













Amazon Simple Storage Service (S3)は、Amazon Web Services (AWS)によって提供される高度にスケーラブルで耐久性が高く、安全なオブジェクトストレージサービスです。S3を使用することで、企業はウェブ上のどこからでも、どれだけの量のデータでも保存して取得できます。S3は、高度に相互運用可能であり、他のAmazon Web Services (AWS)やサードパーティのツールやテクノロジとシームレスに統合され、Amazon S3に保存されたデータを処理します。その一つがAmazon EMR (Elastic MapReduce)で、Sparkなどのオープンソースツールを使用して大量のデータを処理できます。
Apache Sparkは、大規模データ処理に使用されるオープンソースの分散コンピューティングシステムです。Sparkは速度を実現することを目的として構築されており、Amazon S3を含む様々なデータソースをサポートしています。Sparkは、大量のデータを効率的に処理し、最小限の時間で複雑な計算を実行する方法を提供します。
Memphis.devは、従来のメッセージブローカーに代わる次世代のオプションです。シンプルで堅牢で耐久性の高いクラウドネイティブメッセージブローカーで、コスト効果の高く、迅速で信頼性の高いモダンなキューベースのユースケースの開発を可能にする包括的なエコシステムが組み込まれています。
メッセージブローカーの一般的なパターンは、定義されたリテンションポリシー(時間/サイズ/メッセージ数など)を超えるとメッセージを削除することです。Memphisは、保存されたメッセージの長期、おそらく無期限のリテンションを可能にする2番目のストレージ層を提供します。エステーションから排出された各メッセージは自動的に2番目のストレージ層に移行します。この場合、それはAWS S3です。
このチュートリアルでは、AWS S3に接続された2つ目のストレージクラスを備えたメンフィスステーションの設定手順を案内します。その後、S3バケットの作成、EMRクラスタの設定、クラスタにApache Sparkのインストールと設定、S3でのデータ準備、Apache Sparkでのデータ処理、ベストプラクティス、パフォーマンスチューニングを行います。
環境の設定
メンフィス
- 始めるために、まずインストールメンフィスを行います。
- メンフィスのインテグレーションセンター経由でAWS S3の統合を有効にします。
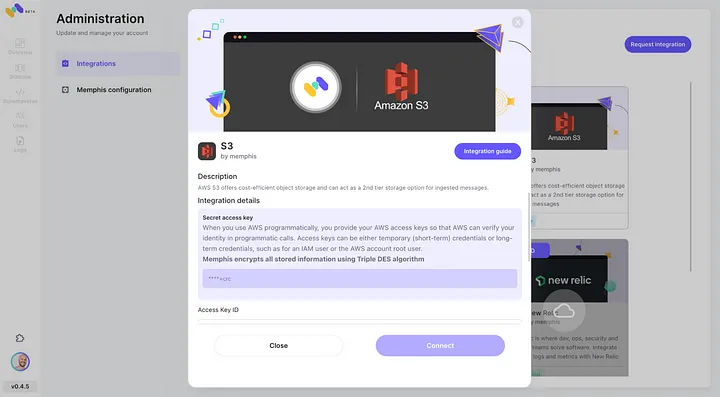
3. ステーション(トピック)を作成し、リテンションポリシーを選択します。
4. 設定されたリテンションポリシーを通過する各メッセージは、S3バケットにオフロードされます。
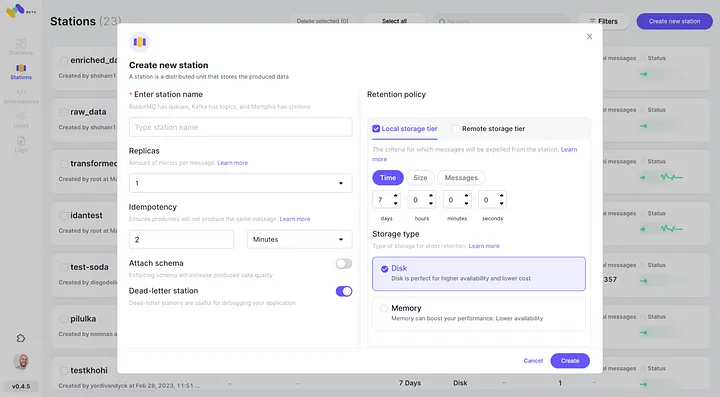
5. 「Connect」をクリックして新しく設定されたAWS S3統合を2つ目のストレージクラスとして確認します。
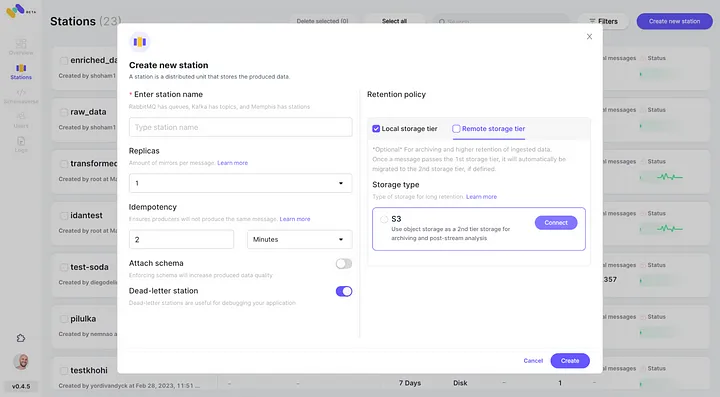
6. 新しく作成したメンフィスステーションにイベントを生成し始めます。
AWS S3バケットの作成
既に行っていない場合は、まず、AWS アカウントを作成する必要があります。次に、データを保存できるS3バケットを作成します。AWS管理コンソール、AWS CLI、またはSDKを使用してバケットを作成できます。このチュートリアルでは、AWS管理コンソール
を使用します。「バケットを作成」をクリックします。
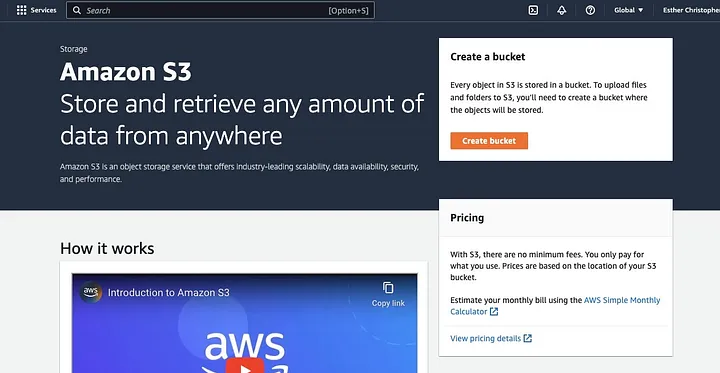
次に、命名規則に従ったバケット名を作成し、バケットを配置したいリージョンを選択します。「オブジェクト所有権」と「すべての公開アクセスをブロック」を使用ケースに合わせて設定します。
