













VAR-As-A-Serviceは、統計モデルと機械学習モデルのデプロイメントパイプラインの統一と再利用を目的としたMLOpsアプローチです。これは、さまざまな統計および機械学習モデル、既存のDAGツールを使用して実装されたデータパイプライン、クラウドベースおよびオンプレミスの代替ストレージサービスで行われた実験を表す一連の記事の2番目です。この記事では、機械学習モデルにも適用可能で使用されているアプローチでモデルファイルストレージに焦点を当てています。実装されたストレージは、AWS S3互換オブジェクトストレージサービスとしてのMinIOをベースにしています。さらに、この記事では代替ストレージソリューションの概要を示し、オブジェクトベースのストレージの利点を概説しています。
シリーズの最初の記事(時系列分析:VARMAX-As-A-Service)では、統計モデルと機械学習モデルを数学モデルとして比較し、Pythonライブラリstatsmodelsを使用してVARMAXベースの統計モデルのマクロ経済予測のエンドツーエンド実装を提供しています。モデルはPython FlaskとApacheウェブサーバーを使用してRESTサービスとしてデプロイされ、Dockerコンテナにパッケージ化されています。アプリケーションのハイレベルなアーキテクチャは以下の図に示されています。
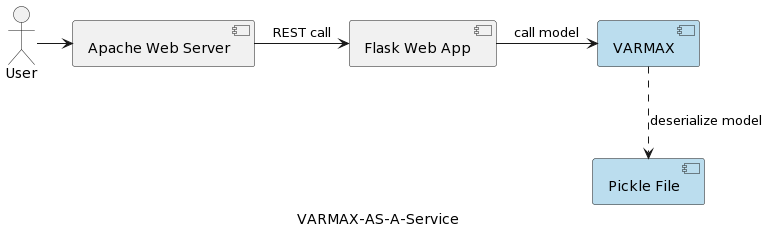
モデルはpickleファイルとしてシリアル化され、RESTサービスパッケージの一部としてウェブサーバーに展開されます。しかし、実際のプロジェクトでは、モデルはバージョン管理され、メタデータ情報と共にセキュリティ保護され、トレーニング実験はログに記録され、再現可能な状態に保たれる必要があります。さらに、アーキテクチャ的な観点から、アプリケーションと同じファイルシステムにモデルを保存することは、単一責任の原則に矛盾します。良い例がマイクロサービスベースのアーキテクチャです。モデルサービスを水平方向にスケーリングすると、各マイクロサービスインスタンスが物理的なpickleファイルの独自のバージョンを持ち、すべてのサービスインスタンスにコピーされます。それはまた、モデルの複数バージョンのサポートが、RESTサービスとそのインフラストラクチャの新しいリリースと再デプロイを必要とすることを意味します。この記事の目的は、モデルをウェブサービスインフラストラクチャから切り離し、異なるバージョンのモデルでウェブサービスロジックの再利用を可能にすることです。
実装に入る前に、統計モデルとそのプロジェクトで使用されたVARモデルについて少し説明しましょう。統計モデルは数学的モデルであり、機械学習モデルも同様です。この2つの違いについては、シリーズの最初の記事で詳しく説明されています。統計モデルは通常、1つ以上の確率変数と他の非確率的変数との間の数学的関係として指定されます。ベクトル自己回帰(VAR)は、時間の経過とともに変化する複数の量の関係を捉えるために使用される統計モデルです。VARモデルは、多変量時系列を可能にする単一変数自己回帰モデル(AR)を一般化したものです。提示されたプロジェクトでは、2つの変数の予測を行うためにモデルがトレーニングされています。VARモデルは経済学や自然科学でよく使用されます。一般的に、モデルはプロジェクトではPythonライブラリstatsmodelsの背後に隠れた方程式系で表されます。
