













Big data has significantly evolved since its inception in the late 2000s. Many organizations quickly adapted to the trend and built their big data platforms using open-source tools like Apache Hadoop. Later, these companies started facing trouble managing the rapidly evolving data processing needs. They have faced challenges handling schema level changes, partition scheme evolution, and going back in time to look at the data.
I faced similar challenges while designing large-scale distributed systems back in the 2010s for a big tech company and a healthcare customer. Some industries need these capabilities to adhere to banking, finance, and healthcare regulations. Heavy data-driven companies like Netflix faced similar challenges as well. They invented a table format called “Iceberg,” which sits on top of the existing data files and delivers key features by leveraging its architecture. This has quickly become the top ASF project as it gained rapid interest in the data community. I will explore the top 5 Apache Iceberg key features in this article with examples and diagrams.
1. Time Travel

Figure 1: Time travel in Apache Iceberg table format (image created by author)
This feature allows you to query your data as it exists at any point. This will open up new possibilities for data and business analysts to understand trends and how the data evolved over time. You can effortlessly roll back to a previous state in case of any errors. This feature also facilitates auditing checks by allowing you to analyze the data at a specific point in time.
-- time travel to October 5th, 1978 at 07:00:00
SELECT * FROM prod.retail.cusotmers TIMESTAMP AS OF '1978-10-05 07:00:00';
-- time travel using a specific snapshot ID:
SELECT * FROM prod.retail.customers VERSON AS OF 949530903748831869;
2. Schema Evolution
Apache Iceberg’s schema evolution allows changes to your schema without any huge effort or costly migrations. As your business needs evolve, you can:
- Add and remove columns without any downtime or table rewrites.
- Update the column (widening).
- Change the order of columns.
- Rename an existing column.
These changes are handled at the metadata level without needing to rewrite the underlying data.
-- add a new column to the table
ALTER TABLE prod.retail.customers ADD COLUMNS (email_address STRING);
-- remove an existing column from the table
ALTER TABLE prod.retail.customers DROP COLUMN num_of_years;
-- rename an existing column
ALTER TABLE prod.retail.customers RENAME COLUMN email_address TO email;
-- iceberg allows updating column types from int to bigint, float to double
ALTER TABLE prod.retail.customers ALTER COLUMN customer_id TYPE bigint;
3. Partition Evolution
Using the Apache Iceberg table format, you can change the table partitioning strategy without rewriting the underlying table or migrating the data to a new table. This is made possible as queries do not reference the partition values directly like in Apache Hadoop. Iceberg keeps metadata information for each partition version separately. This makes it easy to get the splits while querying the data. For example, querying a table based on the date range, while the table was using the month as a partition column (before) as one split and day as a new partition column (after) as another split. This is called split planning. See the example below.
-- create customers table partitioned by month of the create_date initially
CREATE TABLE local.retail.customer (
id BIGINT,
name STRING,
street STRING,
city STRING,
state STRING,
create_date DATE
USING iceberg
PARTITIONED BY (month(create_date));
-- insert some data into the table
INSERT INTO local.retail.customer VALUES
(1, 'Alice', '123 Maple St', 'Springfield', 'IL', DATE('2024-01-10')),
(2, 'Bob', '456 Oak St', 'Salem', 'OR', DATE('2024-02-15')),
(3, 'Charlie', '789 Pine St', 'Austin', 'TX', DATE('2024-02-20'));
-- change the partition scheme from month to date
ALTER TABLE local.retail.customer
REPLACE PARTITION FIELD month(create_date) WITH days(create_date);
-- insert couple more records
INSERT INTO local.retail.customer VALUES
(4, 'David', '987 Elm St', 'Portland', 'ME', DATE('2024-03-01')),
(5, 'Eve', '654 Birch St', 'Miami', 'FL', DATE('2024-03-02'));
-- select all columns from the table
SELECT * FROM local.retail.customer
WHERE create_date BETWEEN DATE('2024-01-01') AND DATE('2024-03-31');
-- output
1 Alice 123 Maple St Springfield IL 2024-01-10
5 Eve 654 Birch St Miami FL 2024-03-02
4 David 987 Elm St Portland ME 2024-03-01
2 Bob 456 Oak St Salem OR 2024-02-15
3 Charlie 789 Pine St Austin TX 2024-02-20
-- View parition details
SELECT partition, file_path, record_count
FROM local.retail.customer.files;
-- output
{"create_date_month":null,"create_date_day":2024-03-02} /Users/rellaturi/warehouse/retail/customer/data/create_date_day=2024-03-02/00000-6-ae2fdf0d-5567-4c77-9bd1-a5d9f6c83dfe-0-00002.parquet 1
{"create_date_month":null,"create_date_day":2024-03-01} /Users/rvellaturi/warehouse/retail/customer/data/create_date_day=2024-03-01/00000-6-ae2fdf0d-5567-4c77-9bd1-a5d9f6c83dfe-0-00001.parquet 1
{"create_date_month":648,"create_date_day":null} /Users/rvellaturi/warehouse/retail/customer/data/create_date_month=2024-01/00000-3-64c8b711-f757-45b4-828f-553ae9779d14-0-00001.parquet 1
{"create_date_month":649,"create_date_day":null} /Users/rvellaturi/warehouse/retail/customer/data/create_date_month=2024-02/00000-3-64c8b711-f757-45b4-828f-553ae9779d14-0-00002.parquet 2
4. ACID Transactions
Iceberg provides robust support for transactions in terms of Atomicity, Consistency, Isolation, and Durability (ACID). It allows multiple concurrent write operations, which will enable high throughput in heavy data-intensive jobs without compromising data consistency.
