













RETRIEVAL_AUGMENTED_GENERATION (RAG)は、大規模言語モデル(LLM)における変革的な進歩を表しています。トランスフォーマーアーキテクチャの生成能力と動的な情報 retrievalを統合しています。
この統合により、LLMがテキスト生成の際に関連のある外部知識をアクセスし、取り込むことができるようになり、より正確で、コンテキストに合わせた、事実的な一貫性のある出力が得られます。
初期のルールベースシステムからBERTやGPT-3などの高度なニューラルモデルに至るまでの進化は、RAGに道を開いています。これは静的なパラメータ的な記憶の限界に対する解決策です。また、マルチモーダルRAGは、画像、音声、ビデオなど多样なデータタイプを統合することで、生成コンテンツの豊富さと関連性を增强します。
このパラダイムシフトは、LLMの出力の精度と解釈性を改善するだけでなく、さまざまな分野にわたる革新的な應用をサポートすることです。
ここでは以下を扱います。
- 第1章 RAGについてのIntroduction
– 1.1 RAGは何ですか?概要
– 1.2 RAGは複雑な問題を解決していますか? - 第2章 技術の基礎
– 2.1 ニューラルLMからRAGへの移行
– 2.2 RAGのメモリ理解:パラメトリック対ノンパラメトリック
– 2.3 マルチモーダルRAG:複数データタイプの統合 - 第3章 コアメカニズム
– 3.1 RAGにおける情報検索と生成の組み合わせの力
– 3.2 リトリーバーとジェネレーターの統合戦略 - 第4章 応用とユースケース
– 4.1 RAGの活用:QAからクリエイティブライティングまで
– 4.2 低リソース言語のためのRAG:到達範囲と能力の拡大 - 第5章. 最適化技術
– 5.1 RAGシステムの最適化に向けた高度な復号技術 - 第6章. 挑戦と革新
– 6.1 RAGに関する現在の挑戦と未来の方向性
– 6.2 RAGシステムのハードウェア加速と効率的な部署 - 第7章. 結びつきの考え方
– 7.1 RAGの未来:結論と反省
前提条件
Retrieval-Augmented Generation (RAG)など的大规模言語モデル(LLM)に焦点を当てたコンテンツを取り組むために、以下の2つの基本的前提条件が必要です。
- 機械学習の基礎: 基本的な機械学習の概念とアルゴリズムを理解することは非常に重要で、特にニューラルネットワークのアーキテクチャに適用される部分です。
- 自然言語処理(NLP):テキストの前処理、トーキンジズメント、そしてエンベディングの使用など、自然言語モデルを使うためには、NLP技術の知識が欠かせない。
第1章:RAGの紹介
取り出しを加えた生成(RAG)は、情報探求と生成型モデルの強みを組み合わせたことで、自然言語処理を革新する。RAGは動的に外部知識をアクセスし、生成されるテキストの正確性と関連性を高める。
この章では、RAGの機構、利点、そして挑戦について探る。私たちは取り出し技術、生成型モデルとの統合、そしてさまざまなアプリケーションに及ぼす影響を深く観察する。
RAGは幻想を軽減し、最新の情報を取り込み、複雑な問題を解決する。私たちはまた、効率的な取り出しと倫理的な考慮について议論する。この章は、自然言語処理におけるRAGの変革的な可能性を詳細に理解するための所存です。
1.1 RAGとは何か?概観
取り出しを加えた生成(RAG)は、自然言語処理のパラダイムを変えるもので、情報探求と生成型言語モデルの強みを徐々に統合しています。RAGシステムは、外部知識源を利用して、生成されるテキストの正確性、関連性、そして一貫性を高め、伝統的な言語モデルである纯粹なパラメーター記憶の限界を克服します。 (Lewis et al., 2020)
RAGは、生成過程の間に相手の情報を動的に取り出し、取り込むことで、質問回答や対話システムから要約や創造的書き込みまでの幅広い应用において、より文脈に根ざしたものと、事実上の一貫性を持たせた出力を可能にします。(Petroni et al., 2021)
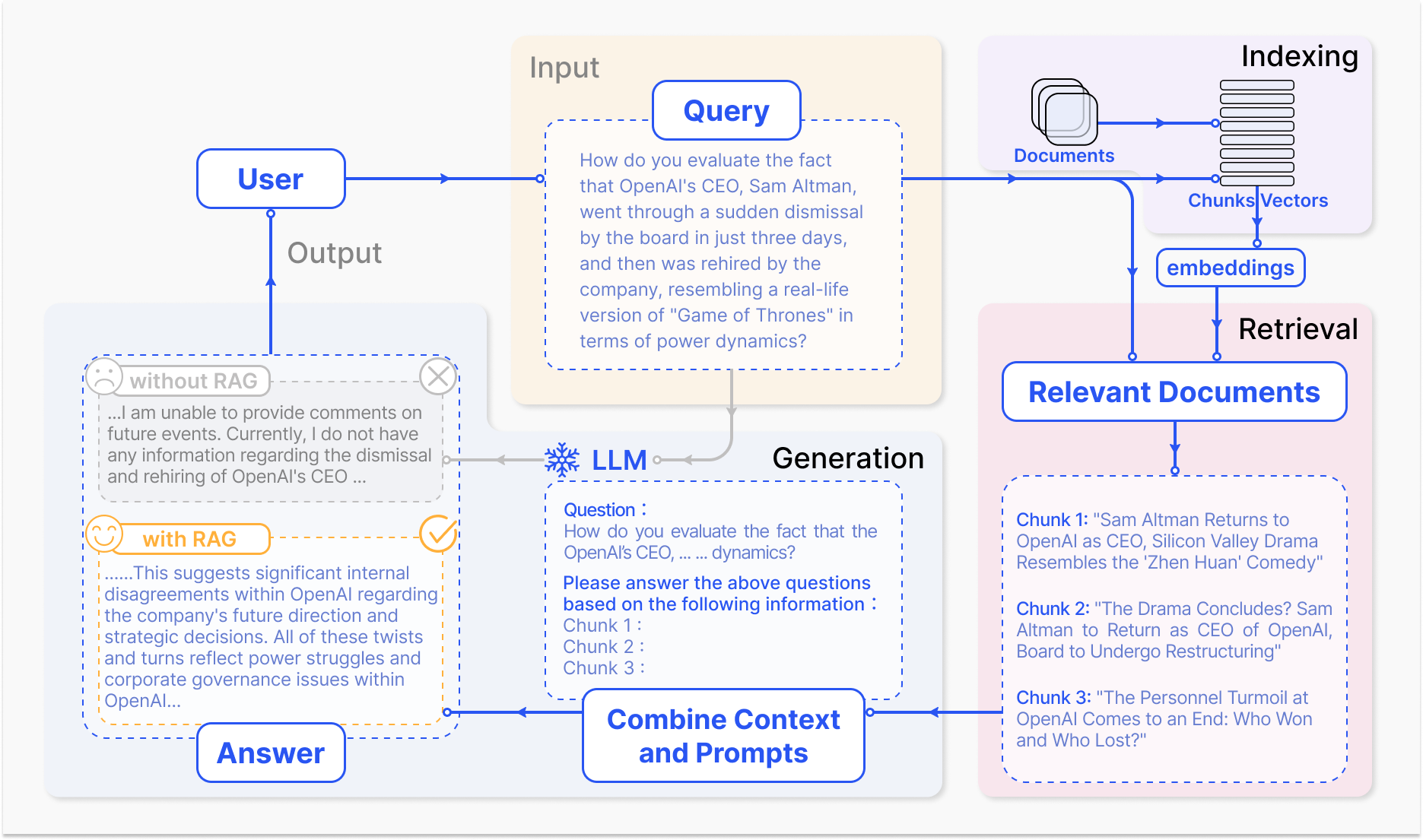
RAGシステムの动作方法 – arxiv.org
RAGの核の機構は、取得と生成の2つの主要なコンポーネントを含んでいます。
取得部分は、大きな知識ベースを効率的に探して、入力クエリまたはコンテキストに基づいて最も関連した情報を特定します。稀な取得技術や密集な取得技術といった手法が用いられており、それぞれ逆索引と単語に基づくマッチング、密集なベクトル表現と意味の類似性を利用して取得過程を最適化しています。(Karpukhin et al., 2020)
取得した情報は、生成モデルに統合されます。生成モデルは通常、GPTやT5のような大きな言語モデルであり、これは関連したコンテンツを一貫性と流暢性のある応答に変換します。(Izacard & Grave, 2021)
RAGの取り込みと生成の統合は、従来の言語モデルに比べていくつかの利点を提供します。RAGは生成したテキストを外部知識に根ざすことで、幻覚や事実上の間違いの発生率を大幅に削減します。(Shuster et al., 2021)
RAGはまた、最新の情報を取り込むことができるため、生成された応答は、特定の分野で最も新しい知識と発展を反映しています。(Lewis et al., 2020)この適応性は、医療、金融、科学研究など、情報の正確さと实时性が最も重要である分野において特に重要です。(Petroni et al., 2021)
しかしながら、RAGシステムの開発と導入は、大きな挑戦も伴います。大規模な知識ベースから効率的な取り込み、幻覚の軽減、及び多样なデータモジュラーの統合など、技術的な課題が解決する必要があります。(Izacard & Grave, 2021)
また、公平な情報の検索と生成を保証するように無偏性を確保する倫理的な考慮は、RAGシステムの責任のある展開には非常に重要です。(Bender et al., 2021)検索の正確性と生成の品質の間の相互作用を捉える包括的な評価指標とフレームワークの開発は、RAGシステムの効果性を評価するために不可欠です。(Lewis et al., 2020)
RAGの分野は進化し続けており、将来の研究の方向性は、検索プロセスの最適化、多モーダル機能の拡張、モジュール化されたアーキテクチャの開発、そして堅牢な評価フレームワークの設立に焦点を当てています。(Izacard & Grave, 2021)これらの進歩は、RAGシステムの効率性、精度,および適応性を強化し、自然言語処理におけるより知的で多様なアプリケーションへの道を開くでしょう。
以下は、LangChainとFAISSという人気のライブラリを使用したRetrieval Augmented Generation (RAG)セットアップの基本Pythonコード例です。
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.document_loaders import TextLoader
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
# 1. 文書の読み取りと埋め込み
loader = TextLoader('your_documents.txt') # ドキュメントのソースを入れ替えてください
documents = loader.load()
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(documents, embeddings)
# 2. 関連するドキュメントの取得
def retrieve_docs(query):
return vectorstore.similarity_search(query)
# 3. RAG チェーンの設定
llm = OpenAI(temperature=0.1) # 応答の創造性に応じて温度調整
chain = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=vectorstore.as_retriever())
# 4. RAG モデルの使用
def get_answer(query):
return chain.run(query)
# 例の使用法
query = "What are the key features of Company X's latest product?"
