













로그는 종종 회사의 데이터 자산 대부분을 차지합니다. 로그의 예로는 사용자 활동 로그 등의 비즈니스 로그와 서버, 데이터베이스, 네트워크 또는 IoT 장치의 운영 및 유지보수 로그가 있습니다.
로그는 비즈니스의 수호천사입니다. 한편으로 시스템 위험 경고를 제공하고 문제 해결에서 엔지니어가 원인을 신속하게 파악하는 데 도움을 줍니다. 반면에 시간 범위를 확대하면 유용한 추세와 패턴을 식별할 수 있을 뿐만 아니라 비즈니스 로그는 사용자 인사이트의 기반이 됩니다.
그러나 로그는 다음과 같은 이유로 관리가 어려울 수 있습니다:
- 마구 들어옵니다. 모든 시스템 이벤트나 사용자 클릭이 로그를 생성합니다. 회사는 종종 하루에 수천억 개의 새 로그를 생성합니다.
- 그들은 큽니다. 로그는 보존되어야 합니다. 그들은 가치가 있을 때까지 유용하지 않을 수 있습니다. 따라서 회사는 최대 PB의 로그 데이터를 축적할 수 있으며 이 중 대부분은 거의 방문하지 않지만 거대한 저장 공간을 차지합니다.
- 빠르게 로드하고 찾아야 합니다. 문제 해결을 위해 대상 로그를 찾는 것은 마치 바늘 대모를 찾는 것과 같습니다. 사람들은 실시간 로그 작성과 로그 쿼리에 대한 실시간 응답을 갈망합니다.
이제 이상적인 로그 처리 시스템의 모습이 분명해졌습니다. 다음을 지원해야 합니다.
- 고처리량 실시간 데이터 수집: 대량의 로그를 씀과 동시에 즉시 볼 수 있어야 합니다.
