













Agentic AI의 부상은 작업을 자율적으로 수행하고 권장 사항을 제공하며 AI를 전통적인 컴퓨팅과 혼합한 복잡한 워크플로를 실행하는 에이전트 주변에 흥미를 불러일으켰습니다. 그러나 실제 제품 중심 환경에서 이러한 에이전트를 만드는 것은 AI 자체를 넘어서는 문제에 직면하게 됩니다.
주의 깊은 아키텍처 없이 구성 요소 간의 의존성은 병목 현상을 일으키고 확장 가능성을 제한하며 시스템이 발전함에 따라 유지 관리를 복잡하게 만들 수 있습니다. 해결책은 워크플로를 분리하는 데 있으며, 여기에는 에이전트, 인프라 및 다른 구성 요소가 강하게 의존성을 두지 않고 유연하게 상호 작용하는 것이 포함됩니다.
이러한 유형의 유연하고 확장 가능한 통합은 데이터 교환을 위한 공유 “언어”가 필요하며, 이는 이벤트 스트림을 통해 구동되는 견고한 이벤트 주도 아키텍처(EDA)를 필요로 합니다. 이벤트를 중심으로 응용 프로그램을 구성함으로써, 에이전트는 각 부분이 독립적으로 작동하는 반응성이 뛰어난 분리된 시스템에서 작동할 수 있습니다. 팀은 기술 선택을 자유롭게 할 수 있고, 확장 필요를 별도로 관리하며, 구성 요소 간에 명확한 경계를 유지함으로써 진정한 민첩성을 허용할 수 있습니다.
이러한 원칙을 테스트하기 위해, 나는 Software Engineering Daily 및 Software Huddle에서 팟캐스트 인터뷰를 준비하는 데 도움을 주는 AI 기반 연구 보조 도구인 PodPrep AI를 개발했습니다. 이 게시물에서는 PodPrep AI의 설계 및 아키텍처에 대해 자세히 살펴보며, EDA와 실시간 데이터 스트림이 효과적인 에이전트 시스템을 지원하는 방법을 보여줄 것입니다.
참고: 코드만 보고 싶다면 내 GitHub 저장소로 이동하십시오 여기로
AI를 위한 이벤트 주도 아키텍처는 왜 필요한가?
실제 AI 애플리케이션에서 긴밀하게 결합된 단일 설계는 효과적이지 않습니다. 개념 증명이나 데모는 간단함을 위해 단일 통합 시스템을 사용하는 경우가 많지만, 이러한 접근 방식은 특히 분산 환경에서 프로덕션에서는 빠르게 비현실적이 됩니다. 긴밀하게 결합된 시스템은 병목 현상을 발생시키고, 확장성을 제한하며, 반복 속도를 늦추어 AI 솔루션이 성장함에 따라 피해야 할 모든 중요한 도전 과제가 됩니다.
전형적인 AI 에이전트를 고려해 보십시오.
여러 출처에서 데이터를 가져오고, 프롬프트 엔지니어링 및 RAG 워크플로를 처리하며, 결정론적 워크플로를 실행하기 위해 다양한 도구와 직접 상호작용해야 할 필요가 있을 수 있습니다. 필요한 오케스트레이션은 복잡하며 여러 시스템에 대한 의존성이 있습니다. 그리고 에이전트가 다른 에이전트와 통신해야 하는 경우, 복잡성은 더욱 증가합니다. 유연한 아키텍처가 없다면 이러한 의존성은 확장 및 수정이 거의 불가능하게 만듭니다.

프로덕션에서는 서로 다른 팀이 일반적으로 스택의 서로 다른 부분을 처리합니다: MLOps 및 데이터 엔지니어링은 RAG 파이프라인을 관리하고, 데이터 과학자는 모델을 선택하며, 애플리케이션 개발자는 인터페이스와 백엔드를 구축합니다. 긴밀하게 결합된 설정은 이러한 팀을 의존성에 묶어 배포 속도를 늦추고 확장을 어렵게 만듭니다. 이상적으로, 애플리케이션 계층은 AI의 내부 구조를 이해할 필요가 없어야 하며, 필요한 경우 결과를 단순히 소비해야 합니다.