answer = get_answer(query)
print(answer)
# 会社歴の例の使用法
query = "When was Company X founded and who were the founders?"
answer = get_answer(query)
print(answer)
# 財務性能の例の使用法
query = "What were Company X's revenue and profit figures for the last quarter?"
answer = get_answer(query)
print(answer)
# 未来展望の例の使用法
query = "What are Company X's plans for expansion or new product development?"
answer = get_answer(query)
print(answer)
RAGは、取り出しと生成の力を活用して、我々が情報とのやり取りや生成を変える巨大な可能性を秘めています。これは、さまざまな分野を革命し、人間と機械の交流の未来を形成するものです。
1.2 RAGで複雑な問題を解決する方法
Retrieval-Augmented Generation (RAG)は、 traditions large language models (LLMs)が苦しんでいる複雑な問題を強力に解決します。特に、非構造化データの大量に遭遇するシーンです。
そのような問題の1つは、YouTubeビデオなどの特定のドキュメントやマルチメディアコンテントについて、事前のファインチューニングや明示的なトレーニングなしで有意な会話を行う能力です。
传统的LLM(大規模生成型モデル)は、学習時に固定的になるパラメータ付随メモリに制限されています。すなわち、(Lewis et al., 2020) 彼らは学習データを超えて新しい情報に直接アクセスしたり取り込んだりすることができず、これにより、見たことのない文書やビデオに関する知っているような讨论に参加することが困難になります。
その結果、LLMは、特定のコンテンツに関するクエリを提示されたときに、一貫性を欠く、関連性を欠く、または、事実上の間違いが生まれるレスポンスを生成する可能性があります。(Petroni et al., 2021)
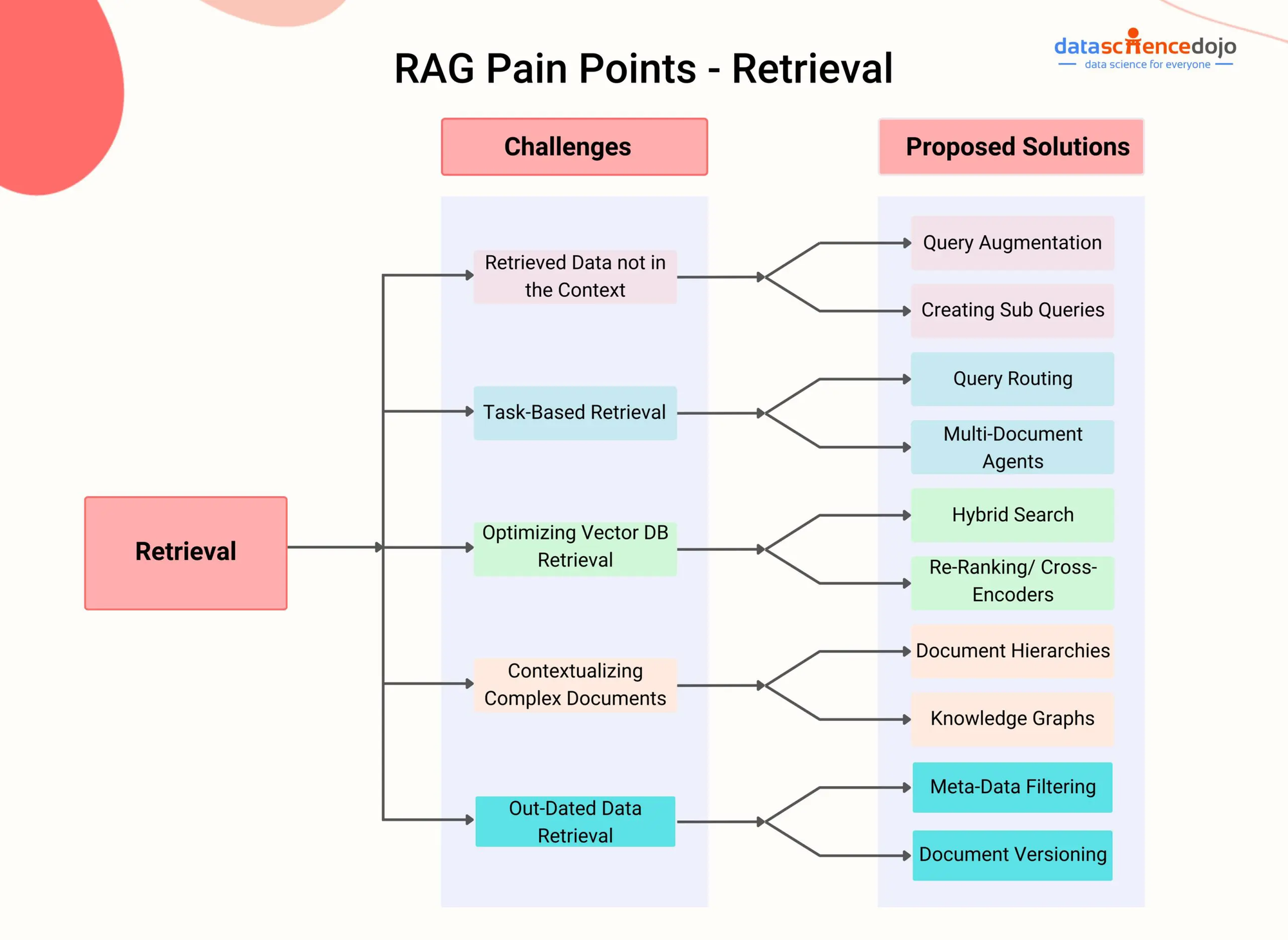
RAGの問題点 – DataScienceDojo
RAGは、生成過程において、モデルが外部知識源から Dynamicにアクセスし、関連する情報を取り込む機能を持つ復帰部分を統合しています。
高度な復帰技術を利用して、例えば密集型パス復帰(Karpukhin et al., 2020)やハイブリッドサーチ(Izacard & Grave, 2021)など、RAGシステムは、会話のコンテクストに基づいて、与えられた文書やビデオから最も関連性のあるパスやセグメントを効率よく特定することができます。
例えば、科学トピックに関するYouTube動画についての会話をすることができるように、RAGシステムが動画の音声コンテンツを変換し、その結果のテキストを密接な vectore 表現で索引化することができます。
そして、ユーザーが動画に関連した質問をしたとき、RAGシステムの取り出しコンポーネントは、クエリと索引化されたコンテンツの意味的な類似性に基づいて、最も関連性のあるパーツを迅速に识別することができます。
それぞれのパーツは、生成モデルに供給され、これはユーザーの質問に直接答えることができ、動画のコンテンツに基づいて答案を根ざすように、一貫性のある情報を生成します。(Shuster et al., 2021)
この方法は、RAGシステムが明示的な微調整なしで、幅広いドキュメントやマルチメディアコンテンツについての知識を持った会話を行えるようにすることを可能にします。RAGは動的に取り出したり、関連性のある情報を組み込んだりして、传统のLLMと比べてより正確で、文脈に関連したり、事実的な一貫性に関連した答えを生成することができます。(Lewis et al., 2020)
また、RAGは、テキスト、画像、音声などの様々なモーダリティの無構造データを処理する能力があり、異なる情報源を持つ複雑な問題に対する多用途な解決策です。(Izacard & Grave, 2021)RAGシステムが進化を続けるにつれて、異なる分野にわたる複雑な問題に取り組む可能性はより增长します。
高度な retrieval 技術とマルチモーダル統合を利用して、RAGはより知的でコンテキスト意識のある会話エージェント、個人化推奨システム、知識密集型アプリケーションを可能にします。
効率的な索引、 Cross-modal アラインメント、 retrieval-generation 統合などの研究领域で研究が進展するにつれて、RAGは言語モデルや人工知能の可能限りの境界を押し上げる重要な役割を果たすでしょう。
第2章:技術的な基礎
この章では、Multimodal Retrieval-Augmented Generation (RAG) の魅力に満ちた世界を探索します。これは、伝統的なテキストベースのモデルを超える最尖端のアプローチです。
大規模な言語モデル(LLM)として、画像、音声、ビデオなどの多様なデータモーダリティを取り込んだMultimodal RAGは、AIシステムにより豊かな情報の面を理由することができます。
これらの統合の背后の机制や、contrastive learning、 Cross-modal attentionなどが、LLMにより细やかで、コンテキストに合わせた回答を生成することを可能にする方法について探索します。
多モーダルRAGは、精度の向上や、ビジュアル質問回答などの新しい用途のサポートなど、期待される利点を持っていますが、独自の課題も提示しています。これらの課題には、大規模な多モーダルデータセットの需要、計算の複雑度の増加、及び、取得された情報に偏見がある可能性が含まれます。
私たちがこの旅立ちをすると、Multimodal RAGの変革的な可能性を発見するだけでなく、前に立ちはだかる壁について深く調査することで、この素晴らしく進化し続ける分野についてのより深い理解を開辟することになります。
2.1 Neural LMs to RAG
言語モデルの進化は、早期的なルールベースのシステムから、より洗練された統計的およびニューラルネットワークベースのモデルに徐々に進化してきました。
初期の時代では、言語モデルは手作りのルールと言語知識に基づいてテキストを生成していました。これにより柔軟で有限的な出力が生成されました。統計的モデル、例えばn-gramモデルの導入で、大規模なコーパスから学習していくパターン認識を可能にし、より自然で一貫性のある言語生成を実現しました。 (Redis)
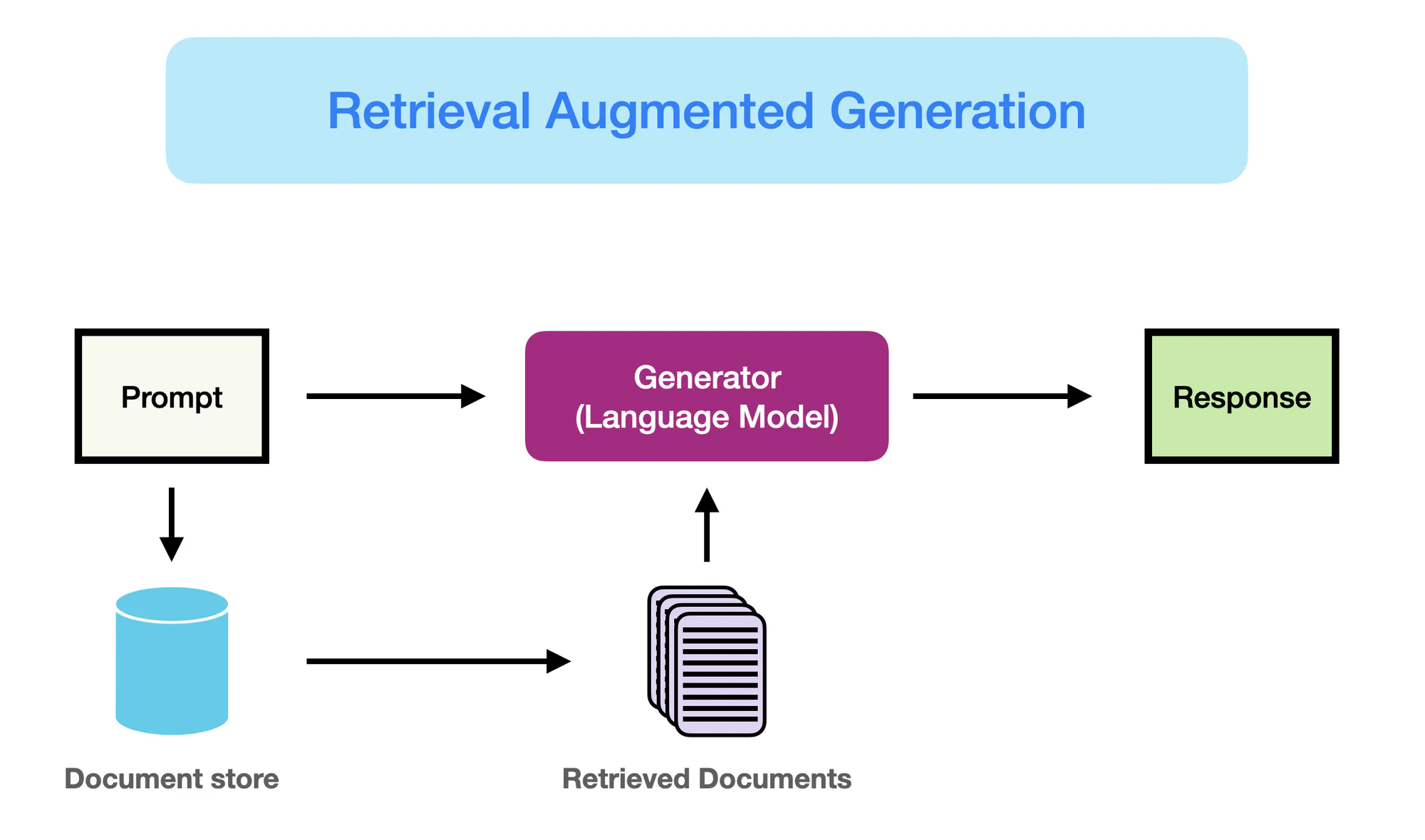
How RAG Works – promptingguide.ai
しかし、ニューラルネットワークベースのモデル、特にBERTやGPT-3などのトランスフォーマーアーキテクチャのモデルの出現が、自然言語処理(NLP)分野を革命しました。
これらのモデルは、大規模言語モデル(LLM)として知られており、深層学習の力を利用して複雑な言語パターンを捕らえ、前例のない流暢さと一致性で人間のようなテキストを生成します。 (Yarnit) LLMの複雑さとスケールの増加に伴い、GPT-3などのモデルは1250億以上のパラメータを持っており、言語翻訳、質問回答、コンテンツ创作などのタスクに対する勋功を立てています。
しかし、传统的なLLMは、纯粹にパラメータ的な記憶に依存するために限界に直面しています。 (StackOverflow) これらのモデルでエンコードされた知識は、静的であり、トレーニングデータの終了日によって制約されています。
