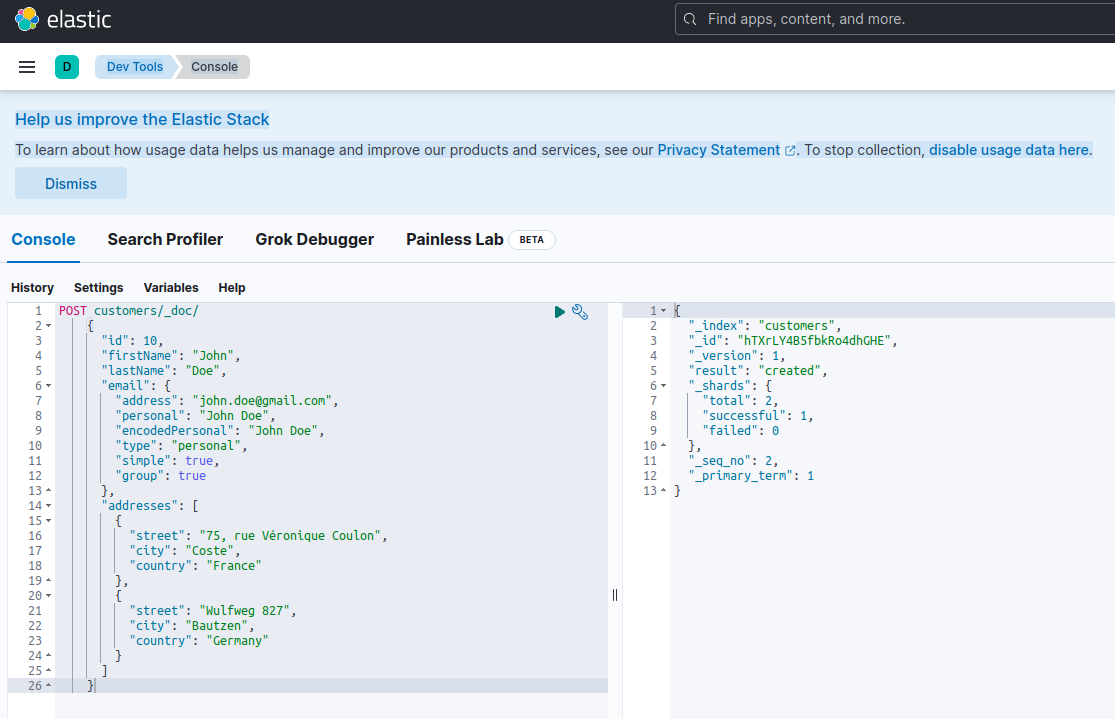
Elasticsearch에서 새 문서를 인덱싱하다는 것은 특별한 RESTful API 엔드포인트인 _doc에 대해 POST 요청을 사용하여 생성하는 것을 의미합니다. 예를 들어, 다음 요청은 새 Elasticsearch 인덱스를 생성하고 새 고객 인스턴스를 저장합니다.
POST customers/_doc/
{
"id": 10,
"firstName": "John",
"lastName": "Doe",
"email": {
"address": "[email protected]",
"personal": "John Doe",
"encodedPersonal": "John Doe",
"type": "personal",
"simple": true,
"group": true
},
"addresses": [
{
"street": "75, rue Véronique Coulon",
"city": "Coste",
"country": "France"
},
{
"street": "Wulfweg 827",
"city": "Bautzen",
"country": "Germany"
}
]
}위 요청을 curl 또는 Kibana 콘솔(나중에 설명하겠습니다)을 사용하여 실행하면 다음과 같은 결과를 생성합니다:
{
"_index": "customers",
"_id": "ZEQsJI4BbwDzNcFB0ubC",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 1,
"_primary_term": 1
}
이것은 POST 요청에 대한 Elasticsearch 표준 응답입니다. 이 응답은 customers라는 인덱스를 생성했음을 확인하며, 새로운 customer 문서가 자동으로 생성된 ID(ZEQsJI4BbwDzNcFB0ubC)로 식별된다.