- 저렴한 저장소: 상당한 양의 로그를 저장하면서 너무 많은 자원을 소비하지 않아야 합니다.
- 실시간 텍스트 검색: 빠른 텍스트 검색 기능이 필요합니다.
일반적인 솔루션: Elasticsearch 및 Grafana Loki
업계에서 두 가지 일반적인 로그 처리 솔루션이 있으며, 각각 Elasticsearch와 Grafana Loki로 예시됩니다.
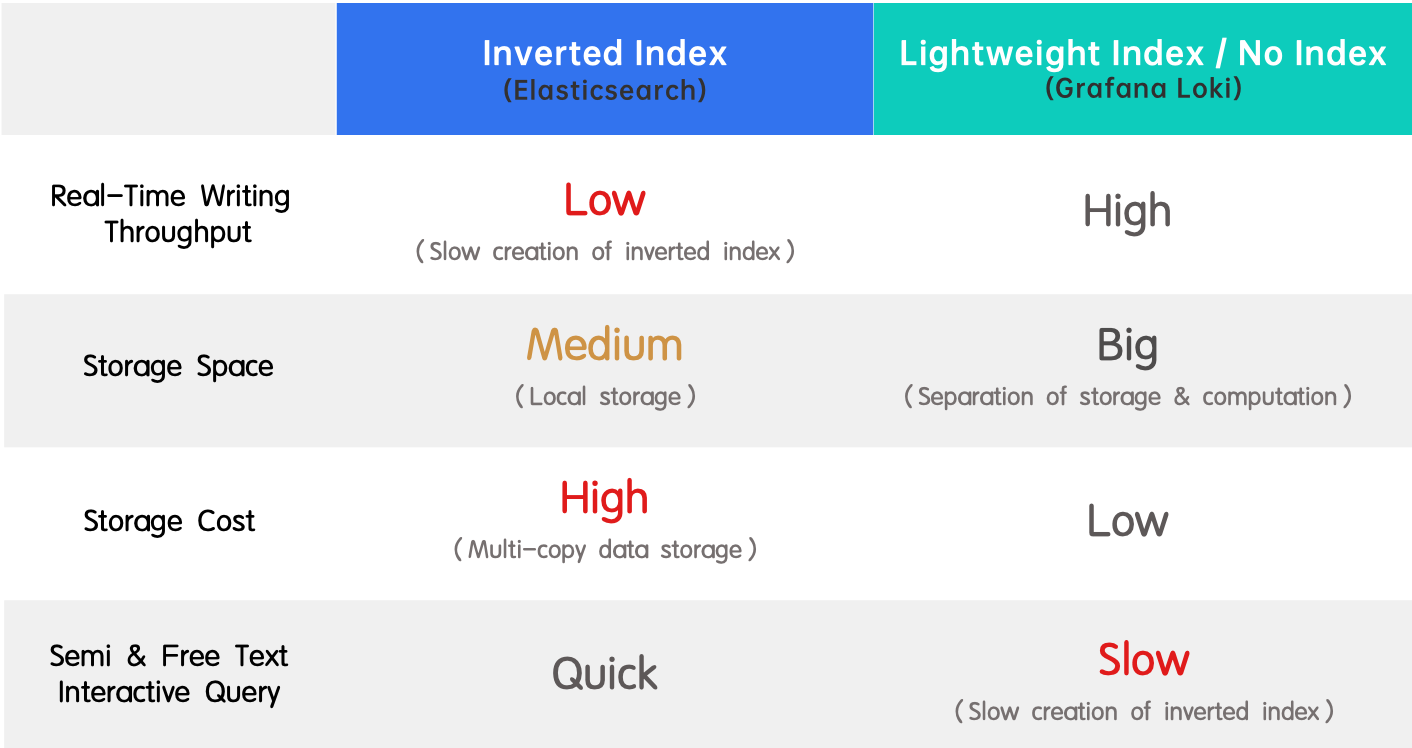
- 역색인 (Elasticsearch): 전체 텍스트 검색 및 높은 성능을 지원하기 때문에 널리 채택되었습니다. 단점은 실시간 쓰기 처리량이 낮고 색인 생성 시 많은 자원 소모입니다.
- 경량 인덱스 / 인덱스 없음 (Grafana Loki): 역색인과 반대되는 개념으로, 실시간 쓰기 처리량이 높고 저장 비용이 낮지만 쿼리 속도가 느립니다.
역색인 소개
A prominent strength of Elasticsearch in log processing is quick keyword search among a sea of logs. This is enabled by inverted indexes.
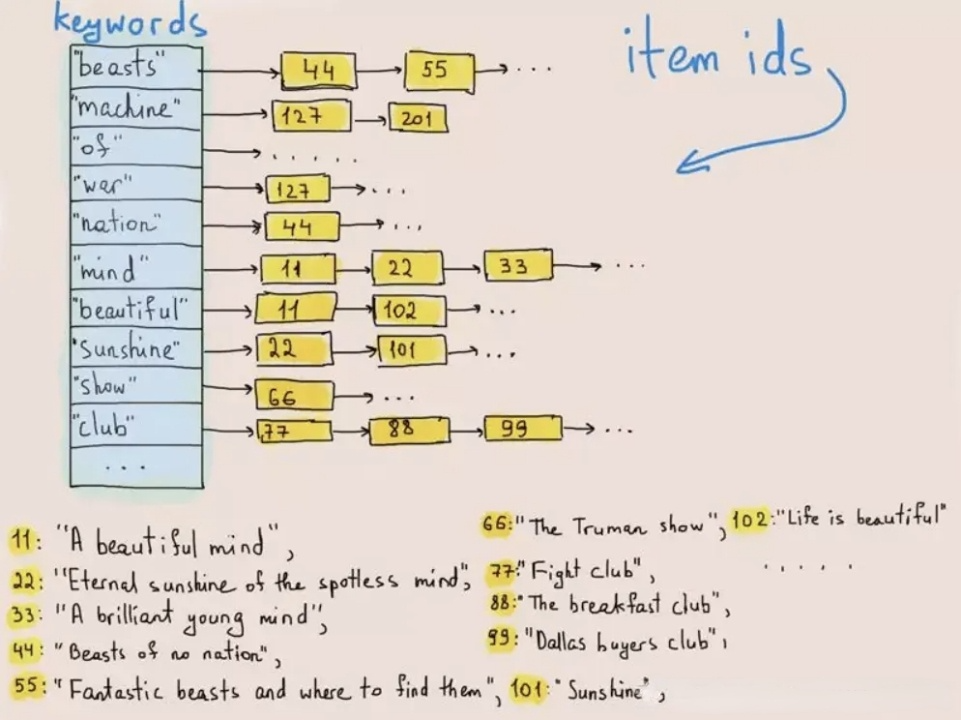
역색인은 원래 텍스트에서 단어나 구를 검색하는 데 사용되었습니다. 아래 그림은 그 작동 방식을 보여줍니다.
