













ユーバーのような企業では、リアルタイムデータは顧客向けサービスだけでなく内部サービスの生命線です。顧客はリアルタイムデータに依存して、都合の良い時に乗車や食料品の取得を行っています。内部チームも最新のデータに依存して、顧客向けアプリケーションの背後にあるインフラストラクチャを活用しており、例えば、モバイルアプリのクラッシュ分析を監視する社内ツールです。
ユーバーはこの社内ツールを強化するためにApache Pinotに移行し、以前の分析エンジン(Elasticsearch)と比較して大幅な改善を実現しました。Pinotを導入することで、本当のリアルタイム分析プラットフォームとして、以下のような利点を得ました:
- インフラコストの70%削減(年間200万ドル以上の節約)
- CPUコアの80%削減
- データフットプリントの66%削減
- ページロード時間の64%削減(14秒から5秒未満)
- 取り込み遅延を10ミリ秒未満に削減
- クエリタイムアウトの減少とデータ損失問題の解消

今すぐ視聴
このブログの内容は、Apache Pinotのユーザーストーリーを特集したインページングミートアップに基づいています。また、ユーバーのエンジニアリングチームのブログも参照し、モバイルアプリのクラッシュに対するリアルタイム分析をどのように提供しているかを説明しています。ミートアップをこちらで視聴できます:
あるいは、ユーバーがApache Pinotでこれらの結果をどのように達成したかを読んで学ぶことができます。
モバイルアプリのクラッシュに対するリアルタイム分析をユーバーがどのように提供しているか
