













이것은 부동산 거물의 디지털 전환의 일부입니다. 기밀성을 위해 어떤 비즈니스 데이터도 공개하지 않겠지만, 우리의 데이터 웨어하우스와 최적화 전략에 대한 상세한 뷰를 얻게 될 것입니다.
이제 시작하겠습니다.
아키텍처
논리적으로 우리의 데이터 아키텍처는 네 부분으로 나눌 수 있습니다.
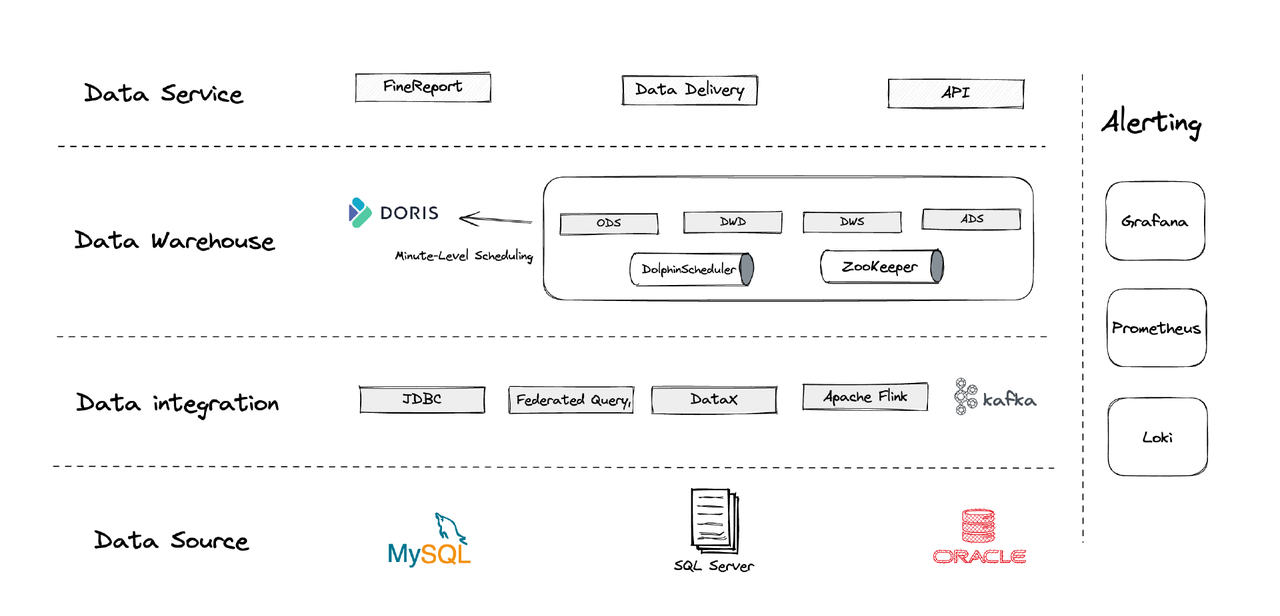
- 데이터 통합: 이는 Flink CDC, DataX 및 Apache Doris의 Multi-Catalog 기능으로 지원됩니다.
- 데이터 관리: 스크립트 수명 주기 관리, 다중 테넌시 관리의 권한 및 데이터 품질 모니터링을 위해 Apache Dolphinscheduler를 사용합니다.
- 알림: Grafana, Prometheus 및 Loki를 사용하여 구성 요소 리소스 및 로그를 모니터링합니다.
- 데이터 서비스: 이곳에서 BI 도구가 사용자 상호 작용을 위해 참여하여 데이터 쿼리 및 분석을 수행합니다.
1. 테이블
우리는 비즈니스의 각 운영 엔티티를 중심으로 차원 테이블과 사실 테이블을 생성합니다. 이에 따른 고객, 집 등이 포함됩니다. 동일한 운영 엔티티와 관련된 일련의 활동이 있는 경우 하나의 필드에 의해 기록되어야 합니다. (이는 이전 혼란스러운 데이터 관리 시스템에서 얻은 교훈입니다.)
2. 레이어
우리의 데이터 웨어하우스는 다섯 개의 개념적 레이어로 나누어져 있습니다. 이 레이어들 사이의 DAG 스크립트를 스케줄링하기 위해 Apache Doris와 Apache DolphinScheduler를 사용합니다.

매일, 레이어들은 역사적 상태 필드의 변경이나 ODS 테이블의 불완전한 데이터 동기화가 있을 경우 증분 업데이트 외에도 전반적인 업데이트를 거칩니다.