다른 흥미로운 매개변수도 여기에 나타나는데, _version과 특히 _shards가 그 중 하나입니다.太多한 설명을 하지 않자면, Elasticsearch는 문서의 논리적 모음으로 인덱스를 생성합니다. 서류 문서를 파일 캐비닛에 보관하는 것처럼, Elasticsearch는 인덱스에 문서를 보관합니다. 각 인덱스는 shards,로 구성되어 있으며, 이는 Apache Lucene의 물리적인 인스턴스로, 데이터를 저장하거나 저장에서 꺼내는 데 책임이 있는 백그라운드 엔진입니다. 이 shard는 primary일 수도 있고, 문서를 저장하거나 replicas일 수도 있으며, 이름 그대로 primary shard의 사본을 저장합니다. 이에 대한 자세한 내용은 Elasticsearch 문서에서 찾아볼 수 있습니다 – 현재 우리는 customers라는 인덱스가 두 개의 shard로 구성되어 있으며, 그 중 하나는 물론 primary임을 주목해야 합니다.
A final notice: the POST request above doesn’t mention the ID value as it is automatically generated. While this is probably the most common use case, we could have provided our own ID value. In each case, the HTTP request to be used isn’t POST anymore, but PUT.
다시 도메인 모델 다이어그램으로 돌아가면, 보시다시피 그 중심 문서는 Order로, Orders라는 전용 컬렉션에 저장됩니다. Order는 OrderItem 문서의 집합으로, 각 OrderItem은 연관된 Product를 가리킵니다. Order 문서는 또한 주문을下单한 Customer를 참조합니다. Java에서 이는 다음과 같이 구현됩니다:
public class Customer
{
private Long id;
private String firstName, lastName;
private InternetAddress email;
private Set<Address> addresses;
...
}
위의 코드는 Customer 클래스의 프래그먼트를 보여줍니다. 이 클래스는 고객의 ID, 이름, 이메일 주소, 그리고 우편 주소 집합과 같은 속성을 가진 간단한 POJO(Plain Old Java Object)입니다.
이제 Order 문서를 살펴보겠습니다.
public class Order
{
private Long id;
private String customerId;
private Address shippingAddress;
private Address billingAddress;
private Set<String> orderItemSet = new HashSet<>()
...
}
여기서 MongoDB 버전과 비교하여 몇 가지 차이점을 발견할 수 있습니다. 사실, MongoDB에서는 이 주문과 관련된 고객 인스턴스에 대한 참조를 사용했습니다. Elasticsearch에서는 참조 개념이 존재하지 않기 때문에, 이 문서 ID를 사용하여 주문과 주문을 한 고객 간의 연관을 생성합니다. orderItemSet 속성에 대해서도 마찬가지로 주문과 그 항목 간의 연관을 생성합니다.
우리의 도메인 모델의 나머지 부분은 같은 정규화 아이디어를 기반으로 매우 유사합니다. 예를 들어, OrderItem 문서:
public class OrderItem
{
private String id;
private String productId;
private BigDecimal price;
private int amount;
...
}
여기서는 현재 주문 항목의 대상이 되는 제품을 연관시켜야 합니다. 마지막으로, Product 문서:
public class Product
{
private String id;
private String name, description;
private BigDecimal price;
private Map<String, String> attributes = new HashMap<>();
...
}데이터 리포지토리
Quarkus Panache는 데이터 저장 절차를 액티브 레코드와 리포지토리 디자인 패턴을 지원하여 크게 단순화합니다. Part 1에서는 Quarkus Panache 확장을 사용하여 MongoDB를 위한 데이터 리포지토리를 구현했지만, Elasticsearch에 대한 동일한 Quarkus Panache 확장은 아직 없습니다. 따라서 Elasticsearch의 가능한 미래 확장을 기다리는 동안, 우리는 Elasticsearch 전용 클라이언트를 사용하여 데이터 리포지토리를 수동으로 구현해야 합니다.
Elasticsearch는 자바로 작성되었으며, 그 결과 자바 클라이언트 라이브러리를 사용하여 Elasticsearch API를 호출하는 데 네이티브 지원을 제공하는 것은 놀라운 일이 아닙니다. 이 라이브러리는 fluent API 빌더 디자인 패턴을 기반으로 하며 동기 및 비동기 처리 모델을 제공합니다. 최소 Java 8이 필요합니다.
그렇다면, 우리의 fluent API 빌더 기반 데이터 리포지토리는 어떻게 보일까요? 아래는 CustomerServiceImpl 클래스의 일부로, Customer 문서를 위한 데이터 리포지토리 역할을 합니다.
