













Shift-leftは、ソフトウェア開発と運用において、テスト、監視、そして自動化をソフトウェア開発ライフサイクルの初期段階で重視するアプローチです。このアプローチの目標は、問題が発生する前にそれを早期に発見し、迅速に対処することによって問題を防ぐことです。
スケーラビリティの問題やバグを早期に特定すれば、それを解決するのがより迅速かつコスト効果的です。非効率的なコードをクラウドコンテナに移動すると、オートスケーリングが活性化され、月額請求額が増加する可能性があります。さらに、問題を特定、隔離、修正できるまで、緊急事態に陥ることになります。
問題の概要
I would like to demonstrate to you a case where we managed to avert a potential issue with an application that could have caused a major issue in a production environment.
I was reviewing the performance report of the UAT infrastructure following the recent application change. It was a Spring Boot microservice with MariaDB as the backend, running behind Apache reverse proxy and AWS application load balancer. The new feature was successfully integrated, and all UAT test cases are passed. However, I noticed the performance charts in the MariaDB performance dashboard deviated from pre-deployment patterns.
これがイベントのタイムラインです。
8月6日14:13、アプリケーションは新しいSpring Boot jarファイルを使用して再起動され、その中に組み込まれたTomcatが含まれていました。
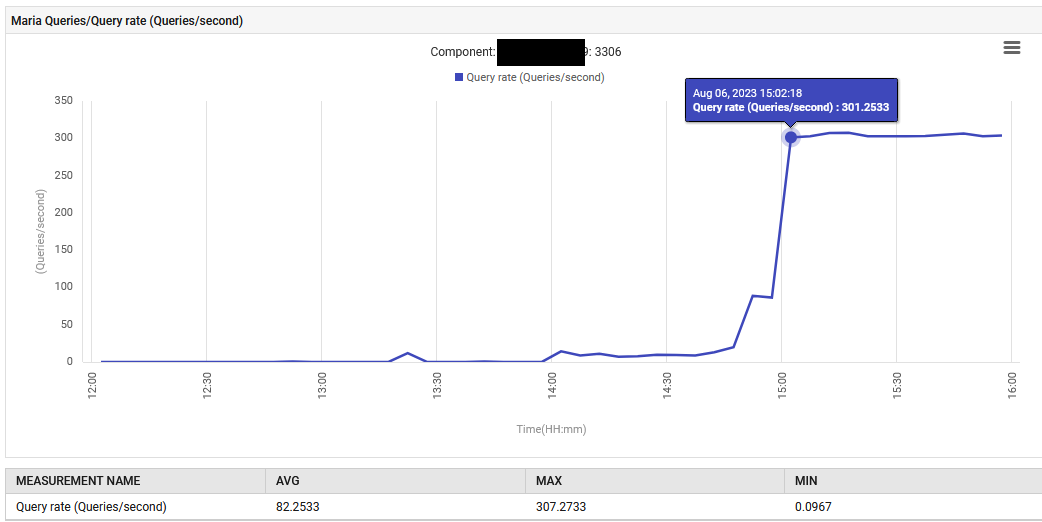
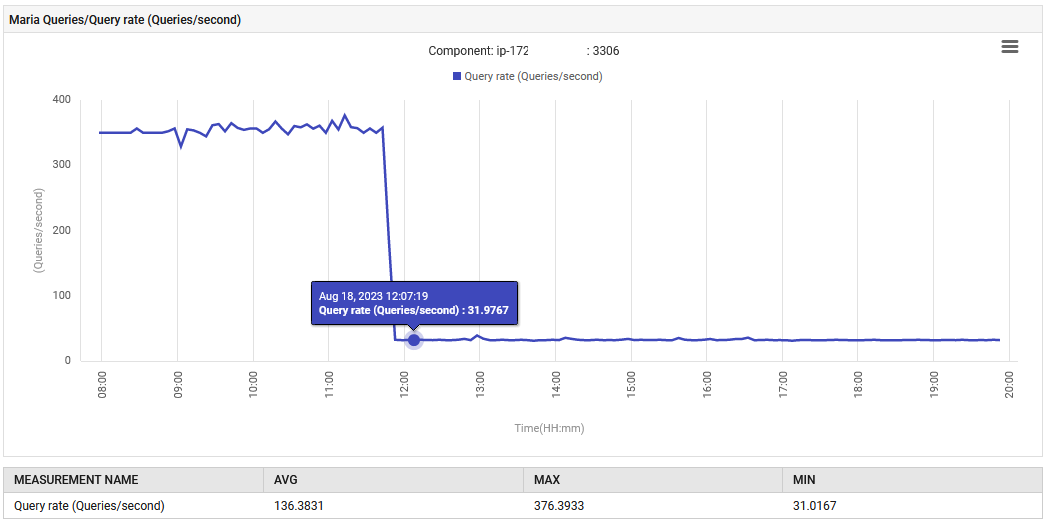