3. 증분 업데이트 전략
(1) 시간 간격을 방지하기 위해 스크립트의 스케줄링 시간 간격으로 인한 데이터 이탈을 방지하기 위해 where >= "activity time -1 day or -1 hour" 대신 where >= "activity time
예를 들어, 실행 간격을 10분으로 설정했다면, 스크립트가 23:58:00에 실행되고 새 데이터가 23:59:00에 도착한다고 가정합니다. where >= "activity time를 설정하면 그날의 데이터 중 일부가 누락됩니다.
(2) 매번 스크립트 실행 전에 테이블의 가장 큰 기본 키 ID를 가져와 보조 테이블에 저장하고, where >= "ID in auxiliary table"
이는 데이터 중복을 방지하기 위한 것입니다. Apache Doris의 Unique Key 모델을 사용하고 기본 키 세트를 지정하면 원본 테이블의 기본 키에 변경이 있을 경우 변경 사항이 기록되고 관련 데이터가 로드될 수 있습니다. 이 방법은 원본 테이블에 자동 증가 기본 키가 있는 경우에만 적용할 수 있습니다.
(3) 테이블 파티셔닝
시간 기반 자동 증가 데이터(로그 테이블 등)의 경우, 과거 데이터와 상태의 변경이 적을 수 있지만 데이터 양이 많아 전체 업데이트 및 스냅샷 생성에 대한 연산 압력이 클 수 있습니다. 따라서 이러한 테이블을 파티셔닝하여 증분 업데이트마다 하나의 파티션만 교체하는 것이 좋습니다. (데이터 이탈에 대해서도 주의해야 합니다.)
4. 전체 업데이트 전략
(1) 테이블 잘라내기
테이블을 비운 다음 원본 테이블에서 모든 데이터를 가져옵니다. 이는 작은 테이블 및 새벽에 사용자 활동이 없는 시나리오에 적합합니다.
(2) ALTER TABLE tbl1 REPLACE WITH TABLE tbl2
이는 원자적 작업이며 큰 테이블에 권장됩니다. 스크립트를 실행하기 전에 매번 동일한 스키마를 가진 임시 테이블을 생성하고 모든 데이터를 로드한 다음 원래 테이블을 교체합니다.
응용 프로그램
- ETL 작업: 매분
- 초기 배포 설정: 8개 노드, 2개 프런트엔드, 8개 백엔드, 하이브리드 배포
- 노드 구성: 32C * 60GB * 2TB SSD
이는 레거시 데이터 TB와 증분 데이터 GB에 대한 구성입니다. 참고용으로 사용하여 이 기반으로 클러스터를 확장할 수 있습니다. Apache Doris의 배포는 간단합니다. 다른 구성 요소가 필요하지 않습니다.
1. 오프라인 데이터와 로그 데이터를 통합하기 위해 우리는 CSV 형식을 지원하고 많은 관계형 데이터베이스의 리더를 가지고 있는 DataX를 사용하며, Apache Doris는 DataX-Doris-Writer를 제공합니다.

2. 우리는 소스 테이블에서 데이터를 동기화하기 위해 Flink CDC를 사용합니다. 그런 다음 Apache Doris의 Materialized View 또는 Aggregate Model을 활용하여 실시간 메트릭을 집계합니다. 우리는 실시간으로 일부 메트릭만 처리해야 하고 너무 많은 데이터베이스 연결을 생성하고 싶지 않기 때문에 하나의 Flink 작업으로 여러 CDC 소스 테이블을 유지합니다. 이것은 Dinky의 다중 소스 병합 및 전체 데이터베이스 동기화 기능에 의해 실현되거나 Flink DataStream 다중 소스 병합 작업을 직접 구현할 수 있습니다. Flink CDC와 Apache Doris는 스키마 변경을 지원한다는 점에 주목해야 합니다.
EXECUTE CDCSOURCE demo_doris WITH (
'connector' = 'mysql-cdc',
'hostname' = '127.0.0.1',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'checkpoint' = '10000',
'scan.startup.mode' = 'initial',
'parallelism' = '1',
'table-name' = 'ods.ods_*,ods.ods_*',
'sink.connector' = 'doris',
'sink.fenodes' = '127.0.0.1:8030',
'sink.username' = 'root',
'sink.password' = '123456',
'sink.doris.batch.size' = '1000',
'sink.sink.max-retries' = '1',
'sink.sink.batch.interval' = '60000',
'sink.sink.db' = 'test',
'sink.sink.properties.format' ='json',
'sink.sink.properties.read_json_by_line' ='true',
'sink.table.identifier' = '${schemaName}.${tableName}',
'sink.sink.label-prefix' = '${schemaName}_${tableName}_1'
);3. SQL 스크립트 또는 “Shell + SQL” 스크립트를 사용하고 스크립트 라이프사이클 관리를 수행합니다. ODS 레이어에서는 각 소스 테이블의 데이터 수집을 위해 일반 DataX 작업 파일을 작성하고 매개변수를 전달하여 각 소스 테이블에 대한 DataX 작업을 작성하는 대신에 일반 DataX 작업 파일을 작성합니다. 이렇게 함으로써 유지보수가 훨씬 쉬워집니다. 우리는 DolphinScheduler에서 Apache Doris의 ETL 스크립트를 관리하고 여기서 버전 관리도 수행합니다. 생산 환경에서 오류가 발생할 경우 언제든지 롤백할 수 있습니다.