데이터 쓰기 시 시스템은 텍스트를 용어로 토큰화하고 이러한 용어를 게시 목록에 저장합니다. 이 게시 목록은 용어를 해당 용어가 존재하는 행의 ID에 매핑합니다. 텍스트 쿼리에서 데이터베이스는 게시 목록에서 키워드(용어)에 해당하는 행 ID를 찾고 행 ID를 기반으로 대상 행을 가져옵니다. 이렇게 하면 시스템이 전체 데이터 세트를 탐색할 필요가 없으므로 쿼리 속도를 수십 배 빠르게 향상시킬 수 있습니다.
엘라스틱서치의 역색인에서 빠른 검색은 쓰기 속도, 쓰기 처리량 및 저장 공간의 비용을 지불합니다. 왜냐하면 첫째, 토큰화, 사전 정렬 및 역색인 생성은 모두 CPU와 메모리 집약적인 작업입니다. 둘째, 엘라스틱서치는 원본 데이터, 역색인, 쿼리 가속을 위해 저장된 열 데이터의 추가 복사본을 저장해야 합니다. 이는 삼중 중복입니다.
그러나 역색인이 없는 경우, 예를 들어 Grafana Loki는 쿼리 속도가 느리다는 점에서 사용자 경험에 타격을 주어 로그 분석에서 엔지니어들에게 가장 큰 고통이 됩니다.
간단히 말해, 엘라스틱서치와 Grafana Loki는 높은 쓰기 처리량, 낮은 저장 비용 및 빠른 쿼리 성능 사이의 다양한 트레이드오프를 나타냅니다. 이 모두를 가질 수 있는 방법이 있다고 말씀드린다면요? 우리는 Apache Doris 2.0.0에서 역색인을 도입하고 추가로 최적화하여 엘라스틱서치보다 로그 쿼리 성능이 2배 빠르고 사용하는 저장 공간은 5분의 1입니다. 이 두 요소를 합하면 10배 더 나은 솔루션입니다.
Apache Doris의 역색인
일반적으로 색인을 구현하는 두 가지 방법은 외부 색인 시스템 또는 내장 색인입니다.
외부 색인 시스템: 데이터베이스에 외부 색인 시스템을 연결합니다. 데이터 수집 과정에서 데이터는 두 시스템 모두에 가져오게 됩니다. 색인 시스템이 색인을 생성한 후, 자체 내부의 원본 데이터를 삭제합니다. 데이터 사용자가 쿼리를 입력하면 색인 시스템은 관련 데이터의 ID를 제공하고, 그 후 데이터베이스는 해당 ID를 기반으로 대상 데이터를 조회합니다.
외부 색인 시스템을 구축하는 것은 데이터베이스에 덜 침투적이고 더 쉽지만, 몇 가지 성가신 단점이 있습니다:
- 두 시스템에 데이터를 기록해야 하므로 데이터 불일치와 저장 중복이 발생할 수 있습니다.