14:52に、MariaDBのクエリ処理速度が0.1から88クエリ/秒に上昇し、その後301クエリ/秒に達しました。
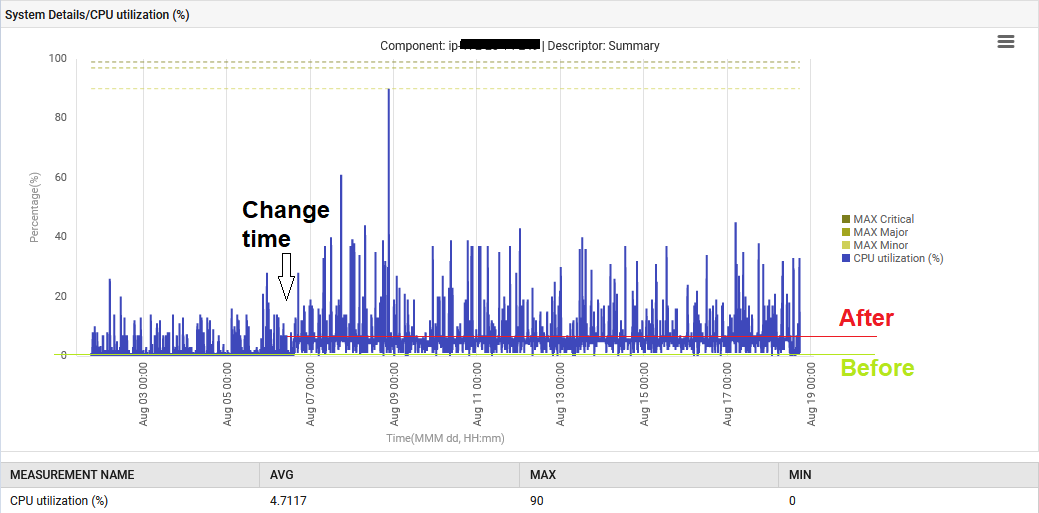
また、システムCPUは1%から6%に上昇しました。
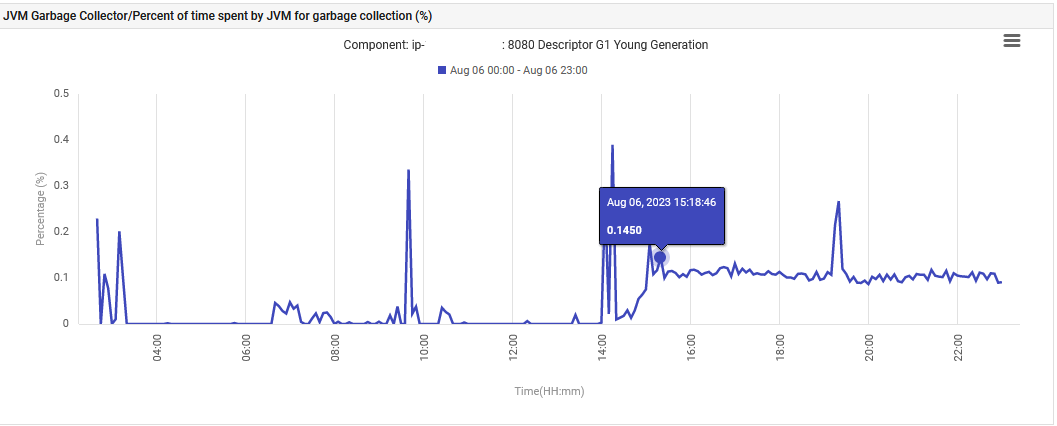
最後に、JVMがG1 Young Generation Garbage Collectionに費やす時間が0%から0.1%に増加し、そのレベルで維持されました。
アプリケーションはUATフェーズにあり、設計された仕様をはるかに超えて300クエリ/秒を異常に発行しています。新機能によりデータベース接続が増加し、そのためクエリの増加がこれほど急激になっています。しかし、モニタリングダッシュボードでは、新しいバージョンがデプロイされる前は問題のある指標が正常であったことが示されています。
解決策
これは、JPAを使用してMariaDBにクエリを実行するSpring Bootアプリケーションです。アプリケーションは最小負荷のために2つのコンテナ上で実行されるよう設計されていますが、最大10個までスケールアップすることが想定されています。
もし1つのコンテナが1秒間に300クエリを生成できるのであれば、10個すべてのコンテナが稼働している場合には1秒間に3000クエリを処理できるでしょうか?データベースは、アプリケーションの他の部分のニーズを満たすために十分な接続を持っているでしょうか?
選択肢がなかったため、Gitでの変更を調査するために開発者のテーブルに戻るしかありませんでした。
新しい変更は、テーブルから数レコードを取り出して処理するものです。これはサービスクラスで観察された内容です。
List<X> findAll = this.xRepository.findAll();
いいえ、SpringのCrudRepositoryでページネーションなしでfindAll()メソッドを使用することは効率的ではありません。ページネーションは、データベースからデータを取得する時間を短縮するために、取得するデータの量を制限することで機能します。これは私たちの主要なRDBMS教育で教えられたことです。さらに、ページネーションはアプリケーションがデータの過負荷によってクラッシュするのを防ぐために、メモリ使用量を低く保ちます。また、Java仮想マシンのガベージコレクションの努力を減らすことにもつながります。これは、上記の問題文で述べられていました。