또한, AI 응용 프로그램은 독립적으로 작동할 수 없습니다. 진정한 가치를 위해, AI 통찰력은 고객 데이터 플랫폼(CDP), CRM, 분석 등에서 원활하게 흐를 필요가 있습니다. 고객 상호작용은 실시간으로 업데이트를 촉발해야 하며, 이는 다른 도구로 직접 피드되어 행동과 분석에 사용됩니다. 통합된 접근 방식이 없으면 플랫폼 간 통찰력을 통합하는 것은 관리하기 어려운 조각 모음이 되어 확장할 수 없게 됩니다.
EDA 기반 AI는 데이터를 위한 “중추 신경계”를 생성하여 이러한 문제를 해결합니다. EDA를 사용하면 응용 프로그램이 연결된 명령에 의존하는 대신 이벤트를 방송합니다. 이는 구성 요소를 분리하여 데이터가 필요한 곳에서 비동기적으로 흐를 수 있게 하여 각 팀이 독립적으로 작업할 수 있도록 합니다. EDA는 원활한 데이터 통합, 확장 가능한 성장 및 회복력을 촉진하여 현대 AI 기반 시스템을 위한 강력한 기반이 됩니다.
확장 가능한 AI 기반 연구 에이전트 설계하기
지난 2년 동안, 저는 Software Engineering Daily, Software Huddle, Partially Redacted의 여러 팟캐스트를 수백 개 진행했습니다.
각 팟캐스트를 준비하기 위해, 저는 팟캐스트 브리프를 준비하기 위해 심층적인 연구 과정을 수행하여 제 생각, 게스트 및 주제에 대한 배경, 그리고 일련의 잠재적인 질문을 포함합니다. 이 브리프를 작성하기 위해, 저는 일반적으로 게스트와 그들이 일하는 회사에 대해 조사하고, 그들이 출연했을 수 있는 다른 팟캐스트를 듣고, 그들이 작성한 블로그 게시물을 읽고, 우리가 논의할 주요 주제에 대해 공부합니다.
나는 다른 팟캐스트에 연결을 얽어 토픽이나 유사한 주제와 관련된 내 경험을 제공하려고 노력합니다. 이 모든 과정에는 상당한 시간과 노력이 필요합니다. 대규모 팟캐스트 운영은 주최자를 위해 이 작업을 수행하는 전문 연구원과 보조 인력을 보유하고 있습니다. 하지만 저는 그런 종류의 운영을 하고 있지 않습니다. 이 모든 일을 내가 스스로 해야 합니다.
이 문제에 대처하기 위해 나는 나를 대신할 수 있는 에이전트를 구축하고 싶었습니다. 에이전트는 대략 아래 이미지와 같이 보일 것입니다.

나는 게스트 이름, 회사, 집중하고자 하는 토픽, 블로그 게시물 및 기존 팟캐스트와 같은 참조 URL과 같은 기본 소스 자료를 제공하고, 그런 다음 일부 AI 마법이 발생하여 나의 연구가 완료될 것입니다.
이 간단한 아이디어가 나를 이끌어 PodPrep AI를 만들게 되었고, 이것은 나에게 토큰만 비용이 드는 AI 기반 연구 보조 도구입니다.
본 문서의 나머지 부분은 PodPrep AI의 디자인에 대해 논의하며, 먼저 사용자 인터페이스에서 시작합니다.
에이전트 사용자 인터페이스 구축
나는 연구 과정에 소스 자료를 쉽게 입력할 수 있는 웹 애플리케이션으로 에이전트의 인터페이스를 설계했습니다. 이는 게스트의 이름, 회사, 인터뷰 주제, 추가 컨텍스트, 관련 블로그, 웹사이트 및 이전 팟캐스트 인터뷰에 대한 링크를 포함합니다.