- 데이터베이스와 색인 시스템 간의 상호 작용은 오버헤드를 초래하므로 대상 데이터가 많을 경우 두 시스템을 건너뛰는 쿼리가 느려질 수 있습니다.
- 두 시스템을 유지 관리하는 것은 힘듭니다.
Apache Doris에서는 다른 방식을 선택합니다. 내장된 역색인은 만들기가 더 어렵지만, 일단 완성되면 더 빠르고, 사용자 친화적이며, 유지 관리가 문제없습니다.
Apache Doris에서 데이터는 다음과 같은 형식으로 정렬됩니다. 색인은 색인 영역에 저장됩니다:
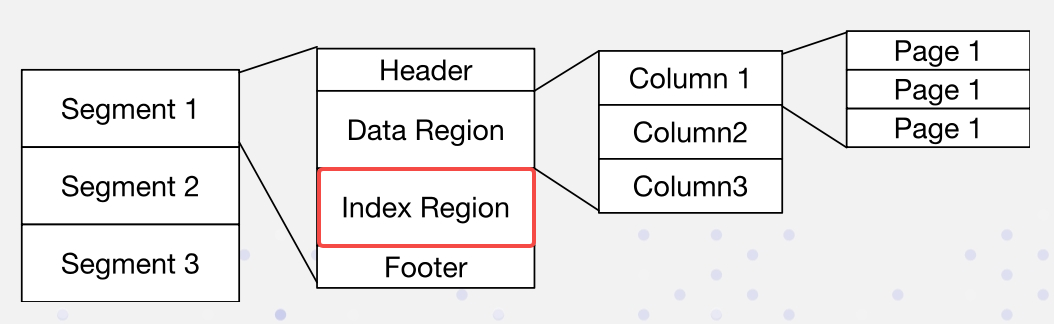
우리는 침투적이지 않은 방식으로 역색인을 구현합니다:
- 데이터 수집 및 압축: 세그먼트 파일이 Doris에 기록될 때마다 역색인 파일도 함께 기록됩니다. 색인 파일의 경로는 세그먼트 ID와 색인 ID에 의해 결정됩니다. 세그먼트의 행은 색인의 문서와 일치하며, RowID와 DocID도 마찬가지입니다.
- 질의: 만약
where절에 역색인이 있는 컬럼이 포함되어 있다면, 시스템은 색인 파일에서 검색하여 DocID 목록을 반환하고, 이 DocID 목록을 RowID Bitmap으로 변환합니다. Apache Doris의 RowID 필터링 메커니즘 하에서는 대상 행만 읽게 됩니다. 이것이 쿼리를 가속화하는 방식입니다.