結果的に、LLMは実際のところ間違ったものや最新の情報と矛盾する出力を生成することがあります。また、外部知識源への明示的なアクセスがないため、知識依存な質問に対する正確かつ文脈的な回答を提供する能力が限られています。
Retrieval Augmented Generation(RAG)は、これらの限界を克服する划期的な解決策として出現しています。LLMの生成能力と外部情報源からの情報取得能力を密接に統合することで、RAGはモデルに生成過程で関連 knowledge from external sources during the generation process.
この参数的な记忆と非参数的な记忆の融合により、RAGを搭載したLLMが生成する出力は、流暢で一致性があるだけでなく、事実的に正確で、文脈に基づいているということが可能になります。
RAGは言語生成における重要な飛躍的な進歩で、LLMの強みと外部のリポジトリにある非常に多くの知識を合わせています。両方の世界を最善の部分を活用して、RAGはモデルによるテキスト生成をより信頼性のある、情報を提供する、実際の知識に合わせたものにすることができます。
このパラダイムの変換は、質問回答やコンテンツ作成から、ヘルスケア、財務、科学研究などの分野における知識依存の業務に新たな可能性を開くでしょう。
2.2 参数的な記憶と非参数的な記憶
参数的な記憶は、BERTやGPT-4などの预訓練された言語モデルの内部に格納される知識を指します。これらのモデルは、学習過程で大規模のテキストデータから言語パターンと関係を捕らえることを学び、この知識を数百万、数億のパラメータにエンコードします。
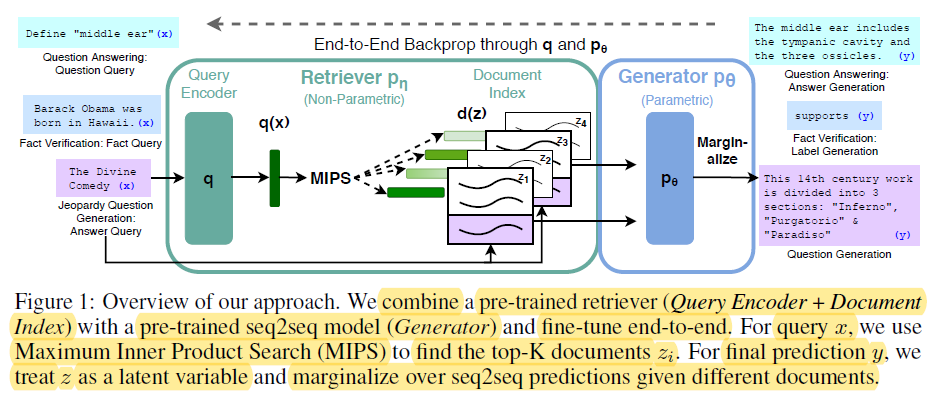
End-t-End Backprop through q and p0 – miro.medium.com
参数的な記憶の強みには以下が含まれます:
- 流暢性: 事前トレーニングされた言語モデルは、人間のような文章を素晴らしい流暢性と一貫性で生成し、自然言語の细かい分别在とスタイルを捉えることができ。(RedisとLewis et alについて)
- 一般化: モデルのパラメータに格納された知識が新しいタスクや領域に一般化することができ、移転学習や少数のショット学習の能力を持つことができ。(RedisとLewis et alについて)
しかし、パラメータ的な記憶は著しい限界があります:
- 事実的な誤差: 言語モデルは、学習されたデータに制限されている知識に基づいて、実際の世界の事実に矛盾する出力を生成することができる。
- 時代遅れの知識: モデルのパラメータに格納された知識は、学習時の状態で固定されており、実際の世界の更新や変化に反映されていないため、随時間に時代遅れする。
- 高い計算コスト: 大规模な言語モデルのトレーニングは、多大な計算資源とエネルギーを必要とし、知識の更新には昂贵で時間がかかる。
- 一般知識: 言語モデルによって捕獲された知識は幅広く、一般的であり、多くの領域特定の应用には深さと特异性が欠けています。
しかしながら、非Parametric Memoryは、データベース、文書、知識グラフなどの明示的な知識源を使用して、言語モデルに最新で正確な情報を提供することを指します。これらの外部源は、生成過程の間、モデルにアクセスおよび要求に応じて関連情報を取得することができる补完的な記憶形態として機能します。
非Parametric Memoryの利点には以下が含まれます:
- 最新の情報: 外部の知識源は簡単に更新および維持でき、モデルが最新で最も正確な情報にアクセスすることを保証します。
- 幻覚の減少: “外部源から関連情報を取り出すことによって、RAGは幻覚または事実上の間違った生成出力の発生を大幅に减少する”(Lewis など.とGuu など.)。
- 分野特定の知識: 非パラメトリック記憶は、モデルが分野特定の情報源から専門的な知識を活用できるようにし、特定のアプリケーションにより正確で脉络に合った出力が可能にします。(Lewis et al. および Guu et al.)
パラメトリック記憶の限界は、言語生成においてパラダイムシフトの必要性を指摘します。
RAGは、情報検索技術を統合することで生成モデルの性能を向上させ、自然言語処理において重要な進歩をもたらしています。(Redis)
以下は、RAGのコンテキストでのパラメトリック記憶と非パラメトリック記憶の違いを示すPythonコードであり、明確な出力ハイライトがあります:
from sentence_transformers import SentenceTransformer
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import FAISS
from langchain.chains import RetrievalQAWithSourcesChain
from langchain.llms import OpenAI
# サンプル文書コレクション(実際のシナリオではより充実した文書を想定)
documents = [
"The Large Hadron Collider (LHC) is the world's largest and most powerful particle accelerator.",
"The LHC is located at CERN, near Geneva, Switzerland.",
"The LHC is used to study the fundamental particles of matter.",
"In 2012, the LHC discovered the Higgs boson, a particle that gives mass to other particles.",
]
# 1. 非パラメトリック記憶(埋め込みを用いた検索)
model_name = "sentence-transformers/all-mpnet-base-v2"
embeddings = HuggingFaceEmbeddings(model_name=model_name)
vectorstore = FAISS.from_documents(documents, embeddings)
# 2. パラメトリック記憶(検索付き言語モデル)
llm = OpenAI(temperature=0.1) # 応答の創造性のための温度を調整
chain = RetrievalQAWithSourcesChain.from_chain_type(llm=llm, chain_type="stuff", retriever=vectorstore.as_retriever())
# --- クエリと応答 ---
query = "What was discovered at the LHC in 2012?"
answer = chain.run(query)
print("Parametric (w/ Retrieval): ", answer["answer"])
query = "Where is the LHC located?"
docs = vectorstore.similarity_search(query)
print("Non-Parametric: ", docs[0].page_content)
出力:
Parametric (w/ Retrieval): The Higgs boson, a particle that gives mass to other particles, was discovered at the LHC in 2012.