VARモデルサービスアプリケーションのアーキテクチャは、以下の図に示されています。
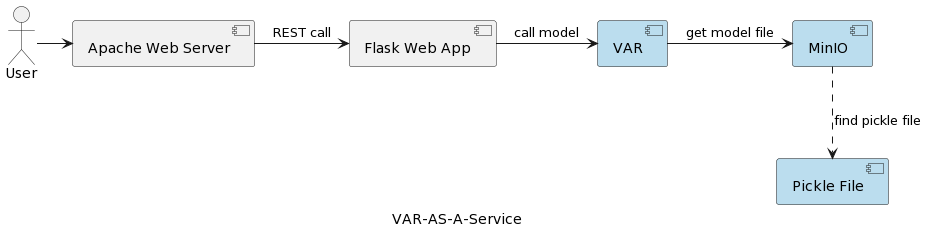
VARランタイムコンポーネントは、ユーザーから送られたパラメータに基づいて実際のモデル実行を表します。RESTインターフェースを介してMinIOサービスに接続し、モデルをロードして予測を実行します。最初の記事のソリューションと比較して、VARMAXモデルがアプリケーションの起動時にロードおよび逆シリアル化されるのに対し、VARモデルは予測がトリガーされるたびにMinIOサーバーから読み込まれます。これには、追加のロードおよび逆シリアル化時間が伴いますが、各実行で最新のデプロイメントされたモデルを持つという利点もあります。さらに、モデルの動的バージョン管理を可能にし、後の記事で示すように、外部システムおよびエンドユーザーに自動的にアクセス可能になります。ロードオーバーヘッドのため、選択されたストレージサービスのパフォーマンスは非常に重要です。
しかし、なぜMinIOや一般的なオブジェクトベースのストレージなのでしょうか?
MinIOは、Kubernetesデプロイメントに対応した高性能なオブジェクトストレージソリューションであり、Amazon Web ServicesS3互換APIを提供し、すべてのコアS3機能をサポートしています。提案されたプロジェクトでは、MinIOはシングルサーバーとシングルドライブまたはストレージボリュームで構成されるスタンドアロンモードでLinux上でDocker Composeを使用しています。拡張開発や本番環境の場合、記事Deploy MinIO in Distributed Modeで説明されている分散モードのオプションがあります。
詳細な説明はこちらおよびこちらで確認できますが、いくつかのストレージ代替案について簡単に見てみましょう。
- ローカル/分散ファイルストレージ:ローカルファイルストレージは、最初の記事で実装されたソリューションであり、最も単純なオプションです。計算とストレージは同じシステム上に存在します。PoC(概念実証)の段階や、単一バージョンのモデルをサポートする非常に単純なモデルに対しては許容されます。ローカルファイルシステムは、ストレージ容量が限られており、トレーニングデータセットのような追加のメタデータを保存したい場合には大きなデータセットには向いていません。レプリケーションやオートスケーリングがないため、ローカルファイルシステムは可用性、信頼性、スケーラビリティの面で機能できません。水平スケーリングのためにデプロイされる各サービスは、モデルの独自のコピーを持っています。さらに、ローカルストレージはホストシステムと同じくらい安全です。ローカルファイルストレージの代替案には、NAS(ネットワーク接続ストレージ)、SAN(ストレージエリアネットワーク)、分散ファイルシステム(Hadoop Distributed File System (HDFS)、Google File System (GFS)、Amazon Elastic File System (EFS)、Azure Files)があります。ローカルファイルシステムに比べて、これらのソリューションは可用性、スケーラビリティ、回復力を特徴としていますが、複雑性の増加に伴うコストがかかります。