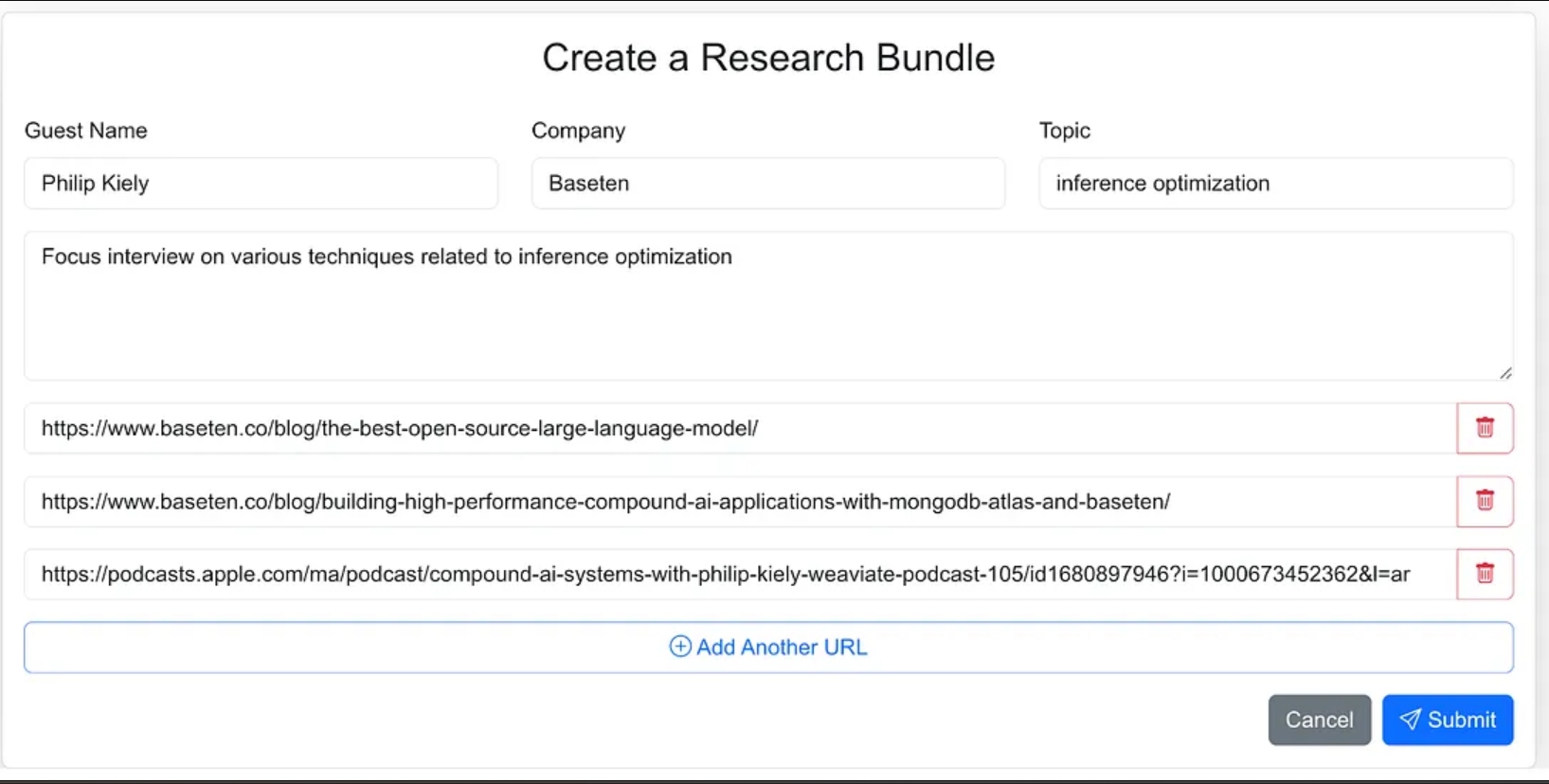
에이전트에 더 적은 방향을 주고, 에이전트 워크플로의 일부로 소스 자료를 찾도록 할 수도 있었지만, 1.0 버전에서는 소스 URL을 제공하기로 결정했습니다.
웹 어플리케이션은 Next.js와 MongoDB를 사용하여 구축된 표준 3계층 앱입니다. 이 어플리케이션은 AI에 대해 아무것도 모릅니다. 사용자가 새로운 연구 번들을 입력할 수 있게 하며, 이들은 처리 중인 상태로 나타납니다. 이후 에이전틱 프로세스가 워크플로를 완료하고 어플리케이션 데이터베이스에 연구 개요를 작성할 때까지 계속해서 나타납니다.
