













このシリーズの第1部では、最も信頼性が高く強力なドキュメント指向のNoSQLデータベースの一つであるMongoDBを見てきました。ここで第2部では、避けられないNoSQLデータベースの一つであるElasticsearchを検証します。
人気があり強力なオープンソースの分散型NoSQLデータベース以上に、Elasticsearchはまず検索および分析エンジンです。最も有名な検索エンジンApache Luceneの上に構築され、構造化データと非構造化データに対してリアルタイムの検索および分析操作を行うことができます。大量のデータを効率的に処理するように設計されています。
ここでもう一度、この短い投稿がElasticsearchのチュートリアルであることを否定します。したがって、読者は公式ドキュメントを広範に使用し、また、Madhusudhan Konda(Manning、2023年)の優れた書籍「Elasticsearch in Action」を活用して、製品のアーキテクチャと操作についてさらに学ぶことを強く推奨します。ここでは、前回と同じユースケースを実装しますが、今回はMongoDBではなくElasticsearchを使用します。
それでは、始めましょう!
ドメインモデル
以下の図は、私たちの*customer-order-product*ドメインモデルを示しています:
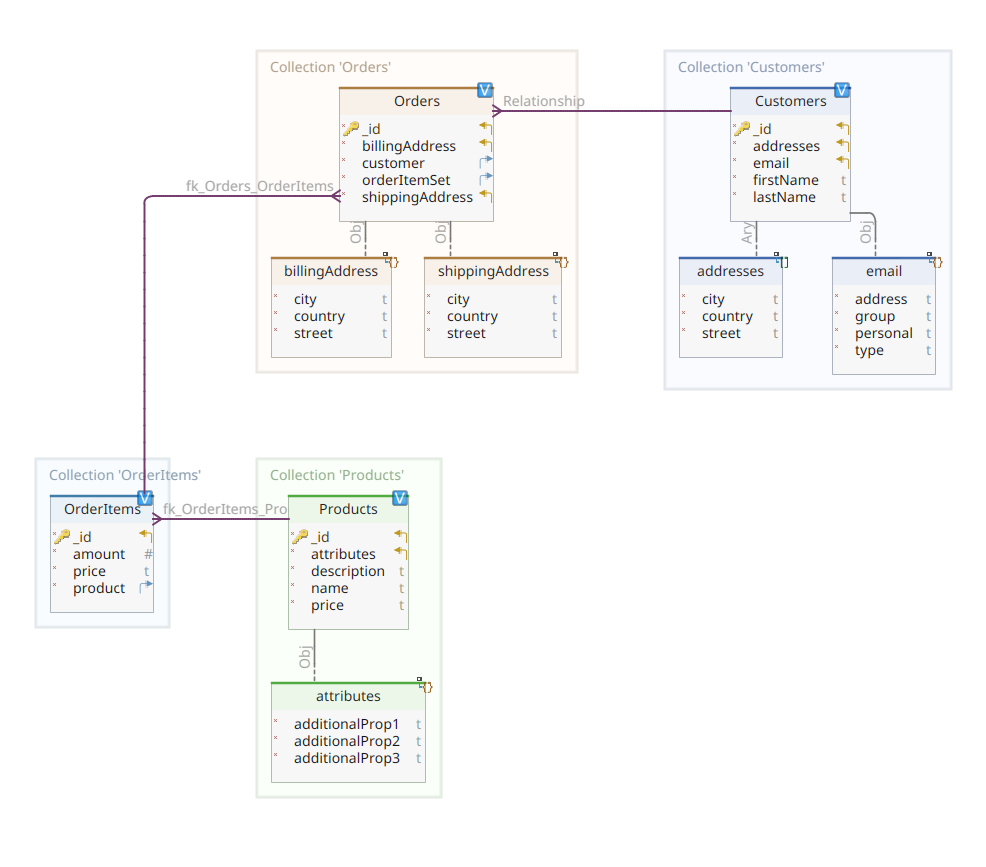
この図は第1部で提示されたものと同じです。MongoDBと同様に、Elasticsearchもドキュメントデータストアであり、したがって、JSON記法で提示されるドキュメントを想定しています。唯一の違いは、データを処理するために、Elasticsearchはインデックス化する必要があることです。
Elasticsearchデータストアにデータをインデックス化する方法はいくつかあります。例えば、リレーショナルデータベースからのパイプ、ファイルシステムからの抽出、リアルタイムソースからのストリーミングなどです。しかし、いかなるインジェスションメソッドであれ、最終的にはElasticsearch RESTful APIを専用クライアントを使用して呼び出すことになります。そのような専用クライアントは2つのカテゴリーに分けられます:
- RESTベースのクライアントは、
curl、Postman、Java、JavaScript、Node.jsなどのHTTPモジュールです。 - プログラミング言語SDK(ソフトウェア開発キット):Elasticsearchは、Java、Pythonなど最もよく使われるプログラミング言語全てにSDKを提供しています。
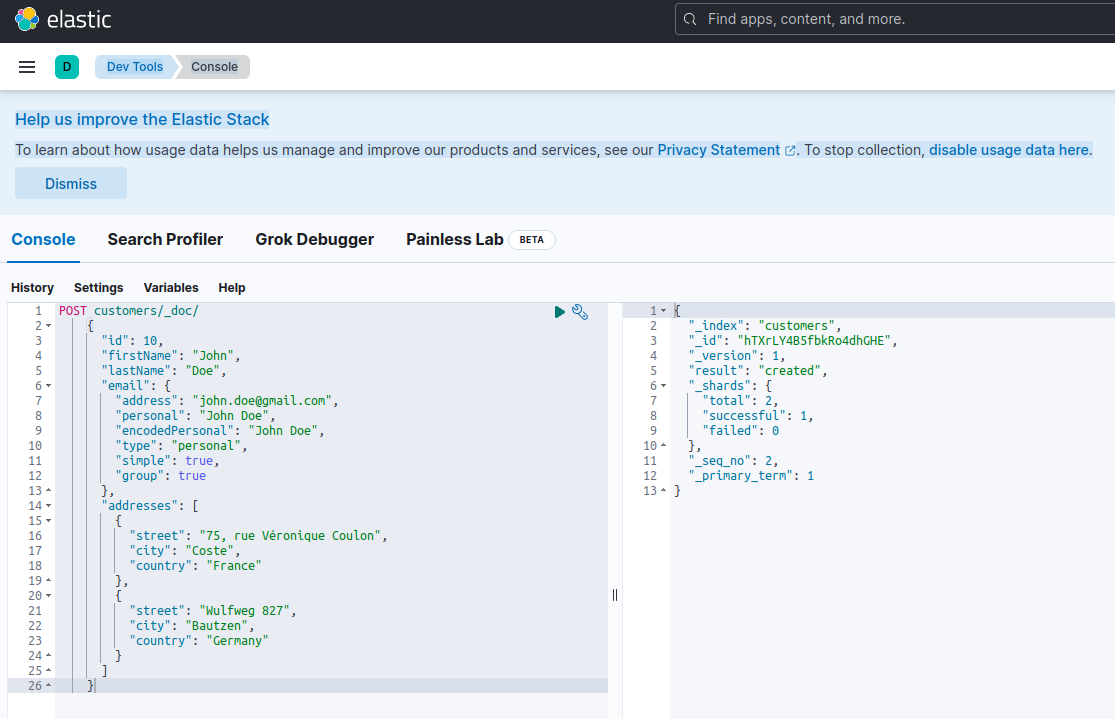
Elasticsearchで新しいドキュメントをインデックス化するには、特別なRESTful APIエンドポイントである_docに対してPOSTリクエストを使用して作成します。例えば、以下のリクエストは新しいElasticsearchインデックスを作成し、新しい顧客インスタンスをその中に保存します。
