













PostgreSQLにおけるレプリケーションラグは、プライマリサーバーで行われた変更がレプリカサーバーに反映されるまでに時間がかかることを指します。ストリーミングレプリケーションまたはロジカルレプリケーションを使用する場合でも、ラグはパフォーマンス、一貫性、およびシステムの可用性に影響を及ぼす可能性があります。この投稿では、レプリケーションの種類、その違い、ラグの原因、ラグ推定のための数学的公式、監視技術、およびレプリケーションラグを最小化するための戦略について説明します。
PostgreSQLにおけるレプリケーションの種類
ストリーミングレプリケーション
ストリーミングレプリケーションは、プライマリから1つまたは複数のレプリカサーバーに対して、ほぼリアルタイムでウォル(WAL)の変更を継続的に送信します。レプリカは、受信した変更を順次適用します。この方法は、データベース全体をレプリケートし、レプリカが同期を保つことを保証します。
利点
- ほぼリアルタイムの同期による低遅延。
- 完全なデータベースのレプリケーションに効率的。
欠点
- レプリカは読み取り専用であり、すべての書き込みトランザクションはプライマリノードに送信されなければなりません。
- ネットワーク接続が切断されると、ラグが大幅に増加する可能性があります。
ロジカルレプリケーション
論理レプリケーションは、低レベルのWALデータではなくデータレベルの変更を転送します。特定のテーブルやデータベースの一部のみをレプリケーションする選択的レプリケーションが可能です。論理レプリケーションは論理デコーディングプロセスを使用して、WALの変更をSQLライクな変更に変換します。
利点
- 特定のテーブルやスキーマの選択的レプリケーションが可能です。
- 競合解決オプションを備えた書き込み可能なレプリカをサポートします。
欠点
- 論理デコーディングのオーバーヘッドによる遅延があります。
- 大規模なデータセットに対してストリーミングレプリケーションよりも効率が低いです。
レプリケーション遅延の発生方法
レプリケーション遅延は、プライマリサーバーで生成される変更の速度がレプリカサーバーで処理および適用される速度を上回ると発生します。この不均衡は、データ同期の遅延に寄与するさまざまな基本的な要因によって生じる可能性があります。レプリケーション遅延の最も一般的な原因は次のとおりです:
ネットワークレイテンシー
ネットワークレイテンシーとは、データがプライマリサーバーからレプリカサーバーまで移動する時間を指します。ストリーミングレプリケーション中にはWAL(Write-Ahead Log)セグメントがネットワークを通じて連続して送信されます。ネットワーク伝送のわずかな遅延でも蓄積され、レプリカの遅延の原因となります。
原因
- 高いネットワーク往復時間(RTT)。
- 高いWALデータのボリュームを処理するための帯域幅。
- ネットワークの混雑またはパケット損失。
プライマリサーバーがピークトラフィック中に大きな変更を生成すると、遅いまたは過負荷のネットワークがボトルネックを引き起こし、レプリカがWAL変更を受信できなくなる可能性があります。
解決策
低遅延、高帯域幅のネットワーク接続を使用し、WAL圧縮(wal_compression = on)を有効にして、データのサイズを伝送中に削減します。
I/Oボトルネック
I/Oボトルネックは、レプリカサーバーのディスクが受信したWAL変更を書き込むのに遅すぎる場合に発生します。ストリーミングレプリケーションは、変更を適用する前にディスクに書き込むことに依存しているため、I/Oサブシステムの遅延が発生すると、遅れが蓄積される可能性があります。
原因
- 遅いまたは過負荷のハードディスクドライブ(HDD)。
- ディスク書き込みスループットが不十分。
- 他のプロセスからのディスク競合。
- レプリカサーバーがソリッドステートドライブ(SSD)ではなく回転ディスク(HDD)を使用している場合、WAL変更がデータ変更に追いつくのに十分な速さで書き込まれない可能性があり、レプリカがプライマリから遅れる原因となります。
解決策
レプリカのディスクI/Oを最適化するために、SSDを使用してより高速な書き込み速度を実現し、レプリケーションプロセスを他のディスク集約型タスクから隔離します。
CPU/メモリ制約
レプリケーションプロセスは、変更をデコード、書き込み、適用するためにCPUとメモリを必要とします。レプリカサーバーに十分な処理能力やメモリがない場合、受信する変更に追いつくのが難しくなり、レプリケーションラグが発生する可能性があります。
原因