- リレーショナルデータベース:モデルのバイナリシリアル化により、リレーショナルデータベースはモデルをテーブル列内のblobまたはバイナリストレージとして保存するオプションを提供します。ソフトウェア開発者や多くのデータサイエンティストはリレーショナルデータベースに精通しており、そのソリューションは直感的です。モデルのバージョンは追加のメタデータとともに別々のテーブル行として保存され、データベースから読み取りやすくなっています。一方で、データベースはより多くのストレージスペースを必要とし、これはバックアップに影響を与えます。データベース内の大量のバイナリデータは、パフォーマンスにも影響を与える可能性があります。さらに、リレーショナルデータベースはデータ構造に対する制約を課し、CSVファイル、画像、JSONファイルなどのヘテロジニアスデータをモデルメタデータとして保存することを複雑にする場合があります。
- オブジェクトストレージ: オブジェクトストレージはかなり前から存在していましたが、Amazonが2006年にSimple Storage Service (S3)で最初のAWSサービスとしてそれを革新したときに大きく変わりました。現代のオブジェクトストレージはクラウドに原生であり、他のクラウドもすぐに市場にサービスを提供しました。MicrosoftはAzure Blob Storageを提供し、GoogleはGoogle Cloud Storageサービスを提供しています。S3 APIは、クラウド内のストレージと対話するための開発者の実質的な標準であり、パブリッククラウド、プライベートクラウド、およびプライベートオンプレミスソリューション用のS3互換ストレージを提供する複数の企業があります。オブジェクトストアがどこにあるかに関係なく、RESTfulインターフェイスを介してアクセスされます。オブジェクトストレージはディレクトリ、フォルダ、その他の複雑な階層的な組織の必要性を排除しますが、常に変化する動的データには適していません。オブジェクトを変更するには、オブジェクト全体を書き換える必要がありますが、シリアル化されたモデルとモデルのメタデータを保存するための良い選択です。
A summary of the main benefits of object storage are:
- 巨大なスケーラビリティ: オブジェクトストレージのサイズは本質的に無制限であるため、新しいデバイスを追加するだけでデータはエクサバイトにスケールできます。オブジェクトストレージソリューションは、分散クラスタとして実行するときに最良のパフォーマンスを発揮します。
- 複雑性の低減: データはフラットな構造で保存されます。複雑な木やパーティション(フォルダやディレクトリなし)の欠如により、正確な場所を知る必要がないため、ファイルの取得が容易になります。
- 検索可能性: メタデータはオブジェクトの一部であり、別のアプリケーションを必要とせずに検索してナビゲートするのが容易です。コンシューマ、コスト、自動削除、保持、階層化に関するポリシーなど、オブジェクトに属性と情報をタグ付けすることができます。基盤となるストレージのフラットなアドレス空間(各オブジェクトが1つのバケットにのみ存在し、バケット内にバケットがない)のため、オブジェクトストアは数十億のオブジェクトの中からオブジェクトを迅速に見つけることができます。