Uberは、アプリのクラッシュを追跡し、調査データを収集する自動化された取り込みパイプラインを持っています。このデータの一部は、Apache Flinkに取り込まれて変換され、その後、下流の消費のためにKafkaトピックに戻されます。Kafka内のこれらの生のイベントと処理されたイベントは、Apache Pinotによって消費され、分析クエリが実行され、その結果がGrafanaと内部の可視化ツールを通じて内部ユーザーに届けられます。彼らのパイプラインはリアルタイムおよびオフラインデータ(描かれていない)の両方を取り込み、Apache Pinotのハイブリッドテーブルとして知られるユーザーの完全なビューを作成します。
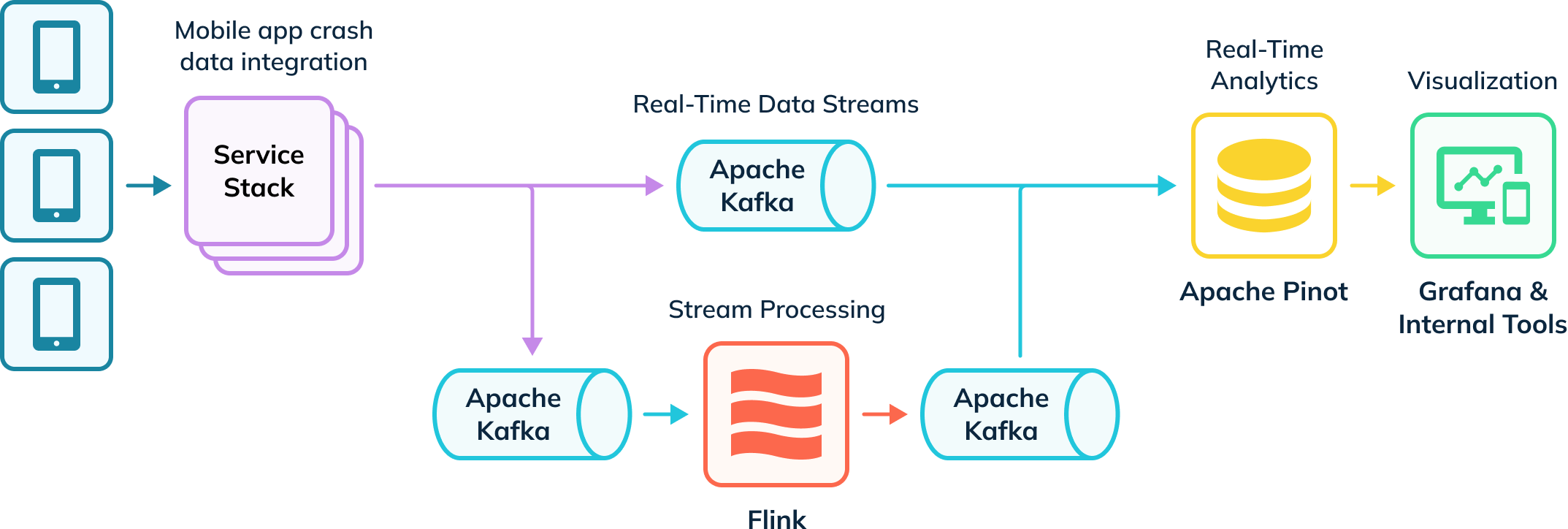
Apache Pinotによるリアルタイムアプリクラッシュ分析
Uberは毎週約11,000の新しいコードとインフラストラクチャの変更をリリースし、クラッシュ問題の検出と解決を支援するために独自のツール(Healthline)に依存しています。Healthlineを使って、UberはMean Time To Detect(MTTD)をより良く測定し、達成することができます。例えば、予期しないアプリクラッシュを引き起こす新機能をリリースする場合、クラッシュデータを掘り下げることでクラッシュの原因を迅速に特定できる必要があります。
以下のダッシュボードは、1つのモバイルアプリと1つのOSバージョンの1週間分のクラッシュデータを示しています。この例では、セッションイベントは1秒あたり数十万回発生し、クラッシュは1秒あたり15,000から20,000イベントで測定されます。Uberはこれらの指標を組み合わせて致命的クラッシュ無しの率を計算し、アプリケーションの健全性を示します(目標は100%に近づけることです)。