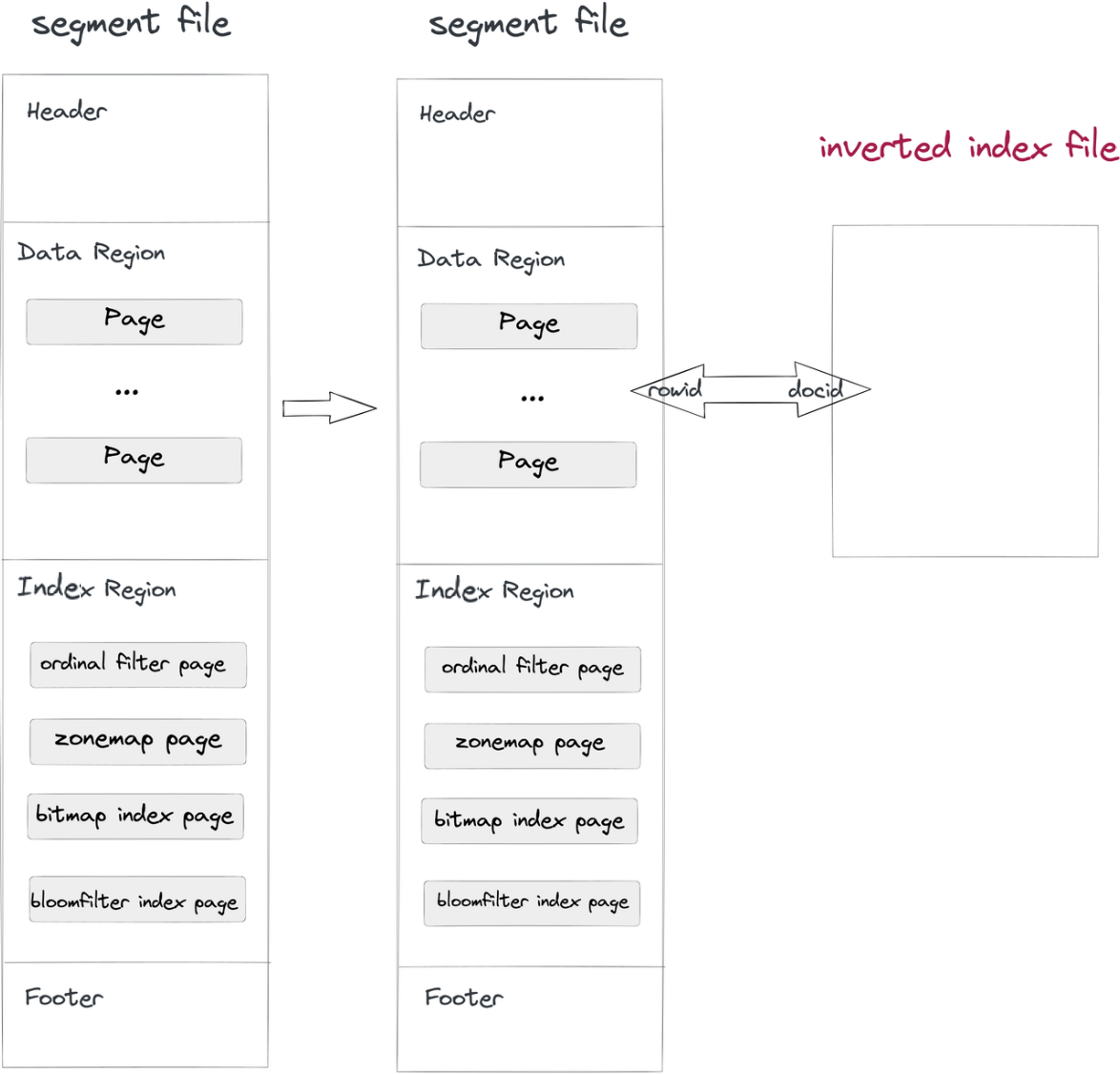
이러한 비침습적인 방법은 색인 파일을 데이터 파일로부터 분리하므로, 역색인에 대한 어떤 변경을 해도 데이터 파일 자체나 다른 색인에 영향을 주지 않게 됩니다.
역색인 최적화
일반적인 최적화
C++ Implementation and Vectorization
자바를 사용하는 Elasticsearch와 달리, Apache Doris는 저장 모듈, 쿼리 실행 엔진 및 역색인을 C++로 구현합니다. 자바에 비해 C++는 더 나은 성능을 제공하고, 벡터화가 더 쉽게 가능하며, JVM GC 오버헤드가 발생하지 않습니다. Apache Doris에서는 토큰화, 색인 생성, 쿼리와 같은 역색인의 모든 단계를 벡터화하였습니다. 참고로, 역색인에서 Apache Doris는 각 코어당 20MB/s의 속도로 데이터를 쓰는데, 이는 Elasticsearch의 4배(5MB/s)입니다.
열 저장 및 압축
Apache Lucene은 Elasticsearch에서 역색인의 기반을 제공합니다. Lucene 자체는 파일 저장을 지원하기 위해 구축되었으며, 데이터를 행 지향 형식으로 저장합니다.