このテストは、1つのコンテナに2,000件のレコードのみを使用して実施されました。このコードが本番環境に移行した場合、最大10個のコンテナに約20万件のレコードがあるため、その日はチームにとって多くのストレスと心配を引き起こす可能性がありました。
アプリケーションは、メソッドにWHERE句を追加することで再構築されました。
List<X> findAll = this.xRepository.findAllByY(Y);
正常な動作が回復しました。1秒あたりのクエリ数は300から30に減少し、ガベージコレクションに費やされる努力は元のレベルに戻りました。さらに、システムのCPU使用率が低下しました。
学習とまとめ
SRE (SRE) に携わる者なら誰もが、この発見の重要性を理解するでしょう。我々は、重大度1の警告を発生させることなく、それに対処することができました。この欠陥のあるパッケージが本番環境に展開されていた場合、顧客のオートスケーリングのしきい値を引き起こし、追加のユーザー負荷なしで新しいコンテナが起動する可能性がありました。
この話から三つの主要な教訓があります。
まず第一に、観測性ソリューションを最初から有効にすることが最善であり、潜在的な問題を特定するために使用できるイベントの履歴を提供することができます。この履歴がなければ、0.1%のガベージコレクション率と6%のCPU消費を重視せず、悲惨な結果を招く可能性がある生産環境へのコードリリースを行っていたかもしれません。監視ソリューションの範囲をUATサーバーに拡大することで、チームは潜在的な根本原因を特定し、問題が発生する前に防止することができました。
第二に、パフォーマンス関連のテストケースはテストプロセスに存在するべきであり、これらは観測性に精通した人によってレビューされるべきです。これにより、コードの機能だけでなく、そのパフォーマンスもテストされます。
第三に、クラウドネイティブのパフォーマンストラッキング技術は、高い利用率や可用性などに関するアラートを受信するのに良いです。観測性を達成するためには、適切なツールと専門知識が必要になることがあります。楽しいコーディングを!
Source:
https://dzone.com/articles/shift-left-monitoring-approach-for-cloud-apps-in-c