- CPUコアの制限または遅いプロセッサ。
- WALバッファ用のメモリ不足。
- 他のプロセスがCPUまたはメモリリソースを消費している。
- レプリカが大きなトランザクションを処理したり、レプリケーションと同時にクエリを実行している場合、CPUが飽和状態になり、レプリケーションプロセスが遅くなる可能性があります。
解決策
レプリカサーバーにより多くのCPUコアとメモリを割り当てます。WAL処理効率を改善するために、wal_buffersのサイズを増やします。
プライマリサーバーの重い負荷
レプリケーションラグは、プライマリサーバーがレプリカが処理できる以上の変更を急速に生成する場合にも発生することがあります。大きなトランザクション、バルク挿入、または頻繁な更新は、レプリケーションを圧倒する可能性があります。
原因
- バルクデータのインポートや大規模なトランザクション。
- 大きなテーブルへの高頻度の更新。
- プライマリ上の高い同時実行負荷。
- プライマリサーバーが同時に複数の大きなトランザクションを処理している場合、トランザクションの負荷が重すぎる可能性があります。例えば、バルクデータのインポート中などです。WALデータの量がレプリカがリアルタイムで処理できる量を超えると、ラグが増加します。
解決策
トランザクションを最適化するために、より小さな更新をバッチ処理し、長時間実行されるトランザクションを避けてください。厳密な同期が重要でない場合は、非同期レプリケーションを使用してレプリケーションの負担を軽減してください。
リソース競合
リソース競合は、複数のプロセスがCPU、メモリ、またはディスクI/Oなどの同じリソースを競い合うときに発生します。これはプライマリサーバーまたはレプリカサーバーのいずれかで発生し、レプリケーション処理の遅延を引き起こす可能性があります。
原因
- 他のプロセスがディスクI/O、CPU、またはメモリを消費します。
- バックアップや分析などのバックグラウンドタスクが同時に実行されています。
- レプリケーショントラフィックと他のデータ転送との間のネットワーク競合。
- レプリカサーバーがバックアップや分析クエリも実行している場合、CPUやディスクリソースの競合によりレプリケーションプロセスが遅くなる可能性があります。
解決策
レプリケーションのワークロードを他のリソース集約型プロセスから分離します。バックアップや分析をオフピーク時間にスケジュールして、レプリケーションへの干渉を防ぎます。
レプリケーション遅延の数学的公式
レプリケーション遅延を計算するには、次の公式を使用します:

論理レプリケーションでは、論理デコーディングによって追加の時間が消費されます:

レプリケーション遅延の監視
ストリーミングレプリケーションの監視
pg_stat_replication ビューを使用してストリーミングレプリケーションの遅延を監視できます。これにより、プライマリとレプリカサーバー間の状態と遅延に関する洞察が得られます。
SELECT application_name, state,
pg_size_pretty(sent_lsn - write_lsn) AS lag_bytes,
sync_state
FROM pg_stat_replication;
sent_lsn:レプリカに送信された最後のWALロケーション。write_lsn:レプリカに書き込まれた最後のWALロケーション。lag_bytes:この2つの間の差は遅延を示します。
論理レプリケーションの監視
論理レプリケーションの遅延はpg_stat_subscription ビューを使用して監視できます。
SELECT subscription_name, active,
pg_size_pretty(pg_current_wal_lsn() - replay_lsn) AS lag_bytes
FROM pg_stat_subscription;
例:レプリケーション遅延の可視化
次のPythonコードスニペットは、時間経過によるストリーミングおよび論理レプリケーションの遅延を可視化します。
import matplotlib.pyplot as plt
time = ['12:00', '12:10', '12:20', '12:30', '12:40', '12:50', '13:00']
streaming_lag = [0.5, 0.6, 0.4, 0.7, 1.0, 0.9, 0.6]
logical_lag = [2.0, 2.5, 3.0, 2.8, 3.5, 4.0, 3.2]
plt.plot(time, streaming_lag, label='Streaming Replication Lag', marker='o')