Non-Parametric: The LHC is located at CERN, near Geneva, Switzerland.
このコードで何が行われているかについては以下の通りです:
パラメータ的メモリー:
- LLMの广大的な知識を利用して、ヒッグス粒子が他の粒子に質量を与える重要な事実を含む完全な答えを生成する。LLMは、その幅広いトレーニングデータによって「パラメータ化されている」。
非パラメータ的メモリー:
- vektorスペース内で類似性検索を行い、LHCの位置に直接答える質問に最も関連性のある文書を見つける。新しい情報を合成することはなく、関連性のある事実を簡単に取得するだけです。
主要な違い:
| Feature | Parametric Memory | Non-Parametric Memory |
|---|---|---|
| 知識保存 | 学習された表現としてモデルのパラメータ(重み)に格納されている。 | 直接に生のテキストや他の形式(例:嵌入)として格納されている。 |
| 取得 | 学習された知識に基づいて、クエリに関連性のあるテキストを生成するためにモデルの生成能力を使用する。 | クエリに最も似ている文書を探索する(類似性やキーワードの一致を通じて)。 |
| フレキシブリティ | 非常にフレキシブルで、新しい応答を生成することができますが、間違った情報を生成する可能性もあります。 | 柔軟性が低く、既存のデータに依存するため幻覚(誤った情報の生成)にはなりやすくない。 |
| 応答スタイル | より複雑で微妙な応答を生成することができますが、潜在的にはより多くの関連性のない情報を含む可能性があります。 | 直接と簡潔な答えを提供しますが、コンテキストや詳細については欠ける可能性があります。 |
| 計算コスト | 生成反応は計算的に重いことがありますが、大きなモデルにはより甚だしいです。 | retrievalは、効率的な索引とsearch algorithmを用いることで、より速かったです。 |
parametricとnon-parametric memoryの強みを組み合わせることで、RAGは传统の言語モデルの限界を救え、より正確で、更新された、そして文脈において関連性のある出力を生成することができます。(Redis, Lewis et al., そしてGuu et al.)
2.3 多モデルRAG: テキスト
多モデルRAGは、画像、音声、ビデオなどの複数のデータモデルを取り込んだことで、大規模な言語モデル(LLM)の retrieval および生成能力を高めます。
対比学習技術を利用することで、多モデルRAGシステムは異なるデータ型を共有のベクトル空間に埋め込むことを学びますが、これによりよく cross-modal retrieval が可能です。これにより、LLMはより豊かなコンテキスト上で推論することができます。テキスト情報を視覚および音響のサインALlを組み合わせて、より细致した、文脈において関連性のある出力を生成することができます。(Shen et al.)
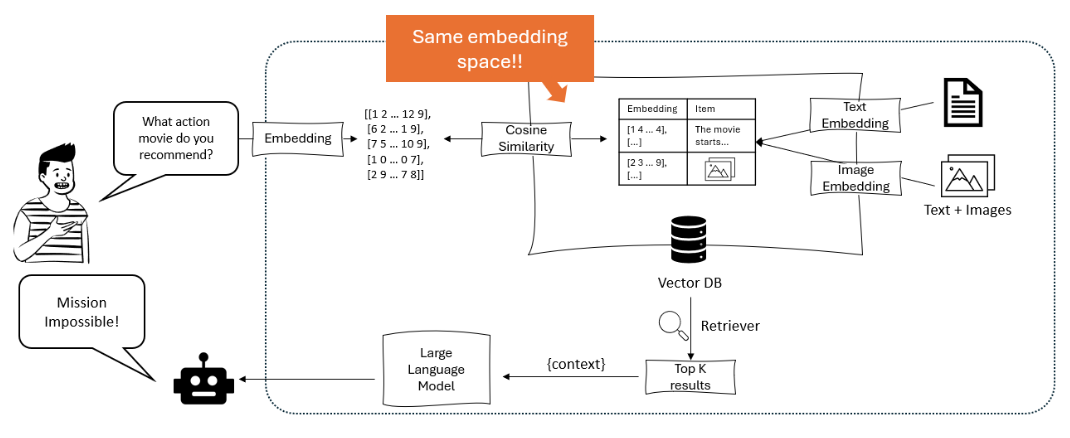
この図は、ユーザーのクエリを埋め込みに変換し、テキストと画像の埋め込みを含むベクターデータベースでコサイン類似度を使用して一致させ、最も関連性の高いアイテムを取得して推奨する大規模言語モデルを用いた推薦システムを示しています。 – opendatascience.com
マルチモーダルRAGの主要なアプローチの一つは、クロスモーダル注意メカニズムを採用するViLBERTやLXMERTのようなトランスフォーマーベースのモデルの使用です。これらのモデルは、テキスト生成中に画像の関連領域や音声/ビデオの特定のセグメントに注意を向け、モダリティ間の微細な相互作用を捉えることができます。これにより、より視覚的かつ文脈に基づいた応答が可能になります。 (Protecto.ai)
RAGパイプラインでのテキストと他のモダリティの統合には、異なるデータタイプ間でのセマンティック表現の整合や、埋め込みプロセス中の各モダリティの独自の特性の処理といった課題があります。これらの課題に対処するために、モダリティ特有のエンコーディングやクロスアテンションなどの手法が使用されます。 (Zhu et al.)
しかし、マルチモーダルRAGの潜在的な利点は大きく、生成されたコンテンツの精度、制御性、解釈性の向上や、ビジュアル質問応答やマルチモーダルコンテンツ制作といった新しいユースケースのサポート能力が含まれます。
例えば、Li 等人(2020年)は、可视化質問回答(VQA)にたいするマルチモーダルRAGフレームワークを提案し、関連する画像とテキスト情報を retrieval して正確な答えを生成することで、VQA v2.0やCLEVRなどのベンチマークにおいて、以前の最も良い手法を上回る結果を得ました。(MyScale)
しかし、マルチモーダルRAGは、計算の複雑性の増加、大規模なマルチモーダルデータセットの需要、およびRETRIEVED情報に偏見やノイズの可能性が引き起こされる新しい課題も引き込んでいます。
研究者たちは、これらの問題を軽減するための技術を积极探索しています。例えば、効率的なインデックス構造、データ拡張戦略、そしてアドバーシャルトレーニング方法です。(Sohoni et al.)
第3章:RAGの核 mechanism
この章では、Retrieval-Augmented Generation(RAG)システム内でRETRIEVERとジェネレーティブモデルの複雑な相互関係を探索し、それらが索引、RETRIEVAL、および生成を行い、正確でコンテキストに合わせた回答を生成するための重要な役割を強調します。
ここで、稀なと密集的なRETRIEVAL技術の強みと弱みを比較し、さまざまな状況でのそれぞれの効果を考察します。また、RETRIEVED情報をジェネレーティブモデルに統合するためのさまざまな戦略についても見てきます。具体的には、結合とクロスアテンションなどです。それらがRAGシステムの全体的な効果に与える影響について讨论します。
これらの統合戦略を理解することで、特定のタスクと領域に最適化されたRAGシステムについての有価な洞察を得ることができ、この強力なパラダイムのより情報を基にした効果的な使用を開くことができます。
3.1 RAGでの情報の retrievalとgenerationの組み合わせの力
Retrieval-Augmented Generation (RAG)は、情報の retrievalをgenerative language modelsと組み合わせた強力なパラダイムです。RAGの名前からは2つの主要なコンポーネントがあることがわかります: RetrievalとGeneration。
retrievalコンポーネントは、知識の大きな存储库を索引化し、搜索しますが、生成コンポーネントは、RETRIEVALされた情報を利用して、文脈に合わせた relevantで、事実に基づいた回答を生成します。(RedisとLewis et al.)