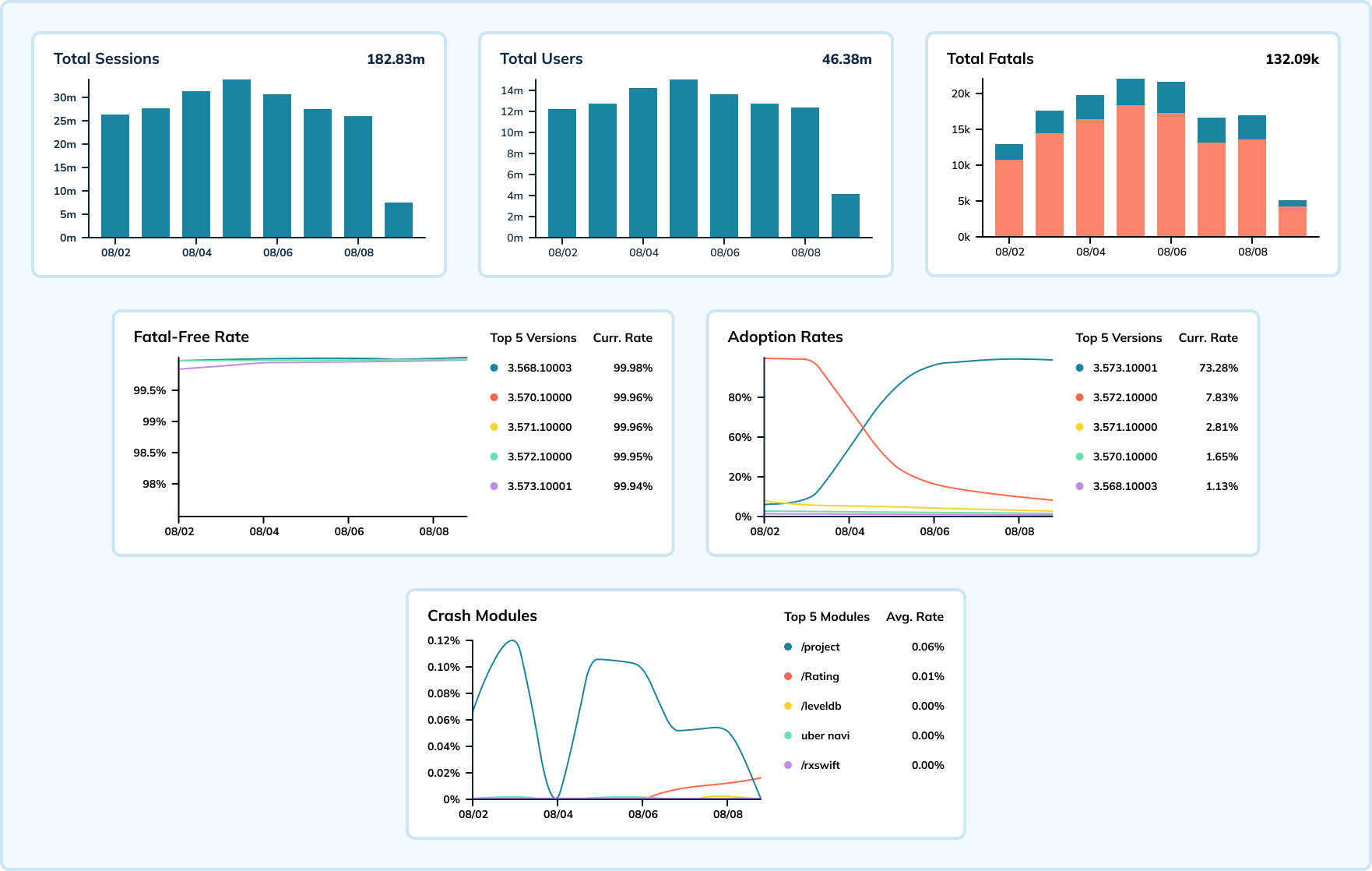
Elasticsearchを使っていたとき、クラッシュ率の急増が取り込みの遅延を引き起こし、問題の特定へのチームの対応を遅らせていました。大規模なリアルタイム分析に特化して設計されたApache Pinotに移行することで、チームは取り込み遅延の数と深刻度が減少したことを確認しています。
クラッシュデータの詳細分析
クラッシュデータの概要だけでなく、Uberは詳細なクラッシュレベルの分析も提供しています。オペレーティングシステムやバージョンごとのクラッシュ数、バージョンごとのクラッシュ分布など、様々な次元でクラッシュ指標を集計しています。このユースケースでは、あるタイプのクラッシュが発生した時、どのバージョンが影響を受けたか、発生回数、影響を受けたユーザー数やデバイス数を共有するために、複数のPinotインデックス(レンジ、インバース、テキスト)を活用しています。
詳細な分析を行うには、クラッシュエラーメッセージを読むためのテキスト検索機能がUberにとって不可欠でした。PinotのテキストインデックスはLuceneの上に構築されており、クラッシュメッセージ、クラス名、スタックトレースなどでクラッシュを検索できる能力を提供しています。
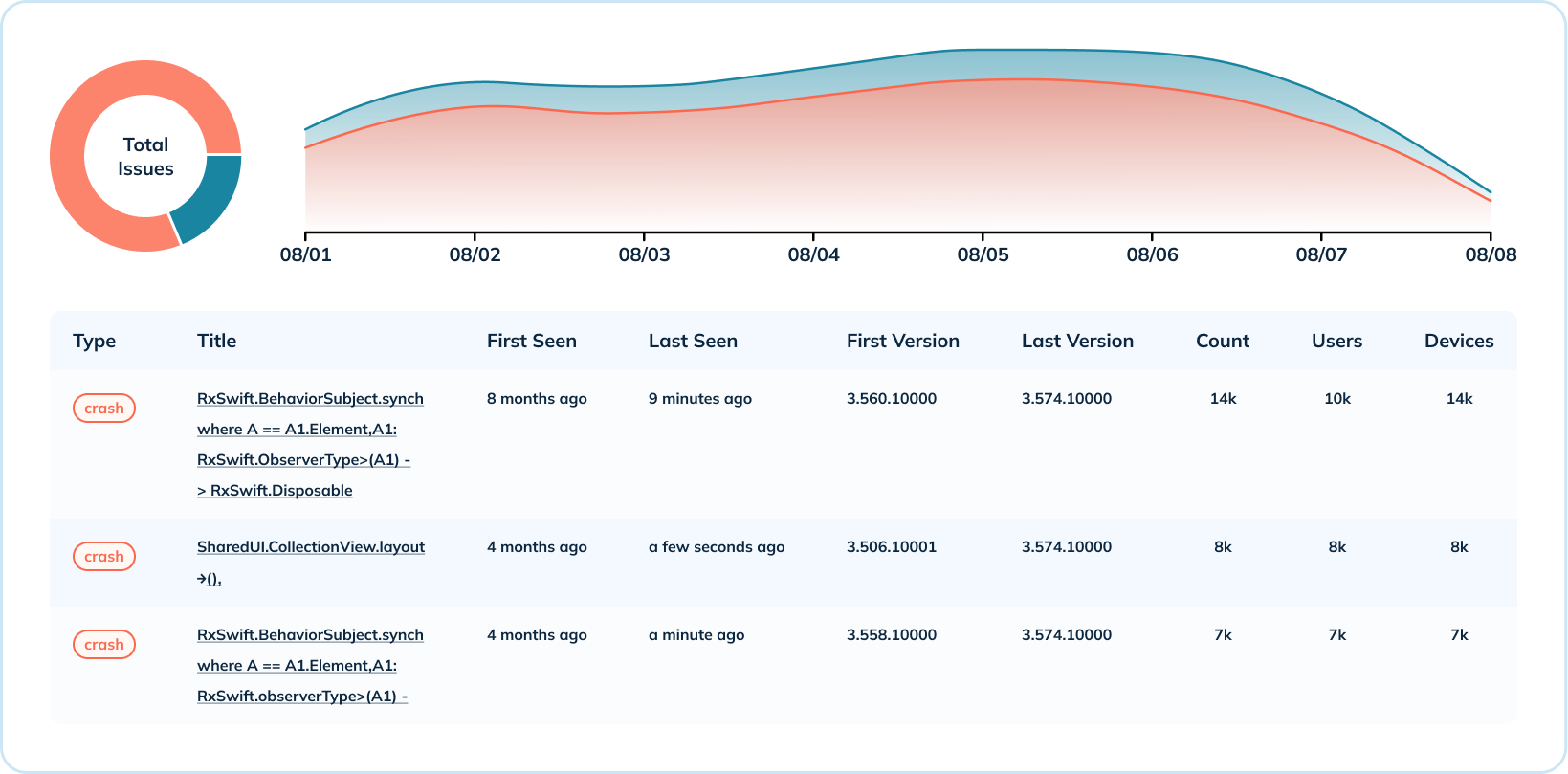
大規模なセッションの測定
Uberはまた、Pinotを使用して、デバイス、バージョン、オペレーティングシステム、時間ごとのユニークセッションを大規模に測定しています。Pinotは、Uberの30万件/秒の分析イベントを取り込むことができる高スケールのスループットでリアルタイム処理を提供しています。チームは、リアルタイムテーブル(10分間隔、3日間データ保持)とオフラインテーブル(1時間間隔、1日間隔、45日間データ保持)を含むハイブリッドセットアップを持っています。