Apache Doris에서는 다른 컬럼의 역색인이 서로 격리되어 있으며, 역색인 파일은 벡터화와 데이터 압축을 용이하게 하기 위해 열 저장 방식을 채택하고 있습니다.
Zstandard 압축을 활용하여 Apache Doris는 5:1에서 10:1 범위의 압축 비율을 달성하며, GZIP 압축보다 빠른 압축 속도와 50% 적은 공간 사용량을 실현합니다.
숫자/일시 컬럼용 BKD 트리
Apache Doris는 숫자 및 일시 컬럼에 BKD 트리를 구현합니다. 이는 범위 쿼리의 성능을 향상시키는 동시에 해당 컬럼을 고정 길이 문자열로 변환하는 것보다 더 공간 절약적인 방법입니다. 다른 이점으로는:
- 효율적인 범위 쿼리: 숫자 및 일시 컬럼에서 대상 데이터 범위를 신속하게 찾을 수 있습니다.
- 적은 저장 공간: 인접한 데이터 블록을 집계 및 압축하여 저장 비용을 감소시킵니다.
- 다차원 데이터 지원: BKD 트리는 GEO 포인트 및 범위와 같은 다차원 데이터 유형에 확장 가능하고 적응적입니다.
BKD 트리 외에도 숫자 및 일시 컬럼에 대한 쿼리를 추가로 최적화했습니다.
- 저카디널리티 시나리오 최적화: 저카디널리티 시나리오에 대한 압축 알고리즘을 세밀하게 조정하여 많은 역 목록을 디코딩 및 역직렬화하는 데 적은 CPU 자원을 소모합니다.
- 사전 가져오기: 높은 히트율 시나리오에서 사전 가져오기를 채택합니다. 히트율이 특정 임계치를 초과하면 Doris는 인덱싱 과정을 건너뛰고 데이터 필터링을 시작합니다.
OLAP에 맞게 조정된 최적화
일반적으로, 로그 분석은 고급 기능(예: Apache Lucene의 관련성 점수 매기기)이 필요하지 않은 단순한 쿼리 유형입니다. 로그 처리 도구의 핵심 기능은 빠른 쿼리와 낮은 저장 비용입니다. 따라서 Apache Doris에서는 OLAP 데이터베이스의 요구에 맞게 역방향 인덱스 구조를 간소화했습니다.
- 데이터 수집 시 여러 스레드가 동일한 인덱스에 데이터를 쓰는 것을 방지하여 잠금 경합으로 인한 오버헤드를 피합니다.
- 저장 공간을 확보하고 I/O 오버헤드를 줄이기 위해 정방향 인덱스 파일과 Norm 파일을 폐기합니다.
- 관련성 점수 및 순위 계산 논리를 단순화하여 오버헤드를 추가로 줄이고 성능을 향상시킵니다.
로그가 시간 범위로 분할되고 과거 로그가 덜 자주 방문되는 사실을 감안할 때 Apache Doris의 향후 버전에서 보다 세분화되고 유연한 인덱스 관리를 제공하기를 계획합니다.
- 지정된 데이터 파티션에 대한 역방향 인덱스 생성: 지난 7일 동안의 로그에 대한 인덱스 생성 등.
- 지정된 데이터 파티션에 대한 역방향 인덱스 삭제: 한 달 이상 된 로그에 대한 인덱스 삭제 등(인덱스 공간을 정리하기 위해).
벤치마킹
공개 데이터 세트에서 Elasticsearch 및 ClickHouse와 대조적으로 Apache Doris를 테스트했습니다.
공정한 비교를 위해 벤치마킹 도구, 데이터 세트 및 하드웨어를 포함한 테스트 조건의 통일성을 보장합니다.
Apache Doris vs. Elasticsearch
- 벤치마킹 도구: Elasticsearch의 공식 테스팅 도구인 ES Rally
- 데이터셋: 1998년 월드컵 HTTP 서버 로그 (ES Rally 내부에 포함된 데이터셋)
- 압축 전 데이터 크기: 32GB, 2억 4천7백만 행, 평균 134바이트/행
- 쿼리: 키워드 검색, 범위 쿼리, 집계, 순위 지정을 포함한 11개의 쿼리; 각 쿼리는 100회 연속 실행됩니다.