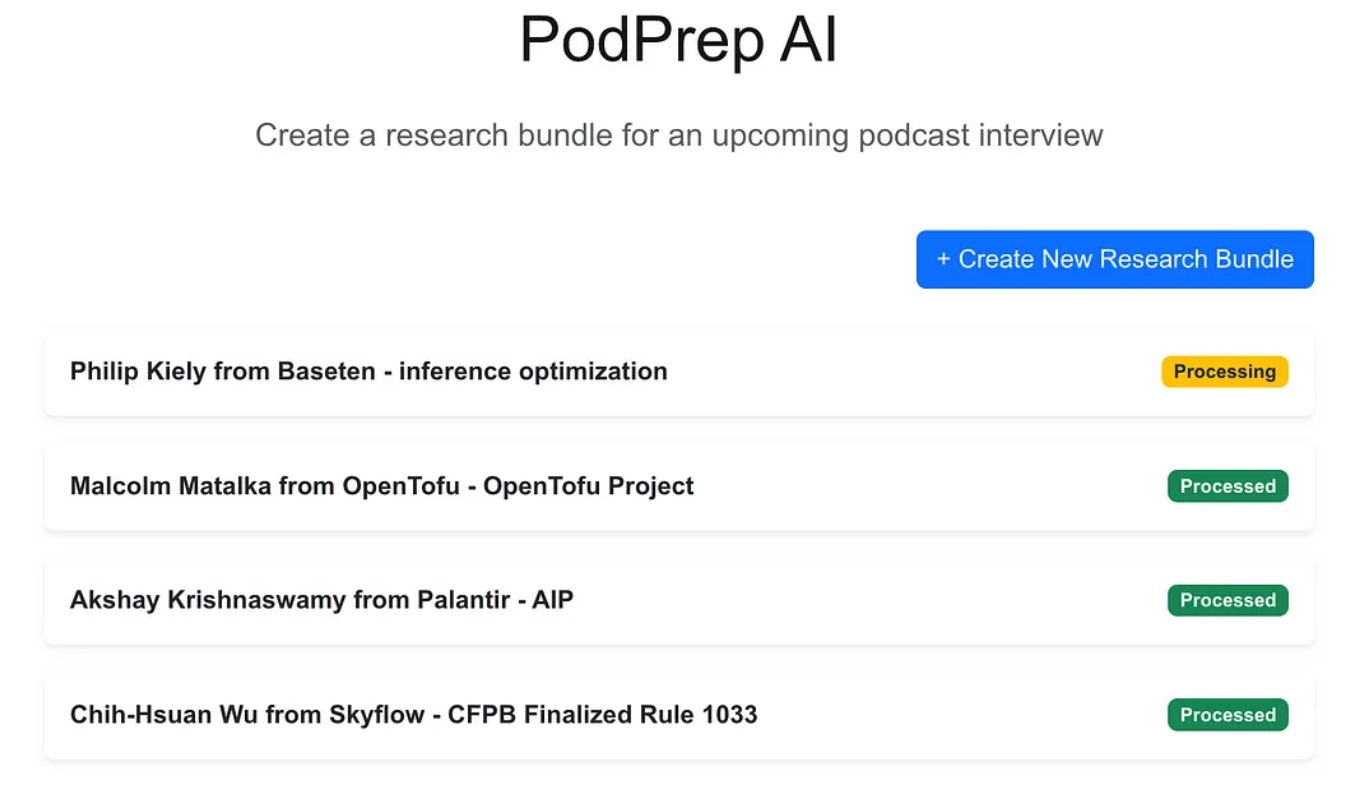
AI 매직이 완료되면 아래와 같이 항목에 대한 간단한 설명 문서에 액세스할 수 있습니다.

에이전틱 워크플로 만들기
버전 1.0에서 연구 개요를 작성하기 위해 세 가지 주요 작업을 수행하고 싶었습니다:
- 모든 웹사이트 URL, 블로그 글 또는 팟캐스트에서 텍스트 또는 요약문을 가져와서 텍스트를 합리적인 크기로 분할하고 임베딩을 생성하고 벡터 표현을 저장합니다.
- 연구 원본 URL에서 추출된 모든 텍스트에서 가장 흥미로운 질문을 추출하여 저장합니다.