Apache PinotのHyperLogLogを活用することで、チームは保存するイベントの数を減らし、イベント全体での一意な集計をより少なく行うことができました。また、Pinotは非常に低いレイテンシを提供しており、p99.5のレイテンシは100ミリ秒未満です。
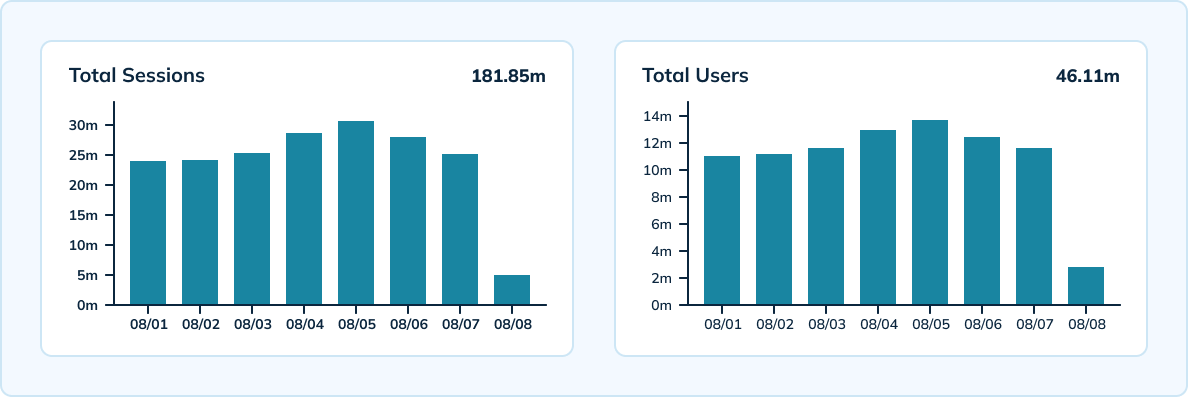
インフラコストの節約
Uberの計算によると、Pinotへの移行により年間のインフラコストを200万ドル以上節約しました。彼らのPinot設定は、Elasticsearchに比べてインフラコストを70%削減し、CPUコア数を80%、データフットプリントを66%減らしました。

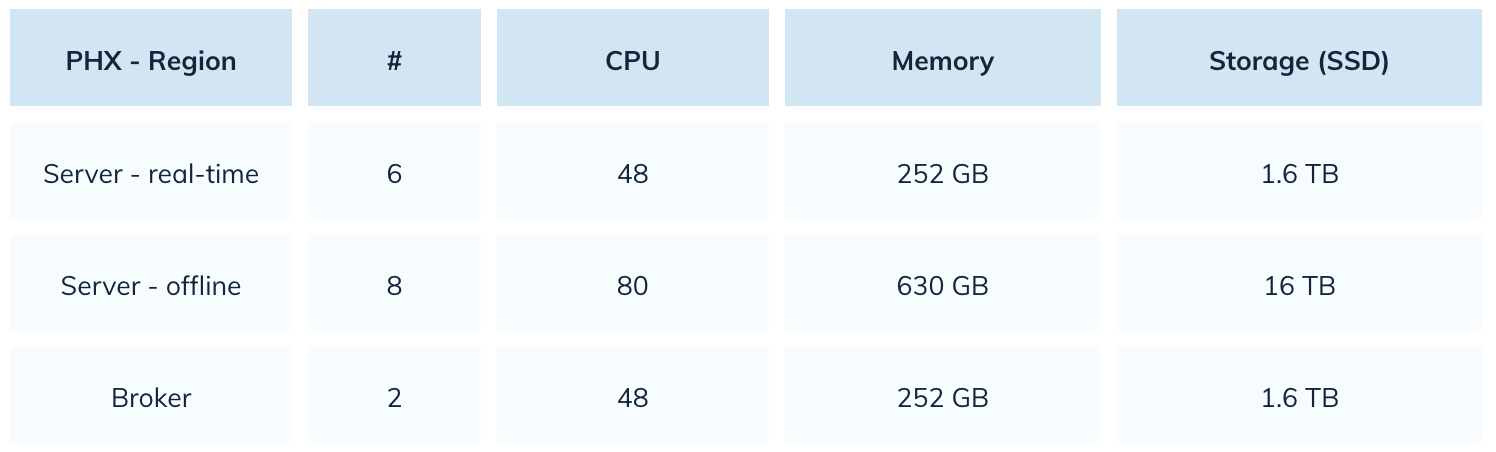
Elasticsearchを使用していたUberは、22,000コアのCPUを使用していました。Pinotを使用することで、その数を80%削減しました。彼らのPinot設定のスナップショットは以下の通りです。
クエリパフォーマンスとユーザーエクスペリエンスの改善
Apache Pinotを使用することで、Uberはより速いページ読み込みと信頼性の向上でユーザーエクスペリエンスを向上させることができました。Pinotへの移行により、ページ読み込み時間が64%削減され、14秒から5秒未満に短縮されました。Pinotはまた、負荷の急増に対する耐性があり、遅延の回復がより迅速になります。たとえインジェスト遅延が発生しても、Pinotは数分以内に迅速に回復します。