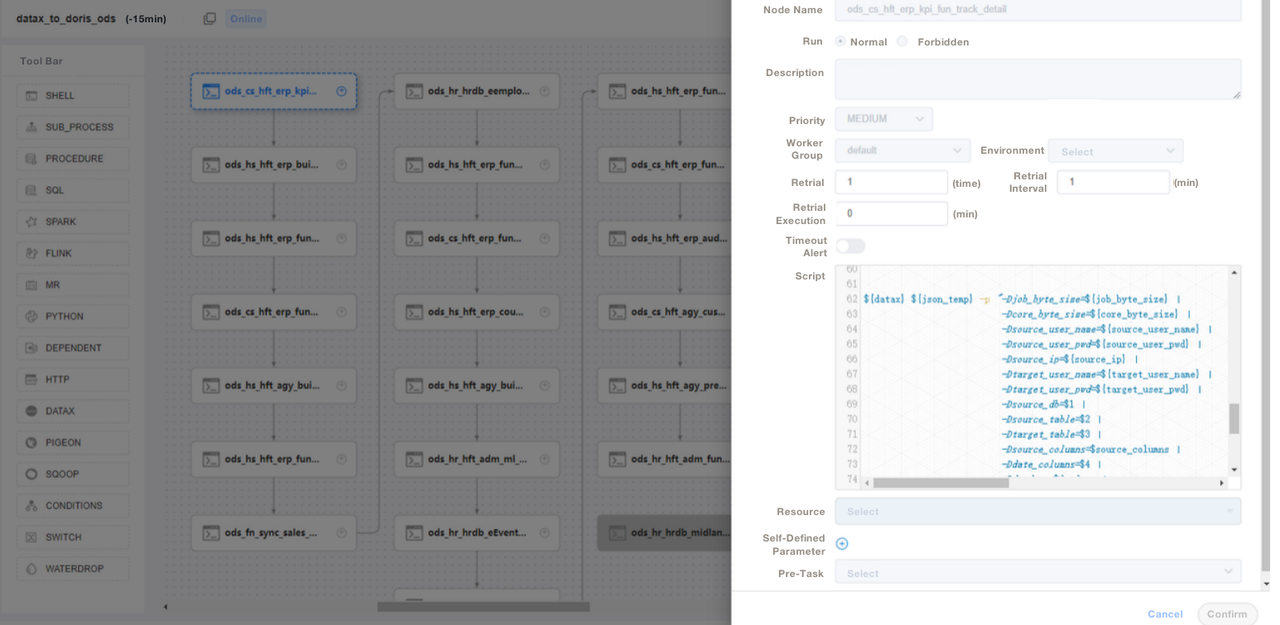
4. ETL 스크립트로 데이터를 수집한 후, 보고 도구에서 페이지를 생성합니다. 우리는 SQL을 사용하여 서로 다른 계정에 서로 다른 권한을 할당하며, 이는 행, 필드 및 전역 사전 수정 권한을 포함합니다. Apache Doris는 MySQL의 권한 제어와 마찬가지로 계정에 대한 권한 제어를 지원합니다. MySQL.
우리는 재해 복구를 위해 Apache Doris 데이터 백업을 사용하며, Apache Doris 감사 로그를 통해 SQL 실행 효율성을 모니터링하고, Grafana+Loki를 사용하여 클러스터 메트릭 경고를 받으며, Supervisor를 통해 노드 구성 요소의 데몬 프로세스를 모니터링합니다.
최적화
데이터 수집
우리는 DataX를 사용하여 오프라인 데이터를 스트림 로드합니다. 이를 통해 각 배치의 크기를 조정할 수 있습니다. 스트림 로드 방식은 결과를 동기적으로 반환하므로 우리 아키텍처의 요구 사항을 충족시킵니다. DolphinScheduler를 사용하여 비동기 데이터 가져오기를 실행하는 경우 시스템은 스크립트가 실행되었다고 간주할 수 있으며, 이로 인해 혼란이 발생할 수 있습니다. 다른 방법을 사용하는 경우 쉘 스크립트에서 show load를 실행하고 정규식 필터링 상태를 확인하여 수집이 성공했는지 확인하는 것이 좋습니다.