POST customers/_doc/
{
"id": 10,
"firstName": "John",
"lastName": "Doe",
"email": {
"address": "[email protected]",
"personal": "John Doe",
"encodedPersonal": "John Doe",
"type": "personal",
"simple": true,
"group": true
},
"addresses": [
{
"street": "75, rue Véronique Coulon",
"city": "Coste",
"country": "France"
},
{
"street": "Wulfweg 827",
"city": "Bautzen",
"country": "Germany"
}
]
}上記のリクエストを実行するためにcurlやKibanaコンソール(後述します)を使用すると、以下の結果が得られます:
{
"_index": "customers",
"_id": "ZEQsJI4BbwDzNcFB0ubC",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 1,
"_primary_term": 1
}
これは、POSTリクエストに対するElasticsearchの標準的な応答です。これにより、customersという名前のインデックスが作成され、新しいcustomerドキュメントが生成され、自動的に生成されたID(この場合、ZEQsJI4BbwDzNcFB0ubC)で識別されます。
ここには他にも興味深いパラメータが表示されます。例えば、_versionや特に_shardsなどです。詳細に立ち入ることなく、Elasticsearchはインデックスを論理的なドキュメントのコレクションとして作成します。書類をファイルキャビネットに保管するのと同様に、Elasticsearchはインデックスにドキュメントを保管します。各インデックスは、シャード,というApache Luceneの物理インスタンスで構成され、データの格納や取得をバックボーンワークhorseとして行います。これらは、ドキュメントを格納するプライマリ、または、名前の通り、プライマリシャードのコピーを格納するレプリカのいずれかかもしれません。その詳細についてはElasticsearchのドキュメントを参照してください – 今のところ、私たちが作成したcustomersというインデックスが2つのシャードで構成されていることに注意する必要があります。もちろん、そのうちの1つはプライマリです。
A final notice: the POST request above doesn’t mention the ID value as it is automatically generated. While this is probably the most common use case, we could have provided our own ID value. In each case, the HTTP request to be used isn’t POST anymore, but PUT.