Elasticsearchと比較して、Pinotはクエリタイムアウトとデータ損失においても顕著な改善を示しています。Elasticsearchを使用していた時に、モバイルアプリケーションで災害が発生した場合、そのインデックスに関連するクエリがタイムアウトすることがありました。UberはPinotでセグメントサイズを制御することでこの問題を解決しました。また、Pinotを使用している間はデータ損失の問題は発生せず、Elasticsearchが増加したインジェストスループットを処理していた時に頻繁に発生していた問題とは対照的です。
UberのPinot設定の次の進化
次に、Uberはモバイルのクラッシュデータにネイティブテキストインデックスを移行する予定です。彼らのモバイルクラッシュデータには多くの構造化データが含まれており、チームがすべてのユースケースをネイティブテキストインデックスに移行することが現実的です。この移行により、データストレージからのコスト削減とデータ照会に費やされる時間の短縮が実現されます。
ElasticsearchからPinotに移行することで成功を収めたのはUberだけではありません
Uniqode(旧Beaconstac)はElasticsearchからPinotに切り替えることで、全体的なクエリパフォーマンスが10倍向上しました。Cisco Webexも高いレイテンシーに直面した後、リアルタイム分析と可観測性をPinotに移行しました。Webexチームは、Apache PinotがElasticsearchよりも5倍から150倍低いレイテンシーを提供することを発見しました。
Source:
https://dzone.com/articles/real-time-app-crash-analytics-with-apache-pinot