- 임베딩을 기반으로 가장 관련성 높은 컨텍스트, 이전에 제기된 최상의 질문 및 번들 입력의 일부인 다른 정보를 결합한 팟캐스트 연구 개요를 생성합니다.
아래 이미지는 웹 어플리케이션에서 에이전틱 워크플로까지의 아키텍처를 보여줍니다.
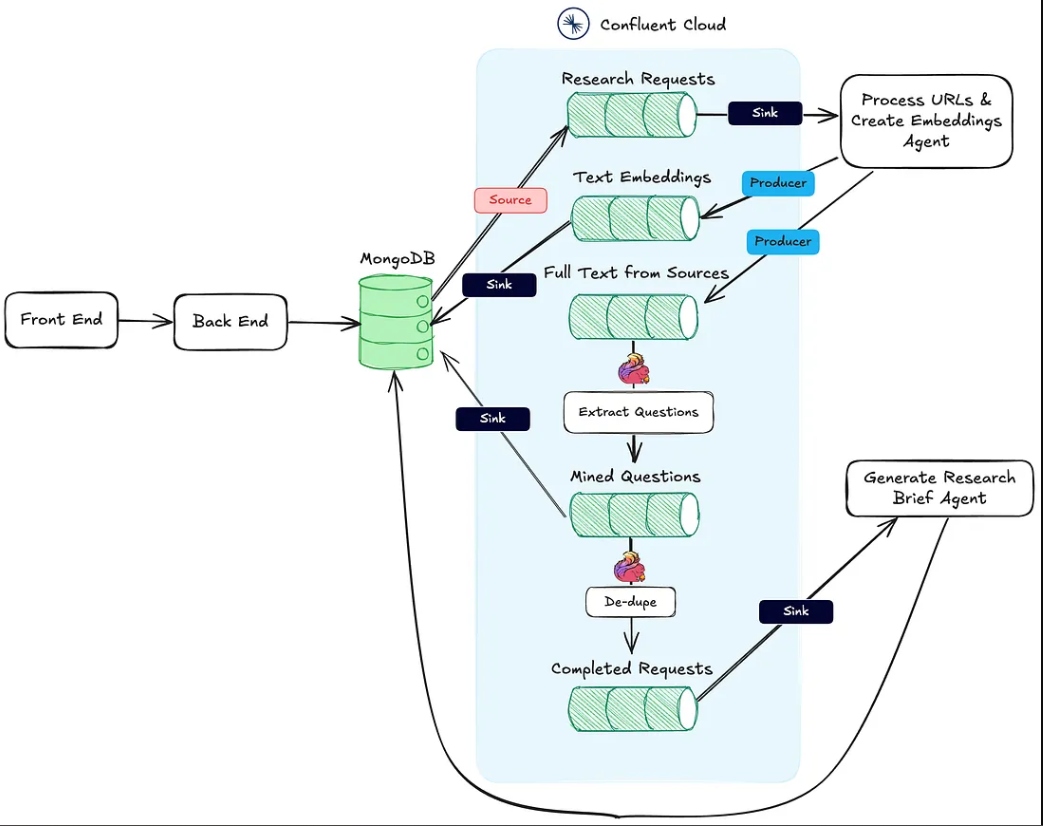
위의 작업 #1은 Process URLs & Create Embeddings Agent HTTP sink 엔드포인트에서 지원됩니다.
작업 #2는 Flink와 Confluent Cloud의 내장 AI 모델 지원을 사용하여 수행됩니다.
마지막으로, 액션 #3은 연구 요약 생성 에이전트에 의해 실행되며, 이는 HTTP 싱크 엔드포인트로, 첫 번째 두 액션이 완료되면 호출됩니다.
다음 섹션에서는 이러한 각 액션에 대해 자세히 설명합니다.
프로세스 URL 및 임베딩 생성 에이전트
이 에이전트는 연구 소스 URL과 벡터 임베딩 파이프라인에서 텍스트를 가져오는 역할을 합니다. 아래는 연구 자료를 처리하기 위해 배후에서 발생하는 고수준의 흐름입니다.

사용자가 연구 번들을 생성하고 MongoDB에 저장하면, MongoDB 소스 커넥터가 research-requests라는 Kafka 주제로 메시지를 생성합니다. 이것이 에이전틱 워크플로우를 시작하는 것입니다.