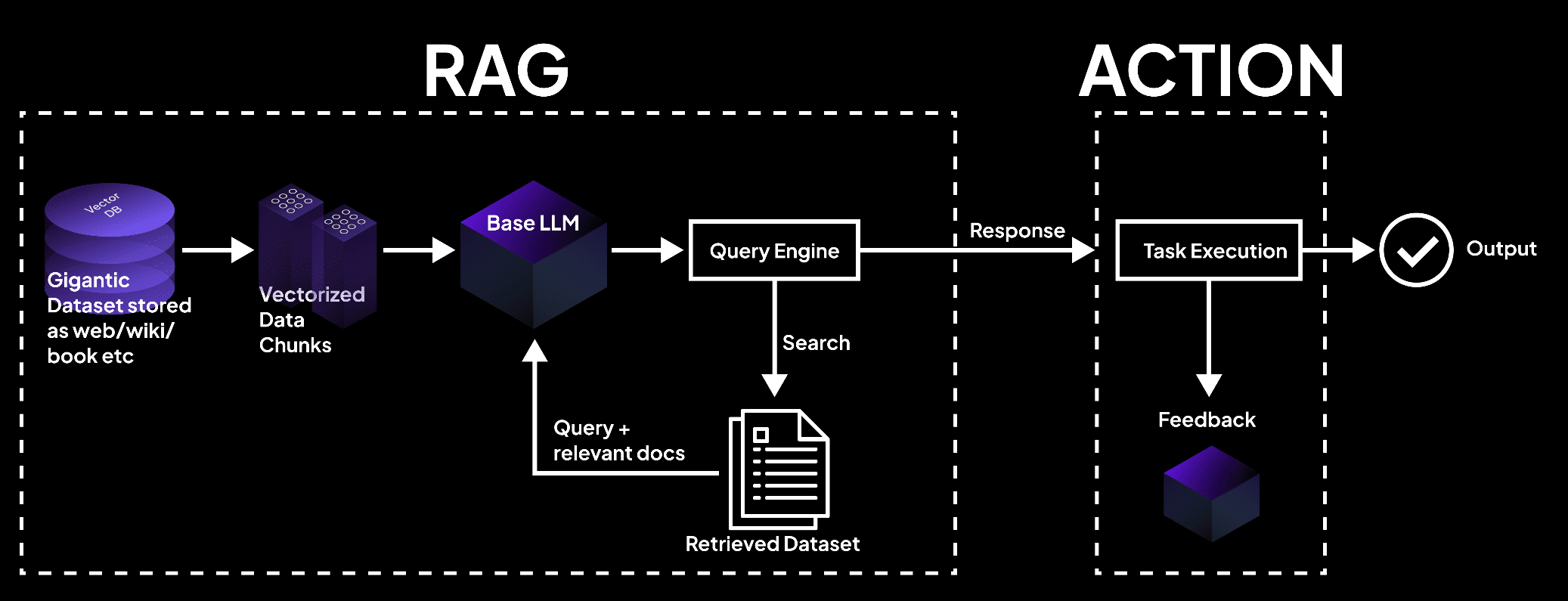
画像は、vector databaseがデータをチャンク化し、language modelによってタスク実行と正確な出力に基づいて文書をRETRIEVALするシステムを示しています。- superagi.com
外部知識源(如データベース、文書、ウェブページ)の索引化が始まることで、情報の取り出しプロセスが開始されます。 (RedisとLewis など) 取り出しと索引化は、効率的に情報を组织和保管し、迅速な探索と取り出しを促進する格式にして、このプロセスにおいて重要な役割を果たします。
RAGシステムに対してクエリが提出されると、取り出し器は索引化された知識ベースを搜索し、意味的な類似性と他の関連指标に基づいて最も関連性のある情報を特定します。
関連する情報を取り出した後、生成コンポーネントが取り越します。取り出した内容は、生成型言語モデルを促し、指導し、必要なコンテキストと事実的な根拠を提供して、正確で情報的な回答を生成するために使用されます。
言語モデルは、アテンション機構やトランスフォーマーアーキテクチャーなどの高度な推論技術を用いて、取り出した情報と既存の知識を合成して、一貫性と流暢性のあるテキストを生成します。
RAGシステム内での情報の流れは以下のように示されます。
graph LR
A[Query] --> B[Retriever]
B --> C[Indexed Knowledge Base]
C --> D[Relevant Information]
D --> E[Generator]
E --> F[Response]
RAGの利点は多く、以下に示します。
この恢复と生成の能力の融合により、文脈に適切なだけでなく、最新で最も正確な情報を参照した回答の作成が可能になります。(Guu et al.)
外部の知識源を活用することで、RAGは純粋に生成型モデルによる常见の陷阱である、幻视や事実上の間違いの发生率を显著に低下させることができます。
また、RAGは最新の情報の統合を許可し、生成される回答は、特定の分野における最新の知識と発展を反映することができます。これは、医療、金融、科学研究など、情報の正確さと实时性が非常に重要な分野に特に重要です。(Guu et al.とNVIDIA)
RAGはまた、素晴らしい適応性を示しており、言語モデルがさまざまな任务を強化されたパフォーマンスで处理することができます。特定のクエリやコンテキストに基づいて相応の情報を動的に参照して、RAGはモデルに対して各々の任务独自の要件に合わせた回答生成を可能にします。これは、質問回答、コンテンツ生成、または分野固有のアプリケーションなどです。
多くの研究で、RAGが生成型言語モデルの事実の正確性、関連性、以及び適応性を向上させる効果を示しています。
リュイスなど(2020)は、RAGが純粋な生成モデルに対して様々な質問応答タスクで優れた性能を示し、Natural QuestionsやTriviaQAなどの基準において最も先进的な結果を達成したことを示しています。(リュイス et al.)
同様に、IzacardとGrave(2021)は、RAGが従来の言語モデルを上回る性能を発揮し、一貫性と事実的な一貫性を持つ長い文章を生成することを証明しました。
検索強化型生成は、言語生成において革新的なアプローチであり、情報検索の力を利用して生成モデルの精度、関連性、適応性を強化します。
外部知識をプリexistentの言語能力と無縁に統合することによって、RAGは自然言語処理に新たな可能性を開き、より知能的で信頼性のある言語生成システムの道を開いています。
3.2 検索器-ジェネレータ統合戦略
検索強化型生成(RAG)システムは、2つの主要なコンポーネントに依存しています:検索器と生成モデル。検索器は、大規模な知識ベースから効率的に情報を検索および取得する役割を果たします。
“それは、2つの主要なフェーズ、インデックス作成と検索を含みます。インデックス作成は、効率的な検索を促進するために文書を編成し、疎検索のためには逆インデックスを使用し、密集検索のためには密集ベクトルエンコーディングを使用します。”(Redis)
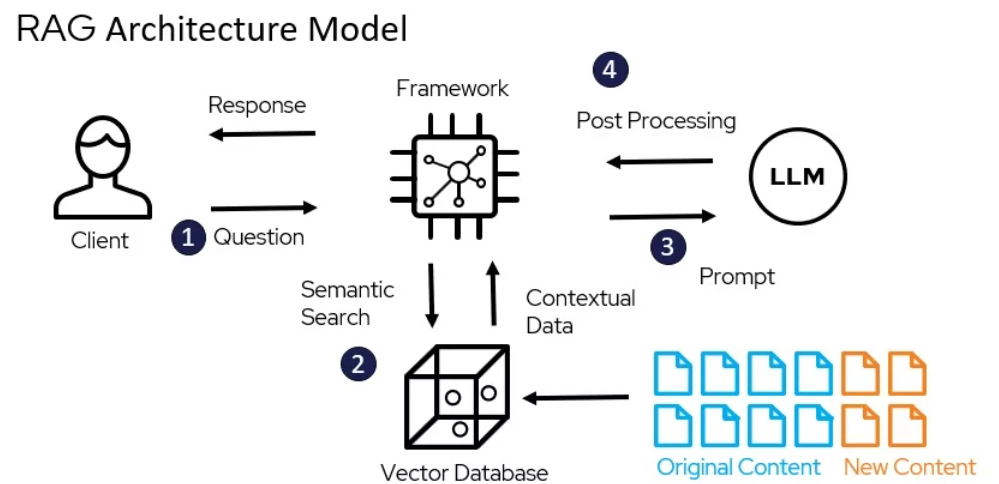
RAGのアーキテクチャモデル – miro.medium.com
TF-IDFとBM25などの稀な取り出し技術は、文書を高次元の稀なベクトルとして表現する。それぞれの次元は語彙の唯一の単語に対応している。文書がクエリとの関連性は、語彙の重叠に基づいて重み付けられた関連性で決まる。
たとえば、人気のあるElasticsearchライブラリを使用して、TF-IDFベースの取り出し器は以下のように実装できる:
from elasticsearch import Elasticsearch
es = Elasticsearch()
es.index(index="documents", doc_type="_doc", body={"text": "This is a sample document."})
query = "sample"
results = es.search(index="documents", body={"query": {"match": {"text": query}}})
密集型取り出し技術は、密集 passage retrieval (DPR)およびBERTベースのモデルなど、文書とクエリを連続的な嵌入空间の密集なベクトルとして表現する。関連性は、クエリと文書ベクトルの余弦類似性に基づいて決まる。
DPRは、Hugging Face Transformersライブラリを使用して実装できる:
from transformers import DPRContextEncoder, DPRQuestionEncoder
context_encoder = DPRContextEncoder.from_pretrained("facebook/dpr-ctx_encoder-single-nq-base")
question_encoder = DPRQuestionEncoder.from_pretrained("facebook/dpr-question_encoder-single-nq-base")
context_embeddings = context_encoder(documents)
query_embedding = question_encoder(query)
scores = torch.matmul(query_embedding, context_embeddings.transpose(0, 1))
生成型モデルは、GPTとT5など、RAGにおいては、取り出した情報に基づいて一贯的でコンテキストに合わせた回答を生成する。これらのモデルを分野固有のデータにファインチューンし、プロンプト工程技術を应用して、RAGシステムでの性能を大幅に向上させることができる。 (DEV Community)
取り出したコンテンツを生成型モデルに統合する策略は、取り出した内容が生成型モデルにどのように取り込まれるかを決める。
「生成コンポーネントは、取り出した内容を使用して、プロンプトンと推論段階により一貫性のある、文脈に合わせた回答を形成する。」(Redis)
2つの一般的なアプローチがあり、串接とクロスアトテンションです。
串接は、取り出したパスワードを入力クエリに追加することで、生成モデルがデコード过程中に関連情報に注意を払うことができます。
实现が簡単ですが、このアプローチは長いシーケンスと不関連な情報に苦しむ可能性があります。(DEV Community)クロスアトテンション機構として、RAG-TokenとRAG-Sequenceがあり、生成モデルが各デコード段階で取り出したパスワードに選択的に注意を払うことができます。
これにより、統合プロセスにより細かいコントロールが可能ですが、計算的な複雑性が増加するという問題があります。
たとえば、Hugging Face Transformersライブラリを使用してRAG-Tokenを実装することができます。
from transformers import RagTokenizer, RagRetriever, RagSequenceForGeneration
tokenizer = RagTokenizer.from_pretrained("facebook/rag-token-nq")
retriever = RagRetriever.from_pretrained("facebook/rag-token-nq", index_name="exact", use_dummy_dataset=True)
model = RagSequenceForGeneration.from_pretrained("facebook/rag-token-nq")
input_ids = tokenizer(query, return_tensors="pt").input_ids
retrieved_docs = retriever(input_ids)
generated_output = model.generate(input_ids, retrieved_docs=retrieved_docs)
RETRIEVER、生成モデル、統合戦略の選択は、知識ベースの大きさや性質、効率と効果のバランス、ターゲットアプリケーション領域によるRAGシステムの特定の要求によって行われます。
第4章:アプリケーションとユースケース
この章では、リテラルリソースを持っていない言語とマルチ言语アプリケーションを革新するために、リテラルアドオン生成(RAG)の変革的な可能性を探る。資源の豊かな言語に原文献を翻訳するなどの戦略、マルチ言语埋め込みを利用し、連邦学習を用いて、データの制約と言語の違いを乗り越える方法などを深く取り組む。
また、マルチ言语RAGシステムで幻影を軽減することが重要であることに注意を払い、正確で信頼性のあるコンテンツ生成を确保する。これらのイノベーティブな取り組みを探ることで、この章はRAGの力を语言処理の包括性と多様性に供給するための完全なガイドを提供します。