- 回復力: オブジェクトストレージは自動的にデータを複製し、複数のデバイスや地理的位置に分散して保存することができます。これにより、障害に対する保護、データ損失からの保護、そして災害復旧戦略のサポートに役立ちます。
- シンプルさ: モデルの保存と取得にREST APIを使用することは、ほとんど学習曲線がありませんし、マイクロサービスベースのアーキテクチャへの統合を自然な選択にします。
VARモデルをサービスとして実装し、MinIOとの統合を見る時期です。提示されたソリューションの展開は、DockerおよびDocker Composeを使用することで簡略化されます。全体のプロジェクトの構成は以下の通りです。

最初の記事と同様に、モデルの準備はいくつかのステップで構成されており、これらのステップはvar_model.pyというPythonスクリプトに記述されています。このスクリプトは、専用のGitHubリポジトリに配置されています。
- データの読み込み
- トレーニング用とテスト用のデータセットにデータを分割する
- 内因性変数の準備
- 最適なモデルパラメータp(各変数の最初のp遅れを回帰予測子として使用)を見つける
- 特定された最適パラメータでモデルをインスタンス化する
- インスタンス化されたモデルをpickleファイルにシリアル化する
- pickleファイルをMinIOバケット内のバージョン管理されたオブジェクトとして保存する
これらのステップは、より新しいデータで新しいモデルバージョンをトレーニングする必要があることによってトリガーされるワークフローエンジン(例えばApache Airflow)のタスクとして実装することもできます。DAG(Directed Acyclic Graphs)とMLOpsにおけるその応用については、別の記事で取り上げます。
var_model.pyで実装された最後のステップは、シリアル化されたpickleファイルモデルをS3内のバケットに保存することです。オブジェクトストレージの平坦な構造のため、選択された形式は:
<バケット名>/<ファイル名>です。
しかし、ファイル名に関しては、階層構造を模倣するために前方スラッシュを使用でき、高速な線形検索の利点を保ちます。VARモデルを保存するための規約は以下の通りです:
models/var/0_0_1/model.pkl
ここで、バケット名はmodels、ファイル名はvar/0_0_1/model.pklであり、MinIO UIでは以下のように表示されます:

これは、様々なタイプのモデルやモデルバージョンを構造化する非常に便利な方法でありながら、フラットファイルストレージのパフォーマンスとシンプルさを維持しています。
モデルのバージョン管理はモデル名の一部として実装されていることに注意してください。MinIOはファイルのバージョニングも提供しますが、ここで選択されたアプローチにはいくつかの利点があります:
- スナップショットバージョンとオーバーライドのサポート
- セマンティックバージョニングの使用(制限によりドットが’_’に置き換えられている)
- バージョニング戦略のより大きな制御
- 特定のバージョニング機能に関する基盤となるストレージメカニズムの分離
