













Whisper AIは、印象的な精度でオーディオをテキストに転記し、複数の言語をサポートする、OpenAIによって開発された高度な自動音声認識(ASR)モデルです。Whisper AIは主にバッチ処理用に設計されていますが、Linux上でリアルタイムの音声からテキストへの変換を行うように構成することも可能です。
このガイドでは、Linuxシステムでライブトランスクリプション用にWhisper AIをインストール、設定、実行する手順を詳しく説明します。
Whisper AIとは何ですか?
Whisper AIは、幅広いオーディオ録音のデータセットでトレーニングされたオープンソースの音声認識モデルであり、以下の機能を可能にするディープラーニングアーキテクチャに基づいています:
- 複数の言語での音声の転記。
- アクセントやバックグラウンドノイズの効率的な処理。
- 話された言語の英語への翻訳。
高精度の転記を目的として設計されているため、以下で広く使用されています:
- ライブトランスクリプションサービス(アクセシビリティ向上のため)。
- 音声アシスタントと自動化。
- 録音されたオーディオファイルの転記。
Whisper AIはデフォルトではリアルタイム処理に最適化されていません。ただし、追加のツールを使用することで、ライブオーディオストリームを即座に転記することができます。
Whisper AIシステム要件
Whisper AIをLinuxで実行する前に、システムが以下の要件を満たしていることを確認してください:
ハードウェア要件:
- CPU:マルチコアプロセッサ(Intel/AMD)。
- RAM:最低8GB(16GB以上を推奨)。
- GPU:NVIDIA GPU(CUDA付き、オプションですが処理速度が大幅に向上します)。
- ストレージ:モデルと依存関係のために最低10GBの空きディスクスペース。
ソフトウェア要件:
- Ubuntu、Debian、Arch、FedoraなどのLinuxディストリビューション。
- Pythonバージョン3.8以上。
- Pipパッケージマネージャー(Pythonパッケージをインストールするため)。
- FFmpeg(オーディオファイルとストリームを処理するため)。
ステップ1:必要な依存関係のインストール
Whisper AIをインストールする前に、パッケージリストを更新し、既存のパッケージをアップグレードします。
sudo apt update [On Ubuntu] sudo dnf update -y [On Fedora] sudo pacman -Syu [On Arch]
次に、Python 3.8以上とPipパッケージマネージャーをインストールする必要があります。
sudo apt install python3 python3-pip python3-venv -y [On Ubuntu] sudo dnf install python3 python3-pip python3-virtualenv -y [On Fedora] sudo pacman -S python python-pip python-virtualenv [On Arch]
最後に、オーディオとビデオファイルを処理するためのマルチメディアフレームワークであるFFmpegをインストールする必要があります。
sudo apt install ffmpeg [On Ubuntu] sudo dnf install ffmpeg [On Fedora] sudo pacman -S ffmpeg [On Arch]
ステップ2:LinuxにWhisper AIをインストール
必要な依存関係がインストールされたら、Pythonパッケージをシステムパッケージに影響を与えることなくインストールできる仮想環境にWhisper AIをインストールできます。
python3 -m venv whisper_env source whisper_env/bin/activate pip install openai-whisper
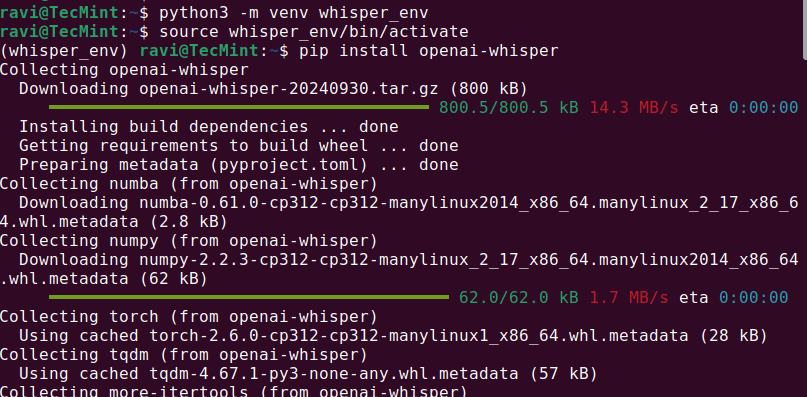
インストールが完了したら、実行してWhisper AIが正しくインストールされたかどうかを確認してください。
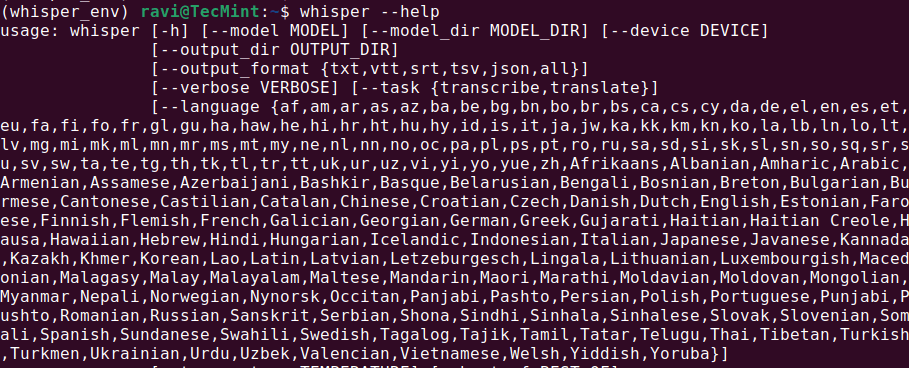