4.1 RAGアプリケーション:QAから創造的書き込み
リテラルアドオン生成(RAG)は、さまざまな分野で多くの実用的な应用を見せていて、私たちが情報とのやり取り、生成方法を革新する可能性を示しています。 retrievalと生成の力を活用しているため、RAGシステムは精度、関連性、ユーザーの関心を大きく向上させています。
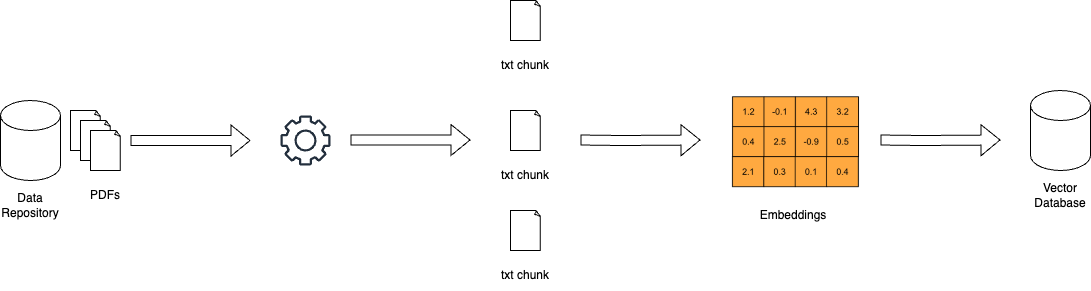
RAGの仕組み – miro.medium.com
質問応答
RAGは、質問回答の分野で変革的なツールとして証明されました。RAGシステムは、外部知識源から関連する情報を取り出し、生成プロセスに組み込んで、ユーザーの質問により正確で、文脈に合わせた回答を提供することができます。(LangChainとDjango Stars)
例えば、IzacardとGrave(2021)は、RAGの基础上に構築された「Fusion-in-Decoder(FiD)」モデルを提案しました。このモデルは、Natural QuestionsやTriviaQAなどの複数の質問回答のベンチマークで最も優れた性能を記録しました。(Izacard and Grave)
FiDは、密接な取り出し機能を用いて関連するパラグラフを取得し、生成型モデルを用いて取得した情報を一貫性のある回答に合成する。これは、纯粹に生成型モデルを大幅に上回る性能を提供します。(Izacard and Grave)
会話システム
RAGは、より魅力的で有用な会話エージェントを作成するためにも応用されています。RAGベースの会話システムは、外部の知識を取り込むことで、適切なコンテキストであり、事実に基づいた回答を生成することができます。(LlamaIndex および MyScale)
Shuster など (2021) は、RAGベースの会話システムであるBlenderBot 2.0を導入し、前作と比較して会話能力が改善されていることを示しました。(Shuster et al.)
BlenderBot 2.0は、ウィキペディア、新聞記事、ソーシャルメディアなどの多くの知識源から関連する情報を取り出すことで、より情報量が多く、 themedliary な会話が可能になります。(Shuster et al.)
要約
RAGは、複数の源の関連情報を取り込むことで、生成される要約の質を向上させると期待されています。(Hyperight) Pasunuru など (2021) は、RAGベースの要約モデルPEGASUS-Xを提案し、外部の文書から関連のあるパーシャルを取り出し、より情報量が多く、themedliaryな要約を生成することができるように統合しました。
PEGASUS-Xは、生成型モデルを超えるサマリーズ化ベンチマークの性能を示し、 retrievalを用いることで、生成された要提高する事実の正確さと関連性の重要性を示しました。
創造的な書き込み
RAGの可能性は、事実の領域だけでなく、創造的な書き込みの分野にも拡大しています。多様な文学作品のコープスから関連するパーシャルを引き取ることで、RAGシステムは新鮮で魅力的な物語や記事を生成することができます。
Rashkin et al. (2020)は、RAGを基盤とした創造的な書き込みモデル、CTRL-RAGを紹介しました。これは大規模な小説データセットから関連するパーシャルを引き取り、生成プロセスに統合します。CTRL-RAGは、一贯性とスタイルの一致性がある物語を生成する能力を示したことで、RAGが創造的な適用においての可能性を示しています。
ケーススタUDY
いくつかの研究論文とプロジェクトで、RAGをいくつかの分野で効果的なものであることを示しています。
たとえば、Lewis et al. (2020)はRAGフレームワークを紹介し、それを開域の質問回答に適用し、自然質問ベンチマークで最も効果的な性能を得ました。(Lewis et al.)彼らは、効率的な retrievalに面临的する課題と、生成型モデルを引き取ったパーシャルによる細微調整の重要性を強調しました。
他の案例研究において、Petroni など (2021) は RAGを事実の確認として適用し、その能力を示した。関連する証拠を抽出し、正確な判決を生成することができることを示した。彼らは、RAGが誤情報と戦う可能性を示し、情報システムの信頼性を向上させる可能性を示した。
RAGは、ユーザー経験とビジネスメトリクスに大きな影響を与えている。より正確で情報量のある回答を提供することで、RAGベースのシステムはユーザーの満足と関与を向上させた。(LlamaIndex と MyScale)
会話エージェントの場合、RAGはより自然で一貫性のある交流を可能にし、ユーザーの保持と忠诚度を増やしました。(LlamaIndex と MyScale) 創造的な書き込みの分野では、RAGはコンテンツ创作プロセスを流暢にすることができ、新しいアイデアを生成し、ビジネスにとって時間とリソースを節約することができます。
ご覧の通り、RAGの実用的な応用は、質問回答と会話システムから要約と創造的な書き込みまでに幅広い分野にわたります。抽出と生成の力を活用することで、RAGは正確性、関連性、およびユーザーの関与に大きな改善を示しています。
その分野が進化を続けるにつれて、私たちはRAGの新しいアプリケーションを期待することができ、さまざまなコンテキストで情報とのやり取りや生成を変えることができる。
4.2 低資源言語と多言語環境におけるRAGの活用
低資源言語と多言語環境でのRetrieval-Augmented Generation (RAG)の実用を #### することは機会ではなく、必要です。世界で7000以上の言語が使われていて、多くの言語には十分なデジタル資源がないことが明らかです。この課題は明確です:デジタル時代にこれらの言語が落后しないようにするのは如何なるか。
翻訳を橋として
一つの効果的な戦略は、索引作成前に源文档を资源が豊富な言語に翻訳することです。この方法は、英語などの言語には十分なコーパスが利用できるため、 retrieval accuracy と関連性の改善に大変役立ちます。
文書を英語に翻訳することで、丰富なリソースと高機能の翻訳技術が既に開発されている高資源言語用に適用できるため、RAGシステムの低資源環境のパフォーマンスを向上させることができます。
マルチlingual Embeddings
最近のマルチ言語単語嵌入の進歩は、また別の有望な解決策を提供しています。複数の言語の共有嵌入空間を作成することで、非常に低資源の言語でも跨言語パフォーマンスを改善することができます。
研究は、高品質の嵌入を持つ中介言語を取り込んだ場合、远い言語ペア之间的を橋渡し、マルチ言語嵌入の全体的な質を向上させることを示しています。
この手法は、不仅要件に基づいた精度を向上させるだけでなく、生成されたコンテンツが文脈的に适宜して、言語的に一貫性を持つことを保証します。
連携学習
連携学習は、データ共有の制約や言語の違いを克服する新しい手法を提供します。デンサードラウンドのデータ源でモデルを细工することで、ユーザーのプライバシーを保護しながら、複数の言語上でモデルの性能を向上させることができます。
この手法は、 traditiona 方法より6.9%の精度向上と99%のトレーニングパラメータの削減を示しており、多言語RAGシステムにおける高效率と効果的な解決策です。
幻影を軽減する
多言語環境でRAGシステムを実装する際の重要な課題の1つは、幻影の軽減です。これは、モデルが事実的に間違ったまたは関連性のない情報を生成するインスタンスを指します。
Modular RAGなどの高度なRAG技術は、新しいモジュールと細工ステートメントを導入してこの問題を解決します。知識ベースを継続的に更新し、厳密な評価基準を採用することで、幻影の発生率を大幅に低下させ、生成されたコンテンツが正確で信頼性があることを保証することができます。
実践的な実装
これらの戦略を効果的に実装するために、以下の実践的な手順を考慮してください。
- 翻訳を活用する: 索引作成前に低資源言語の文書を英语など高資源言語に翻訳してください。
- 多言語エンブレディングの利用: 高品質のエンブレディングを持った中介言語を統合して、クロス言語性能を改善する。
- 連携学習の導入: デンドラル化されたデータ源でモデルを微調整することで、パフォーマンスを向上させながらプライバシーを保護する。
- 幻视現象の軽減: 高度なRAG技術と知識ベースの連続的な更新を採用して、事実の正確性を確保する。
これらの戦略を採用することで、低資源環境や多言語環境においてRAGシステムの性能を大幅に向上させることができ、デジタル革命であらゆる言語が落ちこぼれないようにする。
第5章: 最適化技術
この章では、Retrieval-Augmented Generation (RAG)システムの効果を支える高度な呼声技術について調査します。チャンク最適化、メタデータ統合、グラフ基盤の索引、アルインメント技術、ハイブリッド検索、以及び再順序化が情報呼声の精度、関連性、そして完全性を向上させる仕組みを探ることができます。
これらの最先端の方法を理解することで、RAGシステムが単なる搜索引擎から、複雑なクエリを理解し、正確で、コンテキスト的に関連性のある応答を提供することができる知的情報提供者にどのように進化したのかを見ることができます。
5.1 RAGシステムの最適化に使用する高度な呼声技術
Retrieval Augmented Generation (RAG)システムは、私たちがアクセスおよび利用する情報の方法を革新しています。これらのシステムの核となるのは、効果的に関連する情報を取り出す能力です。
Let’s delve deeper into the advanced retrieval techniques that empower RAG systems to deliver accurate, contextually relevant, and comprehensive responses.