데이터 모델
대부분의 테이블에 대해 Apache Doris의 Unique Key 모델을 채택합니다. Unique Key 모델은 데이터 스크립트의 멱등성을 보장하고 상류 데이터 중복을 효과적으로 방지합니다.
외부 데이터 읽기
Apache Doris의 Multi-Catalog 기능을 사용하여 외부 데이터 소스에 연결합니다. 이를 통해 카탈로그 수준에서 외부 데이터의 매핑을 생성할 수 있습니다.
쿼리 최적화
가장 자주 사용되는 비문자형 필드(예: int 및 where 절)를 처음 36바이트 내에 배치하는 것이 좋습니다. 이렇게 하면 포인트 쿼리에서 이러한 필드를 밀리초 내에 필터링할 수 있습니다.
데이터 사전
우리에게 데이터 사전을 만드는 것이 중요한 이유는 이것이 인력 커뮤니케이션 비용을 크게 줄여주기 때문입니다. 팀이 커질수록 이러한 문제가 골치아픈 일이 될 수 있습니다. 우리는 Apache Doris에서 information_schema를 사용하여 데이터 사전을 생성합니다. 이를 통해 테이블과 필드의 전체적인 관점을 빠르게 파악하고 개발 효율성을 높일 수 있습니다.
성능
오프라인 데이터 수집 시간: 몇 분 이내
쿼리 대기 시간: 1억 건 이상의 행을 포함하는 테이블에 대해 Apache Doris는 1초 이내에 임시 쿼리에 응답하고 복잡한 쿼리는 5초 이내에 처리합니다.
자원 소모: 이 데이터 웨어하우스를 구축하기 위해 소수의 서버만 사용합니다. Apache Doris의 70% 압축 비율은 우리에게 많은 저장 자원을 절약해줍니다.
경험 및 결론
사실, 현재의 데이터 아키텍처로 진화하기 전에 Hive, Spark, Hadoop을 사용하여 오프라인 데이터 웨어하우스를 구축하려고 시도했습니다. 그 결과, Hadoop은 우리 같은 전통적인 기업에게는 데이터 처리가 너무 많아 과하다는 것이 밝혀졌습니다. 가장 적합한 구성 요소를 찾는 것이 중요합니다.
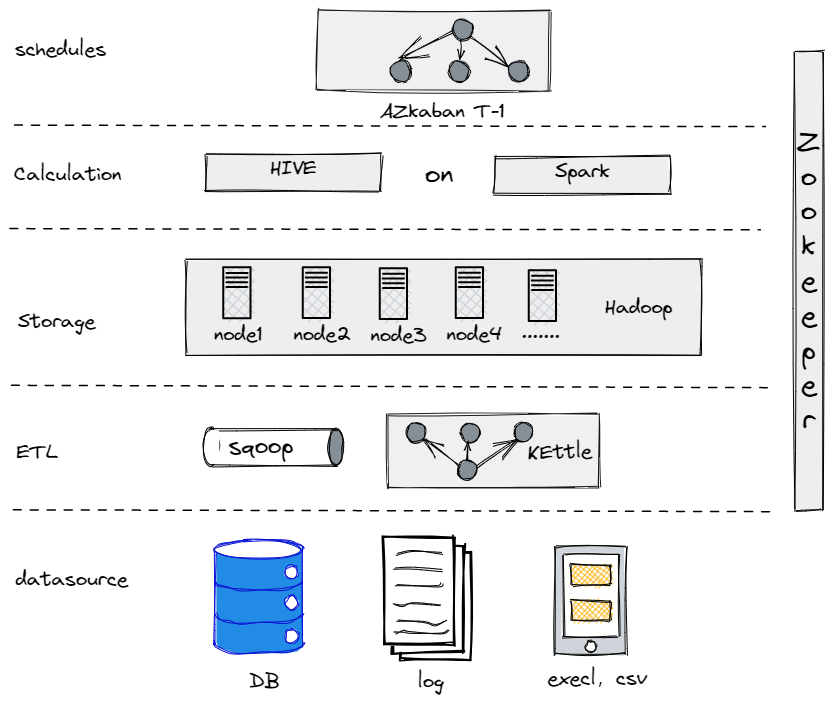
우리의 구 오프라인 데이터 웨어하우스
다른 한편으로, 빅데이터 전환을 원활하게 하기 위해 데이터 플랫폼을 사용 및 유지보수 측면에서 가능한 한 간단하게 만들어야 합니다. 그래서 Apache Doris를 선택한 이유입니다. MySQL 프로토콜과 호환되며 다양한 함수 집합을 제공하기 때문에 고유한 UDF를 개발할 필요가 없습니다. 또한, 프런트엔드와 백엔드의 두 가지 유형의 프로세스로만 구성되어 있어 확장 및 추적이 용이합니다.
Source:
https://dzone.com/articles/building-a-data-warehouse-for-traditional-industry