-- Start a transaction
START TRANSACTION;
-- Insert new records
INSERT INTO customers VALUES (1, 'John'), (2, 'Mike');
-- Update existing records
UPDATE customers SET column1 = 'Josh' WHERE id = 1;
-- Delete records
DELETE FROM customers WHERE id = 2;
-- Commit the transaction
COMMIT;
All operations in Iceberg are transactional, meaning the data remains consistent despite failures or modifications to the data concurrently.
-- Atomic update across multiple tables
START TRANSACTION;
UPDATE orders SET status = 'processed' WHERE order_id = 100;
INSERT INTO orders_processed SELECT * FROM orders WHERE order_id = 100;
COMMIT;
It also supports different isolation levels, which allows you to balance performance and consistency based on the requirement.
-- Set isolation level (syntax may vary depending on the query engine)
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
-- Perform operations
SELECT * FROM customers WHERE id = 1;
UPDATE customers SET rec_status= 'updated' WHERE id = 1;
COMMIT;
Here is a summary showing how Iceberg handles row-level updates and deletes.
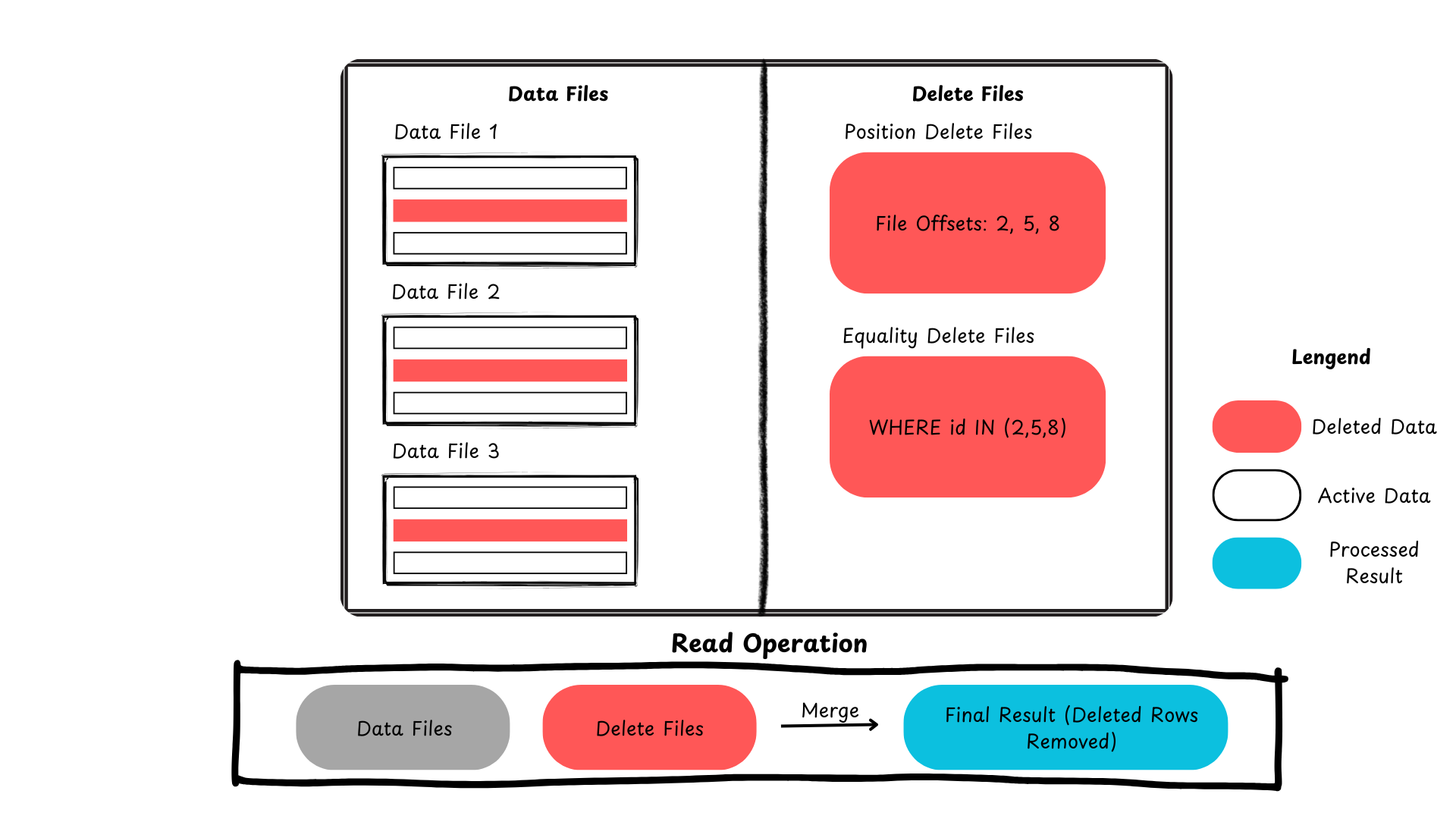
Figure 2: Delete records process in Apache Iceberg (image created by author)
5. Advanced Table Operations
Iceberg supports advanced table operations such as:
- Creating/managing table snapshots: This gives the ability to have robust version control.
- Fast query planning and execution with it’s highly optimized metadata
- Built-in tools for table maintenance, such as compaction and orphan file cleanup
Iceberg is designed to work with all major cloud storage, such as AWS S3, GCS, and Azure Blob Storage. Also, Iceberg integrates easily with data processing engines such as Spark, Presto, Trino, and Hive.
Final Thoughts
These highlighted features allow companies to build modern, flexible, scalable, and efficient data lakes, which can time travel, easily handle schema changes, support ACID transactions, and partition evolution.
Source:
https://dzone.com/articles/key-features-of-apache-iceberg-for-data-lakes