@ApplicationScoped
public class CustomerServiceImpl implements CustomerService
{
private static final String INDEX = "customers";
@Inject
ElasticsearchClient client;
@Override
public String doIndex(Customer customer) throws IOException
{
return client.index(IndexRequest.of(ir -> ir.index(INDEX).document(customer))).id();
}
...
우리가 볼 수 있듯이, 데이터 리포지토리 구현은 애플리케이션 범위를 가진 CDI 비지이어여야 합니다. Elasticsearch 자바 클라이언트는 quarkus-elasticsearch-java-client Quarkus 확장을 통해 단순히 주입됩니다. 이 방식은 그렇지 않으면 사용해야 했던 많은 장식을 피할 수 있습니다. 클라이언트를 주입할 수 있도록 선언해야 하는 유일한 것은 다음 프로퍼티입니다:
quarkus.elasticsearch.hosts = elasticsearch:9200이하 elasticsearch는 docker-compose.yaml 파일에서 Elastic search 데이터베이스 서버와 연결되는 DNS(도메인 네임 서버) 이름입니다. 9200은 서버가 연결을 수신하도록 사용하는 TCP 포트 번호입니다.
위의 doIndex() 메서드는 customers라는 새로운 인덱스가 존재하지 않으면 새로 만들고, Customer 클래스의 인스턴스를 나타내는 새로운 문서를 인덱스( 저장)합니다. 인덱싱 과정은 인덱스 이름과 문서 본문을 입력 인자로 받는 IndexRequest를 기반으로 수행됩니다. 문서 ID는 자동으로 생성되고, 후속 참조를 위해 호출자에게 반환됩니다.
다음 메서드는 입력 인자로 주어진 ID로 식별되는 고객을 검색하는 데 사용됩니다:
...
@Override
public Customer getCustomer(String id) throws IOException
{
GetResponse<Customer> getResponse = client.get(GetRequest.of(gr -> gr.index(INDEX).id(id)), Customer.class);
return getResponse.found() ? getResponse.source() : null;
}
...
원리는 같습니다: 이 fluency API 빌더 패턴을 사용하여 GetRequest 인스턴스를 IndexRequest와 같은 방식으로 구축하고, Elasticsearch Java 클라이언트에 대해 실행합니다. 우리 데이터 저장소의 다른 엔드포인트는 전체 검색 작업을 수행하거나 고객을 업데이트하고 삭제하는 데 사용되며, 같은 방식으로 설계됩니다.
코드를 살펴보아서 어떻게 작동하는지 이해해 보세요.
REST API
우리의 MongoDB REST API 인터페이스는 `quarkus-mongodb-rest-data-panache` 확장 덕분에 간단히 구현할 수 있었습니다. 이 확장의 애노테이션 프로세서는 자동으로 모든 필요한 엔드포인트를 생성합니다. Elasticsearch의 경우, 아직 같은 편리함을 누리지 못하고 있으며, 따라서 수동으로 구현해야 합니다. 그러나 큰 문제는 아니며, 아래와 같이 이전 데이터 리포지토리를 주입할 수 있습니다:
@Path("customers")
@Produces(APPLICATION_JSON)
@Consumes(APPLICATION_JSON)
public class CustomerResourceImpl implements CustomerResource
{
@Inject
CustomerService customerService;
@Override
public Response createCustomer(Customer customer, @Context UriInfo uriInfo) throws IOException
{
return Response.accepted(customerService.doIndex(customer)).build();
}
@Override
public Response findCustomerById(String id) throws IOException
{
return Response.ok().entity(customerService.getCustomer(id)).build();
}
@Override
public Response updateCustomer(Customer customer) throws IOException
{
customerService.modifyCustomer(customer);
return Response.noContent().build();
}
@Override
public Response deleteCustomerById(String id) throws IOException
{
customerService.removeCustomerById(id);
return Response.noContent().build();
}
}이것은 고객의 REST API 구현입니다. 주문, 주문 항목 및 제품과 관련된 다른 것들은 비슷합니다.
이제 전체를 어떻게 실행하고 테스트하는지 보겠습니다.