Sparkアプリケーションがデータにアクセスできるように、他のバケットの権限も設定することを確認してください。最後に、「バケットを作成」ボタンをクリックしてバケットを作成します。
SparkがインストールされたEMRクラスターの設定
Amazon Elastic MapReduce (EMR)は、Apache HadoopをベースにしたWebサービスであり、Apache Sparkを含むビッグデータ技術を使用して膨大な量のデータをコスト効果よく処理できます。SparkがインストールされたEMRクラスターを作成するには、EMRコンソールを開き、ページの左側にある「EMR on EC2」の下の「Clusters」を選択します。
「クラスターを作成」をクリックし、クラスターにわかりやすい名前を付けます。「アプリケーションバンドル」の下でSparkを選択してクラスターにインストールします。
「クラスタログ」セクションまでスクロールし、「クラスタ固有のログをAmazon S3に公開する」のチェックボックスを選択します。
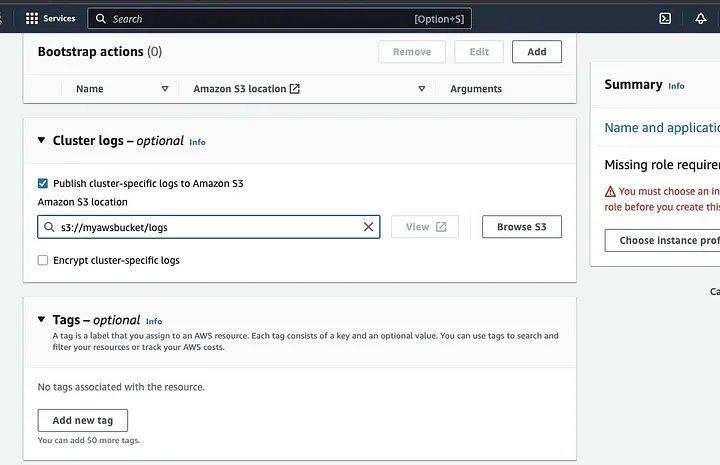
これにより、前のステップで作成したS3バケット名を使用してAmazon S3の場所を入力するプロンプトが表示されます。/logs、つまりs3://myawsbucket/logsです。Amazonは、クラスタのログファイルをコピーできるように、バケット内に新しいフォルダを作成するために/logsを必須としています。
「セキュリティ構成とアクセス許可」セクションに移動し、EC2キーペアを入力するか、新規作成オプションを選択してください。
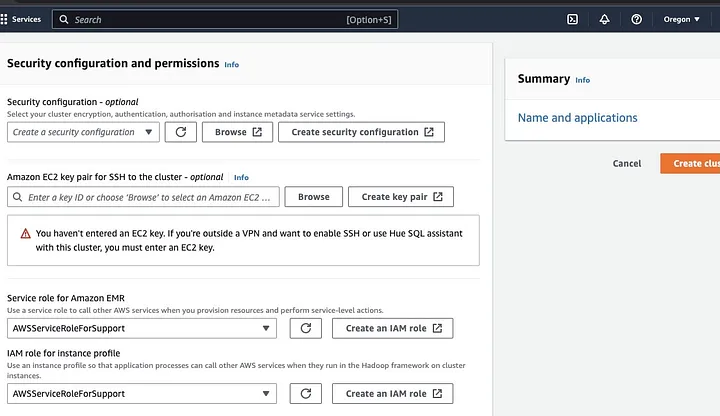
次に、「Amazon EMRのサービスロール」のドロップダウンオプションをクリックし、AWSServiceRoleForSupportを選択します。「インスタンスプロファイルのIAMロール」に対しても同じドロップダウンオプションを選択します。必要に応じてアイコンを更新して、これらのドロップダウンオプションを取得してください。
最後に、「クラスタを作成」ボタンをクリックしてクラスタを起動し、クラスタのステータスを監視して作成が確認されるまで待ちます。
EMRクラスタでのApache Sparkのインストールと設定
EMRクラスタの作成に成功した後、次のステップはEMRクラスタでApache Sparkを設定することです。EMRクラスタは、AWSインフラストラクチャでSparkアプリケーションを実行するためのマネージド環境を提供し、クラウドでSparkクラスタを起動および管理することを簡単にします。その後、データと処理要件に合わせてSparkを構成し、クラスタにSparkジョブを送信してデータを処理します。
Apache SparkをSecure Shell (SSH)プロトコルでクラスタに構成できます。ただし、最初に、EMRクラスタを作成した際にデフォルトで設定されたクラスタへのSSHセキュリティ接続を承認する必要があります。SSH接続の承認方法に関するガイドはこちらで見つけることができます。
SSH接続を作成するには、クラスタを作成した際に選択したEC2キーペアを指定する必要があります。そして、Sparkシェルを使用してEMRクラスタに接続するには、最初にプライマリノードに接続する必要があります。プライマリノードのマスター公開DNSを取得するために、AWSコンソールの左側にあるEMR on EC2の下をクリックし、クラスタを選択して公開DNS名を取得します。
OSのターミナルで以下のコマンドを入力してください。