高度な取得技術についてより深く調査しましょう。これらの技術は、RAGシステムが正確で、文脈的に関連性のある、包括的な回答を提供するのに役立ちます。
チャンク最適化:グラニュラー取得を通じた関連性最大化
RAGシステムの世界では、大きな文書は厄介であることがあります。チャンク最適化は、この課題に対応し、広範なテキストをより小さく、管理しやすいユニットであるチャンクに分割します。この粒度は、取得システムがクエリー用語に合致するテキストの特定の部分を指摘することができ、精度と効率を改善します。
チャンク最適化の芸術は、理想的なチャンクサイズと重複を決定することにあります。過小なチャンクは文脈を失いかねず、过大なチャンクは関連性を薄めかねません。動的チャンkingは、コンテンツの構造とセマンティクスに基づいてチャンクサイズを適応させる技術で、各チャンクが一貫性と文脈的な意味を持つことを保証します。
メタデータ統合:情報タグの力を利用する
文書に付属する、しばしば見落とされるメタデータは、取得システムにとって金の山です。文書タイプ、著者、公開日、トピックタグなどのメタデータを統合することで、RAGシステムはよりターゲット付けられた検索を行うことができます。
自己クエリー取得は、メタデータ統合によって可能にされる技術で、システムは初期の結果に基づいて追加のクエリーを生成することができます。この反復過程は検索を精製し、取得された文書がクエリーに合致するだけでなく、ユーザーの特定の要件と文脈的なニーズにも応じます。
従来の索引方法、如く逆向索引と密集ベクトルエンコーディングは、複数のエンティティと彼らの関連性を含む複雑なクエリに対応する際に制約がある。图基索引は、文書とその関連をグラフ構造に組織して解決を提供する。
このようなグラフ構造により、関連のある文書の効率的な巡回と取得が可能で、複雑な状況でもよく行える。階層索引と近傍のApproximate Nearest Neighbor Searchは、图基の取得システムのスケーラビリティと速度をさらに向上させる。
アラインメント技術:正確さと幻视を確保し减少する
RAGシステムの信頼性は、正確な情報を提供する能力に基づいている。アラインメント技術、例えば対照的訓練は、この問題に取り組む。モデルに対して仮想的な状況に触れることで、対照的訓練は実際の世界の事実と生成された情報を区別することを教えてくれるし、そうすることで幻视を減少させる。
マルチモーダルRAGシステムは、テキストと画像など様々な源からの情報を統合する。この技術は、異なるデータモーダリティの意味的な表現を対齐させることが重要で、抽出された情報が一貫性を持ち、文脈的に統合されることを保証する。
ハイブリッドサーチ:キーワードの正確さと意味理解を融合する
ハイブリッドサーチは、両方の利点をCombineする。まず、キーワードベースの搜索は可能な文書のPoolを速く狭めます。
後に、ベクトル基盤のsearchが、語义の似さに基づいて結果を细工します。この手法は、正確なキーワードの一致を重要視する場合に特に有効ですが、クエリの意図に深い理解が必要であるため、正確な抽出が可能です。
Re-ranking: Refining Relevance for the Optimal Response
抽出の最終段階で、re-rankingが結果を細工することになります。クロスエンコーダなどの機械学習モデルが、抽出された文書の関連度スコアを再評価します。クエリと文書を同時に処理することで、これらのモデルは彼らの関連性に深い理解を得ます。
このような细微な比較は、最も上位に評価された文書が実際にはユーザーのクエリとコンテキストに合致していることを保証し、より満足を得ることができるようにします。
RAGシステムの強みは、情報を流暢に抽出して提供する能力にあります。これらの高度な抽出技術を適用して、チャンク最適化、メタデータ統合、グラフ基盤の索引、アラインメント技術、ハイブリッド検索、およびre-rankingを行います。これらの技術を应用して、RAGシステムは単なる搜索引擎を超え、複雑なクエリを理解し、细かい違いを区別し、正確で、関連性があり、信頼できる回答を提供する知的な情報提供者に成長します。
Chapter 6: Challenges and Innovations
この章は、Retrieval-Augmented Generation (RAG) システムの開発と導入における主要な課題と将来の方向性に深く取り組みます。
私たちは、RAGシステムの評価の複雑さを探ります。それには、その性能を正確に評価するための包括的な指標と適応的なフレームワークの必要性、情報 retrievalおよび生成における偏見軽減と公正性の倫理上的考慮が含まれます。
また、ハードウェア加速と効率的な部署戦略の重要性を考察し、スペシャルハードウェアおよびOptimumなどの最適化ツールの使用を強調して、パフォーマンスとスケーラビリティを向上させることに焦点を当てます。
これらの課題を理解し、潜在的な解決策を探ることによって、この章はRAG技術の持続的な発展と責任ある実装のための完璧なロードマップを提供します。
6.1 課題と未来の方向
Retrieval-Augmented Generation (RAG)システムは、生成テキストの精度、関連性、一致性を向上させるときには驚くほどの可能性を示してきました。しかし、RAGシステムの開発と部署は、その潜在的な可能性を完全に実現するために解決すべき重要な課題を抱えています。
“RAGシステムの評価は、特定のコンポーネントの多くと全システム評価の複雑さを考慮する必要があります。”(Salemi et al.)
RAGシステムの評価における課題
RAGの主要な技術課題の1つは、大規模知識ベースから適切な情報の効率的な取得を保証することです。(Salemi et al.およびYu et al.)
知識源の大きさと多样性がどんどん増加しているため、スケーラブルで強固な取得メカニズムの開発は、ますます重要です。階層的なインデックス作成、近傍を推定する最近傍探索、適応的な取得戦略など、取得プロセスを最適化するために探求する必要があります。
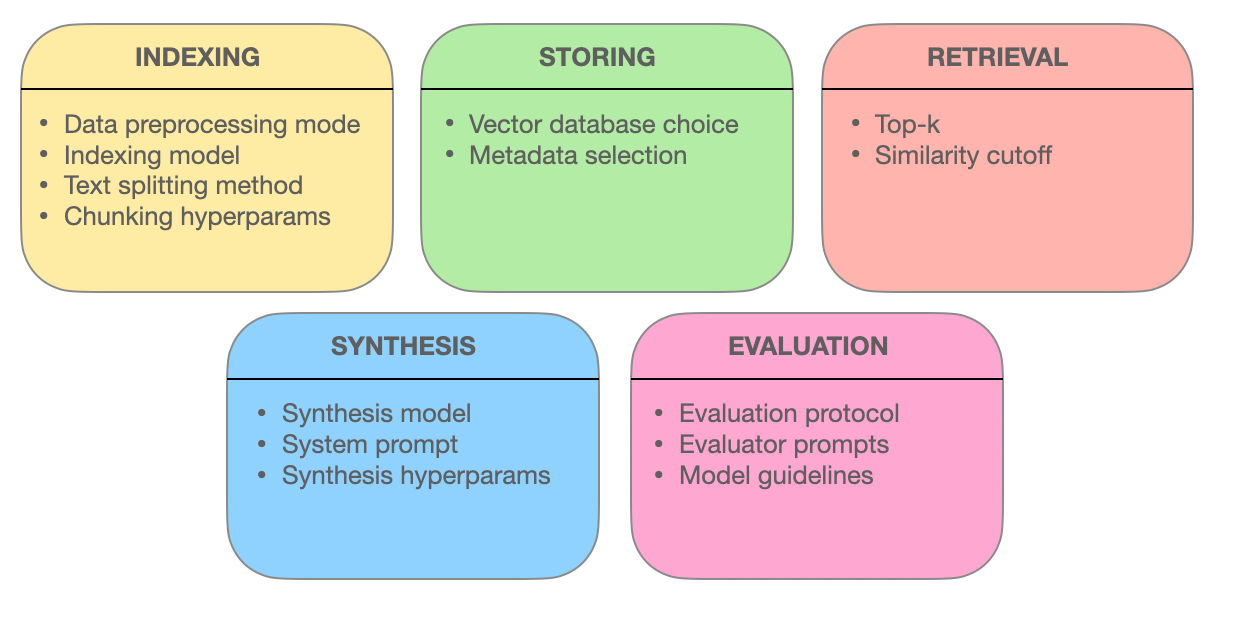
RAGシステムに涉及される要素 – miro.medium.com
もう1つの重要な課題は、幻覚现象の軽減することです。生成型モデルが事実上不正確なまたは不一致な情報を生成する問題です。
たとえば、RAGシステムは歴史上の事件を生成し、科学の発見を間違って归属することができます。取得が事実的な知識に根ざした生成文本を保証することは、やっとも複雑な問題です。
たとえば、RAGシステムはウィキペディアなど信頼性のある源から科学の発見について正確な情報を取得することができますが、生成型モデルはこれらの情報を誤って結合したり、存在しない詳細を追加して幻覚を引き起こすことができます。
効果的な幻覚の検出と防止机制の開発は研究の活気ある分野です。外部データベースを使用した事実確認と複数の源を交叉参照した一致性チェックなどの技術が究極されています。これらの手法は、取得と生成プロセスを並行させることに固有の困難にもかかわらず、生成されたコンテンツが正確で信頼性を持ち続けることを目的としています。
RAGシステムにおいて、構造化されたデータベース、非構造化テキスト、マルチモーダルデータなどの多様な知識源を統合することは、追加の困難をもたらします。(Yu et al.とZilliz)異なるデータモーダリティと知識形式の表現と意味を合わせるためには、クロスモーダルアテンションや知識グラフエンジニアリングなどの高度な技術が必要です。各种知識源の互換性と互操作性を保証することは、RAGシステムの効果的な機能を実現するには重要です。(Zilliz)
セレミー他。 と バナファによる):
トレーニングデータや知識源に存在する偏向を意図せず拡大させることがあり、差別的または誤解を招く出力を引き起こすRAGシステムは、公正で無偏の情報の取得と生成を保証することが重要な伦理的な考慮を引き起こします。バナファによる):
偏向の検出と軽減のための技術、例えば敵対的学習と公平性を考慮した回収を開発することは、重要な研究途上です。
将来の研究方向
RAGシステムの評価の課題に対処するために、いくつかの潜在的な解決策と研究方向を探索することができます。セレミー他。による):回収の精度と生成の質の間の相互作用を捉える包括的な評価指標の開発は、重要です。
生成テキストの関連性、一貫性、事実の正確性を評価し、検索コンポーネントの効果性を考慮するメトリクスを設定する必要があります。(Salemi et al.)これは、BLEUやROUGEのような従来のメトリクスを超え、人的評価とタスク固有の測定を取り入れる包括的アプローチを必要とします。
適応性と実時間評価フレームワークの探索は、別の有望な方向です。
RAGシステムは、知識ソースとユーザーの要求が時間とともに変化する動的環境で動作します。(Yu et al.)これらの変化に適応し、システムの性能に関する実時間のフィードバックを提供する評価フレームワークの開発は、持続的な改善と監視に不可欠です。
これは、ユーザーのフィードバックとシステムの行動に基づいて、評価メトリクスとモデルを更新するオンライン学習、活動的学習、強化学習などの技術を含むかもしれません。(Yu et al.)