私たちのドメインモデル図に戻ると、ご覧の通り、その中心のドキュメントはOrderで、Ordersという専用のコレクションに格納されています。OrderはOrderItemドキュメントのアグリゲートで、それぞれが関連するProductを指しています。Orderドキュメントは、また、注文をしたCustomerを参照しています。Javaでは以下のように実装されます:
public class Customer
{
private Long id;
private String firstName, lastName;
private InternetAddress email;
private Set<Address> addresses;
...
}
コードの上は、Customerクラスのフラグメントを示しています。これは、顧客のID、名前、フリガナ、メールアドレス、以及郵便住所のセットを持つシンプルなPOJO(Plain Old Java Object)です。
それでは、Orderドキュメントを見てみましょう。
public class Order
{
private Long id;
private String customerId;
private Address shippingAddress;
private Address billingAddress;
private Set<String> orderItemSet = new HashSet<>()
...
}
ここで、MongoDBバージョンとの違いに気づくことができます。実際、MongoDBでは、この注文に関連する顧客インスタンスへの参照を使用していました。Elasticsearchでは、参照という概念が存在しないため、このドキュメントIDを使用して、注文とそれを注文した顧客の間に関連を生成しています。同様に、orderItemSetプロパティも、注文とそのアイテムの間に関連を生成します。
ドメインモデルの残りは、同じ正規化アイデアに基づいて非常に似ています。例えば、OrderItemドキュメント:
public class OrderItem
{
private String id;
private String productId;
private BigDecimal price;
private int amount;
...
}
ここでは、現在の注文アイテムのオブジェクトである製品を関連付ける必要があります。最後に、Productドキュメント:
public class Product
{
private String id;
private String name, description;
private BigDecimal price;
private Map<String, String> attributes = new HashMap<>();
...