ssh hadoop@ec2-###-##-##-###.compute-1.amazonaws.com -i ~/mykeypair.pemec2-###-##-##-###.compute-1.amazonaws.comをマスター公開DNSの名前に置き換え、~/mykeypair.pemを.pemファイルのファイル名とパスに置き換えてください(.pemファイルを取得するためのガイドに従ってください)。プロンプトメッセージが表示され、その応答はyesであるべきです—SSHコマンドを閉じるにはexitと入力します。
Sparkで処理するデータの準備とS3バケットへのアップロード
データ処理を行う前に、Sparkが容易に処理できる形式でデータを提示するための準備が必要です。使用する形式は、持っているデータの種類と実行する分析に影響されます。使用される形式には、CSV、JSON、Parquetなどがあります。
新しいSparkセッションを作成し、関連するAPIを使用してデータをSparkに読み込みます。例えば、spark.read.csv()メソッドを使用してCSVファイルをSpark DataFrameに読み込むことができます。
データを処理するためには、Hadoopエコシステムのクラスタを管理するAmazon EMRというサービスを使用できます。クラスタのセットアップ、チューニング、メンテナンスの必要性を軽減し、Amazon SageMakerなどとの他の統合も備えています。例えば、Amazon EMRのSparkパイプラインからSageMakerモデルトレーニングジョブを開始することができます。
データが準備できたら、DataFrame.write.format("s3")メソッドを使用して、Amazon S3バケットからCSVファイルをSpark DataFrameに読み込むことができます。AWS資格情報を構成し、S3バケットへの書き込み権限があることが必要です。
保存したいS3バケットとパスを指定します。例えば、df.write.format("s3").save("s3://my-bucket/path/to/data")メソッドを使用して、指定したS3バケットにデータを保存できます。
データがS3バケットに保存されると、他のSparkアプリケーションやツールからアクセスしたり、さらに分析や処理のためにダウンロードしたりできます。バケットをアップロードするには、最初に作成したバケットを選択してフォルダを作成します。アクションボタンを選択し、ドロップダウン項目で「フォルダを作成」をクリックします。新しいフォルダに名前を付けることができます。
バケットにデータファイルをアップロードするために、データフォルダの名前を選択してください。
「アップロード」―「ファイルウィザード」を選択し、「ファイルを追加」を選択します。
Amazon S3コンソールの指示に従ってファイルをアップロードし、「アップロード開始」を選択します。
S3バケットにデータをアップロードする前に、データのセキュリティを最善に考慮し確保することが重要です。
データフォーマットとスキーマの理解
データフォーマットとスキーマは、データ管理において関連するが完全に異なる重要な概念です。データフォーマットは、データベース内のデータの構造と構成を指します。CSV、JSON、XML、YAMLなど、データを保存するためのさまざまなフォーマットがあります。これらのフォーマットは、データの構造と共に、それに適用可能なさまざまな種類のデータやアプリケーションを定義します。一方、データスキーマはデータベース自体の構造です。これは、データベースのレイアウトを定義し、データが適切に保存されることを保証します。データベーススキーマは、ビュー、テーブル、インデックス、タイプ、その他の要素を指定します。これらの概念は、分析やデータベースの可視化において重要です。
S3でのデータのクリーニングと前処理