研究者、業界実践者、そして分野の専門家の間の共同作業は、RAG評価の分野を進展させるために必要である。標準化されたベンチマーク、データセット、そして評価プロトコルの設定は、異なる分野や應用においてRAGシステムの比較と再現性を促進することができる。 (Salemi et al.およびBanafa)
最終用户および政策制定者を含む利害関係者と取り組むことは、RAGシステムの開発および導入が社会の価値と倫理原則に沿っていることを保証するために重要である。(Banafa)
しかし、RAGシステムは非常に大きな可能性を示しているが、その評価における課題を解決することは、彼らの幅広く導入されるように信頼を持っている必要がある。より完璧な評価指標を開発し、適応的な实时評価フレームワークを探索し、協力努力を促進することで、信頼できる、偏見のない、効果的なRAGシステムを開辟することができる。
分野が進化するに伴い、技術的なRAGの capabilityを進展させるだけでなく、彼らが実際の应用で責任あると伦理的な導入を保証する研究努力を優先することが不可欠である。
6.2 RAGシステムのハードウェアアクセラレーションと効率的な導入
ハーネスングハードウェア加速は、Retrieval-Augmented Generation (RAG) システムの効率的な導入に欠かせない。計算的に強い任务を専門化的ハードウェアにオフロードすることで、RAGモデルのパフォーマンスとスケール性を大幅に向上させることができる。
ハードウェアに特化した最適化ツール
Optimumのツールを利用することで、大きな利点を得ることができる。たとえば、Habana GaudiプロセッサにRAGシステムを導入することで、推論のレイテンシーを显著に短縮することができ、Intel Neural Compressorの最適化によりレイテンシーの指標をさらに改善することができる。Optimum Neuronを通じて最適化されたAWS Inferentiaハードウェアは、吞吐量の capabilityを向上させ、RAGシステムをより反应的で効率的なものにすることができる。
リソースの最適化
効率的なリソース利用は非常に重要である。Optimum ONNX Runtimeの最適化により、メモリの使用がより効率的になることができ、BetterTransformer APIはCPUとGPUの利用を改善することができる。これらの最適化は、RAGシステムが最も効率的に作動し、运算コストを低め、パフォーマンスを向上させることを保証します。
スケーラビリティとフレキシビリティ
Optimumは異なるハードウェア加速器間でスムーズな移行をサポートしており、動的スケール性を提供しています。このマルチハードウェアサポートは、核算的な computational demandに适応するために大幅な再構成を行わずに、変更を受け入れることができます。また、Optimumにあるモデルクォンセンションとプルング機能は、より効率的なモデルサイズを実現し、導入を簡素化し、コスト効率を向上させることができます。
ケーススタディと実際の応用
医療情報検索において最適化アプリケーションを考慮する。ハードウェアに特化した最適化を活用することで、RAGシステムは大規模なデータセットを効率よく処理し、正確で及时の情報検索を提供する。これは、医療サービスの質を向上させるだけでなく、全体的なユーザー経験を改善する。
実践的な実施手順
- 適切なハードウェアの選択:具体的なパフォーマンス要件に基づいて、Habana GaudiやAWS Inferentiaのようなハードウェアアクセラレータを選択してください。
- 最適化ツールの利用:Optimumの最適化ツールを実装して、レイテンシー、スループット、リソース Utilizationを向上させます。
- スケール可能性を確保する:マルチハードウェアサポートを利用して、必要に応じてRAGシステムを動的にスケールする。
- モデルサイズの最適化:モデル量化和プルリングを使用して、計算オーバーヘッドを reduceし、デプロイの手間を軽減する。
これらの戦略を統合することで、RAGシステムのパフォーマンス、スケール性、効率を大幅に向上させることができます。これにより、複雑な実際の应用に対応するのに最適な装備が整ったことを保証します。
結論:RAGの変革的な可能性
Retrieval-Augmented Generation (RAG)は、自然言語処理の新たなパラダイムを表しており、情報 retrievalのパワーと大規模な言語モデルの生成能力を密接に統合しています。
外部の知識源を活用することで、RAGシステムは、質問回答や対話システムから要提高Abstractや創造的な書き言葉に至るまでに幅広いアプリケーション领域で、生成したテキストの精度、関連性、一致性に著しい改善を示しています。
言語モデルの進化は、初期のルールベースシステムからBERTやGPT-3などの最も最先端のニューラルアーキテクチャーまでを経て、RAGの出現に道を開いています。伝統的な言語モデルの纯粋なパラメータ記憶の限界、例えば知識の切れ端日と事実の不一致など、 Retrieval機構を通じて非パラメータ記憶の組み入れによって効果的に解決されています。
RAGシステムの核のコンポーネント、それは取得機(Retriever)と生成モデルであり、これらは一緒になって、コンテキスト的に関連性のあるものと事実に基づく出力を生成します。
取得機は、スパースなどの技術を用いて、最も関連性のある知識ベース内で効率的に搜索します。生成モデルは、GPTやT5のアーキテクチャーを利用して、抽出された内容を coherent and fluent textに合成します。
統合戦略、例えば結合とクロスアテンションなど、抽出された情報が生成プロセスにどのように取り込まれるかを決定します。
RAGの実用的な応用は、多様な分野をカバーしており、これは様々な産業を革新する可能性を示しています。
質問応答において、RAGは、返信の精度と関連性を显著に改善し、より情報的で信頼性の高い情報を引き出すことができました。対話システムは、RAGの恩恵を受け、より魅力的で一貫性のある会話を実現しました。要約タスクは、複数の源からの関連情報を統合することで、品質と一貫性を向上させました。また、創造的な書き込みも探索され、RAGシステムは新しく、スタイル的に一致する物語を生成することができました。
しかしながら、RAGシステムの開発と評価は、大きな挑戦を伴います。大規模な知識ベースから効率的に検索すること、幻想の軽減、及び多様なデータの模様を統合することなど、技術的な壁が存在しています。倫理的な考慮、特に偏見のない、公平な情報の引き出しと生成を保証することは、RAGシステムの責任ある導入に際して非常に重要です。
RAGの可能性を完全に実現するために、将来の研究段階は、 retrieval精度と生成品質の相互関係を捕らえることができる全面的な評価指標の開発に集中する必要があります。
適応性と実時間の評価フレームワークは、RAGシステムの動的な性質を処理することが必要で、持続的な改善とモニタリングに欠かせません。研究者、業界実践者、そして分野の専門家の间的協力が必要で、標準化されたベンチマーク、データセット、そして評価プロトコルを設立することが必要です。
RAGの分野がどのように进化していくにつれて、私たちが情報とのやり取りや生成を行う方法を大きく変える大きな約束を持っています。RETRIEVAL-AUGMENTED GENERATIONは、更なる知能を持ち、正確で、文脈に合わせた言葉の生成において重要な飛躍的な進歩を表しています。
パラメータ的な記憶と非パラメータ的な記憶の間を架けることで、RAGシステムは自然言語処理とその应用に新たな可能性を开いています。
研究が进展を遂げ、課題が解決されるたびに、RAGが人間と機械の交流と知識の生成の未来を形成する重要性を増やすことが期待されます。
著者について
Vahe Aslanyanは、コンピューターサイエンス、データサイエンス、AIの交差点にいます。
precisionandprogressの証であるポートフォリオを見るには、vaheaslanyan.comに訪れてください。私の経験は、フルスタック開発とAI製品最適化の間を結びつけ、新しい方法で問題解決に取り組むものです。
トレンド的なデータ科学のブートキャンプを立ち上げ、そして業界のトップ専門家と共同作业を行ったことがあり、私の焦点は、テクノロジー教育を普遍的な基盤に升华为することです。
どうやって深めることができますか?
このガイドを学んだ後、もっと深く钻き込むことが望まれるとき、个别的な学習があなたのスタイルであれば、LunarTechに加入してください。私たちは、データ科学、機械学習、AIの個別コースとブートキャンプを提供しています。
私たちは、理論の深い理解を提供し、实際の実装のための手順を提供し、幅広い練習材料を提供し、身に付けるための針對的な面接準備を提供しています。これらを通じて、各段階で成功を収める準備をお願いいたします。
私们的究極のデータサイエンスブートキャンプをご確認ください。無料トライアルに参加して、コンテンツを直接試してみてください。これは2023年の最も優れたデータサイエンスブートキャンプの1つとして认知され、フォーブス、ヤフー、エントレプレンアーなどの有名な誌で特集しています。これは、革新と知識に耽溺するコミュニティーの一員になるチャンスです。
私とコネクトしてください。

LunarTechニュースレター
- LinkedInで私に关注して、CS、ML、AIに関する大量の無料リソースを入手してください
- 私の個人ウェブサイトを訪れてください
- 私のデータ科学とAIニュースレターに suscribe してください。
データ科学、機械学習、AIの分野でのキャリアについて学び、データ科学の仕事を手的に入れる方法を学びたい方は、この無料のデータ科学とAIキャリアハンドブックをダウンロードすることができます。
Source:
https://www.freecodecamp.org/news/retrieval-augmented-generation-rag-handbook/