HTTP 엔드포인트에 대한 각 POST 요청에는 연구 요청의 URL과 MongoDB 연구 번들 컬렉션의 기본 키가 포함됩니다.
에이전트는 각 URL을 반복하고, 만약 Apple 팟캐스트가 아니라면 전체 페이지 HTML을 가져옵니다. 페이지의 구조를 모르기 때문에, 관련 텍스트를 찾기 위해 HTML 파싱 라이브러리에 의존할 수 없습니다. 대신, 아래의 프롬프트를 사용하여 온도 0으로 gpt-4o-mini 모델에 페이지 텍스트를 전송하여 필요한 정보를 얻습니다.
`Here is the content of a webpage:
${text}
Instructions:
- If there is a blog post within this content, extract and return the main text of the blog post.
- If there is no blog post, summarize the most important information on the page.`
팟캐스트의 경우, 좀 더 작업을 해야 합니다.
Apple 팟캐스트 URL 역공학
팟캐스트 에피소드에서 데이터를 끌어오기 위해, 먼저 Whisper 모델을 사용하여 오디오를 텍스트로 변환해야 합니다. 그러나 그 전에 각 팟캐스트 에피소드의 실제 MP3 파일을 찾아 다운로드하고, 25MB 이하의 청크로 나누어야 합니다(Whisper의 최대 크기).
Apple은 팟캐스트 에피소드에 대한 직접 MP3 링크를 제공하지 않는다는 것이 도전 과제입니다. 그러나 MP3 파일은 팟캐스트의 원래 RSS 피드에서 사용할 수 있으며, 우리는 Apple 팟캐스트 ID를 사용하여 프로그램적으로 이 피드를 찾을 수 있습니다.
예를 들어, 아래 URL에서 /id 뒤의 숫자 부분이 팟캐스트의 고유한 Apple ID입니다:
https://podcasts.apple.com/us/podcast/deep-dive-into-inference-optimization-for-llms-with/id1699385780?i=1000675820505
Apple의 API를 사용하여 팟캐스트 ID를 조회하고 RSS 피드의 URL을 포함한 JSON 응답을 가져올 수 있습니다:
https://itunes.apple.com/lookup?id=1699385780&entity=podcast
RSS 피드 XML을 얻은 후, 우리는 특정 에피소드를 검색합니다. Apple에서 에피소드 URL만 가지고 있기 때문에(실제 제목은 아님), URL에서 제목 슬러그를 사용하여 피드 내에서 에피소드를 찾아 MP3 URL을 가져옵니다.
async function getMp3DownloadUrl(url) {
let podcastId = extractPodcastId(url);
let titleToMatch = extractAndFormatTitle(url);
if (podcastId) {
let feedLookupUrl = `https://itunes.apple.com/lookup?id=${podcastId}&entity=podcast`;
const itunesResponse = await axios.get(feedLookupUrl);
const itunesData = itunesResponse.data;
// Check if results were returned
if (itunesData.resultCount === 0 || !itunesData.results[0].feedUrl) {
console.error("No feed URL found for this podcast ID.");
return;
}
// Extract the feed URL
const feedUrl = itunesData.results[0].feedUrl;
// Fetch the document from the feed URL
const feedResponse = await axios.get(feedUrl);
const rssContent = feedResponse.data;
// Parse the RSS feed XML
const rssData = await parseStringPromise(rssContent);
const episodes = rssData.rss.channel[0].item; // Access all items (episodes) in the feed
// Find the matching episode by title, have to transform title to match the URL-based title
const matchingEpisode = episodes.find(episode => {
return getSlug(episode.title[0]).includes(titleToMatch);
}
);
if (!matchingEpisode) {
console.log(`No episode found with title containing "${titleToMatch}"`);
return false;
}
// Extract the MP3 URL from the enclosure tag
return matchingEpisode.enclosure[0].$.url;
}
return false;
}
이제 블로그 게시물, 웹사이트 및 MP3의 텍스트가 준비되었으므로, 에이전트는 LangChain의 재귀적 문자 텍스트 분할기를 사용하여 텍스트를 청크로 분할하고 이러한 청크에서 임베딩을 생성합니다. 청크는 text-embeddings 주제로 게시되고 MongoDB에 싱크됩니다.