データを処理する前にエラーをダブルチェックすることが重要です。始めに、S3バケットに保存したデータファイルがあるデータフォルダにアクセスし、ローカルマシンにダウンロードします。次に、データをクリーニングおよび前処理するために使用するデータ処理ツールにデータをロードします。このチュートリアルでは、前処理ツールとしてAmazon Athenaを使用しています。これは、Amazon S3に保存された構造化および非構造化データを分析するのに役立ちます。
AWSコンソールのAmazon Athenaにアクセスします。
「Create」をクリックして新しいテーブルを作成し、「CREATE TABLE」を選択します。
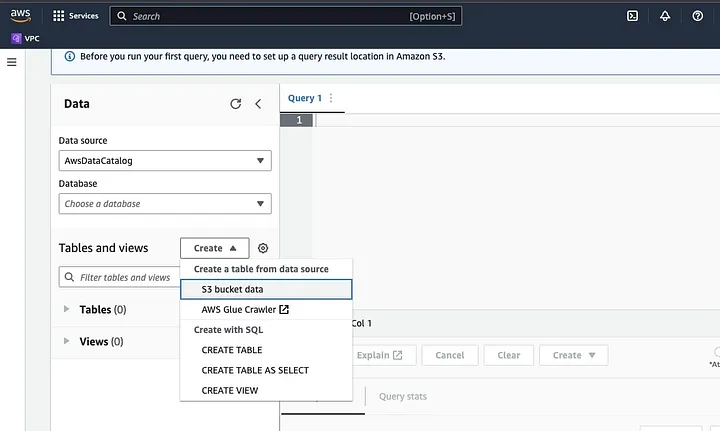
LOCATIONとしてハイライトされた部分にデータファイルのパスを入力します。
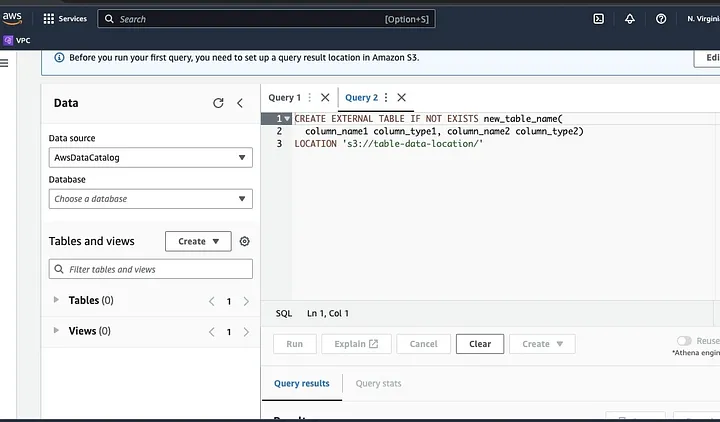
プロンプトに従ってデータのスキーマを定義し、テーブルを保存します。その後、データが正しく読み込まれていることを確認するためにクエリを実行し、データをクリーンアップして前処理を行います。
例:
このクエリはデータ内の重複を識別します。
SELECT row1, row2, COUNT(*)
FROM table
GROUP row, row2
HAVING COUNT(*) > 1;この例は重複なしで新しいテーブルを作成します。
CREATE TABLE new_table AS
SELECT DISTINCT *
FROM table;最後に、クリーンアップされたデータをS3にエクスポートするには、S3バケットとアップロードするフォルダーに移動します。
Sparkフレームワークの理解
Sparkフレームワークは、オープンソースでシンプルかつ表現力豊かなクラスタ計算システムで、迅速な開発のために構築されています。Javaプログラミング言語に基づいており、他のJavaフレームワークの代替手段として機能します。Sparkの中心的な特徴は、大規模データセットの処理を高速化するインメモリデータ計算能力です。
SparkをS3で動作させるための設定
SparkをS3で動作させるためには、最初にSparkアプリケーションにHadoop AWS依存関係を追加します。これを行うには、ビルドファイル(Scalaの場合はbuild.sbt、Javaの場合はpom.xmlなど)に次の行を追加します:
libraryDependencies += "org.apache.hadoop" % "hadoop-aws" % "3.3.1"SparkアプリケーションでAWSアクセスキーIDと秘密アクセスキーを入力するには、次の設定プロパティを設定します:
spark.hadoop.fs.s3a.access.key <ACCESS_KEY_ID>
spark.hadoop.fs.s3a.secret.key <SECRET_ACCESS_KEY>コード内のSparkConfオブジェクトを使用して次のプロパティを設定します:
val conf = new SparkConf()
.set("spark.hadoop.fs.s3a.access.key", "<ACCESS_KEY_ID>")
.set("spark.hadoop.fs.s3a.secret.key", "<SECRET_ACCESS_KEY>")SparkアプリケーションでS3エンドポイントURLを設定するには、以下の設定プロパティを設定します:
spark.hadoop.fs.s3a.endpoint s3.<REGION>.amazonaws.com
<REGION>を、S3バケットが存在するAWSリージョンに置き換えてください(例: us-east-1)。