モデルがデプロイされたら、Flaskを使用してRESTサービスとして公開し、MinIOとApache Webサーバーを実行するdocker-composeを使用してデプロイする時です。Dockerイメージおよびモデルコードは、専用のGitHubリポジトリで見つけることができます。
そして最後に、アプリケーションを実行するために必要な手順は次の通りです:
- アプリケーションのデプロイ:
docker-compose up -d - モデル準備アルゴリズムを実行:
python var_model.py(MinIOサービスが稼働中である必要があります) - モデルがデプロイされているか確認: http://127.0.0.1:9101/browser
- モデルをテスト:
http://127.0.0.1:80/apidocs
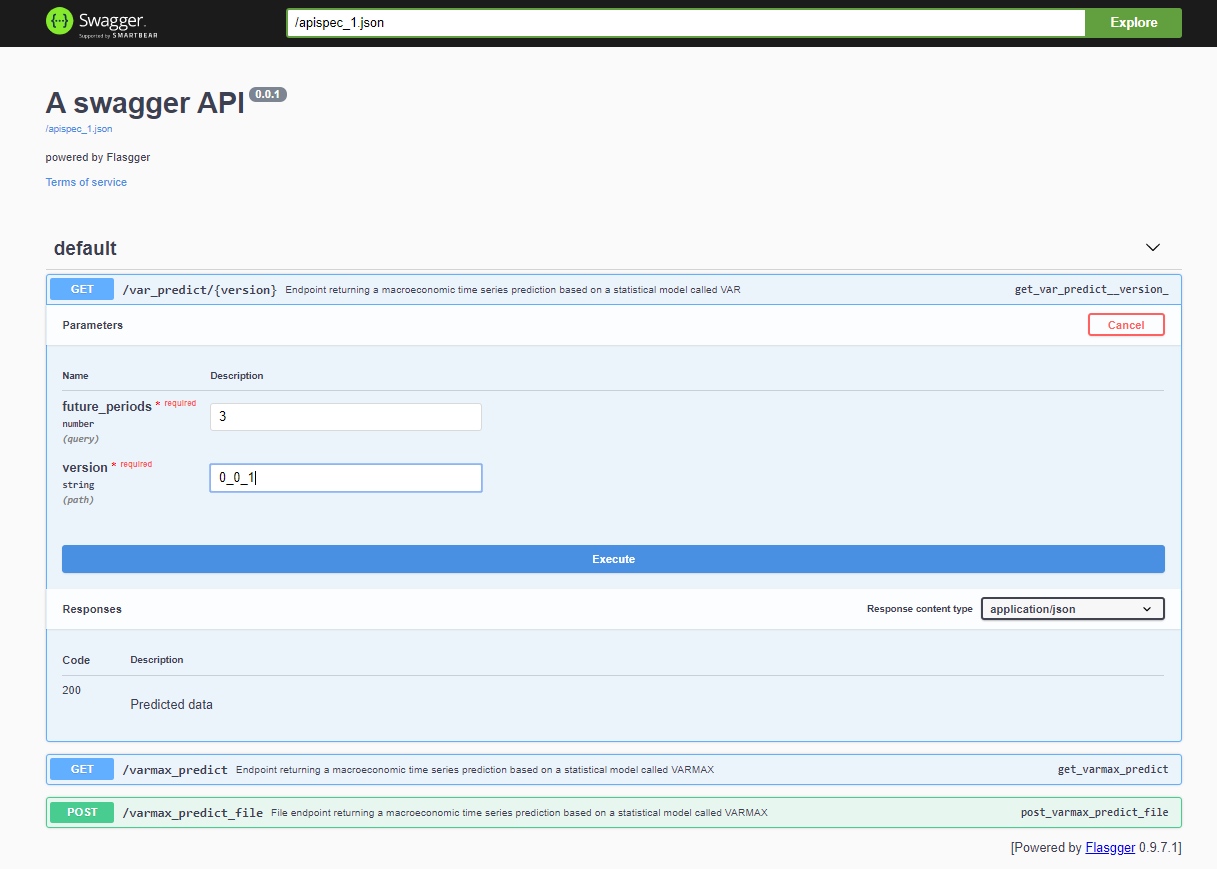
プロジェクトをデプロイした後、Swagger APIは<host>:<port>/apidocs (例: 127.0.0.1:80/apidocs) 経由でアクセス可能です。VARモデルのエンドポイントが他の2つの隣に表示され、VARMAXモデルを公開しています:
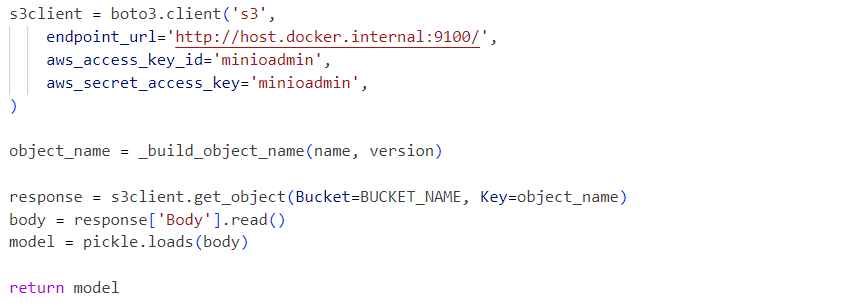
内部では、サービスはMinIOサービスからロードされたデシリアライズされたモデルピッキルファイルを使用します:
リクエストは以下のように初期化されたモデルに送られます:

提示されたプロジェクトは、標準的なVARモデルワークフローであり、次のような追加機能で段階的に拡張できます:
- 標準的なシリアル化フォーマットを探索し、ピッキルを代替ソリューションに置き換える
- KibanaやApache Supersetなどの時系列データ可視化ツールを統合する
- Prometheus、TimescaleDB、InfluxDB、またはS3のようなオブジェクトストレージなどの時系列データベースに時系列データを保存する
- データ読み込みとデータ前処理ステップを含むパイプラインを拡張する
- パイプラインの一部としてメトリックレポートを組み込む
- Apache AirflowやAWS Step Functions、またはGitlabやGitHubなどの標準ツールを使用してパイプラインを実装する
- 統計モデルのパフォーマンスと精度を機械学習モデルと比較する
- Infrastructure-As-Codeを含むエンドツーエンドのクラウド統合ソリューションを実装する
- 他の統計およびMLモデルをサービスとして公開する
- 実際のストレージメカニズムとモデルのバージョニングを抽象化し、モデルのメタデータとトレーニングデータを格納するモデルストレージAPIを実装する
これらの将来の改善点は、今後の記事やプロジェクトの焦点となります。この記事の目的は、S3互換のストレージAPIを統合し、バージョン管理されたモデルのストレージを可能にすることです。その機能は近日中に別のライブラリに抽出されます。提示されたエンドツーエンドのインフラストラクチャソリューションは、プロダクションにデプロイされ、CI/CDプロセスの一部として時間の経過とともに改善されることができ、またMinIOの分散デプロイオプションを使用するか、AWS S3で置き換えることもできます。
Source:
https://dzone.com/articles/time-series-analysis-var-model-as-a-service