- 참고: 나는 MongoDB를 애플리케이션 데이터베이스와 벡터 데이터베이스로 모두 사용하기로 선택했습니다. 그러나 내가 취한 EDA 접근 방식 때문에, 이러한 시스템은 쉽게 분리될 수 있으며, 텍스트 임베딩 주제에서 싱크 커넥터를 교체하는 것만으로 해결됩니다.
임베딩을 생성하고 게시하는 것 외에도 에이전트는 소스에서 텍스트를 full-text-from-sources라는 주제에 발행합니다. 이 주제에 발행함으로써 Action #2를 시작합니다.
Flink와 OpenAI로 질문 추출하기
아파치 Flink는 대량 데이터를 실시간으로 처리하기 위해 만들어진 오픈 소스 스트림 처리 프레임워크로, 고처리량 및 저대기 지연 애플리케이션에 이상적입니다. Flink를 Confluent와 함께 사용하면 OpenAI의 GPT와 같은 LLM을 스트리밍 워크플로에 직접 통합할 수 있습니다. 이 통합을 통해 실시간 RAG 워크플로를 구현하여 질문 추출 프로세스가 가장 최신 데이터와 함께 작동함을 보장합니다.
스트림에 원본 소스 텍스트가 포함되어 있으면 나중에 동일한 데이터를 사용하는 새로운 워크플로를 도입하여 연구 브리프 생성 프로세스를 향상하거나 데이터 웨어하우스와 같은 하류 서비스로 보낼 수 있습니다. 이 유연한 설정을 통해 핵심 파이프라인을 변경하지 않고 시간이 지남에 따라 추가적인 AI 및 비 AI 기능을 계층적으로 추가할 수 있습니다.
PodPrep AI에서는 Flink를 사용하여 소스 URL에서 텍스트를 추출하여 질문을 생성합니다.
Flink를 사용하여 LLM을 호출하려면 Confluent의 CLI를 통해 연결을 구성해야 합니다. 아래는 OpenAI 연결을 설정하는 예제 명령어이지만 여러 옵션이 있습니다.
confluent flink connection create openai-connection \
--cloud aws \
--region us-east-1 \
--type openai \
--endpoint https://api.openai.com/v1/chat/completions \
--api-key <REPLACE_WITH_OPEN_AI_KEY>
연결이 설정되면, Cloud Console 또는 Flink SQL 셸에서 모델을 생성할 수 있습니다. 질문 추출을 위해 모델을 적절히 설정합니다.
-- Creates model for pulling questions from research source material
CREATE MODEL `question_generation`
INPUT (text STRING)
OUTPUT (response STRING)
WITH (
'openai.connection'='openai-connection',
'provider'='openai',
'task'='text_generation',
'openai.model_version' = 'gpt-3.5-turbo',
'openai.system_prompt' = 'Extract the most interesting questions asked from the text. Paraphrase the questions and seperate each one by a blank line. Do not number the questions.'
);
모델이 준비되면, Flink의 내장 ml_predict 함수를 사용하여 소스 자료에서 질문을 생성하고, 출력을 mined-questions라는 스트림에 기록하여 나중에 사용할 수 있도록 MongoDB와 동기화합니다.
-- Generates questions based on text pulled from research source material
INSERT INTO `mined-questions`
SELECT
`key`,
`bundleId`,
`url`,
q.response AS questions
FROM
`full-text-from-sources`,
LATERAL TABLE (
ml_predict('question_generation', content)
) AS q;
Flink는 모든 연구 자료가 처리되었는지를 추적하여 연구 요약 생성을 촉발하는 데에도 도움을 줍니다. 이는 mined-questions의 URL이 전체 텍스트 소스 스트림의 URL과 일치할 때 completed-requests 스트림에 기록하여 수행됩니다.
-- Writes the bundleId to the complete topic once all questions have been created
INSERT INTO `completed-requests`
SELECT '' AS id, pmq.bundleId
FROM (
SELECT bundleId, COUNT(url) AS url_count_mined
FROM `mined-questions`
GROUP BY bundleId
) AS pmq
JOIN (
SELECT bundleId, COUNT(url) AS url_count_full
FROM `full-text-from-sources`
GROUP BY bundleId
) AS pft
ON pmq.bundleId = pft.bundleId
WHERE pmq.url_count_mined = pft.url_count_full;
메시지가 completed-requests에 기록되면, 연구 번들의 고유 ID가 생성 연구 요약 에이전트에 전송됩니다.