- 환경: 3개의 16코어 64GB 클라우드 가상 머신
Apache Doris의 결과:
- 쓰기 속도: 550MB/s, Elasticsearch의 4.2배
- 압축 비율: 10:1
- 저장 사용량: Elasticsearch의 20%
- 응답 시간: Elasticsearch의 43%

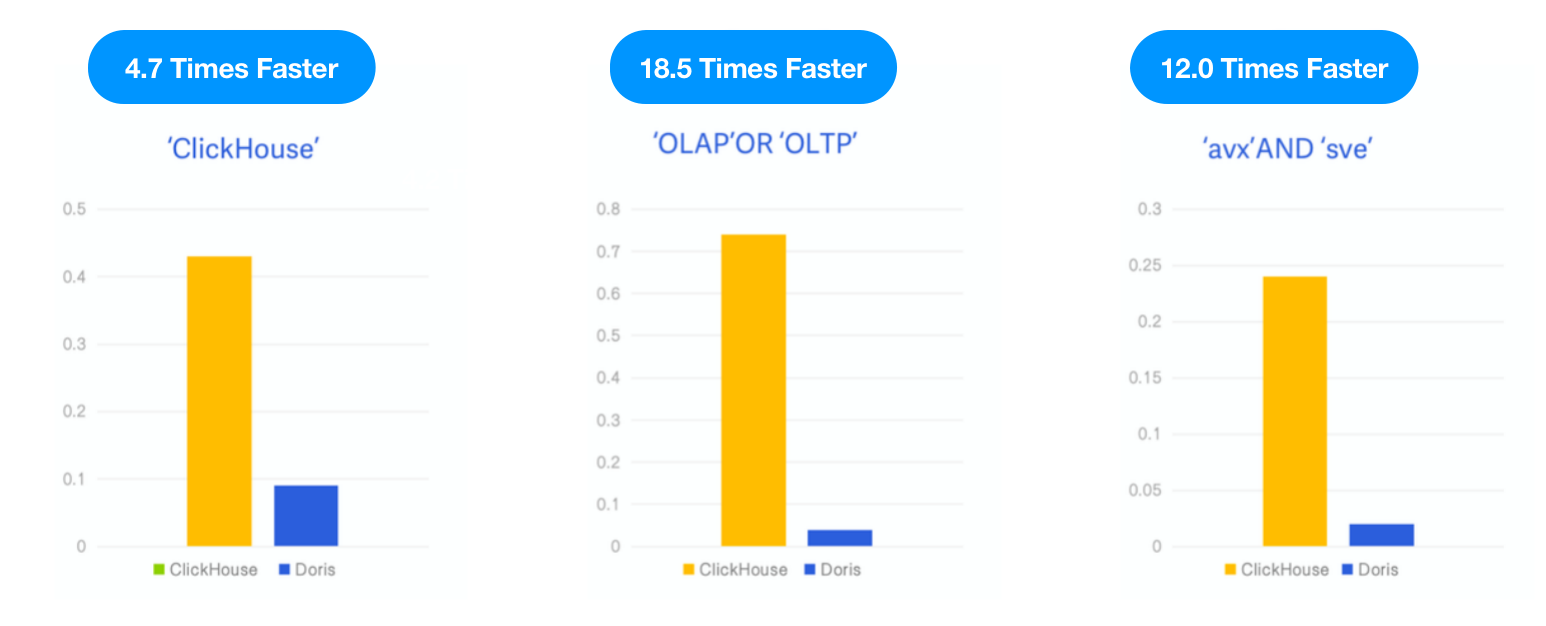
Apache Doris vs. ClickHouse
ClickHouse가 v23.1에서 역방향 인덱스를 실험적 기능으로 출시한 후, ClickHouse 블로그에 설명된 것과 동일한 데이터셋 및 SQL로 Apache Doris를 테스트하고 동일한 테스팅 리소스, 사례 및 도구 하에서 두 시스템의 성능을 비교했습니다.