}データリポジトリ
Quarkus Panacheは、データ永続化プロセスを大大に簡素化し、アктивレコードとリポジトリのデザインパターンの両方をサポートしています。第1部では、Quarkus Panacheエクステンションを使用してMongoDBのデータリポジトリを実装しましたが、Elasticsearchのための同様のQuarkus Panacheエクステンションはまだありません。したがって、将来的にElasticsearchのためのQuarkusエクステンションが登場するのを待つ間、ここではElasticsearch専用クライアントを使用してデータリポジトリを手動で実装する必要があります。
ElasticsearchはJavaで書かれており、そのため、Javaクライアントライブラリを使用してElasticsearch APIを呼び出すネイティブサポートを提供していることに驚きはありません。このライブラリはフランクなAPIビルダーデザインパターンに基づいており、同期と非同期の処理モデルの両方を提供しています。最低Java 8が必要です。
では、フランクなAPIビルダーに基づくデータリポジトリはどんな風に見えるのでしょうか?以下はCustomerServiceImplクラスの一部であり、Customerドキュメントのためのデータリポジトリとして機能しています。
@ApplicationScoped
public class CustomerServiceImpl implements CustomerService
{
private static final String INDEX = "customers";
@Inject
ElasticsearchClient client;
@Override
public String doIndex(Customer customer) throws IOException
{
return client.index(IndexRequest.of(ir -> ir.index(INDEX).document(customer))).id();
}
...
見て的分かりますが、私たちのデータリポジトリ実装はアプリケーションスコープを持つCDIビーンでなければならず、Elasticsearch Javaクライアントは単にインジェクションされます。これにより、quarkus-elasticsearch-java-client Quarkusエクステンションを使用することで、多くの余計な設定を避けることができます。クライアントをインジェクトできるようにするためだけに、以下のプロパティを宣言する必要があります:
quarkus.elasticsearch.hosts = elasticsearch:9200以下は、elasticsearchがdocker-compose.yamlファイル内でElastic searchデータベースサーバーに関連付けられているDNS(ドメイン名サーバー)名です。9200は、サーバーが接続をリスeningするために使用するTCPポート番号です。
上記のメソッドdoIndex()は、customersという新しいインデックスが存在しない場合にそれを生成し、Customerクラスのインスタンスを表す新しいドキュメントをインデックス(保存)します。インデックスプロセスは、インデックス名とドキュメント本文を受け取るIndexRequestに基づいて実行されます。ドキュメントIDは自動的に生成され、呼び出し元に返されます。
以下のメソッドは、入力引数として与えられたIDで特定された顧客を取得することを許可します:
...
@Override
public Customer getCustomer(String id) throws IOException
{
GetResponse<Customer> getResponse = client.get(GetRequest.of(gr -> gr.index(INDEX).id(id)), Customer.class);
return getResponse.found() ? getResponse.source() : null;
}
...
原則は同じです:フラットAPIビルダーパターンを使用して、GetRequestインスタンスをIndexRequestと同様に構築し、Elasticsearch Javaクライアントに対して実行します。私たちのデータリポジトリの他のエンドポイント、完全な検索操作や顧客の更新および削除を許可するものも同様に設計されています。
コードを確認して、どのように動作しているかを理解してください。
REST API
私たちのMongoDB REST APIインターフェースは、quarkus-mongodb-rest-data-panacheエクステンションのおかげで簡単に実装できました。アノテーションプロセッサーが自動的にすべての必要なエンドポイントを生成します。Elasticsearchでは、まだ同じ利便性を享受できず、手動で実装する必要があります。でも、問題ありません。前のデータリポジトリを注入できるからです。以下はその例です:
@Path("customers")
@Produces(APPLICATION_JSON)
@Consumes(APPLICATION_JSON)
public class CustomerResourceImpl implements CustomerResource
{
@Inject
CustomerService customerService;
@Override
public Response createCustomer(Customer customer, @Context UriInfo uriInfo) throws IOException
{
return Response.accepted(customerService.doIndex(customer)).build();
}
@Override
public Response findCustomerById(String id) throws IOException
{
return Response.ok().entity(customerService.getCustomer(id)).build();
}
@Override
public Response updateCustomer(Customer customer) throws IOException
{
customerService.modifyCustomer(customer);
return Response.noContent().build();
}
@Override
public Response deleteCustomerById(String id) throws IOException
{
customerService.removeCustomerById(id);
return Response.noContent().build();
}
}これは顧客のREST API実装です。注文、注文アイテム、製品に関連する他のものも同様です。