생성 연구 요약 에이전트
이 에이전트는 사용 가능한 가장 관련성 높은 연구 자료를 모두 수집하여 LLM을 사용해 연구 요약을 생성합니다. 아래는 연구 요약을 생성하기 위해 발생하는 이벤트의 고급 흐름입니다.

연구 요약 생성 에이전트의 흐름도
이 단계 중 일부를 자세히 살펴보겠습니다. LLM에 대한 프롬프트를 구성하기 위해, 저는 채굴된 질문, 주제, 게스트 이름, 회사 이름, 지침을 위한 시스템 프롬프트, 그리고 팟캐스트 주제와 가장 의미적으로 유사한 벡터 데이터베이스에 저장된 맥락을 결합합니다.
연구 번들이 제한된 맥락 정보를 가지고 있기 때문에, 벡터 저장소에서 가장 관련성 높은 맥락을 직접 추출하는 것은 도전적입니다. 이를 해결하기 위해 LLM이 최적의 콘텐츠를 찾기 위한 검색 쿼리를 생성하도록 합니다. 이는 다이어그램의 “검색 쿼리 생성” 노드에 표시되어 있습니다.
async function getSearchString(researchBundle) {
const userPrompt = `
Guest:
${researchBundle.guestName}
Company:
${researchBundle.company}
Topic:
${researchBundle.topic}
Context:
${researchBundle.context}
Create a natural language search query given the data available.
`;
const systemPrompt = `You are an expert in research for an engineering podcast. Using the
guest name, company, topic, and context, create the best possible query to search a vector
database for relevant data mined from blog posts and existing podcasts.`;
const messages = [
new SystemMessage(systemPrompt),
new HumanMessage(userPrompt),
];
const response = await model.invoke(messages);
return response.content;
}
LLM이 생성한 쿼리를 사용하여 임베딩을 만들고, bundleId로 필터링하여 특정 팟캐스트와 관련된 자료로 검색을 제한하며 MongoDB를 통해 벡터 인덱스를 검색합니다.
최상의 맥락 정보가 확인되면, 프롬프트를 작성하고 연구 개요를 생성하여 결과를 웹 애플리케이션에서 표시할 수 있도록 MongoDB에 저장합니다.
구현 시 유의 사항
저는 PodPrep AI의 프론트엔드 애플리케이션과 에이전트를 자바스크립트로 작성했지만, 실제 시나리오에서는 에이전트가 파이썬과 같은 다른 언어로 작성될 가능성이 큽니다. 또한, 단순성을 위해 URL 처리 및 임베딩 생성 에이전트와 연구 개요 생성 에이전트가 동일한 프로젝트 내에서 동일한 웹 서버에서 실행되고 있습니다. 실제 운영 시스템에서는 이들이 독립적으로 실행되는 서버리스 함수일 수 있습니다.
최종 생각
PodPrep AI의 구축은 이벤트 기반 아키텍처가 실제 AI 애플리케이션이 원활하게 확장하고 적응할 수 있도록 하는 방법을 강조합니다. Flink와 Confluent를 사용하여 실시간으로 데이터를 처리하는 시스템을 만들었으며, 이를 통해 엄격한 의존성 없이 AI 기반 워크플로우를 지원합니다. 이 분리된 접근 방식은 구성 요소가 독립적으로 작동할 수 있도록 하면서도 이벤트 스트림을 통해 연결 상태를 유지할 수 있게 합니다. 이는 다양한 팀이 스택의 여러 부분을 관리하는 복잡하고 분산된 애플리케이션에 필수적입니다.
오늘날의 AI 중심 환경에서는 시스템 전반에 걸쳐 신선하고 실시간 데이터를 접근하는 것이 필수적입니다. EDA는 데이터의 “중추 신경계” 역할을 하여 시스템이 확장될 때 원활한 통합과 유연성을 가능하게 합니다.
Source:
https://dzone.com/articles/build-a-research-assistant-with-kafka-flink