Hadoop内のS3クライアントにS3リクエストへのアクセスを許可するために、DNS互換のバケット名が必要です。バケット名にドットやアンダースコアが含まれている場合、HadoopのS3クライアントがバーチャルホストスタイルを使用するため、パススタイルアクセスを有効にする必要があります。以下の設定プロパティを設定してパスアクセスを有効にしてください:
spark.hadoop.fs.s3a.path.style.access true
最後に、S3設定を使用してSparkセッションを作成するには、Spark設定内でspark.hadoopプレフィックスを設定します:
val spark = SparkSession.builder()
.appName("MyApp")
.config("spark.hadoop.fs.s3a.access.key", "<ACCESS_KEY_ID>")
.config("spark.hadoop.fs.s3a.secret.key", "<SECRET_ACCESS_KEY>")
.config("spark.hadoop.fs.s3a.endpoint", "s3.<REGION>.amazonaws.com")
.getOrCreate()
<ACCESS_KEY_ID>、<SECRET_ACCESS_KEY>、および<REGION>を、AWS資格情報とS3リージョンで置き換えてください。
SparkからS3のデータを読み込むには、spark.readメソッドを使用し、入力ソースとしてS3上のデータのパスを指定します。
SparkでDataFrameにS3からCSVファイルを読み込む方法を示すサンプルコード:
val spark = SparkSession.builder()
.appName("ReadDataFromS3")
.getOrCreate()
val df = spark.read
.option("header", "true") // Specify whether the first line is the header or not
.option("inferSchema", "true") // Infer the schema automatically
.csv("s3a://<BUCKET_NAME>/<FILE_PATH>")
この例では、<BUCKET_NAME>をS3バケットの名前に、<FILE_PATH>をバケット内のCSVファイルのパスに置き換えてください。
Sparkでのデータ変換
Sparkでのデータ変換は、データをクリーンアップ、フィルタリング、集計、結合するための操作を指します。Sparkはデータ変換のための包括的なAPIセットを提供しており、それにはDataFrame、Dataset、RDD APIが含まれます。Sparkで一般的なデータ変換操作には、フィルタリング、列の選択、データの集計、データの結合、データのソートがあります。
データ変換操作の一例を示します。
データのソート:この操作では、1つ以上の列を基準にデータをソートします。DataFrameやDatasetのorderByまたはsortメソッドを使用して、1つ以上の列を基準にデータをソートします。例:
val sortedData = df.orderBy(col("age").desc)最後に、結果をS3に書き戻して保存する必要がある場合があります。
SparkはDataFrameWriter、DatasetWriter、RDD.saveAsTextFileなど、S3にデータを書き込むためのさまざまなAPIを提供しています。
次のコード例は、DataFrameをS3のParquet形式で書き込む方法を示しています。
val outputS3Path = "s3a://<BUCKET_NAME>/<OUTPUT_DIRECTORY>"
df.write
.mode(SaveMode.Overwrite)