whisper --help
これにより、利用可能なコマンドとオプションを含むヘルプメニューが表示されるはずです。これはWhisper AIがインストールされ、使用準備が整っていることを意味します。
ステップ3:LinuxでWhisper AIを実行する
Whisper AIがインストールされたら、異なるコマンドを使用してオーディオファイルを文字起こしできます。
オーディオファイルの文字起こし
オーディオファイル(audio.mp3)を文字起こしするには、次を実行します。
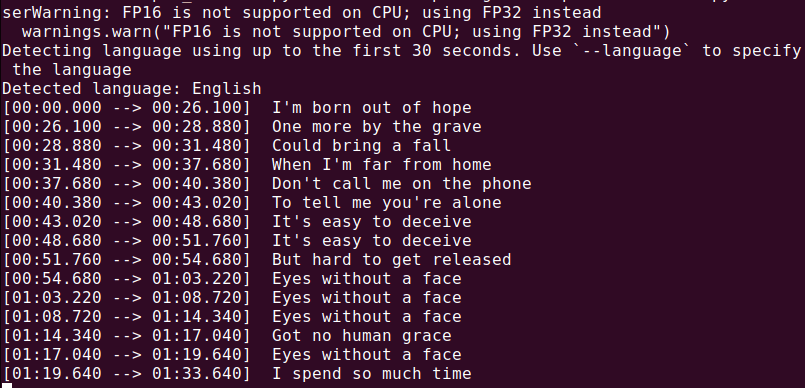
whisper audio.mp3
Whisperがファイルを処理し、テキスト形式でトランスクリプトを生成します。
すべてがインストールされたので、マイクから音声をキャプチャし、リアルタイムでそれを文字起こしするPythonスクリプトを作成しましょう。
nano real_time_transcription.py
次のコードをファイルにコピーして貼り付けます。
import sounddevice as sd
import numpy as np
import whisper
import queue
import threading
# Load the Whisper model
model = whisper.load_model("base")
# Audio parameters
SAMPLE_RATE = 16000
BUFFER_SIZE = 1024
audio_queue = queue.Queue()
def audio_callback(indata, frames, time, status):
"""Callback function to capture audio data."""
if status:
print(status)
audio_queue.put(indata.copy())
def transcribe_audio():
"""Thread to transcribe audio in real time."""
while True:
audio_data = audio_queue.get()
audio_data = np.concatenate(list(audio_queue.queue)) # Combine buffered audio
audio_queue.queue.clear()
# Transcribe the audio
result = model.transcribe(audio_data.flatten(), language="en")
print(f"Transcription: {result['text']}")
# Start the transcription thread
transcription_thread = threading.Thread(target=transcribe_audio, daemon=True)
transcription_thread.start()
# Start capturing audio from the microphone
with sd.InputStream(callback=audio_callback, channels=1, samplerate=SAMPLE_RATE, blocksize=BUFFER_SIZE):
print("Listening... Press Ctrl+C to stop.")
try:
while True:
pass
except KeyboardInterrupt:
print("\nStopping...")
Pythonを使用してスクリプトを実行すると、マイク入力を受信し、リアルタイムで文字起こししたテキストが表示されます。マイクにはっきりと話し、結果が端末に表示されるはずです。
python3 real_time_transcription.py
結論
Whisper AIはLinuxでリアルタイムの文字起こしに適応できる強力な音声からテキストへの変換ツールです。最良の結果を得るには、GPUを使用し、システムをリアルタイム処理に最適化してください。
Source:
https://www.tecmint.com/whisper-ai-audio-transcription-on-linux/