마이크로서비스 실행 및 테스트
이제 구현의 세부 사항을 살펴보았으므로, 어떻게 실행하고 테스트하는지 보겠습니다. 우리는 `docker-compose` 유틸리티를 대신하여 이 작업을 수행하기로 했습니다. 다음은 관련 `docker-compose.yml` 파일입니다:
version: "3.7"
services:
elasticsearch:
image: elasticsearch:8.12.2
environment:
node.name: node1
cluster.name: elasticsearch
discovery.type: single-node
bootstrap.memory_lock: "true"
xpack.security.enabled: "false"
path.repo: /usr/share/elasticsearch/backups
ES_JAVA_OPTS: -Xms512m -Xmx512m
hostname: elasticsearch
container_name: elasticsearch
ports:
- "9200:9200"
- "9300:9300"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- node1-data:/usr/share/elasticsearch/data
networks:
- elasticsearch
kibana:
image: docker.elastic.co/kibana/kibana:8.6.2
hostname: kibana
container_name: kibana
environment:
- elasticsearch.url=http://elasticsearch:9200
- csp.strict=false
ulimits:
memlock:
soft: -1
hard: -1
ports:
- 5601:5601
networks:
- elasticsearch
depends_on:
- elasticsearch
links:
- elasticsearch:elasticsearch
docstore:
image: quarkus-nosql-tests/docstore-elasticsearch:1.0-SNAPSHOT
depends_on:
- elasticsearch
- kibana
hostname: docstore
container_name: docstore
links:
- elasticsearch:elasticsearch
- kibana:kibana
ports:
- "8080:8080"
- "5005:5005"
networks:
- elasticsearch
environment:
JAVA_DEBUG: "true"
JAVA_APP_DIR: /home/jboss
JAVA_APP_JAR: quarkus-run.jar
volumes:
node1-data:
driver: local
networks:
elasticsearch:
이 파일은 `docker-compose` 유틸리티에 세 가지 서비스를 실행하도록 지시합니다:
- A service named
elasticsearchrunning the Elasticsearch 8.6.2 database - A service named
kibanarunning the multipurpose web console providing different options such as executing queries, creating aggregations, and developing dashboards and graphs - A service named
docstorerunning our Quarkus microservice
이제 모든 필요한 프로세스가 실행되고 있는지 확인할 수 있습니다:
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
005ab8ebf6c0 quarkus-nosql-tests/docstore-elasticsearch:1.0-SNAPSHOT "/opt/jboss/containe…" 3 days ago Up 3 days 0.0.0.0:5005->5005/tcp, :::5005->5005/tcp, 0.0.0.0:8080->8080/tcp, :::8080->8080/tcp, 8443/tcp docstore
9678c0a04307 docker.elastic.co/kibana/kibana:8.6.2 "/bin/tini -- /usr/l…" 3 days ago Up 3 days 0.0.0.0:5601->5601/tcp, :::5601->5601/tcp kibana
805eba38ff6c elasticsearch:8.12.2 "/bin/tini -- /usr/l…" 3 days ago Up 3 days 0.0.0.0:9200->9200/tcp, :::9200->9200/tcp, 0.0.0.0:9300->9300/tcp, :::9300->9300/tcp elasticsearch
$
Elasticsearch 서버가 사용 가능하고 쿼리를 실행할 수 있는지 확인하려면, http://localhost:601에서 Kibana에 연결하세요. 페이지를 아래로 卷帘하고 기본 메뉴에서 `Dev Tools`를 선택한 후, 아래와 같이 쿼리를 실행할 수 있습니다:
마이크로서비스를 테스트하려면 다음과 같이 하세요:
1. 관련 GitHub 리포지토리를 클론합니다:
$ git clone https://github.com/nicolasduminil/docstore.git2. 프로젝트로 이동합니다:
$ cd docstore3. 올바른 브랜치를 체크아웃합니다:
$ git checkout elastic-search4. 빌드합니다:
$ mvn clean install5. 통합 테스트를 실행합니다:
$ mvn -DskipTests=false failsafe:integration-test이 마지막 명령어는 제공된 17개 통합 테스트를 실행하며, 모두 성공해야 합니다. 또한 Swagger UI 인터페이스를 테스트 목적으로 사용할 수 있으며, 선호하는 브라우저를 http://localhost:8080/q:swagger-ui에 열어 사용합니다. 그런 다음, 엔드포인트를 테스트하기 위해 docstore-api 프로젝트의 src/resources/data 디렉토리에 있는 JSON 파일에 있는 페이로드를 사용할 수 있습니다.
즐겁게 사용하세요!
Source:
https://dzone.com/articles/cruding-nosql-data-with-quarkus-part-two-elasticse