.option("compression", "snappy")
.parquet(outputS3Path)入力フィールド<BUCKET_NAME>をS3バケットの名前に、<OUTPUT_DIRECTORY>をバケット内の出力ディレクトリのパスに置き換えてください。
modeメソッドは書き込みモードを指定し、Overwrite、Append、Ignore、ErrorIfExistsのいずれかになります。optionメソッドを使用して、出力形式のさまざまなオプションを指定できます。例えば、圧縮コーデックなどです。
CSV、JSON、Avroなど、他の形式でS3にデータを書き込むこともできます。出力形式を変更し、適切なオプションを指定するだけです。
スパークにおけるデータパーティショニングの理解
簡単に言えば、スパークにおけるデータパーティショニングとは、データセットをクラスタ全体にわたってより小さく、管理しやすい部分に分割することを指します。これはパフォーマンスを最適化し、スケーラビリティを低減し、最終的にデータベースの管理性を向上させることを目的としています。スパークでは、複数のクラスタでデータが並列に処理されます。これは、巨大で複雑なデータのコレクションであるレジリアントディストリビューテッドデータセット(RDD)によって可能になります。デフォルトでは、RDDはそのサイズのために複数のノードに分割されます。
最適に機能するために、ジョブが迅速に実行され、リソースが効果的に管理されるようにスパークを構成する方法があります。これらには、キャッシング、メモリ管理、データシリアル化、そしてmapPartitions()をmap()よりも使用することが含まれます。
スパークUIは、スパークアプリケーションのパフォーマンスとリソース使用量に関する包括的な情報を提供するウェブベースのグラフィカルユーザインターフェースです。概要、エグゼキュータ、ステージ、タスクなど、スパークジョブのさまざまな側面に関する情報を提供するいくつかのページが含まれています。スパークUIは、パフォーマンスのボトルネックやリソースの制約、エラーのトラブルシューティングを特定するのに役立つため、スパークアプリケーションの監視とデバッグに不可欠なツールです。タスクの完了数、ジョブの所要時間、CPUおよびメモリ使用量、シャッフルデータの読み書きなどのメトリクスを調べることで、ユーザーはスパークジョブを最適化し、効率的に実行されるように保証できます。
結論
要約すると、AWS S3上でApache Sparkを使用してデータを処理することは、巨大なデータセットを分析するための効果的かつスケーラブルな方法です。クラウドベースのストレージおよびコンピューティングリソースを利用することで、AWS S3とApache Sparkを使用して、アーキテクチャ管理の心配なく迅速かつ効果的にデータを処理できます。
本チュートリアルでは、S3バケットとAWS EMR上のApache Sparkクラスタの設定方法、SparkをAWS S3と連携させるための設定、そしてデータ処理のためのSparkアプリケーションの作成と実行について説明しました。また、Spark内のデータパーティション分割、Spark UI、およびSparkのパフォーマンス最適化についても触れました。
参考資料
Sparkを最適なパフォーマンスで動作させるための設定に関してさらに詳しく知りたい方は、こちらをご覧ください。
https://docs.aws.amazon.com/emr/latest/ManagementGuide/emr-connect-master-node-ssh.html
Source:
https://dzone.com/articles/stateful-stream-processing-with-memphis-and-apache-spark