それでは、全体をどう运行し、テストするか見てみましょう。
マイクロサービスの运行とテスト
実装の詳細を見たところで、それを実行しテストする方法を見てみましょう。私たちはdocker-composeユーティリティを使って実行することにしました。以下は関連するdocker-compose.ymlファイルです:
version: "3.7"
services:
elasticsearch:
image: elasticsearch:8.12.2
environment:
node.name: node1
cluster.name: elasticsearch
discovery.type: single-node
bootstrap.memory_lock: "true"
xpack.security.enabled: "false"
path.repo: /usr/share/elasticsearch/backups
ES_JAVA_OPTS: -Xms512m -Xmx512m
hostname: elasticsearch
container_name: elasticsearch
ports:
- "9200:9200"
- "9300:9300"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- node1-data:/usr/share/elasticsearch/data
networks:
- elasticsearch
kibana:
image: docker.elastic.co/kibana/kibana:8.6.2
hostname: kibana
container_name: kibana
environment:
- elasticsearch.url=http://elasticsearch:9200
- csp.strict=false
ulimits:
memlock:
soft: -1
hard: -1
ports:
- 5601:5601
networks:
- elasticsearch
depends_on:
- elasticsearch
links:
- elasticsearch:elasticsearch
docstore:
image: quarkus-nosql-tests/docstore-elasticsearch:1.0-SNAPSHOT
depends_on:
- elasticsearch
- kibana
hostname: docstore
container_name: docstore
links:
- elasticsearch:elasticsearch
- kibana:kibana
ports:
- "8080:8080"
- "5005:5005"
networks:
- elasticsearch
environment:
JAVA_DEBUG: "true"
JAVA_APP_DIR: /home/jboss
JAVA_APP_JAR: quarkus-run.jar
volumes:
node1-data:
driver: local
networks:
elasticsearch:
このファイルはdocker-composeユーティリティに3つのサービスを実行するよう指示しています:
- A service named
elasticsearchrunning the Elasticsearch 8.6.2 database - A service named
kibanarunning the multipurpose web console providing different options such as executing queries, creating aggregations, and developing dashboards and graphs - A service named
docstorerunning our Quarkus microservice
現在、すべての必要なプロセスが运行しているか確認できます:
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
005ab8ebf6c0 quarkus-nosql-tests/docstore-elasticsearch:1.0-SNAPSHOT "/opt/jboss/containe…" 3 days ago Up 3 days 0.0.0.0:5005->5005/tcp, :::5005->5005/tcp, 0.0.0.0:8080->8080/tcp, :::8080->8080/tcp, 8443/tcp docstore
9678c0a04307 docker.elastic.co/kibana/kibana:8.6.2 "/bin/tini -- /usr/l…" 3 days ago Up 3 days 0.0.0.0:5601->5601/tcp, :::5601->5601/tcp kibana
805eba38ff6c elasticsearch:8.12.2 "/bin/tini -- /usr/l…" 3 days ago Up 3 days 0.0.0.0:9200->9200/tcp, :::9200->9200/tcp, 0.0.0.0:9300->9300/tcp, :::9300->9300/tcp elasticsearch
$
Elasticsearchサーバーが利用可能であり、クエリを実行できることを確認するために、Kibanaにhttp://localhost:601で接続できます。ページを下にスクロールして、設定メニューでDev Toolsを選択すると、以下のようにクエリを実行できます:
マイクロサービスをテストするには、以下の手順に従ってください:
1. 関連するGitHubリポジトリをクローンします:
$ git clone https://github.com/nicolasduminil/docstore.git2. プロジェクトに移動します:
$ cd docstore3. 正しいブランチをチェックアウトします:
$ git checkout elastic-search4. ビルドします:
$ mvn clean install5. 統合テストを実行します:
$ mvn -DskipTests=false failsafe:integration-testこの最後のコマンドは、提供された17の統合テストを実行し、すべて成功するはずです。テストのためには、Swagger UIインターフェースを使用することもでき、お好みのブラウザで http://localhost:8080/q:swagger-ui にアクセスします。また、エンドポイントをテストするために、docstore-apiプロジェクトのsrc/resources/dataディレクトリに配置されたJSONファイル内のパayloadを使用できます。
楽しみましょう!
Source:
https://dzone.com/articles/cruding-nosql-data-with-quarkus-part-two-elasticse