plt.plot(time, logical_lag, label='Logical Replication Lag', marker='s')
plt.xlabel('Time')
plt.ylabel('Lag (seconds)')
plt.title('Replication Lag Over Time')
plt.legend()
plt.grid(True)
# Save the plot as an image file
plt.savefig('replication_lag_plot.png')
print("Plot saved as replication_lag_plot.png")
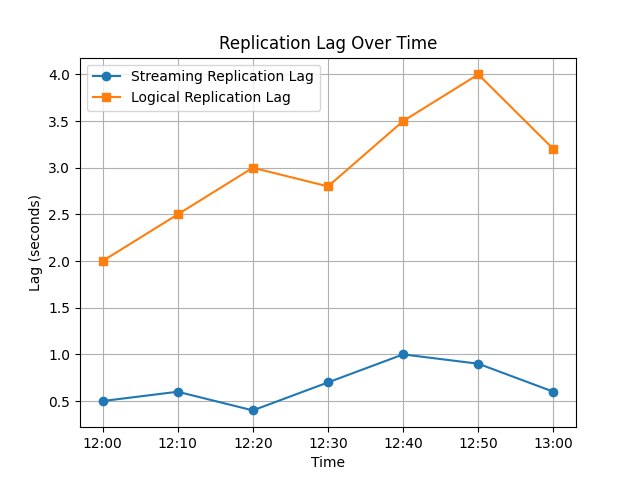
生成されるグラフは、ストリーミングと論理レプリケーションのパフォーマンスを比較します。デコードおよび処理のオーバーヘッドにより、論理レプリケーションの遅延がより変動する傾向があります。
レプリケーション遅延の削減方法
1. WAL構成の最適化
wal_buffersを増やして、より多くのWALデータをメモリに保持します。wal_writer_delayを低い値(例:10ms)に設定して、WALデータをより速く書き込みます。
wal_buffers = 64MB
wal_writer_delay = 10ms
2. ネットワークパフォーマンスの改善
- プライマリとレプリカ間で低レイテンシーで高帯域幅のネットワーク接続を使用します。
- 転送時間を短縮するために、WALデータを送信時に圧縮します:
wal_compression = on。
3. 非同期レプリケーションを使用する(可能な場合)
-
非同期レプリケーションは、レプリカが変更を確認するのを待たずにラグを減少させますが、データ損失のリスクも導入します。
ALTER SYSTEM SET synchronous_commit = 'off';
4. 論理レプリケーションで並列適用を有効にする
-
PostgreSQL 14+では、論理変更の並列適用が可能で、大規模なトランザクションのラグを減少させます。
ALTER SUBSCRIPTION my_subscription SET (parallel_apply = on);
5. レプリカにより多くのリソースを割り当てます
- レプリカがWALの変更を迅速に処理するために、十分なCPUとメモリがあることを確認してください。
- レプリカではSSDを使用してディスクI/Oを高速化してください。
6. トランザクションのバッチ処理
-
複数のマイナーアップデートを少ないトランザクションにグループ化してオーバーヘッドを最小限に抑えます。
実践例
ストリーミングレプリケーション遅延の削減
高トラフィックのPostgreSQLクラスターを運用している企業は、ピーク時にレプリケーション遅延に直面しました。彼らはwal_buffersを64MBに増やし、wal_writer_delayを10msに減らすことで、レプリケーション遅延を半減させました。高速ネットワーク接続に切り替えることで、遅延を1秒未満に短縮しました。
論理レプリケーション遅延の削減
複数の論理サブスクリプションを持つシステムは、高い書き込みワークロード時に遅延を経験しました。PostgreSQL 14での並列アプリケーションの有効化により、複数のワーカーにワークロードを分散させ、レプリケーション遅延を4秒から1秒未満に短縮しました。
結論
レプリケーション遅延は、PostgreSQLシステムのパフォーマンスと一貫性に影響を与える重要な問題です。ストリーミングレプリケーションは低レイテンシを提供しますが、全データベースのレプリケーションが必要です。一方、論理レプリケーションは柔軟性を提供しますが、オーバーヘッドが大きくなります。pg_stat_replicationおよびpg_stat_subscriptionを使用した定期的なモニタリングにより、管理者は遅延を検出して軽減することができます。
WAL(Write-Ahead Logging)の設定を最適化し、ネットワークパフォーマンスを向上させ、並列アプリケーションを使用し、十分なリソースを割り当てることで、遅延を大幅に減らすことができます。適切なチューニングにより、レプリカが同期されたままであり、システムが高い可用性とパフォーマンスを維持します。
Source:
https://dzone.com/articles/understanding-and-reducing-postgresql-replication-lag