- 데이터: 6.7GB, 2천8백73만 행, Hacker News 데이터셋, Parquet 형식
- 쿼리: 키워드 “ClickHouse,” “OLAP,” OR “OLTP,” 및 “avx” AND “sve”의 등장 횟수를 세는 3개의 키워드 검색
- 환경: 1개의 16코어 64GB 클라우드 가상 머신
결과: Apache Doris는 ClickHouse보다 각각 세 가지 쿼리에서 4.7배, 18.5배, 12배 빠른 성능을 보였습니다.
사용 및 예시
- 데이터셋: Hacker News의 백만 건의 댓글 기록
1단계: 테이블 생성 시 역색인을 데이터 테이블에 지정합니다.
매개변수:
- INDEX idx_comment (
comment): “comment” 열에 대해 “idx_comment”라는 이름의 인덱스를 생성합니다. - USING INVERTED: 테이블에 대한 역색인을 지정합니다.
- PROPERTIES(“parser” = “english”): 토큰화 언어를 영어로 지정합니다.
CREATE TABLE hackernews_1m
(
`id` BIGINT,
`deleted` TINYINT,
`type` String,
`author` String,
`timestamp` DateTimeV2,
`comment` String,
`dead` TINYINT,
`parent` BIGINT,
`poll` BIGINT,
`children` Array<BIGINT>,
`url` String,
`score` INT,
`title` String,
`parts` Array<INT>,
`descendants` INT,
INDEX idx_comment (`comment`) USING INVERTED PROPERTIES("parser" = "english") COMMENT 'inverted index for comment'
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 10
PROPERTIES ("replication_num" = "1");(참고: 기존 테이블에 인덱스를 추가할 수 있습니다 via ADD INDEX idx_comment ON hackernews_1m(comment) USING INVERTED PROPERTIES("parser" = "english"). 스마트 인덱스 및 보조 인덱스와 달리 역색인의 생성은 댓글 열의 읽기만 포함하므로 훨씬 빠르게 수행될 수 있습니다.)
2단계: MATCH_ALL을 사용하여 댓글 열에서 “OLAP” 및 “OLTP” 단어를 검색합니다. 여기서의 응답 시간은 like를 사용한 하드 매칭의 1/10입니다. (데이터 양이 증가할수록 성능 격차가 벌어집니다.)
mysql> SELECT count() FROM hackernews_1m WHERE comment LIKE '%OLAP%' AND comment LIKE '%OLTP%';
+---------+
| count() |
+---------+
| 15 |
+---------+
1 row in set (0.13 sec)
mysql> SELECT count() FROM hackernews_1m WHERE comment MATCH_ALL 'OLAP OLTP';
+---------+
| count() |
+---------+
| 15 |
+---------+
1 row in set (0.01 sec)
자세한 기능 소개 및 사용 가이드는 문서 참조: 역색인
마무리
한마디로, Apache Doris가 Elasticsearch보다 10배 높은 비용효과를 달성하는 데 기여하는 것은 역방향 인덱싱을 위한 OLAP 맞춤 최적화이며, 이는 Apache Doris의 열 저장 엔진, 대규모 병렬 처리 프레임워크, 벡터화 쿼리 엔진 및 비용 기반 최적화 기술에 의해 지원됩니다.
우리 자신의 역방향 인덱싱 솔루션에 대해 자부심을 가지고 있지만, 자가 발행 벤치마크가 논란의 여지가 있음을 이해하므로 모든 제3자 테스터로부터 피드백을 공개적으로 받고 실제 사례에서 Apache Doris가 어떻게 작동하는지 보고 싶습니다.
Source:
https://dzone.com/articles/building-a-log-analytics-solution-10-times-more-co